TL;DR#
Small language models often struggle with knowledge-intensive tasks due to their limited capacity. Retrieval-Augmented Generation (RAG) can help by providing external knowledge, but small LMs struggle with query formulation and content comprehension, resulting in vague queries and misinterpreted details. Existing RAG systems also lack dynamic adjustment of retrieval strategies, leading to unnecessary or repetitive steps. Conventional Monte Carlo Tree Search depends on internal model knowledge.
MCTS-RAG addresses these issues by integrating MCTS’s reasoning with adaptive retrieval mechanisms. It iteratively refines both retrieval and reasoning through a search-based process, dynamically incorporating retrieval actions at key decision points. Retrieved knowledge evaluates intermediate states, reinforcing beneficial retrieval pathways through backpropagation. This structured search ensures efficient acquisition and utilization of relevant information for accurate reasoning.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework that boosts the reasoning capabilities of small language models by integrating MCTS with adaptive retrieval, which can significantly enhance their performance on knowledge-intensive tasks. It opens up new research directions in scaling inference-time compute to improve the reasoning of small-scale models.
Visual Insights#

🔼 This figure illustrates the step-by-step process of the MCTS-RAG framework in answering a complex question from the ComplexWebQA dataset. It showcases how MCTS-RAG dynamically integrates retrieval and reasoning through an iterative decision-making process. The figure visually depicts the different actions within the MCTS-RAG workflow, including direct answering, quick reasoning, question decomposition, retrieval reasoning, and answer summarization. Each step involves refining both retrieval and reasoning, ultimately converging to a final answer. The example question is displayed, along with the decision tree and intermediate steps taken.
read the caption
Figure 1: An illustration of MCTS-RAG workflow for answering the question sampled from ComplexWebQA.
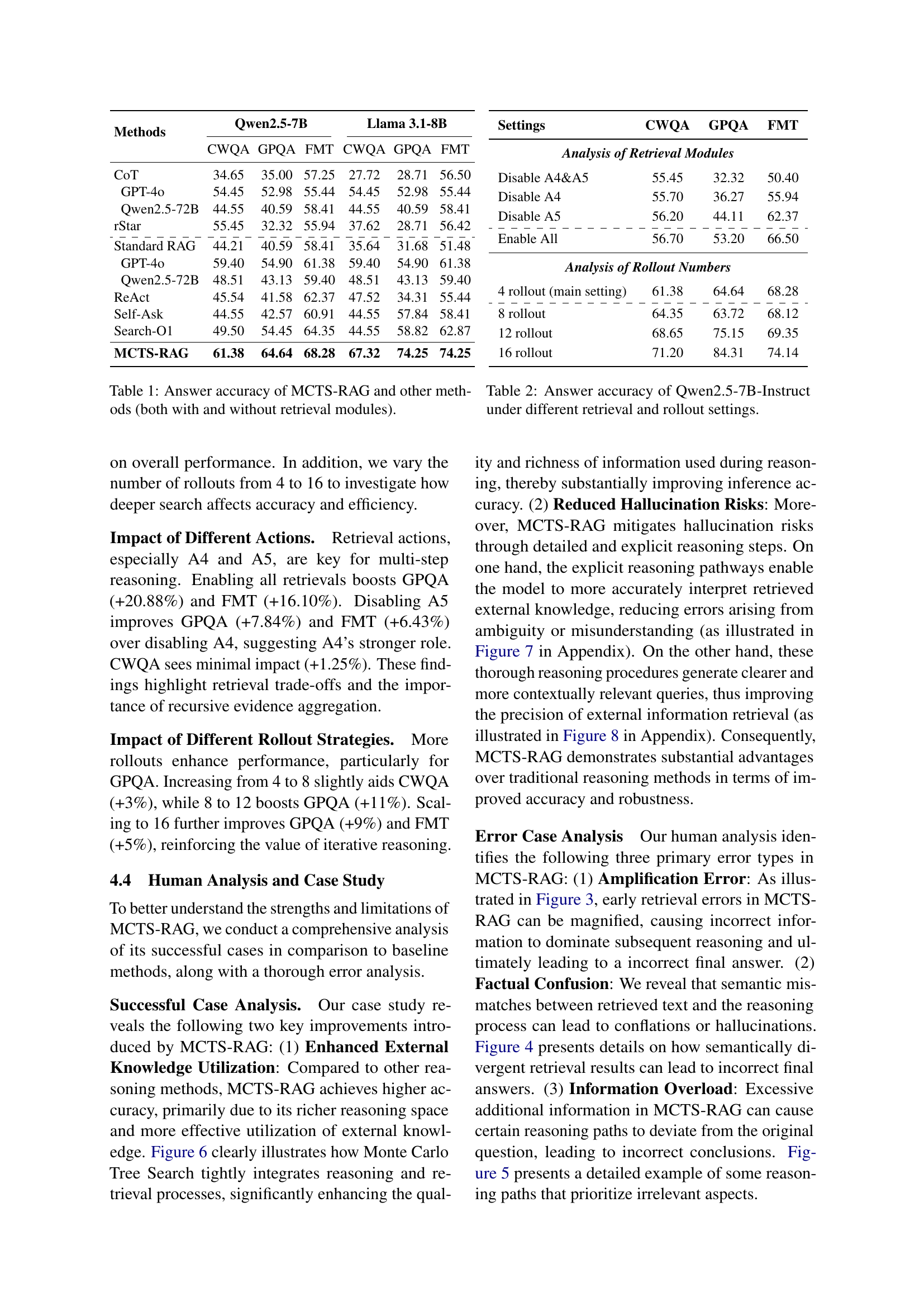
| Methods | Qwen2.5-7B | Llama 3.1-8B | ||||
|---|---|---|---|---|---|---|
| CWQA | GPQA | FMT | CWQA | GPQA | FMT | |
