TL;DR#
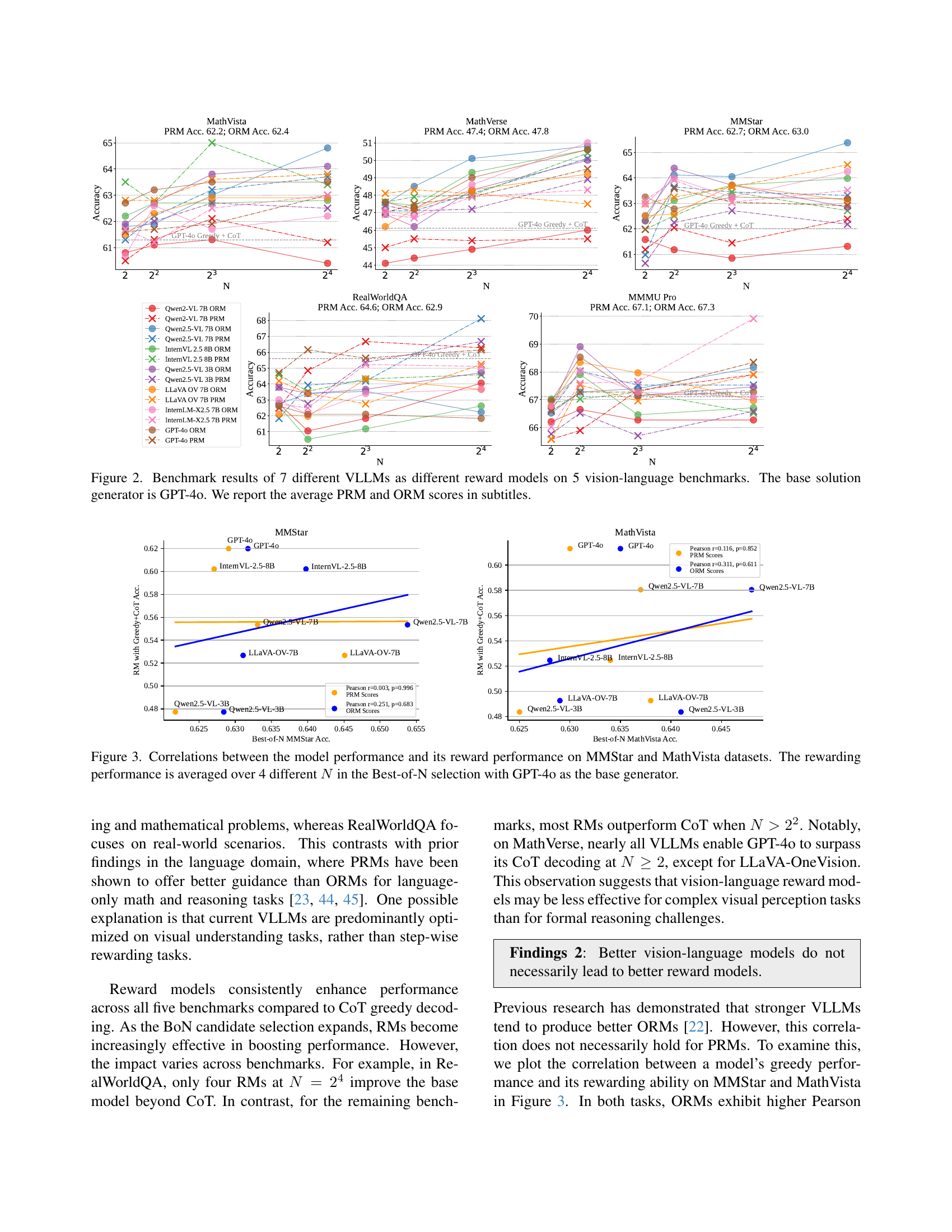
Process-supervised reward models offer detailed feedback to model responses, which is key for complex tasks. Despite advantages, PRM evaluation in multimodal contexts is lacking. The study benchmarks vision large language models as reward models, and finds no consistent outperformance across tasks. VLLMs do not inherently yield better rewarding performance. To address this, the paper introduces VILBENCH, a vision-language benchmark that requires process reward signals.
