TL;DR#
Recent advancements in Large Multimodal Models (LMMs) hold promise for Autonomous Driving Systems (ADS). However, direct application faces obstacles: traffic knowledge misunderstanding, complex road conditions, and diverse vehicle states. Knowledge Editing offers a solution, enabling targeted model behavior modifications without full retraining. This paper tackles these challenges to improve LMMs for ADS.
To address these shortcomings, the authors introduce ADS-Edit, a dataset designed for ADS knowledge editing. Encompassing real-world scenarios and diverse data types, it facilitates comprehensive evaluation. Experiments with knowledge editing baselines are done under single & lifelong editing scenarios. This work contributes to editing applications in autonomous driving.
Key Takeaways#
Why does it matter?#
This paper introduces ADS-Edit, a new multimodal knowledge editing dataset for autonomous driving. It provides a structured platform for researchers to enhance LMMs’ understanding and reasoning abilities. By addressing challenges, it paves the way for safer and more reliable autonomous systems and stimulate innovation in the field.
Visual Insights#

🔼 This figure illustrates the challenges of directly applying Large Multimodal Models (LMMs) to Autonomous Driving Systems (ADS). Three major issues are highlighted: 1) LMMs may misunderstand traffic rules and signage, leading to incorrect actions. 2) Real-world driving conditions are highly variable and complex, exceeding the scope of typical training data; therefore LMMs may not perform well in all situations. 3) Vehicles exhibit diverse states of motion, making accurate prediction difficult. The figure proposes Knowledge Editing as a solution to address these challenges by allowing for targeted, efficient, continuous, and precise updates to the model’s knowledge base without needing a complete re-training.
read the caption
Figure 1: Direct application of LMMs in Autonomous Driving Systems faces several challenges, including the misunderstanding of traffic knowledge, the complex and varied road conditions, and the diverse states of vehicle. Knowledge Editing that enables efficient, continuous, and precise updates to knowledge can effectively address these challenges.
| Video | Multi-view | Single | All | |
| Train | 1,926 | 960 | 1,093 | 3,979 |
| Test | 481 | 239 | 358 | 1,078 |
🔼 This table presents a summary of the data included in the ADS-Edit dataset. It breaks down the dataset by data type (video, multi-view images, and single images), showing the number of samples available for training and testing in each category. This allows readers to understand the scale and composition of the dataset used in the evaluation of knowledge editing methods for autonomous driving systems.
read the caption
Table 1: Statistical information of ADS-Edit data types and dataset splits for training and testing.
In-depth insights#
ADS Domain Edit#
ADS Domain Edit likely refers to the process of modifying a model’s knowledge specifically within the autonomous driving systems (ADS) domain. This could involve correcting misinformation, adding new information about traffic regulations, vehicle dynamics, or handling complex road conditions. The goal is to improve the model’s performance by directly editing its parameters or contextual understanding, without full retraining. This is valuable because full retraining is computationally expensive. Successful ADS domain editing facilitates rapid and precise updates to the model’s behavior, addressing key challenges like traffic rule misunderstanding, complex environmental awareness, and the ability to adapt to diverse vehicle states.
LMMs in Driving#
Large Multimodal Models (LMMs) are increasingly explored within autonomous driving, aiming to enhance perception, decision-making, and overall system robustness. Integrating LMMs offers potential advancements in handling complex, real-world driving scenarios by leveraging vast data for improved environment understanding. However, realizing this potential requires addressing key challenges like domain adaptation, real-time processing, and ensuring reliability and safety. Furthermore, existing models lack nuanced understanding and integration within autonomous systems which highlights the importance of new benchmarks and datasets specifically designed to evaluate and improve LMMs for autonomous driving. This paves the way for knowledge editing to modify the model’s behavior without complete retraining, reducing catastrophic forgetting and extensive resource costs.
Bench Tri-Axis#
The “Bench Tri-Axis” design principle for evaluating LMMs in ADS offers a structured approach. It helps to comprehensively assess model capabilities by categorizing evaluation requirements into distinct scenario types. It considers both the input data types (video, images) and the level of reasoning needed (perception, understanding, decision-making), thus addressing the challenges faced by LMMs such as traffic rule knowledge and diverse vehicle states. Such approach also ensures a well-rounded evaluation.
