TL;DR#
Large Language Models (LLMs) have shown improved performance with test-time scaling. However, challenges like long texts and reinforcement learning inefficiencies remain. To address these limitations, the paper introduces Multi-round Thinking, a test-time scaling approach. It iteratively refines reasoning by using previous answers as prompts for subsequent rounds. This method aims to enhance reasoning without requiring extensive model retraining or complex setups, thus offering a practical and scalable solution.
The research demonstrates that the Multi-round Thinking enhances performance across models like QwQ-32B and DeepSeek-R1 on AIME 2024, MATH-500, GPQA-diamond, and LiveCodeBench. The accuracy improved by using previous answers as prompts for subsequent rounds. Lexical analysis further indicates that the approach promotes more confident and concise reasoning. This highlights the effectiveness and potential of this approach for improving LLM reasoning.
Key Takeaways#
Why does it matter?#
This paper introduces Multi-round Thinking, a novel test-time scaling method. It offers a practical and efficient way to enhance LLM reasoning without extra training, potentially impacting future research in test-time scaling and real-world LLM deployments.
Visual Insights#

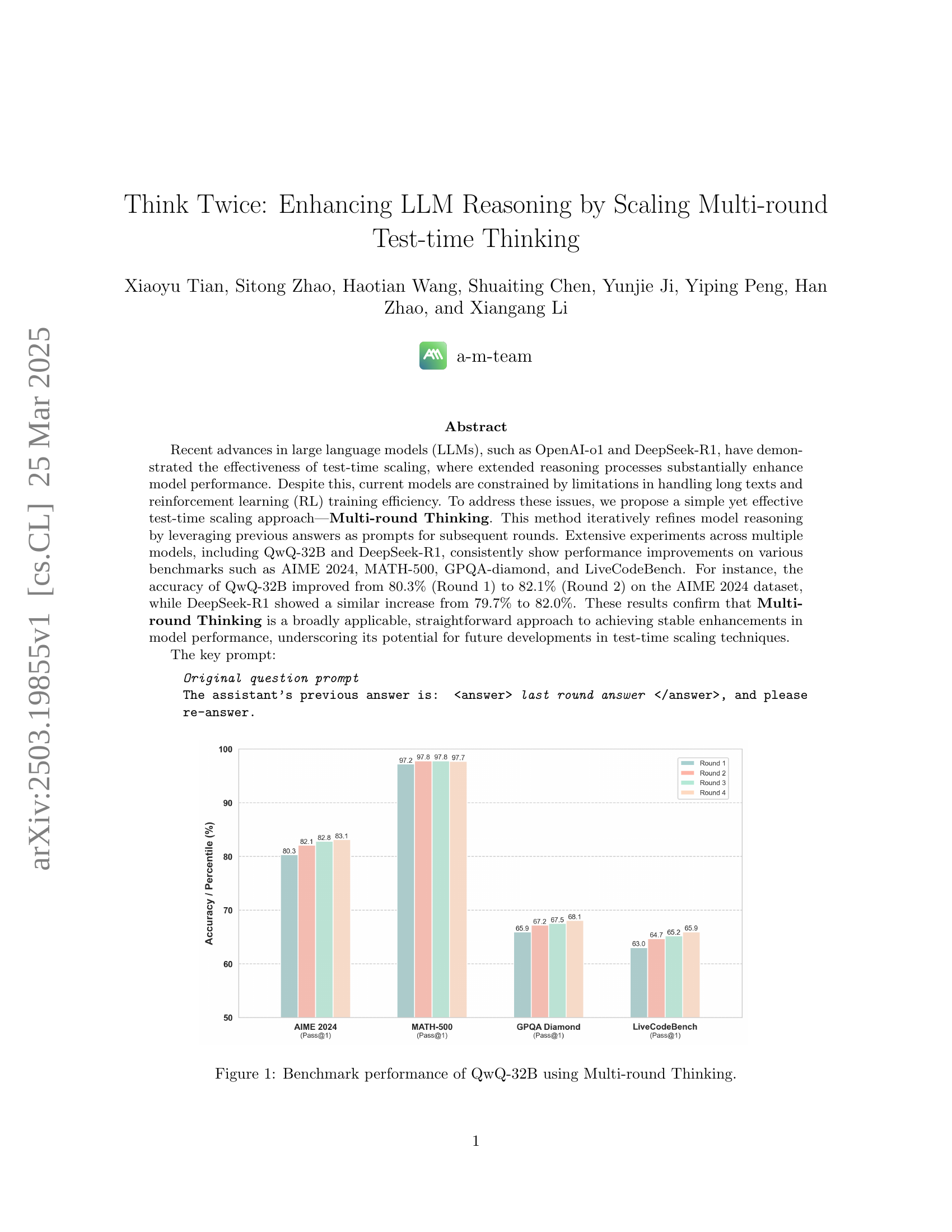
🔼 This figure displays the performance of the QwQ-32B language model across four rounds of reasoning using the Multi-round Thinking approach. It shows the accuracy (or pass@1 rate) on four different benchmarks: AIME 2024, MATH-500, GPQA-Diamond, and LiveCodeBench. The bars represent the accuracy achieved at each round of reasoning, demonstrating the improvement in performance with each subsequent round.
read the caption
Figure 1: Benchmark performance of QwQ-32B using Multi-round Thinking.
