TL;DR#
Real-time interactive video-chat portraits have gained traction. Existing methods primarily focus on generating head movements, often struggling with synchronized body motions and fine-grained control over facial expressions. To address these issues, this paper presents a framework for stylized real-time portrait video generation, enabling flexible video chat that extends to upper-body interactions.
The approach involves efficient hierarchical motion diffusion models that account for both explicit and implicit motion representations based on audio inputs, generating diverse facial expressions and synchronized head and body movements. The system supports efficient and continuous generation of upper-body portrait video, achieving 30fps on a 4090 GPU, which supports interactive video-chat in real-time.
Key Takeaways#
Why does it matter?#
This paper introduces a real-time portrait video generation framework called ChatAnyone, enabling natural & expressive upper-body movements and facial expressions. It is significant for creating immersive digital interactions, and also sets the stage for future work in virtual avatars and human-computer interfaces.
Visual Insights#

🔼 This figure demonstrates the real-time portrait video generation capabilities of the ChatAnyone model. The input consists of a single portrait image and an audio sequence. The output is a high-fidelity video of a full head and upper body avatar, exhibiting realistic and diverse facial expressions. The model allows for control over the style of the generated video.
read the caption
Figure 1: Illustration of real-time portrait video generation. Given a portrait image and audio sequence as input, our model can generate high-fidelity animation results from full head to upper-body interaction with diverse facial expressions and style control.
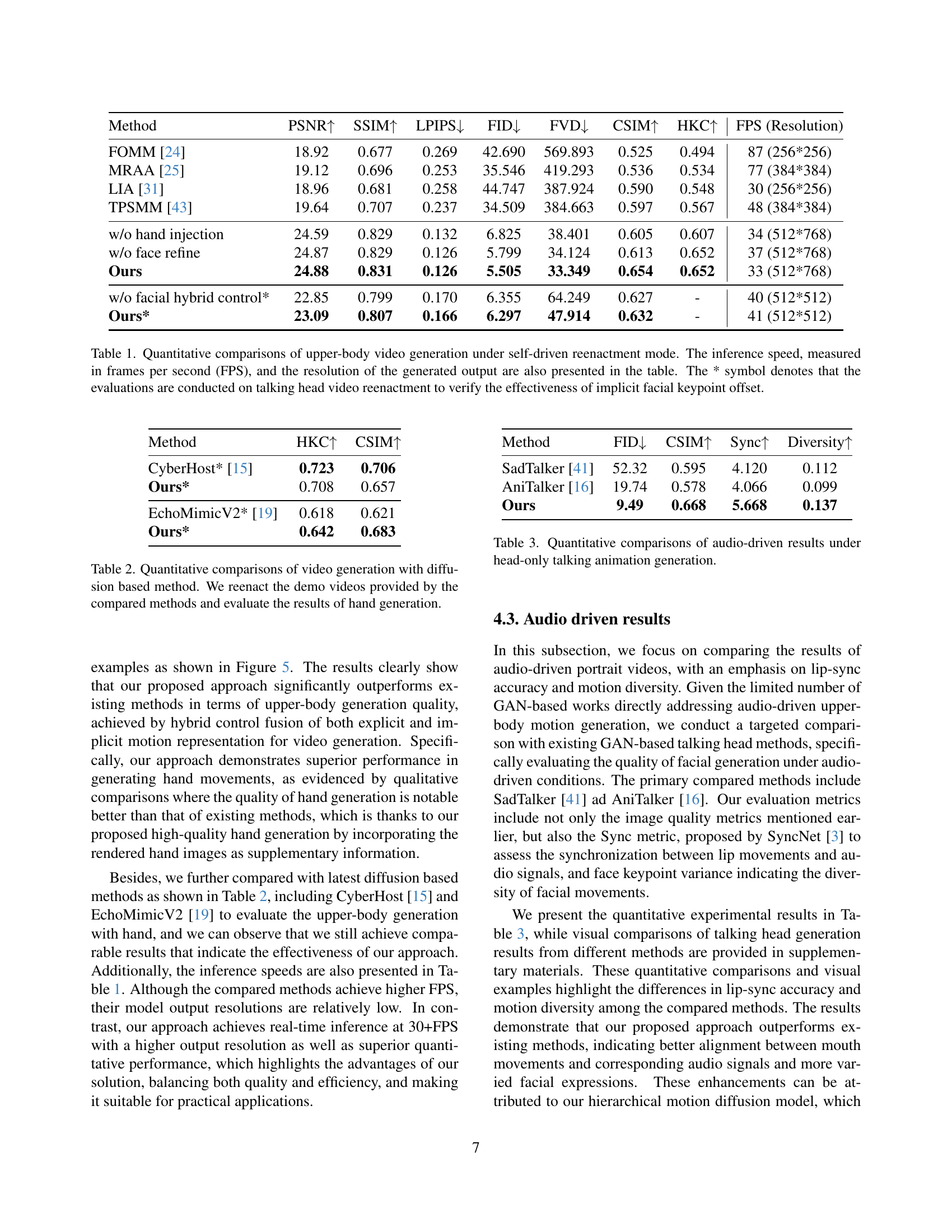
| Method | PSNR | SSIM | LPIPS | FID | FVD | CSIM | HKC | FPS (Resolution) |
|---|---|---|---|---|---|---|---|---|
| FOMM [24] | 18.92 | 0.677 | 0.269 | 42.690 | 569.893 | 0.525 | 0.494 | 87 (256*256) |
| MRAA [25] | 19.12 | 0.696 | 0.253 | 35.546 | 419.293 | 0.536 | 0.534 | 77 (384*384) |
| LIA [31] | 18.96 | 0.681 | 0.258 | 44.747 | 387.924 | 0.590 | 0.548 | 30 (256*256) |
| TPSMM [43] | 19.64 | 0.707 | 0.237 | 34.509 | 384.663 | 0.597 | 0.567 | 48 (384*384) |
| w/o hand injection | 24.59 | 0.829 | 0.132 | 6.825 | 38.401 | 0.605 | 0.607 | 34 (512*768) |
| w/o face refine | 24.87 | 0.829 | 0.126 | 5.799 | 34.124 | 0.613 | 0.652 | 37 (512*768) |
| Ours | 24.88 | 0.831 | 0.126 | 5.505 | 33.349 | 0.654 | 0.652 | 33 (512*768) |
| w/o facial hybrid control* | 22.85 | 0.799 | 0.170 | 6.355 | 64.249 | 0.627 | - | 40 (512*512) |
| Ours* | 23.09 | 0.807 | 0.166 | 6.297 | 47.914 | 0.632 | - | 41 (512*512) |
🔼 This table presents a quantitative comparison of several methods for generating upper-body videos from a single image using a self-driven reenactment approach. The comparison includes metrics such as PSNR, SSIM, LPIPS, FID, FVD, CSIM, and HKC, assessing the visual quality and accuracy of the generated videos. The table also shows the inference speed in frames per second (FPS) and the resolution of the generated videos for each method. Note that results marked with an asterisk (*) used talking head video reenactment to specifically evaluate the effectiveness of the implicit facial keypoint offset technique.
