TL;DR#
Contrastive Language-Image Pre-Training (CLIP) is good at high-level semantics but lacks in fine-grained visual details. To fix this, generative models use CLIP’s visual features for reconstruction. However, the underlying principle remains underexplored. The authors found that visually perfect generations aren’t always optimal for enhancement. Effective extraction of fine-grained knowledge while reducing irrelevant info is key. They found that even small local tokens can cause training collapse, leading to the conclusion that only global visual tokens are most effective.
To address this, the authors introduce GenHancer, a two-stage training strategy prioritizing useful visual knowledge, using lightweight denoisers, showing that end-to-end training introduces extraneous information. They validate their method using both continuous and discrete denoisers and present an effective method (GenHancer) that consistently outperforms prior methods on the MMVP-VLM benchmark. Enhanced CLIP leads to vision-centric performance.
Key Takeaways#
Why does it matter?#
This paper introduces GenHancer, a novel method enhancing vision-centric tasks by improving how generative models extract and transfer knowledge to discriminative models like CLIP. The insights on conditioning, denoising, & model design offer pathways for boosting multimodal models & visual understanding.
Visual Insights#

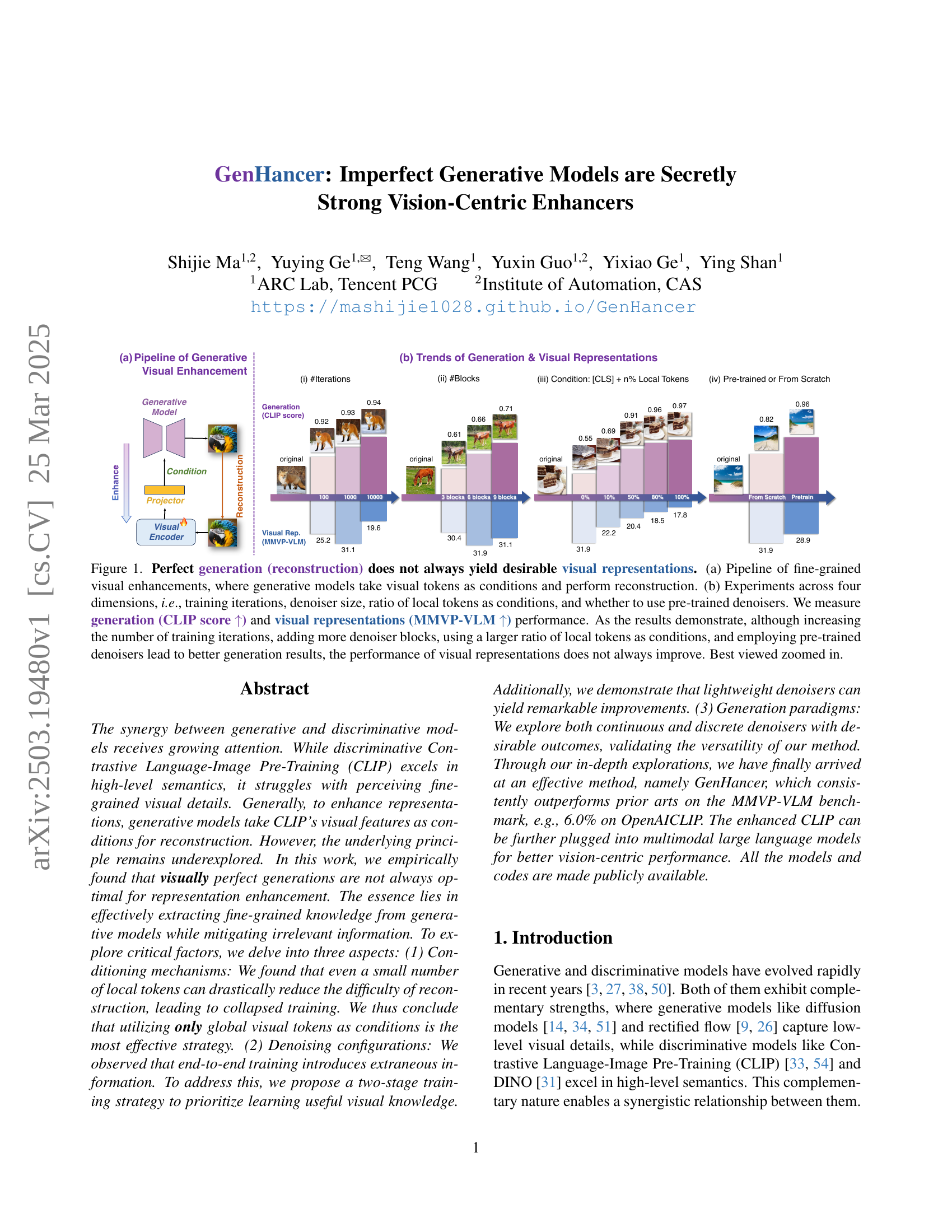
🔼 Figure 1 explores the relationship between perfect image generation and the quality of resulting visual representations. Panel (a) illustrates the method: a generative model reconstructs an image conditioned on visual tokens. Panel (b) shows experiments varying four factors: training iterations, denoiser size, the proportion of local tokens used for conditioning, and whether a pre-trained denoiser was used. The evaluation metrics were CLIP score (higher is better, indicating better generation) and MMVP-VLM score (higher is better, indicating better visual representation). The results demonstrate that while increasing training iterations, adding denoiser blocks, using more local tokens, and using pre-trained denoisers improve generation quality (CLIP score), this does not guarantee improved visual representation quality (MMVP-VLM score). In other words, perfect image reconstruction does not always lead to better visual features.
read the caption
Figure 1: Perfect generation (reconstruction) does not always yield desirable visual representations. (a) Pipeline of fine-grained visual enhancements, where generative models take visual tokens as conditions and perform reconstruction. (b) Experiments across four dimensions, i.e., training iterations, denoiser size, ratio of local tokens as conditions, and whether to use pre-trained denoisers. We measure generation (CLIP score ↑↑\uparrow↑) and visual representations (MMVP-VLM ↑↑\uparrow↑) performance. As the results demonstrate, although increasing the number of training iterations, adding more denoiser blocks, using a larger ratio of local tokens as conditions, and employing pre-trained denoisers lead to better generation results, the performance of visual representations does not always improve. Best viewed zoomed in.
