TL;DR#
Proprietary search AI solutions dominate, limiting transparency and innovation. To address this, the paper introduces Open Deep Search (ODS), aiming to bridge the gap with an open-source alternative. ODS seeks to encourage community-driven development in search AI, harnessing collective talent. It achieves performance matching or surpassing closed-source options in benchmark evaluations, offering a competitive, transparent solution.
ODS augments open-source LLMs with reasoning agents for web search. It consists of Open Search Tool and Open Reasoning Agent. The Open Search Tool outperforms proprietary tools. Combined with LLMs like DeepSeek-R1, ODS nears or exceeds state-of-the-art baselines on SimpleQA and FRAMES. For instance, ODS improves FRAMES accuracy by 9.7% over GPT-4o Search Preview. This flexible framework enhances any LLM.
Key Takeaways#
Why does it matter?#
This paper is crucial for democratizing search AI. It provides an open-source alternative that matches the state-of-the-art performance, reducing reliance on closed solutions. This fosters innovation and opens new research directions in reasoning and search methodologies. ODS enables future work to build upon a transparent, high-performing search AI.
Visual Insights#

🔼 The figure illustrates the architecture of Open Deep Search (ODS), an open-source framework that enhances Large Language Models (LLMs) with search and reasoning capabilities. Users can select any LLM as a base model. The core components are the Open Reasoning Agent and the Open Search Tool. The Open Reasoning Agent receives user queries and uses a chain of thought to determine which tools are needed to best answer the query. The Open Search Tool is a key component, designed to retrieve high-quality context from multiple web sources. The figure shows the flow of information, highlighting the interaction between the LLM, the reasoning agent, the search tool, and other auxiliary tools like a calculator or code interpreter. The example uses Llama3.1-70B and DeepSeek-R1 as base models.
read the caption
Figure 1: A user can choose to plug in any base LLM of their choice and harness the benefits of the open-source framework of Open Deep Search (ODS), which consists of two components: Open Search Tool and Open Reasoning Agent. A query is first fed into Open Reasoning Agent which orchestrates the available set of tools to interpret and answer the query. The most important tool is the Open Search Tool that we design, which provides a high quality context from multiple retrieved sources from the web. In our experiments we use Llama3.1-70B and DeepSeek-R1 as our base model.
| SimpleQA | FRAMES | ||
| Llama3.1-70B | 20.4 | 34.3 | |
| w/o access to the web | DeepSeek-R1 | 82.4 | 30.1 |
| GPT-4o | 37.5 | 50.5 | |
| Perplexity [21] | 82.4 | 42.4 | |
| Perplexity Sonar Reasoning Pro [22] | 85.8 | 44.4 | |
| with access to the web | GPT-4o Search Preview [17] | 90.0 | 65.6 |
| ODS-v1+DeepSeek-R1 (ours) | 87.7 | 56.7 | |
| ODS-v2+DeepSeek-R1 (ours) | 88.3 | 75.3 |
🔼 This table compares the performance of the proposed Open Deep Search (ODS) framework, using the open-source DeepSeek-R1 language model, against several state-of-the-art closed-source search AI solutions (Perplexity, Perplexity Sonar Reasoning Pro, and GPT-4 Search Preview) on two benchmark datasets (FRAMES and SimpleQA). It highlights ODS’s performance exceeding those of the closed-source solutions, showing that ODS nearly matches and sometimes surpasses them. The table also differentiates between two versions of ODS (ODS-v1 and ODS-v2), which use different reasoning agents (ReAct and CodeAct, respectively), and notes that ODS-v2 provides a significant improvement on the FRAMES benchmark compared to the GPT-40 Search Preview, although it performs slightly worse on SimpleQA.
