TL;DR#
The paper addresses the challenge of selectively removing sensitive data from large language models without compromising their performance, a critical issue in AI safety and privacy. Existing unlearning methods often struggle with over-forgetting (excessive elimination of information) or under-forgetting (incomplete removal). It is also difficult to balance performance across multiple evaluation dimensions.
To overcome these limitations, the authors propose a novel unlearning system that leverages model merging. They use TIES-Merging to combine an over-forgetting model with an under-forgetting model, creating a more balanced and effective unlearned model. The system achieved second place in the SemEval-2025 Task 4 competition, demonstrating its effectiveness in selectively removing sensitive content. The paper also provides analyses of the unlearning process, examining performance, loss dynamics and weight perspectives.
Key Takeaways#
Why does it matter?#
This paper is vital for researchers addressing privacy and copyright in AI systems. It highlights the limitations of current unlearning methods and evaluation metrics, paving the way for more robust and comprehensive approaches. The research opens avenues for exploring advanced merging techniques and refining unlearning objectives.
Visual Insights#

🔼 This figure illustrates the model merging technique used for unlearning sensitive information. The top panel shows a vanilla language model, where high probabilities are assigned to data points in the forget set (data to be removed) and low probabilities are given to the holdout data (data to be retained). The middle-left panel displays an ‘over-forgetting’ model, which removes too much information, while the middle-right panel shows an ‘under-forgetting’ model that doesn’t remove enough. The bottom panel depicts the final ‘balanced-forgetting’ model obtained by merging the over-forgetting and under-forgetting models. This merging process reduces the model’s confidence in predicting sensitive data from the forget set while maintaining its performance on the non-sensitive holdout data.
read the caption
Figure 1: Visualizing Unlearning via Model Merging. The vanilla model (top) initially assigns high probabilities to forget set (member) and low probabilities to holdout data (nonmember). We then merge two individually unlearned models: one exhibiting over-forgetting (middle left) and the other under-forgetting (middle right). Model merging aims to achieve balanced forgetting (bottom), effectively reducing the model’s confidence in predicting sensitive member data while preserving its performance on nonmember data.
| Environment | Algorithm | Aggregate | Task Aggregate | MIA Score/MIA AUC | MMLU Avg. |
| Online | AILS-NTUA | 0.706 | 0.827 | 0.847 / – | 0.443 |
| YNU | 0.470 | 0.834 | 0.139 / – | 0.436 | |
| Mr.Snuffleupagus | 0.376 | 0.387 | 0.256 / – | 0.485 | |
| ZJUKLAB (ours) | 0.487 | 0.944 | 0.048 / – | 0.471 | |
| Local | NPO+GDR+KLR () | 0.481 | 0.968 | 0.045 / | 0.431 |
| NPO+GDR+KLR () | 0.504 | 0.659 | 0.364 / | 0.491 | |
| Ours | 0.806 | 0.939 | 0.997 / | 0.480 |
🔼 This table presents a comparison of the online and local experimental results for the ZJUKLAB team’s unlearning system. It shows the aggregate score, task aggregate score, MIA score (with AUC), and MMLU average score for the ZJUKLAB system and several other systems. The symbols ♣ (over-forgetting), ♠ (under-forgetting), and ♡ (balanced forgetting) indicate the bias of different models’ unlearning behavior. The MIA AUC score close to 0.5 signifies a balanced forgetting scenario.
read the caption
Table 1: The online and local experiments results. Note that ♣♣\clubsuit♣ indicates over-forgetting, ♠♠\spadesuit♠ indicates under-forgetting, and ♡♡\heartsuit♡ signifies balanced forgetting, achieving a raw MIA AUC close to 0.5. All metrics are detailed in §2.
