TL;DR#
Text-guided image editing modifies specific image regions according to language instructions while preserving structure & background fidelity. Existing methods use masks from cross-attention maps. However, they focus on semantic relevance and often lack spatial consistency, leading to artifacts & distortions. A method is needed to precisely identify editing areas without jeopardizing image integrity.
This paper introduces LOCATEdit, enhancing cross-attention maps via a graph-based approach. It uses self-attention-derived patch relationships to maintain attention across image regions, ensuring alterations are limited while retaining surrounding structure. This work also uses CASA graphs to encapsulate word-to-pixel relevance and optimizes masks through graph Laplacian regularization.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it provides a novel method for precise and localized text-guided image editing. The proposed LOCATEdit significantly reduces editing artifacts and distortions, paving the way for more trustworthy and accessible image editing solutions. The framework can enhance the quality and reliability of image editing applications in various fields.
Visual Insights#

🔼 Figure 1 showcases several example results produced by LOCATEdit, demonstrating its capability to perform a variety of complex image editing tasks guided by text prompts. Each example shows an original image alongside a modified version generated by LOCATEdit. The modifications demonstrate the model’s ability to precisely target and edit specific regions of an image while preserving the integrity of the overall image structure and background fidelity. The examples range from simple changes like altering the color of an object to more complex modifications such as adding or removing elements from a scene.
read the caption
Figure 1: Our LOCATEdit demonstrates strong performance on various complex image editing tasks.
| Source Image | LOCATEdit | ViMAEdit | InfEdit | MasaCtrl | LEDITS++ | |
| an orange black cat sitting on top of a fence | ![[Uncaptioned image]](extracted/6315178/images/source_image/000000000005.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_black_cat.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_black_kitten.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_black_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_black_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_orange_black_cat.png) |
| a cat tiger sitting next to a mirror | ![[Uncaptioned image]](extracted/6315178/images/source_image/121000000001.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_tiger_mirror.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_tiger_mirror.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_cat_tiger.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_tiger_mirror.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_cat_tiger.png) |
| the crescent moon golden crescent moon and stars are seen in the night sky | ![[Uncaptioned image]](extracted/6315178/images/source_image/714000000003.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_moon_golden.jpg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_crescent_moon.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_crescent_moon.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_crescent_moon.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_golden_moon.png) |
| A white golden horse running in the sunset | ![[Uncaptioned image]](extracted/6315178/images/source_image/original_horse.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/horse_ours_golden.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_golden_horse.jpg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_golden_horse.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masa_ctrl_golden_horse.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/leedits_golden_horse.png) |
| a open closed eyes cat sitting on wooden floor | ![[Uncaptioned image]](extracted/6315178/images/source_image/original_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_cat_eye_closed.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_cat_closed.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/000000000027.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_eyes_closed.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledit_eyes_closed.png) |
| a kitten duck walking through the grass | ![[Uncaptioned image]](extracted/6315178/images/source_image/000000000029.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_kitten_duck.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_duck_kitten.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_kitten_duck.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_kitten_duck.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_kitten_duck.png) |
| a boat is docked on a lake in the heavy fog sunny day | ![[Uncaptioned image]](extracted/6315178/images/source_image/000000000127.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_sunny_fog.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_sunny_fog.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_boat_dock_sunny.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_sunny_fog.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_sunny_fog.png) |
| a woman man and a horse | ![[Uncaptioned image]](extracted/6315178/images/source_image/122000000008.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_man_horse.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_woman_horse.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_woman_man_horse.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_horse_man.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_man_horse.png) |
🔼 Table 1 presents a qualitative comparison of LOCATEdit against other state-of-the-art text-guided image editing methods. The comparison focuses on the localization of edits, structural preservation of the original image, and the overall fidelity and consistency of the results. Examples are shown for various image editing tasks, demonstrating LOCATEdit’s ability to produce highly localized edits that maintain the integrity and visual quality of the original images, thus outperforming other methods.
read the caption
Table 1: Qualitative comparisons with competing text-guided editing methods. LOCATEdit yields more localized edits while preserving overall structure, outperforming baselines in both fidelity and consistency.
