↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current embodied AI agents struggle with complex tasks requiring both high-level planning and precise low-level control. Large Language Models (LLMs) excel at planning but lack precise control, while Reinforcement Learning (RL) excels at precise control but struggles with complex planning. This creates a need for a unified approach combining both.
RL-GPT is proposed as a two-level hierarchical framework. A slow agent (LLM) plans the high-level actions which are either coded (if simple enough) or passed on to the fast agent. The fast agent (also LLM) either implements the code or uses RL to learn the low-level actions that were too complex to code. This method significantly improves the efficiency and success rate of learning in challenging environments, surpassing traditional RL and existing LLM agents.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between LLMs and RL, two powerful but distinct AI paradigms. It offers a novel and effective method for building more capable agents that can tackle complex, open-world tasks. The results demonstrate the potential for significant advances in embodied AI, opening new avenues for researchers to explore. The integration of code and RL is especially relevant given the current trend of integrating LLMs into various real-world applications.
Visual Insights#
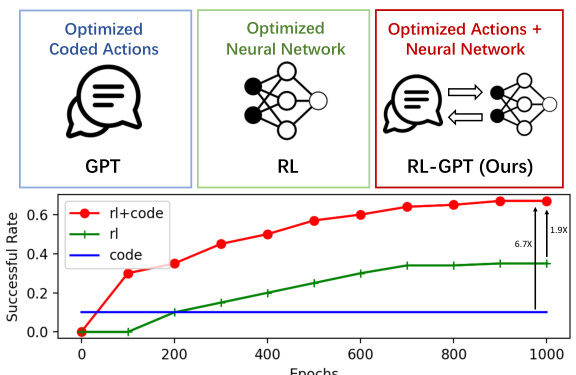
This figure provides a comparison of three different approaches for solving tasks in an environment: using only GPT (Large Language Models), using only Reinforcement Learning (RL), and using a combined approach called RL-GPT. The GPT approach uses LLMs to generate optimized coded actions. The RL approach uses a neural network to learn optimized actions. RL-GPT combines both approaches, leveraging the strengths of LLMs for high-level planning and RL for low-level control to achieve both optimized coded actions and an optimized neural network. The line graph shows the successful rate over epochs, demonstrating RL-GPT’s improved performance over the other two methods.
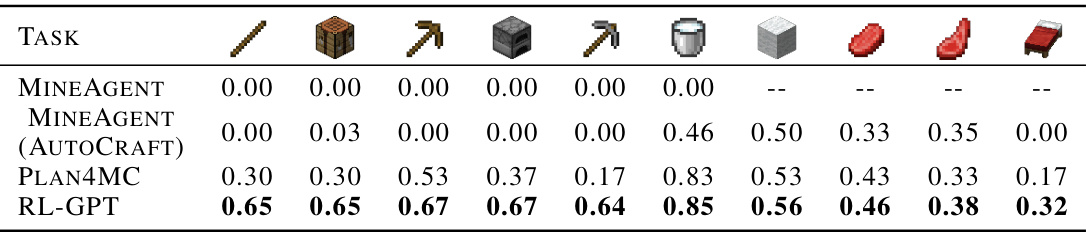
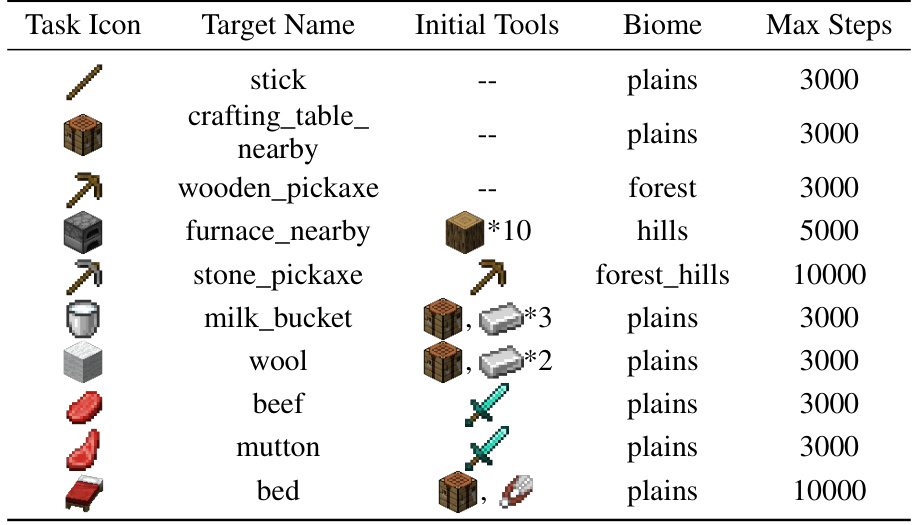
This table presents a comparison of the success rates achieved by different methods (MINEAGENT, MINEAGENT (AUTOCRAFT), PLAN4MC, and RL-GPT) on various tasks selected from the MineDojo benchmark. The tasks involve crafting and harvesting items within the Minecraft environment. RL-GPT demonstrates the highest success rate across all tasks.
