↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current image generation methods, especially Classifier-Free Guidance (CFG), struggle to balance image quality and variation. CFG improves quality by using an unconditional model to guide a conditional one but reduces the variation. This entanglement makes independent control difficult. The existing methods also have limitations such as task discrepancy in training and inability to control prompt alignment and quality separately.
This paper proposes a novel method called Autoguidance to address this problem. Instead of using an unconditional model, Autoguidance guides the generation process using a less-trained, smaller version of the model itself. This surprisingly leads to significant improvements in image quality without sacrificing variation. The researchers demonstrate the effectiveness of Autoguidance on various datasets, setting new benchmarks for image generation quality.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation because it introduces a novel method, Autoguidance, that significantly improves the quality of images generated by diffusion models without sacrificing variation. This is a major step forward in controlling the trade-off between quality and diversity, a long-standing challenge in the field. The findings open new avenues for improving other generative models and enhancing image synthesis techniques.
Visual Insights#
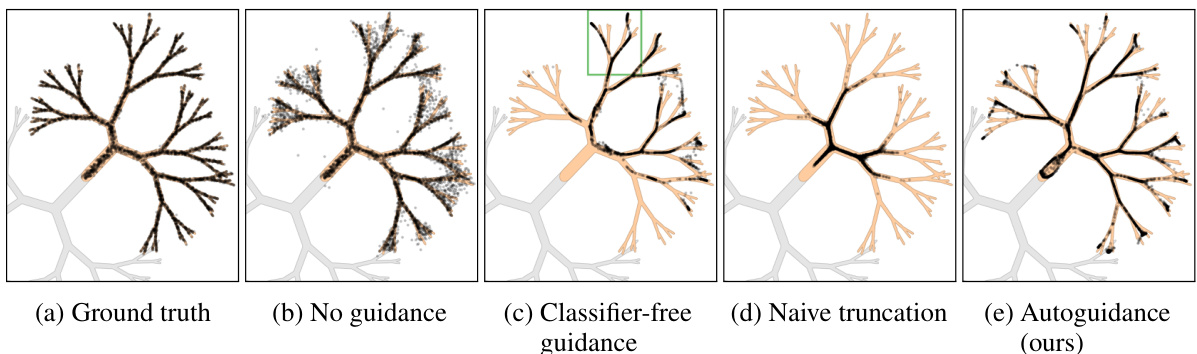
This figure demonstrates the effect of different sampling methods on a 2D fractal-like data distribution. It compares the ground truth distribution to results from unguided sampling, classifier-free guidance (CFG), naive truncation, and the authors’ proposed autoguidance method. The figure highlights how autoguidance effectively concentrates samples in high-probability regions without sacrificing diversity, unlike CFG which overemphasizes the class and reduces variation, or naive truncation which leads to reduced diversity.
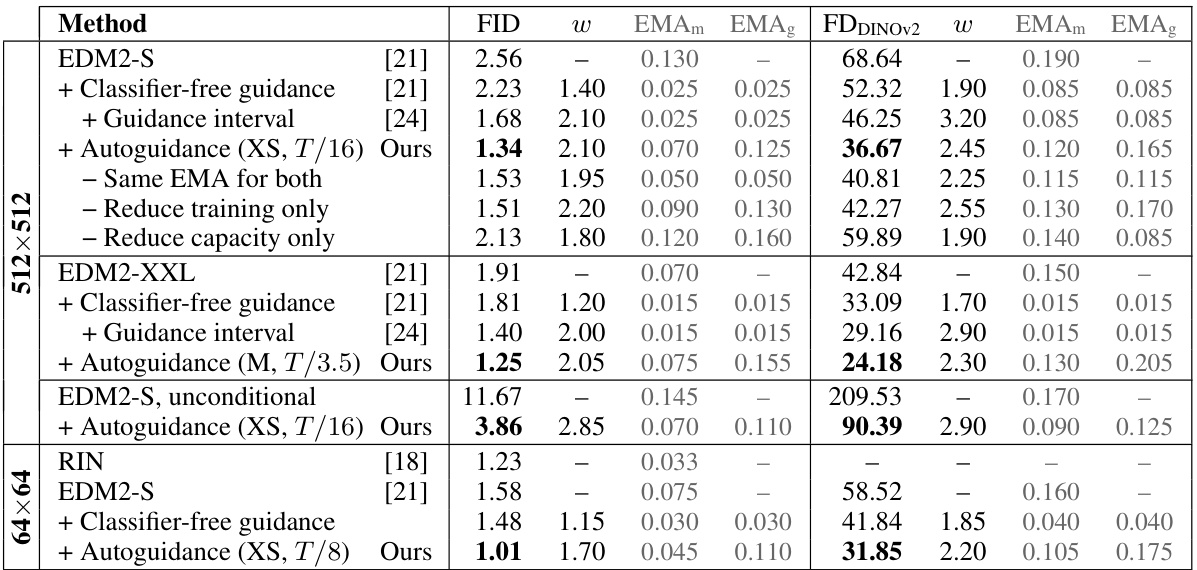
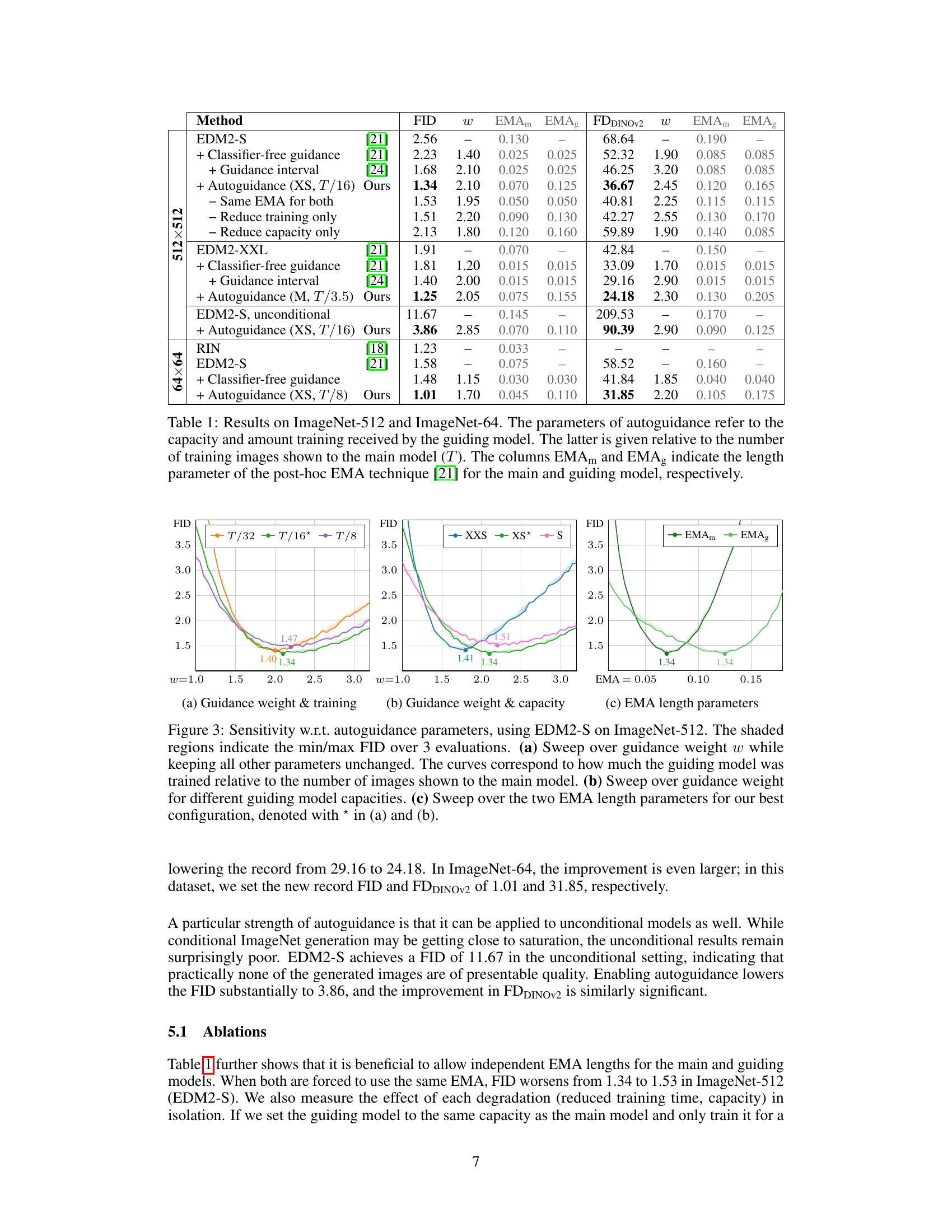
This table presents the results of experiments conducted on the ImageNet dataset at two resolutions: 512x512 and 64x64. It compares several methods for image generation, including the baseline EDM2 models, classifier-free guidance (CFG), guidance interval, and the proposed autoguidance method. The FID (Fréchet Inception Distance) and FDDINOV2 scores are reported, which measure the quality and diversity of generated images. The table details the hyperparameters used for each method, including the guidance weight (w), EMA (exponential moving average) lengths for the main and guiding models (EMAm and EMAg), and the capacity and training time of the guiding model for the autoguidance method. The results demonstrate the effectiveness of autoguidance in improving image quality and diversity, especially compared to CFG.