Locality Struggle#
Locality struggle in knowledge editing refers to the challenge of modifying a model’s behavior regarding specific facts or concepts without inadvertently affecting its performance on unrelated knowledge. Ideally, an edit should be highly targeted, altering only the parameters necessary to represent the new information while preserving the model’s existing competence across diverse domains. A significant issue arises when editing one aspect of knowledge negatively impacts another, potentially due to the distributed nature of information storage in neural networks. Effective knowledge editing requires a delicate balance between precision and preservation, ensuring that targeted modifications do not degrade the model’s overall functionality or introduce unintended side effects. Several methods are used to maintain locality, including modular architectures that confine edits to specific components, sparsity-inducing techniques to limit the scope of parameter changes, and regularization strategies that penalize deviations from the original model behavior. Evaluating locality requires comprehensive benchmarks that assess the model’s performance on a wide range of tasks, particularly those unrelated to the edited knowledge. Moreover, techniques that enhance interpretability can help to identify and mitigate potential locality issues by revealing how edits propagate through the network.
OOM Edit Decline#
Out-of-Memory (OOM) errors leading to edit decline signifies a critical challenge. When a knowledge editing method hits an OOM, it abruptly halts further updates, crippling its capacity for continual learning. It reveals that methods struggle to manage memory effectively. Specifically, longer multimodal inputs exacerbate memory issues, as codebooks are not good at distinct representation. This reveals a limitation when models must adapt to a constant stream of new information in complex, real-world scenarios, such as ADS. Thus, OOM acts as a bottleneck, preventing the system from refining its knowledge and adapting to the environment.
More visual insights#
More on figures

🔼 This figure shows a breakdown of the different scenario types included in the ADS-Edit dataset. The three main scenario types are: Perception (evaluating basic visual perception), Understanding (assessing comprehension of autonomous driving knowledge), and Decision Making (testing the ability to make informed driving decisions). The numbers represent the quantity of data samples belonging to each scenario type.
read the caption
Figure 2: The statistics of scenario types for ADS-Edit.

🔼 This figure illustrates the process of constructing the ADS-Edit dataset, which is a multimodal knowledge editing dataset specifically designed for autonomous driving systems. It begins by selecting three autonomous driving datasets as raw data sources: LingoQA, DriveLM, and CODA-LM. These datasets contain various types of visual data including videos, multi-view images, and single images, along with associated questions and answers. The raw