TL;DR#
Recent models struggle with generating coherent, long-form text in images. Existing text-to-image systems are limited to brief phrases or sentences. This paper identifies the image tokenizer as a key bottleneck in text generating quality. State-of-the-art autoregressive generation models need improvement in handling complex or lengthy text inputs, particularly regarding codebook embedding limitations. Existing methods render longer text but lack font control and support limited token lengths.
LongTextAR, a multi-modal autoregressive model, excels in generating high-quality long-text images with unprecedented fidelity via a novel binary tokenizer optimized for capturing detailed scene text features. It provides robust controllability, allowing customization of font style, size, color, and alignment. Experiments show it outperforms models such as SD3.5 Large and DALL-E 3 in generating long text accurately and flexibly. The versatility also allows for innovative applications like document/PowerPoint generation.
Key Takeaways#
Why does it matter?#
Addresses long-text image generation, overcoming limitations of existing models. Offers a new approach and opens avenues for document and PowerPoint generation. It can significantly impact future research trends related to multi-modal learning and content creation.
Visual Insights#

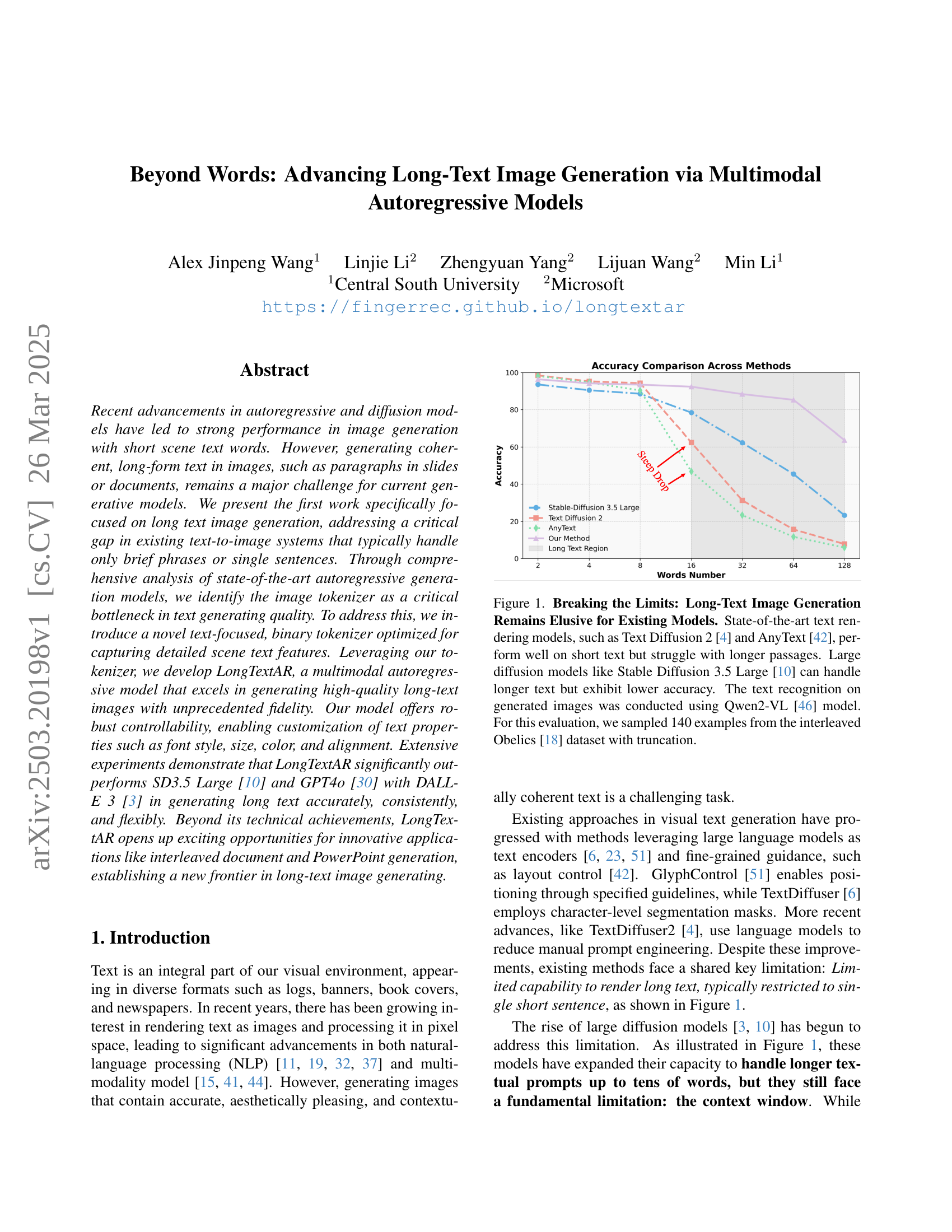
🔼 The figure illustrates the limitations of existing text-to-image models in handling long text. While models like Text Diffusion 2 and AnyText perform well with short text inputs, their accuracy significantly decreases when processing longer passages. Even large diffusion models such as Stable Diffusion 3.5 Large struggle to maintain high accuracy with long text. This experiment used the Qwen2-VL model for text recognition on images generated from 140 examples (with truncation) of the interleaved Obelics dataset.
read the caption
Figure 1: Breaking the Limits: Long-Text Image Generation Remains Elusive for Existing Models. State-of-the-art text rendering models, such as Text Diffusion 2 [4] and AnyText [42], perform well on short text but struggle with longer passages. Large diffusion models like Stable Diffusion 3.5 Large [10] can handle longer text but exhibit lower accuracy. The text recognition on generated images was conducted using Qwen2-VL [46] model. For this evaluation, we sampled 140 examples from the interleaved Obelics [18] dataset with truncation.