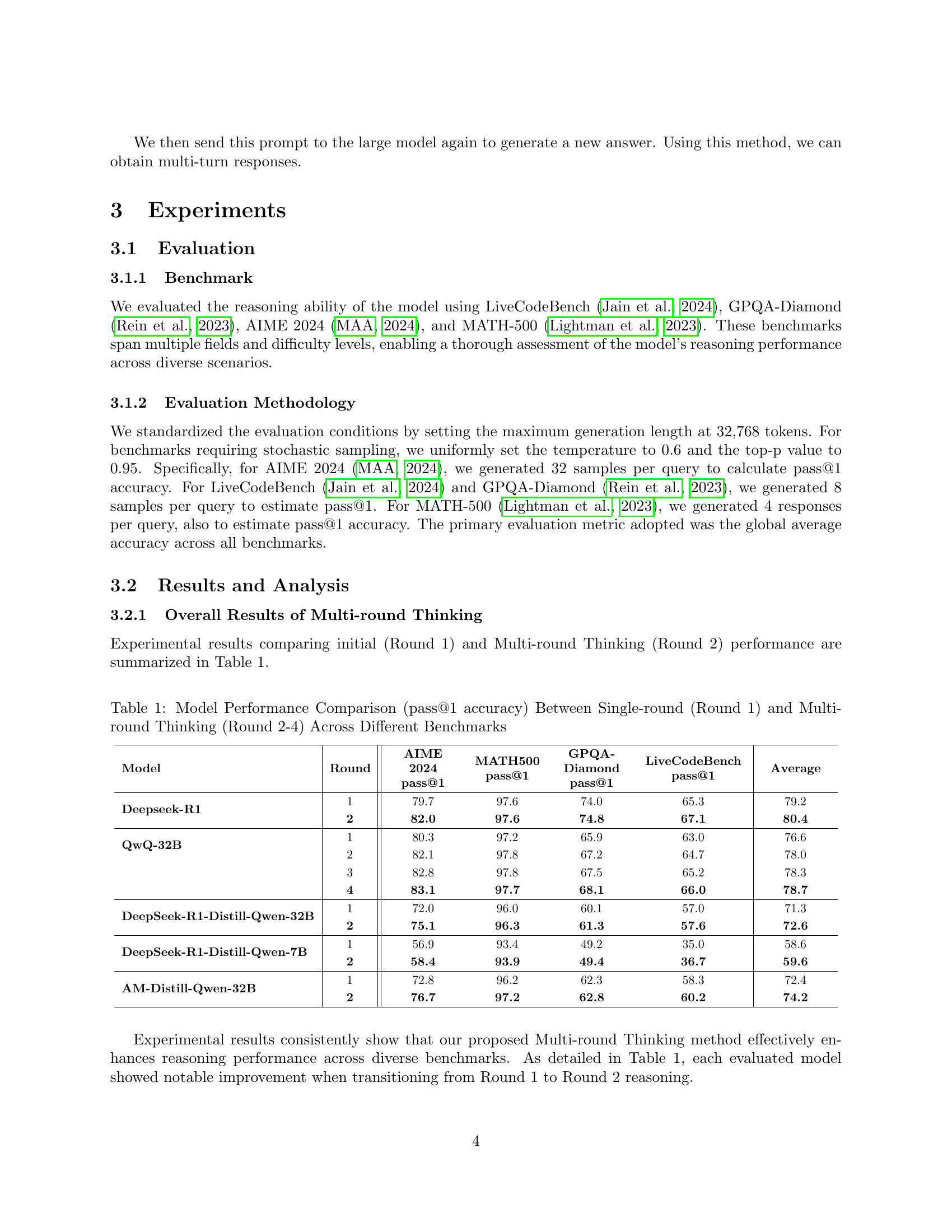
| Model | Round | AIME 2024 pass@1 | MATH500 pass@1 | GPQA-Diamond pass@1 | LiveCodeBench pass@1 | Average |
|---|---|---|---|---|---|---|
| Deepseek-R1 | 1 | 79.7 | 97.6 | 74.0 | 65.3 | 79.2 |
| 2 | 82.0 | 97.6 | 74.8 | 67.1 | 80.4 | |
| QwQ-32B | 1 | 80.3 | 97.2 | 65.9 | 63.0 | 76.6 |
| 2 | 82.1 | 97.8 | 67.2 | 64.7 | 78.0 | |
| 3 | 82.8 | 97.8 | 67.5 | 65.2 | 78.3 | |
| 4 | 83.1 | 97.7 | 68.1 | 66.0 | 78.7 | |
| DeepSeek-R1-Distill-Qwen-32B | 1 | 72.0 | 96.0 | 60.1 | 57.0 | 71.3 |
| 2 | 75.1 | 96.3 | 61.3 | 57.6 | 72.6 | |
| DeepSeek-R1-Distill-Qwen-7B | 1 | 56.9 | 93.4 | 49.2 | 35.0 | 58.6 |
| 2 | 58.4 | 93.9 | 49.4 | 36.7 | 59.6 | |
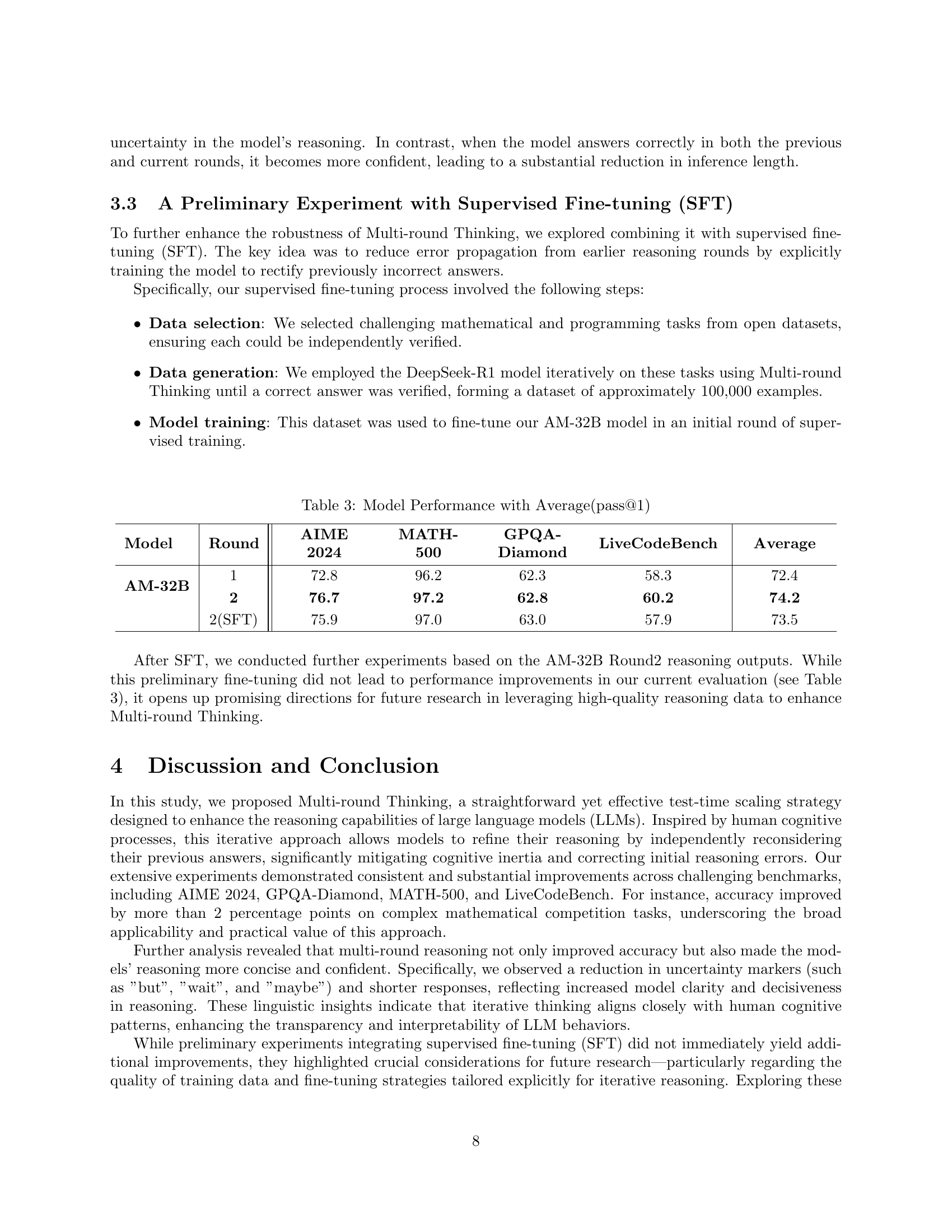
| AM-Distill-Qwen-32B | 1 | 72.8 | 96.2 | 62.3 | 58.3 | 72.4 |
| 2 | 76.7 | 97.2 | 62.8 | 60.2 | 74.2 |
🔼 This table presents a comparison of the performance (pass@1 accuracy) of several large language models (LLMs) on four different reasoning benchmarks. It compares the performance of each model under a single round of reasoning (Round 1) with the performance achieved when using the Multi-round Thinking approach for 2 to 4 rounds. The benchmarks assess performance across various reasoning tasks, offering a holistic evaluation of the Multi-round Thinking method’s effectiveness in improving model accuracy. Models tested include DeepSeek-R1, QwQ-32B, and variations using distilled Qwen models.
read the caption
Table 1: Model Performance Comparison (pass@1 accuracy) Between Single-round (Round 1) and Multi-round Thinking (Round 2-4) Across Different Benchmarks
In-depth insights#
LLM Test-time Scaling#
LLM Test-time Scaling is an emerging area focused on enhancing the capabilities of large language models during the inference phase, distinct from training-time scaling. The idea is to improve performance by strategically using computational resources during the prediction process. Techniques such as Multi-round Thinking, majority voting, and best-of-N strategies demonstrate the potential. A core benefit is that test-time scaling can refine initial outputs through iterative methods or by exploring multiple reasoning paths. However, challenges persist, including the computational overhead of these methods. Balancing accuracy gains with inference costs is crucial. Future research may focus on developing more efficient test-time scaling techniques, leveraging human feedback, or combining test-time scaling with fine-tuning.
Multi-round Thinking#
Multi-round Thinking introduces a novel test-time scaling strategy to enhance LLM reasoning by iteratively refining answers. It leverages previous answers as prompts for subsequent rounds, promoting independent reconsideration and correction, mitigating cognitive inertia, and enabling models to overcome entrenched errors. This approach enhances reasoning processes, corrects earlier mistakes, and boosts model performance across challenging