Existing benchmarks for evaluating LLMs’ mathematical reasoning are becoming saturated. The rapid development of LLMs necessitates more challenging and rigorous evaluations to identify their limitations and guide future improvements. Current benchmarks struggle to differentiate capabilities and multilingual assessment is also lacking.
This paper introduces OlymMATH, a new Olympiad-level math benchmark to rigorously test LLMs’ reasoning. OlymMATH has 200 problems with varying difficulty, manually verified and available in both English and Chinese. Experiments show that models like DeepSeek-R1 struggle with OlymMATH, highlighting its difficulty. The benchmark facilitates bilingual assessment and the analysis helps understand limitations in solving complex math problems.
This paper introduces a new Olympiad-level math benchmark for LLMs, addressing limitations in existing benchmarks. It offers rigorous evaluations, bilingual assessment, and insights into models’ reasoning abilities, opening new research avenues to improve LLMs in mathematical problem-solving.
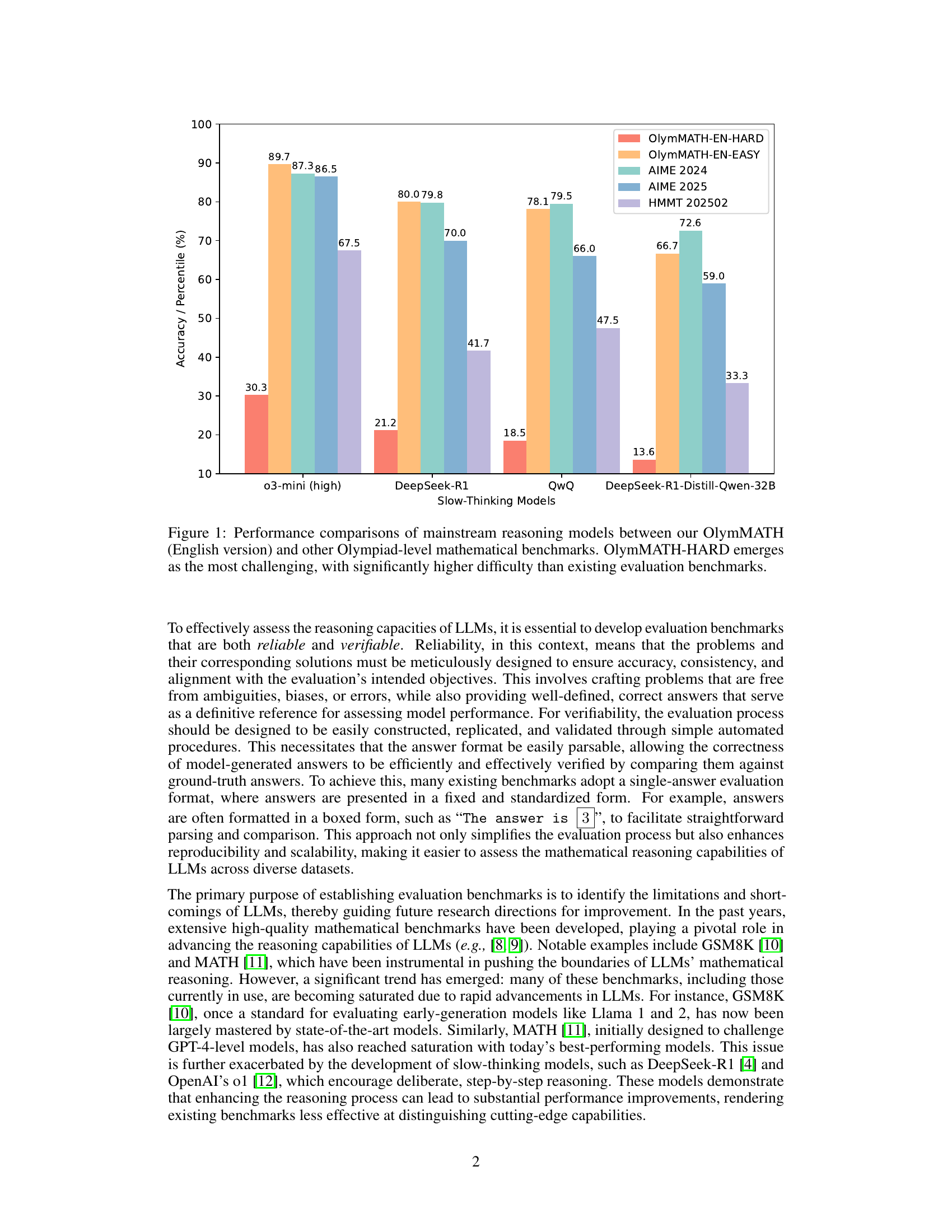
🔼 This figure compares the performance of several large language models (LLMs) on various Olympiad-level mathematics benchmarks, including the OlymMATH benchmark (English version) introduced in this paper. The x-axis shows the different models tested, and the y-axis displays their accuracy (or percentile) on each benchmark. The bars are grouped by benchmark: OlymMATH-EN-EASY, OlymMATH-EN-HARD (the new benchmark proposed in the paper), and other existing Olympiad-level benchmarks like AIME 2024, AIME 2025, and HMMT 202502. The figure highlights that the OlymMATH-HARD subset is significantly more challenging than existing benchmarks, with even the state-of-the-art models showing considerably lower accuracy on this subset.