| Method | Embed Dim | Codebook Size | FID | PSNR | SSIM | Utilization |
|---|---|---|---|---|---|---|
| VQ | 512 | 8192 | 33.52 | 29.13 | 0.85 | 0.84 |
| Taming-Transformer VQ [9] | 512 | 8192 | 39.74 | 27.33 | 8.82 | 0.93 |
| Chameleon VQ [38] | 512 | 8192 | 34.63 | 29.65 | 0.86 | 0.82 |
| TextBinarizer | 512 | 8192 | 27.47 | 33.99 | 0.93 | 0.73 |
| TextBinarizer | 512 | 65536 | 24.38 | 30.57 | 0.88 | 0.17 |
🔼 This table presents a quantitative comparison of the performance of TextBinarizer and Vector Quantization (VQ) methods on a complex long-text dataset reconstruction task. It shows that TextBinarizer significantly outperforms VQ in terms of FID (Fréchet Inception Distance), PSNR (Peak Signal-to-Noise Ratio), and SSIM (Structural Similarity Index) scores, indicating a substantial improvement in reconstruction quality. The table also includes the embedding dimension, codebook size, and utilization rate for both methods, providing additional context for the performance differences. The results demonstrate that TextBinarizer offers a more efficient and effective approach for reconstructing text in complex datasets.
read the caption
Table 1: TextBinarizer clearly outperform Vector Quantization on complex long-text dataset reconstruction.
In-depth insights#
Tokenizer Limit#
When focusing on the idea of a ‘Tokenizer Limit,’ several key insights emerge. Current autoregressive models and even large diffusion models often face constraints due to their limited context windows. This impacts their ability to handle longer, coherent text, leading to a drop in accuracy and consistency. Tokenization, the process of converting text into discrete units, becomes a bottleneck when dealing with extensive textual data. Traditional tokenizers, often prioritizing general image features, may not capture the nuances of fine-grained textual details, leading to blurry or illegible outputs. Overcoming this ‘Tokenizer Limit’ is crucial for advancing text-rich image generation, necessitating specialized tokenization strategies tailored for text rendering to maintain fidelity and coherence in generated images.
