TL;DR#
Video generation models struggle with physical fidelity, limiting their use in applications demanding realistic physics. Using synthetic videos addresses this gap. These videos, rendered via computer graphics, inherently respect real-world physics, such as 3D consistency. The study investigates how integrating such synthetic data enhances physical fidelity, focusing on human motion, camera rotation, and layer decomposition.
The solution involves curating and integrating synthetic data. At the data level, the study constructs a synthetic video pipeline offering diverse assets and animations. To mitigate rendering artifacts, they propose SimDrop, training a reference model to capture visual patterns of synthetic data. Experiments show significant improvements in reducing collapse in human motion and enhancing 3D consistency under camera movements.
Key Takeaways#
Why does it matter?#
This study pioneers a novel data-centric strategy for enhancing video generation by integrating synthetic data. It paves the way for future investigations into how synthetic data can address the challenge of physical fidelity and can potentially shift the focus towards data engineering.
Visual Insights#

🔼 Figure 1 showcases the capabilities of a novel video generation model enhanced with synthetic data. The figure presents three rows of video examples, each demonstrating a different aspect of the model’s capabilities. Row 1 displays videos of humans dancing, highlighting the model’s ability to generate realistic human motion. Row 2 shows scenes with a large camera orbiting around an object, demonstrating the model’s capacity to handle complex camera movements while maintaining 3D consistency. Row 3 features examples of animals against solid-color backgrounds, showcasing the model’s performance on the challenging task of video matting, preparing the generated videos for seamless integration with other footage or backgrounds.
read the caption
Figure 1: Our synthetic-data-enhanced video generation model is capable of producing videos depicting human dancing (rows 1), scenes featuring large camera orbiting around the object (row 2), and animals against solid-color backgrounds for matting (row 3).
| Training Data | Human Motion Collapse Rate |
| (a) Random | 87% |
| (b) Forward shot only | 42% |
| (c) Forward + following shot | 23% |
🔼 This table presents the results of an experiment evaluating the impact of different camera configurations on the success rate of video generation. The experiment tested three different setups: (a) randomly chosen camera configurations, (b) camera configurations only using forward shots, and (c) camera configurations using both forward and following shots. The table shows that the success rate is significantly higher when camera configurations align with how cameras are typically used in real-world scenarios. The high failure rate with random and forward-only setups highlights the importance of using real-world camera techniques for successful video generation.
read the caption
Table 1: Randomly chosen camera configurations (a-b) lead to high collapse rate for generated videos. Using configuration (c) aligning with the real world greatly reduce the rate.
In-depth insights#
Synthetic Data++#
While ‘Synthetic Data++’ isn’t present, I can discuss its implications. It suggests a leap beyond basic synthetic data, implying enhanced realism, diversity, and control. This could involve advanced rendering techniques to bridge the reality gap, procedural generation for vast datasets, and AI-driven refinement to mimic real-world complexities. Key benefits include addressing data scarcity, enabling precise control over data distribution, and mitigating privacy concerns. Challenges involve ensuring the synthetic data truly reflects target scenarios, avoiding bias amplification, and validating the models trained with such data. The “++” signifies a concerted effort to overcome limitations of earlier synthetic data approaches. Such advancement could fuel progress in diverse fields where data is a bottleneck.
Physics via CGI#
The notion of “Physics via CGI” suggests leveraging computer-generated imagery (CGI) to understand and replicate physical phenomena. This approach offers several advantages, including precise control over experimental conditions, the ability to visualize complex systems, and the potential to generate vast datasets for training AI models. CGI enables the creation of simulated environments where physical laws can be explicitly defined and manipulated, allowing researchers to test hypotheses and explore scenarios that would be impossible or impractical in the real world. Furthermore, CGI can visualize intricate physical processes, such as fluid dynamics or electromagnetic fields, providing valuable insights into their behavior. The realism of CGI-based simulations is crucial for their effectiveness, requiring accurate modeling of materials, lighting, and interactions. Moreover, the computational cost of high-fidelity simulations can be significant, necessitating efficient algorithms and hardware. The rise of AI and machine learning offers new opportunities for using CGI in physics research, with simulated datasets serving as training data for models that can predict physical phenomena or optimize experimental designs.
SimDrop Strategy#
The SimDrop strategy appears to be a method designed to mitigate the introduction of unwanted artifacts during the training of video generation models using synthetic data. It leverages the concept of classifier-free guidance to steer the generation process towards the overlapping distribution of real and synthetic videos. A reference model, trained specifically on synthetic data but with captions that omit the desired aspects (e.g., human motion), is used to capture unique patterns and artifacts associated with the rendering engine. This reference model then works in tandem with the main generation model to remove visual artifacts while preserving physical fidelity during the inference stage, allowing the model to generate high quality videos. It helps the model to distinguish the specific characteristics of synthetic data and real data, resulting to generating realistic outputs. By training a synthetic reference model and properly guiding the synthetic and the real model can improve the performance.
CGI Data Key#
While the provided document doesn’t explicitly mention a heading titled ‘CGI Data Key,’ we can infer its relevance based on the paper’s content, which emphasizes leveraging synthetically generated video to enhance physical fidelity in video synthesis models. The ‘CGI Data Key’, in this context, represents the critical elements and strategies for creating and utilizing synthetic data effectively. This includes aspects like diverse scene configurations, asset selection (high-quality 3D assets), animation, camera movements, varied environments and illumination. Also, it is significant to capture the essence of data curation and integration. Further, the key also is in the proper blending with its real counterparts.
More Physics?#
The notion of ‘More Physics?’ in video synthesis implies a need to go beyond mere visual plausibility. Current models often generate visually appealing content but fail to adhere to fundamental physical laws, such as object permanence, consistent 3D structure, and realistic dynamics. Future research could explore incorporating explicit physical simulation or leveraging physics engines during the training process. This could involve training models to predict physical properties or constraints, or using simulations to generate training data that inherently respects physical laws. Integrating modalities beyond RGB, like depth or normals, could also provide valuable cues for physics-aware synthesis. Ultimately, achieving true ‘More Physics?’ means building models that generate not just visually convincing videos, but physically plausible and consistent ones.
More visual insights#
More on figures