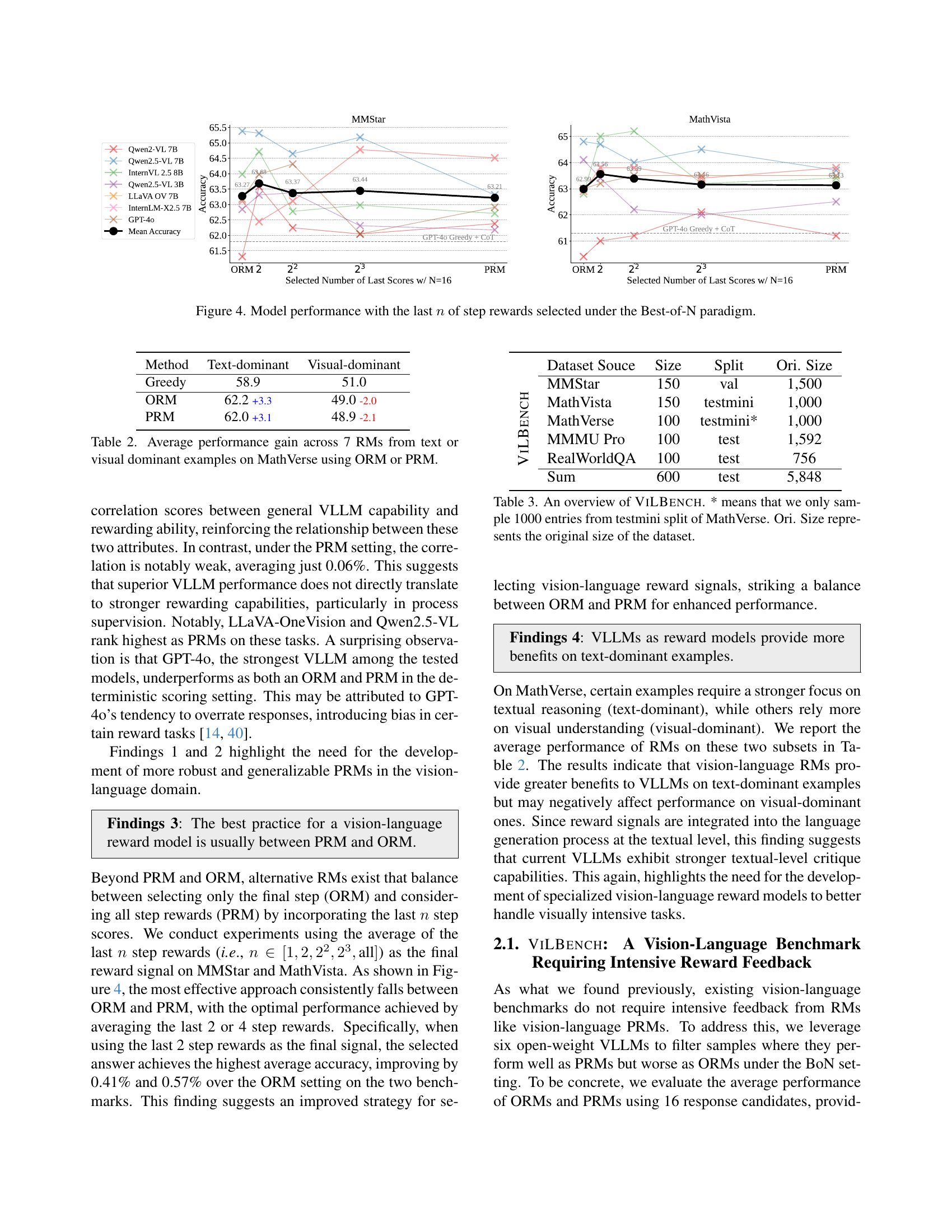
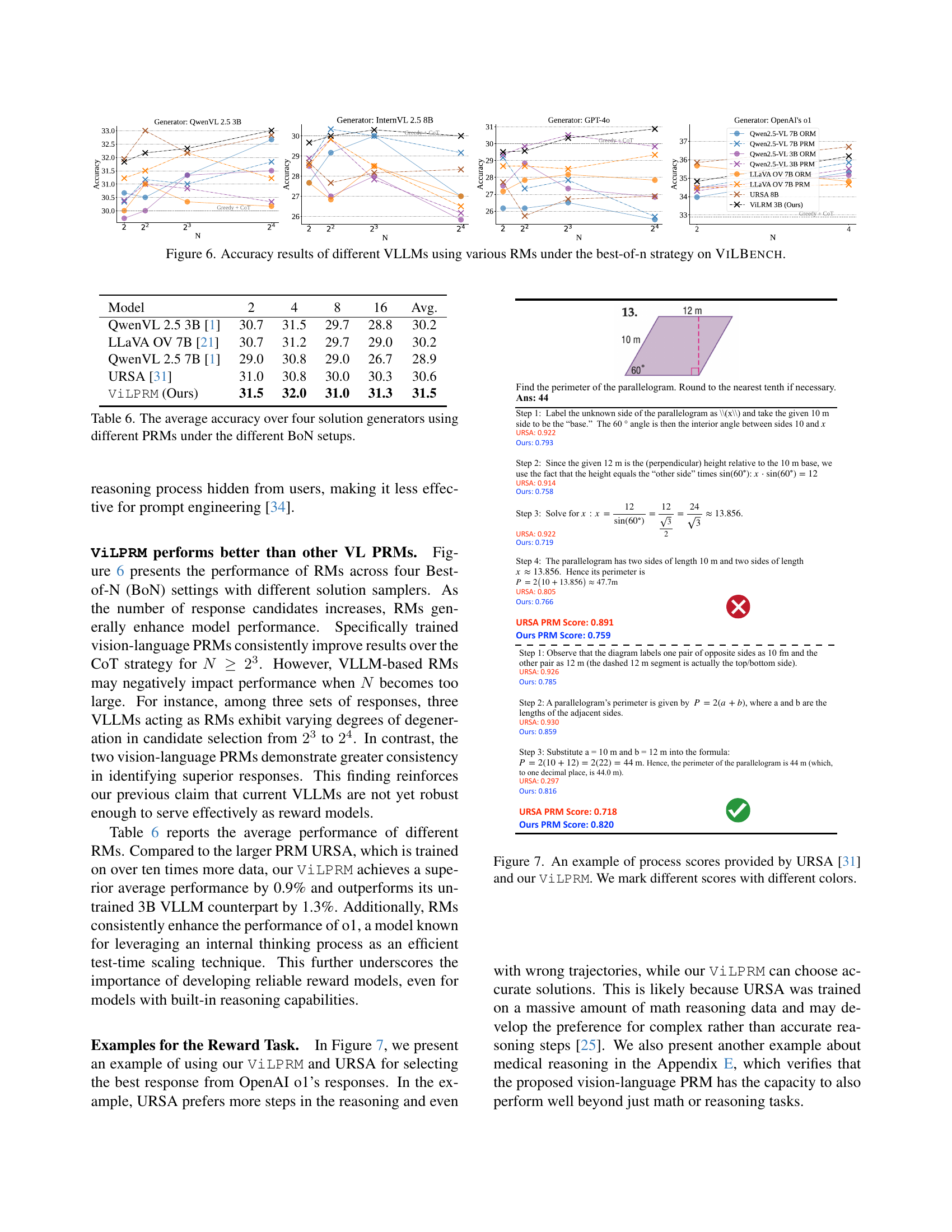
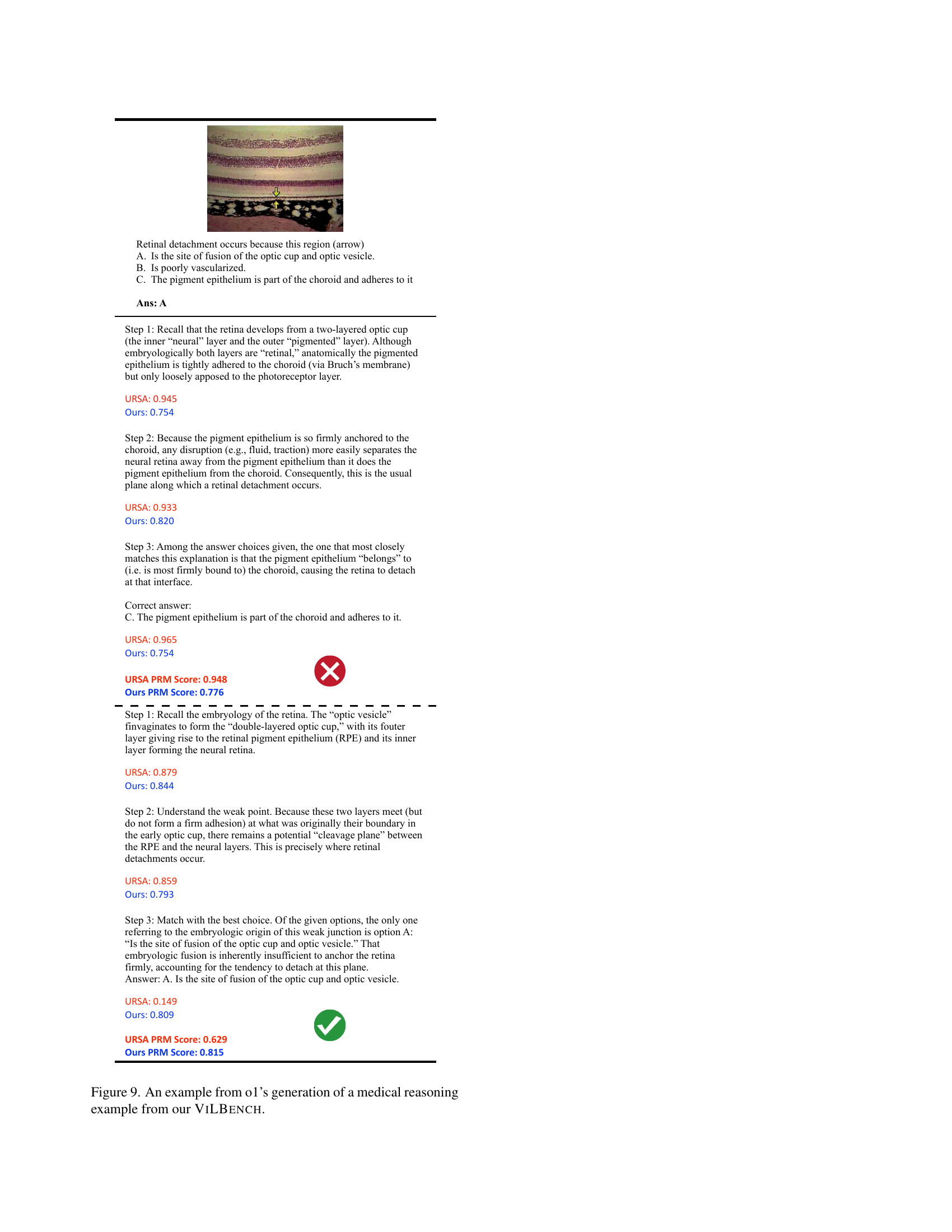
The paper also presents a vision-language PRM, ViLPRM, trained using 73.6K vision-language process reward data. MCTS enhances the PRM by using a tree-search algorithm. The PRM improves stepwise reward evaluation accuracy. The 3B model surpasses standard chain-of-thought approaches, improving by 3.3%, and outperforming its counterpart in VILBENCH by 2.5% when selecting OpenAI-generated solutions.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it reveals limitations of current vision-language models in process reward modeling. The work introduces a new benchmark, VILBENCH, to foster research in this area and provides a vision-language PRM, ViLPRM, as a promising direction for future exploration. By identifying the challenges and providing resources, the paper helps facilitate advances in multimodal AI.
Visual Insights#
🔼 This figure shows a Monte Carlo Tree Search (MCTS) tree used in constructing the ViLReward-73K dataset. The MCTS process explores different reasoning paths to solve geometry problems. Each node in the tree represents a step in the reasoning process, and the edges connect steps. One path in the MCTS tree leads to the correct solution, while other paths result in incorrect answers. The value associated with each node represents the estimated quality of that reasoning step. The ellipses indicate that some nodes in the original MCTS tree have been omitted for clarity.
read the caption
Figure 1: MCTS tree we have constructed for geometry problem datasets (e.g., MAVIS-Geometry). One path in the tree yields a correct result, while the remaining paths result in incorrect answers. It is worth noting that we use ellipses to omit some nodes in the original MCTS tree for better presentation.
Full paper#