TL;DR#
Multimodal generative models, essential for understanding and generating across various modalities, are dominated by autoregressive approaches. These methods process tokens sequentially, which can be inefficient. This work explores discrete diffusion models as a unified generative formulation in the joint text and image domain to address these limitations.
This paper introduces UniDisc, a Unified Multimodal Discrete Diffusion model capable of jointly understanding and generating text and images. UniDisc offers advantages over AR models, including improved control over quality versus diversity, joint multimodal inpainting, and greater controllability through guidance. Experiments demonstrate that UniDisc outperforms AR models in performance, compute efficiency, and controllability.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach to multimodal generative modeling, offering a unified discrete diffusion framework. It challenges existing autoregressive methods and presents a promising alternative for joint text and image understanding. Researchers can leverage this framework for various downstream tasks and explore its potential for broader applications in multimodal AI.
Visual Insights#

🔼 This figure showcases the model’s ability to perform joint inpainting on image and text pairs. The model is given an image and text with masked regions, and it successfully fills in both the missing image and text portions. Notably, the model was not explicitly trained for this specific inpainting task; rather, its ability to perform this task is an inherent consequence of its unified diffusion objective, which allows the model to jointly model and generate both image and text modalities.
read the caption
Figure 1: We show UniDisc’s ability to jointly inpaint image & text pairs. We do not explicitly optimize for this objective but it is intrinsic to UniDisc’s unified diffusion objective.
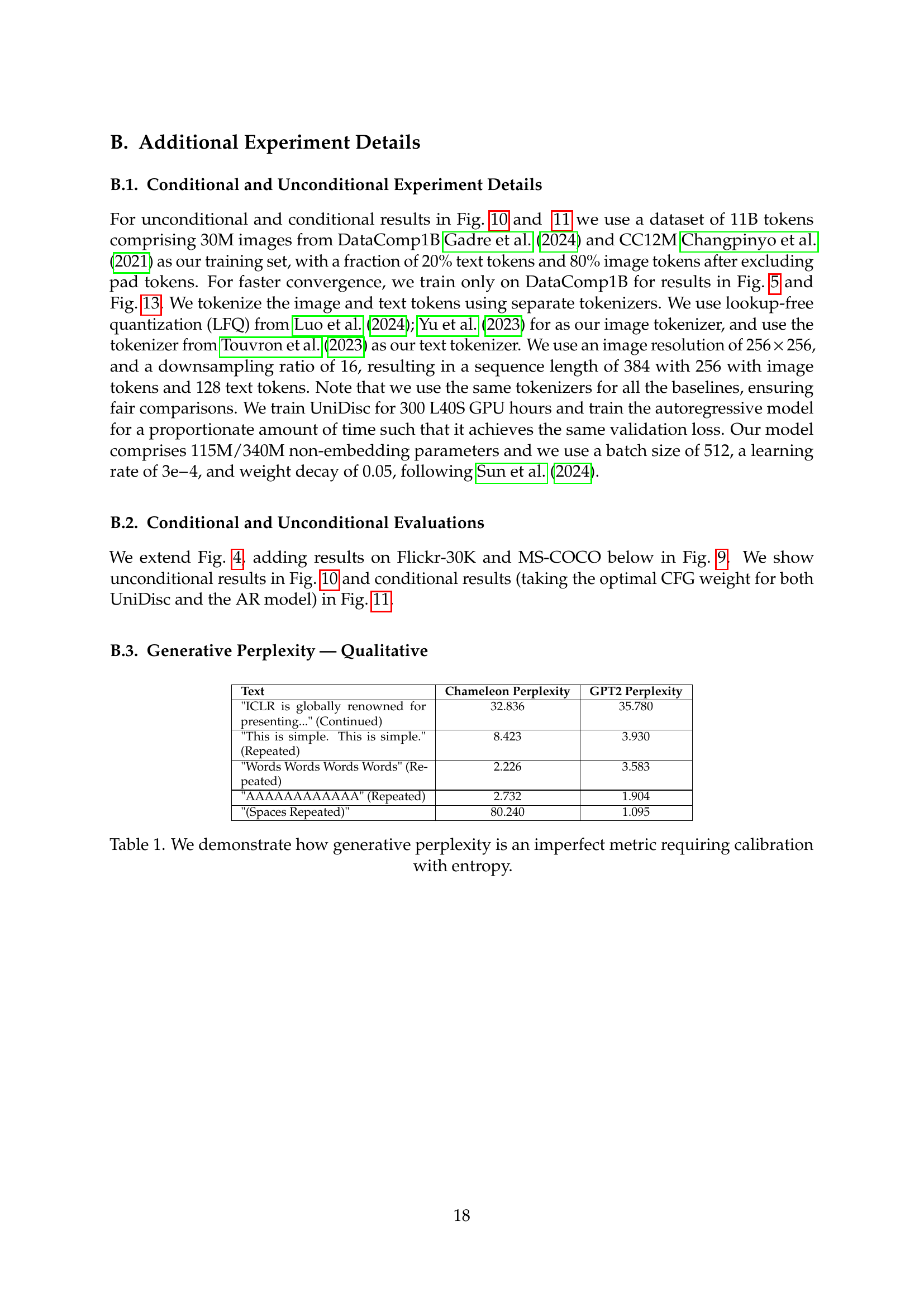
| Text | Chameleon Perplexity | GPT2 Perplexity |
|---|---|---|
| "ICLR is globally renowned for presenting…" (Continued) | 32.836 | 35.780 |
| "This is simple. This is simple." (Repeated) | 8.423 | 3.930 |
| "Words Words Words Words" (Repeated) | 2.226 | 3.583 |
| "AAAAAAAAAAAA" (Repeated) | 2.732 | 1.904 |
| "(Spaces Repeated)" | 80.240 | 1.095 |
🔼 This table shows that generative perplexity alone is insufficient for evaluating the quality of text generation models. It demonstrates how, even with low generative perplexity scores, the generated text might lack diversity or be repetitive. The table highlights that combining generative perplexity with entropy provides a more robust and comprehensive evaluation of generation quality.
read the caption
Table 1: We demonstrate how generative perplexity is an imperfect metric requiring calibration with entropy.
In-depth insights#
UniDisc: Diffuse All#
The name ‘UniDisc: Diffuse All’, though not explicitly present in the paper, suggests a central methodology: unified diffusion across modalities. This implies a framework where diverse data types (text, images) are processed through a shared diffusion process, unlike methods with modality-specific handling. The core idea revolves around corrupting data with discrete noise (masking tokens) and learning to reverse this corruption. This unified approach likely enables seamless cross-modal generation and manipulation (inpainting), control, and efficient trade-offs between quality and speed. UniDisc’s strength lies in its potential to capture interdependencies between modalities more effectively than autoregressive models or continuous diffusion models.
