TL;DR#
Text-to-image models often struggle with accurately rendering text and integrating it seamlessly into images. While accuracy has been a focus, the aesthetic quality & integration with image content have been overlooked. Existing datasets lack high-quality samples for training models to produce diverse, aesthetically pleasing results. Thus, the paper explores these challenges in visual text generation.
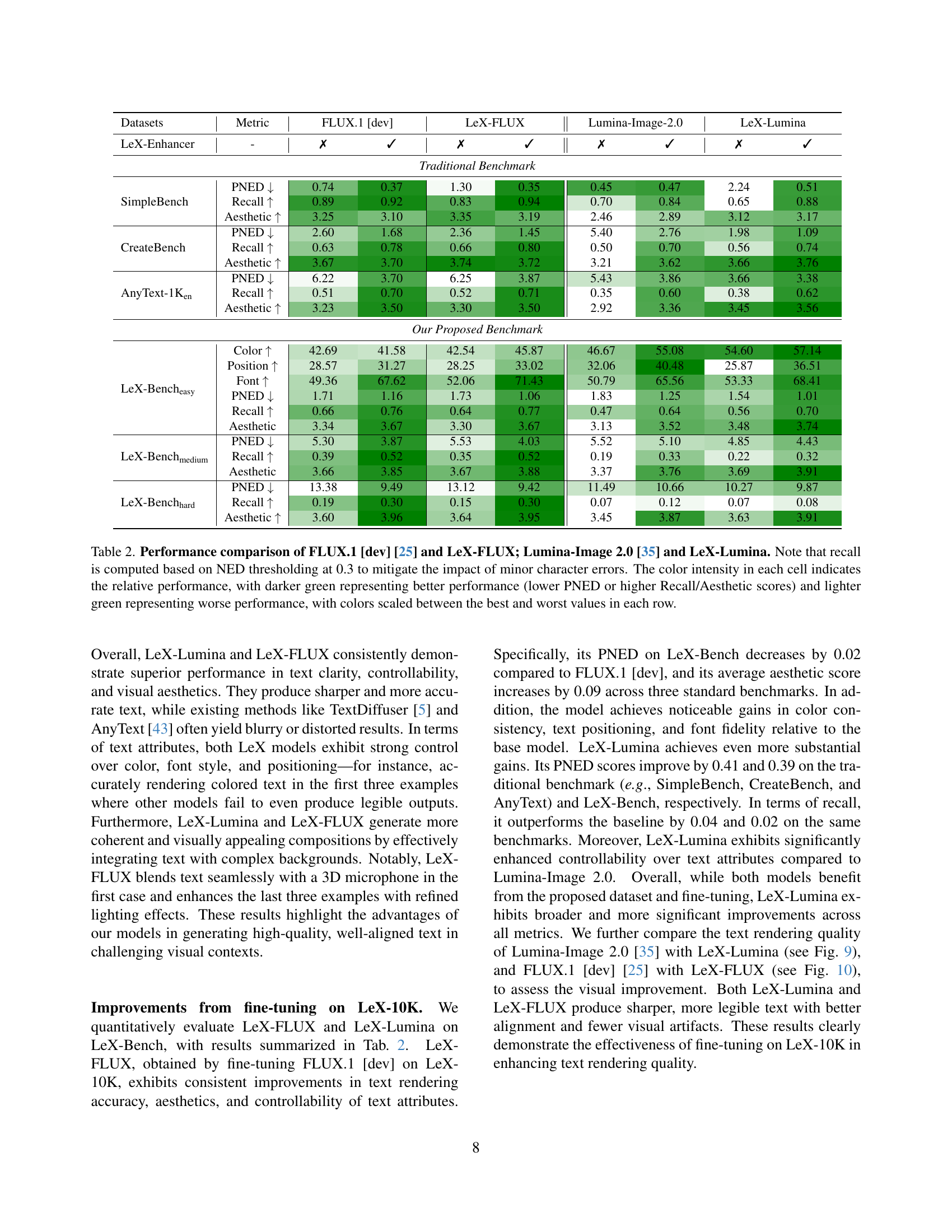
The paper introduces LeX-Art, a framework for high-quality text-image synthesis. This includes the LeX-10K dataset, created using DeepSeek-R1 for prompt refinement and multi-stage filtering. Additionally, the paper provides LeX-Enhancer prompt enrichment and two text-to-image models, LeX-FLUX & LeX-Lumina. The benchmark LeX-Bench & a new metric, PNED, are introduced for evaluation, demonstrating significant improvements.