In-depth insights#
Edit Integrity#
Maintaining edit integrity in text-guided image manipulation is crucial for realistic and plausible results. It involves ensuring that modifications adhere to the user’s instructions while preserving the overall structure, semantic consistency, and background fidelity of the original image. A key challenge lies in preventing unintended alterations or artifacts that can arise from imperfect attention mechanisms, which may lead to edits spilling over into unrelated regions or distorting the image. Methods that fail to uphold edit integrity often produce results that appear unnatural or nonsensical, undermining the user’s intent. Successful approaches must balance semantic guidance with spatial coherence, ensuring that changes are localized and consistent with the surrounding context. Graph-based techniques and Laplacian regularization offer promising avenues for promoting edit integrity by enforcing smoothness and consistency in the attention maps that guide image modification.
CASA Graph Edit#
While ‘CASA Graph Edit’ isn’t a direct heading in this paper, the concept of using graphs to refine image edits is present. It likely involves constructing a graph where nodes represent image patches and edges capture relationships between them, potentially derived from self-attention mechanisms. This graph, termed ‘CASA’ for Cross and Self Attention, would then be used to guide the image editing process. By applying graph-based techniques, such as Laplacian regularization, the method aims to enforce spatial consistency and smoothness in the attention maps that determine which areas of the image are modified. This could mitigate artifacts and ensure that edits are localized to the intended regions, while preserving the overall structure and context of the original image. The edges in the graph could be weighted by the strength of the self-attention between patches, allowing for adaptive smoothing that respects image boundaries and semantic coherence. Ultimately, the goal is to improve the quality and realism of text-guided image editing by incorporating spatial reasoning into the attention mechanism.
Laplacian Smooth#
Laplacian smoothing is a powerful technique to enforce spatial consistency. The core idea lies in the Laplacian operator, which approximates the smoothness of a function over a graph. The Laplacian works by penalizing differences between neighboring nodes, thus encouraging nearby values to be similar. In image processing, the graph can represent pixels or patches, and the edges can encode proximity or similarity. The Laplacian effectively acts as a low-pass filter, attenuating high-frequency noise and preserving sharp edges. This regularization is particularly useful when dealing with noisy or incomplete data, as it can help to fill in missing information and reduce artifacts. By applying Laplacian smoothing to attention maps, one can achieve more coherent and spatially consistent regions of interest, which lead to better image editing. The strength of the smoothing is controlled by a hyperparameter, which allows for fine-tuning the trade-off between fidelity and smoothness.
IP-Adapter Prune#
The concept of an ‘IP-Adapter Prune’ suggests a strategy for refining the influence of image prompt adapters within a diffusion model framework. Since IP-Adapters inject image-derived features to guide the image generation process, pruning could involve selectively removing or down-weighting certain feature channels or attention weights learned by the adapter. This could be motivated by several factors. First, certain features might be redundant or introduce noise, hindering the model’s ability to generate high-quality or consistent edits. Second, pruning can enhance the model’s generalization capabilities by preventing overfitting to the training data of the IP-Adapter. Third, it might improve control over the editing process, allowing users to focus on specific aspects of the source image by emphasizing certain features and suppressing others. The selective pruning ensures that only significant semantic shifts contribute to the target image embedding, thereby reducing the risk of global edits and preserving the structural consistency of non-target regions. Finally, the pruned embedding is processed through the IP-Adapter ensuring that the final diffusion process is both semantically guided and robust to minor, spurious variations.
PIE-Bench Focus#
When a paper emphasizes ‘PIE-Bench Focus’, it signals a commitment to rigorous evaluation using a standardized benchmark. PIE-Bench provides a controlled environment to compare image editing methods objectively. This focus likely means the paper prioritizes quantitative results and comparative analysis, ensuring the proposed method’s performance is not just subjectively appealing but demonstrably better than existing techniques. By adhering to PIE-Bench, the research gains credibility and facilitates reproducibility, allowing others to validate and build upon the findings. A strong PIE-Bench focus typically involves detailed reporting of metrics and ablation studies to understand the contribution of each component.
More visual insights#
More on figures

🔼 This figure shows three examples of image editing results where imprecise masks have led to undesired modifications. In each example, the LOCATEdit model produces a more localized edit, accurately targeting the desired area without affecting the surrounding image content. In contrast, ViMAEdit struggles to achieve this level of precision and produces edits that spill into unwanted regions. These results highlight the challenges in creating accurate masks for effective text-guided image editing.
read the caption
Figure 2: Example of over-editing caused due to imprecise masks.