read the captionFigure 1: Performance comparisons of mainstream reasoning models between our OlymMATH (English version) and other Olympiad-level mathematical benchmarks. OlymMATH-HARD emerges as the most challenging, with significantly higher difficulty than existing evaluation benchmarks.
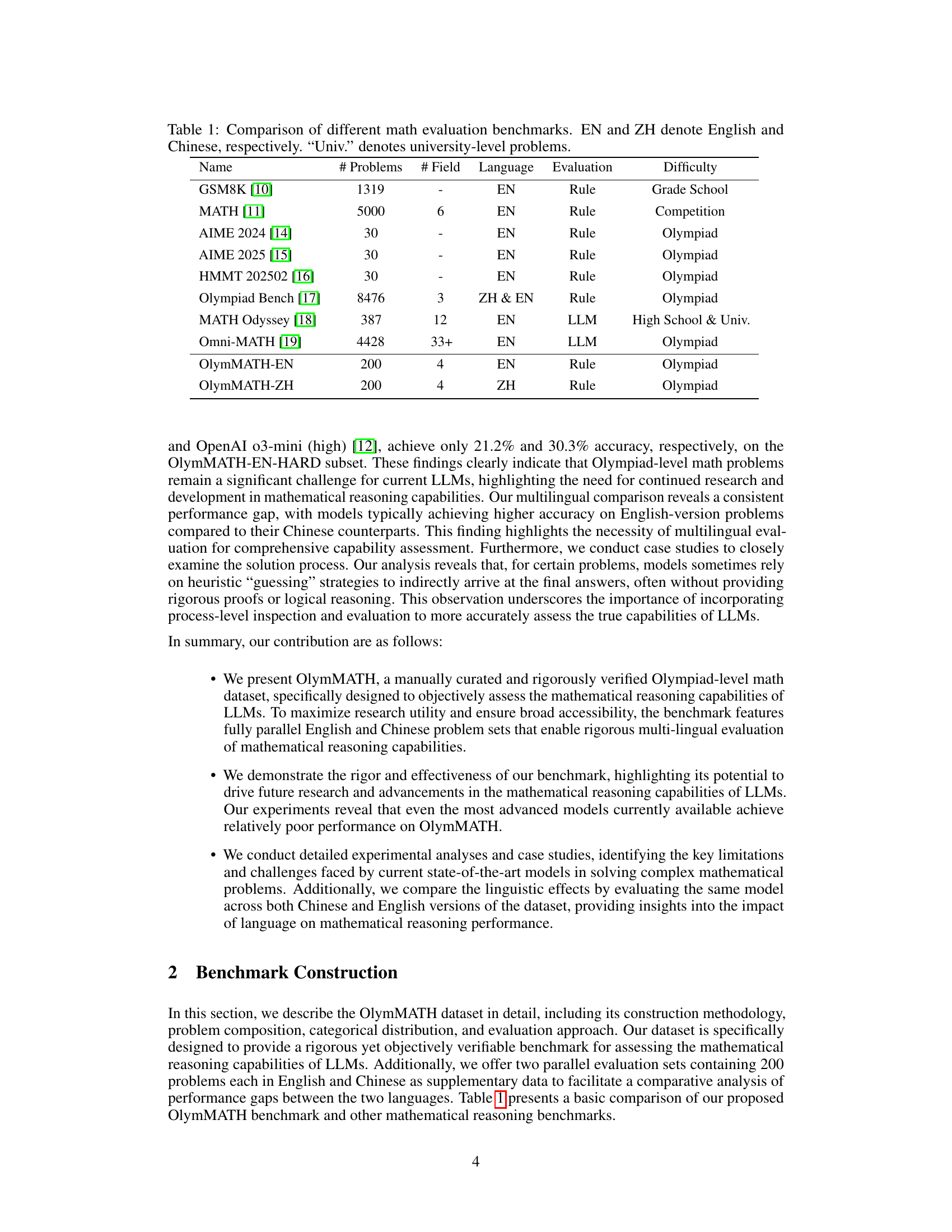
🔼 This table compares various mathematical reasoning benchmarks used to evaluate large language models (LLMs). It lists the name of each benchmark, the number of problems it contains, the number of mathematical fields covered, the languages supported (English, Chinese, or both), the evaluation method used (rule-based or LLM-based), and the difficulty level of the problems (grade school, competition, university, or Olympiad). This allows for a comparison of benchmark scale, scope, and difficulty.
read the captionTable 1: Comparison of different math evaluation benchmarks. EN and ZH denote English and Chinese, respectively. “Univ.” denotes university-level problems.