In-depth insights#
RL-GPT Framework#
The RL-GPT framework represents a novel approach to integrating Large Language Models (LLMs) and Reinforcement Learning (RL). Its core innovation lies in leveraging LLMs not just as policy generators, but as tools to design and manage the RL training pipeline itself. This is achieved through a two-level hierarchical architecture: a slow agent, responsible for high-level task decomposition and determining which sub-tasks are best addressed via coding or RL; and a fast agent that executes coding tasks or instantiates RL training processes based on the slow agent’s directives. This decomposition significantly enhances efficiency by allowing each agent to focus on its specialized strengths. RL-GPT’s iterative refinement process, involving a critic agent to optimize both the slow and fast agents, further improves performance. The framework’s success in challenging open-world environments like Minecraft, particularly in tasks requiring long-horizon planning and low-level control, underscores its potential as a powerful method for building more capable and efficient embodied AI agents. A key advantage is the ability to integrate high-level GPT-coded actions directly into the RL action space, improving sample efficiency and enabling the system to learn more effectively from fewer interactions. Overall, RL-GPT offers a promising direction for future research in embodied AI by bridging the gap between LLMs’ high-level reasoning capabilities and RL’s capacity for fine-grained control.
Two-Level Hierarchy#
A two-level hierarchy in a reinforcement learning (RL) system, such as the one described, offers a powerful mechanism for efficient decision-making by dividing complex tasks into manageable sub-tasks. The upper level focuses on high-level planning and action selection, often leveraging the strengths of large language models (LLMs) to generate code for simpler actions or to decompose complex problems. The lower level, on the other hand, is responsible for execution and refinement, often utilizing RL agents to handle nuanced interactions, low-level control, and situations not readily amenable to coding. This division of labor improves efficiency. The LLM’s ability to plan and code high-level actions reduces the burden on the RL agent, leading to faster learning and better sample efficiency. This also allows for the seamless integration of symbolic reasoning (LLM) and reactive learning (RL), resulting in a more robust and adaptable system. However, challenges may arise in the interaction between the two levels. Effective communication and coordination are crucial; the upper level needs to provide clear and concise instructions to the lower level, while the lower level needs to provide feedback to the upper level to guide subsequent planning. Careful design of interfaces and feedback mechanisms is essential for the successful implementation of this type of hierarchical system.
LLM-RL Integration#
The integration of Large Language Models (LLMs) and Reinforcement Learning (RL) presents a powerful paradigm shift in AI, offering a unique blend of high-level reasoning and fine-grained control. LLMs excel at complex planning and decision-making, leveraging their vast knowledge bases to strategize and decompose complex tasks. However, LLMs alone often lack the adaptability and fine motor skills necessary for effective interaction with the physical world. RL, on the other hand, shines in learning complex behaviors through trial-and-error, directly optimizing an agent’s actions in a specific environment. The combination of these strengths is transformative. By using LLMs to provide high-level guidance and RL to refine low-level actions, researchers can build agents capable of tackling complex, real-world challenges that are beyond the capabilities of either approach in isolation. A key challenge lies in effectively bridging the gap between the symbolic reasoning of LLMs and the continuous action spaces of RL, often requiring careful design of interfaces and reward functions. Successful integration hinges on a nuanced understanding of each component’s limitations and leveraging their respective advantages to achieve synergistic performance. Future research should focus on more robust methods for handling noisy environments, efficient knowledge transfer between LLM and RL, and further exploration of various architectural designs for LLM-RL integration.