🔼 This figure illustrates the architecture of LOCATEdit, a text-guided image editing pipeline. It shows a dual-branch framework (source and target) where each branch processes the image through a U-Net. The key innovation is the use of CASA graphs (combining cross and self-attention maps) which are regularized using a graph Laplacian to improve the spatial consistency of the attention maps. These refined attention maps guide the editing process. Further, an IP-Adapter is utilized for additional guidance and selective pruning is applied to text embeddings to mitigate noise and preserve crucial structural information from the original image. The figure visually details the flow of information and the interaction between these different components during the image editing process.
read the caption
Figure 3: Overview of our text-guided image editing pipeline. LOCATEdit refines cross-attention maps with graph Laplacian regularization for spatial consistency, uses an IP-Adapter for additional guidance, and employs selective pruning on text embeddings to suppress noise, ensuring the edited image preserves key structural details.

🔼 This figure illustrates the process of constructing a CASA (Cross and Self-Attention) graph, which enhances spatial consistency in cross-attention maps. First, initial cross-attention maps are upsampled to create a higher-resolution representation. These upsampled maps are then used to form a patch-level adjacency graph, where each patch represents a node, and the connections between patches are weighted based on self-attention relationships. Laplacian regularization is then applied to this graph to smooth the attention values across the image, ensuring spatial coherence. Finally, the refined cross-attention maps are thresholded to generate more robust attention masks, which are more precise for image editing tasks.
read the caption
Figure 4: CASA (Cross and Self-Attention) Graph Construction workflow. The initial cross-attention maps are upsampled to form a patch-level adjacency graph, then Laplacian regularization enforces spatial consistency. Thresholding the refined maps yields final, more robust attention masks.

🔼 The figure displays a 2D cross-section of the convex objective function J(m), which is used in optimizing the saliency maps in the LOCATEdit model. The plot shows that the function has a single global minimum (marked in red), clearly indicating its convex nature. This convexity guarantees that the optimization process will converge to the unique optimal solution, which represents the refined saliency maps that are spatially consistent and precise. The x and y axes represent the values of the saliency map m in the two dimensions being visualized, and the z-axis represents the value of the objective function J(m).