The introduction of OlymMATH addresses a critical gap in evaluating LLMs’ mathematical reasoning. Existing benchmarks are becoming saturated, failing to challenge advanced models effectively. OlymMATH, an Olympiad-level benchmark, aims to rigorously test complex reasoning. Its key features include meticulously curated problems, manual verification, parallel English and Chinese versions for comprehensive bilingual assessment, and two distinct difficulty tiers: AIME-level (easy) and significantly more challenging (hard). The problems span four core mathematical fields, each with verifiable numerical solutions for objective evaluation. Initial results show state-of-the-art models struggle with OlymMATH, particularly the hard subset, indicating its higher difficulty and potential to push the boundaries of mathematical reasoning evaluation.
LLM reasoning gaps signify the disparities between expected and actual performance in complex tasks. These gaps often manifest in areas requiring multi-step inference, nuanced understanding of context, and the ability to handle ambiguity. Current LLMs, while excelling in pattern recognition, often struggle with causal reasoning, analogical thinking, and counterfactual simulations, exhibiting limitations in systematic generalization and transfer learning. Addressing these gaps necessitates innovations in model architectures, training methodologies, and evaluation benchmarks to better assess and enhance true reasoning capabilities. The focus should be on developing models that can robustly handle novel situations and exhibit more human-like reasoning proficiency.
A bilingual analysis of mathematical reasoning models offers a potent lens for evaluating their capabilities. By assessing performance across both English and Chinese, we can discern the influence of language on problem-solving efficacy. Differences in linguistic structure, cultural context embedded in problems, and the nuances of mathematical terminology across languages can all contribute to variations in a model’s accuracy and efficiency. Furthermore, a bilingual approach helps mitigate biases inherent in datasets predominantly available in one language, fostering more robust and equitable evaluations. Observing performance gaps highlights the need for enhanced multilingual training, ensuring that models generalize effectively across diverse linguistic landscapes and achieve true cross-cultural reasoning proficiency.
In analyzing the dataset details, several key aspects emerge. First, the paper emphasizes the high-quality and original nature of the Olympiad-level problems, meticulously curated from printed resources to minimize data contamination, with problems manually sourced from specialized magazines, textbooks, and official competition materials. The dataset spans four primary mathematical fields—algebra, geometry, number theory, and combinatorics—to ensure comprehensive coverage of reasoning skills. Problems are categorized into two difficulty levels: easy and hard, with the former challenging standard prompting approaches and the latter testing advanced reasoning capabilities, such as slow-thinking modes. The dataset adheres to a format aligning with the MATH dataset, ensuring seamless integration with existing benchmarks and evaluation pipelines. It restricts answers to real numbers and intervals and also deliberately excludes other answer formats such as set operations, variables, complex numbers, and free-form text for easy evaluation. Furthermore, it specifically curates problems that yield challenging numerical answers and provides a summary of all potential outcomes, such as sums, sums of squares, and more.
When introducing a new benchmark, it’s crucial to establish its uniqueness and value proposition compared to existing ones. This involves highlighting specific gaps it addresses, like handling complex reasoning or multilingual capabilities. A new benchmark’s design should minimize biases and ensure reliability through rigorous problem curation and validation. Additionally, its difficulty level must be calibrated to challenge current models without being insurmountable. The benchmark’s format and evaluation metrics should be clearly defined and easily reproducible, facilitating broader adoption and comparison. Also, the diversity of problem types is key to ensure a variety of scenarios. Finally, releasing a new benchmark should be accompanied by an analysis of its performance against state-of-the-art models, demonstrating its effectiveness in differentiating model capabilities and guiding future research.