| CLIP Backbone | #Params (M) | Resolution | Method | \faCompass | \faSearch | \faSync | \faSortNumericUp | \faMapPin | \faPalette | \faCogs | \faFont | \faCamera | Average |
| OpenAI ViT-L-14 | 427.6 | 2242 | Original | 13.3 | 13.3 | 20.0 | 20.0 | 13.3 | 53.3 | 20.0 | 6.7 | 13.3 | 19.3 |
| + DIVA | 13.3 | 20.0 | 40.0 | 6.7 | 20.0 | 53.3 | 46.7 | 20.0 | 13.3 | 25.9 | |||
| + Ours | 13.3 | 33.3 | 33.3 | 20.0 | 6.7 | 73.3 | 46.7 | 20.0 | 40.0 | 31.9 (+6.0) | |||
| OpenAI ViT-L-14 | 427.9 | 3362 | Original | 0.0 | 20.0 | 40.0 | 20.0 | 6.7 | 20.0 | 33.3 | 6.7 | 33.3 | 20.0 |
| + DIVA | 26.7 | 20.0 | 33.3 | 13.3 | 13.3 | 46.7 | 26.7 | 6.7 | 40.0 | 25.2 | |||
| + Ours | 6.7 | 20.0 | 33.3 | 20.0 | 6.7 | 73.3 | 53.3 | 26.7 | 26.7 | 29.6 (+4.4) | |||
| MetaCLIP ViT-L-14 | 427.6 | 2242 | Original | 13.3 | 6.7 | 66.7 | 6.7 | 33.3 | 46.7 | 20.0 | 6.7 | 13.3 | 23.7 |
| + DIVA | 6.7 | 6.7 | 60.0 | 0.0 | 26.7 | 66.7 | 20.0 | 20.0 | 40.0 | 27.4 | |||
| + Ours | 13.3 | 20.0 | 53.3 | 13.3 | 26.7 | 80.0 | 33.3 | 13.3 | 33.3 | 31.9 (+4.5) | |||
| MetaCLIP ViT-H-14 | 986.1 | 2242 | Original | 6.7 | 13.3 | 60.0 | 13.3 | 6.7 | 53.3 | 26.7 | 13.3 | 33.3 | 25.2 |
| + DIVA | 13.3 | 20.0 | 53.3 | 33.3 | 13.3 | 66.7 | 33.3 | 13.3 | 40.0 | 31.9 | |||
| + Ours | 20.0 | 20.0 | 66.7 | 26.7 | 26.7 | 66.7 | 33.3 | 20.0 | 53.3 | 37.0 (+5.1) | |||
| SigLIP ViT-SO-14 | 877.4 | 2242 | Original | 26.7 | 20.0 | 53.3 | 40.0 | 20.0 | 66.7 | 40.0 | 20.0 | 53.3 | 37.8 |
| + DIVA | 13.3 | 26.7 | 60.0 | 46.7 | 13.3 | 73.3 | 53.3 | 26.7 | 53.3 | 40.7 | |||
| + Ours | 20.0 | 20.0 | 66.7 | 60.0 | 20.0 | 86.7 | 40.0 | 13.0 | 53.3 | 42.2 (+1.5) | |||
| SigLIP ViT-SO-14 | 878.0 | 3842 | Original | 20.0 | 26.7 | 60.0 | 33.3 | 13.3 | 66.7 | 33.3 | 26.7 | 53.3 | 37.0 |
| + DIVA | 26.7 | 33.3 | 53.3 | 26.7 | 13.3 | 80.0 | 40.0 | 26.7 | 46.7 | 38.5 | |||
| + Ours | 26.7 | 20.0 | 66.7 | 33.3 | 13.3 | 86.7 | 40.0 | 26.7 | 46.7 | 40.0 (+1.5) |
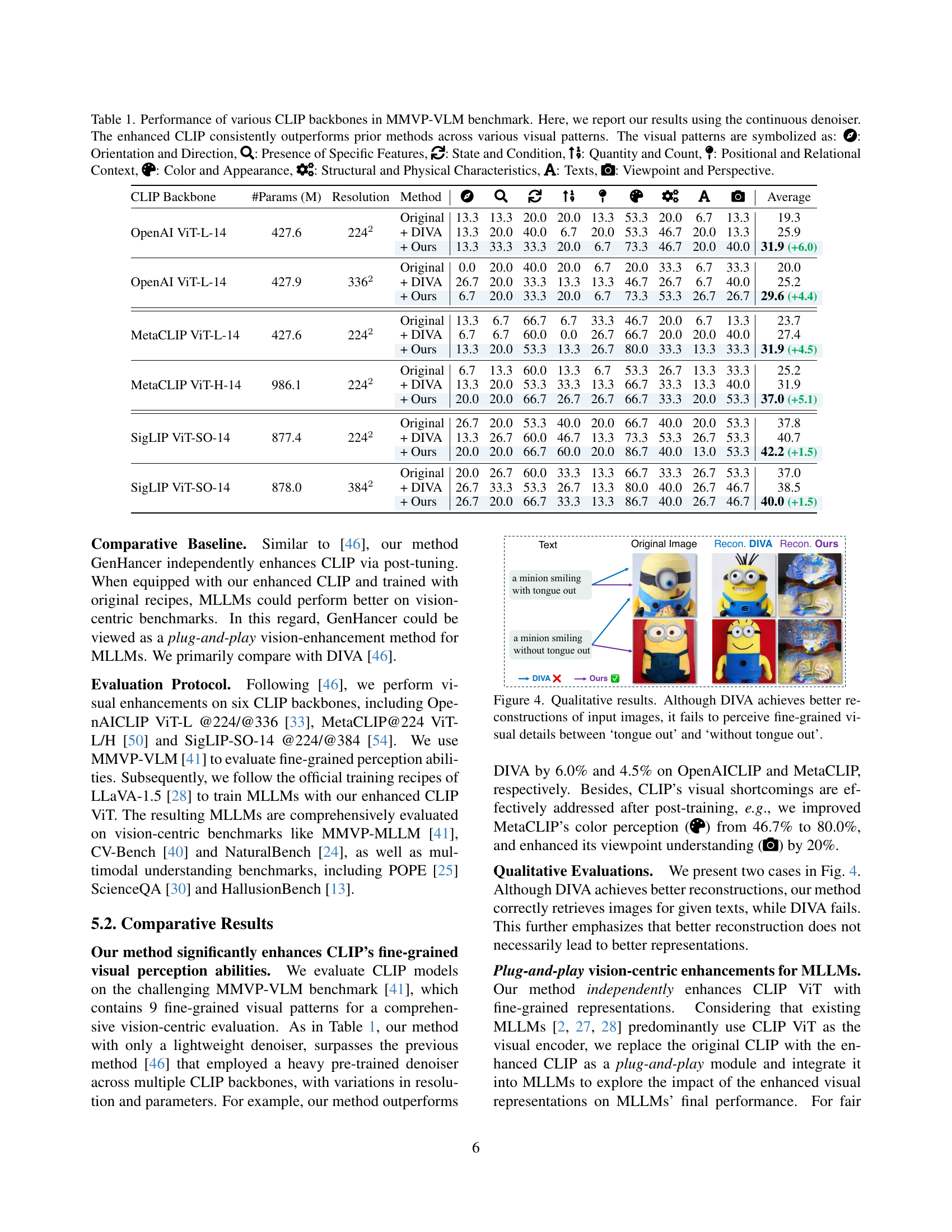
🔼 Table 1 presents a comprehensive evaluation of various CLIP backbones (OpenAI ViT-L, MetaCLIP ViT-L/H, and SigLIP ViT-SO) using the MMVP-VLM benchmark. The table compares the performance of the original CLIP models against those enhanced using both DIVA and the proposed GenHancer method. The results highlight GenHancer’s consistent superiority across different visual patterns (orientation, feature presence, state/condition, quantity, spatial context, color/appearance, physical characteristics, text, and viewpoint), showcasing its effectiveness in improving fine-grained visual perception capabilities. The use of a continuous denoiser in GenHancer is specified in the caption.
read the caption
Table 1: Performance of various CLIP backbones in MMVP-VLM benchmark. Here, we report our results using the continuous denoiser. The enhanced CLIP consistently outperforms prior methods across various visual patterns. The visual patterns are symbolized as: \faCompass: Orientation and Direction, \faSearch: Presence of Specific Features, \faSync: State and Condition, \faSortNumericUp: Quantity and Count, \faMapPin: Positional and Relational Context, \faPalette: Color and Appearance, \faCogs: Structural and Physical Characteristics, \faFont: Texts, \faCamera: Viewpoint and Perspective.
In-depth insights#
GenHancer Intro#
The introduction of ‘GenHancer’ likely sets the stage by highlighting the evolving synergy between generative and discriminative models, recognizing their individual strengths: discriminative models like CLIP excel in high-level semantics, while generative models capture low-level visual details. The intro motivates the need to enhance representations by leveraging generative models for reconstruction tasks, taking CLIP’s visual features as conditions. The paper challenges the assumption that perfect generations are always optimal, suggesting an exploration of the underlying principles for effective enhancement. It is expected to outline the key aspects investigated: conditioning mechanisms, denoising configurations, and generation paradigms, eventually leading to the introduction of ‘GenHancer’ as a novel and effective method.