read the caption
Table 1: The proposed open-source search framework of ODS, when used with the open-source reasoning LLM of DeepSeek-R1 [4], achieves performance exceeding that of closed-source state-of-the-art search AI solutions of Perplexity [21], Perplexity Sonar Reasoning Pro [22] on the two popular factuality evaluation Benchmarks of FRAMES [8] and SimpleQA [30]. Compared to GPT-4o Search Preview, ODS-v2 has a significantly better FRAMES accuracy but a slightly worse SimpleQA accuracy. ODS-v1 uses a ReAct-based agent (Section 2.2.1) and ODS-v2 uses a CodeAct-based agent (Section 2.2.2)
In-depth insights#
ODS: Open Search#
Open Deep Search (ODS) is introduced as an open-source search solution aimed at bridging the gap between proprietary AI search tools and their open-source counterparts. The core innovation lies in augmenting open-source LLMs with reasoning agents capable of judiciously utilizing web search tools for query answering. ODS comprises two main components: the Open Search Tool and the Open Reasoning Agent, both designed to work with a user-selected base LLM. The Open Reasoning Agent interprets tasks and orchestrates actions, including calling upon the novel Open Search Tool. This new search tool outperforms proprietary tools in web searches, achieving strong performance with powerful open-source reasoning LLMs like DeepSeek-R1. ODS as a framework, is created to seamlessly augment any LLMs with search and reasoning capabilities, to achieve state-of-the-art performance in benchmarks like SimpleQA and FRAMES. This effort promotes transparency, fosters innovation, and empowers entrepreneurs in the search AI space.
Reasoning Agents#
Reasoning agents are pivotal in augmenting LLMs for sophisticated search, as highlighted in the paper. They enable LLMs to surpass proprietary solutions by orchestrating sequences of actions involving tools like web search. The architecture involves interpreting queries, assessing context, and utilizing appropriate tools, enhancing overall performance. The paper explores both ReAct and CodeAct-based agents, showcasing versatility. Reasoning enhances the LLM’s ability to understand complex prompts and perform multiple-step retrievals leading to better answers. The agents’ adaptability allows them to handle varying tasks efficiently, contributing to the state-of-the-art performance achieved by the system. These agents also are responsible for tool selection for instance, choosing whether to use a calculator tool or continuing reasoning.
Search Tooling#
Search tools are indispensable for augmenting large language models (LLMs), providing real-time information access. Closed-source solutions dominate, hindering transparency. Open-source alternatives exist but face challenges in query processing, snippet relevance, and context extraction. Effective search tooling requires sophisticated query rephrasing, reliable source prioritization, and content filtering. Agentic frameworks can intelligently leverage search tools, adaptively selecting queries and integrating retrieved information. By promoting open-source development, we can foster innovation, democratize access, and mitigate the risks associated with proprietary systems.
CodeAct Agents#
The ‘CodeAct Agents’ section discusses employing executable Python code for tool calling. This method significantly enhances performance compared to JSON-based approaches. LLMs can compress the action-space using code, making it naturally suited for action taking. Code is composable, modularized, and generalized more easily than JSON, simplifying complex tasks. By using CodeAct Agents, Open Deep Search customizes tools such as SmolAgents to search the web. CodeAgent’s search tool allows for seamless customization and distribution.
Dynamic Prompts#
Dynamic few-shot learning with ReAct leverages demonstrative examples to guide reasoning. The system optimizes prompt efficiency via vector similarity matching, retrieving relevant examples and maintaining performance while reducing complexity. A community campaign designed 200 ReAct prompts, incorporating diverse intuitions resulting in substantially improved ReAct agent performance. Examples are included in Appendix B.
More visual insights#
More on tables
| Accuracy (%) | # of web searches per query | |||
| ODS+base-model | SimpleQA | FRAMES | SimpleQA | FRAMES |
| ODS-v1+Llama3.1-70B | 83.4 | 49.5 | 1.09 | 1.05 |
| ODS-v1+DeepSeek-R1 | 87.7 | 56.7 | 1.00 | 1.00 |
| ODS-v2+DeepSeek-R1 | 88.3 | 75.3 | 1.45 | 3.39 |
🔼 This table presents the average number of web searches performed by the Open Deep Search (ODS) system for each query across two benchmark datasets: SimpleQA and FRAMES. It highlights ODS’s adaptive search strategy. Instead of performing a fixed number of searches, ODS dynamically adjusts the number of searches based on the quality of the initial search results and the model’s output. If the initial results and model’s performance are satisfactory, ODS avoids additional searches. However, if improvement is needed, ODS judiciously conducts further searches to enhance accuracy.