🔼 This figure illustrates the process of integrating synthetic video data into a video generation model to enhance the model’s understanding of physics. The pipeline begins by planning synthetic videos and assigning descriptive tags to their components (objects, characters, motions, etc.). These descriptions are then combined to create captions for the synthetic videos. Finally, the synthetic videos and their captions are integrated with real-world video data during model training. This process is designed to improve physical realism in the model’s output, particularly for complex video generation tasks.
read the caption
Figure 2: Visualization of the pipeline to augment video generation model with synthetic video data. We first plan the synthetic videos and generation descriptive tags for each elements (e.g. object, character, motion, etc). Then we combine the element descriptions to form the caption for synthetic videos. During training, we mix the synthetic videos with real-world video data to improve physics fidelity in challenging video generation tasks.

🔼 This figure visualizes examples of synthetic videos generated using different qualities of 3D assets and rendering techniques. Subfigure (a) compares videos created with high-quality 3D assets against those with low-quality assets, showcasing the visual impact of asset quality on the realism of the final video. Subfigure (b) demonstrates the effect of rendering quality on the synthetic videos, showing differences between high-quality and low-quality renderings, and their impact on the overall visual fidelity. These visual comparisons highlight the importance of both high-quality 3D assets and rendering techniques to bridge the appearance gap between synthetic and real-world videos, essential for effectively training video generation models using synthetic data.
read the caption
Figure 3: Visualizations of synthetic videos highlighting both good- and poor-quality 3D assets (a) and rendering (b).

🔼 Figure 4 presents video results generated by a video generation model enhanced with synthetic training data. The figure is organized into six rows, each showcasing different video generation capabilities. Rows 1 and 2 demonstrate the model’s ability to handle wide-angle camera motion, showing smooth transitions and consistent object representation despite large camera movements. Row 3 illustrates the model’s successful layer decomposition, cleanly separating foreground elements (objects and subjects) from the background, even when presented with complex scenes. Rows 4, 5, and 6 focus on the generation of large human motions, showcasing the model’s ability to generate realistic and physically consistent human movements without artifacts or distortions even during extreme motion.
read the caption
Figure 4: Visualizations of the videos generated by our improved model, trained using synthetic data. Rows 1,2 highlight wide-angle camera motion; rows 3 display layer decomposition; and rows 4,5,6 demonstrate large human motion.

🔼 This figure displays several frames from videos showcasing large human motions generated by the proposed model. The key takeaway is that the model accurately generates realistic shadows that dynamically move and change shape in response to the human body’s movements. This demonstrates an improvement in the physical fidelity of the model’s output, a crucial aspect of realistic video generation.
read the caption
Figure 5: Visualization of video frames with large human motion generated by our model. The shadow of human body follows the human motion.