data undergoes preprocessing steps, primarily condensing answers using the Deepseek-v3 model to improve editing performance and simplify evaluation. The processed data is then split into three subsets for reliability, generality, and locality evaluation. Each subset has additional steps to create targeted data that focuses on a particular evaluation aspect, such as rephrasing questions for generality testing. Finally, quality control is implemented through manual verification to ensure data accuracy.
read the caption
Figure 3: The overview of ADS-Edit construction pipeline.

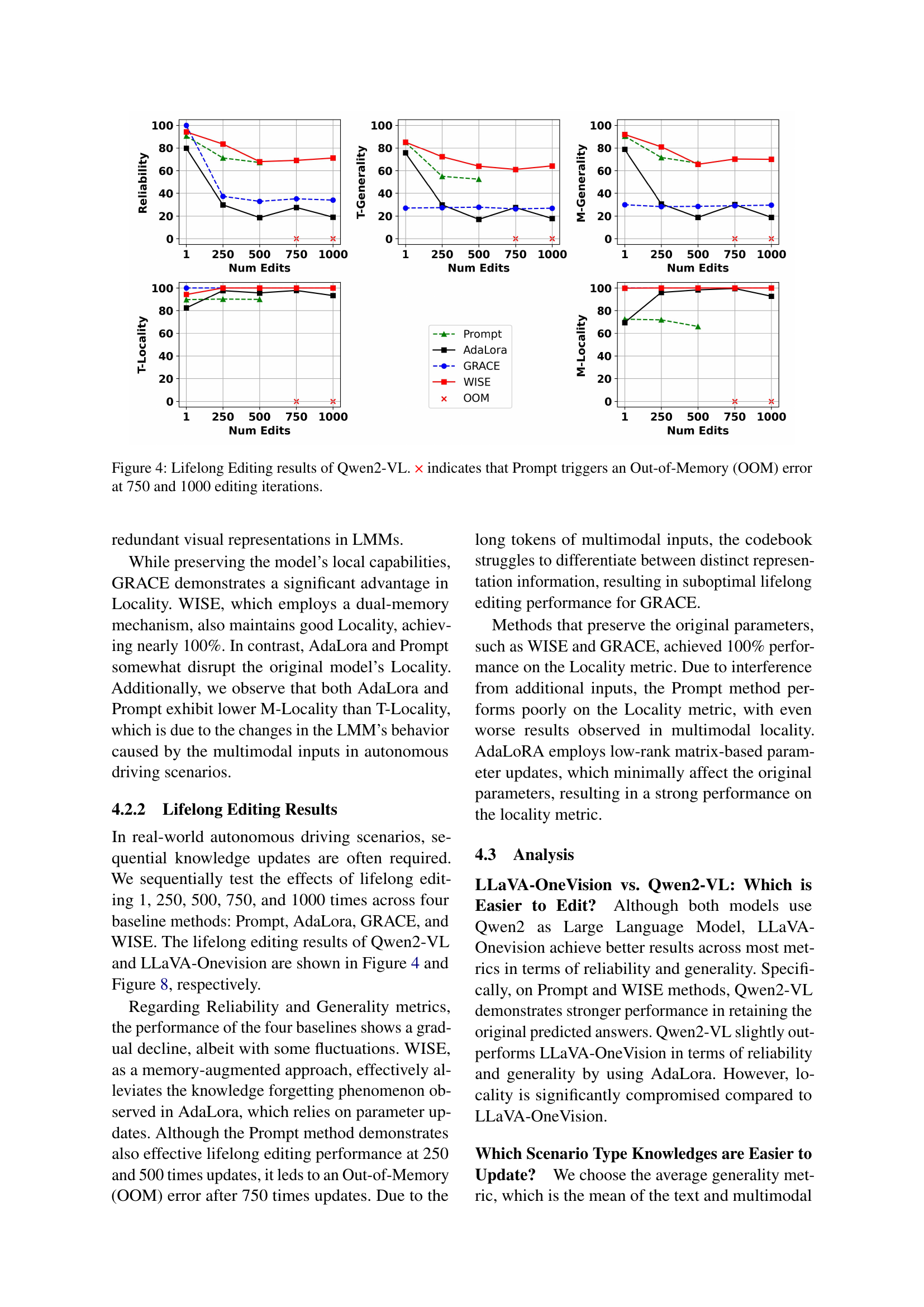
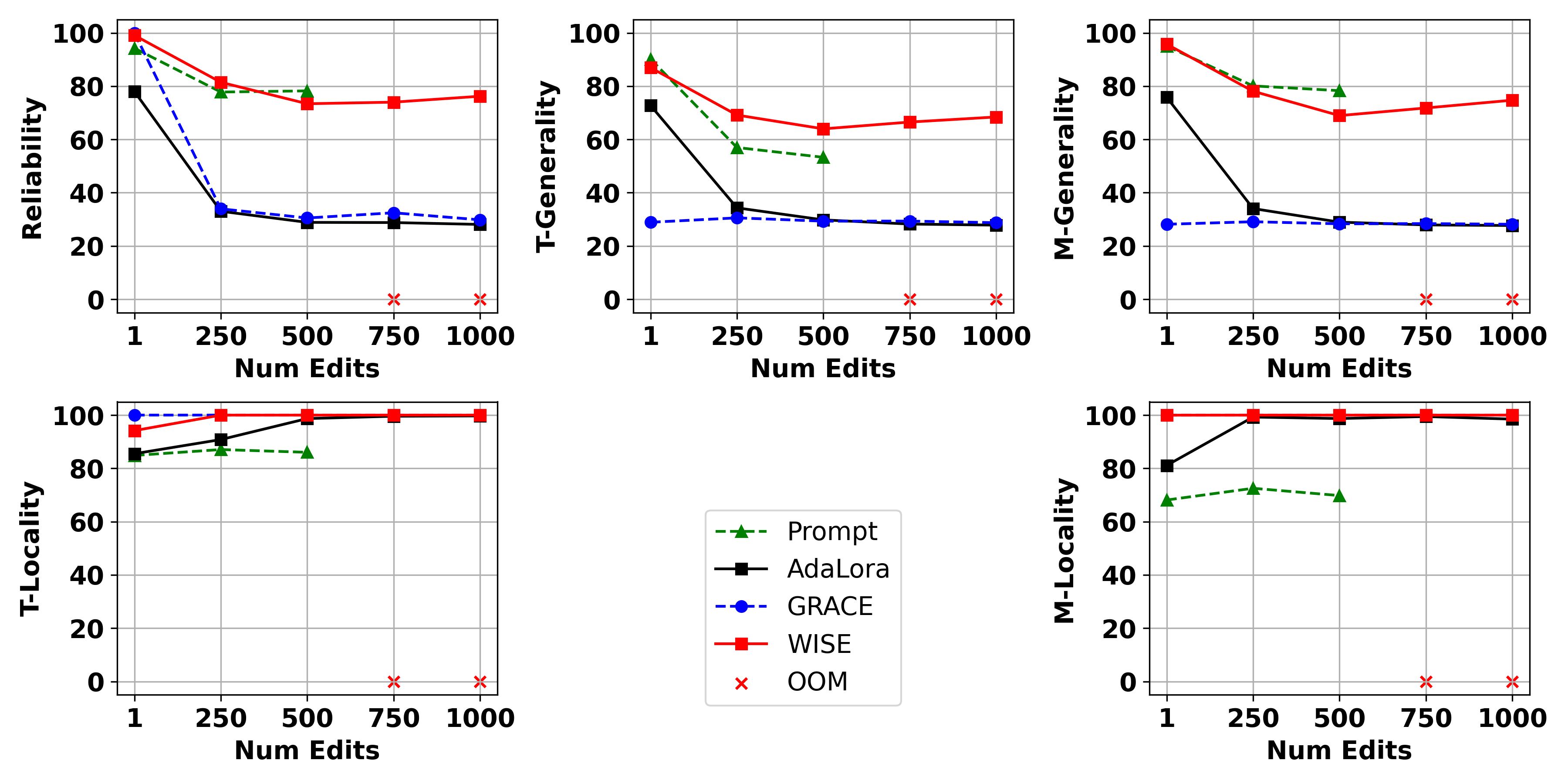
🔼 This figure displays the results of lifelong knowledge editing experiments using the Qwen2-VL language model. Four different knowledge editing methods (Prompt, AdaLora, GRACE, and WISE) were tested. The y-axis shows the performance metrics (Reliability, Generality, and Locality), and the x-axis represents the number of editing iterations. The figure shows how these metrics evolve as the model receives more and more edits, highlighting the effect of repeated knowledge updates. The ‘x’ symbol indicates that the Prompt method caused an out-of-memory error at 750 and 1000 iterations. This suggests that some methods are more computationally expensive than others for this type of task and model.
read the caption
Figure 4: Lifelong Editing results of Qwen2-VL. × indicates that Prompt triggers an Out-of-Memory (OOM) error at 750 and 1000 editing iterations.