Minecraft Experiments#
The Minecraft experiments section of the research paper would likely detail the application of the RL-GPT framework within the Minecraft environment. This would involve a description of the tasks chosen, highlighting their complexity and suitability for testing the two-level hierarchical approach. Specific tasks such as obtaining diamonds or crafting complex items are likely candidates, as they demand high-level planning combined with precise low-level actions. The results would demonstrate the effectiveness of RL-GPT in mastering these challenging tasks, comparing its success rate and sample efficiency against traditional RL methods and other LLMs. A crucial aspect would be a discussion of the decomposition of tasks into code-as-policy and RL sub-tasks, illustrating how LLMs handled high-level planning and decision-making, while RL provided the necessary low-level skill learning and adaptation. The evaluation metrics would likely include success rates, steps taken, and resource utilization, showcasing the framework’s ability to achieve significant improvements in sample efficiency and overall performance compared to baselines. Qualitative results, possibly through visualizations of agent behavior, would provide additional evidence of the system’s capabilities within the rich Minecraft environment. Finally, an analysis of the limitations and challenges encountered during the Minecraft experiments would conclude the section.
Future Research#
Future research directions stemming from this RL-GPT framework are plentiful. Improving the efficiency of the two-level hierarchical framework is crucial; exploring alternative architectures or refined task decomposition strategies could significantly boost performance. Investigating methods to reduce reliance on computationally expensive LLMs for task planning and code generation is also vital; potentially smaller, specialized LLMs or hybrid approaches combining LLMs with other planning techniques would be valuable. Enhancing the agent’s adaptability to more diverse open-world environments beyond Minecraft is a key goal; this will require addressing challenges like dealing with greater environmental complexity and unforeseen events. Finally, exploring applications of RL-GPT to robotics or other embodied AI domains, testing its robustness and scalability in real-world settings, presents a significant avenue for future work. The inherent safety concerns regarding the use of LLMs also necessitate research into safe and reliable methods for integrating LLMs into RL systems. This could involve developing robust mechanisms to prevent undesired behavior or mitigate potential biases in the LLM outputs impacting RL agent performance and safety.
More visual insights#
More on figures
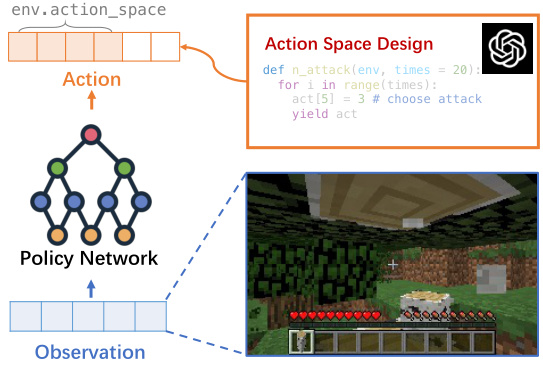
This figure illustrates how LLMs can be used to improve the efficiency of reinforcement learning (RL) by generating environment configurations and code that provide higher-level actions. The LLM reasons about the agent’s behavior to solve a subtask, then generates code for higher-level actions, supplementing the original environment actions. This integration of LLMs and RL increases sample efficiency in the RL process. The diagram shows the LLM generating code that becomes part of a policy network, which takes observations from the environment and produces actions.