reasoning tasks by fostering more concise and assertive phrasing and achieving stable enhancements in model performance. The effectiveness of multi-round thinking lies in its ability to prompt models to reconsider previous conclusions independently, systematically improving the quality of reasoning outcomes and achieving a clear and steady upward trend across various benchmarks. It offers an efficient pathway to enhance model accuracy without additional training overhead, highlighting its practical value for real-world deployment and future research in test-time scaling methods.
Iterative Refinement#
Iterative refinement is a powerful concept, particularly in the context of AI and machine learning. The core idea involves starting with an initial solution or model, then repeatedly improving it through cycles of analysis and modification. Each iteration builds upon the previous one, gradually converging towards a more optimal result. This approach is valuable when the problem is complex or the optimal solution is unknown. It allows for continuous learning and adaptation, incorporating feedback and new information at each stage. The success hinges on well-defined metrics for evaluation and clear strategies for adjusting the model or solution in each iteration. Effectively, iterative refinement enables us to tackle intricate problems by breaking them down into manageable steps and continuously optimizing our approach based on empirical evidence and insight gleaned from each cycle.
No Training Overhead#
The concept of ‘No Training Overhead’ is compelling, especially in resource-constrained scenarios. It implies the ability to enhance model performance without the costly and time-intensive process of retraining. This is a significant advantage, potentially achieved through techniques like intelligent prompting strategies or test-time manipulations of the model’s behavior. If a model can adapt and improve its reasoning simply by altering the input or employing iterative refinement at inference time, it circumvents the need for extensive datasets and computational resources typically required for traditional training. This not only makes deployment more accessible but also allows for rapid experimentation and adaptation to new tasks or domains. The challenge lies in developing robust and generalizable methods that consistently yield improvements without introducing instability or unintended side effects. However, the absence of training doesn’t equate to zero cost, as there might be engineering efforts or human expertise in designing effective prompts or refinement strategies. Moreover, the efficiency gains should be carefully weighed against potential limitations in the magnitude of performance improvement compared to a fully retrained model. Nevertheless, the promise of enhanced reasoning capabilities without training overhead makes it a crucial area for further research and development.