AR: Slow Inpaint#
AR models, while powerful for generative tasks, can be slow for inpainting due to their sequential nature. Inpainting requires filling in missing parts of an image, which for AR models means iteratively generating tokens to replace the missing areas. This is inefficient because AR models were optimized for sequential generation and have difficulties with the insertion task. Also, it leads to many forward passes, which increase compute time. Diffusion models, on the other hand, can be more efficient for inpainting because they fill-in missing areas.
Discrete Diffusion#
Discrete diffusion models present a compelling alternative to autoregressive models, particularly beneficial for addressing multimodality. Unlike continuous diffusion, they operate on discrete data, avoiding the issues associated with adding continuous noise to inherently discrete entities like text. This approach allows for more efficient training in certain domains and enables greater control over generated outputs. The use of masking as a form of discrete noise provides a natural way to handle inpainting and editing tasks, offering a more intuitive framework for joint multimodal manipulation. Different noise schedules, loss functions, and transition kernels further enhance the flexibility and adaptability of discrete diffusion models, making them well-suited for unifying various modalities under a single generative framework, as explored in this paper. They offer faster inference, high controllability and quality, easily trade-off quality vs. compute.
Fast Gen. Tradeoffs#
Faster generation often entails tradeoffs in quality or diversity. Methods to accelerate generation, such as reducing denoising steps in diffusion models or employing more efficient architectures, can lead to lower-quality samples or a loss of fine-grained detail. Balancing computational efficiency with desired output characteristics is key. Techniques like classifier-free guidance can improve sample quality but may still require careful tuning to avoid artifacts or biases. The optimal approach depends on the specific application and acceptable levels of compromise between speed and output fidelity. Exploring novel methods for distillation or approximation of complex generative processes could unlock new pathways for faster and higher-quality generation in the future.
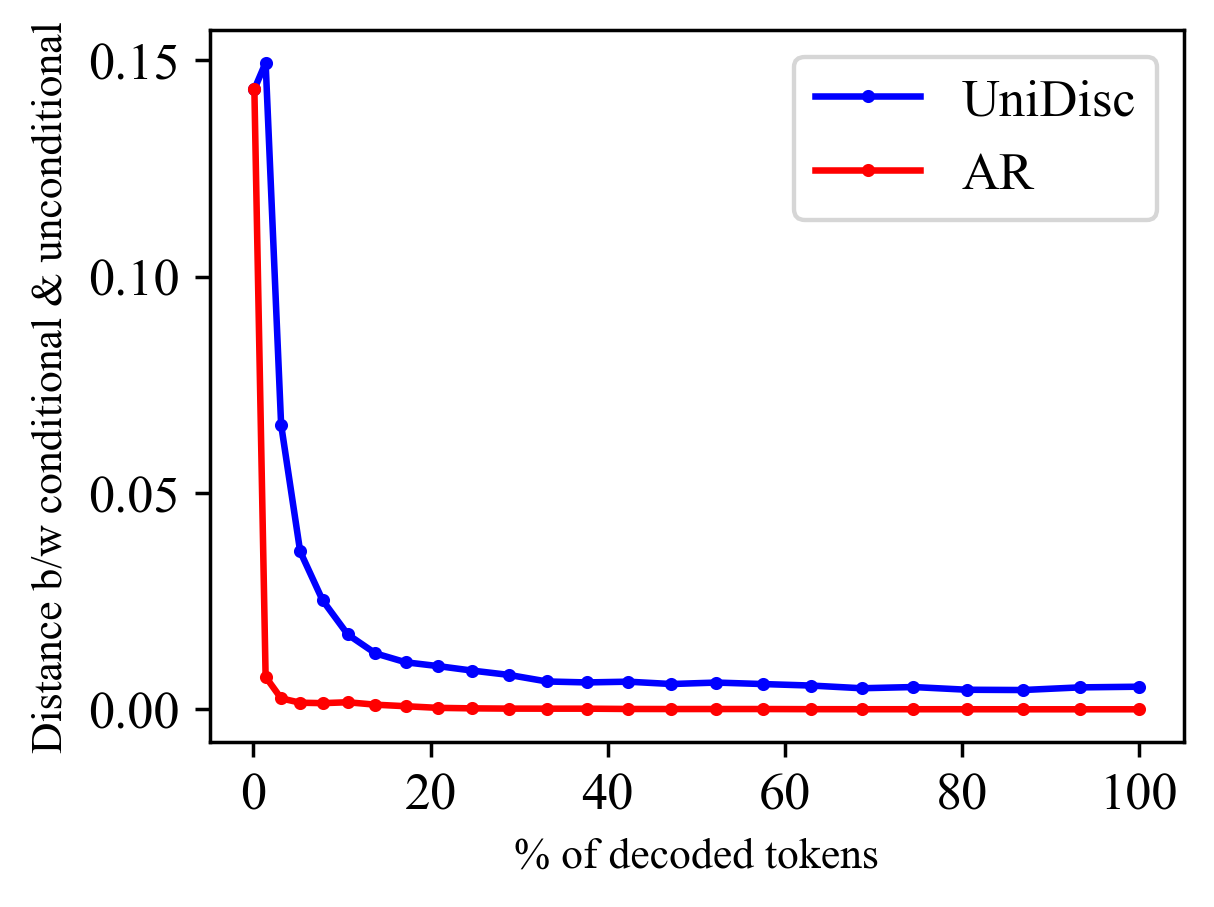
CFG Key to Gen#
Classifier-Free Guidance (CFG) emerges as a pivotal element for enhancing generative model performance, especially in scenarios involving intricate conditional generation. The core idea revolves around leveraging both conditional and unconditional predictions to guide the model’s output. UniDisc extracts more discriminating signal from CFG compared to AR models. UniDisc’s architecture, characterized by its flexibility in decoding tokens based on confidence, outshines AR models, which are constrained by a rigid left-to-right decoding order, resulting in a more efficient and nuanced generation process. Findings suggest that CFG is most effective in the initial stages of decoding, setting the foundation for high-quality results. Optimizing CFG’s application, particularly focusing on early decoding stages, unlocks substantial gains in generative models. By understanding and strategically implementing CFG, we can significantly improve the performance of generative models, achieving a balance between visual quality and prompt adherence.
More visual insights#
More on figures