read the caption
Table 2: How many times ODS searches the web, on average per query, for the two benchmarks. ODS adapts to the quality of the first search result and the model output to judiciously use the extra search only when deemed necessary.
| Search AI | SimpleQA (%) |
|---|---|
| Closed-source | |
| o1-mini [18] | |
| GPT-4o-mini-2024-07-18 [18] | |
| o3-mini-low [18] | |
| o3-mini [18] | |
| o3-mini-high [18] | |
| Grok 3 Mini Beta [32] | |
| Claude 3 Opus [18] | |
| GPT-4-turbo-2024-04-09 [18] | |
| Claude 3.5 Sonnet [18] | |
| GPT-4o [32] | |
| GPT-4o-2024-11-20 [18] | |
| GPT-4o-2024-05-13 [18] | |
| GPT-4o-2024-08-06 [18] | |
| o1 [18] | |
| o1-preview [18] | |
| Grok 3 Beta [32] | |
| Gemini 2.0 Pro [32] | |
| Perplexity Sonar [22] | |
| Perplexity [21] | 82.4 |
| Perplexity Sonar Reasoning Pro [22] | |
| GPT-4o Search Preview [17] | |
| Exa [1] | |
| Linkup [15] | |
| Perplexity Deep Research [23] | 93.9 |
| Open-source | |
| Qwen 2.5 [4] | |
| Llama3.1-70B | |
| DeepSeek-V3 [32] | |
| DeepSeek-R1 [5] | |
| ODS-v1+Llama3.1-70B | |
| ODS-v1+DeepSeek-R1 | |
| ODS-v2+DeepSeek-R1 | |
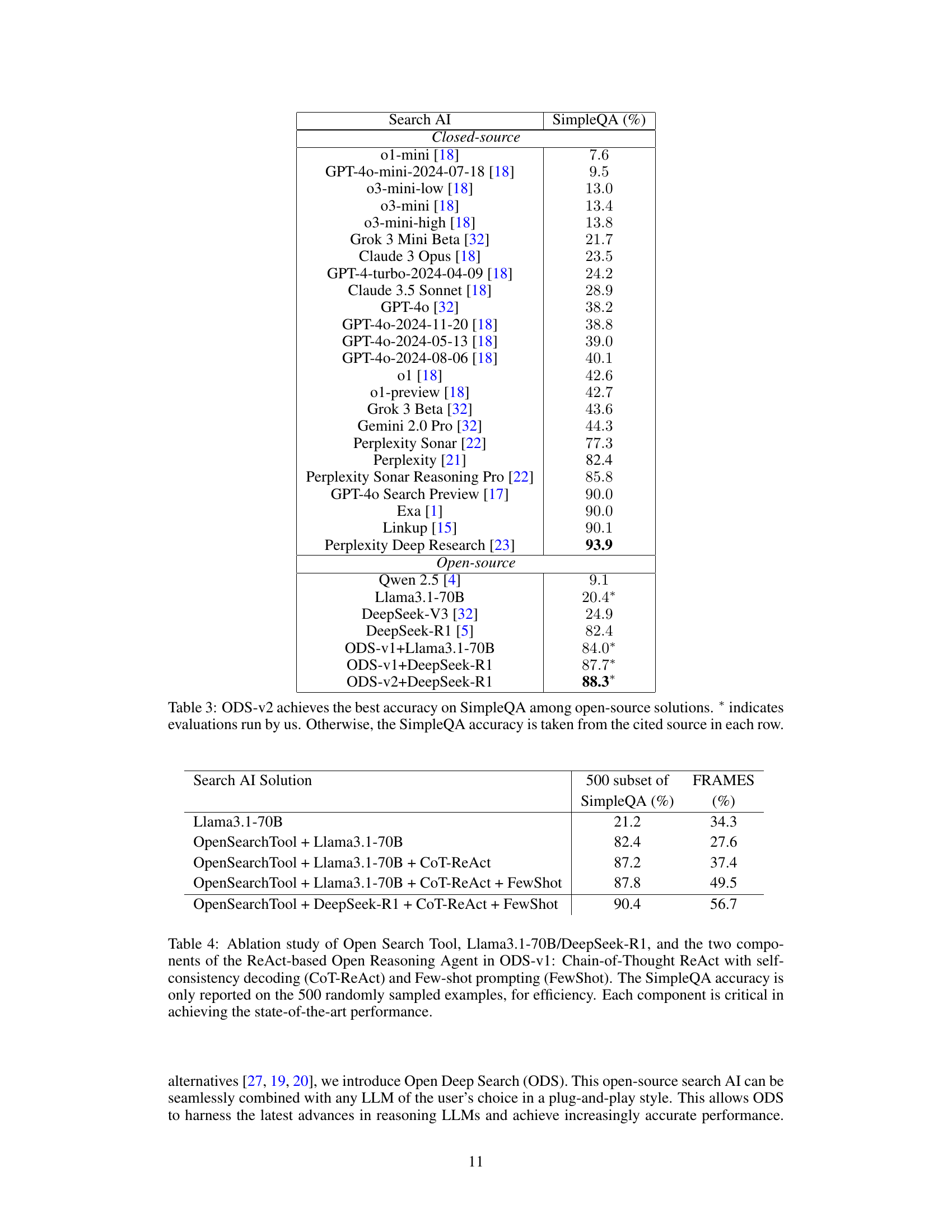
🔼 This table compares the performance of ODS-v2 against various other open-source and closed-source search AI models on the SimpleQA benchmark. The SimpleQA benchmark assesses the factuality of short-answer responses generated by models. The table shows that ODS-v2 achieves the highest accuracy among open-source models. The asterisk (*) indicates results obtained by the authors of the paper; other results were taken from cited publications.
read the caption