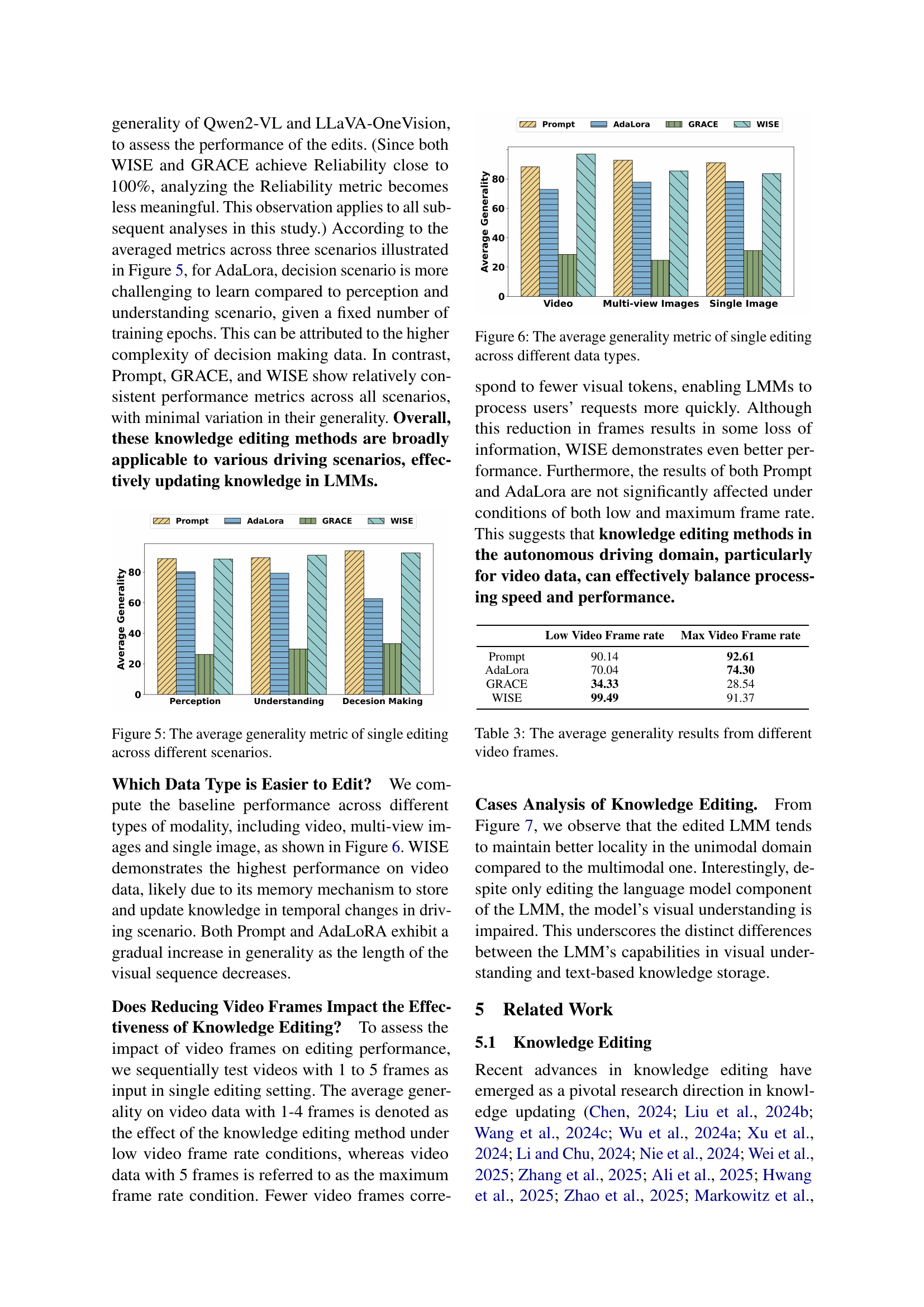
🔼 This figure displays the average generality scores achieved by different knowledge editing methods across three autonomous driving scenarios: perception, understanding, and decision-making. Generality measures how well a model generalizes its learned knowledge to new, similar situations after knowledge editing. The graph helps assess the effectiveness and robustness of each knowledge editing technique across various complexities of driving tasks.
read the caption
Figure 5: The average generality metric of single editing across different scenarios.

🔼 This figure shows the average generality scores achieved by different knowledge editing methods across three data types: video, multi-view images, and single images. Generality refers to how well a model generalizes its learned knowledge to new, unseen examples. The results illustrate the relative effectiveness of knowledge editing techniques on different data modalities in the context of autonomous driving.
read the caption
Figure 6: The average generality metric of single editing across different data types.

🔼 This figure provides a qualitative analysis of the WISE (Wang et al., 2024b) knowledge editing method applied to the LLaVA-OneVision model. It showcases three example scenarios highlighting successful knowledge editing in autonomous driving. The top row illustrates the editing of autonomous driving knowledge, where the model successfully incorporates the user’s instruction to adjust driving based on visibility conditions. The second and third rows show how WISE edits facts (material of umbrella) and context-dependent knowledge (location of keyboard shortcut), successfully preserving the pre-existing knowledge in these separate domains. However, it also highlights how WISE struggles to maintain local knowledge while updating other, related knowledge.
read the caption
Figure 7: Cases analysis of editing LLaVA-OneVision with WISE.