🔼 UniDisc, a unified multimodal discrete diffusion model, processes and generates both text and images. The model first converts text and images into sequences of discrete tokens. Then, it uses a denoising process, where masked tokens ([MASK]) are iteratively replaced with predicted tokens using a weighted cross-entropy loss function applied jointly to the text and image tokens. The resulting model can understand and generate both modalities.
read the caption
Figure 2: UniDisc is a unified multimodal discrete diffusion model that can jointly process and generate text and images. Each modality is converted into a sequence of discrete tokens and we jointly denoise, supervising with a weighted cross-entropy loss. At inference time we begin with a set of [MASK] tokens and iteratively unmask tokens.

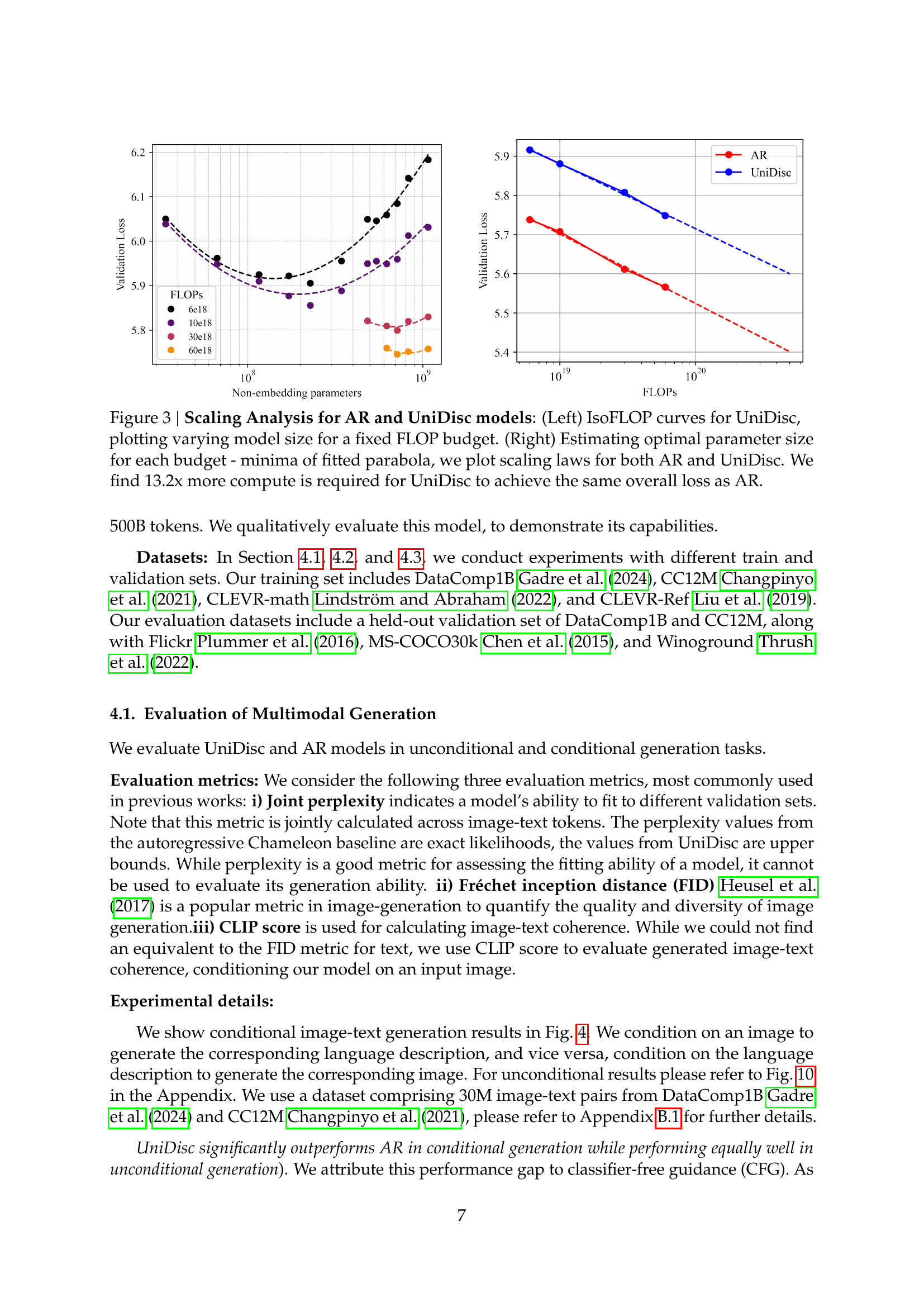
🔼 This figure presents a scaling analysis comparing autoregressive (AR) and Unified Multimodal Discrete Diffusion (UniDisc) models. The left panel shows isoflop curves for UniDisc, illustrating how model size changes for a constant FLOP budget. The right panel displays the estimated optimal parameter size for each budget using fitted parabolas, visualizing the scaling laws for both AR and UniDisc models. The key finding is that UniDisc demands 13.2 times more computational resources than AR to achieve a comparable overall loss.
read the caption
Figure 3: Scaling Analysis for AR and UniDisc models: (Left) IsoFLOP curves for UniDisc, plotting varying model size for a fixed FLOP budget. (Right) Estimating optimal parameter size for each budget - minima of fitted parabola, we plot scaling laws for both AR and UniDisc. We find 13.2x more compute is required for UniDisc to achieve the same overall loss as AR.