| CoT | 34.65 | 35.00 | 57.25 | 27.72 | 28.71 | 56.50 |
| GPT-4o | 54.45 | 52.98 | 55.44 | 54.45 | 52.98 | 55.44 |
| Qwen2.5-72B | 44.55 | 40.59 | 58.41 | 44.55 | 40.59 | 58.41 |
| rStar | 55.45 | 32.32 | 55.94 | 37.62 | 28.71 | 56.42 |
| \hdashline Standard RAG | 44.21 | 40.59 | 58.41 | 35.64 | 31.68 | 51.48 |
| GPT-4o | 59.40 | 54.90 | 61.38 | 59.40 | 54.90 | 61.38 |
| Qwen2.5-72B | 48.51 | 43.13 | 59.40 | 48.51 | 43.13 | 59.40 |
| ReAct | 45.54 | 41.58 | 62.37 | 47.52 | 34.31 | 55.44 |
| Self-Ask | 44.55 | 42.57 | 60.91 | 44.55 | 57.84 | 58.41 |
| Search-O1 | 49.50 | 54.45 | 64.35 | 44.55 | 58.82 | 62.87 |
| MCTS-RAG | 61.38 | 64.64 | 68.28 | 67.32 | 74.25 | 74.25 |
🔼 This table presents a comparison of the accuracy of different methods, including MCTS-RAG and several baselines, on three benchmark datasets (Complex WebQA, GPQA, and FoolMeTwice). It shows the performance of each method with and without retrieval modules enabled. The results highlight the effectiveness of MCTS-RAG in improving the accuracy of small-scale language models on knowledge-intensive reasoning tasks.
read the caption
Table 1: Answer accuracy of MCTS-RAG and other methods (both with and without retrieval modules).
In-depth insights#
MCTS-RAG Intro#
MCTS-RAG marks a significant evolution in reasoning for small language models. It addresses the limitations of standard Retrieval-Augmented Generation (RAG), which often struggles with query formulation and content comprehension in small LMs, leading to suboptimal knowledge integration and potential for repetitive retrieval steps. MCTS-RAG also contrasts with conventional Monte Carlo Tree Search (MCTS) reasoning, which relies heavily on internal knowledge and may not be effective for knowledge-intensive tasks. MCTS-RAG innovatively integrates MCTS’s structured search with adaptive retrieval, enabling dynamic integration of retrieval and reasoning through iterative decision-making. This approach enhances decision-making, reduces hallucinations, and improves factual accuracy and response consistency. By exploring multiple reasoning paths and incorporating retrieval actions at key points, MCTS-RAG aims to improve the performance of small LMs on complex reasoning tasks, enabling them to compete with larger models by scaling inference-time compute.
