↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Traditional urban spatiotemporal models often struggle with dynamic, multi-sourced data and the limitations of single-task approaches. They fail to generalize well to new domains or conditions, hindering the development of robust and adaptable urban intelligence systems. This necessitates the need for a more comprehensive approach that can effectively model interdependencies across various dimensions of urban data and adapt continuously to new tasks and domains.
The proposed Continuous Multi-task Spatio-Temporal learning framework (CMuST) directly addresses these issues. It leverages a novel multi-dimensional spatiotemporal interaction network (MSTI) to capture complex relationships within and across various data dimensions, allowing for effective cross-interactions between context and observations. To ensure continuous learning, CMuST employs a Rolling Adaptation training scheme (RoAda) that preserves task uniqueness while harnessing correlated patterns. Extensive evaluations demonstrate CMuST’s superiority over existing methods, showcasing its impressive performance in both few-shot streaming data and new domain tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in urban computing and spatiotemporal learning. It introduces a novel continuous multi-task learning framework (CMuST) that effectively addresses the limitations of traditional task-specific models. The framework’s ability to handle dynamic, multi-sourced urban data and improve generalization to new domains is highly relevant to current research trends. The benchmark datasets and code availability further enhance its impact, opening new avenues for research in collaborative urban intelligence and continuous learning.
Visual Insights#
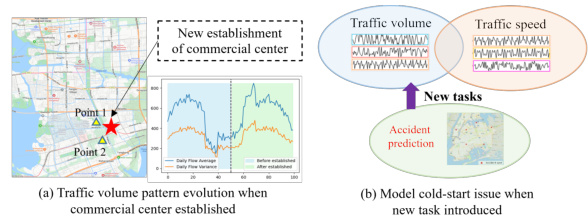
