TL;DR#
Recent advancements in video generation have achieved impressive visual realism but often fail to adhere to fundamental physical laws. This leads to scenarios where generated videos appear visually plausible but are physically nonsensical. Existing models lack a deep understanding of physics, hindering their application in domains such as robotics and autonomous driving. To address this gap, researchers are exploring methods to incorporate physical knowledge into generative models, aiming to create more realistic and reliable simulations. The key challenge is how to effectively embed physical rules and constraints into the learning process, enabling models to reason about and predict the behavior of objects in dynamic environments.
This survey offers a comprehensive overview of the evolution of physical cognition in video generation, categorizing approaches into three tiers: basic schema perception, passive cognition of physical knowledge, and active cognition for world simulation. It examines various techniques, including motion-guided generation, physics-inspired regularization, and the use of physics simulators. The survey also discusses existing benchmarks and metrics for evaluating physical plausibility and highlights key challenges and future research directions, such as constructing large foundational physics models and addressing the Sim2Real gap.
Key Takeaways#
Why does it matter?#
This survey is crucial for researchers in video generation, robotics and autonomous driving. It highlights the limitations of current models in physical reasoning and offers guidance for developing more realistic and reliable AI systems. The paper opens new avenues for interpretable and physically consistent video generation.
Visual Insights#

🔼 Figure 1 showcases videos generated by three leading-edge video generation models (Open-Sora 1.2, CogVideoX 5B, and Cosmos 7B) in response to various prompts. The examples highlight a common challenge in current generative video models: while they can produce visually realistic videos, these videos often violate fundamental laws of physics. This discrepancy, which can range from minor inconsistencies to significant violations of Newtonian mechanics, is a major area of current research and improvement efforts in the field of AI video generation.
read the caption
Figure 1: Video cases generated by three typical state-of-the-art generative video models[1, 48, 87]. We can observe that these advanced models still struggle to produce satisfying videos that strictly conform to physical laws.
| Physics Engines and Platforms | Programming Language | GPU Acceleration | Supported Physics Types | Open Source | Typical Application Scenarios |
| Bullet[152] | C++ | Partial support | Rigid, soft body , collision detection, constraint solving | Game development, film special effects, and robotics simulation | |
| PyBullet[153] | Python | Partial support | Rigid, soft body , collision detection, constraint solving | Robot simulation, reinforcement learning | |
| Blender Physics[131] | Python | Partial support | Rigid body, soft body, fluids, fabrics and particle systems | 3D animation and film special effects | |
| Isaac Gym[154] | Python | Fullly support | Rigid body and joint drive | Large-scale parallel simulation, complex robot motion control | |
| NVIDIA PhysX[155] | C++ | Fullly support | Rigid body, soft body, cloth, fluids and particle system | Game development, virtual reality, and industrial simulation | |
| Taichi[156] | Python/C++ | Fullly support | Fluids, elastic bodies, particle systems | Support for custom physical models (e.g. MPM[157]) | |
| NVIDIA Omniverse[158] | Python/C++/USD[159] | Fullly support | Multi-physics engine integration | Cross-software collaboration, digital twins | |
| Genesis[160] | Python | Fullly support | Coupling various physical models | Robot realistic data generation |
🔼 This table compares various physics engines and platforms, highlighting key features such as programming language, support for different physics types (rigid body, soft body, fluids, etc.), GPU acceleration capabilities, open-source availability, and typical application scenarios. It provides a concise overview of the strengths and weaknesses of each engine or platform for users to choose the most suitable one based on their needs and project requirements.
read the caption
TABLE I: Comparison of features of physics engines and platforms.
In-depth insights#
Physics Cognition#
Physics Cognition in video generation focuses on imbuing models with an understanding of the physical world. This goes beyond mere visual realism; it requires adherence to physical laws. Early approaches focused on motion consistency, using video or motion cues to guide generation. Then, research shifted to explicitly incorporating physics, using simulators or LLMs. Simulators enable generating physically plausible data, while LLMs offer commonsense reasoning. A key challenge is balancing realism with computational efficiency, and bridging the gap between simulated and real environments. Future directions involve creating large physics models and active interaction with the environment.