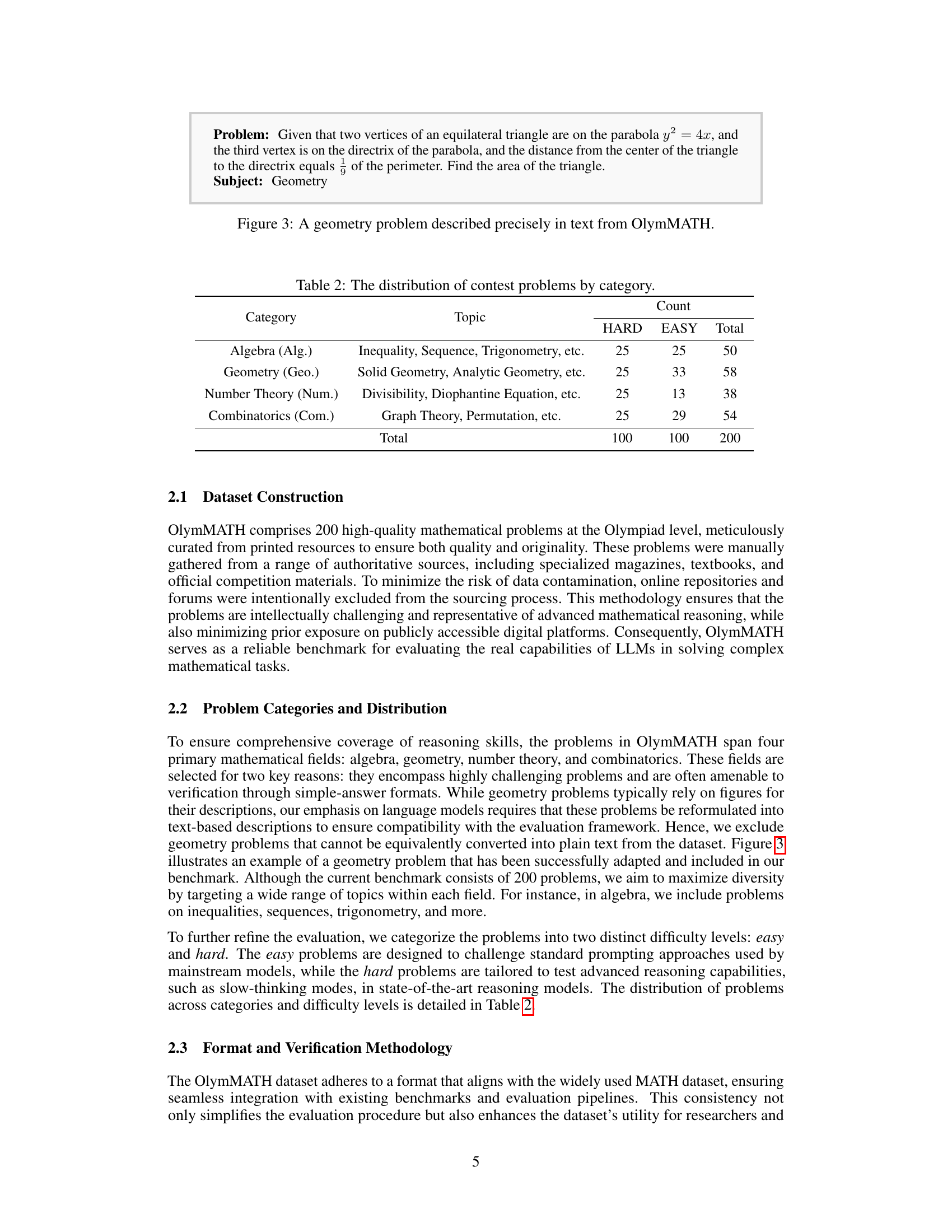
🔼 This table presents a geometry problem from the OlymMATH dataset. The problem is described entirely in text, illustrating the dataset’s focus on textual problem representation, even for subjects like geometry that traditionally rely on diagrams. This exemplifies the OlymMATH design principle of ensuring that all problems are amenable to evaluation via language models, facilitating a fair and consistent assessment of LLMs’ reasoning capabilities.
read the captionFigure 3: A geometry problem described precisely in text from OlymMATH.
🔼 This table shows the distribution of the 200 problems in the OlymMATH benchmark across four mathematical categories (Algebra, Geometry, Number Theory, and Combinatorics) and two difficulty levels (Easy and Hard). It provides the counts of problems for each category and difficulty level combination, and the total number of problems in each category.
read the captionTable 2: The distribution of contest problems by category.
Models
Pass@1
Cons@10
Alg.
Geo.
Num.
Com.
Avg.
Alg.
Geo.
Num.
Com.
Avg.