🔼 Figure 6 shows the 3D scene setups in Blender and Unreal Engine, two popular computer graphics software packages. The left column displays wireframe representations of the 3D scenes, illustrating the object, camera placement, and lighting configurations. The right column presents the resulting rendered images that are produced based on the specified setup in the left column. This visualization helps to illustrate how the parameters used in the scene setup (as detailed in the paper) impact the final rendered output, emphasizing the configurability and control offered by these CGI pipelines.
read the caption
Figure 6: 3D scene setup in Blender and Unreal Engine. The wireframes and corresponding rendering outputs.

🔼 Figure 7 showcases examples of synthetic video data generated using diverse backgrounds. The diversity in backgrounds aims to mitigate potential biases that might arise from using only a limited set of backgrounds during the training process, which can result in the model overfitting to specific visual characteristics of the synthetic data and not generalizing well to real-world videos.
read the caption
Figure 7: Examples of our synthetic video data. We render the synthetic videos with diverse background to alleviate the potential biases in synthetic videos.

🔼 This figure showcases the negative impact of using low-quality synthetic data for training video generation models. The images demonstrate that models trained on these datasets produce videos where the generated objects have an unrealistic, cartoonish, or animated appearance. This differs significantly from the intended, more photorealistic visual style.
read the caption
Figure 8: Example outputs from video generation models trained on synthetic datasets with low-quality assets. The resulting objects frequently exhibit cartoonish or animated characteristics, diverging from the intended original visual style.

🔼 This figure visualizes the results of video generation models trained using synthetic data with low-quality assets. The models were tasked with generating videos featuring large camera motions. The generated videos of objects show a higher likelihood of appearing static or exhibiting unnatural, animated movements compared to videos generated with high-quality assets, highlighting the importance of high-quality synthetic data in training for physically accurate video generation.
read the caption
Figure 9: Visualization of generated outputs from video generation models trained with synthetic videos of low quality assets in large camera motion task. The objects in these generated videos more likely to appear static or animated.

🔼 This figure demonstrates the negative impact of overtraining a video generation model using synthetic data. When trained for excessive iterations, the model starts to incorporate artifacts from the training data, such as specific color palettes or visual styles, which are not reflective of real-world videos. The generated videos become less realistic due to overfitting. This highlights the importance of carefully balancing training with real and synthetic data to avoid overemphasizing the artificial features of the synthetic datasets. The figure likely visually shows a series of videos generated after various training epochs, showcasing a progressive shift towards artificial visual patterns.
read the caption
Figure 10: Visualization of over training video generation models trained with synthetic videos. Visual patterns such as color tone are more likely to appear in generated videos.

🔼 This figure compares different captioning methods for synthetic videos. The existing methods generate generic captions, while the proposed method generates fine-grained captions that provide more detailed descriptions of the video content, including specific actions and visual elements. The figure also demonstrates the impact of adding ‘special tags’ to the captions, which help the model distinguish between synthetic and real videos, improving the transfer of physical fidelity from synthetic to real video generation.
read the caption
Figure 11: A comparison of generating captions for synthetic videos using existing methods (Generic Caption) and our method (Fine-Grained Caption). We also show a comparison of captions with special tags and without special tags.