Taxonomy of Cognition#
The study introduces a novel taxonomy of physical cognition in video generation, drawing inspiration from Piaget’s theory of cognitive development. The taxonomy is structured around three key stages: Intuitive perception, Symbolic learning, and Interaction. This taxonomy provides a framework for understanding how generative models can evolve from simply mimicking visual patterns to actively reasoning about and predicting physical phenomena. The significance lies in its potential to bridge the gap between visually realistic and physically plausible video generation, ultimately enhancing the applicability of these models in domains such as robotics and autonomous driving. The taxonomy offers a guide for developing explainable, controllable, and physically consistent video generation paradigms, pushing the boundaries of AI.
Schematic Perception#
Schematic Perception focuses on leveraging basic visual patterns to guide video generation, enhancing motion consistency. Early methods relied on simple signals, often struggling with fine-grained dynamic control. Recent advancements abstract physical visual patterns (optical flow, trajectories) into controllable schemas, injecting them into latent spaces for motion-coherent videos. Techniques involve video-guided approaches, transferring motion attributes from reference videos using dual-prior frameworks (motion pattern and semantic content). Motion-guided generation emerges, introducing explicit motion control signals as conditional constraints, adopting single or two-stage paradigms. Despite progress, challenges persist, such as motion inconsistencies and ambiguities in camera transitions. Efforts are being made to improve motion consistency and camera-object motion control and generate 3D spatial motions.
Passive Knowledge#
Passive cognition emphasizes pre-existing data to enhance video generation. It focuses on incorporating prior knowledge, like physics simulators or LLMs, to enhance physical realism. This contrasts with intuitive methods and active learning. Methods include using physical loss constraints, simulators, and LLMs for reasoning. Passive methods ensure physical consistency but may lack adaptability to unforeseen situations. While passive knowledge is beneficial for visual coherence, the approach is usually limited because it relies on rigid application of facts. The dependence on LLMs or other means of embedding knowledge poses a challenge in bridging the gap between theoretical principles and applying them to real situations. Addressing these limitations requires active interaction with the environment.
Active Simulation#
Active Simulation marks a pivotal shift in video generation, moving beyond mere replication of existing data towards models that actively interact with and learn from their environment. This entails endowing generative systems with the capacity to predict future states through iterative engagement, allowing for continuous refinement of their internal world models. Unlike passive approaches reliant on pre-stored knowledge, active simulation fosters adaptability and generalization by enabling models to dynamically update their understanding based on feedback, closing the loop between generation, observation, and correction. Multimodal data integration is crucial, incorporating visual, linguistic, and action information to build comprehensive environmental representations. By dynamically updating through interaction, these models bridge the gap between simulation and real-world complexity. ** This active cognition-driven approach enhances counterfactual prediction accuracy and improves generalization ability** It also entails a move toward models designed to integrate more sensor modalities, going beyond mere pixel level rendering, and moving towards genuine physical interaction. As generative models evolve to be more like human brains, they will become more and more capable of creating rich, physically accurate, dynamic video.
More visual insights#
More on figures

🔼 This figure illustrates the parallel evolution of human cognitive development and the capabilities of video generation systems. It maps Piaget’s stages of cognitive development (‘Intuitive Perception’, ‘Symbolic Learning’, ‘Interaction’) to the three-tiered taxonomy of physical cognition in video generation: 1) Basic Schematic Perception, 2) Passive Cognition of Physical Knowledge, and 3) Active Cognition for World Simulation. Each tier represents a progressive level of understanding and modeling of physical phenomena, mirroring the stages of human cognitive development.
read the caption
Figure 2: Cognitive evolution processes of individuals and generation system.