This figure illustrates two key challenges in continuous multi-task spatiotemporal learning. (a) shows how traffic volume patterns evolve with urban expansion and the establishment of new POIs. The introduction of a new commercial center changes the traffic patterns observed at two specific points, highlighting the dynamic nature of urban spatiotemporal systems. (b) shows a model cold-start issue when a new task (accident prediction) is introduced. Existing models trained on single tasks, like traffic volume and speed prediction, are not able to easily generalize to this new task, emphasizing the need for a continuous multi-task learning framework.
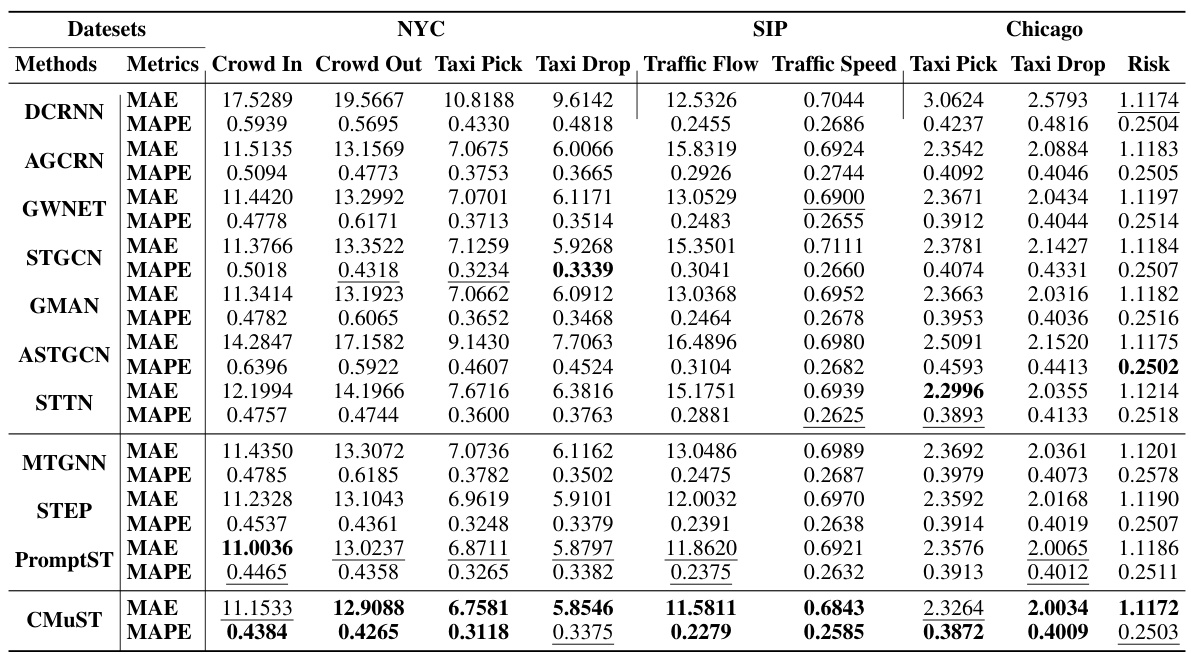
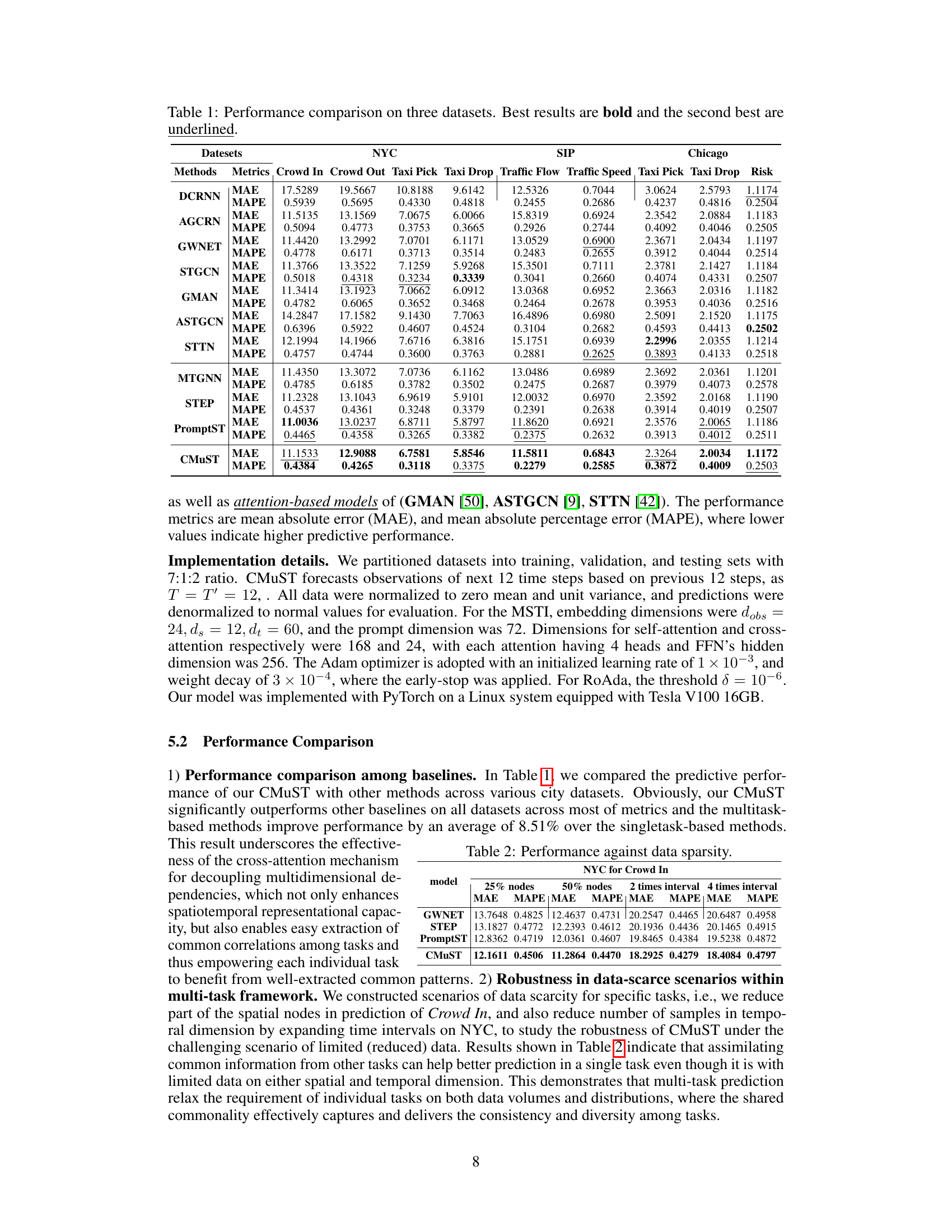
This table presents a comparison of the performance of various models on three different datasets (NYC, SIP, and Chicago). The models are evaluated using two metrics: Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE). Lower values for both metrics indicate better performance. Each dataset has multiple tasks, and the results for each task are shown separately for each model. The table highlights the best and second-best performing models for each task and dataset.
In-depth insights#
Urban Multi-task Learning#
Urban multi-task learning presents a significant advancement in applying machine learning to complex urban systems. Instead of tackling individual urban challenges (like traffic prediction, crime analysis, or resource allocation) in isolation, this approach leverages the inherent interdependencies between these tasks. By jointly modeling multiple urban datasets, urban multi-task learning can capture shared patterns and latent relationships that individual task-specific models miss. This leads to improved accuracy, efficiency, and generalizability across a range of urban prediction problems. A key benefit is the ability to handle data scarcity: if information is limited for one task, related tasks can provide supplementary context and improve overall performance. Challenges remain in effectively handling task heterogeneity and managing the computational complexity of joint model training. Future research should explore techniques for optimizing model architectures, addressing data imbalance, and ensuring fairness and ethical considerations in the context of urban data.