🔼 This figure compares video generation results with and without the SimDrop method. The top row (Row 1) shows videos generated without SimDrop, exhibiting noticeable color inconsistencies and artifacts stemming from the synthetic training data. The bottom row (Row 2) displays videos generated using SimDrop. SimDrop effectively mitigates these artifacts, resulting in videos with more natural and consistent color tones, demonstrating improved visual fidelity.
read the caption
Figure 12: A comparison showcasing the effect of SimDrop. Row 1 is the result without SimDrop and Row 2 is the video with the method. The color tone in row two is significantly more better and without color pattern from the synthetic data.
More on tables
| Training Data | Gym | Layer | Spin shot |
| Default | 83.3% | 95% | 85% |
| Low-quality asset | - | 92.5% | 22.5% |
| Low-cost rendering | 41.7% | 17.5% | - |
🔼 This table presents the success rates of video generation models trained with synthetic videos of varying asset and rendering quality. The success rate indicates how well the physical fidelity of the synthetic videos transfers to the generated videos. Low-quality assets or rendering significantly reduce the success rate, suggesting that high-fidelity synthetic data is crucial for effective training and achieving high physical realism in the generated videos. The results highlight the importance of using high-quality assets and rendering techniques when creating synthetic training data for video generation models.
read the caption
Table 2: Success rates illustrating how asset and rendering quality in synthetic videos affect physical fidelity. When asset or rendering quality is low, the physical fidelity in these synthetic videos is less likely to transfer effectively to video generation models.
| Model | User Study | |||
| Gym | Dance | Gym | Dance | |
| Kling 1.6 [36] | 0.715 | 0.812 | 10% | 43% |
| Runway Gen-3 [52] | 0.672 | 0.809 | 4% | 14% |
| Sora [9] | 0.722 | 0.813 | 15% | 44% |
| Base Model | 0.779 | 0.818 | 9% | 30% |
| Our Model | 0.791 | 0.837 | 61% | 86% |
🔼 This table presents a quantitative and qualitative analysis of the large human motion generation task. It shows the average confidence scores from human pose estimation, a metric measuring the realism and accuracy of human poses in generated videos. Higher scores indicate better pose fidelity. Additionally, it includes user study results, reflecting subjective assessments of the generated video quality. The user study data, expressed as percentages, likely represents the success rate of the model in generating realistic-looking human motions without artifacts. Comparing these metrics across different models allows for an evaluation of their performance regarding the physical realism and accuracy of generated human motions.
read the caption
Table 3: The average confidence score of human pose estimation and user study results on the large human motion task.
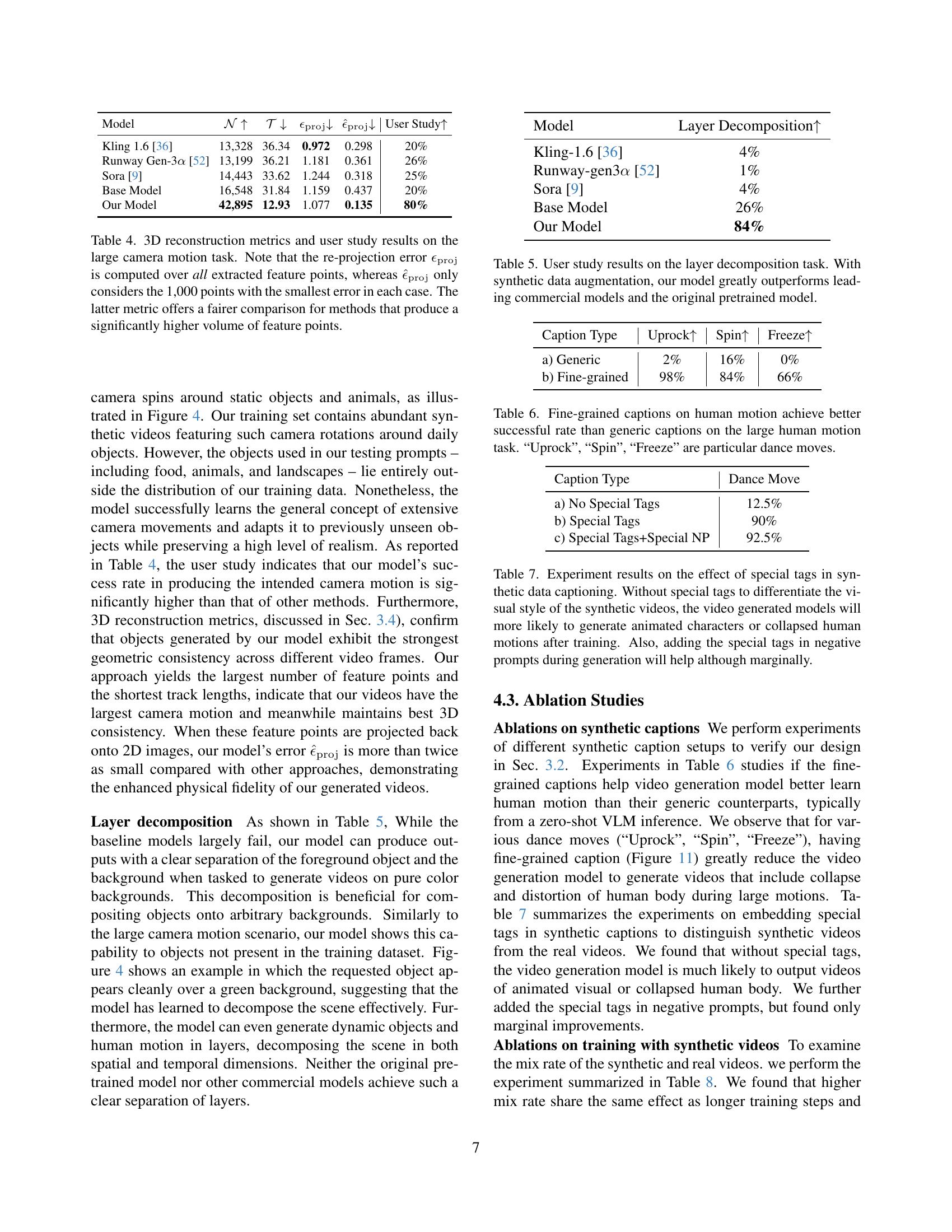
| Model | User Study | ||||
| Kling 1.6 [36] | 13,328 | 36.34 | 0.972 | 0.298 | 20% |
| Runway Gen-3 [52] | 13,199 | 36.21 | 1.181 | 0.361 | 26% |
| Sora [9] | 14,443 | 33.62 | 1.244 | 0.318 | 25% |
| Base Model | 16,548 | 31.84 | 1.159 | 0.437 | 20% |
| Our Model | 42,895 | 12.93 | 1.077 | 0.135 | 80% |
🔼 This table presents a quantitative and qualitative evaluation of different video generation models on the task of generating videos with large camera motions. It assesses the physical fidelity of the generated videos by using 3D reconstruction metrics from COLMAP. These metrics include the number of matched feature points (N), the average track length (T), and the average reprojection error (ϵproj). A lower reprojection error indicates higher 3D consistency. The table also includes a user study comparing the success rate of the various models in generating videos that accurately depict the intended camera motion and are free of artifacts. Note that two versions of the reprojection error are shown: one calculated using all feature points, and another that only uses the top 1000 points with the smallest error, which provides a more fair comparison of models with vastly different numbers of feature points.
read the caption