Key Takeaways#
Why does it matter?#
This paper introduces a new way to generate high-quality text images, which could significantly improve the design process and open new research directions for text-to-image generation. By focusing on data quality and model training, the authors provide a scalable solution that could inspire further advancements in the field.
Visual Insights#

🔼 This figure showcases examples of visual text generation produced by the LeX-FLUX and LeX-Lumina models. Each image demonstrates the model’s ability to generate multiple words within a complex layout, exhibiting high aesthetic quality and precise control over text attributes (such as font, color, and position). The prompts used to generate these images are displayed alongside each resulting image, highlighting the models’ capacity to interpret diverse and complex instructions accurately.
read the caption
Figure 1: Given the prompts for visual text generation, our proposed LeX-FLUX and LeX-Lumina can generate text images with multiple words, aesthetic complex layout, and good text attributes controllability.
In-depth insights#
Text & Image Aligned#
Text and Image Alignment is crucial for high-quality text-to-image generation. Models must ensure that the generated image accurately reflects the text prompt’s content, style, and layout. Poor alignment can manifest as missing text, incorrect font styles, wrong colors, or misplaced text elements. Datasets with well-aligned text and images are essential for training models that can generate visually coherent and semantically accurate results. Metrics that accurately measure the degree of alignment between the generated image and the input text are also necessary for evaluating and improving model performance. Effective strategies for achieving robust text and image alignment often involve fine-grained prompt engineering and data augmentation to train robust models.
LeX: A Data-Centric T2I#
LeX: A Data-Centric T2I Approach suggests a paradigm shift in Text-to-Image (T2I) generation. Rather than solely focusing on architectural innovations in models, it prioritizes the quality and quantity of the training data. This approach acknowledges that even powerful models are limited by the data they are trained on. By emphasizing data curation, LeX likely aims to create a dataset that is more diverse, aesthetically refined, and representative of the desired output characteristics. This could involve meticulous selection, cleaning, and augmentation of existing data or the creation of entirely new synthetic datasets. The benefits of a data-centric approach include improved model performance, generalization, and robustness. A well-curated dataset can also reduce biases and enhance the fairness of the generated images. Furthermore, this approach encourages interpretability and control over the generation process. By carefully designing the data, it becomes easier to understand and influence the model’s behavior. The success of LeX hinges on the ability to create a dataset that effectively captures the complex relationships between text and images, enabling the model to generate high-quality, visually appealing, and semantically accurate outputs. It may also emphasize the importance of scalable data synthesis techniques for further improving T2I technologies.
PNED:Text Metric#
Pairwise Normalized Edit Distance (PNED) is introduced as a flexible metric to evaluate how well generated text matches the input prompt. It addresses the limitations of Normalized Edit Distance (NED) in non-glyph-conditioned models, where text order may vary. PNED treats prompts and OCR-extracted text as unordered word sets, computing pairwise edit distances and applying penalties for unmatched words, allowing for robust text accuracy evaluation. By leveraging PNED, a more robust and generalizable metric for evaluating text accuracy across diverse T2I models can be provided.
Scaling the Dataset#
Scaling a dataset is crucial for enhancing model generalization and performance. A larger dataset typically leads to better representation of the underlying data distribution, enabling models to learn more robust features and patterns. However, simply increasing the dataset size without careful consideration of data quality and diversity can be detrimental. Data augmentation techniques can artificially expand the dataset, but it’s important to ensure that these augmentations generate realistic and meaningful variations. Furthermore, as the dataset grows, efficient data management and processing become essential to avoid computational bottlenecks. Active learning strategies can prioritize the selection of the most informative samples to label, maximizing the impact of each data point and reducing the overall annotation effort. The key is to strike a balance between dataset size, data quality, diversity, and efficient data handling to achieve optimal model performance.
Future: More Scalable#
The idea of a “Future: More Scalable” approach to text-to-image generation is compelling. Scalability implies several key areas of focus. Firstly, data synthesis needs to be more efficient, perhaps through automated prompt engineering and active learning techniques to prioritize data points that most improve model performance. Secondly, the models themselves could benefit from architectures designed for scalability, such as those employing efficient attention mechanisms or knowledge distillation to transfer capabilities from large models to smaller ones. Thirdly, evaluation metrics must also scale, moving beyond human evaluation to automated metrics that reliably assess text accuracy, aesthetic quality, and alignment across diverse datasets. Successfully addressing these challenges would unlock the potential for text-to-image models to be deployed in a wider range of applications, with lower computational costs and greater accessibility.
