TL;DR#
Existing methods for 3D scene understanding rely on neural mesh models, which require extensive 3D annotations for part-contrastive learning. This limits their scalability and applicability to a broader range of objects. To address this, DINeMo is introduced which trains a novel neural mesh model without any 3D annotations, but instead leverages the power of visual foundation models to learn object relationships.
DINeMo uses a bidirectional pseudo-correspondence generation method, combining local appearance features and global context information for enhanced performance. This approach allows DINeMo to outperform existing zero- and few-shot 3D pose estimation methods, narrowing the gap with fully-supervised approaches, while also scaling effectively with more unlabeled data.
Key Takeaways#
Why does it matter?#
This research is important because it presents a new method that significantly reduces the reliance on expensive 3D annotations for training neural mesh models. This enables the use of more abundant unlabeled data, paving the way for more scalable and robust 3D object understanding systems.
Visual Insights#

🔼 This figure illustrates the architecture of DINeMo, a novel neural mesh model. It highlights the model’s training process, which leverages pseudo-correspondence generated from large visual foundation models instead of relying on traditional 3D annotations. The diagram shows how pseudo-correspondences (positive and negative) are derived from the foundation models and used to train the neural mesh. The use of pseudo-correspondence allows the model to learn from large unlabeled datasets, enabling efficient scaling and improved robustness.
read the caption
Figure 1: Overview of DINeMo, a novel neural mesh model trained on pseudo-correspondence obtained from large visual foundation models.
| Methods | L0 | L1 | L2 | L3 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc@ | Acc@ | Acc@ | Acc@ | Acc@ | Acc@ | Acc@ | Acc@ | ||||
| Fully-Supervised | |||||||||||
| Resnet50 [5] | 95.5 | 63.5 | 80.0 | 40.7 | 57.0 | 21.4 | 36.9 | 7.6 | |||
| NOVUM [9] | 97.9 | 94.9 | 91.9 | 78.0 | 77.1 | 52.3 | 49.8 | 23.8 | |||
| Zero- and Few-Shot | |||||||||||
| NVS [31] (7-shot) | 63.8 | 36.4 | - | - | - | - | - | - | |||
| NVS [31] (50-shot) | 65.5 | 39.8 | - | - | - | - | - | - | |||
| 3D-DST [14] (0-shot) | 82.3 | 65.4 | - | - | - | - | - | - | |||
| DINeMo (ours) (0-shot) | 92.8 | 78.6 | 87.9 | 68.1 | 73.7 | 51.5 | 43.9 | 23.1 | |||
🔼 Table 1 presents a comparison of 3D object pose estimation methods on the car dataset from PASCAL3D+ and its occluded version. It shows the accuracy (Acc@) of different methods at varying levels of pose error tolerance (6, π/6, 18 degrees). The table compares fully-supervised methods (ResNet50 and NOVUM), zero-shot and few-shot methods (NVS and 3D-DST), and the authors’ DINeMo method. The key finding is that DINeMo significantly outperforms previous zero/few-shot approaches, substantially reducing the performance gap against the best fully-supervised methods (by 67.3%).
read the caption
Table 1: 3D object pose estimation on the car split of Pascal3D+ [32] and occluded PASCAL3D+ [29]. Our DINeMo outperforms previous zero- and few-shot 3D pose estimation methods by a wide margin, narrowing the gap with fully-supervised methods by 67.3%.
In-depth insights#
No 3D Needed#