🔼 This figure presents a taxonomy of physical phenomena categorized into four main domains: mechanics, optics, thermodynamics, and material properties, which constitute the PhysGenBench benchmark. The benchmark includes a total of 27 physical laws and 4 commonsense principles, illustrating the wide range of physical concepts covered in the benchmark. Each domain is further divided into subcategories representing specific physical laws or principles related to the domain. This comprehensive taxonomy is essential for evaluating the ability of generative models to accurately represent physical realism in simulated environments.
read the caption
Figure 3: The taxonomy of PhysGenBench[86] benchmark, including 4 physical commonsense and 27 physical laws.

🔼 Figure 4 illustrates four prominent generative models frequently used in video generation: Generative Adversarial Networks (GANs), Diffusion Models, Neural Radiance Fields (NeRF), and Gaussian Splatting. Each model is represented with a schematic diagram highlighting its core components and functionalities. GANs are shown with their competing generator and discriminator networks. Diffusion Models depict the iterative noise addition and removal process. NeRF illustrates the volumetric scene representation and novel view synthesis. Lastly, Gaussian Splatting shows the scene representation as a set of 3D Gaussian kernels.
read the caption
Figure 4: Introduction to mainstream generative models: GANs[100], Diffusion Models[101], NeRF[102], Gaussian Splatting[103].

🔼 This figure presents a hierarchical taxonomy of video generation methods categorized by their level of physical cognition. It illustrates the evolutionary path from simpler methods that only capture basic motion patterns to more advanced approaches integrating complex physical simulations and interactions. The tree structure shows the progression of techniques from ‘Basic Schematic Perception for Generation’ (using simple motion cues) through ‘Passive Cognition of Physical Knowledge for Generation’ (incorporating physical knowledge from simulators or LLMs) to ‘Active Cognition for World Simulation’ (actively interacting with a simulated or real environment). Each level contains example methods, highlighting the development of physically informed video generation.
read the caption
Figure 5: Overview of the evolution of physical cognition in video generation. Please note that the typical methods listed here cover only a subset of the relevant literature and do not represent all existing studies.

🔼 Figure 6 illustrates two distinct pipelines for generating videos using motion signals as guidance. Panel (a) shows a video-guided approach (detailed in Section 4.1), where motion information is extracted from a reference video and used to generate a new video with similar movement but potentially different content (e.g., changing the appearance while retaining the movement from the reference video). Panel (b) displays a motion-guided approach (explained in Section 4.2), which directly incorporates explicit motion signals (such as optical flow or trajectories) as input to control the generation process. This approach allows for more direct manipulation of the generated video’s movement.
read the caption
Figure 6: Basic motion signal-guided generation pipeline. (a) is a video-guided generation pipeline in Sec. 4.1, while (b) is a motion-guided generation pipeline in Sec. 4.2.

🔼 The figure illustrates the pipeline of physics-inspired regularization in video generation. It shows how geometric and energy conservation losses are used to constrain a generative model’s output, ensuring that the generated video adheres to physical laws. The geometric loss focuses on maintaining the consistency of geometric relationships throughout the video, while the energy conservation loss ensures that energy is conserved in physical interactions within the scene. This combination of losses guides the model towards creating videos that are not only visually appealing but also physically plausible.
read the caption
Figure 7: Physics-inspired regularization pipeline.

🔼 This figure illustrates the generation pipeline of PhysGaussian [132], a method that integrates physical simulation with visual rendering. It begins with a 3D representation of the scene. This representation is then fed into a Material Point Method (MPM) simulator, which applies forces and simulates the resulting physical interactions and dynamics. The results of this simulation are used in a rendering step to produce a final video.
read the caption
Figure 8: Generation pipeline based on physical simulation, cf. Physguassian[132].

🔼 This figure illustrates a pipeline where a physics simulator is used to generate motion signals which are then incorporated into a video generation model. The physics simulator takes various inputs, such as 3D Gaussian models, possibly including additional inputs not explicitly shown in the figure (like scene geometry, material properties, external forces, etc). It simulates these inputs to produce motion signals representing the dynamics in the scene according to physical laws. These motion signals are then fed into a video generation model, and this model uses these motion signals along with other information to generate the final video. This process aims to enhance the realism and physical accuracy of the generated video by grounding it in physically plausible motions from the physics simulation.
read the caption
Figure 9: Physics simulator generates motion signals.