In-depth insights#
Model Merging#
Model Merging offers a solution to reduce costs by combining multiple pretrained models. Strategies include parameter averaging (Linear), singular value decomposition (SVD) for low-rank alignment, and feature concatenation (CAT). Advanced variants like TIES trim redundant parameters and resolve sign conflicts, while TIES-SVD integrates SVD for fusion. DARE methods introduce parameter dropout and rescaling, with extensions (DARE-TIES-SVD) combining SVD for structured compression. Magnitude-prune removes low-impact weights, and its SVD variant is compressed via low-rank decomposition.
Unlearning System#
An unlearning system aims to selectively remove sensitive information from models, addressing privacy and copyright concerns. Central to its design is the careful balance between over-forgetting (excessive removal) and under-forgetting (incomplete removal). Model merging emerges as a promising technique, combining specialized models with complementary biases. The goal is to achieve balanced forgetting, effectively reducing the model’s confidence in predicting sensitive data while preserving performance on non-sensitive tasks. Key steps involve a training phase to develop complementary models and a merging phase leveraging techniques to integrate their strengths. Evaluation focuses on metrics that accurately assess both the removal of sensitive knowledge and the retention of general knowledge. Further research should emphasize more comprehensive evaluation methodologies and a re-thinking of unlearning objectives, moving towards on-demand unlearning solutions.
Task Aggregate#
Task Aggregate represents a crucial composite metric. It harmonically combines Regurgitation and Knowledge Scores, offering a balanced view of unlearning efficacy. Regurgitation assesses the removal of sensitive data, while Knowledge gauges the preservation of general knowledge. The harmonic mean ensures that a high score in one area doesn’t mask deficiencies in the other. A strong Task Aggregate implies successful sensitive content removal without sacrificing broader knowledge retention. Analyzing Task Aggregate performance across various unlearning methods and datasets is critical for comprehensive evaluation, highlighting methods excelling in both forgetting and remembering, crucial for practical deployment.
