TL;DR#
Inspired by DeepSeek-R1, this paper introduces Video-R1, to explore rule-based reinforcement learning (RL) for video reasoning in multimodal large language models (MLLMs). Applying RL to video presents challenges: lack of temporal modeling and scarcity of video-reasoning data. To address the challenges, the paper introduces T-GRPO algorithm, which encourages models to utilize temporal information for reasoning. Instead of only video, it incorporates high-quality image-reasoning data.
Video-R1 constructs two datasets: Video-R1-COT and Video-R1 for SFT cold start and RL training, comprising both image and video data. Experiments show Video-R1 improves on video reasoning benchmarks like VideoMMMU, VSI-Bench, MVBench, and TempCompass. Notably, Video-R1-7B achieves 35.8% accuracy on VSI-Bench, surpassing the commercial model GPT-4o. The project releases codes, models, and data.
Key Takeaways#
Why does it matter?#
This paper introduces Video-R1, advancing video reasoning in MLLMs via rule-based RL and a novel temporal-aware training method. It sets a new state-of-the-art on VSI-Bench, highlighting the impact of reasoning capabilities for video tasks and stimulating further research in this field.
Visual Insights#

🔼 This figure illustrates the reasoning processes of the Video-R1 model trained with two different algorithms: GRPO and the proposed T-GRPO. The example demonstrates how a model without explicit temporal modeling (GRPO) may take shortcuts and arrive at an incorrect answer by focusing on a single frame instead of considering the temporal evolution of events in the video. In contrast, the model trained with T-GRPO shows a more thorough and accurate reasoning process by considering the temporal relationships between frames. This highlights the importance of incorporating temporal information for robust video reasoning.
read the caption