TextBinarizer#
TextBinarizer appears to be a novel text-focused tokenizer. It is designed to improve text rendering in multimodal autoregressive models. It addresses limitations in existing tokenization methods. The key idea seems to be using a binary codebook instead of vector quantization. This enables more precise text encoding. A bitwise approach captures finer details than traditional methods. It allows it to maintain high-quality text rendering. The implementation uses a CNN encoder, lightweight transformer, and decoder. Freezing VQGAN weights aids natural image transfer. Potential benefits include better text fidelity, computational efficiency, and image adaptation. It aims to overcome blurry outputs when generating text-heavy images.
LongTextAR Model#
The LongTextAR model marks a significant step in image generation, specifically designed for extended textual content. It tackles the challenge of generating coherent, high-quality images from long-form text, unlike existing systems often limited to short phrases. By addressing tokenization bottlenecks, the model improves text rendering in images. LongTextAR employs a multimodal autoregressive approach, effectively synthesizing text and image tokens. The model’s architecture emphasizes capturing detailed textual features for fidelity and robust controllability, offering customization options for font style, size, color and alignment. The focus on a specialized tokenizer highlights the importance of text encoding, leading to more precise reconstruction. The results demonstrate LongTextAR’s effectiveness in generating readable text, outperforming other models in accuracy and consistency. It’s a move from short snippets to detailed content generation.
Control Renders#
Thinking about ‘Control Renders,’ a key aspect would be the ability to manipulate generated images based on defined parameters. This includes controlling the style, content, and attributes of the rendered output. Crucially, it signifies going beyond simple text-to-image generation to offering precise control over visual elements. This could involve specifying font styles, colors, object placement, and overall aesthetic themes. The challenge lies in creating models that understand nuanced instructions and execute them accurately, maintaining both fidelity to the input and stylistic coherence. A robust ‘Control Renders’ system would unlock applications in design, content creation, and personalized image generation, enabling users to realize specific artistic visions with greater ease and precision. Control in rendering would signify a new level of capability in generative AI, moving from general approximation to deliberate artistic direction. It opens avenues for creating targeted visuals aligned with precise user needs, rather than relying on chance or broad prompting.
Generative Gap#
While not explicitly mentioned, a ‘Generative Gap’ in the context of this paper on long-text image generation likely refers to the discrepancy between the ideal output (high-quality, coherent long text in an image) and what current generative models can achieve. This gap arises because existing models, while proficient with short text, struggle with the intricacies of rendering long, contextually relevant passages. Factors contributing to this gap include the limitations of image tokenizers in capturing fine-grained text details, the context window constraints of diffusion models, and the difficulties AR models face in precise text rendering, particularly with complex or lengthy inputs. Overcoming this ‘Generative Gap’ requires innovations in tokenization, model architecture, and training strategies, as evidenced by the authors’ development of TextBinarizer and LongTextAR to push the boundaries of long-text image generation.
More visual insights#
More on figures

🔼 Figure 2 illustrates the architecture of TextBinarizer, a novel text-focused binary tokenizer. It shows how high-dimensional word embeddings are converted into binary tokens through a quantization process, enabling direct quantization without the need for a codebook. The figure depicts the encoder and decoder components, highlighting the use of convolutional neural networks (CNNs) and a quantization discriminator to optimize the process for enhanced text detail preservation.
read the caption
Figure 2: TextBinarizer implementation details. This approach allows for direct quantization.

🔼 The figure illustrates the architecture of LongTextAR, a model designed for generating images from long text. The process begins with a text-focused tokenizer converting the long text into discrete tokens. Simultaneously, a corresponding long-text prompt is generated. The core model then uses this prompt to predict the image’s token IDs, which are subsequently decoded to produce the final image.
read the caption
Figure 3: The main pipeline of LongTextAR. Our trained text-focused tokenizer converts the long-text image into discrete token IDs. A corresponding long-text prompt is generated, and the model is then tasked with predicting the image token IDs based on this long text prompt.