Vision Enhancement#
Vision enhancement through generative models is an emerging field that leverages the strengths of both discriminative and generative networks. Generative models excel at capturing low-level visual details, which discriminative models sometimes miss. By using generative models to reconstruct visual features extracted by models like CLIP, we can imbue discriminative models with a finer-grained understanding of images. The key idea is that by forcing the discriminative model to learn to generate accurate reconstructions, it is forced to pay attention to and encode these fine-grained details. However, perfect reconstruction isn’t always optimal; there is a balance to be struck between fidelity and capturing relevant features. Effective vision enhancement necessitates extracting valuable knowledge from generative models while filtering out irrelevant information. Furthermore, the way visual information is conditioned, the denoising configuration and the generation paradigm all play key roles in improving the visual representational power of the original visual models.
Models Comparison#
When comparing models, several factors must be taken into account, including accuracy, computational efficiency, and generalizability. Evaluating models on multiple datasets can provide a more robust understanding of their performance and highlight potential biases or limitations. It’s crucial to consider the trade-offs between model complexity and performance, as more complex models may not always lead to better results. Another important aspect is the interpretability of the models, which can be crucial for understanding their behavior and identifying potential issues. Additionally, the robustness of the models to noisy or incomplete data should be evaluated. Also, to evaluate the models, the number of parameters must be considered.
Conditional Tokens#
In generative models, conditional tokens play a crucial role in guiding the generation process. The choice of these tokens significantly impacts the model’s ability to capture relevant information and produce desired outputs. Using the right conditional tokens can effectively steer the generative model towards specific features or characteristics, enhancing its control and precision. Appropriate token selection is paramount for achieving high-quality and tailored generations, avoiding irrelevant or noisy information that might hinder the desired outcome. Therefore, thoughtful consideration must be given to the design and implementation of conditional token strategies in generative models, as they directly influence the model’s capacity to produce targeted and meaningful results. The design should be such that extracted knowledge is useful and mitigates extraneous information.
Future MLLMs work#
Future work in Multimodal Large Language Models (MLLMs) could focus on improving fine-grained visual understanding, addressing current limitations in perceiving details like color, orientation, and quantity. Research should explore more efficient generative models and training strategies, such as the proposed two-stage approach, to enhance visual representations within MLLMs without relying on computationally expensive, pre-trained denoisers. Another avenue involves investigating the synergy between continuous and discrete generative models to optimize visual feature extraction. Further research could also focus on integrating these enhanced vision encoders into various MLLM architectures to evaluate the broad applicability and impact on diverse multimodal tasks. Finally, developing more comprehensive vision-centric benchmarks to better assess the performance improvements in fine-grained visual understanding will be crucial for guiding future progress in this area.
