TL;DR#
Multi-step spatial reasoning is crucial for real-world applications but current Multimodal Large Language Models (MLLMs) struggle with it. Existing evaluations are often simplistic or lack scalability, failing to address multi-step aspects. To solve this problem, the authors introduce LEGO-Puzzles, a scalable benchmark designed to evaluate spatial understanding and sequential reasoning in MLLMs through LEGO-based tasks. The dataset consists of 1,100 VQA samples spanning 11 tasks.
By creating this benchmark, the authors conduct a comprehensive evaluation of MLLMs. The results show that even the most powerful MLLMs struggle to follow assembly instructions with a high accuracy. LEGO-Puzzles effectively exposes deficiencies in existing MLLMs’ spatial understanding, underscoring the need for further advancements in multimodal spatial reasoning. The framework is also designed to evaluate spatially grounded image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers aiming to enhance MLLMs’ spatial reasoning for real-world tasks like robotics. It highlights current limitations and provides a benchmark for future developments, spurring innovation in multimodal AI.
Visual Insights#

🔼 This figure shows the breakdown of the 1100+ visual question answering pairs in the LEGO-Puzzles benchmark dataset. It displays the number of questions categorized into three main task types: Spatial Understanding (fundamental spatial reasoning), Single-Step Sequential Reasoning (reasoning across one step in a LEGO construction sequence), and Multi-Step Sequential Reasoning (reasoning across multiple steps). The specific tasks within each category are also listed, along with the percentage of questions belonging to each.
read the caption
Figure 1: Problem Statistics in LEGO-Puzzles.
| Models | Spatial Understanding | Single-Step Reasoning | Multi-Step Reasoning | Overall | ||||||||
| Height | Adjacency | Rotation | Multiview | Next-Step | Dependency | Rotation Stat. | Position | Backwards | Ordering | Outlier | ||
| Proprietary | ||||||||||||
| Claude-3.5-Sonnet | 39.0 | 60.0 | 42.0 | 48.0 | 61.0 | 78.0 | 58.0 | 37.0 | 49.0 | 54.0 | 64.0 | 53.6 |
| Gemini-1.5-Flash | 29.0 | 58.0 | 28.0 | 45.0 | 57.0 | 77.0 | 57.0 | 32.0 | 28.0 | 20.0 | 51.0 | 43.8 |
| Gemini-1.5-Pro | 35.0 | 58.0 | 38.0 | 56.0 | 59.0 | 84.0 | 61.0 | 39.0 | 35.0 | 44.0 | 59.0 | 51.6 |
| Gemini-2.0-Flash | 35.0 | 70.0 | 49.0 | 45.0 | 69.0 | 81.0 | 54.0 | 46.0 | 56.0 | 46.0 | 43.0 | 54.0 |
| GPT-4o | 49.0 | 66.0 | 41.0 | 51.0 | 65.0 | 87.0 | 51.0 | 51.0 | 53.0 | 72.0 | 49.0 | 57.7 |