Weight Analysis#
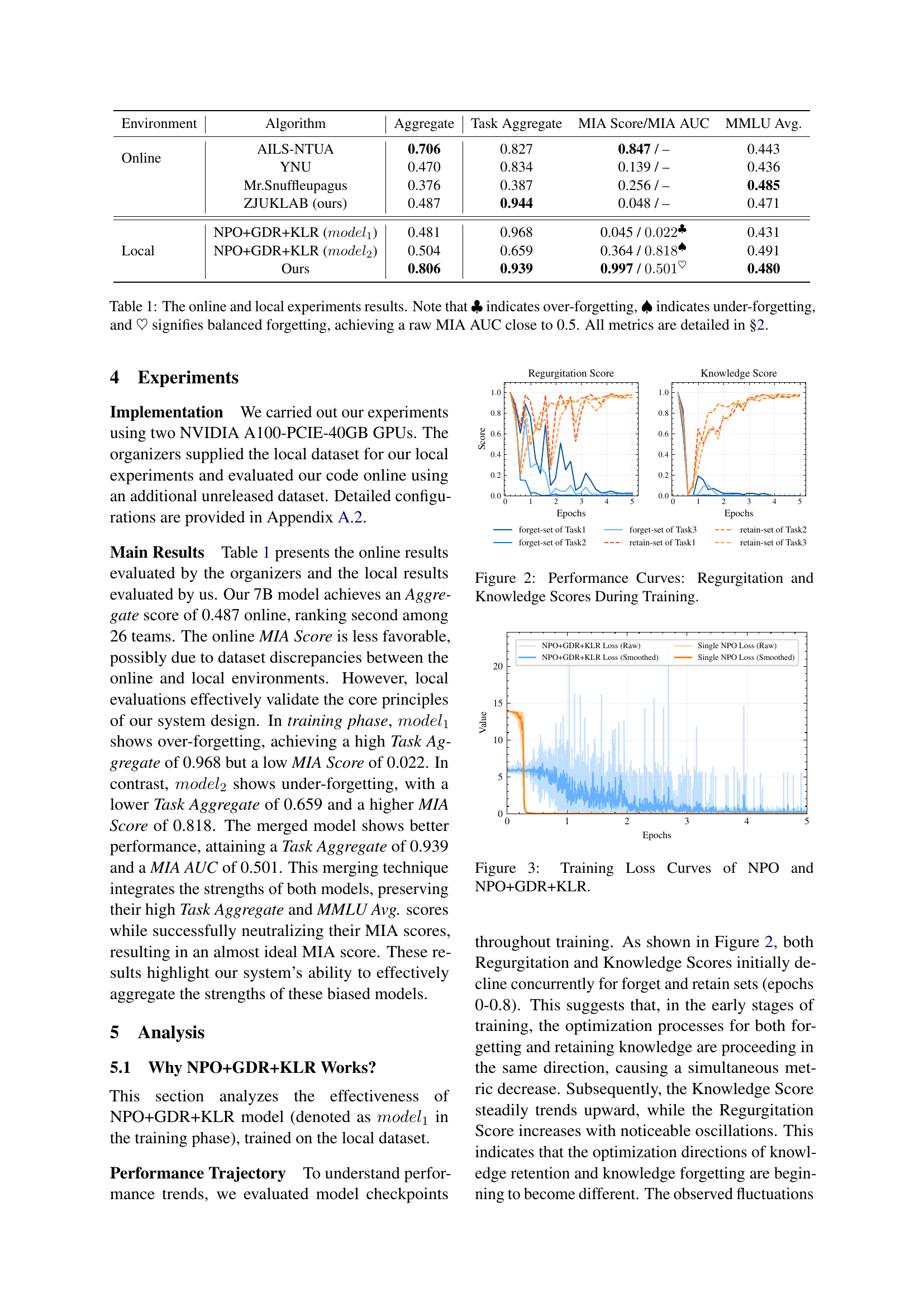
The section analyzes parameter change vectors, focusing on angles between initial (ΔP165) and final (ΔPfinal) weight adjustments. Initial over-forgetting shifts to a balance with retention, reflected in the angle changing from 70-85 degrees. Near orthogonality (90 degrees) between initial and overall optimization direction suggests later retention efforts correct initial “forgetting” bias. This highlights a strategic shift during training, where the model initially prioritizes sensitive content removal but gradually integrates knowledge preservation, showcasing adaptive optimization for balanced unlearning.
Over-forgetting#
The phenomenon of over-forgetting in machine unlearning is a critical concern. It arises when an unlearning method, aiming to remove specific sensitive information, inadvertently eliminates a broader spectrum of knowledge, negatively impacting the model’s overall performance and utility. This can manifest as a model collapse, where the model generates nonsensical or repetitive outputs, failing to generalize to unseen data or retain previously learned general knowledge. It’s crucial to balance the removal of target data with the preservation of valuable information. Over-forgetting can lead to a model that is no longer useful, despite successfully removing the sensitive content. Strategies to mitigate over-forgetting include careful selection of unlearning parameters, targeted interventions that focus on specific knowledge components, and regularization techniques to encourage the retention of relevant information. Furthermore, evaluating unlearning methods requires careful consideration of both forgetting and retention metrics to avoid unintended consequences of over-zealous unlearning.
