↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Two-stage recommender systems are crucial for efficiently handling massive datasets in recommendation. However, understanding their generalization ability has been limited. This paper focuses on this important problem by studying systems with a tree structure, involving a fast retriever and a more accurate ranker. A core issue is the potential for mismatches between the data distributions seen during retrieval and ranking, affecting the overall performance.
The researchers address this by using Rademacher complexity to derive generalization error bounds for different model types. They show that using a tree structure retriever with many branches and harmonizing data distributions across the two stages improves generalization. These theoretical results are supported by experiments on real-world datasets, confirming the effectiveness of their proposed approaches for improving the generalization capabilities of these widely used recommender systems.
Key Takeaways#
Why does it matter?#
This paper is important because it provides theoretical guarantees for the generalization performance of two-stage recommender systems, a widely used architecture. The findings offer valuable insights into model design and training, guiding researchers in creating more effective systems. By providing generalization error bounds, it advances our understanding of the underlying learning process and opens new avenues for improving recommendation accuracy and efficiency.
Visual Insights#
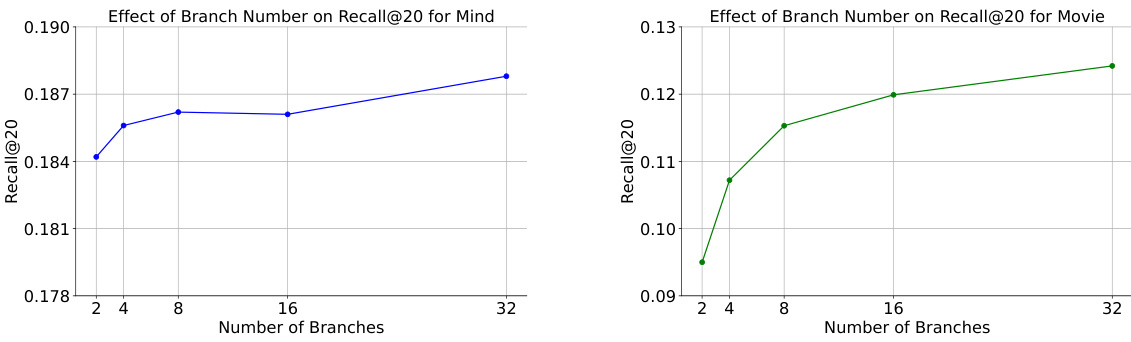
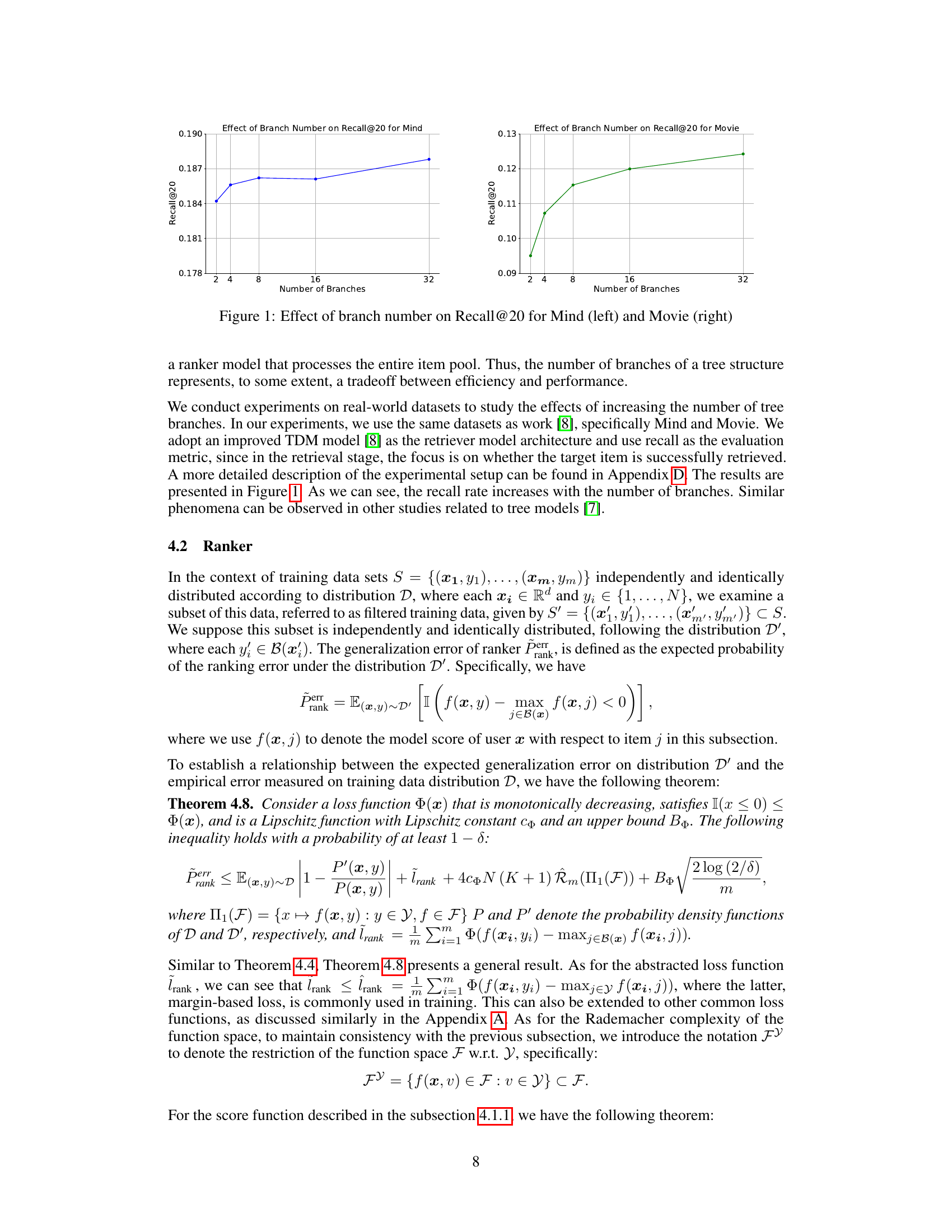
This figure shows the impact of varying the number of branches in a tree-structured retriever model on the Recall@20 metric. Two datasets, Mind and Movie, are used for evaluation. The left panel displays the results for the Mind dataset, while the right panel shows the results for the Movie dataset. Both plots illustrate an increasing trend of Recall@20 with the increasing number of branches, suggesting that a more branched tree structure leads to better retrieval performance.
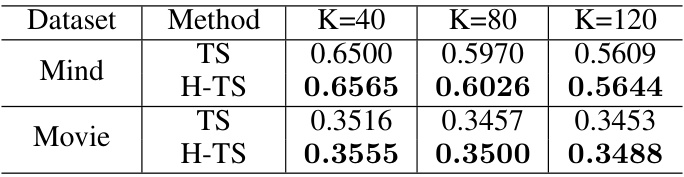
This table presents the top-1 classification accuracy (Precision@1) results for two different two-stage recommendation models, TS and H-TS, evaluated across three different numbers of retrieved items (K=40, K=80, K=120). The results are shown for two datasets, Mind and Movie. The H-TS model (Harmonized Two-Stage Model), which focuses on aligning training and inference data distributions, generally shows slightly better performance than the TS (Two-Stage Model) across all settings.
Full paper#