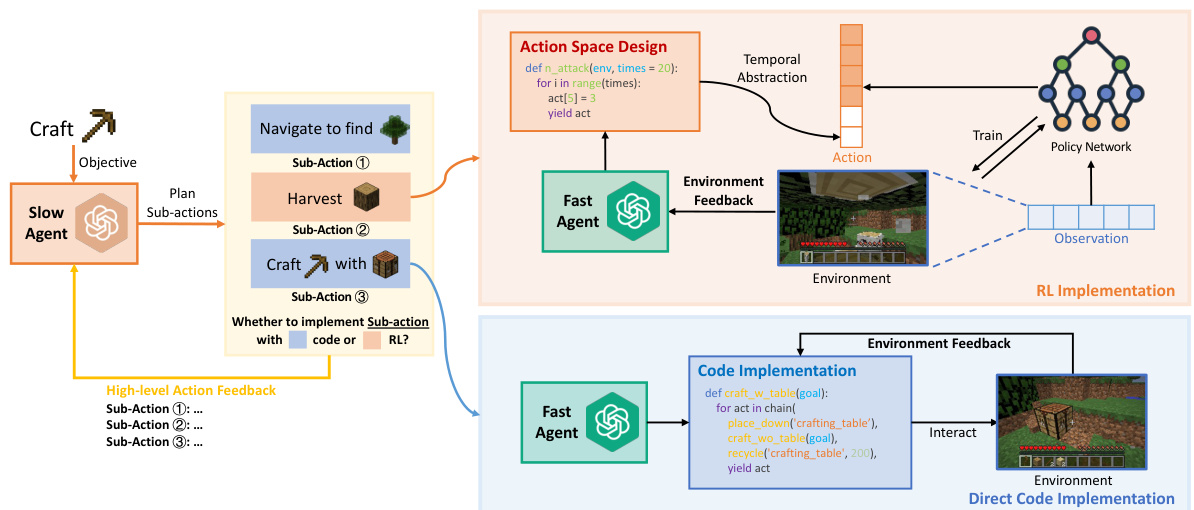
This figure illustrates the overall architecture of RL-GPT, a two-agent hierarchical framework. The slow agent (orange) focuses on high-level task decomposition, deciding which actions should be implemented using code and which should be learned via reinforcement learning (RL). The fast agent (green) is responsible for generating and refining the code for coded actions and setting up the RL pipeline for the remaining actions. There is an iterative process involving feedback from the environment to optimize both agents. The figure also showcases the specific tasks and interactions within each agent.
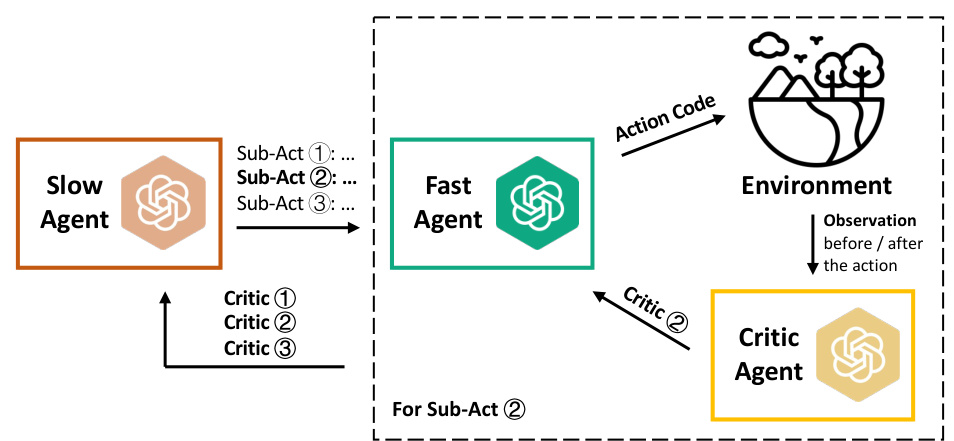
This figure illustrates the iterative optimization process used in RL-GPT. It shows two loops: one for the slow agent which decomposes the tasks and decides which actions to code or learn using RL, and the other for the fast agent that generates code and configures the RL training. A critic agent provides feedback to both the slow and fast agents, allowing them to iteratively refine their decisions and improve performance.
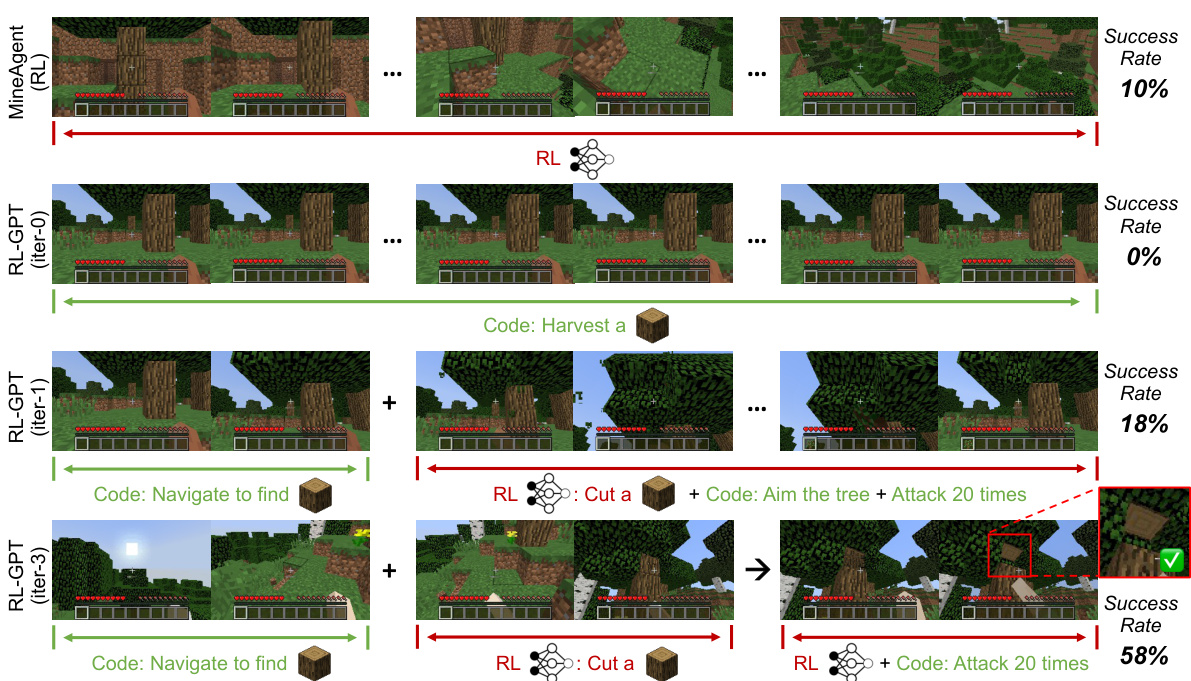
This figure demonstrates how different approaches to solving the task of harvesting a log in Minecraft differ in their success rates. MineAgent, relying solely on reinforcement learning (RL), achieves only a 10% success rate. RL-GPT, in its initial iterations (iter-0 and iter-1), also performs poorly. However, through the iterative process of task decomposition and integrating code-as-policy, RL-GPT gradually improves its performance, reaching a 58% success rate by iter-3. This showcases the effectiveness of RL-GPT’s two-level hierarchical framework, which combines the strengths of LLMs and RL for efficient task completion. The figure shows a sequence of images illustrating the agent’s actions at each stage of the process.