CMuST Framework#
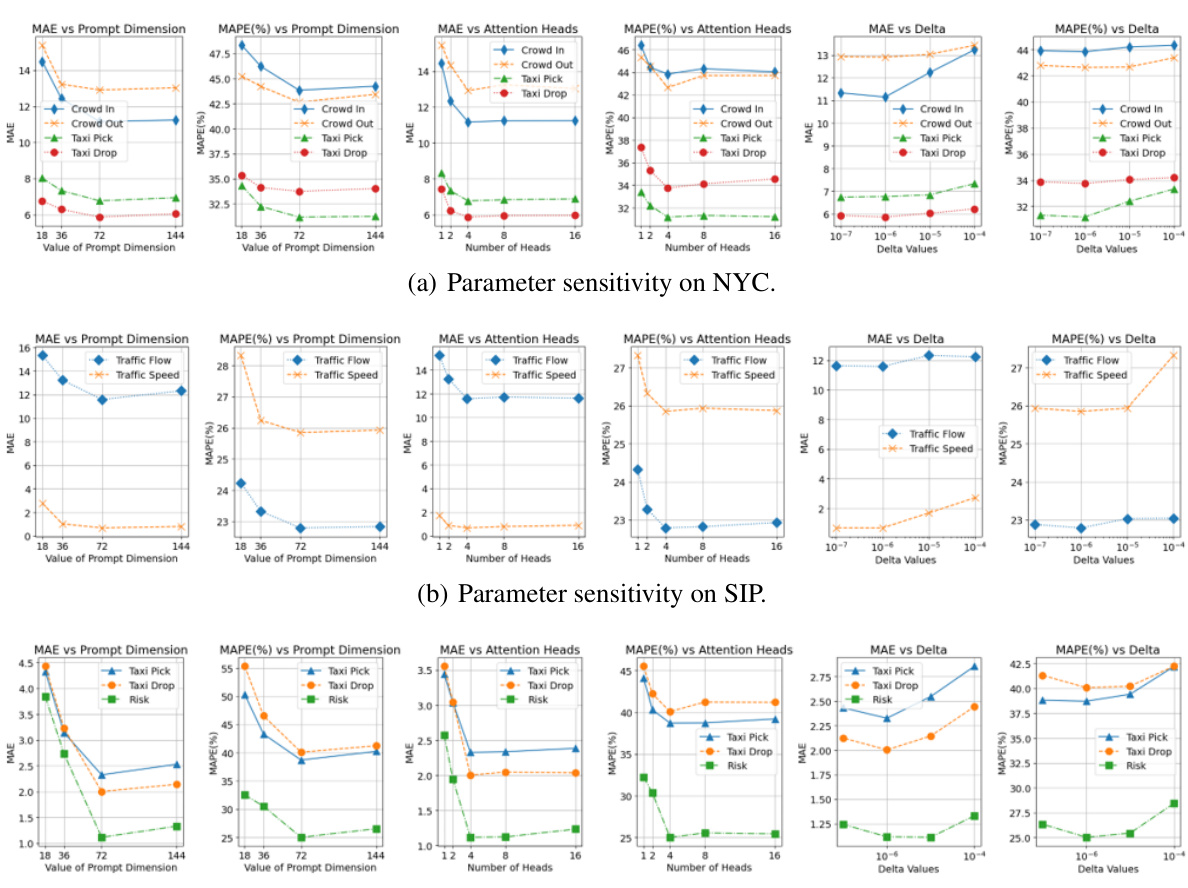
The CMuST framework, a Continuous Multi-task Spatio-Temporal learning framework, is designed to address the limitations of traditional task-specific spatiotemporal models in urban settings. It tackles the challenges posed by dynamic, multi-sourced urban data with imbalanced distributions. The core innovation lies in its ability to move beyond task isolation. This is achieved through a novel multi-dimensional spatiotemporal interaction network (MSTI) that facilitates cross-interactions between various data dimensions, exposing task-level commonality and allowing personalization. The MSTI’s ability to capture complex associations between dimensions and domains, as well as self-interactions within spatial and temporal aspects is crucial. Moreover, a rolling adaptation training scheme (RoAda) ensures continuous task learning, preserving task uniqueness while harnessing correlations among tasks. RoAda’s iterative model behavior modeling and task-specific prompts are key to its effectiveness. This comprehensive framework ultimately improves generalization performance, particularly in scenarios with limited data and new urban conditions, offering a more holistic approach to understanding and leveraging urban spatiotemporal data.