The research explores learning object representations and 3D pose estimation without relying on explicit 3D annotations. This is significant because obtaining 3D data is often expensive and time-consuming, limiting the scalability of traditional methods. The approach likely leverages alternative sources of information, such as 2D images and visual foundation models, to infer 3D properties. Key aspects might involve self-supervision or pseudo-labeling techniques to bridge the gap between 2D observations and 3D understanding. The success of such a method would have a substantial impact on various applications, including robotics and computer vision, by enabling 3D scene understanding from readily available 2D data. The method, named ‘DINeMo’, uses a novel neural mesh model trained with no 3D annotations by leveraging pseudo-correspondence obtained from large visual foundation models, demonstrating superior performance over existing zero-shot and few-shot 3D pose estimation techniques.
Pseudo-Labels#
The research paper introduces an innovative approach using pseudo-labels to train a neural mesh model, eliminating the need for labor-intensive 3D annotations. The method leverages visual foundation models like DINOv2 to generate these labels. A bidirectional pseudo-correspondence generation technique is employed, considering both local appearance and global context for improved accuracy. This addresses the noisiness often associated with raw pseudo-labels. By matching neural features from SD-DINO and refining keypoint correspondences based on predicted global pose labels, the model achieves more consistent and reliable pseudo-labels for training. The use of pseudo-labels enables scaling to broader object categories and efficient training with unlabeled images.
Bidirectional#
The idea of a bidirectional approach is interesting, especially in the context of correspondence matching. It suggests a process that isn’t simply one-way, but rather incorporates information flowing in both directions to refine the results. For example, initially establishing coarse correspondences and then using higher-level contextual information to refine them, or vice versa, could lead to more robust and accurate matching. The bidirectional approach could allow for error correction, where inconsistencies detected in one direction can be resolved by information from the other direction. It may be useful for integrating local and global information or handling ambiguities in complex scenarios.
Visual Priors#
Visual priors play a crucial role in 3D scene understanding by guiding the inference of shape and pose. Models incorporating such priors demonstrate enhanced robustness, especially when dealing with partial occlusions or domain shifts. These priors, often learned from data, regularize the solution space, leading to more plausible and accurate estimates. By leveraging large pre-trained visual foundation models, one can generate pseudo-correspondence, eliminating the need for 3D annotations. Combining local appearance features with global context further refines these priors, improving overall consistency and performance.
Scalable Model#
Scalable models are critical in modern machine learning, particularly for tasks like 3D pose estimation where data annotation can be expensive and time-consuming. DINeMo addresses this by using pseudo-labels from visual foundation models, eliminating the need for direct 3D annotations. The effectiveness of DINeMo scaling with more unlabeled images is demonstrated through experiments, showing performance improvements as the training dataset grows. This is highly significant, as DINeMo overcomes the limitation of supervised approaches that require scarce 3D annotations. By effectively leveraging unlabeled data, DINeMo represents a step towards more practical and scalable 3D learning systems, reducing reliance on labor-intensive annotation processes. The design choices in DINeMo, such as the bidirectional correspondence generation, are pivotal in achieving this scalability by efficiently extracting meaningful information from readily available visual data.
More visual insights#
More on figures