Figure 1: Reasoning paths of Video-R1 trained by GRPO and our proposed T-GRPO on test samples. Without explicit temporal modeling, models may learn sub-optimal video reasoning patterns by taking shortcuts, therefore failing to generalize well.
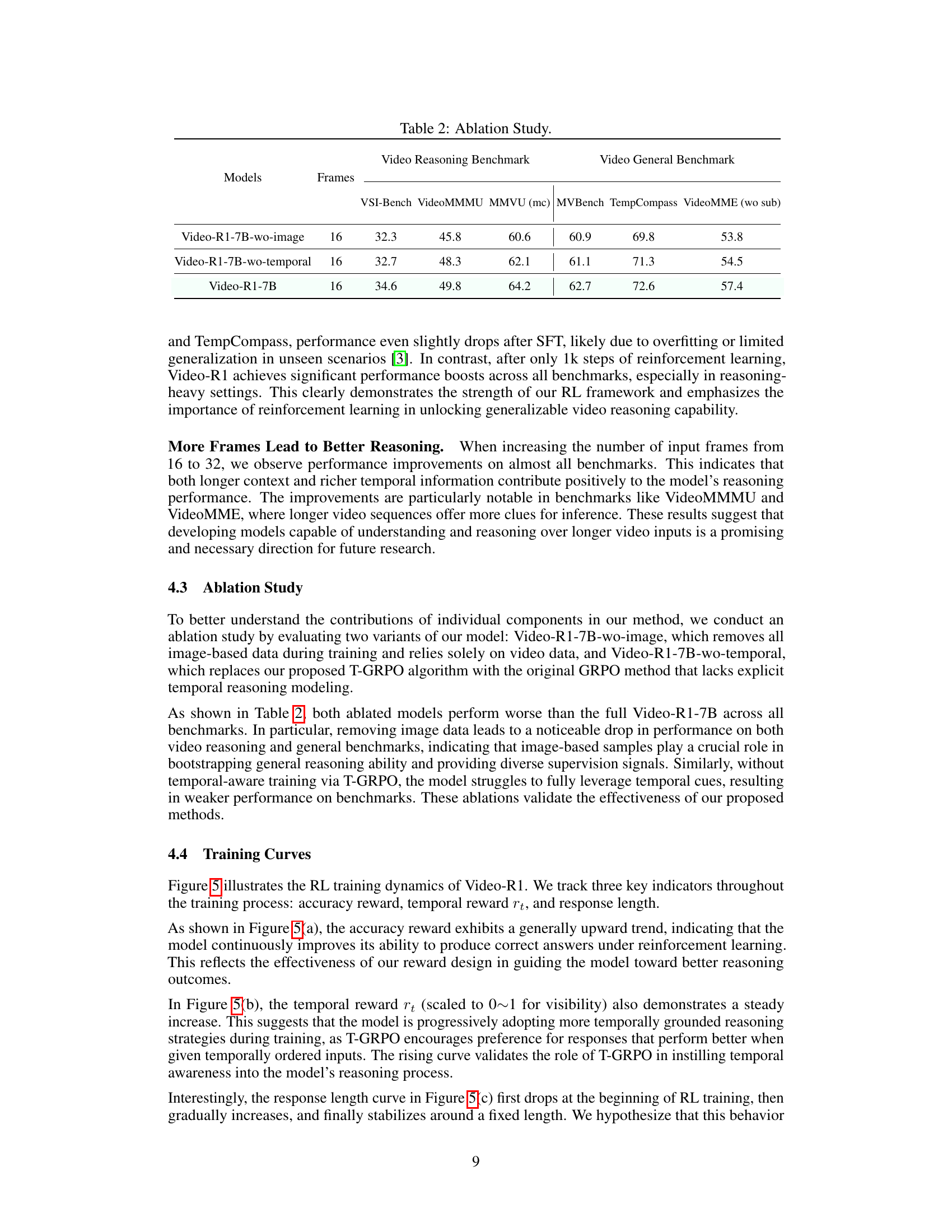
| Models | Frames | Video Reasoning Benchmark | Video General Benchmark | ||||
|---|---|---|---|---|---|---|---|
| VSI-Bench | VideoMMMU | MMVU (mc) | MVBench | TempCompass | VideoMME (wo sub) | ||
| GPT-4o [9] | - | 34.0 | 61.2 | 75.4 | - | - | 71.9 |
| LLaMA-VID [15] | - | - | - | - | 41.9 | 45.6 | - |
| VideoLLaMA2 [2] | - | - | - | 44.8 | 54.6 | - | 47.9 |
| LongVA-7B [28] | - | 29.2 | 23.9 | - | - | 56.9 | 52.6 |
| VILA-1.5-8B [16] | - | 28.9 | 20.8 | - | - | 58.8 | - |
| VILA-1.5-40B [16] | - | 31.2 | 34.0 | - | - | - | 60.1 |
| Video-UTR-7B [26] | - | - | - | - | 58.8 | 59.7 | 52.6 |
| LLaVA-OneVision-7B [12] | - | 32.4 | 33.8 | 49.2 | 56.7 | - | 58.2 |
| Kangeroo-8B [17] | - | - | - | - | 61.1 | 62.5 | 56.0 |
| Qwen2.5-VL-7B (COT) | 16 | 27.7 | 47.8 | 59.2 | 57.4 | 72.2 | 53.1 |
| Qwen2.5-VL-7B-SFT | 16 | 31.8 | 47.4 | 61.3 | 59.4 | 69.2 | 52.8 |
| Qwen2.5-VL-7B (COT) | 32 | 30.1 | 48.1 | 60.0 | 59.0 | 72.6 | 56.6 |
| Qwen2.5-VL-7B-SFT | 32 | 33.3 | 49.4 | 63.5 | 60.5 | 69.9 | 55.4 |
| Video-R1-7B | 16 | 34.6 | 49.8 | 64.2 | 62.7 | 72.6 | 57.4 |
| Video-R1-7B | 32 | 35.8 | 52.3 | 63.8 | 63.9 | 73.2 | 59.3 |
🔼 This table presents a comparison of various models’ performance across several video understanding benchmarks. The benchmarks are categorized into video reasoning tasks (VSI-Bench, VideoMMMU, MMVU) and general video understanding tasks (MVBench, TempCompass, VideoMME). For each model, the table shows its performance (usually accuracy) on each benchmark, along with the number of video frames used during evaluation.
read the caption
Table 1: Performance of different models on benchmarks.