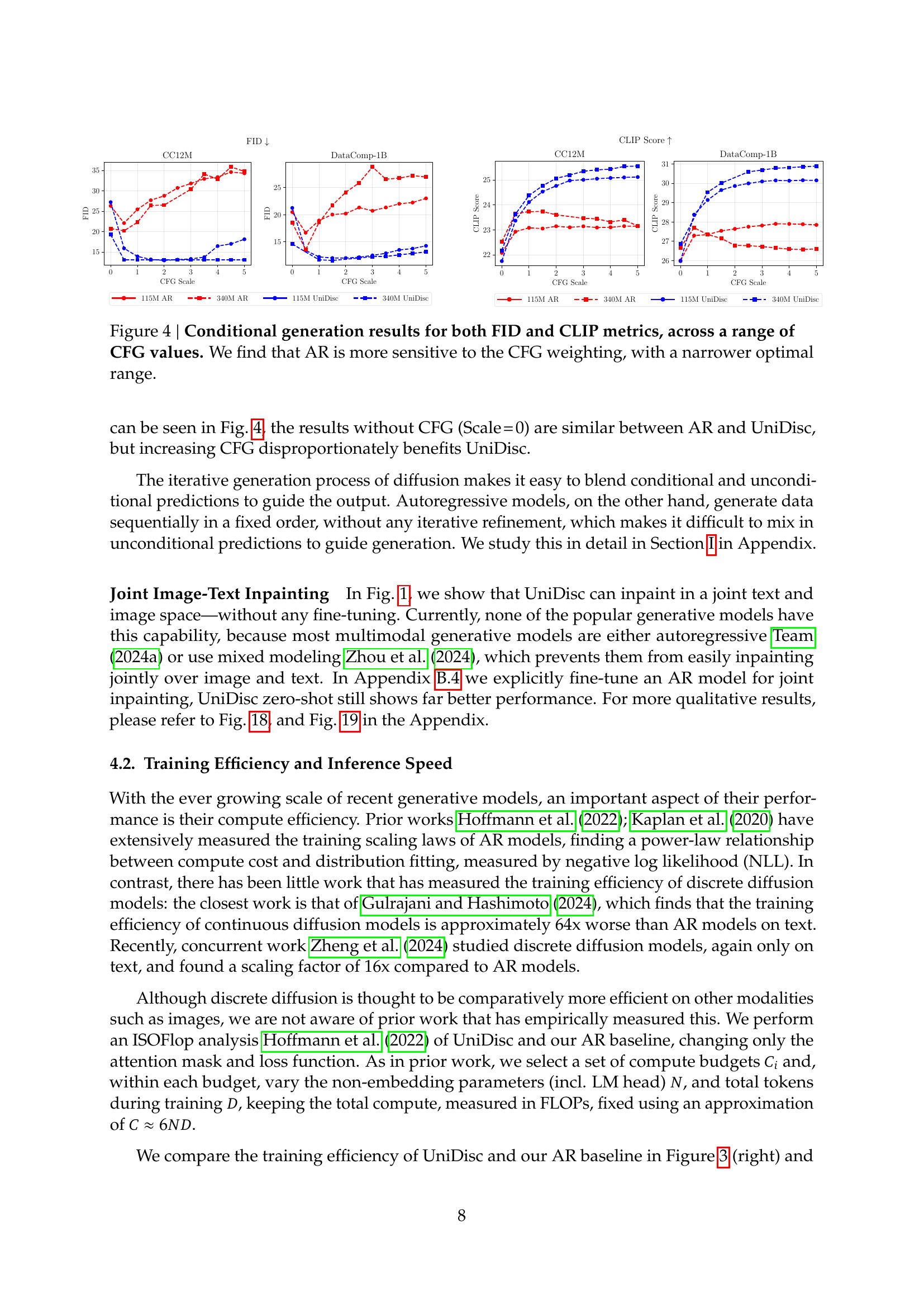
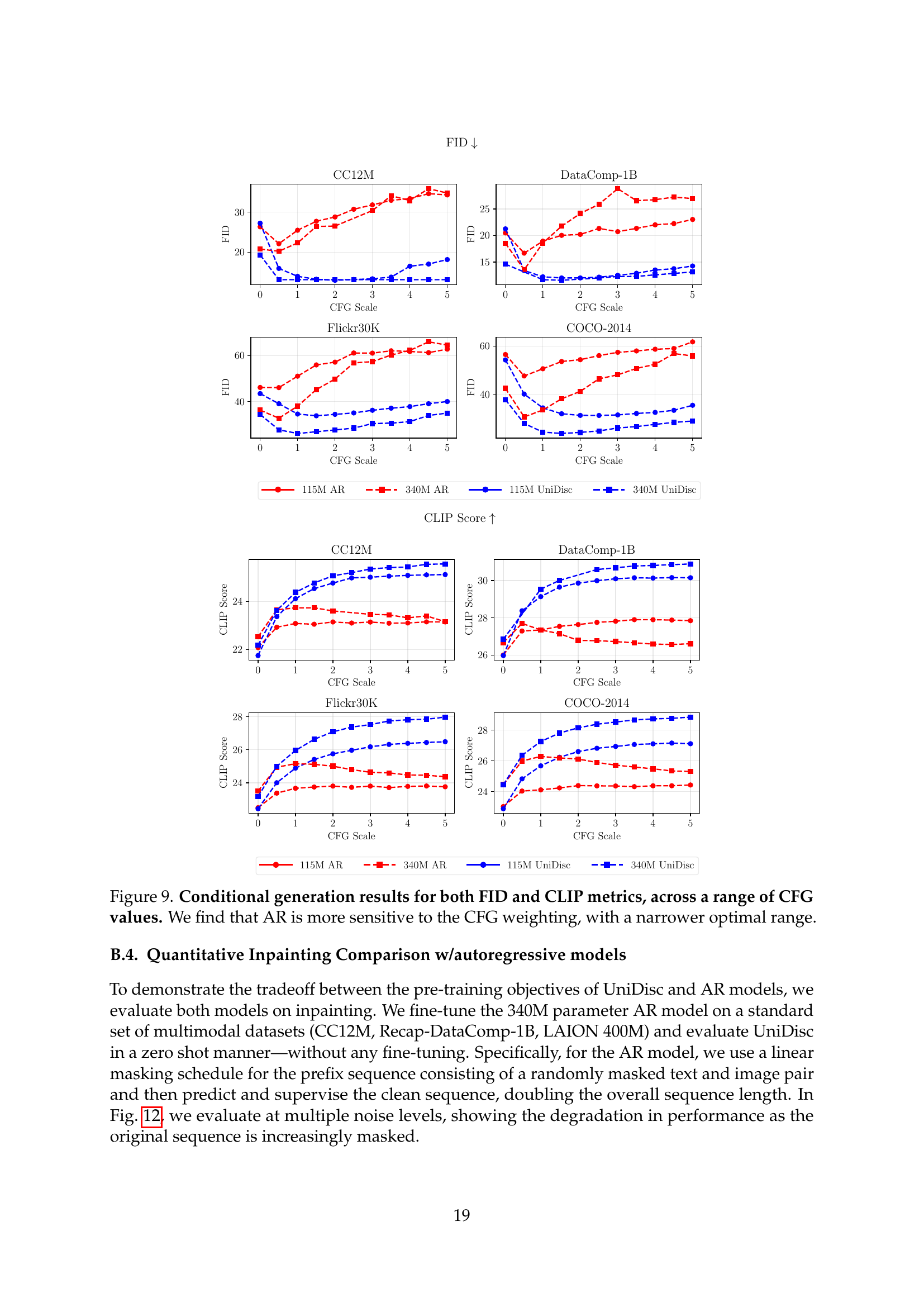
🔼 Figure 4 presents the results of a conditional image generation experiment comparing the performance of autoregressive (AR) models and the UniDisc model. The experiment is conducted across various datasets (CC12M, DataComp-1B, Flickr30K, COCO-2014) and uses classifier-free guidance (CFG) at different scales. The figure shows FID and CLIP scores as metrics for evaluating the quality and diversity of the generated images. The results show that UniDisc outperforms AR models, specifically demonstrating a greater robustness to variations in the CFG weighting. The AR model’s performance is shown to be more sensitive to the CFG value, with its optimal range being narrower compared to that of the UniDisc model.
read the caption
Figure 4: Conditional generation results for both FID and CLIP metrics, across a range of CFG values. We find that AR is more sensitive to the CFG weighting, with a narrower optimal range.