More visual insights#
More on figures

🔼 The LeX-Art framework is composed of three key components: dataset construction, model fine-tuning, and benchmark evaluation. The dataset is created using DeepSeek-R1 to enhance prompts and filter images, resulting in LeX-10K. LeX-Enhancer, a prompt enrichment model, and two text-to-image models (LeX-FLUX and LeX-Lumina) are trained using this dataset. The LeX-Bench benchmark evaluates the fidelity, aesthetics, and alignment of visual text generation, using metrics like Pairwise Normalized Edit Distance (PNED).
read the caption
Figure 2: Illustration of LeX-Art Framework.
🔼 This figure illustrates the data construction pipeline used in LeX-Art for generating high-quality text-image datasets. It starts with seed prompts that are enhanced using DeepSeek-R1, resulting in prompts that include detailed descriptions of visual attributes. These enriched prompts are then used to generate images using a text-to-image model. The generated images and captions are then subjected to a multi-stage filtering process to ensure high quality and alignment. Finally, GPT-40 is utilized for knowledge-augmented recaptioning, where the captions are refined to precisely match the generated images, handling cases where certain words in the enhanced prompt were not accurately rendered. The example showcases how an initial prompt is enhanced, an image is generated, and then the caption is refined to accurately reflect the final image.
read the caption
Figure 3: The framework of data construction pipeline. The red words in the R1 enhanced prompt are not rendered in the generated image, and it is fixed after the knowledge-augmented recaption by gpt-4o.

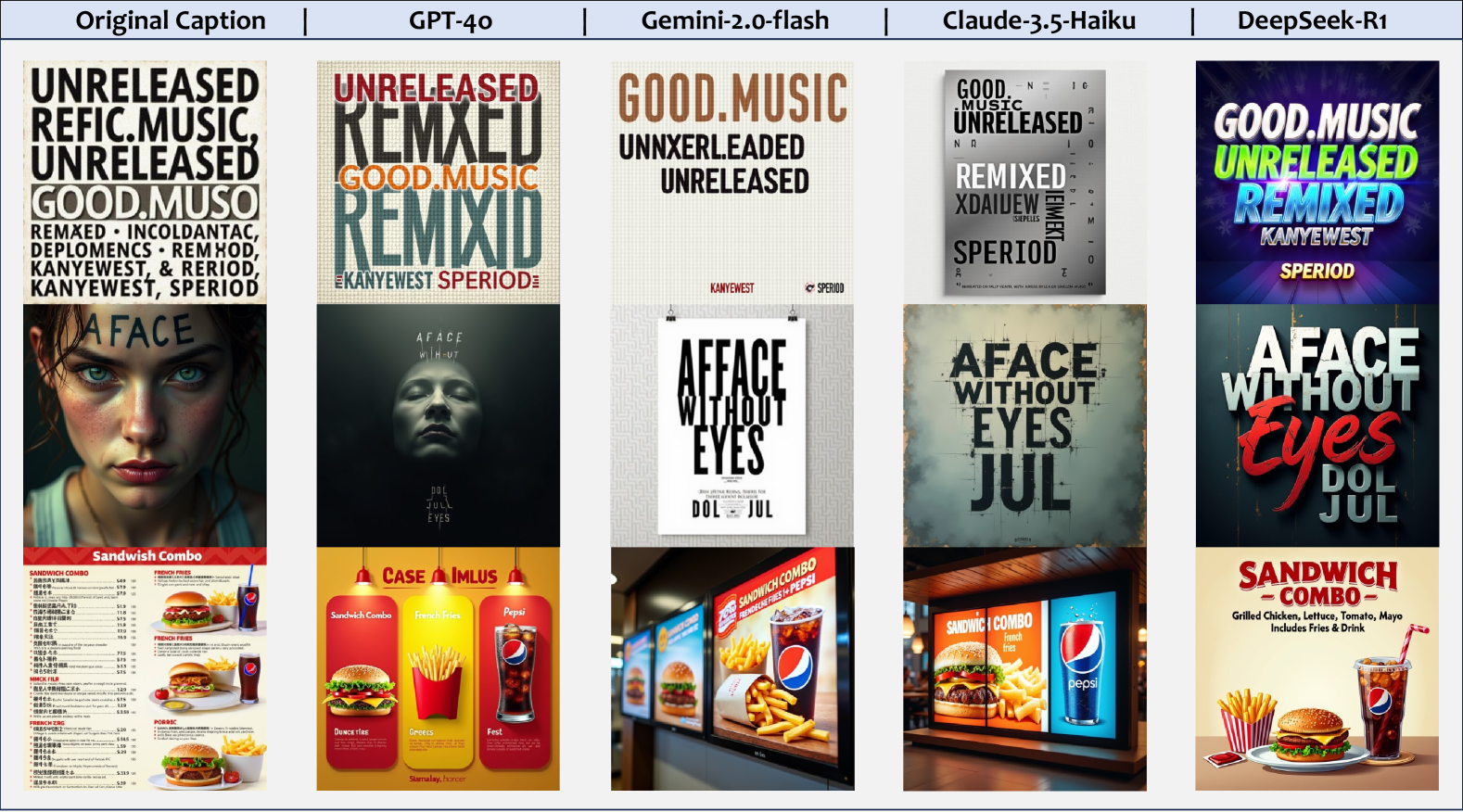