Cognitive Patterns#
Cognitive patterns in language models reveal how they approach problem-solving. Iterative refinement enhances reasoning by mimicking human cognitive processes, reducing errors. Models learn from past mistakes, adapting strategies. This process decreases uncertainty and increases confidence. Lexical analysis shows shifts in language, using fewer hesitation markers. Models become more concise and assertive. Correcting errors involves thoughtful reanalysis. Understanding these patterns offers insights for improving model reasoning and trustworthiness. Analyzing language use uncovers deeper cognitive mechanisms. Emulating human thought boosts performance and reliability. This allows us to use the patterns to guide development.
More visual insights#
More on figures
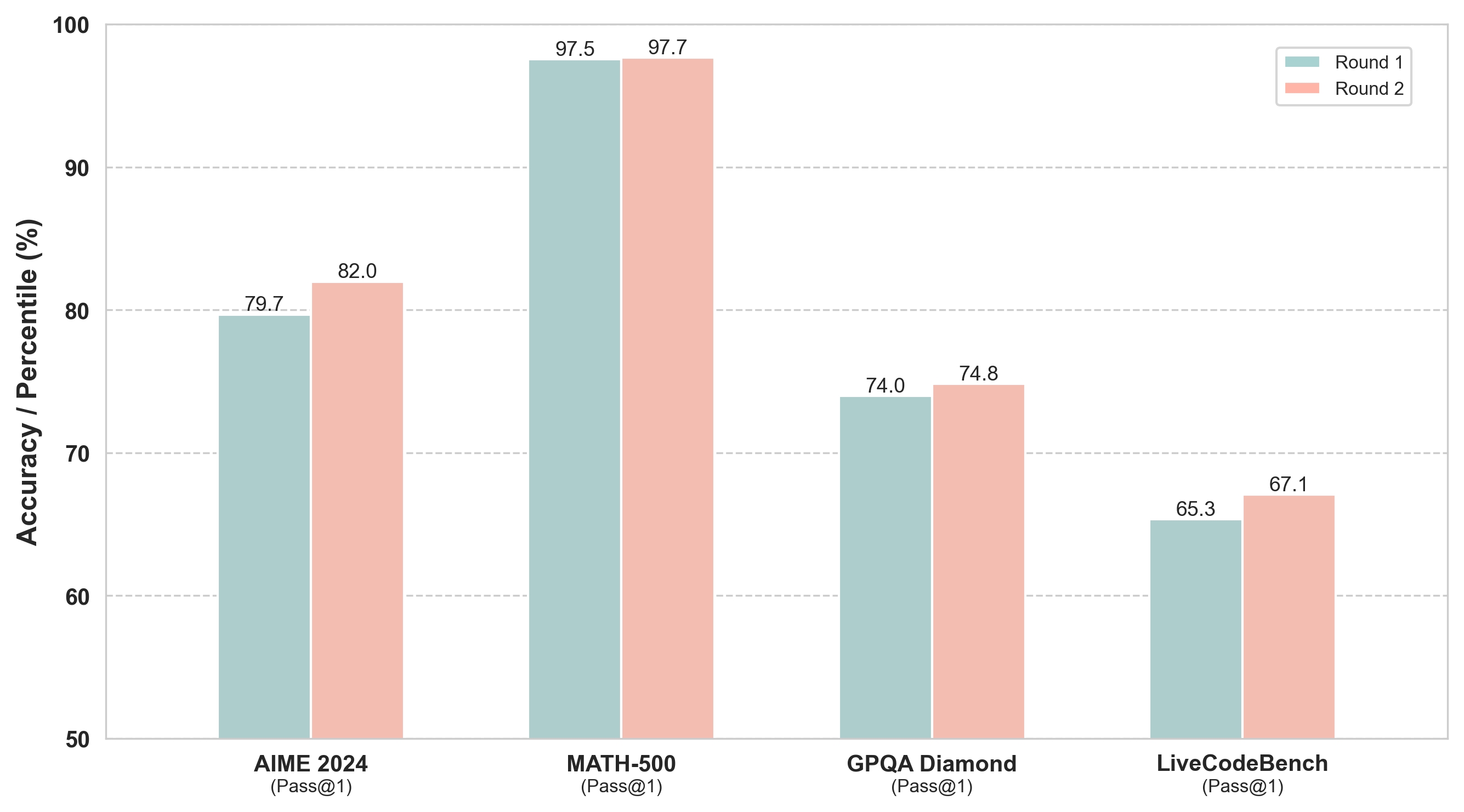
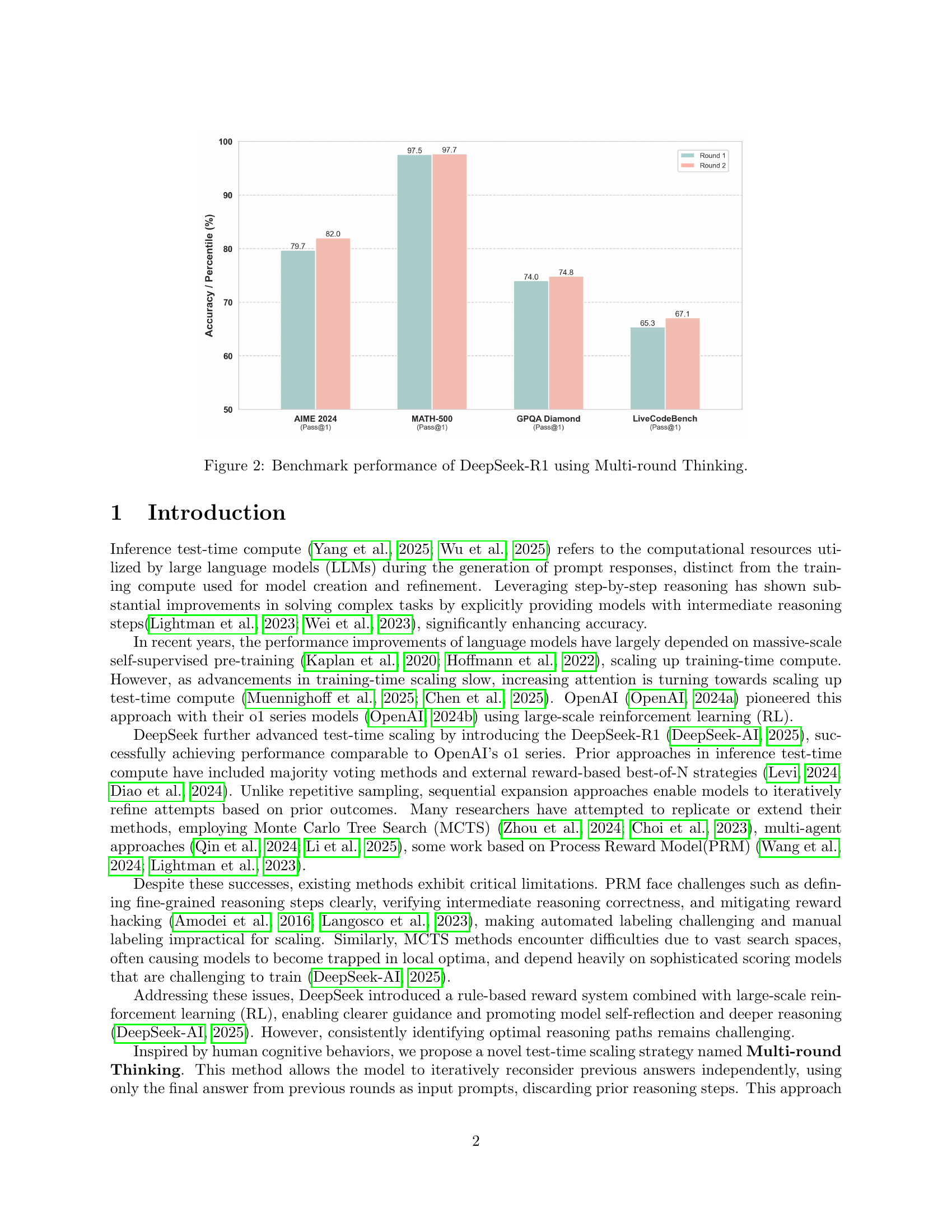