🔼 PhysDreamer’s architecture uses a differentiable material point method (MPM) simulator to generate physically plausible foreground dynamics. The model iteratively refines both the material field and velocity field by minimizing the difference between its rendered video and a reference video. This iterative process optimizes the video’s physical accuracy against the reference.
read the caption
Figure 10: Architecture of PhysDreamer[126]. Optimize the material field and velocity field by minimizing the discrepancy between the rendered video and the reference video.
🔼 This figure illustrates how Large Language Models (LLMs) can be used to incorporate physical knowledge into video generation. It shows a three-stage process: 1) Dynamic Scene Layouts: The LLM takes a user’s text prompt and generates a scene layout by planning the spatiotemporal arrangement of objects. This layout is informed by the physical world knowledge present in the LLM. 2) Program Generation: A program is generated from the user instructions. This program details the actions needed to manipulate objects in the scene, again informed by physical principles implicit in the LLM’s knowledge. 3) Physical Properties Inference: The LLM identifies materials and infers their relevant physical properties (e.g., density, Young’s modulus) based on the objects in the scene and the intended actions. The inferred properties are then used to guide the simulation and generation of physically plausible videos.
read the caption
Figure 11: World physics knowledge in LLMs is used for scene layouts, program generation, and properties inference.

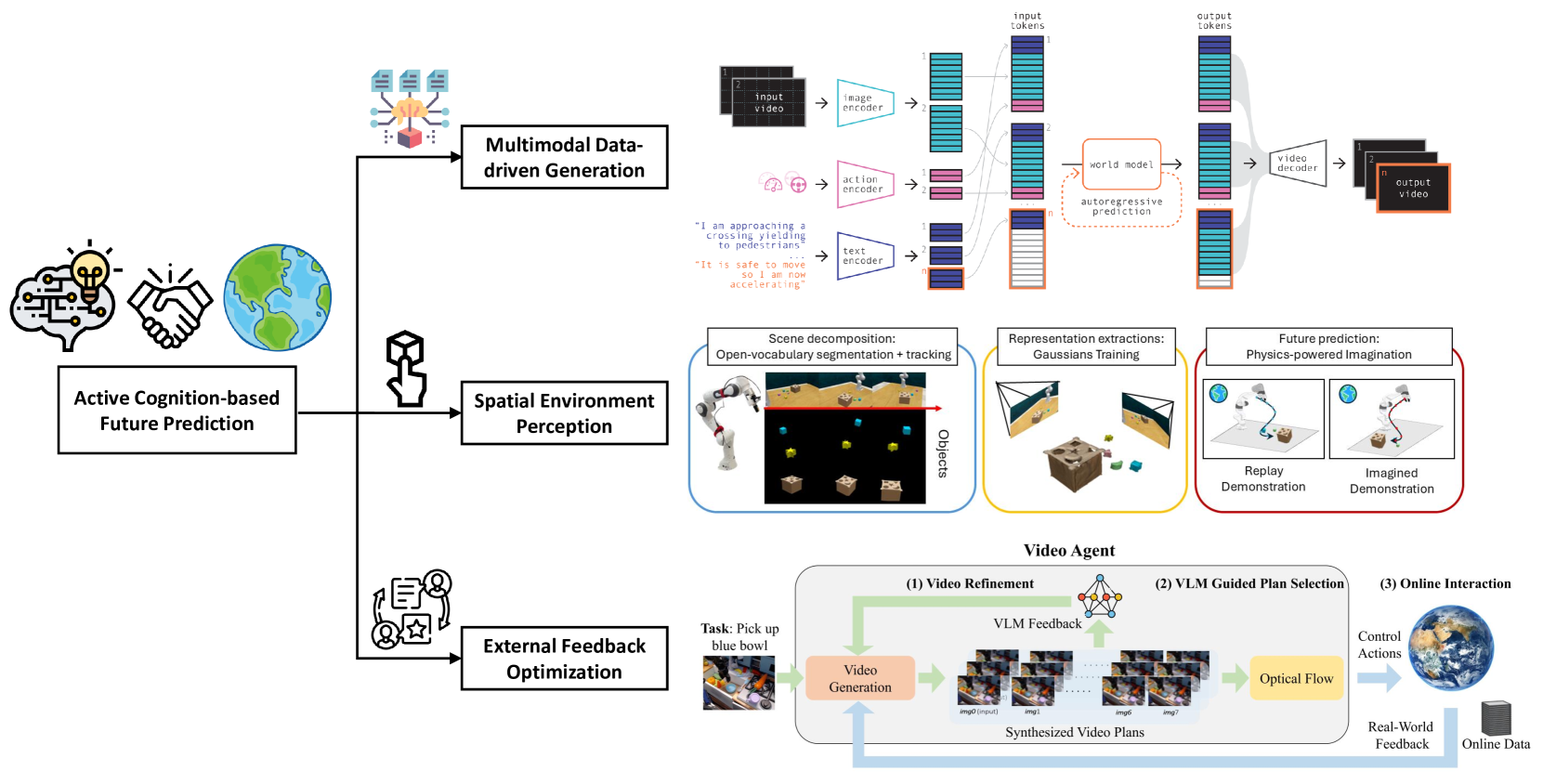