In-depth insights#
RL for MLLMs#
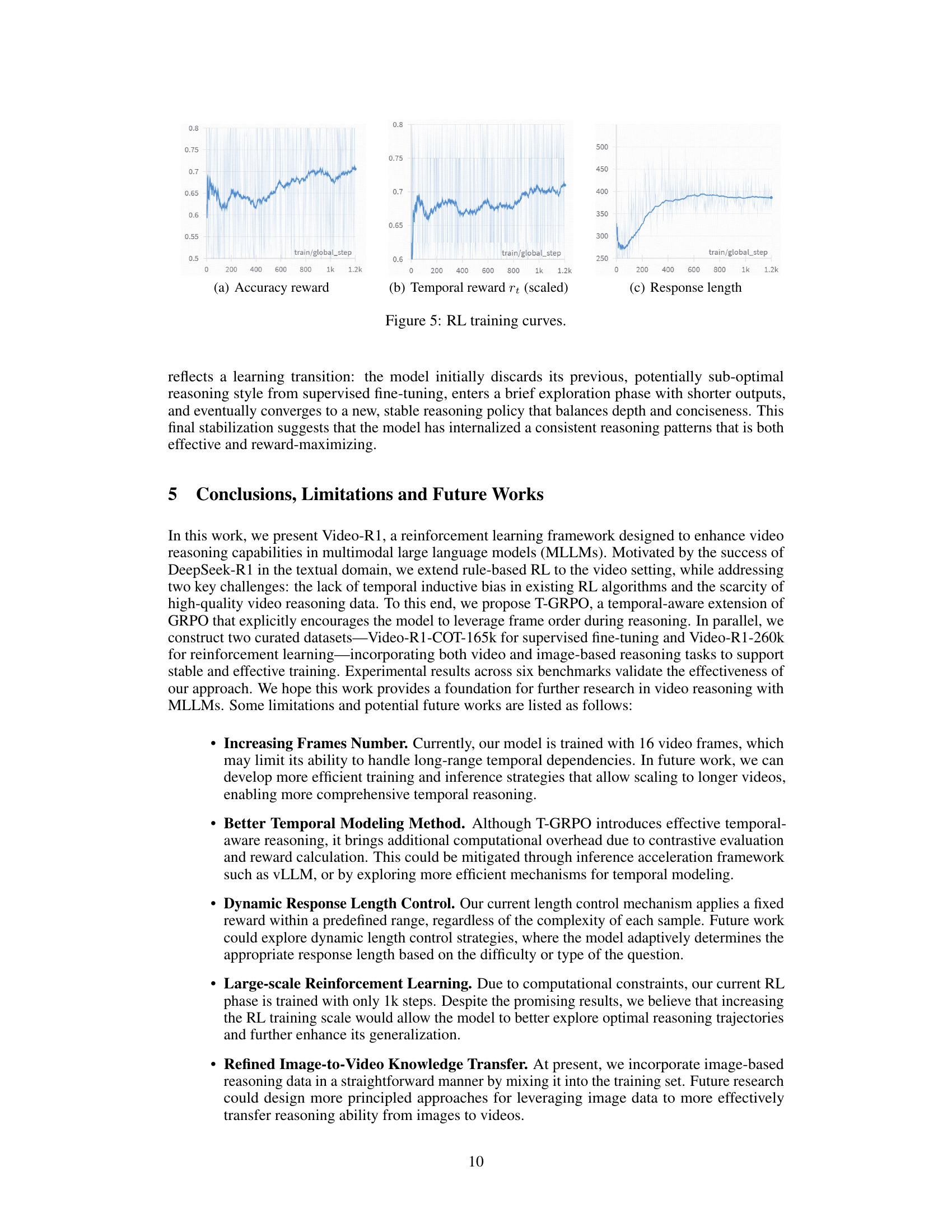
Reinforcement Learning (RL) is emerging as a pivotal technique for enhancing Multimodal Large Language Models (MLLMs). RL offers a framework to refine the reasoning and decision-making capabilities of MLLMs through interaction with an environment and reward signals. The DeepSeek-R1 model’s success has spurred interest in leveraging RL to elicit emergent reasoning abilities.RL allows MLLMs to learn complex, multi-step reasoning strategies without explicit supervision, making it effective for tasks requiring intricate decision-making. However, applying RL to MLLMs presents challenges, including defining appropriate reward functions and addressing data scarcity. Innovations like rule-based RL aim to guide MLLMs towards desired behaviors. Furthermore, addressing the lack of temporal inductive bias is crucial for video reasoning, requiring algorithms that encourage models to utilize temporal information effectively. RL’s potential to unlock complex reasoning in MLLMs is significant, paving the way for more capable and adaptable AI systems.