The Hard Subset
Qwen2.5-32B-R1D
17.2
18.8
17.6
0.8
13.6
36.0
20.0
24.0
0.0
20.0
QwQ-32B
25.6
18.4
24.8
5.2
18.5
36.0
12.0
24.0
4.0
19.0
DeepSeek-R1
32.8
28.8
19.2
4.0
21.2
48.0
36.0
24.0
4.0
28.0
o3-mini (high)
24.0
32.7
44.7
20.0
30.3
/
/
/
/
/
The Easy Subset
Qwen2.5-32B-R1D
73.6
69.1
88.5
48.3
66.7
92.0
97.0
92.3
58.6
84.0
QwQ-32B
84.8
79.7
83.8
67.9
78.1
96.0
100.0
92.3
79.3
92.0
DeepSeek-R1
88.4
84.8
90.8
62.4
80.0
100.0
97.0
92.3
75.9
91.0
o3-mini (high)
90.0
89.4
100.0
85.1
89.7
/
/
/
/
/
🔼 This table details the acceptable and unacceptable answer formats for the OlymMATH benchmark. Acceptable formats are limited to single real numbers, intervals (ranges), and sets of numbers. Unacceptable formats include set operations (union, intersection, etc.), variables (symbols representing unknown values), complex numbers, and any text-based answers. This restriction ensures consistency and ease of automated evaluation.
read the captionTable 3: The included and excluded formats of the final answer.
Models
Pass@1
Cons@10
Alg.
Geo.
Num.
Com.
Avg.
Alg.
Geo.
Num.
Com.
Avg.
The Hard Subset
Qwen2.5-32B-R1D
5.6
6.8
8.0
1.2
5.4
4.0
8.0
12.0
0.0
6.0
QwQ-32B
19.6
12.4
15.2
1.2
12.1
16.0
12.0
24.0
0.0
13.0
DeepSeek-R1
21.6
24.4
16.8
1.6
16.1
20.0
36.0
20.0
0.0
19.0
o3-mini (high)
22.0
26.0
48.7
12.0
27.2
/
/
/
/
/
The Easy Subset
Qwen2.5-32B-R1D
45.2
40.3
54.6
23.4
38.5
56.0
57.6
61.5
31.0
50.0
QwQ-32B
76.8
73.3
87.7
48.6
68.9
92.0
97.0
92.3
62.1
85.0
DeepSeek-R1
79.2
74.8
93.1
50.7
71.3
92.0
90.9
100.0
65.5
85.0
o3-mini (high)
88.0
92.4
96.2
79.9
88.2
/
/
/
/
/
🔼 This figure displays a sample problem from the OlymMATH-HARD subset of the benchmark. It’s designed to evaluate whether large language models (LLMs) can correctly identify and provide all possible solutions to a complex mathematical problem, rather than just finding a single valid answer. The problem’s complexity and the requirement to find all possible answers make this a rigorous test of the model’s true reasoning capabilities.
read the captionFigure 4: An example from OlymMATH-HARD designed to assess whether the model can identify all possible answers.
Benchmarks
o3-mini (high)
DeepSeek-R1
QwQ-32B
Qwen2.5-32B-R1D
MATH-500
/
97.3∗
/
94.3∗
AIME 2024
87.3∗
79.8∗
79.5∗
72.6∗
AIME 2025
86.5∗
70.0∗
66.0∗
59.0∗
HMMT 202502
67.5∗
41.7∗
47.5∗
33.3∗
OlymMATH-EN-HARD
30.3
21.2
18.5
13.6
OlymMATH-EN-EASY
89.7
80.0
78.1
66.7
OlymMATH-ZH-HARD
27.2
16.1
12.1
5.4
OlymMATH-ZH-EASY
88.2
71.3
68.9
38.5
🔼 This table shows an example of the structured format used to present problems and answers in the OlymMATH dataset. It demonstrates the parallel presentation of problems and solutions in both English and Chinese, illustrating the bilingual nature of the dataset. The table includes problem statements, answers, and subject categories, highlighting the consistency in data structure across languages.
read the captionFigure 5: Example of the format used in OlymMATH.