🔼 This figure illustrates the architecture of a model that actively interacts with its environment to predict future events. This is achieved through a combination of three key components: 1) Multimodal Data-driven Generation: The model integrates various data sources (video, images, text, actions) to build a comprehensive understanding of the environment. 2) Spatial Environment Perception: The model utilizes scene decomposition techniques (like open-vocabulary segmentation and tracking) to analyze the objects and their relationships within the scene. 3) External Feedback Optimization: The model receives feedback from its actions in the environment (e.g., real-world feedback) to refine its predictions and control its interactions. The loop of prediction, action, and feedback allows the model to learn and adapt to dynamic changes in the environment, improving its ability to predict future states.
read the caption
Figure 12: The model actively interacts with the environment to achieve future prediction through multimodal data-driven generation, spatial environment perception, and external feedback optimization.
More on tables
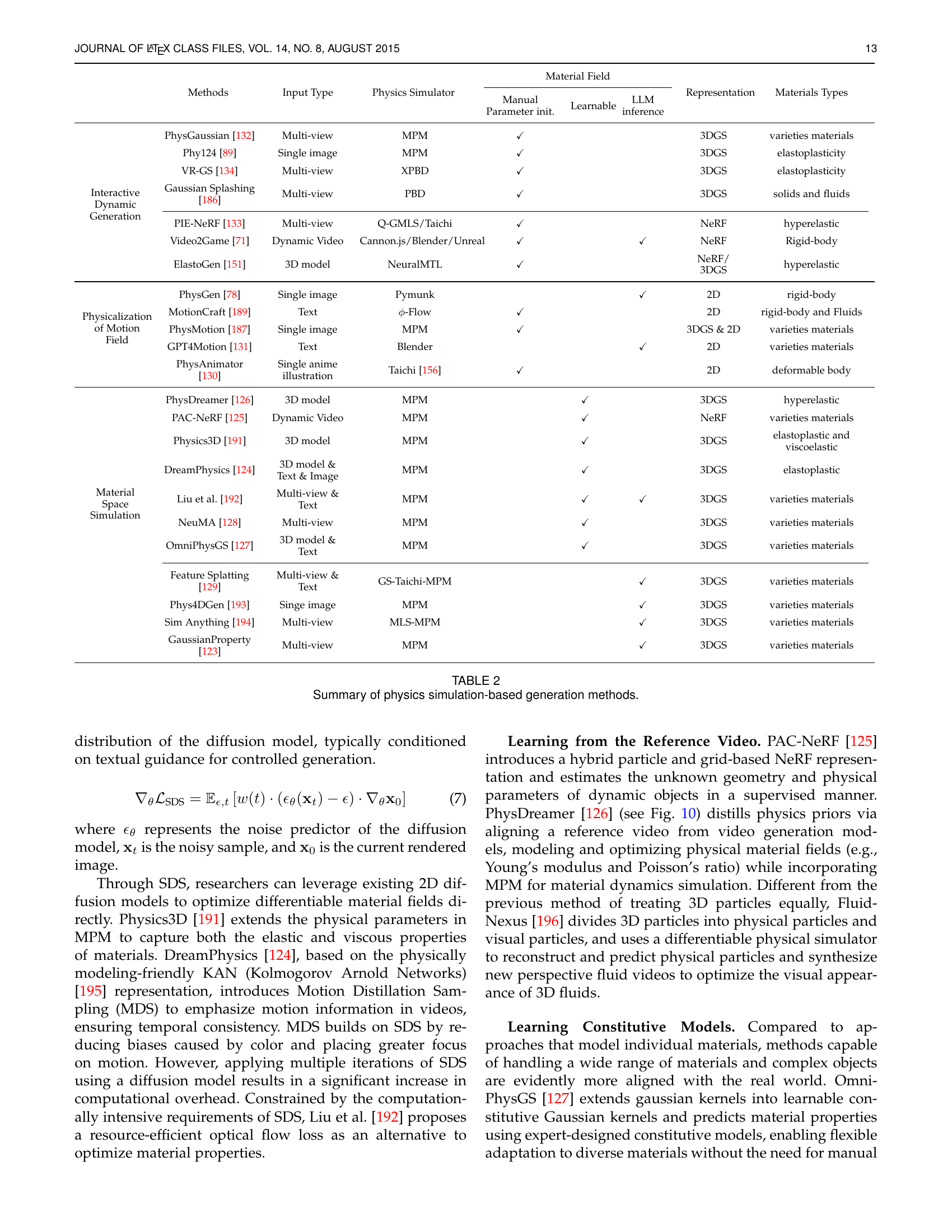
| Methods | Input Type | Physics Simulator | Material Field | Representation | Materials Types | |||
| Manual Parameter init. | Learnable | LLM inference | ||||||
| Interactive Dynamic Generation | PhysGaussian[132] | Multi-view | MPM | 3DGS | varieties materials | |||
| Phy124[89] | Single image | MPM | 3DGS | elastoplasticity | ||||
| VR-GS[134] | Multi-view | XPBD | 3DGS | elastoplasticity | ||||
| Gaussian Splashing[186] | Multi-view | PBD | 3DGS | solids and fluids | ||||
| PIE-NeRF[133] | Multi-view | Q-GMLS/Taichi | NeRF | hyperelastic | ||||
| Video2Game[71] | Dynamic Video | Cannon.js/Blender/Unreal | NeRF | Rigid-body | ||||
| ElastoGen[151] | 3D model | NeuralMTL | NeRF/ 3DGS | hyperelastic | ||||
| Physicalization of Motion Field | PhysGen[78] | Single image | Pymunk | 2D | rigid-body | |||