Temporal GRPO#
The introduction of a “Temporal GRPO” (T-GRPO) algorithm represents a significant advancement in video reasoning for MLLMs. Addressing the limitation of standard GRPO in temporal modeling, T-GRPO smartly uses frame order. By contrasting performance on ordered vs. shuffled frames, T-GRPO creates a contrastive signal. This signal encourages the model to prioritize temporal patterns over shortcuts, promoting deeper reasoning. T-GRPO marks a shift towards explicit temporal awareness in video reasoning models. This potentially improves the model’s ability to understand dynamic events and causal relationships within videos. It enhances reasoning skills by leveraging temporal data.
Video-R1: Datasets#
Based on the research paper, Video-R1 introduces two datasets, Video-R1-COT-165k for SFT cold start and Video-R1-260k for RL training. These datasets contain a mixture of image and video data, strategically created to address the scarcity of high-quality video reasoning data. The image data trains the model on a range of reasoning skills, while the video data focuses on temporal reasoning. The larger Video-R1-260k dataset comprises general open-domain videos (44%), image data covering general QA, charts, OCR, math, knowledge, and spatial reasoning (6%-14% each). COT annotations are generated using Qwen2.5-VL-72B and filtered to ensure high quality. These datasets use rule-based reward design, leveraging multiple-choice, numerical QA, OCR, and free-form QA for precise reward signals. This ensures effective RL training and generalizability of models to diverse tasks.
Aha Moments#
The concept of “Aha Moments” within a video reasoning model like Video-R1 signifies a pivotal shift from rote memorization to genuine understanding. These moments, characterized by a departure from expected answer paths, followed by introspection and eventual convergence on a more logically sound solution, highlight the model’s capacity for self-reflection. This suggests that Video-R1 doesn’t merely execute pre-programmed patterns but actively engages in internal feedback loops, re-examining evidence, and adjusting conclusions accordingly. It marks a transition from a passive learner to an active problem-solver. This ability to identify inconsistencies and revise interpretations mid-process is crucial for handling the complexities of video data, where temporal cues and multi-step inferences often require dynamic adjustments to initial assumptions. The emergence of such behaviors is a testament to the efficacy of the reinforcement learning approach, which incentivizes the model to not only find correct answers but also to develop more robust and adaptable reasoning strategies. This kind of adaptability is particularly valuable in scenarios with ambiguous temporal cues or intricate inference chains, pushing the model beyond superficial pattern recognition. The presence of “aha moments” distinguishes Video-R1 from models that rely solely on pattern-matching, indicating a deeper level of cognitive processing and a greater potential for generalization.
Reasoning Scale#
While the paper doesn’t explicitly use the term “Reasoning Scale,” it implicitly addresses this concept through its exploration of reinforcement learning (RL) to enhance video reasoning in multimodal large language models (MLLMs). The work attempts to scale up reasoning abilities by introducing Video-R1, aiming to elicit more complex reasoning than typically seen in existing MLLMs focused on perception. The use of the T-GRPO algorithm and curated datasets (Video-R1-COT-165k, Video-R1-260k) are efforts to provide models with diverse data to support a broader reasoning spectrum. Video-R1’s architecture allows for the development of more intricate reasoning. The model’s ability to achieve higher accuracy in benchmarks such as VSI-bench, videoMMMU and the like shows its capacity to handle more complex reasoning. The paper tackles the limitations of existing methods and lays a foundation for future models.
More visual insights#
More on figures

🔼 Figure 2 shows the composition of the Video-R1-260k dataset used for training the Video-R1 model. The dataset is a mixture of image and video data, categorized into six types: General Video (everyday scenarios), General Image (general question answering), Chart (reasoning over charts and graphs), OCR (text recognition from images), Math (math problem solving from images), and Spatial (spatial reasoning tasks). The percentage of each data type within the Video-R1-260k dataset is visually represented in a pie chart. This diverse dataset is designed to provide the model with a wide range of reasoning tasks and challenges, spanning various complexities and modalities.
read the caption
Figure 2: The data distribution of our Video-R1-260k dataset.