🔼 This figure presents the performance comparison of DeepSeek-R1 model on four benchmarks (AIME 2024, MATH-500, GPQA Diamond, and LiveCodeBench) across two rounds of reasoning. Round 1 shows the model’s initial performance without multi-round thinking, while Round 2 demonstrates the improvement achieved by incorporating multi-round test-time thinking. Each benchmark is represented by a bar graph displaying the pass@1 accuracy. The results highlight the consistent improvement in accuracy after implementing the multi-round thinking approach.
read the caption
Figure 2: Benchmark performance of DeepSeek-R1 using Multi-round Thinking.

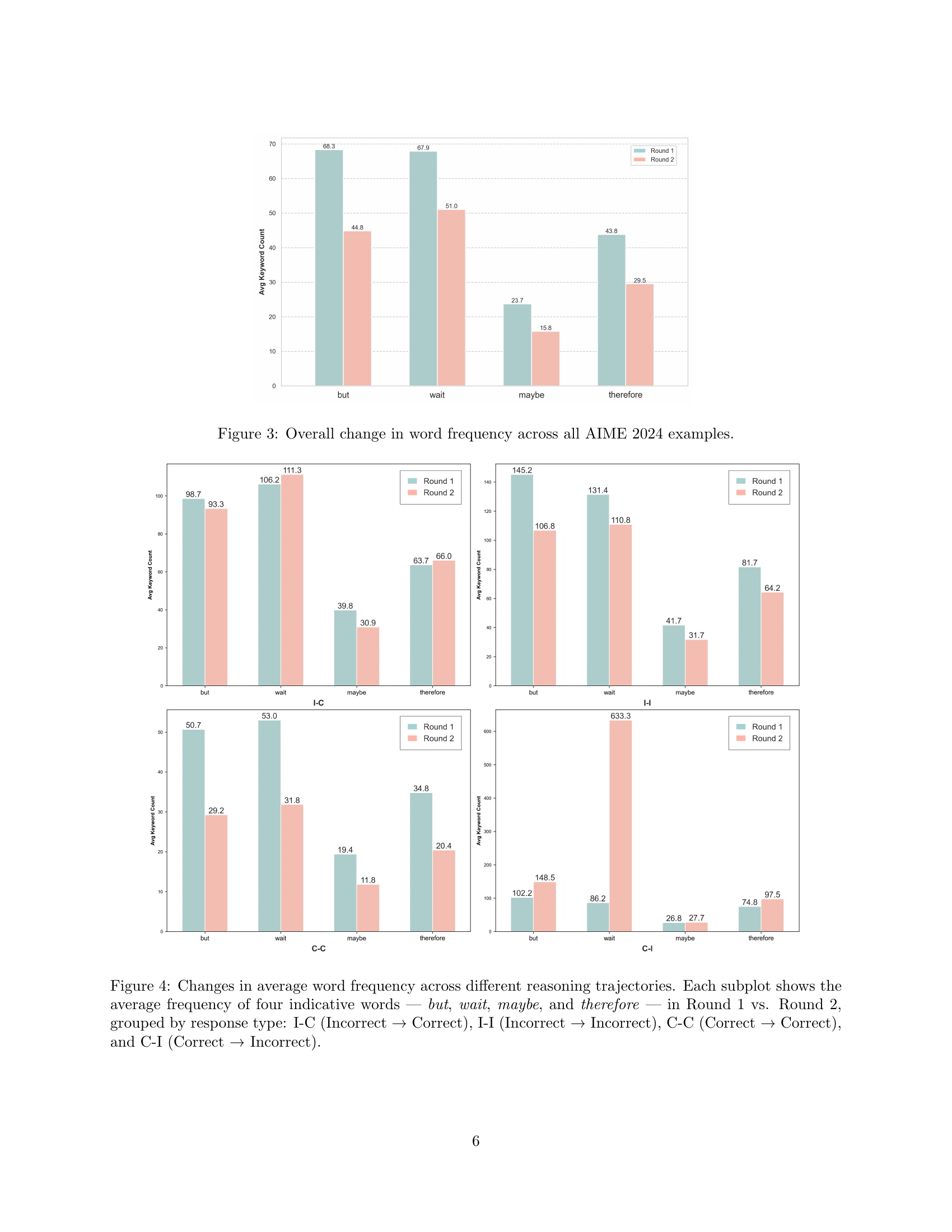
🔼 This figure shows the overall change in frequency of four specific words (but, wait, maybe, therefore) from Round 1 to Round 2 of the Multi-round Thinking process across all examples from the AIME 2024 dataset. It illustrates how the use of these words, indicative of uncertainty or hesitation versus decisiveness, changes as the model iteratively refines its reasoning.