Table 4: 3D reconstruction metrics and user study results on the large camera motion task. Note that the re-projection error ϵprojsubscriptitalic-ϵproj\epsilon_{\mathrm{proj}}italic_ϵ start_POSTSUBSCRIPT roman_proj end_POSTSUBSCRIPT is computed over all extracted feature points, whereas ϵ^projsubscript^italic-ϵproj\hat{\epsilon}_{\mathrm{proj}}over^ start_ARG italic_ϵ end_ARG start_POSTSUBSCRIPT roman_proj end_POSTSUBSCRIPT only considers the 1,000 points with the smallest error in each case. The latter metric offers a fairer comparison for methods that produce a significantly higher volume of feature points.
🔼 This table presents the results of a user study evaluating the performance of different video generation models on a layer decomposition task. The task involved generating videos with a subject clearly separated from a solid-color background, a challenge often faced by video generation models. The models compared include the authors’ model (trained with and without synthetic data augmentation), along with several leading commercial video generation models and their original pre-trained model. The results are expressed as a percentage representing the success rate of each model in correctly performing the layer decomposition. The data shows that the authors’ model, when trained with synthetic data augmentation, significantly outperforms all other models tested, indicating the effectiveness of their proposed synthetic data integration method for enhancing physical fidelity in video generation.
read the caption
Table 5: User study results on the layer decomposition task. With synthetic data augmentation, our model greatly outperforms leading commercial models and the original pretrained model.
| Caption Type | Uprock | Spin | Freeze |
| a) Generic | 2% | 16% | 0% |
| b) Fine-grained | 98% | 84% | 66% |
🔼 This table presents a comparison of the success rates achieved in generating human motion videos using different captioning methods. The task is challenging because it involves creating videos of people performing complex dance moves, requiring a high degree of physical realism. Two captioning strategies are compared: generic captions, which provide general descriptions of the actions, and fine-grained captions, which provide more specific and detailed descriptions of the dance moves, including particular dance move names such as ‘Uprock’, ‘Spin’, and ‘Freeze’. The success rate for each method is shown for three specific dance moves, highlighting the significant improvement in accuracy when using more detailed and precise captions. This improvement demonstrates the importance of providing detailed, specific instructions to the model in order to generate more accurate results.
read the caption
Table 6: Fine-grained captions on human motion achieve better successful rate than generic captions on the large human motion task. “Uprock”, “Spin”, “Freeze” are particular dance moves.
| Caption Type | Dance Move |
| a) No Special Tags | 12.5% |
| b) Special Tags | 90% |
| c) Special Tags+Special NP | 92.5% |
🔼 This table presents an ablation study on the impact of using special tags in captions for synthetic training data on video generation model performance. Three experimental conditions are compared: (a) captions without special tags, (b) captions with special tags, and (c) captions with special tags in both positive and negative prompts during generation. The results show a significant improvement in model performance when using special tags, indicating that these tags help the model distinguish between real and synthetic video data. However, adding the tags to negative prompts leads to only marginal improvements, suggesting diminishing returns.
read the caption
Table 7: Experiment results on the effect of special tags in synthetic data captioning. Without special tags to differentiate the visual style of the synthetic videos, the video generated models will more likely to generate animated characters or collapsed human motions after training. Also, adding the special tags in negative prompts during generation will help although marginally.
| 3000 | 5000 | 10000 | 15000 | |
| 10% synthetic videos | 20% | 25% | 40% | 60% |
| 50% synthetic videos | 55% | 75% | 85% | 80% |