| MotionCraft[189] | Text | -Flow | 2D | rigid-body and Fluids | ||||
| PhysMotion[187] | Single image | MPM | 3DGS & 2D | varieties materials | ||||
| GPT4Motion[131] | Text | Blender | 2D | varieties materials | ||||
| PhysAnimator[130] | Single anime illustration | Taichi[156] | 2D | deformable body | ||||
| Material Space Simulation | PhysDreamer[126] | 3D model | MPM | 3DGS | hyperelastic | |||
| PAC-NeRF[125] | Dynamic Video | MPM | NeRF | varieties materials | ||||
| Physics3D[191] | 3D model | MPM | 3DGS | elastoplastic and viscoelastic | ||||
| DreamPhysics[124] | 3D model & Text & Image | MPM | 3DGS | elastoplastic | ||||
| Liu et al.[192] | Multi-view & Text | MPM | 3DGS | varieties materials | ||||
| NeuMA[128] | Multi-view | MPM | 3DGS | varieties materials | ||||
| OmniPhysGS[127] | 3D model & Text | MPM | 3DGS | varieties materials | ||||
| Feature Splatting[129] | Multi-view & Text | GS-Taichi-MPM | 3DGS | varieties materials | ||||
| Phys4DGen[193] | Singe image | MPM | 3DGS | varieties materials | ||||
| Sim Anything[194] | Multi-view | MLS-MPM | 3DGS | varieties materials | ||||
| GaussianProperty[123] | Multi-view | MPM | 3DGS | varieties materials | ||||
🔼 This table summarizes various video generation methods that leverage physics simulation. For each method, it lists the input type (e.g., multi-view images, text), the physics simulator used (e.g., MPM, XPBD), whether manual parameter initialization or learnable parameters were used, the use of LLMs (Large Language Models), the type of representation used (e.g., 3D Gaussians, NeRF), and the types of materials modeled (e.g., rigid bodies, elastoplasticity, fluids). It provides a comprehensive overview of different approaches to integrating physics simulation into video generation.