More visual insights#
More on figures

🔼 Figure 2 demonstrates the efficiency and effectiveness of the proposed GenHancer method compared to the existing DIVA [46] method. Subfigure (a) highlights that GenHancer only requires a lightweight denoiser, unlike DIVA which relies on heavy, pre-trained generative models. Subfigure (b) shows that despite its simplicity, GenHancer achieves superior performance in terms of visual representation quality, as measured by the MMVP-VLM benchmark.
read the caption
Figure 2: Comparison with prior method [46]. (a) We only need a lightweight denoiser, but (b) achieve stronger performance than DIVA [46], which relies on pre-trained heavy generative models.

🔼 Figure 3 illustrates the two-stage training process used to enhance visual representations. Panel (a) shows the overall pipeline, starting with noisy input and resulting in enhanced representations. Panel (b) details the continuous generative model (denoiser) which uses a lightweight FLUX-like diffusion transformer (DiT) with fewer blocks than the original, minimizing computational cost. A regression loss based on flow matching is used for training this denoiser. Panel (c) presents the discrete generative model (denoiser) which uses a lightweight Perceiver architecture. This model employs a cross-entropy loss function to predict masked tokens during training.
read the caption
Figure 3: The two-stage post-training framework for visual enhancements. (a) Overall training pipeline. (b) Continuous generative model as the denoiser. We employ a lightweight FLUX-like DiT [22] (but with fewer blocks) and employ a regression loss of flow matching. (c) Discrete generative model as the denoiser. We choose a lightweight Perceiver [17] and employ cross-entropy loss to predict masked tokens.
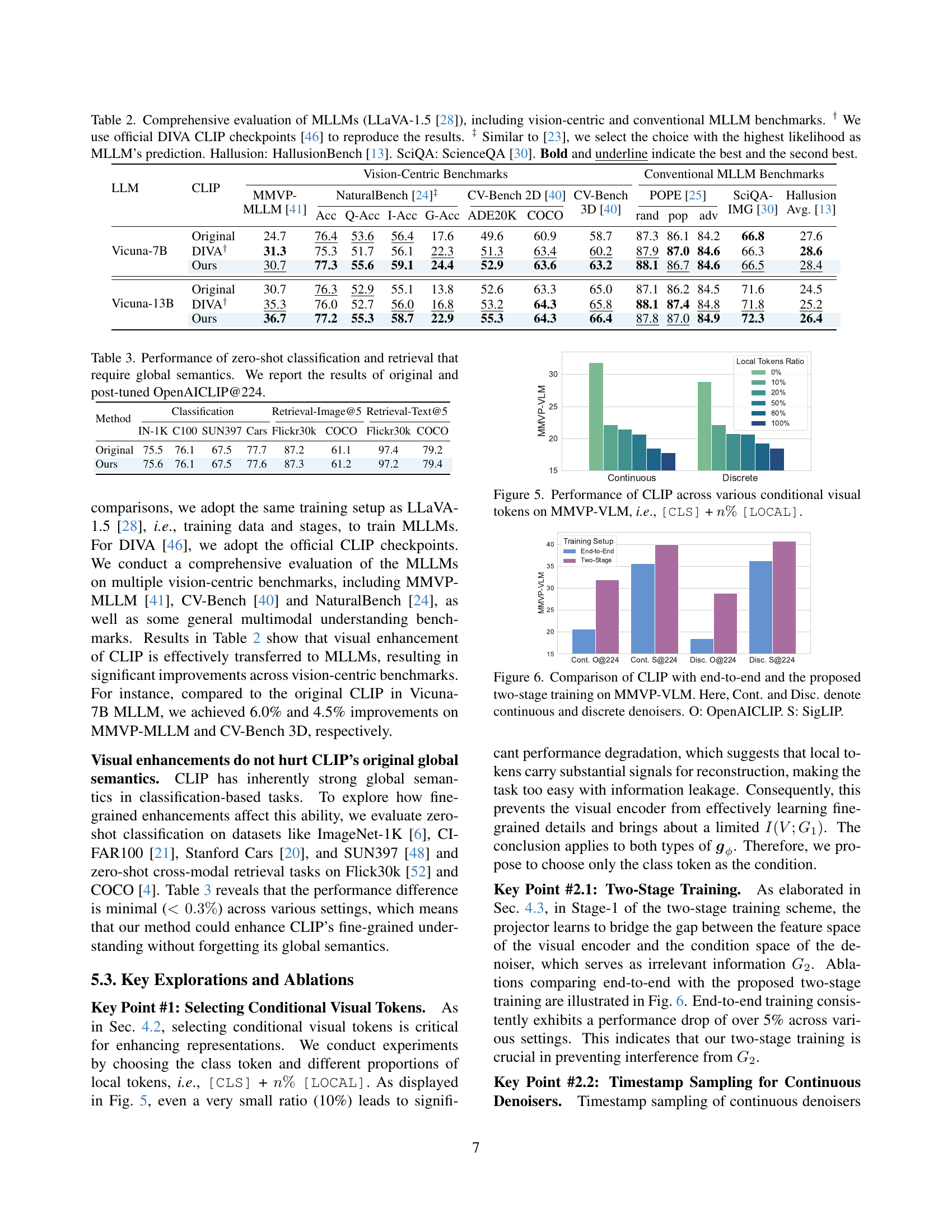
🔼 Figure 4 presents a qualitative comparison of image reconstruction and captioning results between the proposed GenHancer method and the DIVA method. Both methods aim to improve CLIP’s fine-grained visual understanding. While DIVA achieves visually superior image reconstructions, it fails to accurately differentiate between subtle visual details, such as a minion’s tongue being out or not. GenHancer, conversely, shows better performance in distinguishing these fine-grained differences, highlighting its ability to enhance CLIP’s capacity for precise visual comprehension.
read the caption
Figure 4: Qualitative results. Although DIVA achieves better reconstructions of input images, it fails to perceive fine-grained visual details between ‘tongue out’ and ‘without tongue out’.