Table 3: ODS-v2 achieves the best accuracy on SimpleQA among open-source solutions. ∗ indicates evaluations run by us. Otherwise, the SimpleQA accuracy is taken from the cited source in each row.
| Search AI Solution | 500 subset of | FRAMES |
|---|---|---|
| SimpleQA (%) | (%) | |
| Llama3.1-70B | 21.2 | 34.3 |
| OpenSearchTool + Llama3.1-70B | 82.4 | 27.6 |
| OpenSearchTool + Llama3.1-70B + CoT-ReAct | 87.2 | 37.4 |
| OpenSearchTool + Llama3.1-70B + CoT-ReAct + FewShot | 87.8 | 49.5 |
| OpenSearchTool + DeepSeek-R1 + CoT-ReAct + FewShot | 90.4 | 56.7 |
🔼 This table presents an ablation study analyzing the contribution of each component in the ODS-v1 model to its overall performance. It shows the impact of using the Open Search Tool, the base language model (Llama3.1-70B or DeepSeek-R1), the Chain-of-Thought ReAct method, and few-shot prompting, individually and cumulatively, on the accuracy of the model in the SimpleQA and FRAMES benchmarks. A subset of 500 examples from SimpleQA was used for efficiency in this specific ablation study. The results highlight that each component plays a critical role in achieving the state-of-the-art performance.
read the caption
Table 4: Ablation study of Open Search Tool, Llama3.1-70B/DeepSeek-R1, and the two components of the ReAct-based Open Reasoning Agent in ODS-v1: Chain-of-Thought ReAct with self-consistency decoding (CoT-ReAct) and Few-shot prompting (FewShot). The SimpleQA accuracy is only reported on the 500 randomly sampled examples, for efficiency. Each component is critical in achieving the state-of-the-art performance.
Full paper#