read the caption
TABLE II: Summary of physics simulation-based generation methods.
| Methods | Reward Model | Feedback Type | Optimization Technique | Optimization Direction |
| IPO[109] | Human-Annotated Training VLM | Pair-wise & Point-wise feedback | Diffusion-DPO[213] & Diffusion-KTO[214] | Subject consistency, motion smoothness and aesthetic quality |
| VideoReward[110] | Human-Annotated Training VLM | Pair-wise feedback | Flow-DPO& Flow-RWR&Flow-NRG | Visual quality, motion quality, and text alignment |
| Furuta et al.[82] | Gemini-1.5-Pro[215] & Metric | Pair-wise & Point-wise feedback | RWR][216] & DPO[217] | Overall coherence, physical accuracy, task completion, and the existence of inconsistencies |
| VideoAgent[111] | GPT4-turbo[202] & Online Execution Feedback | Binary value | Consistency models[218] & Online finetuning | Trajectory smoothness, physical stability and achieving the goal |
| Gen-Drive[112] | GPT-4o[202] | Pair-wise feedback | DDPO[219] | Complex traffic environment, scene consistency and interactive dynamics |
| PhyT2V[113] | GPT-4o[202] | Mismatch between video semantics and prompts | LLM global step-back reasoning | Adherence physical rules |
🔼 This table provides a detailed comparison of various methods used for external feedback optimization in video generation. It outlines key characteristics of each method, including the type of reward model used (e.g., human-annotated, VLM-trained), the feedback type (e.g., pairwise, point-wise), and the optimization techniques employed (e.g., diffusion-based optimization, reward-weighted regression). The table also specifies the optimization direction for each method, highlighting the specific aspects of video generation that are being optimized (e.g., subject consistency, motion smoothness, physical accuracy).