More visual insights#
More on figures
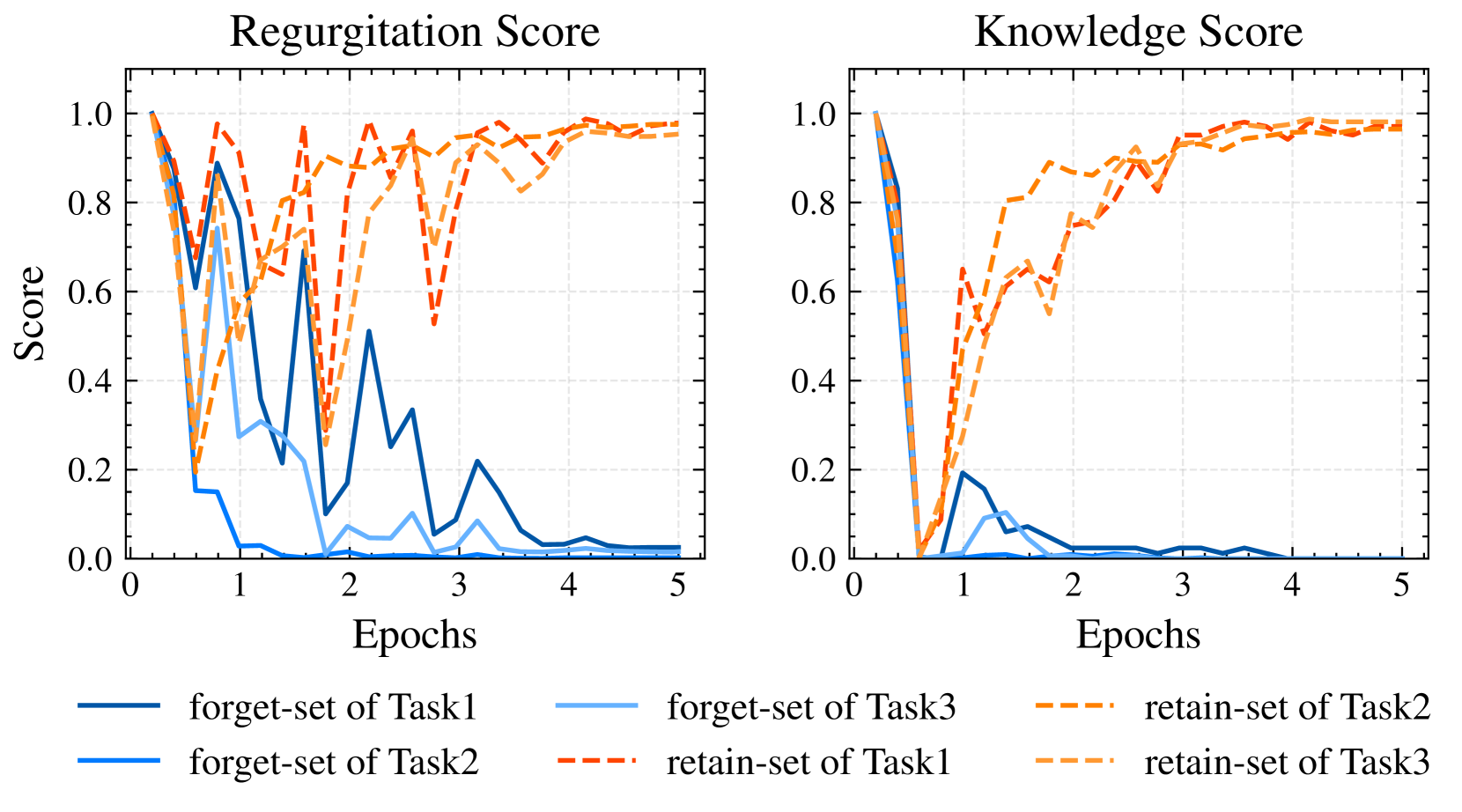
🔼 This figure displays the performance of the model during training, focusing on two key metrics: Regurgitation Score and Knowledge Score. The x-axis represents the training epochs, indicating the progression of training over time. The y-axis shows the scores for both metrics. Separate lines are provided for different tasks (Task 1, Task 2, and Task 3) and whether the data used is the forget set or the retain set. The curves illustrate how the model’s ability to recall (regurgitate) sensitive information from the forget set and its ability to maintain general knowledge from the retain set changes over the course of training. This allows for an analysis of the effectiveness of the training process in achieving the dual goal of removing sensitive information while preserving useful information.
read the caption
Figure 2: Performance Curves: Regurgitation and Knowledge Scores During Training.