🔼 This figure showcases examples of text image generation using the FLUX.1 [dev] model. Three different prompts were used, resulting in three distinct images. The first image is a poster advertising ‘Good Music’, with the words ‘UNRELEASED’, ‘REMIXED’, ‘GOOD.MUSIC’, ‘KANYEWEST’, and ‘SPERIOD’ incorporated into the design. The second image resembles a movie poster, featuring the words ‘AFACE’, ‘WITHOUT’, ‘EYES’, ‘DOL’, and ‘JUL’. The third image is a stylized fast-food menu, advertising a ‘Sandwich Combo’ and listing ingredients like ‘Grilled Chicken’, ‘Lettuce’, ‘Tomato’, ‘Mayo’, ‘Fries & Drink’, and ‘Pepsi’. These diverse outputs illustrate the model’s ability to generate images with varying styles and information.
read the caption
Figure 4: Images generated by FLUX.1 [dev] [25] based on different prompts. The origin caption from the first raw to the bottom raw: (1) A poster with the words Good Music remixed and unreleased on it, with text on it: “UNRELEASED”, “REMIXED”, “GOOD.MUSIC”, “KANYEWEST”, “SPERIOD”. (2) A movie poster, with text on it: “AFACE”, “WITHOUT”, “EYES”, “DOL”, “JUL”. (3) A menu of a fast food restaurant that contains “Sandwich Combo”, “Grilled Chicken”, “Lettuce”, “Tomato”, “Mayo”, “Fries&Drink”, and “Pepsi”.

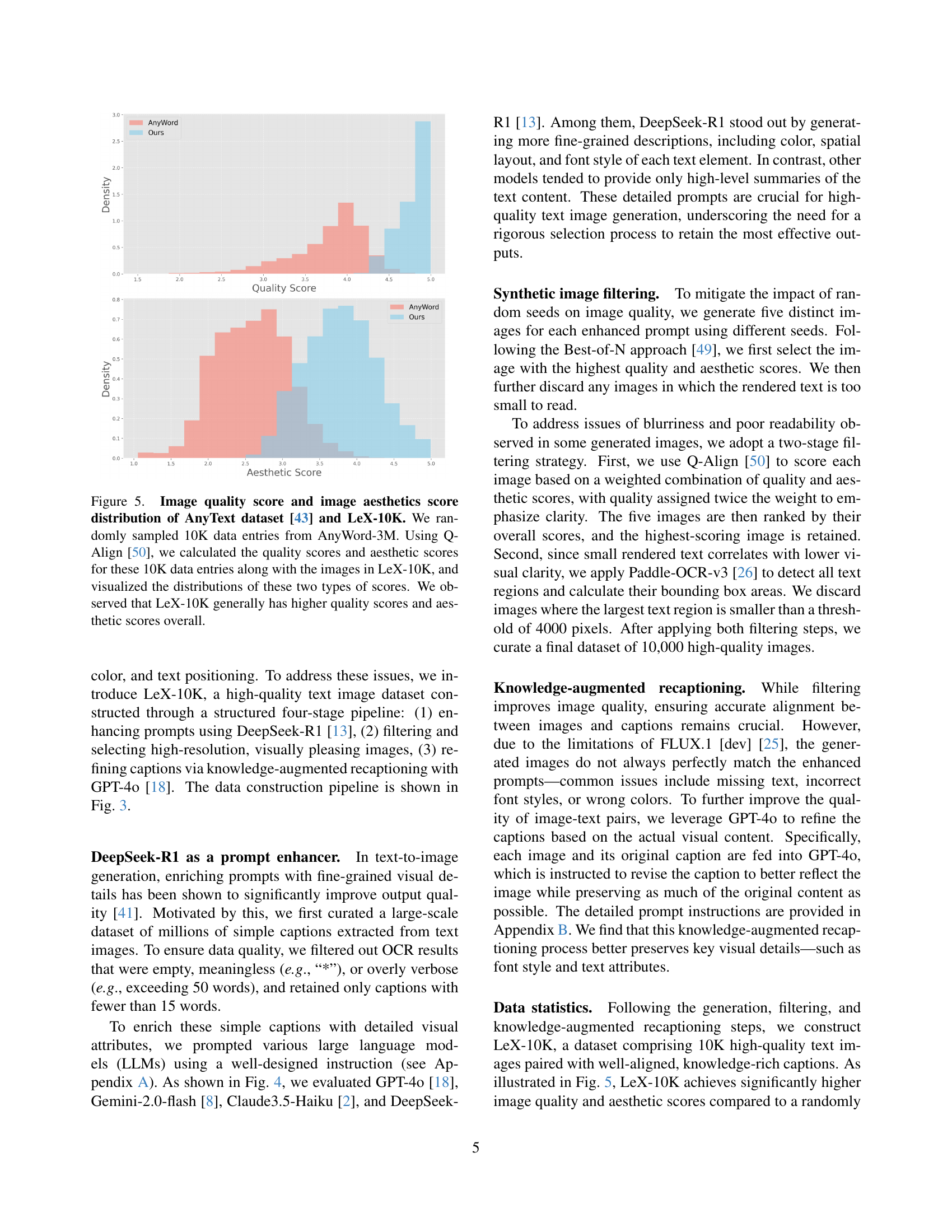
🔼 This figure compares the image quality and aesthetics scores between the AnyText dataset and the LeX-10K dataset. 10,000 samples were randomly selected from the AnyWord-3M dataset for comparison. The Q-Align metric was used to assess both image quality and aesthetics. The results show that LeX-10K images generally have significantly higher scores in both categories.
read the caption