| GPT-4o-mini | 31.0 | 53.0 | 26.0 | 51.0 | 27.0 | 71.0 | 57.0 | 32.0 | 50.0 | 7.0 | 27.0 | 39.3 |
| Open-source | ||||||||||||
| MiniCPM-V2.6 | 26.0 | 56.0 | 22.0 | 44.0 | 34.0 | 50.0 | 51.0 | 29.0 | 23.0 | 0.0 | 19.0 | 32.2 |
| Qwen2-VL-7B | 31.0 | 57.0 | 30.0 | 40.0 | 44.0 | 70.0 | 48.0 | 26.0 | 13.0 | 9.0 | 28.0 | 36.0 |
| Qwen2.5-VL-7B | 35.0 | 60.0 | 22.0 | 27.0 | 26.0 | 60.0 | 49.0 | 25.0 | 24.0 | 5.0 | 13.0 | 31.5 |
| InternVL2.5-8B | 35.0 | 53.0 | 23.0 | 37.0 | 38.0 | 48.0 | 64.0 | 25.0 | 35.0 | 0.0 | 29.0 | 35.2 |
| VILA1.5-13B | 26.0 | 55.0 | 26.0 | 35.0 | 17.0 | 34.0 | 48.0 | 26.0 | 12.0 | 4.0 | 22.0 | 27.7 |
| Idefics3-8B | 29.0 | 51.0 | 23.0 | 23.0 | 18.0 | 20.0 | 47.0 | 30.0 | 24.0 | 4.0 | 24.0 | 26.6 |
| InternVL2.5-78B | 41.0 | 62.0 | 32.0 | 47.0 | 60.0 | 79.0 | 58.0 | 32.0 | 40.0 | 15.0 | 37.0 | 45.7 |
| Qwen2-VL-72B | 40.0 | 62.0 | 37.0 | 51.0 | 57.0 | 79.0 | 49.0 | 43.0 | 34.0 | 26.0 | 31.0 | 46.3 |
| Qwen2.5-VL-72B | 30.0 | 61.0 | 27.0 | 27.0 | 55.0 | 72.0 | 58.0 | 47.0 | 60.0 | 33.0 | 43.0 | 46.6 |
| DeepSeek-VL2-Small | 31.0 | 52.0 | 36.0 | 41.0 | 38.0 | 57.0 | 59.0 | 28.0 | 41.0 | 3.0 | 26.0 | 37.5 |
| DeepSeek-VL2-Tiny | 32.0 | 52.0 | 36.0 | 24.0 | 27.0 | 25.0 | 47.0 | 27.0 | 26.0 | 4.0 | 16.0 | 28.7 |
| Pixtral-12B | 31.0 | 68.0 | 24.0 | 24.0 | 21.0 | 38.0 | 53.0 | 21.0 | 24.0 | 3.0 | 37.0 | 31.3 |
| LLaVA-OneVision-7B | 42.0 | 59.0 | 21.0 | 41.0 | 30.0 | 50.0 | 59.0 | 26.0 | 20.0 | 0.0 | 22.0 | 33.6 |
| EMU3 | 31.0 | 52.0 | 24.0 | 25.0 | 17.0 | 25.0 | 47.0 | 25.0 | 24.0 | 0.0 | 20.0 | 26.4 |
| Baseline | ||||||||||||
| Random Guessing | 33.0 | 50.0 | 25.0 | 25.0 | 20.0 | 25.0 | 50.0 | 25.0 | 25.0 | 4.2 | 20.0 | 27.5 |
| Random () | 42.0 | 59.0 | 33.0 | 33.0 | 28.0 | 33.0 | 59.0 | 33.0 | 33.0 | 9.0 | 28.0 | 35.5 |
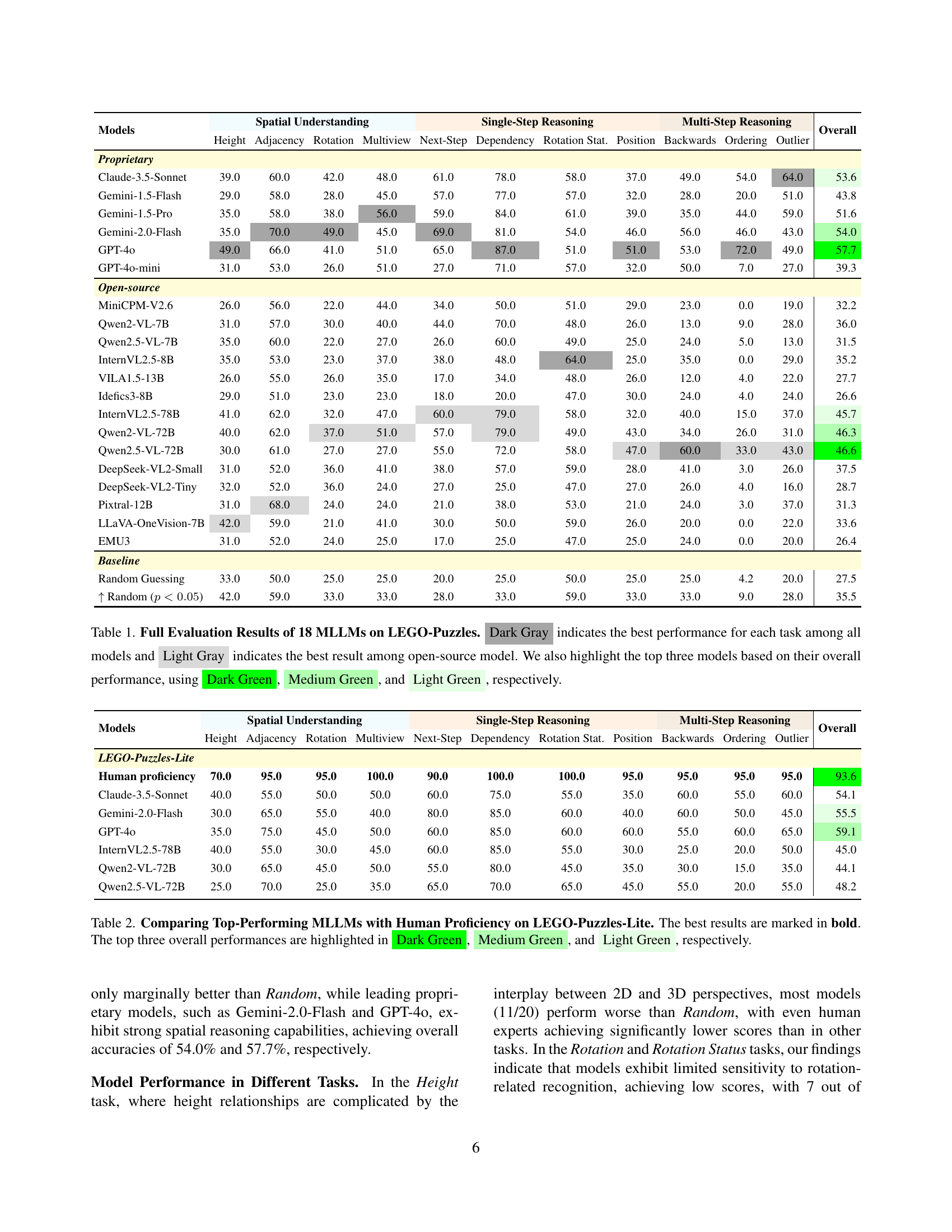
🔼 This table presents a comprehensive evaluation of 18 multimodal large language models (MLLMs) on the LEGO-Puzzles benchmark. It breaks down the performance of each model across various spatial reasoning tasks, categorized into spatial understanding, single-step reasoning, and multi-step reasoning. The best-performing model for each task is highlighted in dark gray, while the best-performing open-source model for each task is highlighted in light gray. The top three overall performing models are further distinguished by dark green, medium green, and light green highlighting, respectively. The table allows for a detailed comparison of the models’ strengths and weaknesses in different aspects of spatial reasoning.