read the caption
Figure 5: Illustration of the convex objective J(m)𝐽mJ(\textbf{m})italic_J ( m ) in a 2D slice of the higher-dimensional space. The single global minimum, marked in red, highlights the function’s convex nature.
More on tables
| Method | Editing | Structure | Background Preservation | CLIP Similarity | |||||
| Inverse | Sampling (steps) | Distance | PSNR | LPIPS | MSE | SSIM | Whole | Edited | |
| VI | DDCM(12) | InfEdit | 13.78 | 28.51 | 47.58 | 32.09 | 85.66 | 25.03 | 22.22 |
| VI | DDIM(50) | ViMAEdit | 12.65 | 28.27 | 44.67 | 30.29 | 85.65 | 25.91 | 22.96 |
| PnP-I | DDIM(50) | P2P-Zero | 51.13 | 21.23 | 143.87 | 135.00 | 77.23 | 23.36 | 21.03 |
| MasaCtrl | 24.47 | 22.78 | 87.38 | 79.91 | 81.36 | 24.42 | 21.38 | ||
| PnP | 24.29 | 22.64 | 106.06 | 80.45 | 79.68 | 25.41 | 22.62 | ||
| P2P | 11.64 | 27.19 | 54.44 | 33.15 | 84.71 | 25.03 | 22.13 | ||
| ViMAEdit | 11.90 | 28.75 | 43.07 | 28.85 | 85.95 | 25.43 | 22.40 | ||
| LOCATEdit (Ours) | 13.19 | 29.20 | 41.60 | 26.90 | 86.53 | 25.96 | 23.02 | ||
| EF | DPM-Solver++(20) | LEDITS++ | 23.15 | 24.67 | 80.79 | 118.56 | 81.55 | 25.01 | 22.09 |
| P2P | 14.52 | 27.05 | 50.72 | 37.48 | 84.97 | 25.36 | 22.43 | ||
| ViMAEdit | 14.16 | 28.12 | 45.62 | 33.56 | 85.61 | 25.51 | 22.56 | ||
| LOCATEdit (Ours) | 8.71 | 29.16 | 39.31 | 24.01 | 86.52 | 26.07 | 22.43 | ||
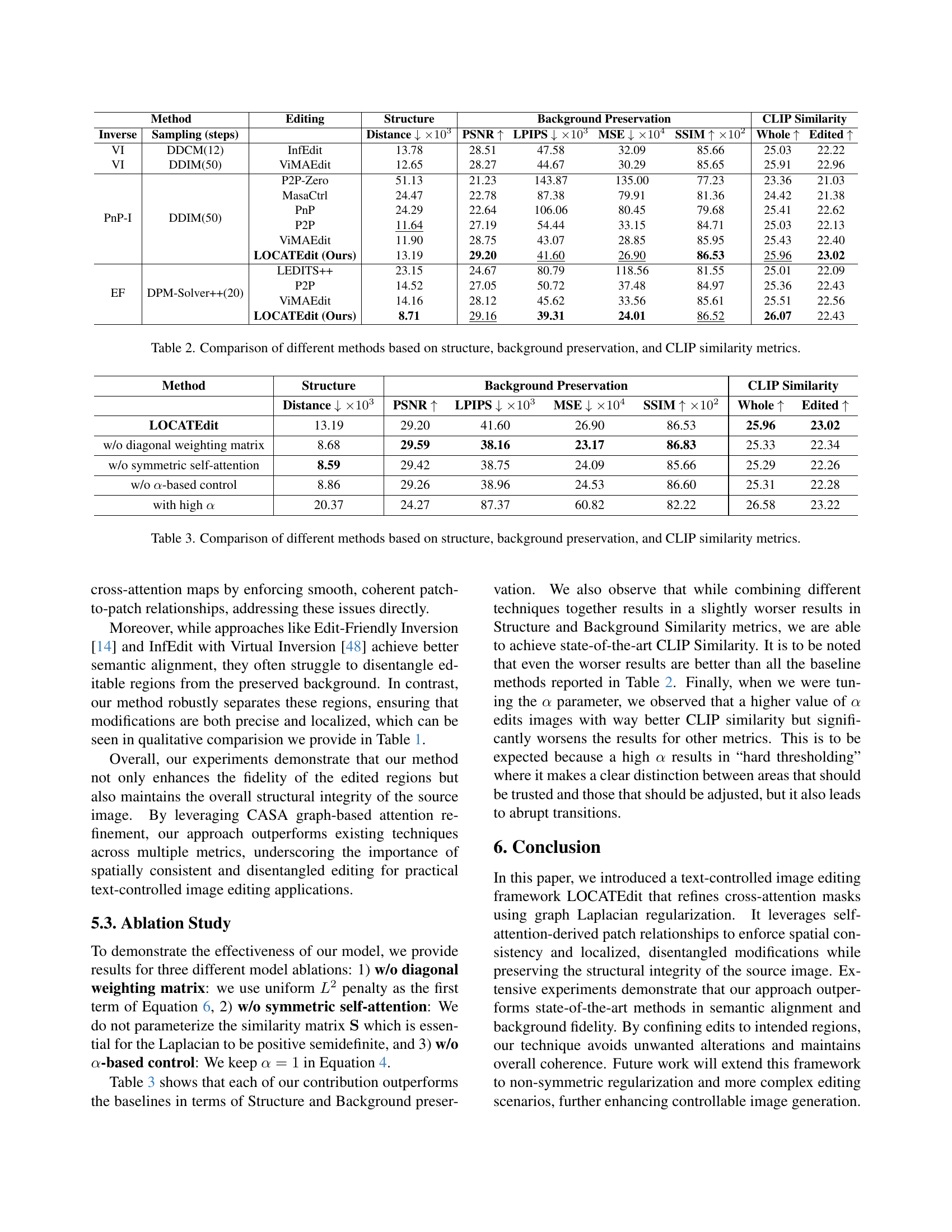
🔼 Table 2 presents a quantitative comparison of various image editing methods. The comparison is based on three key evaluation metrics: Structure (measured by the distance between the original and edited image structures), Background Preservation (assessed using PSNR, LPIPS, MSE, and SSIM scores to quantify the similarity between the original and edited backgrounds), and CLIP Similarity (which evaluates how well the edited image aligns with the target prompt using CLIP scores). Lower scores for Distance and LPIPS indicate better preservation of the original image, higher scores for PSNR and SSIM represent better background preservation, and higher scores for CLIP Similarity signify better alignment with the target textual description.
read the caption
Table 2: Comparison of different methods based on structure, background preservation, and CLIP similarity metrics.