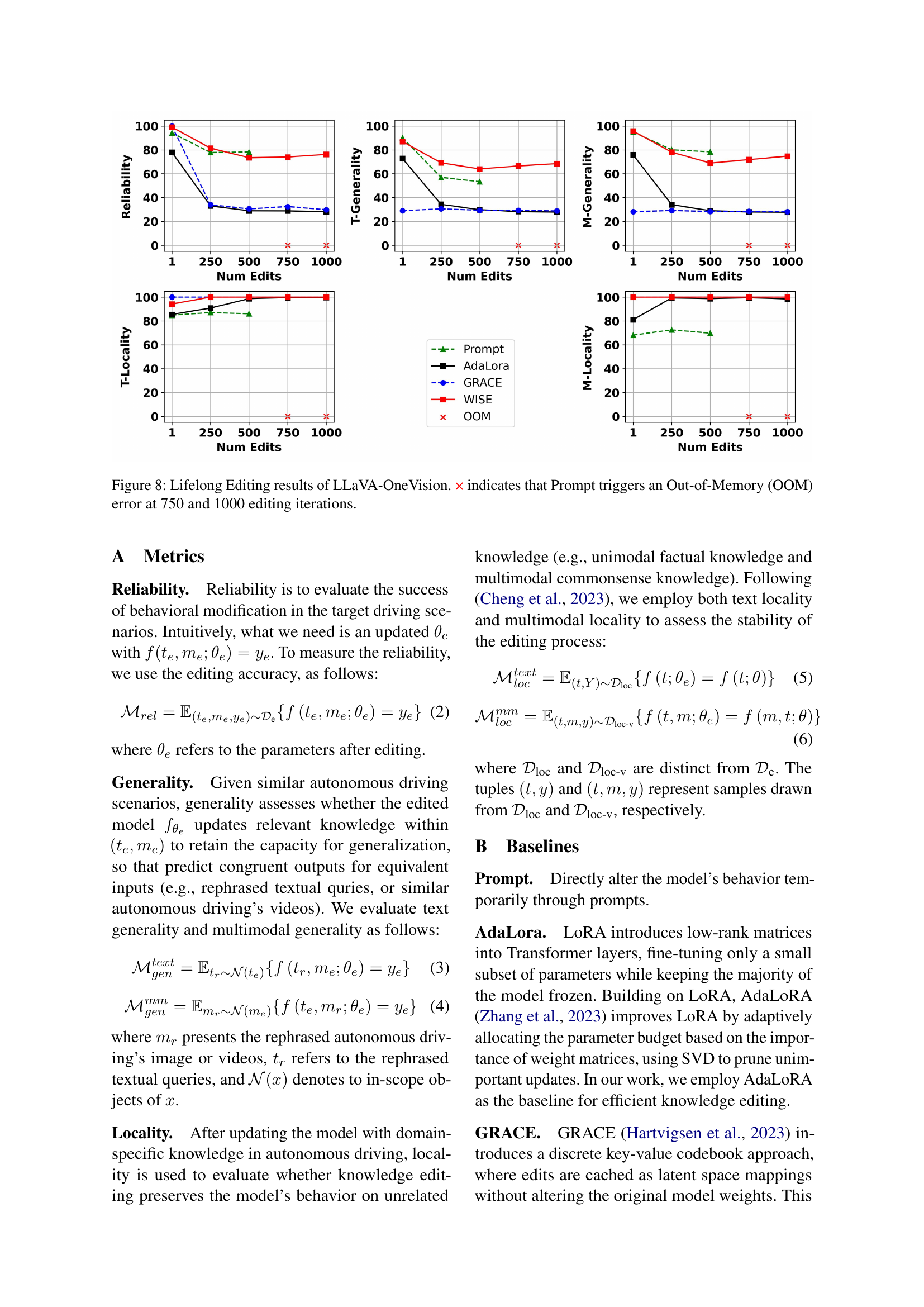
🔼 Figure 8 presents the results of lifelong knowledge editing on the LLaVA-OneVision model. Lifelong editing involves sequentially updating the model’s knowledge multiple times and evaluating its performance after each update. The figure displays the model’s performance on various metrics (Reliability, Generality, and Locality) across different numbers of editing iterations (1, 250, 500, 750, and 1000). The ‘Prompt’ method, a simple approach to knowledge editing, encountered Out-of-Memory (OOM) errors at 750 and 1000 iterations, indicating its limitation in handling numerous edits. The other methods (AdaLora, GRACE, and WISE) show varying degrees of success in maintaining good performance across the metrics, highlighting their robustness to sequential updates.
read the caption
Figure 8: Lifelong Editing results of LLaVA-OneVision. × indicates that Prompt triggers an Out-of-Memory (OOM) error at 750 and 1000 editing iterations.