Rolling Adaptation#
The proposed “Rolling Adaptation” training scheme is a crucial component for enabling continuous multi-task learning in the spatiotemporal domain. It cleverly addresses the challenge of maintaining individual task uniqueness while simultaneously harnessing correlated patterns across tasks. Task summarization via AutoEncoders creates concise, task-specific prompts that preserve individual task characteristics, preventing catastrophic forgetting. Iterative weight behavior modeling focuses on stable weight patterns across tasks to extract commonalities, further enhancing generalization. This iterative approach effectively balances task-specific personalization and the extraction of shared knowledge, leading to impressive improvements in both few-shot and new domain scenarios. The method demonstrates a powerful strategy for continuous adaptation in complex, dynamic urban environments, where new tasks and data constantly emerge.
Data Sparsity Robustness#
Data sparsity is a critical challenge in many real-world applications, especially those involving spatiotemporal data. The core issue stems from the uneven distribution of data points across space and time, leading to regions with limited or no observations. This lack of data makes it difficult to accurately model the underlying spatiotemporal dynamics and significantly impacts the performance of machine learning models. Traditional methods often struggle to generalize to unseen areas or time periods. A robust spatiotemporal learning framework should, therefore, exhibit strong robustness to data sparsity. This means that the model must still be capable of making accurate predictions even in regions with limited data. This might involve incorporating mechanisms that leverage spatial and temporal correlations to fill in missing information or utilize techniques that are inherently more resilient to missing data. Effective approaches may employ advanced imputation methods, weight adjustment strategies for sparse data, or even alternative model architectures more suited to handle uncertainty in data availability. Successful solutions will need to demonstrate improved predictive performance in data-sparse regions compared to existing methods, highlighting enhanced generalization and reliable performance in real-world scenarios where complete data is rarely available.
Future Research#
The paper’s conclusion suggests several avenues for future research. Extending the framework to other urban domains beyond transportation (e.g., energy, environment) is crucial to demonstrate broader applicability and impact. This expansion would necessitate adapting the model to handle diverse data types and potentially different spatiotemporal dynamics. Investigating the collective intelligence of open urban systems is another promising direction; this would involve exploring how the framework can learn and adapt in less controlled, more dynamic environments where data might be noisy, incomplete, or from disparate sources. A key challenge would be developing robust mechanisms for handling this uncertainty and incorporating external knowledge. Furthermore, exploring the scalability and efficiency of the CMuST framework for handling extremely large datasets and complex urban systems is vital for practical deployment. Research into optimized architectures and training strategies is essential. Lastly, more in-depth analysis of the model’s learned representations and their ability to capture task-level commonalities and personalization would provide valuable insights into the framework’s underlying mechanisms. This could include techniques like visualization and interpretability methods.
More visual insights#
More on figures
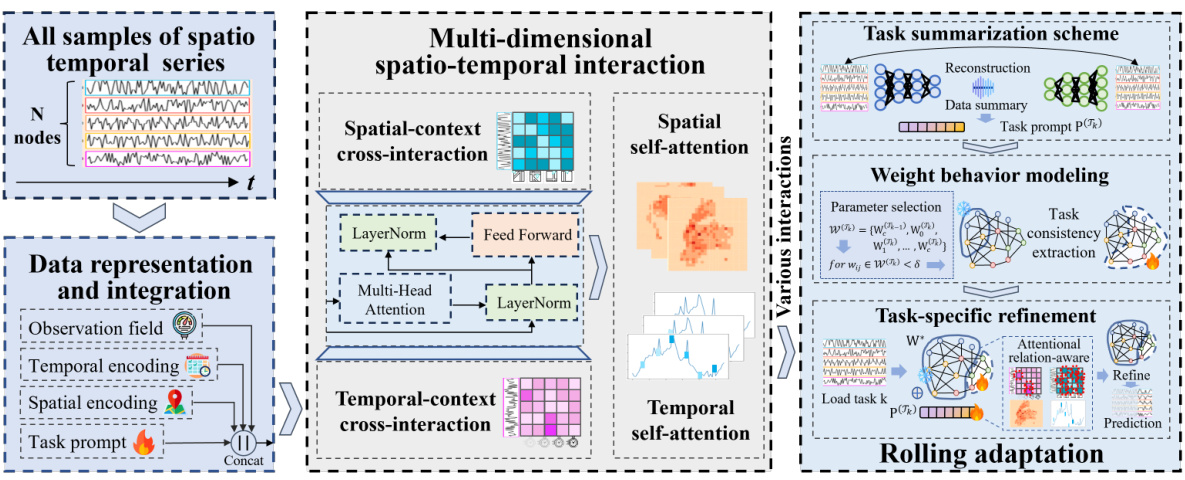
This figure provides a comprehensive overview of the Continuous Multi-task Spatio-Temporal learning framework (CMuST). It illustrates the data flow and processing steps involved in the framework. The framework consists of three main components: Data Representation and Integration, Multi-dimensional Spatio-Temporal Interaction, and Rolling Adaptation. The Data Representation and Integration component takes in all samples of spatio-temporal series, performing data representation and integration to obtain a comprehensive representation H. This is then fed into the Multi-dimensional Spatio-Temporal Interaction component, which uses a multi-head cross-attention mechanism to capture interactions across spatial and temporal dimensions and incorporates task prompts. The resulting representation is then processed by the Rolling Adaptation component, which uses a task summarization scheme, weight behavior modeling, and task-specific refinement to enable continuous multi-task learning and refine the model for each task. The figure highlights the key steps and modules within each component, providing a visual representation of the CMuST framework’s workflow.