Adaptive Retrieval#
Adaptive retrieval is crucial for enhancing the performance of retrieval-augmented generation (RAG) systems, especially when dealing with knowledge-intensive tasks. It moves beyond static retrieval approaches, dynamically adjusting retrieval strategies based on the evolving informational needs and reasoning states. This adaptability involves several key aspects, including iterative query refinement, where initial queries are refined based on retrieved information, and context-aware retrieval, where the retrieval process considers the current reasoning context and identifies the most relevant information. Moreover, adaptive retrieval reduces unnecessary or repetitive retrieval steps by monitoring how the model is progressing in its reasoning process. Adaptive retrieval can significantly enhance factual accuracy and response consistency while addressing semantic discrepancies. It also allows the model to acquire and utilize relevant information in a more efficient manner. This tailored approach to retrieval ensures that the model is equipped with the necessary information to navigate complex problems effectively.
Fine-Grained Eval#
A “Fine-Grained Eval” section in a research paper, though not explicitly present in the provided text, would typically involve a detailed analysis of the model’s performance beyond overall accuracy. It might delve into specific error types, assessing performance on different subsets of the data (e.g., based on question complexity or domain knowledge required). Ablation studies, as mentioned, would be crucial here, isolating the impact of different components (e.g., retrieval modules) on specific error categories. Analyzing the effect of varying the number of MCTS rollouts could reveal the trade-off between computational cost and performance on different types of reasoning tasks. Such an evaluation would aim to uncover the model’s strengths and weaknesses, providing actionable insights for improvement by pointing to which modules most help with what task. Error analysis, potentially including human analysis of failure cases, could identify systematic biases or limitations in the model’s reasoning or retrieval capabilities. Overall, it seeks to look at performance differences in a step-wise fashion.
Halucination Risk#
Hallucination risk, a prevalent issue in retrieval-augmented generation (RAG) systems, stems from several factors. One key aspect is the potential for retrieval errors, where the system fetches irrelevant or misleading information. This can then be amplified in the subsequent reasoning steps, leading to inaccurate conclusions. Furthermore, semantic mismatches between the retrieved text and the reasoning process can cause confusion, resulting in conflations or hallucinations. Another contributing factor is information overload, where excessive additional data can cause certain reasoning paths to deviate from the original question, ultimately leading to incorrect conclusions. Mitigating hallucination risks requires strategies such as detailed reasoning steps, clearer queries, and a focus on external knowledge utilization to ensure accuracy and robustness.
Future Dynamics#
When considering ‘Future Dynamics’ in the context of an AI research paper, several key areas warrant attention. One crucial aspect is the evolution of the model’s architecture. As datasets grow and computational resources expand, there’s potential to scale the model or incorporate novel architectural elements like attention mechanisms or transformers for enhanced performance. Furthermore, the integration of multimodal data such as images, audio, or video, could enrich the model’s understanding and broaden its applicability. Adaptive learning rates, and innovative loss functions are also key for future advancements in the AI space. We could also delve into transfer learning by adapting the AI model to related tasks or domains. Finally, ethical considerations and fairness become increasingly important as the model is deployed in real-world scenarios.
More visual insights#
More on figures

🔼 This figure illustrates the four steps involved in MCTS-RAG’s adaptive retrieval process: (R1) Query Generation, where the model identifies a knowledge gap and formulates a query; (R2) Query Execution, where external knowledge sources are consulted; (R3) Knowledge Reflection, where the retrieved information’s relevance and consistency are evaluated; and (R4) Summary Reasoning, where the retrieved information is integrated into the model’s reasoning process to answer a sub-question. This adaptive process is shown within a single step of the ‘retrieval decomposition’ action (detailed in Figure 1), emphasizing the dynamic interaction between reasoning and information retrieval in MCTS-RAG.
read the caption
Figure 2: An illustration of MCTS-RAG retrieval process (i.e., R1-R4) within one step of the retrieval decomposition action highlighted in Figure 2.