Figure 5: Image quality score and image aesthetics score distribution of AnyText dataset [43] and LeX-10K. We randomly sampled 10K data entries from AnyWord-3M. Using Q-Align [50], we calculated the quality scores and aesthetic scores for these 10K data entries along with the images in LeX-10K, and visualized the distributions of these two types of scores. We observed that LeX-10K generally has higher quality scores and aesthetic scores overall.
🔼 LeX-Bench is a benchmark dataset designed to evaluate the performance of text-to-image generation models. It consists of 1310 prompts categorized into three difficulty levels: Easy (2-4 words), Medium (5-9 words), and Hard (10-14 words). The Easy level prompts further incorporate text attribute constraints including color, font, and position, providing a more comprehensive evaluation of the models’ capabilities.
read the caption
Figure 6: Overview of LeX-Bench. Prompts in LeX-Bench are split into three levels: 630 Easy-Level (2–4 words), 480 Medium-Level (5–9 words), and 200 Hard-Level (10–14 words). Prompts of the easy level also contain text attributes: color, font, position.

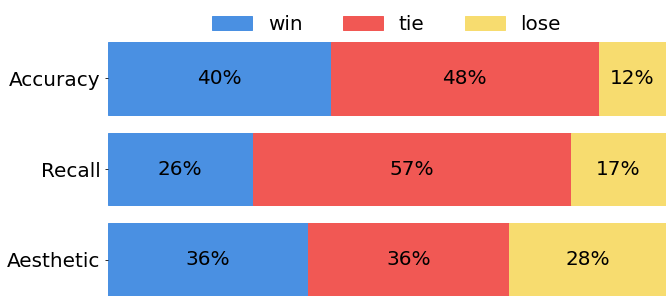
🔼 This figure presents the results of a human preference evaluation comparing the performance of LeX-Lumina and Lumina-Image 2.0 across three aspects: text accuracy, text recall rate, and aesthetics. The visualization uses a bar chart to show the percentage of votes where each model (LeX-Lumina and Lumina-Image 2.0) ‘wins’, ’loses’, or ’ties’ in each category. This provides a clear visual representation of the relative strengths and weaknesses of each model in terms of visual text generation.
read the caption
Figure 7: Human preference result on text accuracy, text recall rate and aesthetics for LeX-Lumina. For ease of illustration, we visualize the proportion of votes where LeX-Lumina wins, loses and ties with Lumina-Image 2.0.