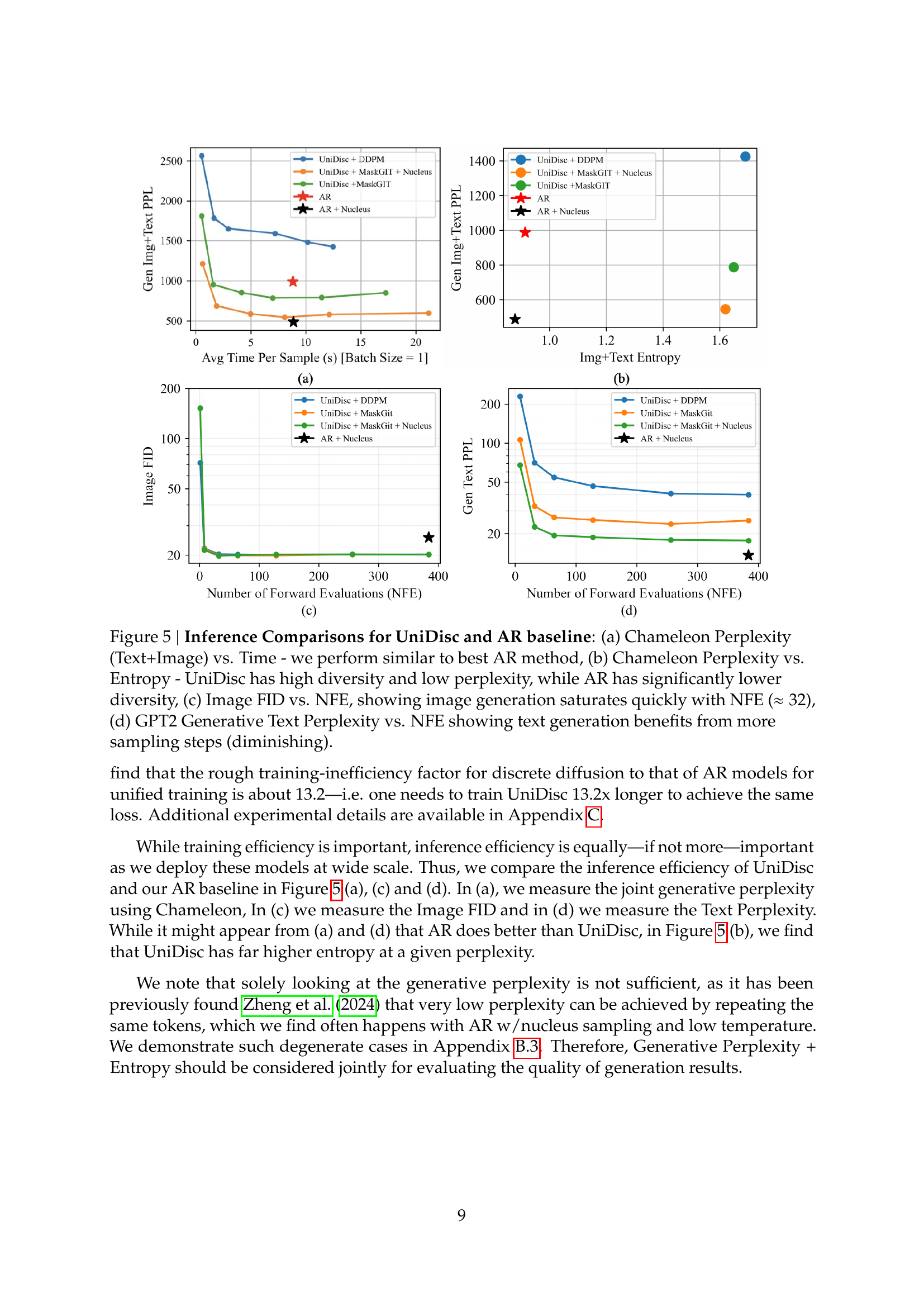
🔼 Figure 5 presents a comparison of UniDisc and an autoregressive (AR) baseline across multiple metrics related to inference efficiency. Subfigure (a) shows the trade-off between generation time and the joint perplexity (a measure of model uncertainty) on the Chameleon dataset; UniDisc performs comparably to the best AR model. Subfigure (b) illustrates the relationship between perplexity and entropy (a measure of diversity). UniDisc achieves a lower perplexity score with higher entropy, suggesting better quality and diversity in generation compared to the AR model’s lower diversity and higher perplexity. Subfigure (c) examines the impact of the number of forward evaluations (NFEs) on the Fréchet Inception Distance (FID), a measure of image generation quality. Image generation quality for UniDisc plateaus after around 32 NFEs. Finally, subfigure (d) shows how the number of NFEs affects text generation quality (measured by GPT2 generative perplexity); improved generation quality with UniDisc is observed with more NFEs.
read the caption
Figure 5: Inference Comparisons for UniDisc and AR baseline: (a) Chameleon Perplexity (Text+Image) vs. Time - we perform similar to best AR method, (b) Chameleon Perplexity vs. Entropy - UniDisc has high diversity and low perplexity, while AR has significantly lower diversity, (c) Image FID vs. NFE, showing image generation saturates quickly with NFE (≈32absent32\approx 32≈ 32), (d) GPT2 Generative Text Perplexity vs. NFE showing text generation benefits from more sampling steps (diminishing).