🔼 This figure shows an example from the ADS-Edit benchmark dataset, specifically illustrating a video data case. It displays multiple modalities of data including a video clip, an original question about obstacle recognition, a rephrased version of the question, the ground truth answer, and even examples of unrelated questions and answers used to assess locality. The inclusion of these elements highlights the multimodal and multifaceted nature of the ADS-Edit dataset designed for knowledge editing tasks in autonomous driving.
read the caption
Figure 9: A video data case of ADS-Edit benchmark.

🔼 This figure shows an example from the ADS-Edit benchmark dataset, specifically showcasing a multi-view image scenario. It includes the original question, a rephrased version, the ground truth answer, and the answers generated by the model. The image data consists of multiple views of the same scene, to test the model’s ability to handle such data. It also includes examples of unrelated knowledge queries and answers to evaluate the model’s locality, meaning its ability to update knowledge without affecting unrelated information.
read the caption
Figure 10: A multi-views image data case of ADS-Edit benchmark.

🔼 This figure shows a sample from the ADS-Edit benchmark dataset, specifically demonstrating a single image data point. The example includes the data type, image type, source dataset, original question, rephrased question, answer, image, rephrased image, original ground truth, rephrased ground truth, and locality data (unrelated question and answer). This illustrates the structure and components of the multimodal knowledge editing dataset used for evaluating various model capabilities in autonomous driving scenarios.
read the caption
Figure 11: A single image data case of ADS-Edit benchmark.
More on tables
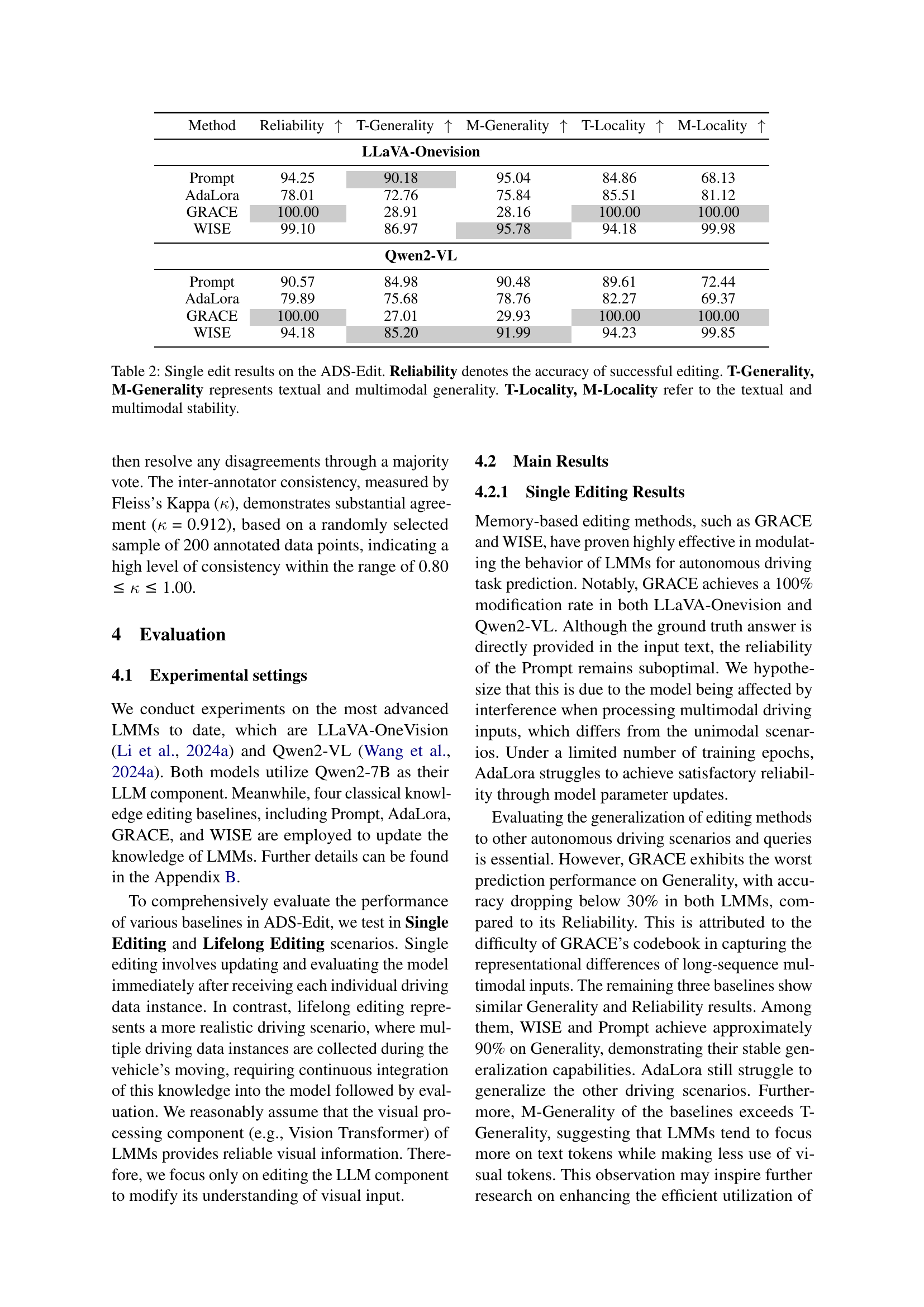
| Method | Reliability | T-Generality | M-Generality | T-Locality | M-Locality | |
| LLaVA-Onevision | ||||||
| Prompt | 94.25 | 90.18 | 95.04 | 84.86 | 68.13 | |
| AdaLora | 78.01 | 72.76 | 75.84 | 85.51 | 81.12 | |