🔼 Figure 2 illustrates the two-step bidirectional pseudo-correspondence generation process. The first step (Local-to-Global) generates raw pseudo-correspondences using features from SD-DINO and determines the 3D object orientation through majority voting. The second step (Global-to-Local) refines these correspondences by down-weighting matches of vertices invisible from the estimated 3D orientation. This process combines low-level local appearance features with high-level global context information for improved consistency and accuracy in keypoint correspondence.
read the caption
Figure 2: Bidirectional pseudo-correspondence generation. See Sec. 3.2.

🔼 This figure shows a qualitative comparison of keypoint pseudo-correspondence generation with and without the authors’ proposed bidirectional method. The bidirectional method uses both local appearance features and global context (3D object orientation) to improve the accuracy of the correspondence. The comparison highlights how the bidirectional approach significantly reduces mismatches and improves the overall quality of the generated correspondence, which is crucial for accurate 3D pose estimation.
read the caption
Figure 3: Qualitative comparisons with and without our bidirectional pseudo-correspondence generation. See Sec. 3.2.

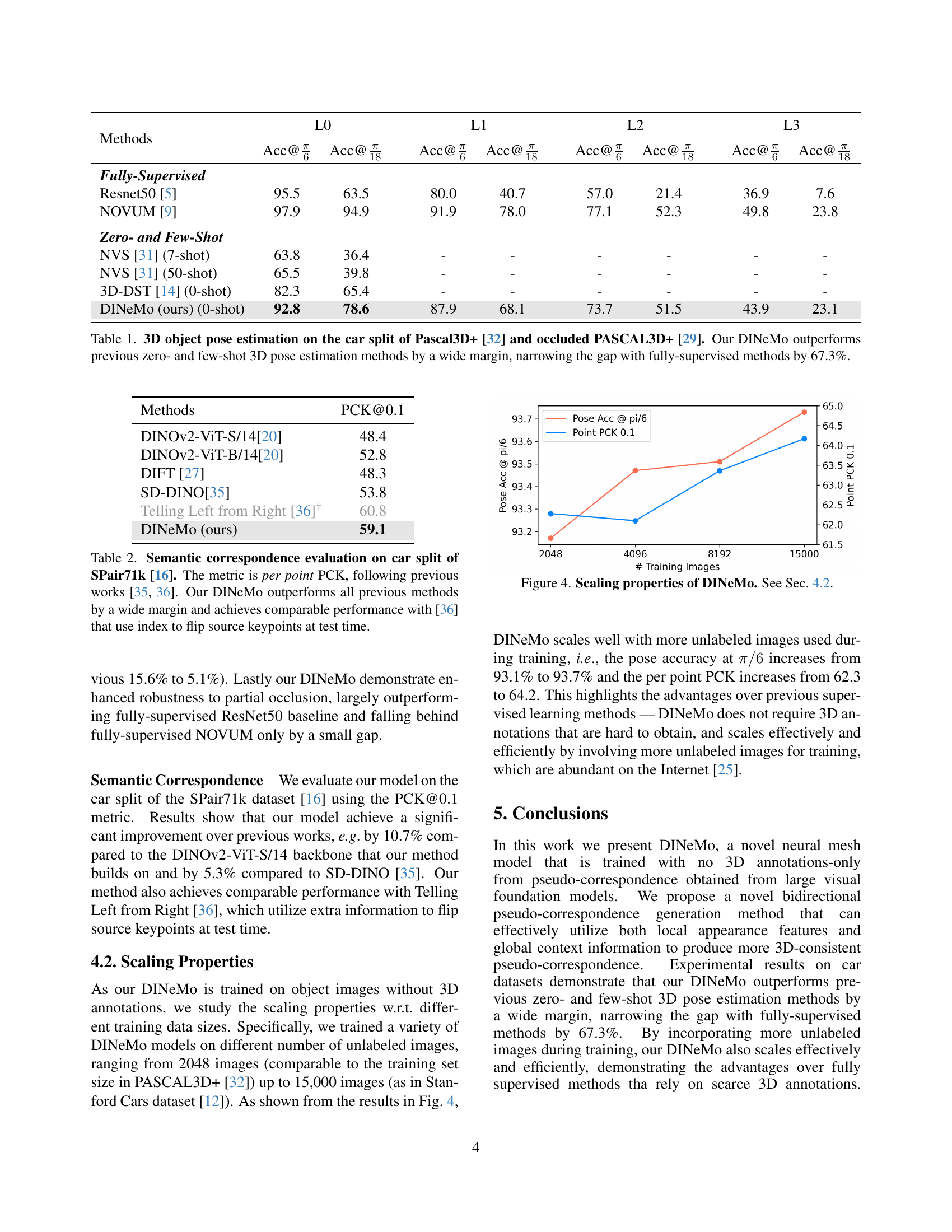
🔼 Figure 4 illustrates how the performance of the DINeMo model scales with the amount of unlabeled data used during training. The x-axis represents the number of training images, ranging from 2048 to 15000. The y-axis displays two key performance metrics: Pose Accuracy at π/6 (measuring the accuracy of pose estimation) and Point PCK@0.1 (measuring the accuracy of keypoint correspondence). The graph shows that as the number of training images increases, both metrics also improve, demonstrating DINeMo’s ability to efficiently leverage large-scale unlabeled data for improved performance.
read the caption
Figure 4: Scaling properties of DINeMo. See Sec. 4.2.

🔼 Figure 5 presents a qualitative comparison of the performance of DINOv2 and DINeMo on the SPair71k dataset. The images show examples of semantic correspondence generated by each method. Each row shows a pair of images, with the left image displaying the output from the DINOv2 model, and the right image showing the corresponding results from the DINeMo model. This visual comparison allows for a direct assessment of the relative strengths and weaknesses of the two models in terms of accuracy and robustness of semantic correspondence in images of cars with varying degrees of occlusion, viewpoint, and lighting conditions.
read the caption
Figure 5: Qualitative comparisons between DINOv2 (left) and our DINeMo (right) on the SPair71k[16] dataset.

🔼 Figure 6 presents a qualitative assessment of 3D pose estimation results obtained using the proposed DINeMo model. It showcases several examples of cars from the PASCAL3D+ dataset [32], with each example displaying both the input image and the estimated 3D mesh. The color-coded mesh allows for visualization of the estimated pose and shape of the vehicle, providing a visual representation of the model’s performance on diverse car instances within the dataset.
read the caption
Figure 6: Qualitative pose estimation results on the Pascal3D+[32] dataset.
Full paper#