🔼 Figure 8 presents a qualitative comparison of text-to-image generation results from LeX-Lumina, LeX-Flux, AnyText [43], and TextDiffuser [5] across five distinct prompts. The comparison highlights LeX-Lumina and LeX-Flux’s superior performance in terms of text fidelity, precise control over text attributes (color, font, etc.), and overall aesthetic appeal compared to the glyph-conditioned models AnyText and TextDiffuser.
read the caption
Figure 8: Qualitative comparison between LeX-Lumina, LeX-FLUX and glyph-conditioned models. We compare our models with AnyText [43] and TextDiffuser [5] for five different prompts. We observe that our models generally achieve high fidelity, better text attribute controllability and higher aesthetics.

🔼 This figure presents a qualitative comparison of image generation results from two models: Lumina-Image 2.0 and LeX-Lumina. Each model is evaluated under two conditions: without and with LeX-Enhancer (a prompt enhancement module), and using simple captions. The comparison showcases LeX-Lumina’s superior text rendering capabilities, demonstrating higher text fidelity and better aesthetics compared to Lumina-Image 2.0. Additionally, it highlights the effectiveness of LeX-Enhancer in improving results for both models, suggesting that this prompt enhancement method significantly boosts the quality of image generation from simple captions.
read the caption
Figure 9: Qualitative comparison between Lumina-Image 2.0 [35] and LeX-Lumina. The first column shows Lumina-Image-2.0 without LeX-Enhancer using Simple Caption; the second column shows the trained LeX-Lumina without LeX-Enhancer using Simple Caption; the third column shows Lumina-Image-2.0 with LeX-Enhancer enabled; and the fourth column shows LeX-Lumina with LeX-Enhancer enabled. We observe that (1) LeX-Lumina exhibits a better text rendering capability in terms of text fidelity and aesthetics; (2) LeX-Enhancer exhibits a strong capability for enhancing simple prompts.

🔼 This figure presents a qualitative comparison of text rendering results between FLUX.1 [dev] and LeX-FLUX, with and without the LeX-Enhancer. The comparison is based on five different prompts. Each row shows the results for a single prompt, while each column shows different model configurations: (1) FLUX.1 [dev] with a simple caption and no LeX-Enhancer, (2) LeX-FLUX (trained with the LeX-10K dataset) with a simple caption and no LeX-Enhancer, (3) FLUX.1 [dev] with a simple caption and LeX-Enhancer enabled, and (4) LeX-FLUX with a simple caption and LeX-Enhancer enabled. The results visually demonstrate that LeX-FLUX exhibits improved text fidelity and controllability over text attributes (color, font, position) compared to FLUX.1 [dev], and that the LeX-Enhancer significantly improves the quality of results generated from simple prompts.
read the caption
Figure 10: Qualitative comparison between FLUX.1 [dev] [25] and LeX-FLUX. The first column shows FLUX.1 [dev] without LeX-Enhancer using Simple Caption; the second column shows the trained LeX-FLUX without LeX-Enhancer using Simple Caption; the third column shows FLUX.1 [dev] with LeX-Enhancer enabled; and the fourth column shows LeX-FLUX with LeX-Enhancer enabled. We observe that (1) LeX-FLUX exhibits a better text rendering capability in terms of text fidelity and text attributes controllability; (2) LeX-Enhancer exhibits a strong capability for enhancing simple prompts.

🔼 This figure presents a comparison of image samples from three different datasets: AnyWord-3M, MARIO-10M, and LeX-10K. Each dataset is represented by a grid of 16 images. The figure allows for a visual comparison of the image quality, aesthetic appeal, diversity of text styles and layouts across the datasets. It highlights the improvements in image quality and text rendering achieved by LeX-10K compared to existing web-crawled datasets.
read the caption
Figure 11: Comparison of data samples from AnyWord-3M [43], MAION-10M [5] and LeX-10K.