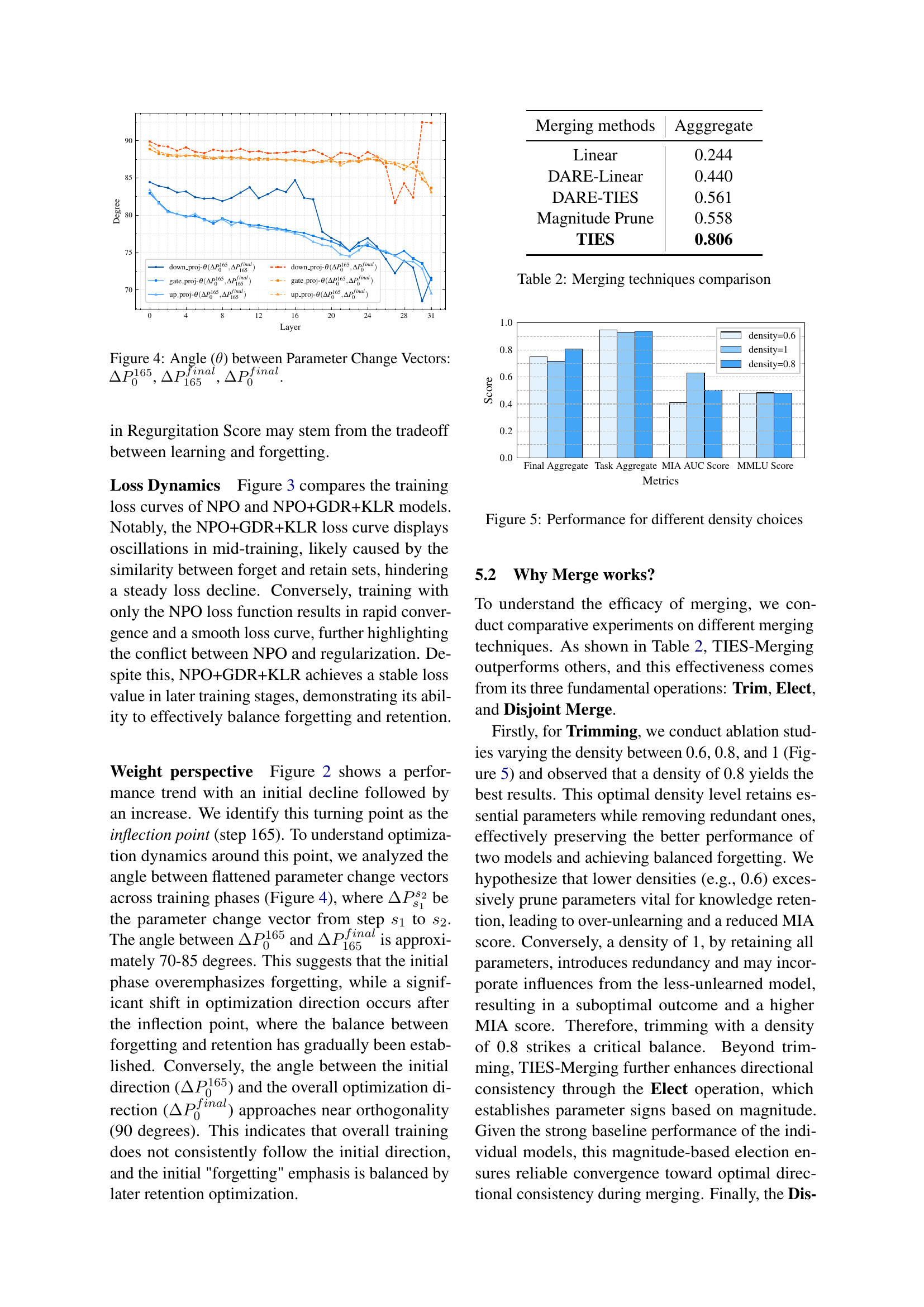
🔼 This figure shows the training loss curves for two different model training approaches: one using only Negative Preference Optimization (NPO) and the other using NPO in combination with Gradient Descent on Retain Set (GDR) and Kullback-Leibler Divergence Minimization on Retain Set (KLR). The graph illustrates how the loss changes over training epochs for each method. By comparing the loss curves, we can observe the effectiveness of adding GDR and KLR to NPO for improving training performance and achieving balanced unlearning.
read the caption
Figure 3: Training Loss Curves of NPO and NPO+GDR+KLR.