This figure provides a high-level overview of the RL-GPT framework. It shows two main agents: a slow agent (orange) responsible for task decomposition and determining which actions are best suited for coding versus reinforcement learning, and a fast agent (green) responsible for writing code and configuring reinforcement learning, and debugging generated code based on the environment’s feedback. The framework iteratively refines both agents’ decisions. The image illustrates how the framework combines code and reinforcement learning to solve tasks efficiently.

This figure compares the performance of the proposed RL-GPT model against baseline methods on a furniture assembly task in a simulated environment. The top row shows a baseline agent’s attempts to assemble the furniture, which result in the robot arm repeatedly inserting parts into incorrect positions. The bottom row demonstrates the RL-GPT agent successfully assembling the furniture. This is achieved by utilizing motion planning as an action in the agent’s action space; this allows the agent to efficiently locate the correct positions for inserting parts.
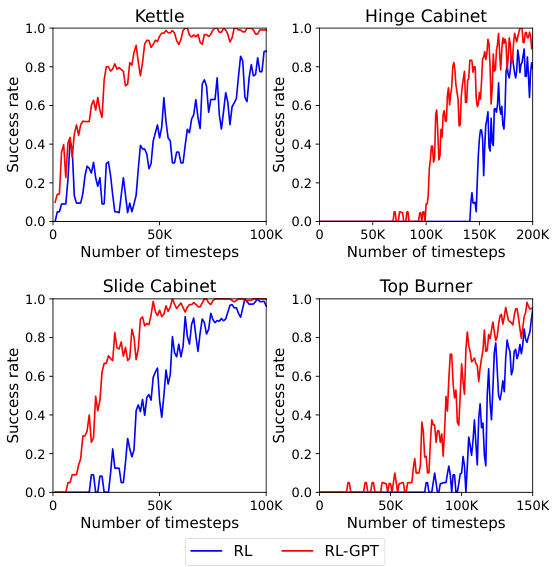
This figure shows the success rate of RL and RL-GPT on four different tasks in the Kitchen environment over a certain number of timesteps. RL-GPT consistently outperforms the baseline RL approach, demonstrating faster learning and improved performance by integrating coded motion planning into the RL process. The results indicate that incorporating high-level coded actions with RL enhances learning efficiency for complex tasks.