Dataset
Avg. Output Length
Avg. Reasoning Length
Correct
Incorrect
Total
Correct
Incorrect
Total
AIME 2024
1591
1707
1617
19958
50836
26820
AIME 2025
1547
1625
1575
23350
53006
33894
OlymMATH-EN-HARD
1608
1610
1610
39024
43850
42827
OlymMATH-EN-EASY
1588
1594
1589
29132
46008
32507
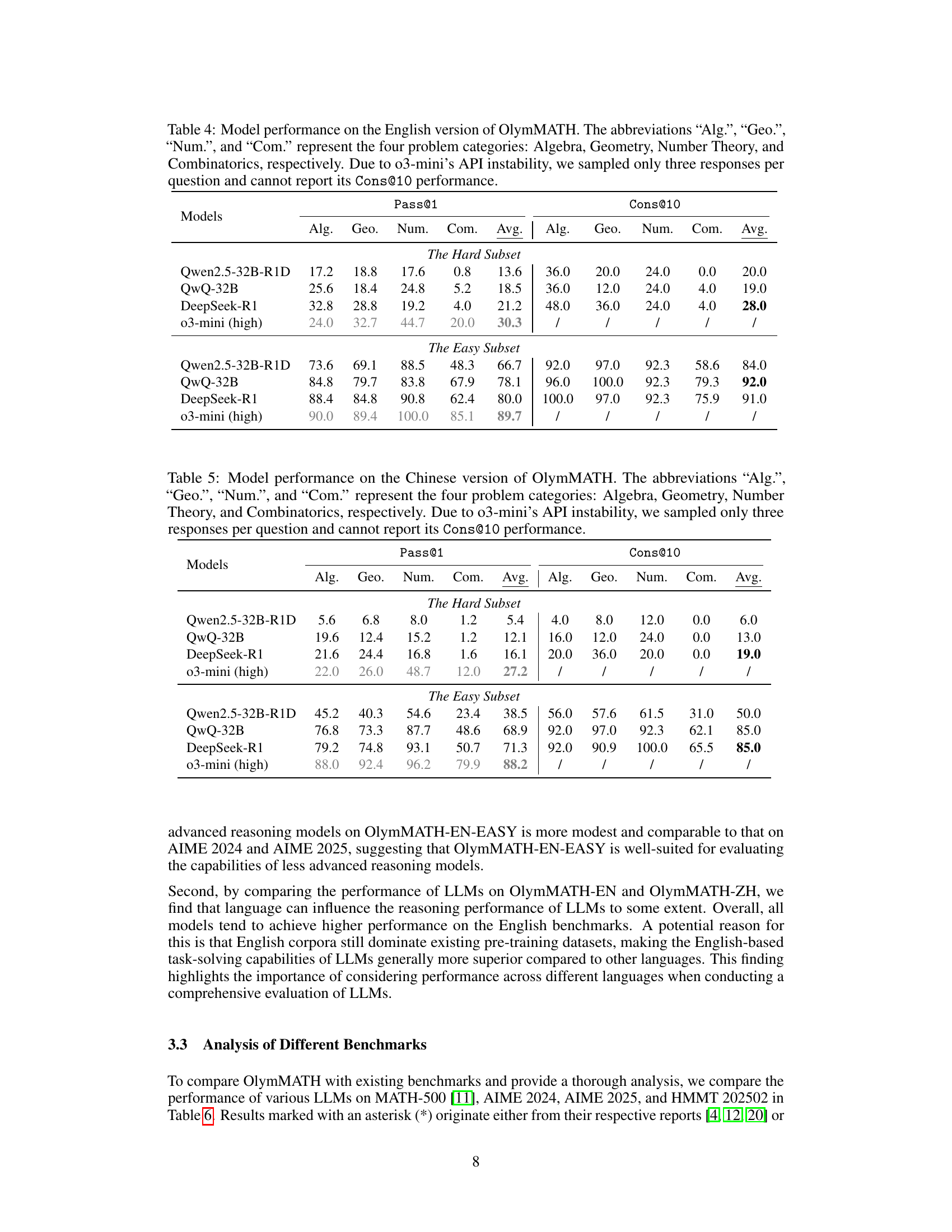
🔼 Table 4 presents the performance of various large language models (LLMs) on the English version of the OlymMATH benchmark. The benchmark contains problems from four mathematical areas: Algebra, Geometry, Number Theory, and Combinatorics. The table shows the Pass@1 and Cons@10 scores for each model and category. Pass@1 indicates the accuracy of the top-ranked answer provided by the model, while Cons@10 represents the accuracy of the majority consensus answer among the top 10 model responses. Due to limitations with the 03-mini model’s API, only three responses per question were sampled, preventing a Cons@10 score from being reported for that model.
read the captionTable 4: Model performance on the English version of OlymMATH. The abbreviations “Alg.”, “Geo.”, “Num.”, and “Com.” represent the four problem categories: Algebra, Geometry, Number Theory, and Combinatorics, respectively. Due to o3-mini’s API instability, we sampled only three responses per question and cannot report its Cons@10 performance.
🔼 Table 5 presents the performance of several large language models (LLMs) on the Chinese version of the OlymMATH benchmark. The benchmark consists of 200 Olympiad-level math problems categorized into four areas: Algebra, Geometry, Number Theory, and Combinatorics. The table shows the models’ Pass@1 (accuracy of the top prediction) and Cons@10 (accuracy of the consensus answer across 10 predictions) scores for each category and overall. Due to limitations in the o3-mini model’s API, only three responses were sampled per question for this model, and its Cons@10 performance is therefore not reported.
read the captionTable 5: Model performance on the Chinese version of OlymMATH. The abbreviations “Alg.”, “Geo.”, “Num.”, and “Com.” represent the four problem categories: Algebra, Geometry, Number Theory, and Combinatorics, respectively. Due to o3-mini’s API instability, we sampled only three responses per question and cannot report its Cons@10 performance.