read the caption
Figure 3: Overall change in word frequency across all AIME 2024 examples.
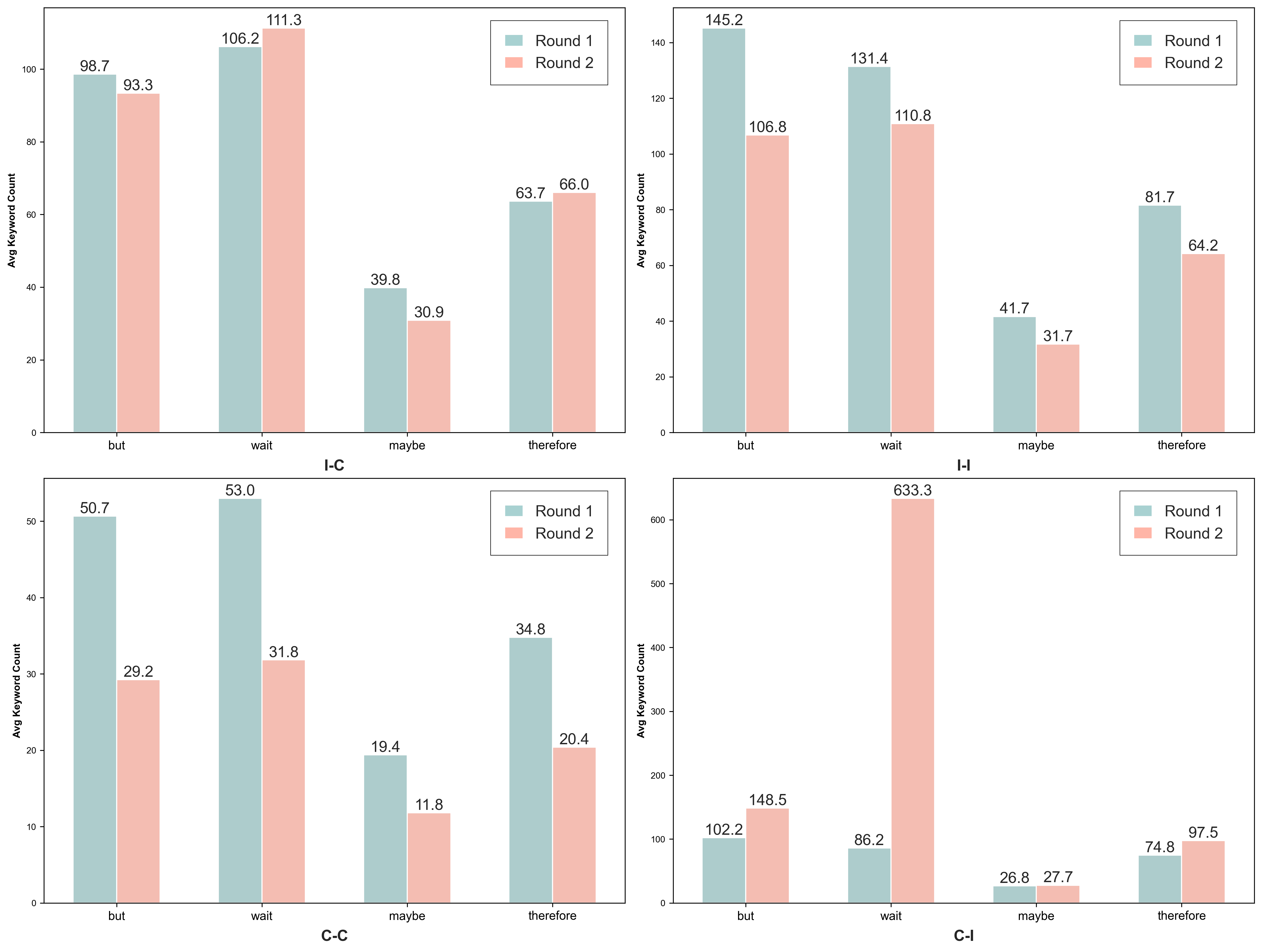
🔼 This figure analyzes how the usage frequency of four specific words (‘but’, ‘wait’, ‘maybe’, and ’therefore’) changes between the first and second reasoning rounds of the Multi-round Thinking model. The analysis is broken down by four categories of reasoning trajectories: I-C (Incorrect to Correct), I-I (Incorrect to Incorrect), C-C (Correct to Correct), and C-I (Correct to Incorrect). Each subplot in the figure represents one of these trajectory types, showing how frequently each of the four words appears in the model’s reasoning process for that trajectory type in Round 1 versus Round 2. This helps to understand the model’s shift in confidence and its reasoning process over multiple rounds.
read the caption
Figure 4: Changes in average word frequency across different reasoning trajectories. Each subplot shows the average frequency of four indicative words — but, wait, maybe, and therefore — in Round 1 vs. Round 2, grouped by response type: I-C (Incorrect → Correct), I-I (Incorrect → Incorrect), C-C (Correct → Correct), and C-I (Correct → Incorrect).