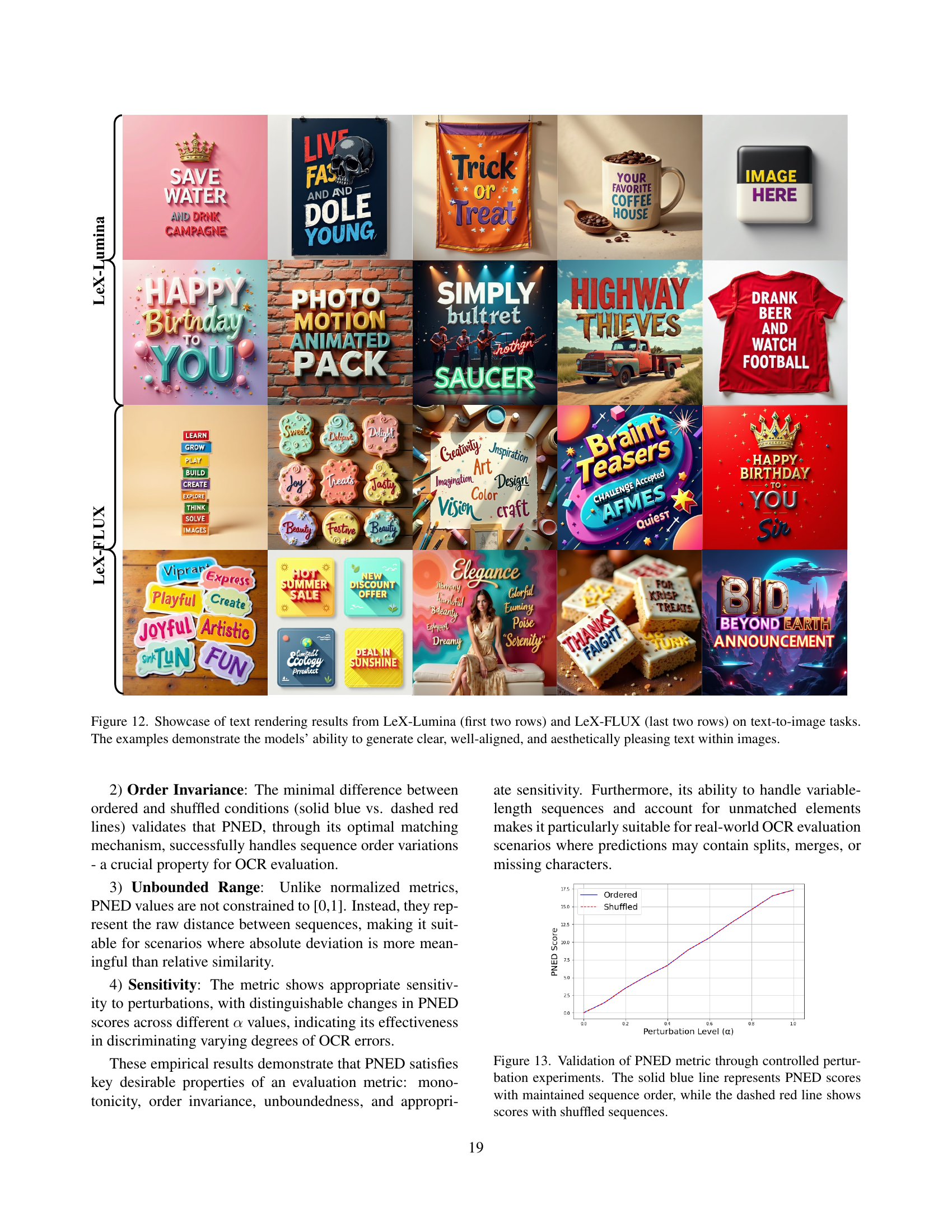
🔼 This figure showcases the text rendering capabilities of two models, LeX-Lumina and LeX-FLUX, for text-to-image generation tasks. The top two rows display results from LeX-Lumina, while the bottom two rows show results from LeX-FLUX. Each image demonstrates the models’ ability to generate text that is clear, accurately positioned, and aesthetically integrated with the overall image. The examples highlight various text styles, font choices, layouts, and background designs, illustrating the versatility of both models in creating visually appealing text within diverse image contexts.
read the caption
Figure 12: Showcase of text rendering results from LeX-Lumina (first two rows) and LeX-FLUX (last two rows) on text-to-image tasks. The examples demonstrate the models’ ability to generate clear, well-aligned, and aesthetically pleasing text within images.
Full paper#