🔼 This figure displays a comparison of text reconstruction quality between a traditional Vector Quantization (VQ) tokenizer and the novel TextBinarizer tokenizer introduced in the paper. The comparison uses a dataset containing long text passages. The results visually demonstrate that TextBinarizer, designed with a focus on detailed text features, achieves superior reconstruction of fine details such as individual letters compared to the VQ tokenizer. The improved quality with TextBinarizer is particularly evident in the more complex, long-text data.
read the caption
Figure 4: Tokenizer reconstruction comparison on data with long-text. Comparing with well-trained VQ tokenizer from Chameleon [38], our text-focus tokenizer leads to better reconstruction result on detail generation for letters.

🔼 This figure demonstrates the controllability of the LongTextAR model in generating text images. Multiple examples are shown, each with different modifications to the text’s font type, color, rotation degree, and alignment. This showcases the model’s ability to precisely follow user-specified formatting instructions, resulting in high-fidelity text rendering and diverse visual styles.
read the caption
Figure 5: Controllable experiment, we modify the text font type, text color and text rotation degree, also the alignment way.
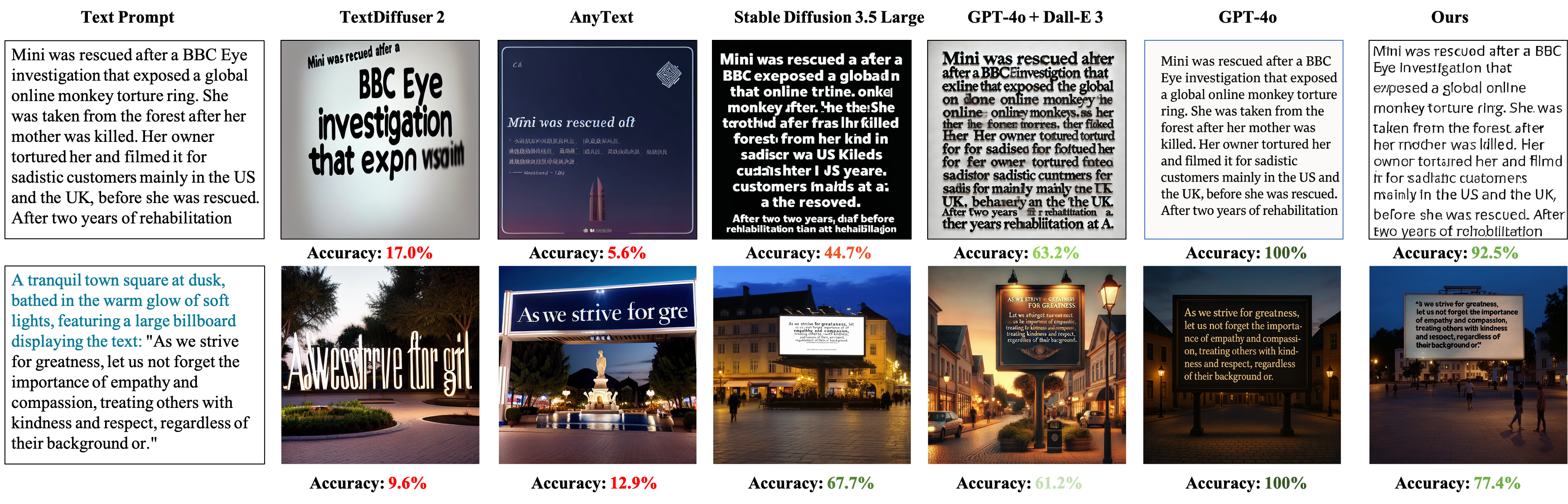
🔼 This figure compares the long-text image generation capabilities of several models: LongTextAR, Stable Diffusion 3.5 Large, GPT-40+DALL-E 3, TextDiffuser 2, and AnyText. The models were prompted to generate images containing a specific long text passage. Stable Diffusion 3.5 Large and GPT-40+DALL-E 3 used a prompt specifying a white background and the target text. TextDiffuser 2 used a different prompt and included the text as tags. The accuracy of text recognition in the generated images was assessed using Qwen2-VL. The results reveal that GPT-40, released in March 2025, significantly outperforms all other models, both open-source and closed-source.
read the caption
Figure 6: Text-conditioned long-text image generation comparison. The Stable Diffusion3.5 Large [10] and GPT-4o [30]+Dall-E3 [3] using the prompt Generate a white-background text image and the text is: [Text Prompt]. The text is clear and large. For TextDiffuser 2 [4] we use the prompt A text image and input other text as tags. We use the Qwen2-VL [46] to recognize words from generated images and compute the accuracy according to the ground-truth text [Text Prompt]. The image generation capabilities of GPT4o [30], released at the end of March 2025, have shown a huge gap over all other models, both open-source and closed-source.