🔼 The figure illustrates how errors in the early stages of the Monte Carlo Tree Search (MCTS) process can be amplified as the search progresses. Minor inaccuracies in initial retrievals compound through subsequent iterations, leading to a final answer that strongly favors incorrect reasoning paths, even if more accurate options exist.
read the caption
Figure 3: An illustration of MCTS Amplification Error. Early MCTS retrieval errors amplify mistakes, leading to a final answer favoring incorrect paths.
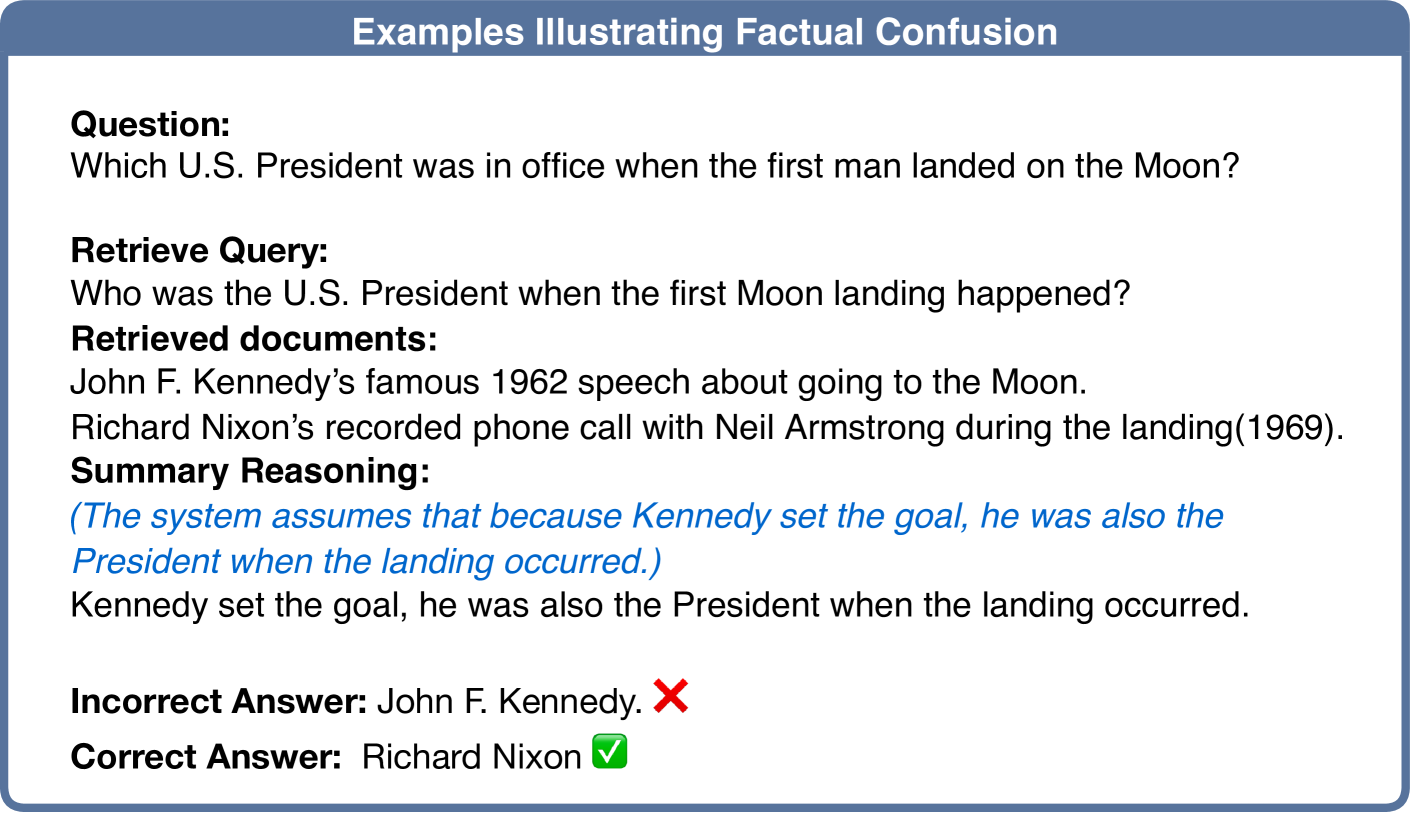
🔼 This figure illustrates a case where the model incorrectly identifies John F. Kennedy as the U.S. president during the moon landing due to a misunderstanding of the timeline. The model confuses the setting of the goal to land on the moon (Kennedy’s presidency) with the actual event of the landing (Nixon’s presidency). This showcases how a flawed understanding of the relationship between the project’s initiation and its completion leads to factually inaccurate results.