🔼 This table compares the performance of four large language models (LLMs) across five different mathematical reasoning benchmarks: MATH-500, AIME 2024, AIME 2025, HMMT 202502, and OlymMATH (both easy and hard versions in English and Chinese). The Pass@1 metric indicates the percentage of problems correctly solved by the model in a single attempt. Results marked with an asterisk (*) were taken from the original publications or the MathArena website, not directly from the authors’ experiments. The table highlights the relative difficulty of each benchmark and how the models’ performance varies across them.
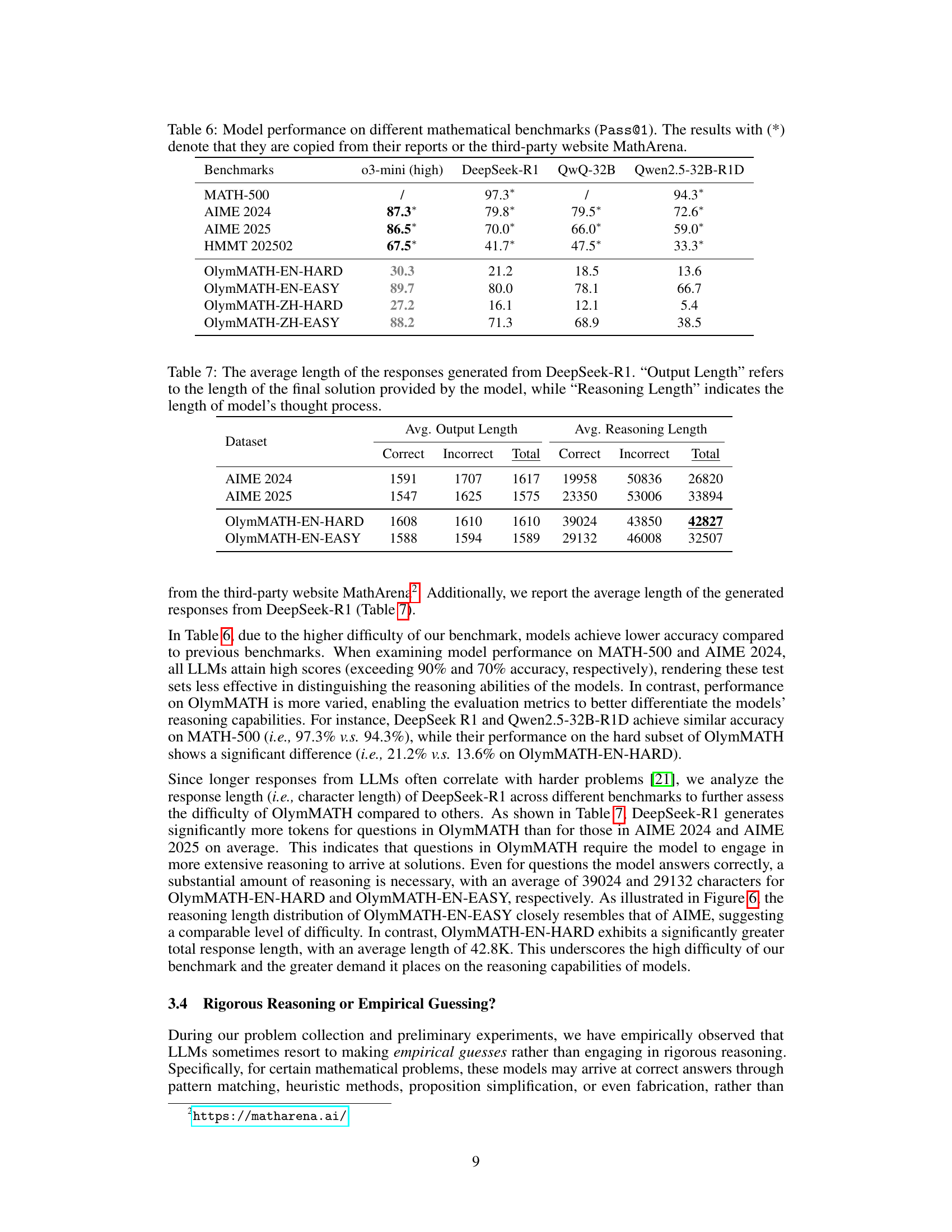
read the captionTable 6: Model performance on different mathematical benchmarks (Pass@1). The results with (*) denote that they are copied from their reports or the third-party website MathArena.