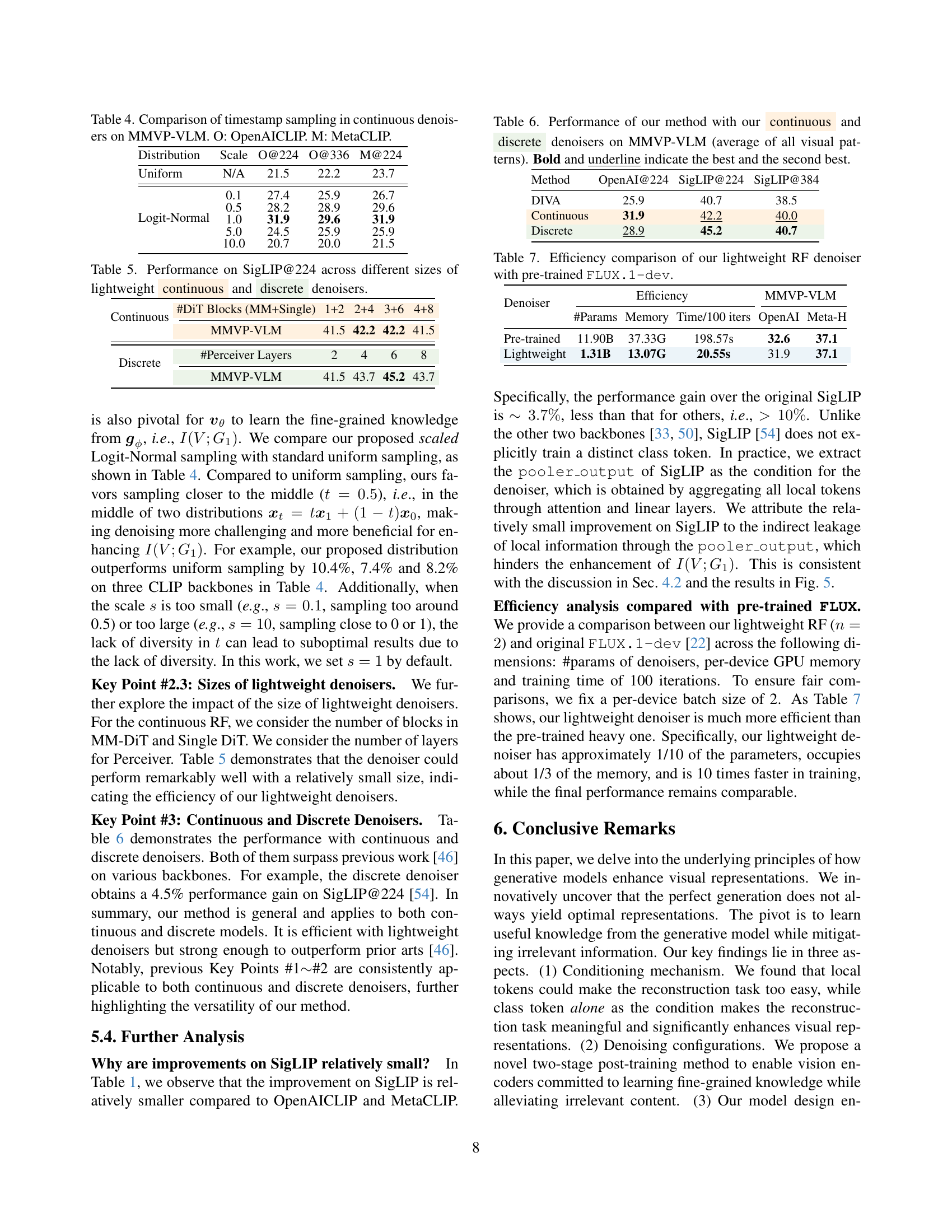
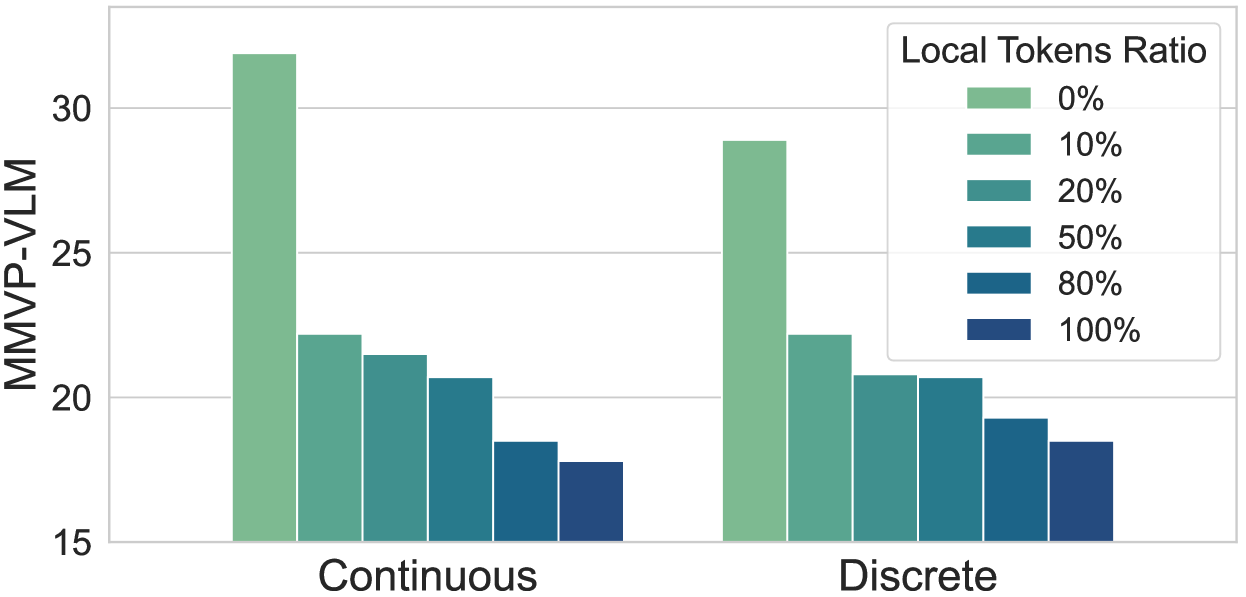
🔼 This figure displays the performance of CLIP (Contrastive Language–Image Pre-training) models on the MMVP-VLM (Multimodal Visual Perception Visual-Linguistic Benchmark) when different combinations of visual tokens are used as input. Specifically, it shows how the model’s performance changes when using the [CLS] token (representing the class or global image information) in conjunction with varying percentages (0%, 10%, 20%, 50%, 80%, 100%) of [LOCAL] tokens (representing local image features). The x-axis indicates the percentage of local tokens included, and the y-axis represents the MMVP-VLM score, which measures the model’s performance in terms of fine-grained visual understanding. Separate bars indicate results for both continuous and discrete generative models.
read the caption
Figure 5: Performance of CLIP across various conditional visual tokens on MMVP-VLM, i.e., [CLS] + n%percent𝑛n\%italic_n % [LOCAL].