| Method | Structure | Background Preservation | CLIP Similarity | ||||
|---|---|---|---|---|---|---|---|
| Distance | PSNR | LPIPS | MSE | SSIM | Whole | Edited | |
| LOCATEdit | 13.19 | 29.20 | 41.60 | 26.90 | 86.53 | 25.96 | 23.02 |
| w/o diagonal weighting matrix | 8.68 | 29.59 | 38.16 | 23.17 | 86.83 | 25.33 | 22.34 |
| w/o symmetric self-attention | 8.59 | 29.42 | 38.75 | 24.09 | 85.66 | 25.29 | 22.26 |
| w/o -based control | 8.86 | 29.26 | 38.96 | 24.53 | 86.60 | 25.31 | 22.28 |
| with high | 20.37 | 24.27 | 87.37 | 60.82 | 82.22 | 26.58 | 23.22 |
🔼 Table 3 presents a quantitative comparison of various image editing methods, focusing on three key aspects: structural consistency (measured by distance), background preservation (evaluated using PSNR, LPIPS, MSE, and SSIM metrics), and CLIP similarity (which assesses the alignment between the edited image and the target prompt). It allows readers to assess the relative strengths and weaknesses of different methods in terms of their ability to produce edits that are both visually coherent and semantically accurate while preserving the quality of the original image background.
read the caption
Table 3: Comparison of different methods based on structure, background preservation, and CLIP similarity metrics.
| Source Image | LOCATEdit | ViMAEdit | InfEdit | MasaCtrl | LEDITS++ | |
| a photo of goat horse and a cat standing on rocks near the ocean | ![[Uncaptioned image]](extracted/6315178/images/source_image/original_goat_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/our_horse_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_horse_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_horse_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masa_ctrl_horse_cat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_horse_cat.png) |
| a brown white tea cup and a book | ![[Uncaptioned image]](extracted/6315178/images/source_image/original_brown_cup.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/our_white_cup.jpg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_white_cup.jpg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_white_cup.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masa_ctrl_white_cup.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/leedits_white_cup.png) |
| a cat sitting in the grass rocks | ![[Uncaptioned image]](extracted/6315178/images/source_image/original_cat_in_grass.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/our_cat_in_rock.jpg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_edit_cat_rock.jpg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_cat_in_rocks.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_cat_sitting_in_rocks.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/leedits_cat_in_rocks.png) |
| a woman with black hair and a white shirt is holding a phone coffee | ![[Uncaptioned image]](extracted/6315178/images/source_image/112000000003.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_woman_coffee.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_woman_coffee-2.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_girl_coffee.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_woman_coffee.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_phone_coffee.png) |
| sea forest and house | ![[Uncaptioned image]](extracted/6315178/images/source_image/000000000069.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_forest_and_house.jpg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vimaedit_forest_sea.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_forest-baseline.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_forest_sea.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_sea_forest.png) |
| a cute little duck marmot with big eyes | ![[Uncaptioned image]](extracted/6315178/images/source_image/111000000002.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_duck_marmot.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_duck_marmot.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_marmot.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_marmot.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_marmot.png) |
| a woman with flowers monster around her face | ![[Uncaptioned image]](extracted/6315178/images/source_image/000000000075.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/our_woman_monster.jpg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_woman_monster.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_monster_around_woman.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_monster_around_woman.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_woman_monster.png) |
| the two people are standing on rocks boat with a fish | ![[Uncaptioned image]](extracted/6315178/images/source_image/000000000135.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_man_boat.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_man_boat.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/000000000135.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_man_boat.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_man_boat.png) |
| the sun moon over an old farmhouse | ![[Uncaptioned image]](extracted/6315178/images/source_image/124000000005.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_sun_moon.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vomaedit_sun_moon.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/infedit_sun_moon.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_sun_moon.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_sun_moon.png) |
| An asian woman with blue thick-lashed eyes and flowers on her black hair | ![[Uncaptioned image]](extracted/6315178/images/source_image/original_asian.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ours/ours_woman_flowers.jpeg) | ![[Uncaptioned image]](extracted/6315178/images/vimaedit/vima_asian.jpg) | ![[Uncaptioned image]](extracted/6315178/images/infedit/212000000003.jpg) | ![[Uncaptioned image]](extracted/6315178/images/masactrl/masactrl_asian.jpg) | ![[Uncaptioned image]](extracted/6315178/images/ledits/ledits_asian.png) |
🔼 Table 4 presents a qualitative comparison of image editing results produced by LOCATEdit and other state-of-the-art methods on the PIE-Bench dataset. For several diverse image editing tasks, it shows example images with their corresponding edits made by each method. This allows visual evaluation of each method’s ability to perform precise, localized edits while preserving the original image structure and avoiding artifacts.
read the caption
Table 4: Additional qualitative results on PIE-Bench
Full paper#