read the caption
Figure 4: An illustration of Factual Confusion. Wrong understanding of the relationship between project launch and moon landing, leading to wrong answers.

🔼 Figure 5 demonstrates a failure case in the MCTS-RAG model due to information overload. The question is simple: what is the capital of the country with the longest coastline? The model correctly retrieves information identifying Canada as having the longest coastline, but focuses excessively on the length of the coastline (202,080 km) to the point of answering that length instead of the actual capital city, Ottawa. This highlights the challenge of managing information retrieval in complex reasoning tasks where an abundance of relevant but not directly answer-related information can lead to incorrect responses. The model’s reasoning process is disrupted by the excessive detail surrounding the coastline length, overshadowing the core question of the capital city.
read the caption
Figure 5: An illustration of Information Overload. Too much coastline information, resulting in the model answering the coastline length instead of the capital city.

🔼 This figure illustrates the MCTS-RAG workflow for a sample Complex WebQA question. It visually demonstrates the iterative decision-making process where the system explores multiple reasoning paths. Each path involves actions such as providing a direct answer, performing quick reasoning, decomposing the question into sub-questions, and performing retrieval reasoning. The system dynamically integrates retrieval actions at key decision points, acquiring relevant external knowledge to evaluate intermediate states and guide the search process toward beneficial retrieval and reasoning pathways. The figure shows how the various action types, A1-A6, are employed and integrated within the MCTS search tree. The final answer is selected based on the consensus of these paths.
read the caption
Figure 6: Illustration of how MCTS-RAG achieves a rich reasoning space and tightly integrates reasoning with retrieval.
🔼 Figure 7 demonstrates the effectiveness of the MCTS-RAG framework in mitigating retrieval-induced hallucinations and improving accuracy. The example shows how MCTS-RAG’s multi-step reasoning process allows it to refine its understanding and ultimately reach the correct answer, even after initially retrieving potentially misleading information. The iterative refinement, facilitated by both reasoning and further retrieval, allows the model to avoid errors introduced by inaccurate or incomplete knowledge from the initial retrieval step.
read the caption
Figure 7: Illustration of the effectiveness of MCTS-RAG. How further reasoning reduces retrieval-introduced hallucinations and improves accuracy.

🔼 Figure 8 demonstrates MCTS-RAG’s superior performance compared to standard RAG approaches. The example shows how MCTS-RAG’s structured reasoning process leads to more precise retrieval queries. This results in more accurate and relevant information being integrated into the model’s answer generation, ultimately reducing errors and improving overall accuracy. Unlike standard RAG, which may make assumptions or hallucinate, MCTS-RAG’s iterative refinement ensures a more reliable and evidence-based response.
read the caption
Figure 8: An illustration of the effectiveness of MCTS-RAG. Based on a clear chain of reasoning, it can generate higher quality retrieval queries and final answers, reduce hallucinations and improve accuracy.

🔼 Figure 9 shows an example where a standard Retrieval-Augmented Generation (RAG) model fails to accurately answer a question about the number of products resulting from a chemical reaction. The model’s reasoning process is unclear and lacks the detailed steps necessary to arrive at the correct answer. The model’s response indicates it only considered the possibilities for the reaction superficially, leading to an incorrect answer of 3, while the actual correct answer is 6. This highlights a key limitation of standard RAG: its inability to perform thorough, multi-step reasoning without additional mechanisms to enhance its reasoning capabilities.
read the caption
Figure 9: An illustration of standard RAG. Because the reasoning process is not clear enough, the final answer to the question is an illusion and the answer is wrong.
Full paper#