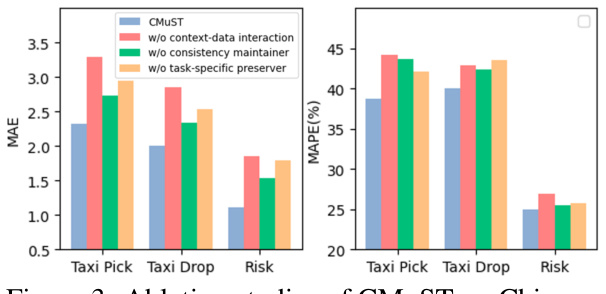
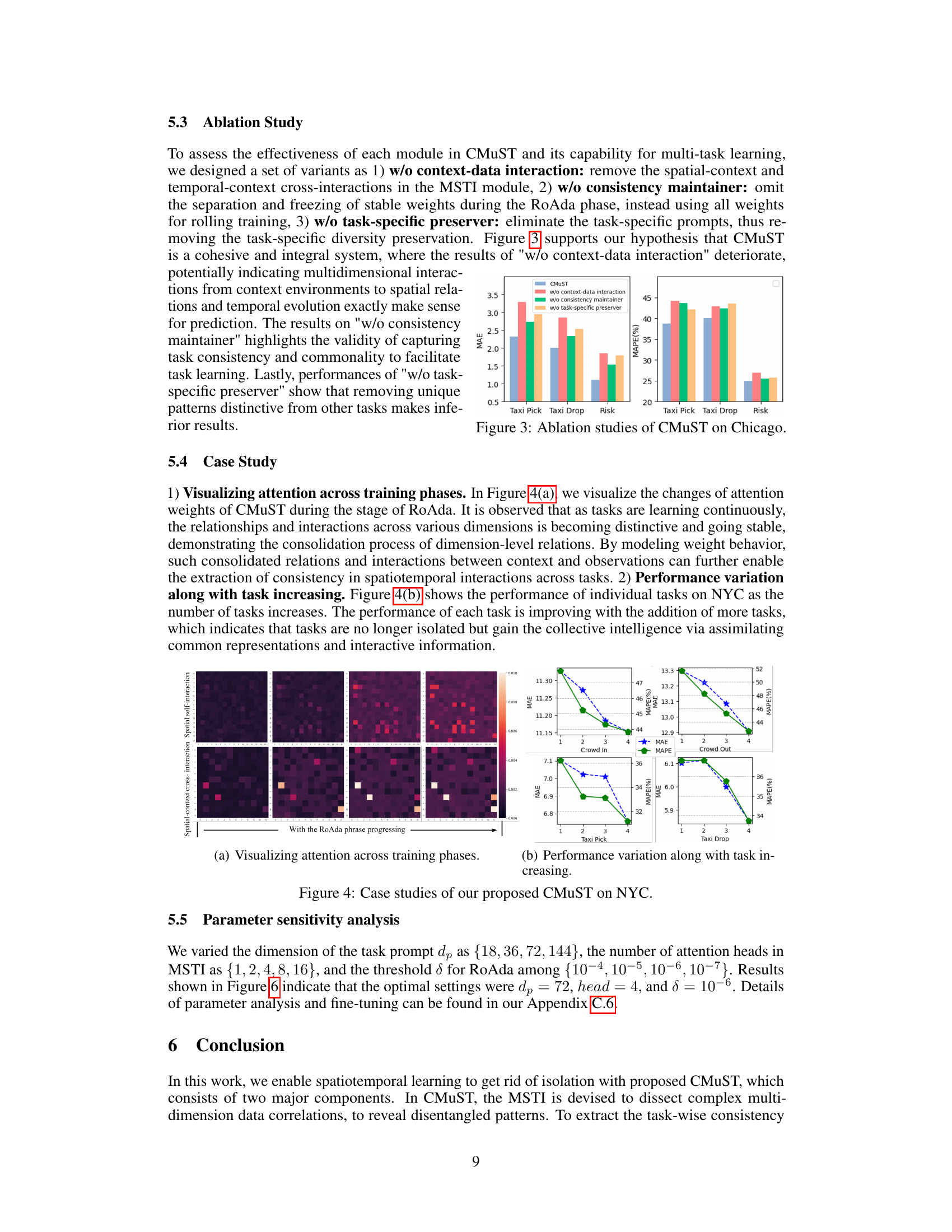
This figure presents the results of ablation studies conducted on the Chicago dataset to evaluate the impact of different components within the CMuST framework. Specifically, it compares the performance (measured by MAE and MAPE) of the full CMuST model against three variants: one without context-data interaction, one without the consistency maintainer (which helps maintain consistency in learning across tasks), and one without task-specific preservation. The results illustrate the contribution of each component to the overall performance on three specific tasks (Taxi Pick, Taxi Drop, and Risk).