read the caption
Table 1: Full Evaluation Results of 18 MLLMs on LEGO-Puzzles. Dark Gray indicates the best performance for each task among all models and Light Gray indicates the best result among open-source model. We also highlight the top three models based on their overall performance, using Dark Green, Medium Green, and Light Green, respectively.
In-depth insights#
LEGO for MLLM#
LEGO construction serves as an innovative framework for evaluating spatial reasoning in Multimodal Large Language Models (MLLMs). This approach leverages the inherent structure and sequential assembly process of LEGO models to create a comprehensive benchmark. By analyzing how MLLMs interpret and execute LEGO assembly instructions, researchers can assess their ability to understand spatial relationships, reason through multi-step processes, and generate accurate visual outputs. LEGO-based tasks offer a balance of complexity and real-world relevance, providing a more ecologically valid assessment compared to purely synthetic datasets. The step-by-step nature of LEGO instructions enables the creation of tasks that specifically target sequential reasoning, a crucial aspect often overlooked in existing benchmarks. This methodology also facilitates the creation of diverse and scalable datasets, as a single LEGO model can generate numerous unique evaluation questions. Overall, employing LEGO construction as a basis for MLLM evaluation represents a promising avenue for advancing the development of more capable and reliable AI systems in spatial understanding.
Multi-step Limits#
While the provided text doesn’t explicitly contain a section titled “Multi-step Limits,” we can infer potential limitations concerning multi-step spatial reasoning in MLLMs based on the observed weaknesses. The main challenge lies in compounding errors through sequential steps, where each inference introduces potential deviations. This is exacerbated by the models’ difficulty in maintaining coherent visual memory across multiple steps, unlike language-based memory in LLMs. Rotation perception and relative spatial relationship understanding also pose hurdles. The tasks become harder when several steps is involved in reasoning to achieve the final output. There exists a need for improving spatially grounded visual-memory representations and enhancing the ability to follow long chain of dependencies. Also lack of training data is a significant hurdle. The models also need to be better at following prompts to generate structured outputs.