🔼 This table presents the ablation study results on the impact of synthetic data mix rate and training steps on the video generation model. The ‘success rate’ is defined as the percentage of generated videos that adhere to the prompts without exhibiting visual artifacts from the synthetic data. The study reveals that increasing the proportion of synthetic data and extending the training duration facilitates the transfer of physical properties from synthetic to real videos. However, the improvement plateaus after a certain point, and excessive training leads to overfitting where generated videos may start incorporating the unique visual patterns of the synthetic data, thus reducing the success rate.
read the caption
Table 8: Ablation results on synthetic data mix rate and training steps. Here we measure the success rate which the trained foundation model generates videos that follows the prompts but does not include visual patterns in the synthetic videos. We found that large proportion and longer training steps help transferring the properties in synthetic videos to the video generation model. However, performance will saturate and failure cases will include visual patterns of synthetic data.
| Good | Same | Bad | G-B | |
| 0.1 | 26.32% | 71.05% | 2.63% | 23.69% |
| 0.2 | 39.47% | 52.63% | 7.89% | 31.58% |
🔼 This table presents an ablation study evaluating the effectiveness of SimDrop, a novel technique introduced to mitigate artifacts introduced by synthetic data in video generation. Two video generation models are compared: one trained with SimDrop and one without. Human evaluators compared pairs of videos (one from each model, generated using the same prompt) and selected the better-quality video based on visual preference. The results are presented as percentages representing the frequency of each model being chosen as ‘better’, showing the relative improvement achieved by SimDrop in generating videos without synthetic data artifacts.
read the caption
Table 9: Experiment results on SimDrop. Here, we compare the output videos with SimDrop with the models without SimDrop. Evaluators will choose the best out of two videos side-by-side. We then compute the winning/same/losing rate against the baseline.
| Property Name | Choice | Description | |
| Camera | Camera Focus Type | Follow | The camera focus follows the object. |
| Fixed | The camera focus is static in the world space. | ||
| Camera Focus Position | Upper, Center, Lower | The camera focus is at the upper/center/lower part of the object. | |
| Camera Movement Type | Truck, Dolly, Pedestal, Tilt, Pan, Spin, Following, Zoom | The basic camera movement types. | |
| Camera Movement Value | Scalar | How much the camera moves. | |
| Camera Initial Position | 3D Position | The initial position of the camera. | |
| Camera Focal Length | Scalar | The scalar controls how much percentage of the object is visible on the screen. | |
| Light and Environment | Scene Type | Env | The environment is given by a HDR environmental map. The map will also be used as the light source. |
| Basic | The environment is an indoor room which color is controlled by “Scene Color” and has two light sources. | ||
| Empty | The environment is empty but has two light sources or one environmental map as the light source. | ||
| Scene Color | RGB color | The color for the indoor room when presented. | |
| Light Position | 3D position | The position of the light when presented. | |
| Light Color | Scalar | The color temperature of the light when presented. | |
| Light Intensity | Scalar | The intensity of the light when presented. | |
| Ambient Light Intensity | Scalar | Ambient light intensity. The ambient light exists when the lights are used. | |
| Render | Background Color | RGBA color | The background color of the location where the scene is empty. |
| Render Engine | Blender/Unreal | ||
| Render Quality | High/Low | The quality of the rendering. We have two presets of rendering setting. |
🔼 This table lists the parameters used to control the video rendering pipeline in the study. It details the options available for each parameter, affecting aspects such as camera focus, movement, position, and focal length; scene type, color, and lighting; background color; and rendering engine and quality. These parameters are used to generate diverse and controlled synthetic videos for training the video generation model. Understanding these parameters is crucial to understanding how the synthetic data is created and its impact on the model.
read the caption
Table 10: The parameters used for controlling our rendering pipeline.
Full paper#