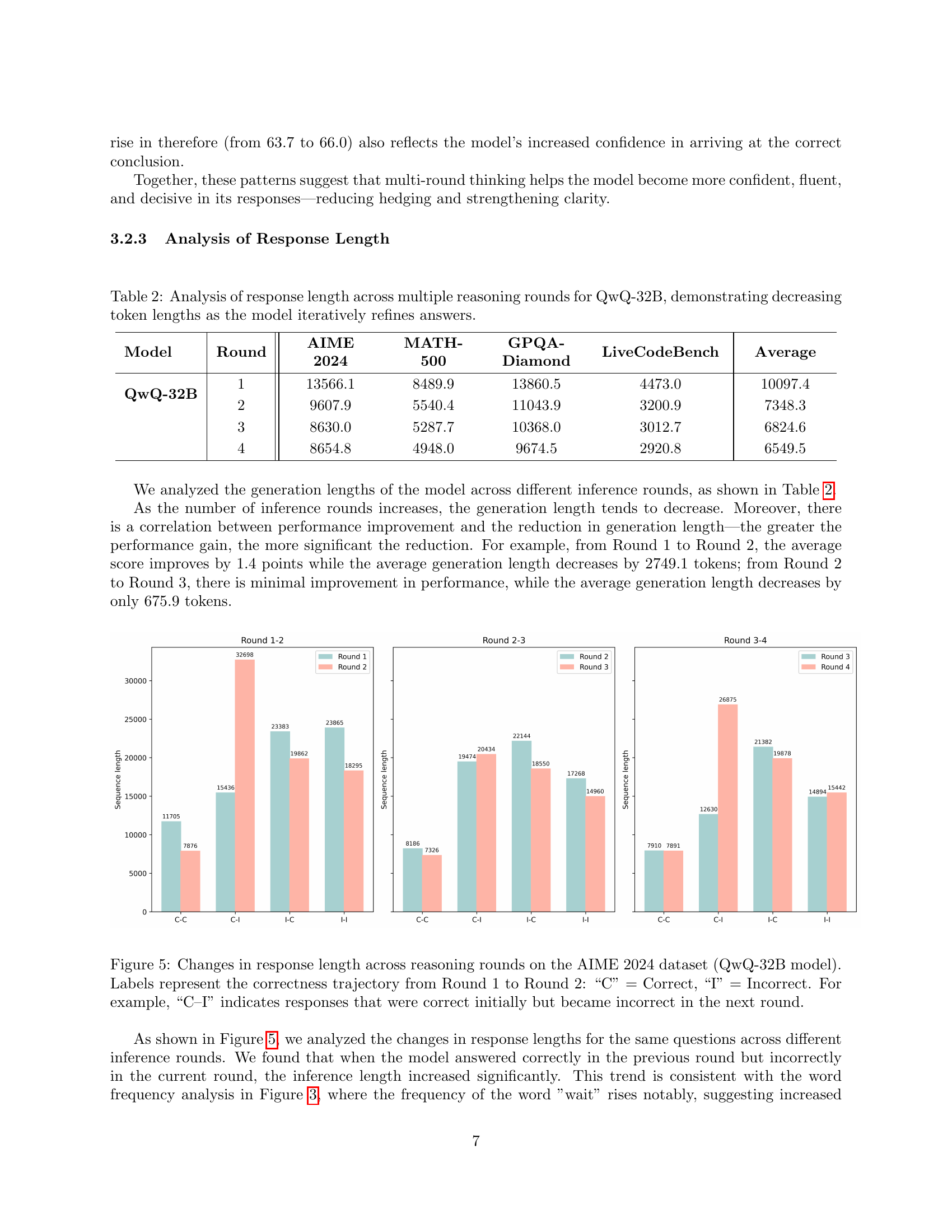
🔼 Figure 5 displays the changes in response length for the QwQ-32B model across multiple reasoning rounds on the AIME 2024 dataset. The x-axis represents the different correctness trajectories from Round 1 to Round 2: C-C (correct in both rounds), C-I (correct in Round 1, incorrect in Round 2), I-C (incorrect in Round 1, correct in Round 2), and I-I (incorrect in both rounds). The y-axis shows the average response length (number of tokens) for each trajectory. This figure helps visualize how the model’s response length changes as it iteratively refines its answers and whether the changes are related to whether the answer is correct or incorrect.
read the caption
Figure 5: Changes in response length across reasoning rounds on the AIME 2024 dataset (QwQ-32B model). Labels represent the correctness trajectory from Round 1 to Round 2: “C” = Correct, “I” = Incorrect. For example, “C–I” indicates responses that were correct initially but became incorrect in the next round.