🔼 This figure showcases examples of LongTextAR’s ability to render text within natural images. Unlike synthetically generated images with precisely placed text, these examples demonstrate the model’s capacity to integrate text naturally into real-world scenes, handling variations in text style and image context.
read the caption
Figure 7: Natural image text rendering examples.

🔼 Figure 8 showcases LongTextAR’s ability to generate PowerPoint slides from long text prompts. The model not only accurately renders the text and images provided but also effectively creates the layout of the slide, demonstrating proficiency in arranging both visual and textual elements in a coherent manner. Bounding boxes around the text within the input highlight the precise placement and alignment of elements in the generated slides.
read the caption
Figure 8: LongTextAR generates interleaved PowerPoint data from long-text prompts. The model accurately produces layouts and renders both text and images effectively. Bounding boxes from the text input are shown as a reference.

🔼 Figure 9 shows a comparison of the capabilities of Lumina-mGPT, a model based on Chameleon, in handling complex textual instructions for image generation. The figure demonstrates that Lumina-mGPT, while an enhanced model, has limitations in effectively following and accurately representing intricate or lengthy textual instructions during the image generation process. The results highlight that simply enhancing a model is not sufficient to overcome the challenge of accurately interpreting complex instructions and converting them into high-fidelity images.
read the caption
Figure 9: Baseline comparison. Lumina-mGPT [21], an enhanced generation model built upon Chameleon [38], demonstrates limited capability in effectively following complex textual instructions.

🔼 This figure compares the performance of different models, including Stable Diffusion 3.5 Large, GPT-4.0 + DALL-E 3, and the authors’ LongTextAR model, on the task of generating interleaved PowerPoint slides from text prompts. The comparison highlights the ability of each model to accurately render text and images within the specified layout and formatting requirements. It demonstrates the superior performance of LongTextAR in terms of both accuracy and adherence to the prompt’s instructions.
read the caption
Figure 10: The interleaved powerpoint generation comparison.

🔼 This figure showcases additional examples of the model’s ability to generate PowerPoint-like slides containing both text and images. The slides demonstrate the model’s capacity to handle various layouts and styles, incorporating both text-only and interleaved content effectively. It highlights the model’s ability to seamlessly integrate different modalities and generate visually appealing and informationally complete slides.
read the caption
Figure 11: More interleaved data examples.

🔼 This figure compares the performance of Stable Diffusion 3.5 Large and GPT-4-O in generating images based on prompts with controllable variables (font color, type, rotation). Stable Diffusion 3.5 Large largely ignores the specified instructions, frequently producing unrelated images. GPT-4-O shows improvement in following instructions but still lacks accuracy and fails to incorporate all specified variables into the generated images.
read the caption
Figure 12: Experiment on Controllable Variables: Stable Diffusion 3.5 Large [10] demonstrates poor instruction-following ability, ignoring all specified variants and occasionally generating irrelevant images. GPT-4-O [30], while showing noticeably better instruction-following capability, produces outputs with low accuracy and fails to capture the specified controllable variables.

🔼 This figure displays additional examples of PowerPoint slides generated by the LongTextAR model. The examples showcase the model’s ability to handle diverse layouts and styles, including those with varying text lengths and combinations of text and images. This demonstrates the model’s flexibility in generating complex, multi-modal documents.
read the caption
Figure 13: More powerpoint generation examples.