🔼 This figure compares the performance of CLIP (Contrastive Language-Image Pre-training) models trained using two different methods: end-to-end training and a proposed two-stage training approach. The comparison is done on the MMVP-VLM benchmark, which evaluates fine-grained visual perception abilities. The results are shown separately for models using continuous and discrete generative denoisers. The abbreviations O and S represent OpenAICLIP and SigLIP, respectively, indicating different CLIP model architectures.
read the caption
Figure 6: Comparison of CLIP with end-to-end and the proposed two-stage training on MMVP-VLM. Here, Cont. and Disc. denote continuous and discrete denoisers. O: OpenAICLIP. S: SigLIP.

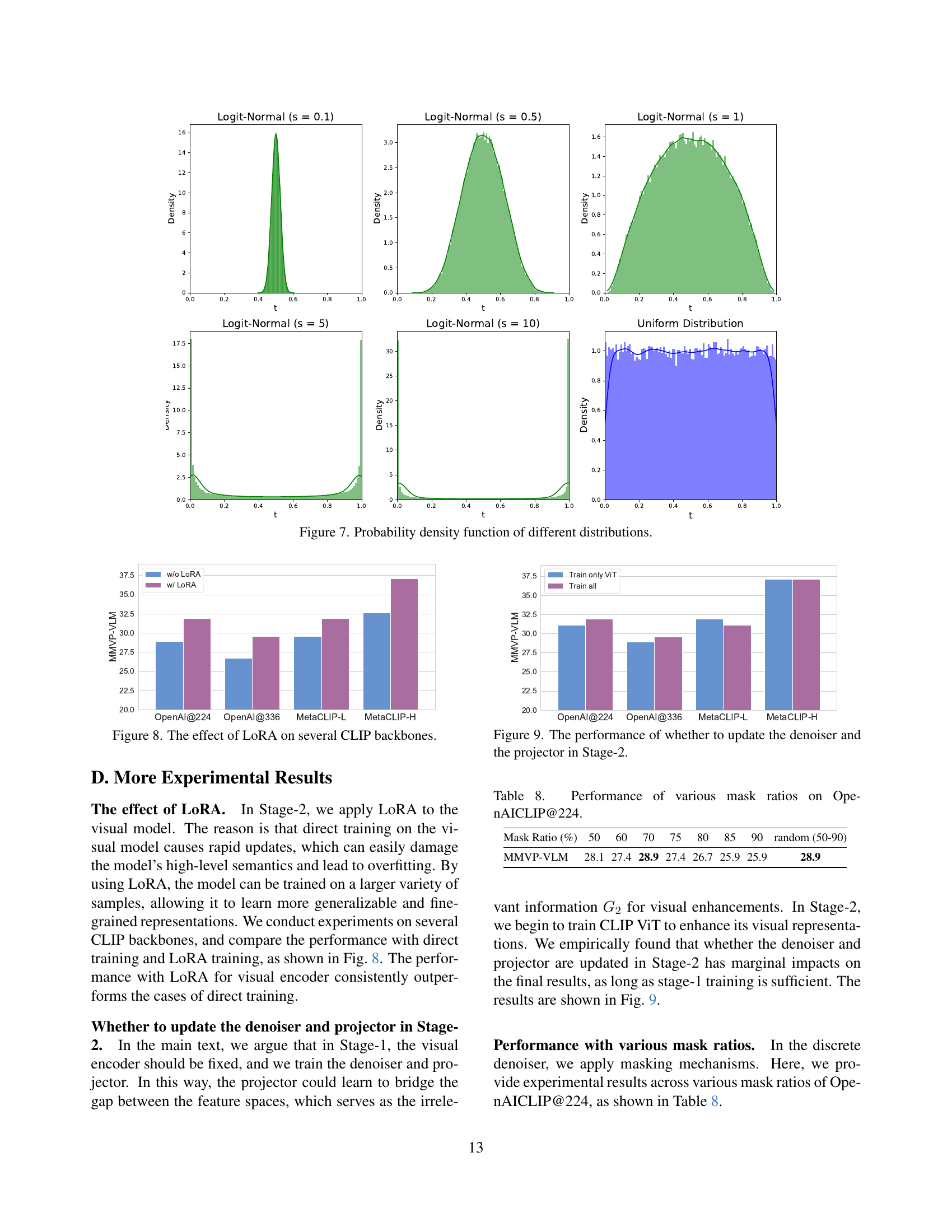
🔼 This figure displays the probability density functions for several different timestamp sampling distributions used in the continuous generative model. These distributions control how frequently different timestamps are sampled during the training process. The figure shows the distributions for uniform sampling and several variations of scaled Logit-Normal sampling, with different scale parameters (s = 0.1, 0.5, 1, 5, 10). The Logit-Normal distributions allow for more focused sampling around the midpoint (t=0.5) of the interval, as opposed to uniform sampling which gives equal weight to all timestamps.
read the caption
Figure 7: Probability density function of different distributions.

🔼 This figure compares the performance of CLIP models enhanced using LoRA (Low-Rank Adaptation) with those trained without LoRA. It showcases the results across various CLIP backbones (OpenAI, MetaCLIP). The graph likely illustrates that employing LoRA improves the fine-grained visual representation learning of the CLIP model by preventing overfitting during the training process, thus achieving better performance compared to training without LoRA.
read the caption
Figure 8: The effect of LoRA on several CLIP backbones.

🔼 This figure compares the performance of updating only the visual encoder (CLIP ViT) versus updating both the visual encoder and the generative model components (denoiser and projector) during the second stage of training. The results show that only updating the visual encoder yields better performance on the MMVP-VLM benchmark, suggesting that additional updates to the generative model components are not beneficial in this stage.
read the caption
Figure 9: The performance of whether to update the denoiser and the projector in Stage-2.