Visual Richness#
Visual richness plays a vital role in spatial reasoning tasks. Datasets with simple geometric shapes(e.g., CLEVR) simplify the challenges MLLMs face in real-world scenarios. LEGO-Puzzles improves visual complexity and diversity, using real-world images to challenge MLLMs’ spatial understanding and sequential reasoning. High visual richness can expose limitations of MLLMs with the ability to discern subtle cues, handle occlusions, and understand the intricacies present in realistic settings. Datasets with rich visual content present complex spatial relationships that demand advanced reasoning capabilities, enhancing evaluation of models.
Image Generation#
The paper evaluates the image generation capabilities of various MLLMs, focusing on tasks like rotation and multi-view synthesis, as well as generating subsequent steps in LEGO assembly. A key finding is that existing MLLMs struggle to maintain both appearance consistency and instruction adherence. Open-source models exhibit limitations in sequential visual transformations, while proprietary models like Gemini-2.0-Flash demonstrate some success in appearance fidelity but struggle with fine-grained reasoning. Further investigation is needed to improve spatial understanding and reasoning-aware image generation.
CoT’s Diminishing#
The research explores the limitations of the Chain-of-Thought (CoT) prompting technique in multi-step sequential reasoning tasks, particularly within LEGO-Puzzles. The findings indicate that while CoT can offer some initial benefits, its effectiveness diminishes as the complexity (number of steps, ‘k’) increases. Several factors contribute to this ‘CoT’s Diminishing’ effect. Firstly, the compounding of errors across multiple reasoning steps leads to inconsistencies in final predictions. Secondly, MLLMs might lack a robust visual memory, hindering their ability to coherently track changes. Thirdly, some models fail to perform genuine step-by-step reasoning in their CoT responses. These findings underscore the need for alternative prompting strategies to improve multi-step sequential reasoning in MLLMs. Future research should focus on developing methods that mitigate error accumulation, enhance visual memory, and encourage genuine step-by-step reasoning.
More visual insights#
More on figures

🔼 Figure 2 presents example questions from the LEGO-Puzzles benchmark, categorized by task type. The figure showcases the visual complexity and diversity of the questions, which range from basic spatial understanding (e.g., identifying the relative heights of LEGO pieces, determining adjacency, understanding rotations and viewpoints) to single-step sequential reasoning (e.g., determining the next assembly state given instructions, identifying required pieces, assessing rotation needs) and multi-step sequential reasoning (e.g., determining the correct order of steps, identifying incorrect intermediate states). This visual representation helps illustrate the progression of task difficulty and the range of spatial reasoning skills assessed by the LEGO-Puzzles benchmark.
read the caption
Figure 2: Task examples of LEGO-Puzzles. From left to right, the columns represent tasks in Spatial Understanding, Single-Step Sequential Reasoning, and Multi-Step Sequential Reasoning. Note: The questions above are slightly simplified for clarity and brevity.

🔼 This figure illustrates the process of creating the LEGO-Puzzles dataset. It starts with collecting diverse LEGO building instructions. These instructions are then rendered into images with consistent formatting. Next, question-answer pairs are generated, combining human annotation with pre-defined templates. Finally, a three-stage quality control process is implemented to ensure accuracy, consistency and reliability of the resulting dataset.
read the caption
Figure 3: Data curation pipeline. Our pipeline first collects a diverse set of LEGO building instructions to render and extract LEGO images in a unified format. Next, we generate question-answer pairs by using a combination of human annotation and predefined question templates. Finally, we implement three quality control strategies to ensure the accuracy, consistency, and reliability of the data.

🔼 Figure 4 shows a template used in the LEGO-Puzzles benchmark for creating question-answer pairs. It illustrates the structure of the template, which includes three parts: instructions explaining the task to the model (in this case, determining the correct assembly point of a LEGO piece), a question presenting a specific scenario with images of the current state, the next piece, and the state after installation, and finally the ground truth answer providing the correct choice from several options given.
read the caption
Figure 4: Task-specific template. Our question-answer template includes instructions, questions, and answers. Here, we provide an example from the Position task for reference.