| GRACE | 100.00 | 28.91 | 28.16 | 100.00 | 100.00 | |
| WISE | 99.10 | 86.97 | 95.78 | 94.18 | 99.98 | |
| Qwen2-VL | ||||||
| Prompt | 90.57 | 84.98 | 90.48 | 89.61 | 72.44 | |
| AdaLora | 79.89 | 75.68 | 78.76 | 82.27 | 69.37 | |
| GRACE | 100.00 | 27.01 | 29.93 | 100.00 | 100.00 | |
| WISE | 94.18 | 85.20 | 91.99 | 94.23 | 99.85 | |
🔼 This table presents the results of single knowledge editing experiments on the ADS-Edit dataset. The performance of four different knowledge editing methods (Prompt, AdaLora, GRACE, and WISE) is evaluated across two Large Multimodal Models (LLaVA-OneVision and Qwen2-VL). The results are broken down into five key metrics: Reliability (the accuracy of successfully editing the model’s behavior), Textual Generality (how well the edits generalize to similar textual queries), Multimodal Generality (how well the edits generalize to similar visual inputs), Textual Locality (how well the edits preserve the model’s behavior on unrelated textual knowledge), and Multimodal Locality (how well the edits preserve the model’s behavior on unrelated visual knowledge). Higher scores indicate better performance.
read the caption
Table 2: Single edit results on the ADS-Edit. Reliability denotes the accuracy of successful editing. T-Generality, M-Generality represents textual and multimodal generality. T-Locality, M-Locality refer to the textual and multimodal stability.
| Low Video Frame rate | Max Video Frame rate | |
| Prompt | 90.14 | 92.61 |
| AdaLora | 70.04 | 74.30 |
| GRACE | 34.33 | 28.54 |
| WISE | 99.49 | 91.37 |
🔼 This table presents the average generality scores achieved by four different knowledge editing methods (Prompt, AdaLora, GRACE, and WISE) across various video frame rates in the context of autonomous driving. The results show how well each method generalizes its knowledge to unseen data with varying degrees of temporal information (number of frames). Lower frame rates represent less temporal information and potentially reduce the effectiveness of some editing methods.
read the caption
Table 3: The average generality results from different video frames.
Full paper#