🔼 This figure demonstrates UniDisc’s ability to generate diverse and coherent images and text, even when only masked text input is provided. The left panel shows the masked text input, while the right panel displays the generated images and text. The language-conditioned segmentation model ensures that the generations are semantically consistent. The results showcase UniDisc’s capability to create uniformly distributed samples within the concept space, indicating a good balance between quality and diversity. It highlights the model’s strength in joint text and image generation, effectively handling the ambiguity of the masked input.
read the caption
Figure 6: Uniform Concept Generation: We perform joint generation given only masked text input (left). We use a language conditioned segmentation model and find that UniDisc generates uniformly in concept space (right).

🔼 This figure demonstrates UniDisc’s ability to perform zero-shot image editing. Given a mismatched or corrupted image-text pair (shown on the left), UniDisc processes both modalities jointly and generates a new, high-quality, and aligned image-text pair (shown on the right). The model uses its own internal likelihood scores to select the best possible output from multiple generated candidates.
read the caption
Figure 8: Zero-shot Image Editing: UniDisc can take corrupted and mismatched image/text pairs (left) and produce an aligned, high-quality pair (right), using the model’s own likelihood as a scoring function.

🔼 This figure displays the impact of classifier-free guidance (CFG) scaling on conditional image generation using both autoregressive (AR) and UniDisc models. The FID (Fréchet Inception Distance) and CLIP (Contrastive Language-Image Pre-training) scores are plotted against different CFG scaling factors for both models. The results show that UniDisc is more robust to changes in CFG weighting, maintaining relatively consistent performance across a broader range of CFG values. In contrast, the AR model demonstrates higher sensitivity to CFG adjustments, with its optimal performance restricted to a much narrower range of CFG scaling factors. This highlights one key advantage of UniDisc over traditional AR models in controlling the trade-off between quality and diversity of generated samples.
read the caption
Figure 9: Conditional generation results for both FID and CLIP metrics, across a range of CFG values. We find that AR is more sensitive to the CFG weighting, with a narrower optimal range.

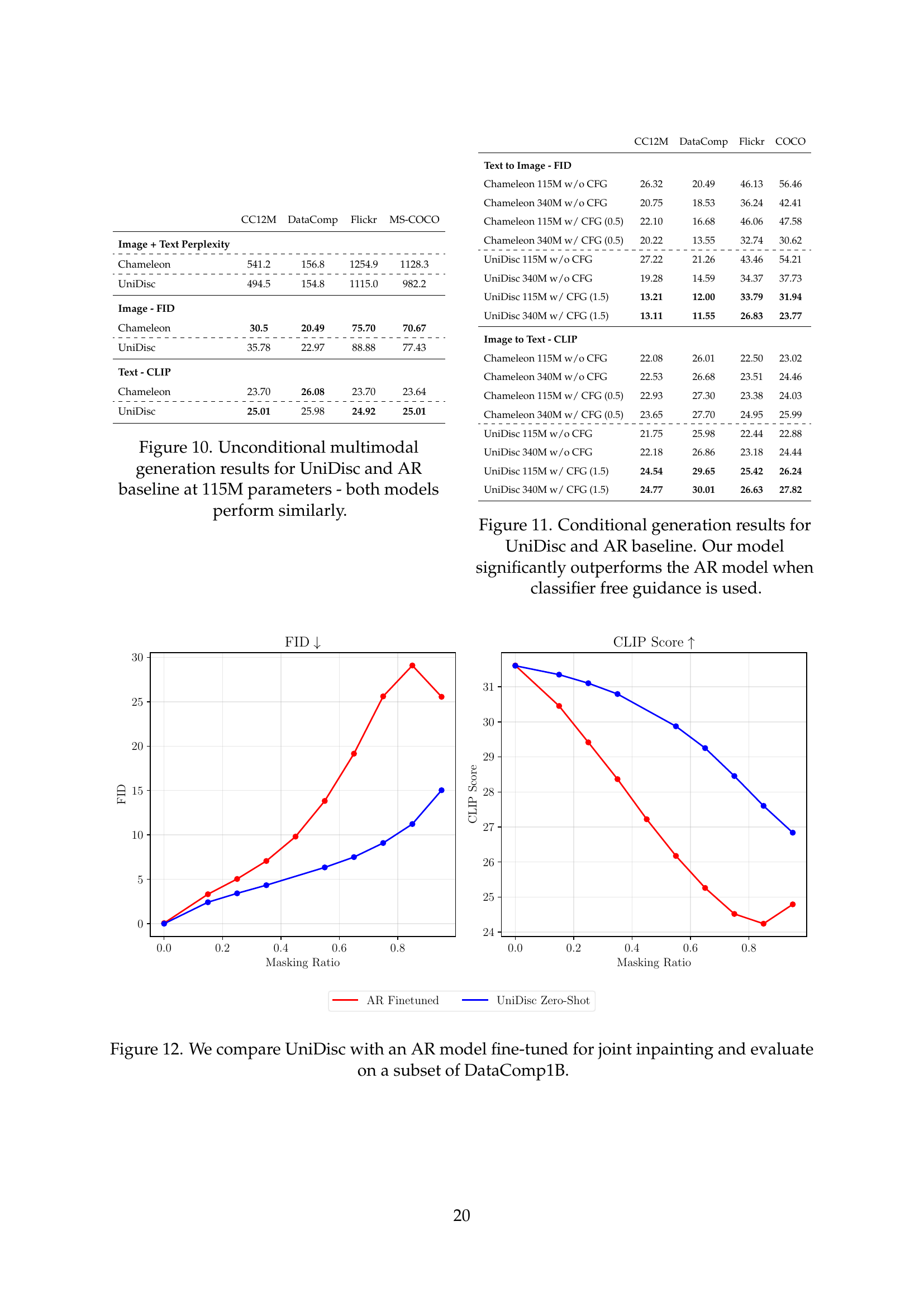
🔼 This figure presents a comparison of unconditional multimodal generation performance between UniDisc and a comparable autoregressive (AR) model, both with 115 million parameters. The results are presented across multiple metrics and datasets, demonstrating that while both models achieve similar overall performance in unconditional generation.
read the caption
Figure 10: Unconditional multimodal generation results for UniDisc and AR baseline at 115M parameters - both models perform similarly.