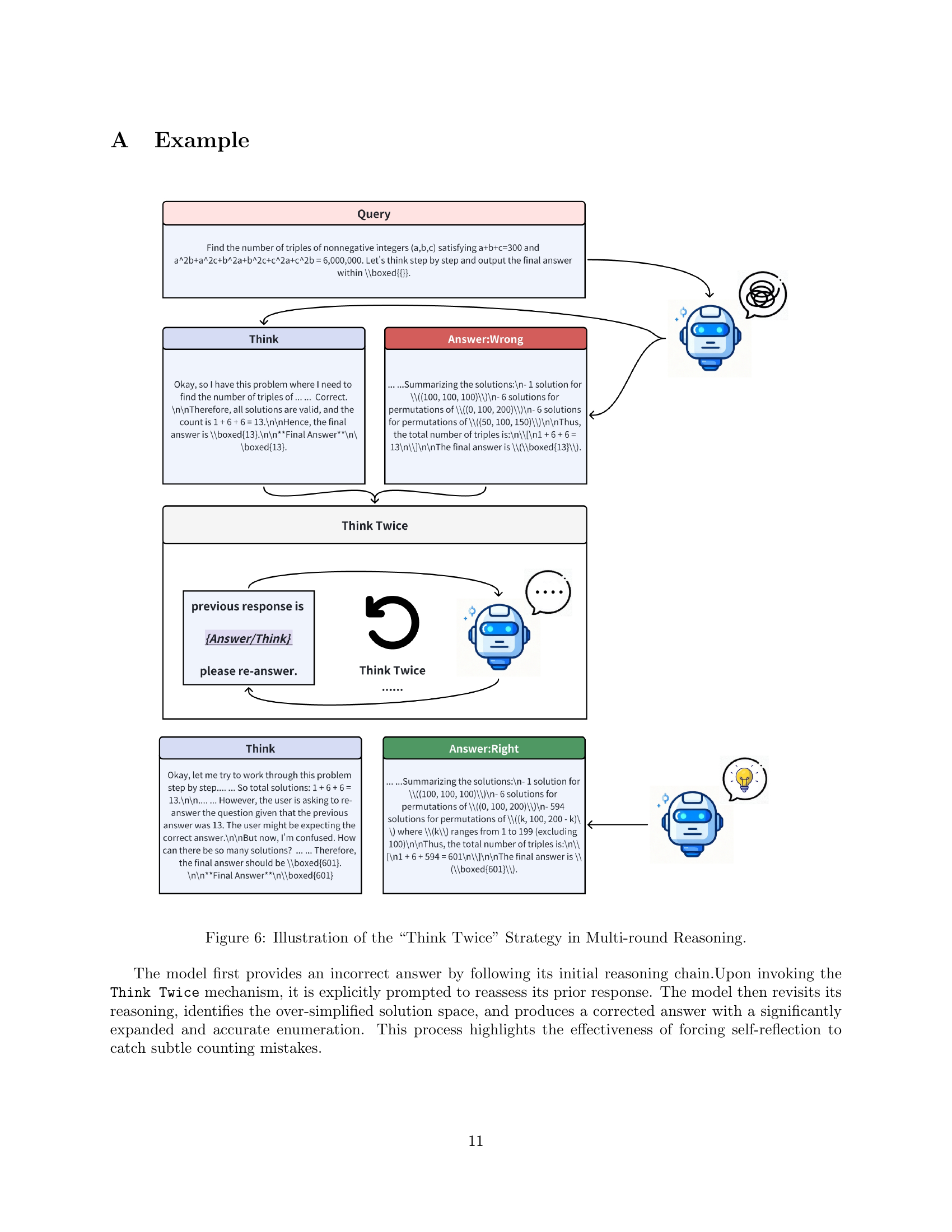
🔼 The figure illustrates how the Think Twice method works. The model initially provides an incorrect response based on flawed reasoning. Then, the Think Twice strategy prompts the model to reconsider its previous answer. In the second round of thinking, the model identifies and corrects its initial error, ultimately arriving at the correct solution. The example highlights the effectiveness of iterative reasoning and self-correction enabled by the Think Twice approach.
read the caption
Figure 6: Illustration of the “Think Twice” Strategy in Multi-round Reasoning.
More on tables
| Model | Round | AIME 2024 | MATH-500 | GPQA-Diamond | LiveCodeBench | Average |
|---|---|---|---|---|---|---|
| QwQ-32B | 1 | 13566.1 | 8489.9 | 13860.5 | 4473.0 | 10097.4 |
| 2 | 9607.9 | 5540.4 | 11043.9 | 3200.9 | 7348.3 | |
| 3 | 8630.0 | 5287.7 | 10368.0 | 3012.7 | 6824.6 | |
| 4 | 8654.8 | 4948.0 | 9674.5 | 2920.8 | 6549.5 |
🔼 This table presents an analysis of response lengths produced by the QwQ-32B model across multiple rounds of reasoning using the Multi-round Thinking approach. It shows the average number of tokens in model responses for four different benchmarks (AIME 2024, MATH-500, GPQA-Diamond, LiveCodeBench) and the overall average across all benchmarks. The key observation is that the average response length decreases as the model iteratively refines its answers, indicating improved efficiency and conciseness in its reasoning process with each subsequent round.
read the caption
Table 2: Analysis of response length across multiple reasoning rounds for QwQ-32B, demonstrating decreasing token lengths as the model iteratively refines answers.
| Model | Round | AIME 2024 | MATH-500 | GPQA-Diamond | LiveCodeBench | Average |
|---|---|---|---|---|---|---|
| AM-32B | 1 | 72.8 | 96.2 | 62.3 | 58.3 | 72.4 |
| 2 | 76.7 | 97.2 | 62.8 | 60.2 | 74.2 | |
| 2(SFT) | 75.9 | 97.0 | 63.0 | 57.9 | 73.5 |
🔼 This table presents a comparison of the AM-32B model’s performance across multiple rounds of reasoning, specifically comparing the initial round (Round 1) against a second round (Round 2) and a second round after supervised fine-tuning (Round 2(SFT)). The performance metrics used are pass@1 accuracy scores, obtained for four distinct benchmarks: AIME 2024, MATH-500, GPQA-Diamond, and LiveCodeBench. The average pass@1 across all benchmarks is also provided for each round.
read the caption
Table 3: Model Performance with Average(pass@1)
Full paper#