read the caption
Table 1: Quantitative comparisons of upper-body video generation under self-driven reenactment mode. The inference speed, measured in frames per second (FPS), and the resolution of the generated output are also presented in the table. The * symbol denotes that the evaluations are conducted on talking head video reenactment to verify the effectiveness of implicit facial keypoint offset.
In-depth insights#
Hierarchical Gen#
Hierarchical generation could refer to a multi-stage or layered approach in generative models, where outputs are refined progressively. In video or image generation, this might involve creating a low-resolution base and then adding details in subsequent steps. The hierarchy could also relate to control, with high-level parameters setting the overall style or content and lower-level parameters controlling specific details. Such a structure allows for efficient generation and editing, as changes at a high level propagate to all subsequent levels, while changes at a low level only affect local details. This aligns well with how humans create complex outputs, starting with broad strokes and adding refinements. This enables control and coherence.
Hybrid Control#
The concept of “Hybrid Control” in the context of portrait video generation likely refers to the combined use of explicit and implicit control mechanisms to achieve more nuanced and realistic facial expressions and body movements. Explicit control might involve using parameters like 3DMM coefficients or facial landmarks to directly manipulate specific features, offering precise control but potentially lacking fine-grained detail. Implicit control, on the other hand, could involve using latent variables or learned representations to capture subtle variations and styles, providing richer expressiveness but with less direct control. A hybrid approach aims to leverage the strengths of both, using explicit controls for overall structure and implicit controls for detail and style, ultimately leading to more controllable and expressive portrait videos. This fusion allows for detailed manipulation of features while keeping the capacity to represent subtle expressions.
Real-time GAN#
Real-time GANs represent a significant area of research, focusing on achieving fast and efficient image and video generation. Traditional GANs often suffer from high computational costs, making them unsuitable for real-time applications. Research in this area aims to optimize GAN architectures and training methods to reduce inference time while maintaining high-quality output. Techniques include model compression, efficient network designs, and optimized training strategies. This is crucial for applications like real-time video editing, interactive gaming, and live streaming, where low latency is essential. The challenge lies in balancing speed and quality, as aggressive optimization can sometimes lead to a reduction in the visual fidelity of the generated content. Success in real-time GANs would enable more interactive and responsive AI-driven experiences.