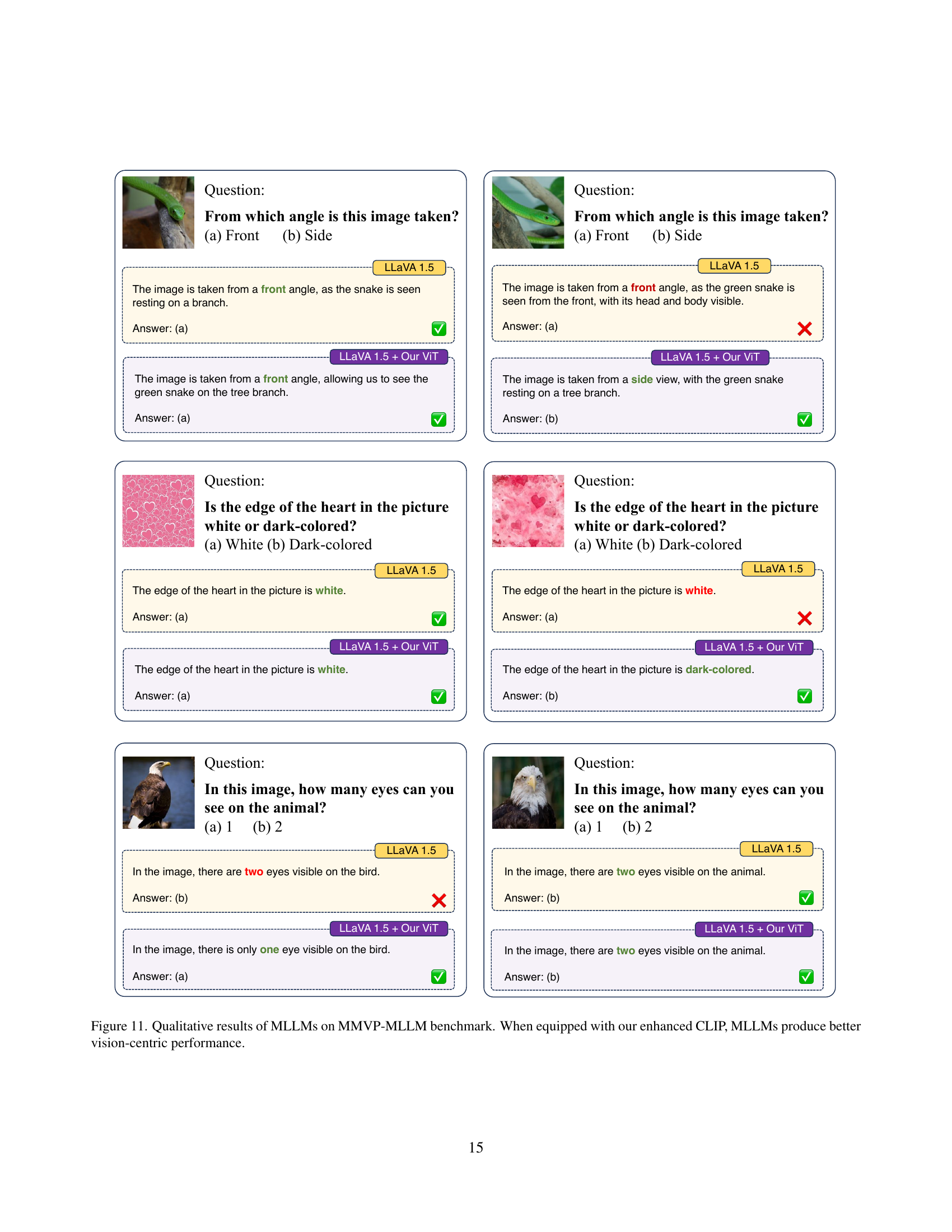
🔼 Figure 10 presents a qualitative comparison of the original CLIP model and the enhanced CLIP model’s performance on the MMVP-VLM benchmark. The images showcase several examples where the original CLIP model struggles with fine-grained visual details, such as color, quantity, and orientation. The enhanced CLIP model, however, demonstrates a significantly improved ability to perceive and correctly identify these fine-grained details, overcoming the visual shortcomings of the original model. This improvement highlights the effectiveness of the proposed method in enhancing the visual understanding capabilities of CLIP.
read the caption
Figure 10: Qualitative results of CLIP on MMVP-VLM benchmark. The enhanced CLIP overcomes original visual shortcomings in fine-grained details.
More on tables
| LLM | CLIP | Vision-Centric Benchmarks | Conventional MLLM Benchmarks | |||||||||||
| MMVP- MLLM [41] | NaturalBench [24]‡ | CV-Bench 2D [40] | CV-Bench 3D [40] | POPE [25] | SciQA- IMG [30] | Hallusion Avg. [13] | ||||||||
| Acc | Q-Acc | I-Acc | G-Acc | ADE20K | COCO | rand | pop | adv | ||||||
| Vicuna-7B | Original | 24.7 | 76.4 | 53.6 | 56.4 | 17.6 | 49.6 | 60.9 | 58.7 | 87.3 | 86.1 | 84.2 | 66.8 | 27.6 |
| DIVA† | 31.3 | 75.3 | 51.7 | 56.1 | 22.3 | 51.3 | 63.4 | 60.2 | 87.9 | 87.0 | 84.6 | 66.3 | 28.6 | |
| Ours | 30.7 | 77.3 | 55.6 | 59.1 | 24.4 | 52.9 | 63.6 | 63.2 | 88.1 | 86.7 | 84.6 | 66.5 | 28.4 | |
| Vicuna-13B | Original | 30.7 | 76.3 | 52.9 | 55.1 | 13.8 | 52.6 | 63.3 | 65.0 | 87.1 | 86.2 | 84.5 | 71.6 | 24.5 |
| DIVA† | 35.3 | 76.0 | 52.7 | 56.0 | 16.8 | 53.2 | 64.3 | 65.8 | 88.1 | 87.4 | 84.8 | 71.8 | 25.2 | |
| Ours | 36.7 | 77.2 | 55.3 | 58.7 | 22.9 | 55.3 | 64.3 | 66.4 | 87.8 | 87.0 | 84.9 | 72.3 | 26.4 | |
🔼 This table presents a comprehensive evaluation of the LLaVA-1.5 [28] multimodal large language model (MLLM) using both vision-centric and conventional MLLM benchmarks. The results for the original LLaVA-1.5 model are compared against versions enhanced using the DIVA method [46] and the GenHancer method proposed in this paper. Vision-centric benchmarks assess the model’s performance on tasks requiring fine-grained visual understanding, while conventional benchmarks test more general multimodal capabilities. Note that the results for DIVA were reproduced using the official checkpoints provided by the authors of DIVA. For the LLaVA-1.5 model’s predictions, the response with the highest likelihood was selected, following the methodology in [23]. The benchmarks include HallusionBench [13], and ScienceQA [30]. Bold and underlined values indicate the best and second-best performing models for each metric.