More on tables
| Metrics | TextDiffuser [6] | AnyText [42] | TextDiffuser-2 [4] | SD3.5 Large [10] | LongTextAR | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Short | Long | Short | Long | Short | Long | Short | Long | Short | Long | |
| CLIPScore | 31.7 | 30.6 | 32.5 | 30.3 | 31.1 | 29.8 | 32.2 | 30.9 | 33.3 | 31.4 |
| OCR (Accuracy) | 72.4 | 38.7 | 69.5 | 34.5 | 71.3 | 33.0 | 73.2 | 52.3 | 82.7 | 69.5 |
| OCR (F-measure) | 77.6 | 50.3 | 75.49 | 51.3 | 76.2 | 52.4 | 78.4 | 63.5 | 85.3 | 70.3 |
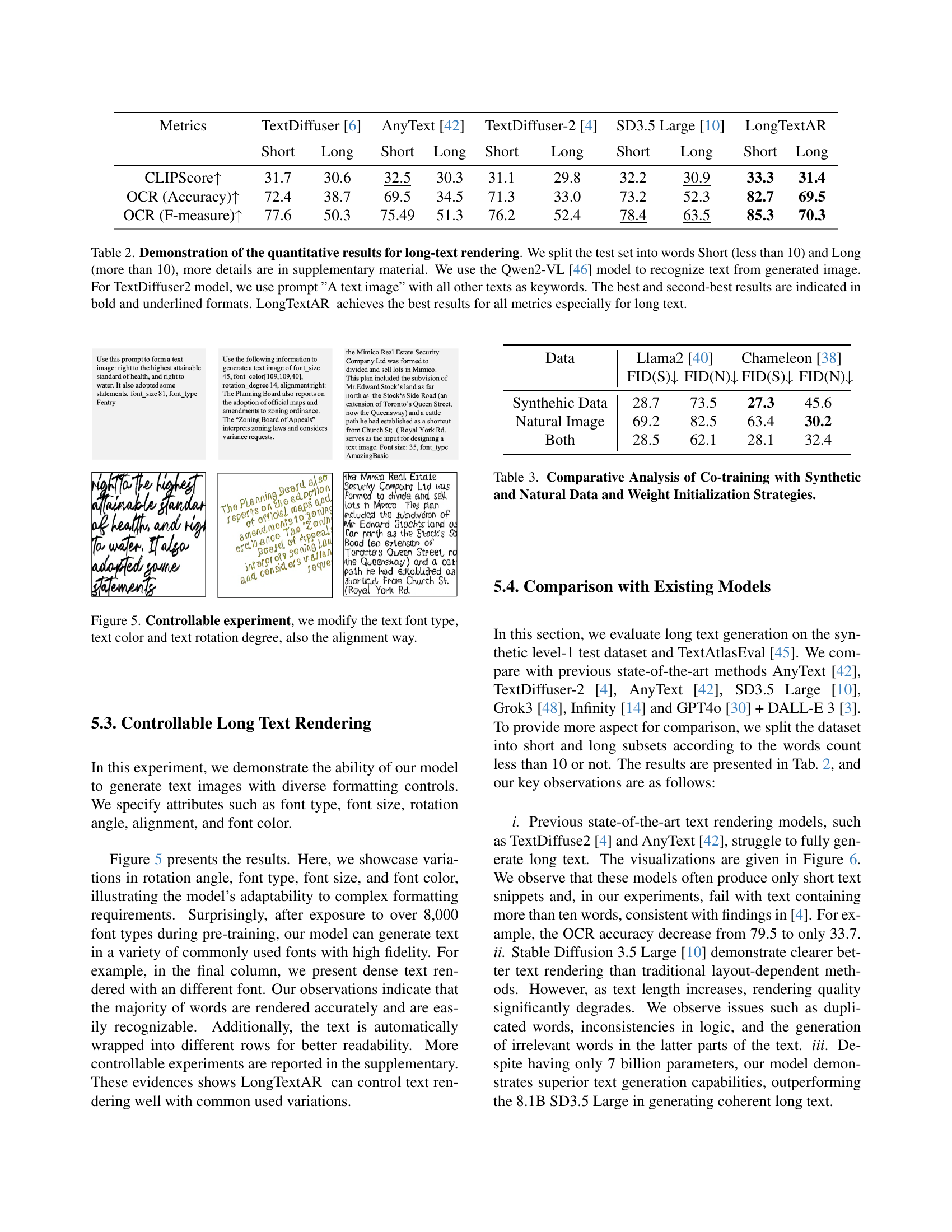
🔼 This table presents a quantitative comparison of different models’ performance on long-text image generation. The models are evaluated on two categories of test data: short text (less than 10 words) and long text (more than 10 words). The metrics used are CLIPScore, OCR accuracy, and OCR F-measure. The evaluation involves generating images from text prompts using each model, then using the Qwen2-VL model to perform optical character recognition (OCR) on the generated images to assess the accuracy of the rendered text. For the TextDiffuser2 model, a specific prompt (‘A text image’) was used with additional keywords. The best and second-best results for each metric and text length are highlighted.