This figure showcases a qualitative comparison of the proposed RL-GPT method against baseline methods for furniture assembly tasks within the Furniture environment. The top row demonstrates a baseline approach, showing the robot arm’s struggles to accurately locate and assemble parts of a piece of furniture. In contrast, the bottom row illustrates the RL-GPT approach, demonstrating significantly improved accuracy in part location and successful assembly. The improved performance highlights the effectiveness of incorporating coded motion planning actions into the RL framework for enhanced task completion. The images provide a visual representation of the steps involved in the furniture assembly task for both the baseline and the RL-GPT methods.
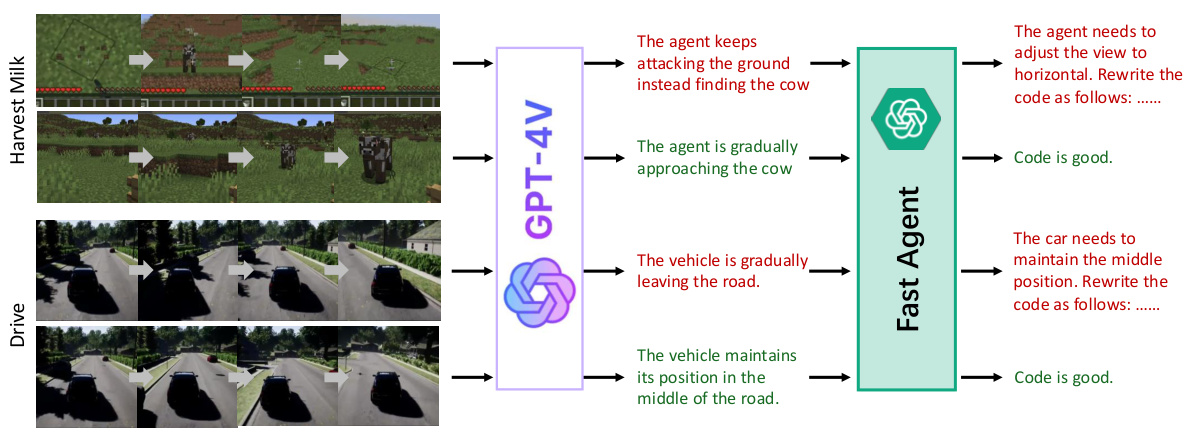
This figure demonstrates how Vision-Language Models (VLMs) provide more detailed and precise feedback compared to LLMs. It shows examples from two different environments: Minecraft (Harvest Milk task) and a driving simulation. In both cases, the VLM not only identifies whether the agent succeeded or failed but also explains the reasons for success or failure. For instance, in the Minecraft example, the VLM points out that the agent was incorrectly attacking the ground instead of the cow; while in the driving simulation example, the VLM correctly observes that the vehicle was gradually drifting off the road. This more nuanced feedback allows for faster improvement in both the slow agent’s task planning and the fast agent’s code generation.
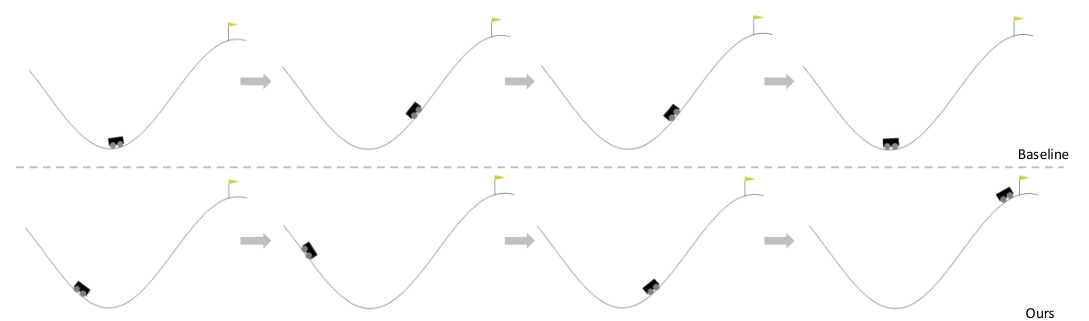
This figure shows a comparison of a baseline approach and the RL-GPT approach on a MuJoCo task. The task involves navigating a car along a winding road. The baseline approach is less efficient, while the RL-GPT approach is able to successfully navigate the car by using GPT-4 to generate code for reversing the car and then moving it forward. This demonstrates the capability of the RL-GPT framework to generate code for complex actions that can improve the efficiency of RL agents.