Style Transfer#
While not explicitly a standalone section, the concept of style transfer is woven into the core of the research. The paper leverages it primarily within the facial motion prediction stage. By conditioning the audio-driven motion diffusion model on a reference video, the framework gains the ability to imbue the generated portrait video with the stylistic nuances of the reference. This means that aspects like expressiveness intensity, subtle emotional cues, or even idiosyncratic head movements seen in the reference can be transferred to the generated avatar. This is achieved through Adaptive Layer Normalization(AdaLN). This allows for a more personalized and controllable output, going beyond simple audio-to-motion mapping. The effectiveness is shown that injecting expression information from reference video can improve the similarity to ground-truth. Further, the ablation study validates the influence of explicitly controlling the magnitude of expressions.
Upper-Body Focus#
Focusing on the upper body in video generation tasks is crucial for creating realistic and engaging digital interactions. Unlike traditional methods that primarily address head movements and facial expressions, a dedicated approach to the upper body allows for the incorporation of natural body language, hand gestures, and subtle postural adjustments. This enhancement significantly contributes to the overall expressiveness and authenticity of the generated video. Accurate upper-body motion is critical for synchronizing with speech and conveying emotional nuances. Moreover, an upper-body focus enables a broader range of applications beyond simple talking head scenarios, such as virtual avatars, live streaming, and augmented reality, thereby enhancing user engagement and immersion. Challenges include capturing the complex interplay between facial expressions, head movements, and body language, as well as ensuring realistic hand gestures and seamless integration of the upper body with the overall scene. Effective solutions often involve advanced techniques for motion capture, body pose estimation, and realistic rendering of clothing and skin textures. The goal is to generate upper-body movements that are not only visually appealing but also contextually relevant and emotionally expressive.
More visual insights#
More on figures

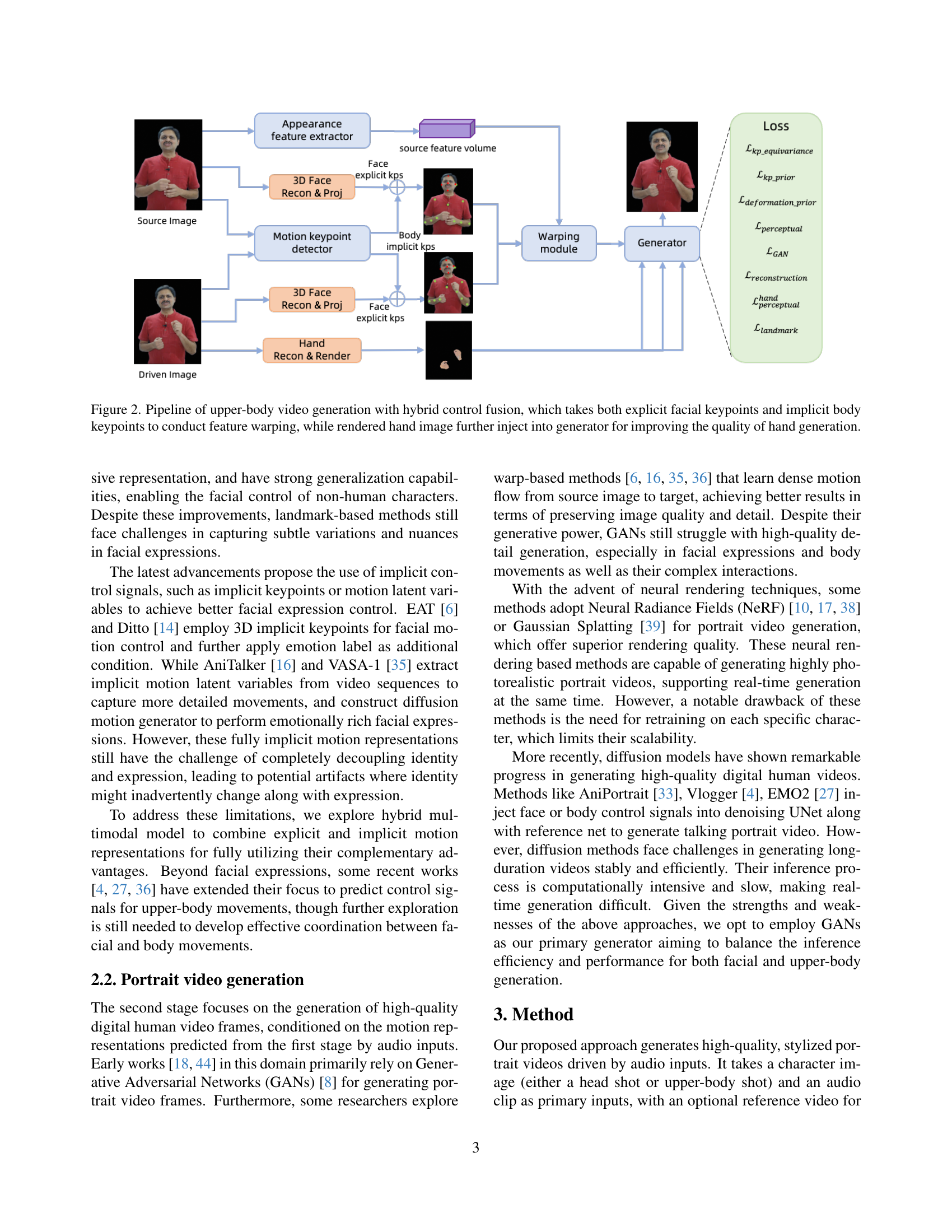
🔼 This figure illustrates the pipeline for generating upper-body videos. It starts with a source image which undergoes feature extraction. Simultaneously, facial keypoints (explicit control) and body keypoints (implicit control) are extracted from the source image. These keypoints, along with rendered hand images (providing additional detailed hand control), are then used to guide a warping module. This warping module distorts the appearance features based on the motion information extracted from the keypoints. The warped features are fed into a generator which produces the final upper-body video output, leveraging both explicit and implicit control signals for refined control over facial expressions and body movements.