read the caption
Table 2: Comprehensive evaluation of MLLMs (LLaVA-1.5 [28]), including vision-centric and conventional MLLM benchmarks. † We use official DIVA CLIP checkpoints [46] to reproduce the results. ‡ Similar to [23], we select the choice with the highest likelihood as MLLM’s prediction. Hallusion: HallusionBench [13]. SciQA: ScienceQA [30]. Bold and underline indicate the best and the second best.
| Method | Classification | Retrieval-Image@5 | Retrieval-Text@5 | |||||
| IN-1K | C100 | SUN397 | Cars | Flickr30k | COCO | Flickr30k | COCO | |
| Original | 75.5 | 76.1 | 67.5 | 77.7 | 87.2 | 61.1 | 97.4 | 79.2 |
| Ours | 75.6 | 76.1 | 67.5 | 77.6 | 87.3 | 61.2 | 97.2 | 79.4 |
🔼 This table presents the performance of zero-shot image classification and text-to-image retrieval tasks using the original and post-tuned OpenAICLIP@224 model. Zero-shot learning means the model is not fine-tuned for these specific tasks. The goal is to assess the model’s ability to generalize to unseen data based solely on pre-training. The datasets used encompass various categories and require the model to understand global image semantics for accurate classification and retrieval, such as recognizing the overall content or matching text descriptions to similar images.
read the caption
Table 3: Performance of zero-shot classification and retrieval that require global semantics. We report the results of original and post-tuned OpenAICLIP@224.
| Distribution | Scale | O@224 | O@336 | M@224 |
| Uniform | N/A | 21.5 | 22.2 | 23.7 |
| Logit-Normal | 0.1 | 27.4 | 25.9 | 26.7 |
| 0.5 | 28.2 | 28.9 | 29.6 | |
| 1.0 | 31.9 | 29.6 | 31.9 | |
| 5.0 | 24.5 | 25.9 | 25.9 | |
| 10.0 | 20.7 | 20.0 | 21.5 |
🔼 This table compares the performance of different timestamp sampling methods within continuous denoisers, specifically focusing on the MMVP-VLM benchmark. It shows how the choice of sampling distribution (uniform vs. Logit-Normal) and the scale parameter (s) influence the quality of visual enhancements achieved using OpenAICLIP and MetaCLIP models.
read the caption
Table 4: Comparison of timestamp sampling in continuous denoisers on MMVP-VLM. O: OpenAICLIP. M: MetaCLIP.
| Continuous | #DiT Blocks (MM+Single) | 1+2 | 2+4 | 3+6 | 4+8 |
| MMVP-VLM | 41.5 | 42.2 | 42.2 | 41.5 | |
| Discrete | #Perceiver Layers | 2 | 4 | 6 | 8 |
| MMVP-VLM | 41.5 | 43.7 | 45.2 | 43.7 |
🔼 This table presents the performance of the GenHancer model on the SigLIP@224 benchmark using different sizes of lightweight continuous and discrete denoisers. It demonstrates how the model’s performance varies with the complexity (number of layers/blocks) of the denoiser, indicating the efficiency of using lightweight denoisers while maintaining performance.
read the caption
Table 5: Performance on SigLIP@224 across different sizes of lightweight continuous and discrete denoisers.
| Method | OpenAI@224 | SigLIP@224 | SigLIP@384 |
| DIVA | 25.9 | 40.7 | 38.5 |
| Continuous | 31.9 | 42.2 | 40.0 |
| Discrete | 28.9 | 45.2 | 40.7 |
🔼 This table presents a comparison of the performance achieved by using either a continuous or discrete generative model within the GenHancer framework. The performance is measured by averaging the results across all visual patterns of the MMVP-VLM benchmark. The best and second-best results are highlighted in bold and underlined, respectively, to easily identify the superior model type.
read the caption
Table 6: Performance of our method with our continuous and discrete denoisers on MMVP-VLM (average of all visual patterns). Bold and underline indicate the best and the second best.
| Denoiser | Efficiency | MMVP-VLM | |||
| #Params | Memory | Time/100 iters | OpenAI | Meta-H | |
| Pre-trained | 11.90B | 37.33G | 198.57s | 32.6 | 37.1 |
| Lightweight | 1.31B | 13.07G | 20.55s | 31.9 | 37.1 |
🔼 This table compares the efficiency of the lightweight rectified flow (RF) denoiser used in GenHancer with the pre-trained, heavier FLUX.1-dev denoiser. It contrasts the number of parameters, GPU memory usage, and training time (per 100 iterations) for both models, demonstrating the significant efficiency gains achieved by the lightweight GenHancer denoiser while maintaining comparable performance on the MMVP-VLM benchmark.
read the caption
Table 7: Efficiency comparison of our lightweight RF denoiser with pre-trained FLUX.1-dev.
| Mask Ratio (%) | 50 | 60 | 70 | 75 | 80 | 85 | 90 | random (50-90) |
| MMVP-VLM | 28.1 | 27.4 | 28.9 | 27.4 | 26.7 | 25.9 | 25.9 | 28.9 |
🔼 This table presents the performance of the discrete denoiser model used in the GenHancer method on the OpenAICLIP@224 backbone across different mask ratios. The mask ratio determines the percentage of input tokens that are masked during training. The table shows how variations in the mask ratio (from 50% to 90%, and a random range between 50% and 90%) affect the performance of GenHancer, as measured by the MMVP-VLM score. This helps to determine the optimal masking strategy for enhancing CLIP’s visual representation learning.
read the caption
Table 8: Performance of various mask ratios on OpenAICLIP@224.
Full paper#