🔼 This figure compares the performance of UniDisc and an autoregressive (AR) model on joint image-text inpainting. The AR model was fine-tuned specifically for this task, while UniDisc was evaluated without any fine-tuning, demonstrating its zero-shot capability. The comparison is performed using a subset of the DataComp1B dataset, allowing for a direct evaluation of the two models’ inherent ability to handle joint inpainting across text and image modalities.
read the caption
Figure 12: We compare UniDisc with an AR model fine-tuned for joint inpainting and evaluate on a subset of DataComp1B.

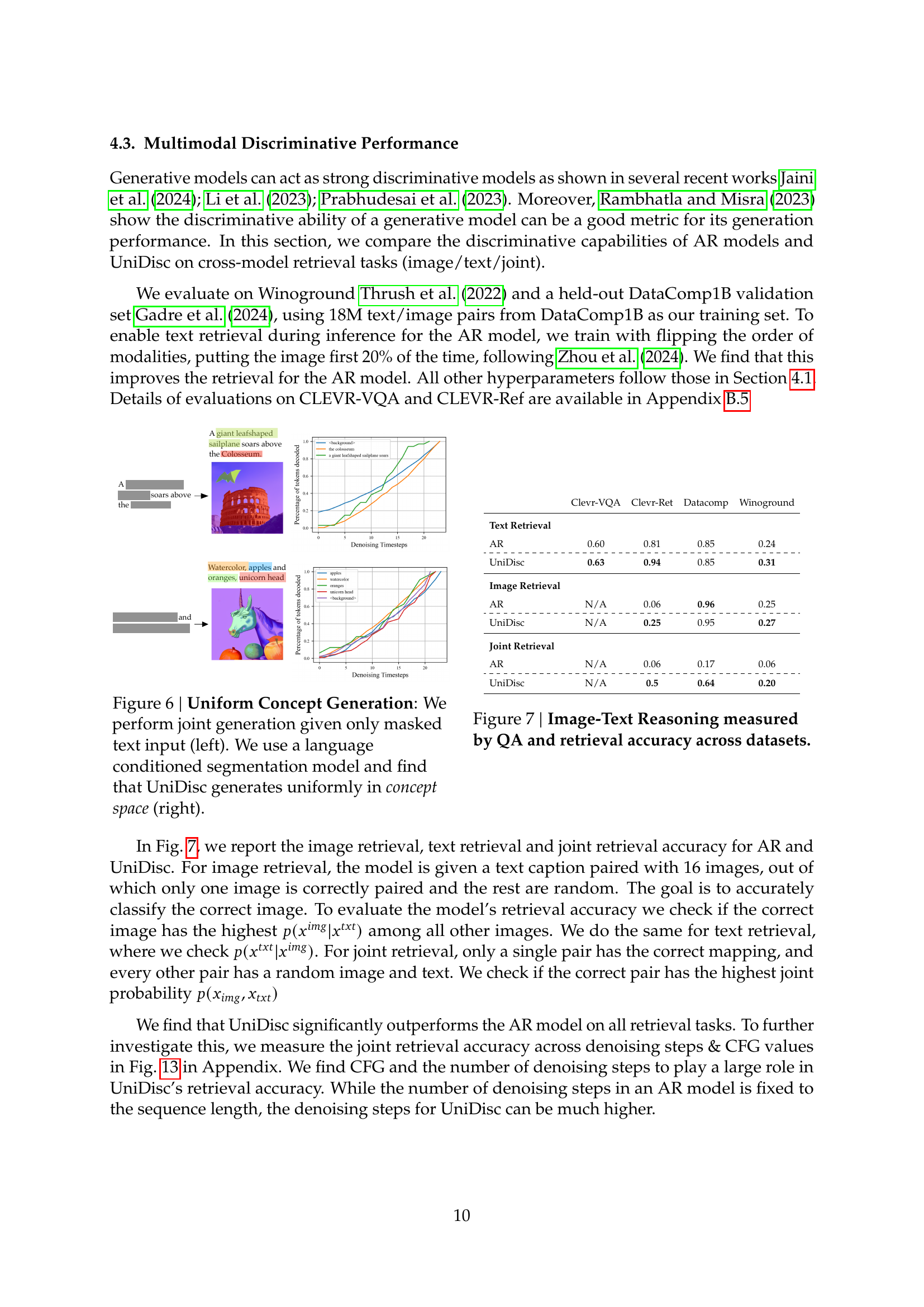
🔼 This figure compares the performance of UniDisc and an autoregressive (AR) model on a joint image-text retrieval task using the DataComp1B dataset. The task involves identifying the correct image-text pair from a set of 16 possible pairs (one correct and 15 incorrect). UniDisc’s superior performance suggests that its unified approach leads to better learned representations, enabling it to more accurately retrieve the correct associations between images and texts.
read the caption
Figure 13: Joint Retrieval Accuracy on DataComp1B. We outperform AR given the task of retrieving one correct image-text pair out of 16 possible pairs, implying better learnt representations.