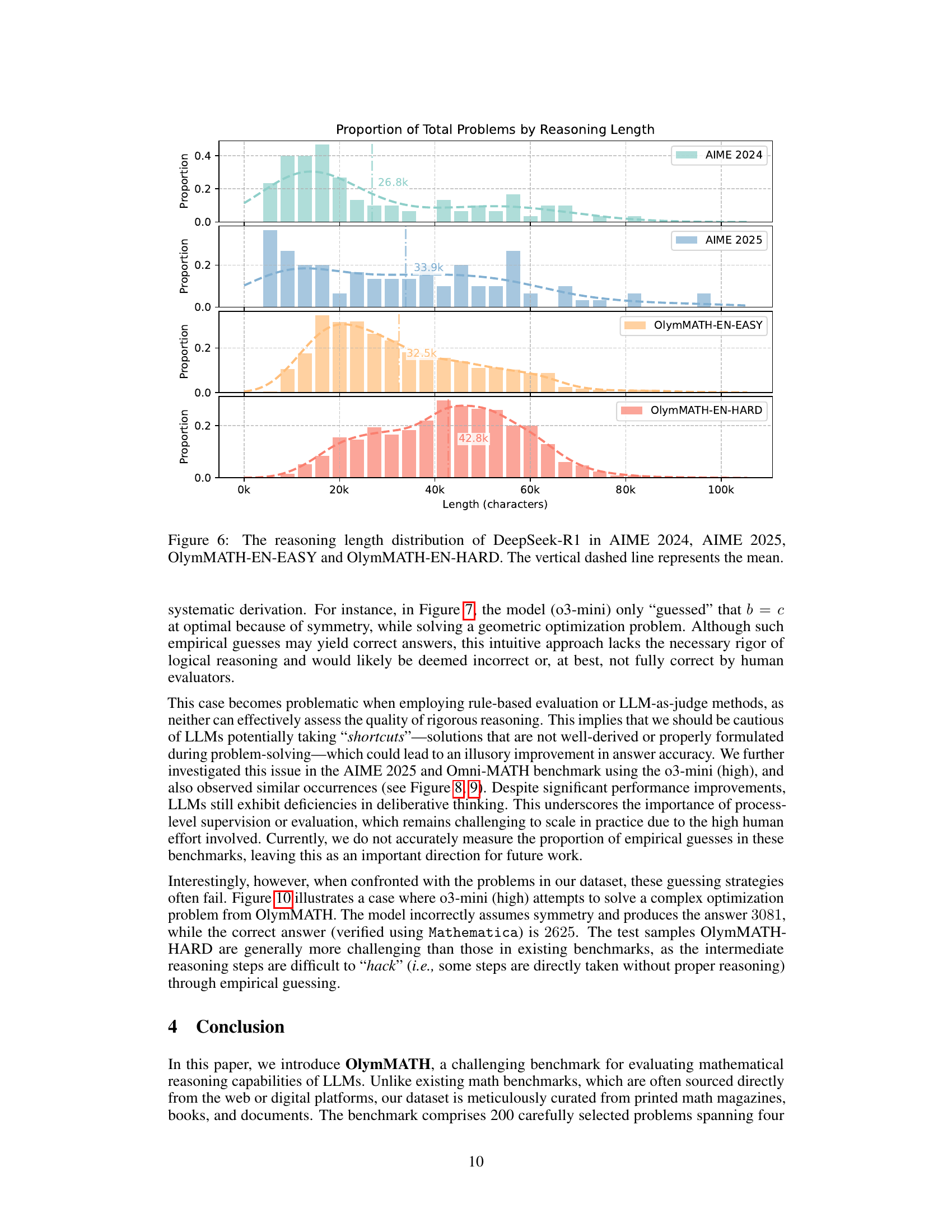
🔼 This table presents a quantitative analysis of the DeepSeek-R1 model’s response length across four different mathematical reasoning benchmarks: AIME 2024, AIME 2025, OlymMATH-EN-HARD, and OlymMATH-EN-EASY. For each benchmark, it shows the average length of the model’s final answer (Output Length) and the average length of its reasoning process (Reasoning Length). These lengths are further broken down into the average lengths for correct and incorrect answers, providing insight into the relationship between response length and solution accuracy. The data reveals how the model’s output and thought processes vary in length based on the complexity and nature of the problems within each benchmark.
read the captionTable 7: The average length of the responses generated from DeepSeek-R1. “Output Length” refers to the length of the final solution provided by the model, while “Reasoning Length” indicates the length of model’s thought process.
🔼 This figure displays an example problem encountered during the OlymMATH dataset creation. The problem involves finding the maximum area of a triangle given a constraint on its side lengths. The model, 03-mini (high), arrived at the correct answer; however, its solution process lacked mathematical rigor. Due to space limitations, only a concise summary of the model’s solution steps is presented, highlighting the model’s non-rigorous approach.
read the captionFigure 7: An example during our data collection. o3-mini (high) found the correct answer without rigorously solving the problem. Due to length constraints, we provide only a summary of its original solution steps.