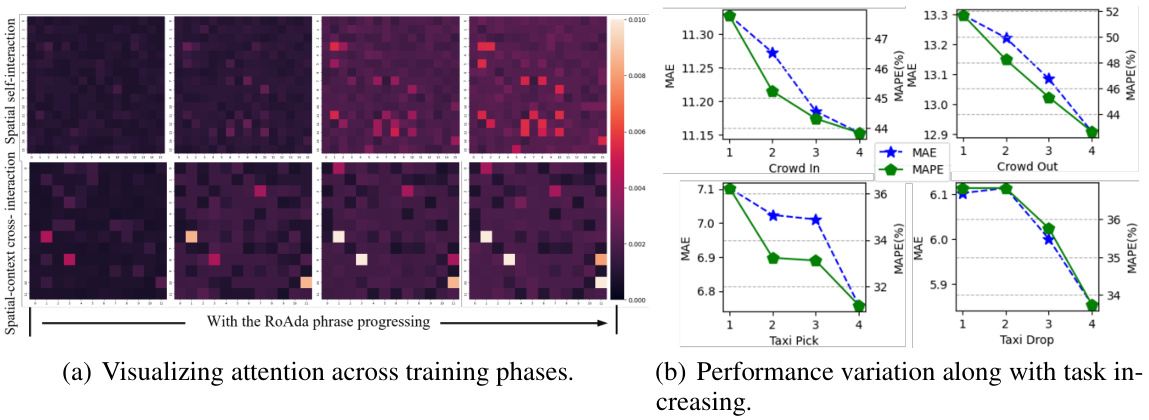
This figure shows the overall framework of the CMuST model. It illustrates the data representation and integration process, the multi-dimensional spatio-temporal interaction network (MSTI), and the rolling adaptation training scheme (RoAda). The MSTI is depicted as processing various data interactions within the spatio-temporal domain, including spatial-context cross-interaction, temporal-context cross-interaction, and self-interactions within the spatial and temporal dimensions. The RoAda training scheme focuses on iterative model behavior modeling and weight behavior modeling, allowing for continuous multi-task learning. The figure also highlights the use of task prompts to capture task distinction and commonality across tasks.