read the caption
Table 2: Demonstration of the quantitative results for long-text rendering. We split the test set into words Short (less than 10) and Long (more than 10), more details are in supplementary material. We use the Qwen2-VL [46] model to recognize text from generated image. For TextDiffuser2 model, we use prompt ”A text image” with all other texts as keywords. The best and second-best results are indicated in bold and underlined formats. LongTextAR achieves the best results for all metrics especially for long text.
| Data | Llama2 [40] | Chameleon [38] | ||
|---|---|---|---|---|
| FID(S) | FID(N) | FID(S) | FID(N) | |
| Synthehic Data | 28.7 | 73.5 | 27.3 | 45.6 |
| Natural Image | 69.2 | 82.5 | 63.4 | 30.2 |
| Both | 28.5 | 62.1 | 28.1 | 32.4 |
🔼 This table presents a comparative analysis of different training strategies for the LongTextAR model. It compares the Fréchet Inception Distance (FID) scores achieved when training with synthetic data only, natural image data only, and a combination of both. It also shows the impact of using different pre-trained weight initializations (Llama2 vs. Chameleon) on the model’s performance across these training scenarios. Lower FID scores indicate better image quality.
read the caption
Table 3: Comparative Analysis of Co-training with Synthetic and Natural Data and Weight Initialization Strategies.
| Encoder | VQ Quant | Projector | Quant Layer 2 | Decoder | FID | |||||
| Model | Frozen | Model | Frozen | Model | Frozen | Model | Frozen | Model | Frozen | |
| ConvNet(256) | ✓ | VQ | ✓ | Single Layer FC | ✓ | - | - | DeConvNet(256) | ✓ | 98.44 |
| ConvNet(256) | ✓ | VQ | ✓ | Single Layer FC | TextBinarizer-13 | DeConvNet(13) | 79.92 | |||
| ConvNet(256) | ✓ | VQ | ✓ | 3-Layer Transformer | TextBinarizer-13 | DeConvNet(13) | 62.35 | |||
| ConvNet(256) | ✓ | VQ | ✓ | 3-Layer Transformer | TextBinarizer-18 | DeConvNet(18) | 58.43 | |||
| ConvNet(256) | - | - | 3-Layer Transformer | TextBinarizer-13 | DeConvNet(13) | 39.36 | ||||
| ConvNet(13) | - | - | Single Layer FC | TextBinarizer-13 | DeConvNet(13) | 42.68 | ||||
🔼 This table presents ablation study results on different configurations of the TextBinarizer tokenizer within the LongTextAR model. It compares various model components, including the encoder, decoder, and the VQ-GAN. Experiments involved freezing certain components (indicated by ✓) during training. The FID score (Fréchet Inception Distance), a metric for image quality, was used to evaluate performance. The last two rows provide upper-bound results using the full model capacity.
read the caption
Table 4: Training quantization and decoder experiments. The VQ-GAN weights are initialized from the Chameleon [38] model, and each model is trained for 4 epochs. Frozen components are indicated with a ✓. The last two rows represent the upper bounds.
Full paper#