More on tables
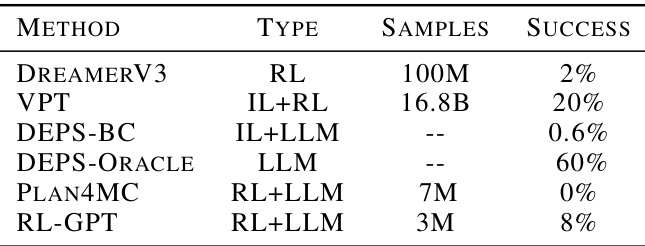
This table presents the main results of the ObtainDiamond challenge in the Minecraft game, comparing the performance of RL-GPT with several existing strong baselines. It highlights that RL-GPT achieves a high success rate (8%) with significantly fewer samples compared to other methods, demonstrating its efficiency in solving complex, long-horizon tasks. The table also emphasizes the advantages of RL-GPT in addressing the limitations of previous approaches, particularly in terms of data requirements, sample efficiency, and the need for human-designed components.
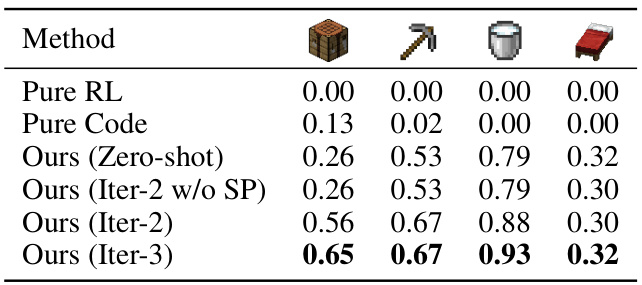
This table presents the results of an ablation study on the RL-GPT model. It shows the success rates of different model variants on four tasks in the Minecraft environment. The variants include a model using only reinforcement learning (Pure RL), a model using only code (Pure Code), and different versions of RL-GPT with varying numbers of iterations. The results demonstrate that integrating both RL and code, as done in RL-GPT, leads to significantly better performance than using either approach alone, and that increasing the number of iterations further improves performance.
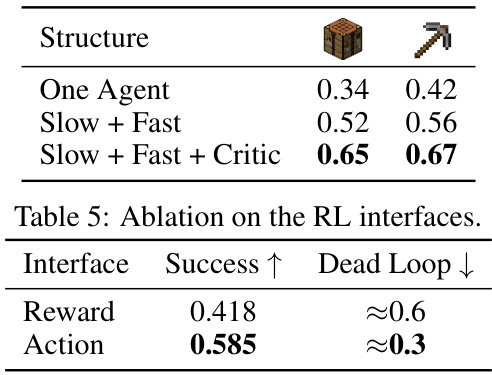
This table presents the ablation study on different agent structures used in the RL-GPT framework. It shows the success rates for three different configurations: 1. One Agent: All tasks are handled by a single agent. 2. Slow + Fast: The tasks are divided between a slow agent (for planning) and a fast agent (for execution). 3. Slow + Fast + Critic: A critic agent is added to provide feedback and improve the performance of the slow and fast agents. The results indicate that using a slow, fast, and critic agent structure leads to the highest success rate.

This table shows the number of OpenAI tokens consumed in each iteration of the RL-GPT framework for enhancing the RL training process. The number of tokens increases with each iteration, suggesting that more complex instructions or reasoning are needed to improve the RL agent’s performance.

This table provides a high-level comparison of several methods in terms of their ability to handle long-horizon tasks, low-level control, sample efficiency and self-improvement. It shows that RL-GPT outperforms other methods in all these aspects.
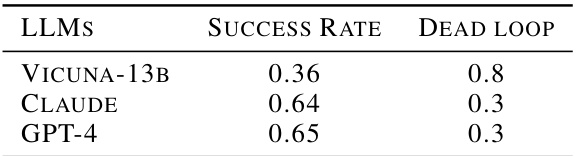
This table compares the performance of three different Large Language Models (LLMs): Vicuna-13B, Claude, and GPT-4, on a specific task. The performance is measured by two metrics: Success Rate and Dead Loop rate. The success rate indicates the percentage of times the LLM successfully completed the task, while the Dead Loop rate shows how often the LLM got stuck in an unproductive loop.
Full paper#