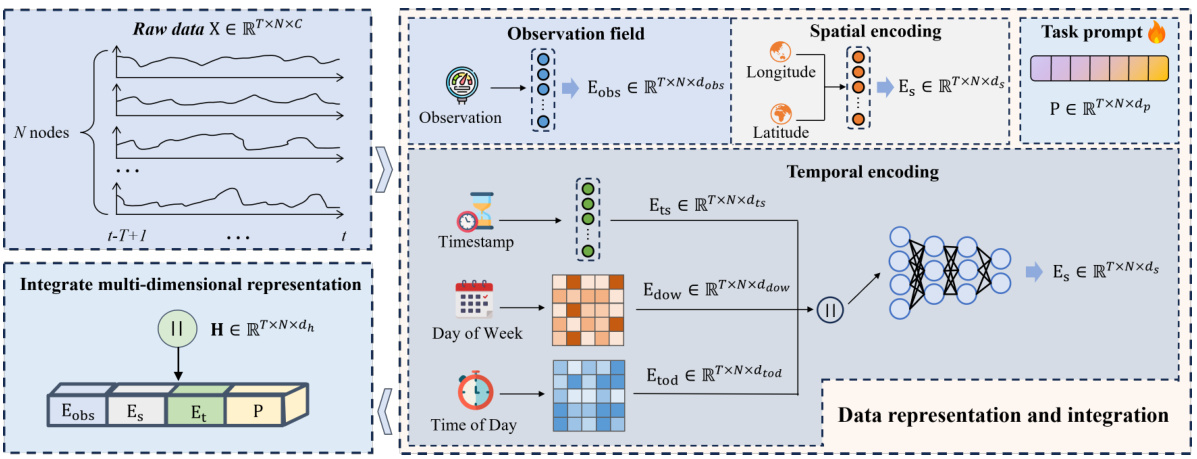
This figure presents a detailed overview of the CMuST framework. It illustrates the data representation and integration process, where raw spatiotemporal data is transformed into multi-dimensional embeddings by integrating observation, spatial, and temporal features with a task-specific prompt. These embeddings are then input into the Multi-dimensional Spatio-Temporal Interaction Network (MSTI) to capture various interactions. The MSTI is followed by the Rolling Adaptation training scheme (RoAda) to ensure continuous task learning, highlighting the task-level commonalities and diversity. The components of the CMuST framework, including data representation, MSTI, and RoAda, work synergistically to improve multi-task learning performance.
This figure provides a comprehensive overview of the CMuST framework, illustrating the data representation and integration process, the multi-dimensional spatio-temporal interaction network (MSTI), and the rolling adaptation training scheme (RoAda). It visually depicts the flow of data, from raw spatiotemporal series to the final prediction output. The MSTI module shows the disentanglement of complex spatiotemporal interactions, highlighting cross-interactions and self-interactions. The RoAda scheme emphasizes the iterative process of model adaptation and task-specific refinement. The figure provides a clear understanding of the framework’s architecture and working mechanisms.
More on tables
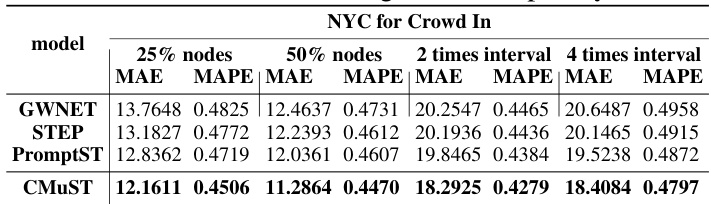
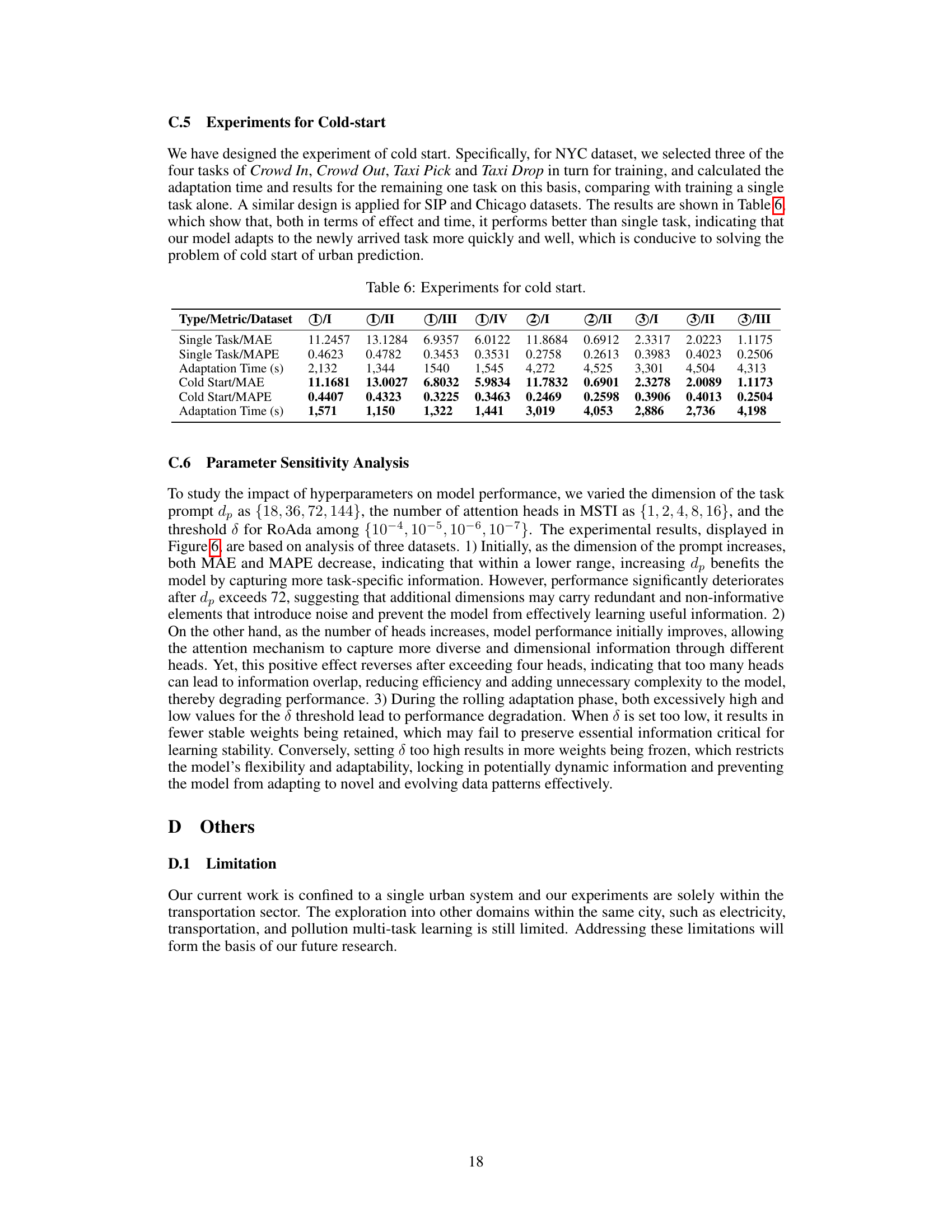
This table presents the results of experiments conducted to evaluate the robustness of different models (GWNET, STEP, PromptST, and CMuST) under data sparsity conditions. The performance is measured using MAE and MAPE metrics. Data sparsity is simulated in three ways: reducing the number of spatial nodes (25% and 50%), and increasing the time interval between observations (2 times and 4 times). The results show how well each model maintains performance when data is limited or less frequently sampled.