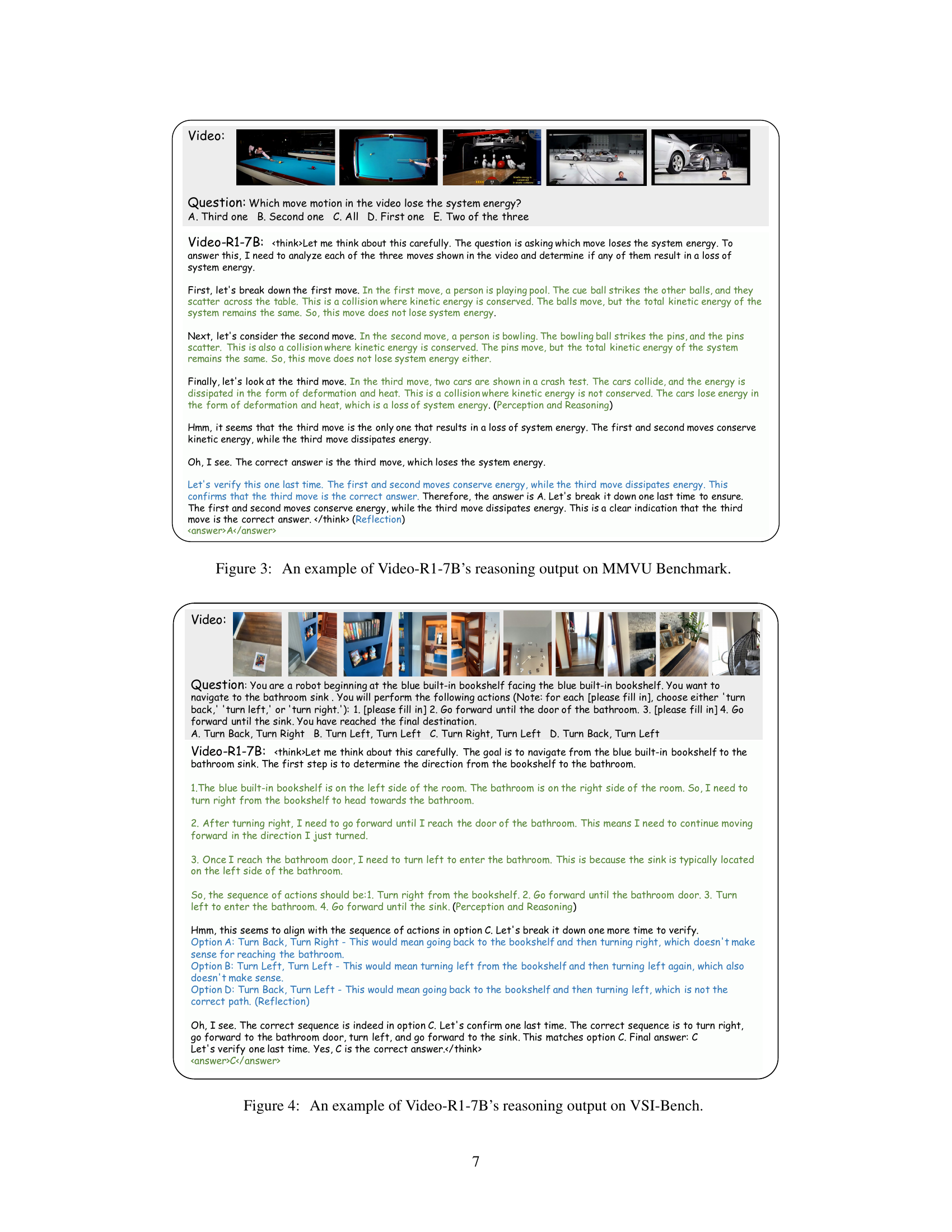
🔼 This figure showcases an example of Video-R1-7B’s reasoning process on the MMVU benchmark. The model is presented with a video and a question: ‘Which move motion in the video loses the system energy?’ The model’s response includes step-by-step reasoning. It analyzes each of three depicted movements (pool, bowling, car crash), deducing that only the car crash involves a loss of system energy due to dissipation of kinetic energy. This demonstrates the model’s capability to perform temporal reasoning and integrate visual and physics-based knowledge for logical deduction. The model revisits and confirms its answer through multiple iterations of thought, highlighting a ‘self-reflection reasoning’ behavior. This multi-stage reasoning process and its explanation are captured and presented in the figure.
read the caption
Figure 3: An example of Video-R1-7B’s reasoning output on MMVU Benchmark.