read the caption
Figure 2: Pipeline of upper-body video generation with hybrid control fusion, which takes both explicit facial keypoints and implicit body keypoints to conduct feature warping, while rendered hand image further inject into generator for improving the quality of hand generation.

🔼 Figure 3 illustrates the hierarchical audio2motion diffusion model. The bottom part shows facial motion prediction, which includes style control mechanisms such as reference sequence injection for style transfer. The top section shows upper-body motion prediction, driven by the output of the facial motion prediction module and audio input. This upper-body module also incorporates hand motion generation using hand coefficients from a MANO template. The model uses a combination of cross-attention mechanisms and adaptive layer normalization to effectively combine audio features and motion information at each level.
read the caption
Figure 3: Illustration of hierarchical audio2motion diffusion model, including facial motion prediction with style control at bottom, and upper-body motion prediction with hands at top.

🔼 Figure 4 illustrates the architecture of a face refinement network used to enhance the realism of generated facial expressions. The network takes as input both explicit and implicit facial keypoints. Explicit keypoints provide coarse control, while implicit offsets refine the position of the keypoints, leading to more precise and natural facial expressions. The right side of the figure visually demonstrates how the addition of implicit offsets leads to a more accurate representation of facial keypoint locations compared to using only explicit keypoints.
read the caption
Figure 4: Illustration of face refine network, the left of figure shows the architecture, while the right demonstrates that more precise facial keypoints are located by adding implicit offset.
More on tables
🔼 This table quantitatively compares the hand generation quality of several video generation methods based on diffusion models. The comparison is performed by reenacting demo videos from existing methods and then assessing the resulting hand gestures using specific metrics. This provides insights into the relative performance of different diffusion-based approaches in generating realistic and detailed hand movements within generated videos.
read the caption
Table 2: Quantitative comparisons of video generation with diffusion based method. We reenact the demo videos provided by the compared methods and evaluate the results of hand generation.
| Method | FID | CSIM | Sync | Diversity |
|---|---|---|---|---|
| SadTalker [41] | 52.32 | 0.595 | 4.120 | 0.112 |
| AniTalker [16] | 19.74 | 0.578 | 4.066 | 0.099 |
| Ours | 9.49 | 0.668 | 5.668 | 0.137 |
🔼 This table presents a quantitative comparison of the results obtained from generating head-only talking animations driven by audio input. It compares various metrics to assess the quality and realism of different approaches, focusing specifically on the accuracy of lip synchronization and the diversity of facial expressions generated.
read the caption
Table 3: Quantitative comparisons of audio-driven results under head-only talking animation generation.
| Method | MAE | SSIM |
|---|---|---|
| w/o style transfer | 0.074 | 0.373 |
| Ours | 0.049 | 0.709 |
🔼 This table presents a comparison of the effectiveness of style transfer using a reference video. It shows the Mean Absolute Error (MAE) and Structural Similarity Index (SSIM) values calculated for facial coefficients predicted by the audio-to-motion model. Lower MAE indicates better accuracy and higher SSIM represents improved visual similarity between the generated and reference video’s facial expressions. The comparison allows for assessing the impact of style transfer on the model’s ability to generate visually consistent and stylistically coherent facial animations.
read the caption
Table 4: Comparison on reference style transfer, calculated on the face coefficients predicted from audio2motion model.
Full paper#