read the caption
TABLE III: Overview of the characteristics of various methods in external feedback optimization.
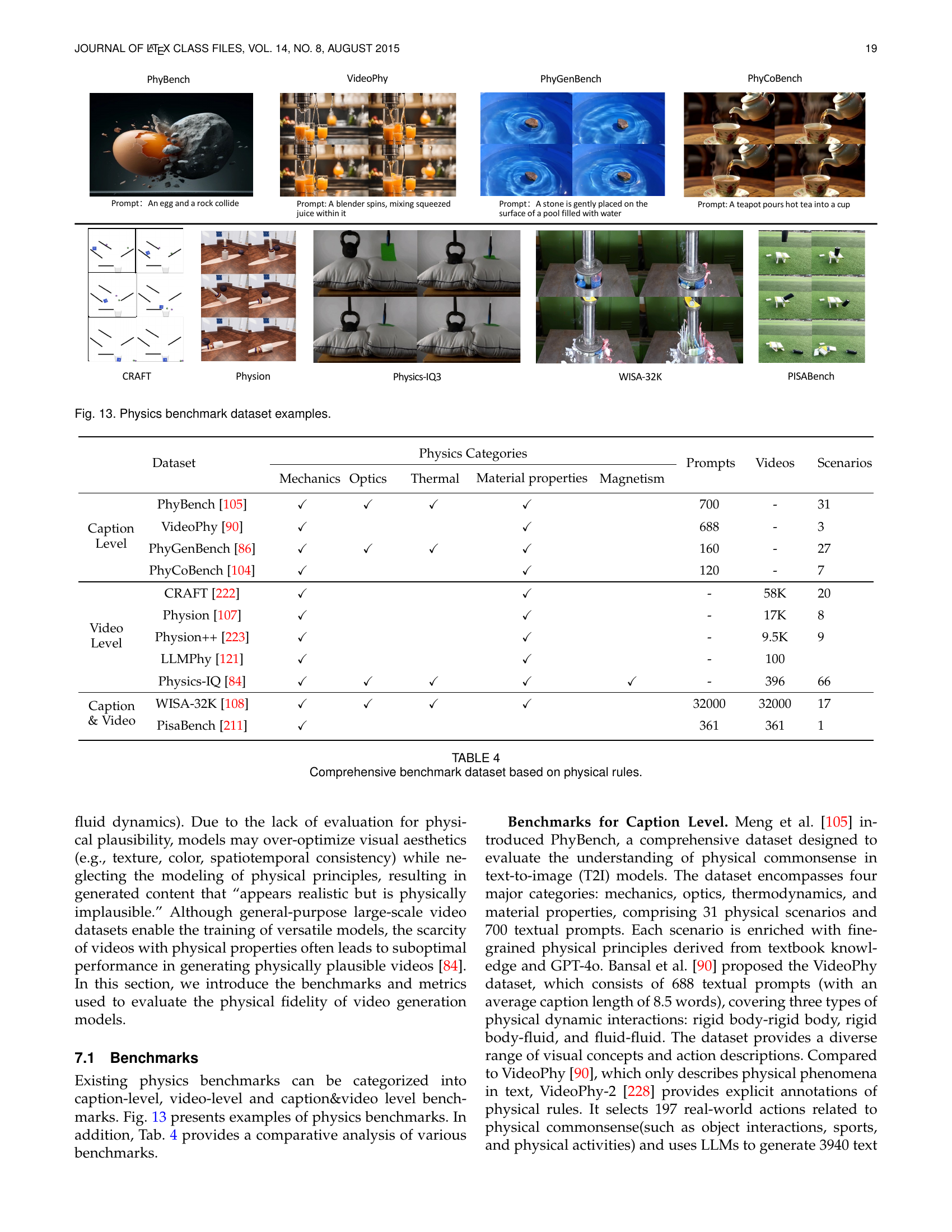
| Dataset | Physics Categories | Prompts | Videos | Scenarios | |||||
| Mechanics | Optics | Thermal | Material properties | Magnetism | |||||
| Caption Level | PhyBench[105] | 700 | - | 31 | |||||
| VideoPhy[90] | 688 | - | 3 | ||||||
| PhyGenBench[86] | 160 | - | 27 | ||||||
| PhyCoBench[104] | 120 | - | 7 | ||||||
| Video Level | CRAFT[222] | - | 58K | 20 | |||||
| Physion[107] | - | 17K | 8 | ||||||
| Physion++[223] | - | 9.5K | 9 | ||||||
| LLMPhy[121] | - | 100 | |||||||
| Physics-IQ[84] | - | 396 | 66 | ||||||
| Caption & Video | WISA-32K[108] | 32000 | 32000 | 17 | |||||
| PisaBench[211] | 361 | 361 | 1 | ||||||
🔼 This table provides a comprehensive overview of benchmark datasets used to evaluate the physical realism of video generation models. It categorizes datasets based on their evaluation level (caption-level, video-level, or caption&video level), highlighting the specific physical phenomena and properties evaluated in each. The table lists the number of prompts and videos included in each dataset and indicates the presence of different physics categories (Mechanics, Optics, Thermal, Material properties, and Magnetism) covered. It provides a detailed comparison across various benchmark datasets, enabling researchers to identify suitable datasets for specific needs in assessing physical fidelity in generated video content.
read the caption
TABLE IV: Comprehensive benchmark dataset based on physical rules.
Full paper#