🔼 Figure 4 illustrates the angle (θ) between parameter change vectors at different stages of model training. Specifically, it shows the angles between the parameter changes from step 0 to 165 (ΔP₀¹⁶⁵), from step 165 to the final step (ΔP₁₆₅final), and from step 0 to the final step (ΔP₀final). This visualization helps analyze the optimization dynamics during training and understand how the model’s focus shifts between forgetting and retaining knowledge.
read the caption
Figure 4: Angle (θ𝜃\thetaitalic_θ) between Parameter Change Vectors: ΔP0165Δsuperscriptsubscript𝑃0165\Delta P_{0}^{165}roman_Δ italic_P start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT 165 end_POSTSUPERSCRIPT, ΔP165finalΔsuperscriptsubscript𝑃165𝑓𝑖𝑛𝑎𝑙\Delta P_{165}^{final}roman_Δ italic_P start_POSTSUBSCRIPT 165 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_f italic_i italic_n italic_a italic_l end_POSTSUPERSCRIPT, ΔP0finalΔsuperscriptsubscript𝑃0𝑓𝑖𝑛𝑎𝑙\Delta P_{0}^{final}roman_Δ italic_P start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_f italic_i italic_n italic_a italic_l end_POSTSUPERSCRIPT.

🔼 This figure demonstrates the impact of different density choices during the model merging phase on overall performance. The x-axis likely represents different density thresholds used for trimming less important parameters during merging. The y-axis shows various performance metrics, such as aggregate score, task aggregate, MIA AUC score, and MMLU score. The graph visualizes how varying the density affects the balance between retaining important information and removing sensitive data, ultimately revealing the optimal density setting for achieving the best results in the unlearning task.
read the caption
Figure 5: Performance for different density choices
More on tables
| Merging methods | Agggregate |
|---|---|
| Linear | 0.244 |
| DARE-Linear | 0.440 |
| DARE-TIES | 0.561 |
| Magnitude Prune | 0.558 |
| TIES | 0.806 |
🔼 This table compares the performance of different model merging techniques on the task of unlearning sensitive content from large language models. The techniques compared include simple linear merging, DARE-Linear, DARE-TIES, Magnitude Prune, and TIES-Merging. The evaluation metric is the aggregate score, indicating the overall effectiveness of each method in balancing the removal of sensitive information with the preservation of non-sensitive knowledge.
read the caption
Table 2: Merging techniques comparison
| Parameter | Model1 | Model2 |
|---|---|---|
| batch_size | 1 | 2 |
| gradient_accumulation | 4 | 4 |
| num_epochs | 5 | 5 |
| lr | ||
| max_length | 256 | 256 |
| weight_decay | 0.01 | 0.01 |
| seed | 42 | 42 |
| ga_ratio | 0.4 | 0.3 |
| gd_ratio | 0.4 | 0.3 |
| gk_ratio | 0.2 | 0.4 |
| LoRA_r | 32 | 32 |
| LoRA_alpha | 32 | 32 |
| LoRA_dropout | 0.05 | 0.05 |
🔼 This table details the specific hyperparameter settings used during the training phase of the unlearning model. It includes parameters like batch size, gradient accumulation steps, learning rate, maximum sequence length, weight decay, and various parameters specific to the LoRA (Low-Rank Adaptation) technique employed for model optimization. The table showcases two different model configurations (Model 1 and Model 2), highlighting the variations used in the training of the two complementary models used in the model merging approach for unlearning.
read the caption
Table 3: Complete Hyperparameters Configuration.
Full paper#