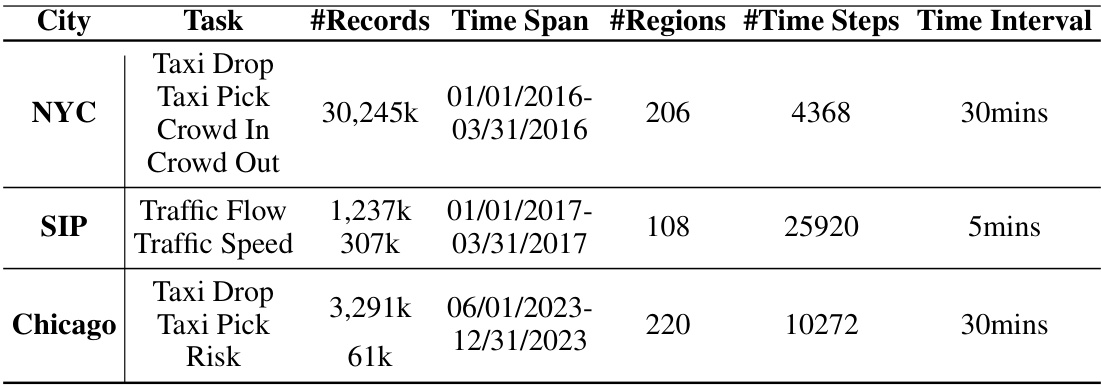
This table presents a comparison of the performance of various spatiotemporal forecasting models (DCRNN, AGCRNN, GWNET, STGCN, GMAN, ASTGCN, STTN, MTGNN, STEP, PromptST, and CMuST) on three different datasets: NYC, SIP, and Chicago. Each dataset includes multiple tasks, and the table shows the Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) for each model on each task. The results highlight the superior performance of the proposed CMuST model compared to existing state-of-the-art methods.
This table presents a comparison of the proposed CMuST model’s performance against several other state-of-the-art models on three different datasets (NYC, SIP, and Chicago). The performance metrics used are Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE). Lower values indicate better performance. Each dataset contains multiple tasks, and the table shows the results for each task and each model, highlighting the best and second-best performing models.

This table presents a comparison of the performance of various models on three different datasets (NYC, SIP, and Chicago). The models are evaluated based on two metrics: Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE). Lower values indicate better performance. The table allows for a direct comparison of the predictive accuracy of different spatiotemporal forecasting models across multiple datasets, highlighting the relative strengths and weaknesses of each model in different contexts.

This table presents a comparison of the performance of different spatiotemporal forecasting methods on three datasets (NYC, SIP, and Chicago). Each dataset has multiple tasks (e.g., crowd flow prediction, taxi trip prediction, risk assessment). The table shows the Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) for each model and task. Lower values of MAE and MAPE indicate better performance. The best and second-best results for each task are highlighted.
Full paper#