🔼 This heatmap visualizes the pairwise correlations between different tasks within the LEGO-Puzzles benchmark. It shows how strongly the performance on one task is related to performance on another. The correlations are calculated using three different methods: Spearman Rank Correlation Coefficient (SRCC), Pearson Linear Correlation Coefficient (PLCC), and R-squared (R²). Stronger correlations (closer to 1) are represented by darker colors, indicating tasks that share underlying skills or cognitive processes. Weaker correlations (closer to 0) are shown in lighter colors, implying greater independence between the tasks. This analysis helps to understand the structure of the benchmark and ensures diversity among the tasks, preventing redundancy and bias in the overall evaluation of MLLM capabilities.
read the caption
Figure 5: Task Similarity Heatmap. The heatmap illustrates the pairwise correlation between tasks in our benchmark, measured using SRCC, PLCC, and R² scores.

🔼 This figure showcases examples where large language models (LLMs) failed to correctly answer questions from the LEGO-Puzzles benchmark. It highlights two specific task types: ‘Height’, which assesses the ability to determine the relative height of LEGO pieces, and ‘Ordering’, which tests the capacity to arrange steps in a LEGO assembly sequence. The figure presents the original question, the correct answer (in blue), and the incorrect answer generated by the LLM (in red). This visually demonstrates the challenges that LLMs face in spatial reasoning, particularly when handling 2D representations of 3D objects and understanding the order of sequential steps.
read the caption
Figure 6: Visualization of sample failure cases in Height and Ordering. The Ground Truth answer is marked in blue, while the MLLM’s answer is marked in red. Note: The questions above are slightly simplified for clarity and brevity.

🔼 This figure showcases the qualitative results of image generation tests performed on two specific tasks within the LEGO-Puzzles benchmark: Rotation* and Multiview*. The Rotation* task evaluates the model’s ability to generate an image of a LEGO object rotated by a specified angle compared to a reference image. The Multiview* task assesses the model’s capacity to produce an image of a LEGO object viewed from a different perspective than shown in a reference image. The figure displays example images generated by various models, highlighting differences in their ability to both accurately depict the LEGO structure and correctly follow the instructions for generating the images. Note that the image questions shown in the caption are slightly simplified versions.
read the caption
Figure 7: Qualitative image generation results for Rotation* and Multiview* tasks. Note: The questions above are slightly simplified for clarity and brevity.
More on tables
| Models | Spatial Understanding | Single-Step Reasoning | Multi-Step Reasoning | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Height | Adjacency | Rotation | Multiview | Next-Step | Dependency | Rotation Stat. | Position | Backwards | Ordering | Outlier | ||
| LEGO-Puzzles-Lite | ||||||||||||
| Human proficiency | 70.0 | 95.0 | 95.0 | 100.0 | 90.0 | 100.0 | 100.0 | 95.0 | 95.0 | 95.0 | 95.0 | 93.6 |
| Claude-3.5-Sonnet | 40.0 | 55.0 | 50.0 | 50.0 | 60.0 | 75.0 | 55.0 | 35.0 | 60.0 | 55.0 | 60.0 | 54.1 |
| Gemini-2.0-Flash | 30.0 | 65.0 | 55.0 | 40.0 | 80.0 | 85.0 | 60.0 | 40.0 | 60.0 | 50.0 | 45.0 | 55.5 |
| GPT-4o | 35.0 | 75.0 | 45.0 | 50.0 | 60.0 | 85.0 | 60.0 | 60.0 | 55.0 | 60.0 | 65.0 | 59.1 |
| InternVL2.5-78B | 40.0 | 55.0 | 30.0 | 45.0 | 60.0 | 85.0 | 55.0 | 30.0 | 25.0 | 20.0 | 50.0 | 45.0 |
| Qwen2-VL-72B | 30.0 | 65.0 | 45.0 | 50.0 | 55.0 | 80.0 | 45.0 | 35.0 | 30.0 | 15.0 | 35.0 | 44.1 |
| Qwen2.5-VL-72B | 25.0 | 70.0 | 25.0 | 35.0 | 65.0 | 70.0 | 65.0 | 45.0 | 55.0 | 20.0 | 55.0 | 48.2 |
🔼 This table presents a comparison of the performance of top-performing large multimodal language models (MLLMs) and human experts on a subset of the LEGO-Puzzles benchmark (LEGO-Puzzles-Lite). It shows the accuracy of each model on various subtasks within the three main categories of LEGO-Puzzles: Spatial Understanding, Single-Step Sequential Reasoning, and Multi-Step Sequential Reasoning. The best performance in each task and the overall top three performing models are highlighted for easy comparison. The results underscore the significant performance gap between current MLLMs and human-level spatial reasoning abilities.