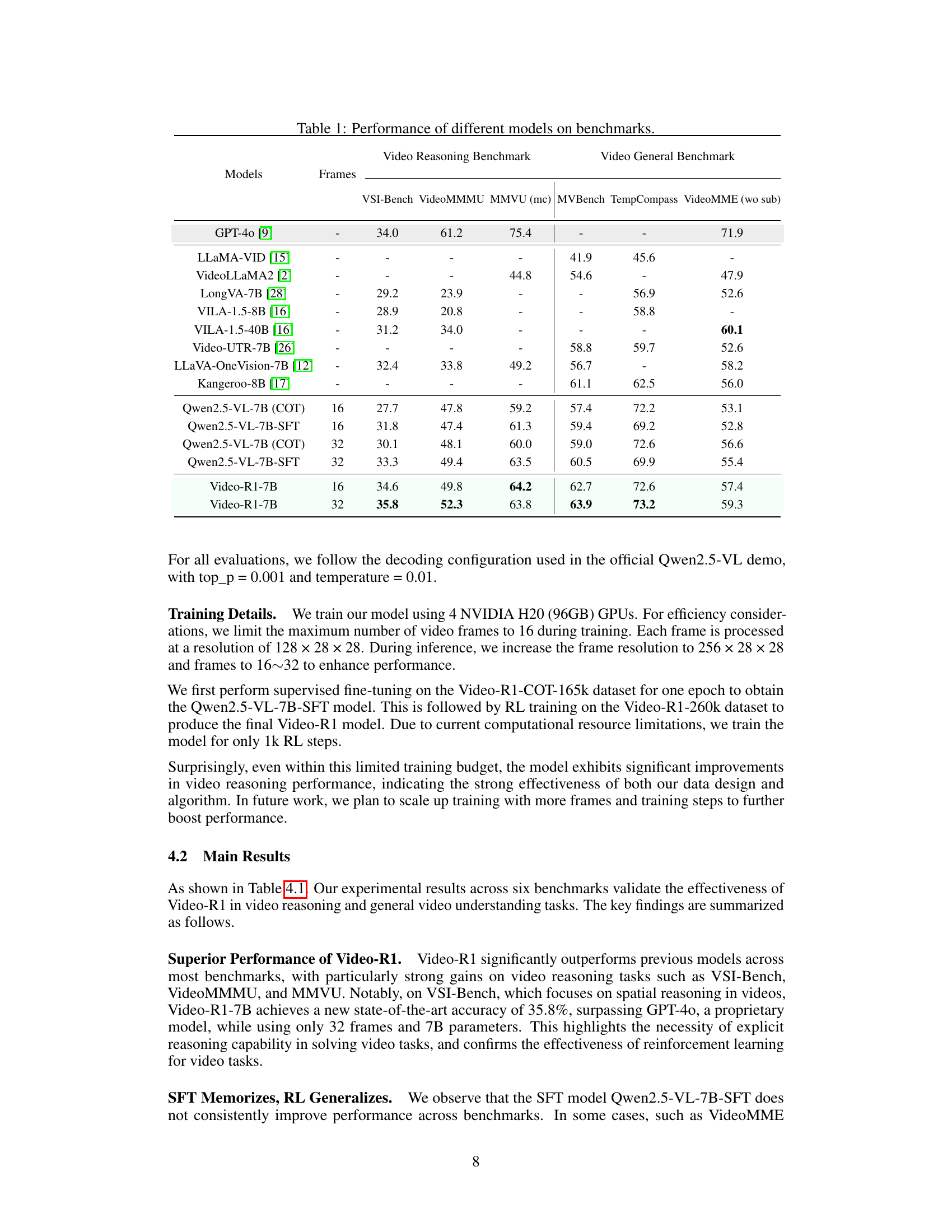
🔼 This figure shows an example of Video-R1-7B’s reasoning process on the VSI-Bench benchmark. The task involves a robot navigation problem where the robot needs to reach a bathroom sink from a starting point. The model generates a chain of thought to determine the correct sequence of actions (turn right, go forward, turn left, go forward) to reach the destination, demonstrating its ability to perform spatial and logical reasoning in a video context. The model demonstrates a self-reflection reasoning behavior in the process, showing its ability to revise its initial plan, identify inconsistencies, and ultimately reach a more accurate conclusion.
read the caption
Figure 4: An example of Video-R1-7B’s reasoning output on VSI-Bench.
Full paper#