🔼 This figure shows the results of fine-tuning a pre-trained 270M parameter autoregressive (AR) language model on the LM1B dataset using a discrete diffusion loss function. It compares the training performance of this approach to two baselines: fine-tuning the same model with the standard AR loss and training a new model from scratch using the discrete diffusion loss. The plot displays the training loss over the number of tokens processed, demonstrating that adapting a pre-trained AR model with the discrete diffusion loss function leads to faster convergence and better training efficiency than training from scratch.
read the caption
Figure 14: Fine-tuning a pre-trained 270M parameter AR model on LM1B.

🔼 This figure shows the training loss curve for the 1.4B parameter UniDisc model. The x-axis represents the number of tokens processed during training (in billions), and the y-axis represents the training loss (presumably cross-entropy loss). The curve visually depicts how the model’s training loss decreases as it processes more data during training, indicating the model’s learning progress. Different colored lines might represent different aspects of the loss (e.g., text loss, image loss, combined loss), offering insights into the learning dynamics across different modalities.
read the caption
Figure 15: Training Loss Curve vs. Tokens on our 1.4B model.

🔼 This ablation study investigates the impact of several design choices on a 115M parameter UniDisc model. Specifically, it examines the effects of using Query-Key Normalization (QK Norm) instead of the standard LayerNorm, initializing linear layers with zeros, employing RMSNorm for normalization, handling invalid tokens by setting them to negative infinity (-∞) during both training and generation, and using Softmin SNR. The results quantify the effect of each of these choices on the model’s performance, measured by perplexity on the DataComp1B validation set.
read the caption
Table 3: Ablation w/115M parameter model of QK Norm, zero initialization of linear layers, RMSNorm, setting invalid tokens to −∞-\infty- ∞ during training and generation, and Softmin SNR.

🔼 This table presents ablation study results for a 115M parameter model. The study investigates the impact of different design choices on the model’s performance, specifically focusing on the objective function level. The design choices examined include the noising schedule (how noise is progressively added during the forward diffusion process), loss weighting (how different parts of the loss function contribute to the overall training loss), and whether to use discrete time (modeling time as discrete steps versus a continuous process). By comparing model performance across various combinations of these design choices, the authors aim to understand their individual effects and their interactions, ultimately contributing to the design and optimization of the model.
read the caption
Table 4: Ablation w/115M parameter model on different objective level decisions such as noising schedule, loss weighting and whether to use discrete time.

🔼 This figure showcases UniDisc’s text-to-image generation capabilities. It presents several example images generated from diverse and unseen text prompts, demonstrating the model’s ability to create coherent and visually appealing images based on textual descriptions. The prompts cover a wide range of styles, objects, and scenes, highlighting the model’s versatility and creativity in image synthesis. Each image is accompanied by its corresponding text prompt, illustrating the direct relationship between textual input and visual output.
read the caption
Figure 16: UniDisc’s ability to generate an image, given unseen text as input.
🔼 This figure demonstrates the UniDisc model’s ability to generate captions for images it has never seen before. It showcases the model’s capacity to understand the content of an image and translate that understanding into a coherent and descriptive caption. Each image is presented alongside its automatically generated caption, highlighting the model’s ability to capture various aspects of the visual scene, including objects, actions, and overall atmosphere.
read the caption
Figure 17: UniDisc’s ability to generate text (captioning), given unseen image as input.

🔼 This figure demonstrates UniDisc’s ability to perform zero-shot inpainting. Four examples are shown where a masked region within an image is inpainted using only a textual prompt provided by the user. The results show that the model is able to generate realistic and coherent inpaintings that match both the style and content of the surrounding image, showcasing its multimodal capabilities and ability to understand and generate from textual prompts.
read the caption
Figure 18: Zero-shot text-conditioned inpainting. UniDisc inpaints a masked region given a user-provided text prompt.

🔼 This figure demonstrates UniDisc’s ability to perform zero-shot multimodal inpainting. In the example shown, masked regions in both the image and text are successfully inpainted using only the available context. This highlights the model’s ability to understand and generate coherent multimodal outputs simultaneously, without any specific training for this inpainting task. The results showcases the model’s unified nature and its capacity to leverage the inherent connections between the image and text modalities during the generation process.
read the caption
Figure 19: Zero-shot multimodal inpainting. UniDisc jointly inpaints in both image and text spaces.
More on tables
| Parameters (M) | n_layers | n_heads | d_model |
|---|---|---|---|
| 34 | 11 | 6 | 384 |
| 67 | 11 | 9 | 576 |
| 116 | 12 | 12 | 768 |
| 172 | 20 | 12 | 768 |
| 228 | 20 | 14 | 896 |
| 343 | 24 | 16 | 1024 |
| 484 | 22 | 10 | 1280 |
| 543 | 17 | 12 | 1536 |
| 622 | 29 | 10 | 1280 |
| 713 | 23 | 12 | 1536 |
| 826 | 27 | 12 | 1536 |
| 1074 | 26 | 14 | 1792 |
| 1290 | 24 | 16 | 2048 |
🔼 This table presents different model variants used in the UniDisc experiments. Each row represents a different model configuration, specifying the number of parameters (in millions), the number of layers, number of heads, and the model dimension (d_model). The feed-forward network (FFN) hidden size is consistently four times the d_model value.
read the caption
Table 2: Model variants. The FFN hidden size is always 4x the overall d_modeld_model\operatorname{d\_model}roman_d _ roman_model
| DataComp1B Validation PPL | |
|---|---|
| UniDisc | 93.8 |
| w/o QK Norm | 92.7 |
| w/ Zero-linear init | 93.8 |
| w/o RMSNorm | 93.8 |
| w/o -inf for invalid tokens | 94.7 |
| w/o Softmin SNR | 109.6 |
| None | 111.2 |
🔼 This table presents a quantitative evaluation of the UniDisc model on the GenEval benchmark, which assesses the model’s ability to generate images that accurately reflect various attributes specified in text prompts. The evaluation metrics include Singularity, Two Objects, Counting, Colors, Position, Color Attributes, and an overall score. The table compares UniDisc’s performance to other state-of-the-art models.
read the caption
Table 5: We evaluate UniDisc on the GenEval Ghosh et al. (2023) benchmark.
Full paper#