read the caption
Table 2: Comparing Top-Performing MLLMs with Human Proficiency on LEGO-Puzzles-Lite. The best results are marked in bold. The top three overall performances are highlighted in Dark Green, Medium Green, and Light Green, respectively.
| Task \MLLM | Gemini-2.0-Flash | GPT-4o | Emu2 | GILL | Anole | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| App | IF | App | IF | App | IF | App | IF | App | IF | |
| Rotation* | 2.30 | 1.65 | 0.95 | 0.80 | 2.10 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 |
| Multiview* | 1.80 | 1.35 | 2.25 | 0.45 | 2.10 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 |
| Position* | 3.00 | 1.40 | 3.00 | 1.10 | 0.65 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Dependency* | 1.85 | 1.25 | 0.55 | 0.25 | 0.65 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Next-Step* | 1.80 | 0.20 | 0.55 | 0.20 | 2.10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Overall | 2.15 | 1.17 | 1.46 | 0.56 | 1.52 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 |
🔼 This table presents a human evaluation of image generation capabilities for five different large language models (LLMs): Gemini-2.0-Flash, GPT-40, Emu2, GILL, and Anole. The evaluation focuses on two aspects: the generated image’s visual appearance and how well the image follows the given instructions. A 0-3 scoring scale is used for both ‘Appearance’ and ‘Instruction Following’, allowing for a nuanced assessment of the models’ image generation performance across various tasks.
read the caption
Table 3: Evaluation on Generation. We conduct human-based evaluation to assess the “Appearance” (App) and “Instruction Following” (IF) scores of Gemini-2.0-Flash, GPT-4o, Emu2, GILL, and Anole, using a scoring scale from 0 to 3 for both dimensions.
| Setting | GPT-4o | Gemini-2.0-Flash | Qwen-2.5-72B | Internvl-2.5-78B | ||||
|---|---|---|---|---|---|---|---|---|
| w/o CoT | w. CoT | w/o CoT | w. CoT | w/o CoT | w. CoT | w/o CoT | w. CoT | |
| 45.0 | 75.0 | 85.0 | 60.0 | 65.0 | 65.0 | 35.0 | 55.0 | |
| 15.0 | 25.0 | 45.0 | 50.0 | 60.0 | 55.0 | 30.0 | 20.0 | |
| 5.0 | 5.0 | 35.0 | 40.0 | 75.0 | 75.0 | 10.0 | 20.0 | |
| 5.0 | 0.0 | 35.0 | 50.0 | 65.0 | 65.0 | 20.0 | 5.0 | |
| 5.0 | 0.0 | 20.0 | 25.0 | 65.0 | 65.0 | 25.0 | 10.0 | |
🔼 This table presents the results of evaluating various LLMs on the Next-k-Step task. The Next-k-Step task is a sequential reasoning task that involves determining the correct LEGO object configuration after sequentially adding k LEGO pieces. The experiment was conducted with and without the Chain-of-Thought (CoT) prompting technique to analyze its effect on the models’ performance. The table shows the accuracy of each model for different values of k (number of steps) and with/without CoT, providing insights into the models’ multi-step sequential reasoning capabilities and the effectiveness of CoT prompting in improving those capabilities.
read the caption
Table 4: Evaluation on Next-kkkitalic_k-Step. k𝑘kitalic_k represents the number of steps, and CoT refers to adding a “Think step by step before answering” instruction in QA pairs, similar to those in LLMs.
| Task | PCC | P-value |
|---|---|---|
| Height | 0.93 | 0.00723 |
| Adjacency | 0.98 | 0.00046 |
🔼 This table presents the Pearson Correlation Coefficients (PCC) and associated p-values, assessing the correlation between the ‘Height’ and ‘Adjacency’ tasks in the LEGO-Puzzles benchmark. The PCC measures the strength and direction of the linear relationship between the performance scores on these two tasks, while the p-value indicates the statistical significance of this correlation. A high PCC near 1 (or -1 for negative correlation) and a small p-value (typically below 0.05) suggest a strong and statistically significant relationship between the tasks.
read the caption
Table 5: Pearson Correlation Coefficients (PCC) and P-values for Height and Adjacency Tasks
Full paper#