In-depth insights#
Autoguidance: A New Method#
The proposed ‘Autoguidance’ method presents a novel approach to enhancing image quality in diffusion models by using a less-trained version of the primary model as a guide, rather than employing a separate unconditional model. This technique offers disentangled control over image quality and variation, overcoming limitations of existing classifier-free guidance (CFG). Unlike CFG, autoguidance avoids the task discrepancy problem inherent in using separately trained models, resulting in improved sample quality and consistency. The method demonstrates significant improvements in ImageNet generation benchmarks, achieving record-breaking FID scores. Autoguidance’s applicability extends to unconditional diffusion models, addressing a limitation of CFG and representing a noteworthy advancement for a wide range of diffusion model applications. The core innovation lies in the use of an inferior model for guidance, which unexpectedly leads to superior results due to how it implicitly corrects and refines model outputs by identifying and mitigating errors.
CFG Limitations#
Classifier-free guidance (CFG) shows significant promise in enhancing image quality and prompt alignment within diffusion models, yet it’s not without limitations. CFG’s reliance on an unconditional model introduces a task discrepancy, potentially leading to suboptimal sampling trajectories and oversimplified image compositions. The entanglement of quality and variation control is another drawback, making it difficult to independently adjust image fidelity without sacrificing diversity. CFG’s inherent reliance on conditional settings restricts its applicability to unconditional generation, limiting its broader use within various diffusion model architectures. Furthermore, CFG can be computationally expensive, especially when used with higher guidance weights or more complex conditional information. Addressing these limitations is crucial for unlocking the full potential of CFG and developing more robust and versatile image generation techniques. Future improvements might involve finding ways to decouple quality and variation control or developing alternatives to the unconditional model that better complement the conditional model’s task.
Synthetic Degradations#
The section on “Synthetic Degradations” explores a controlled experiment to isolate the image quality improvement effect of the proposed autoguidance method. Instead of relying on naturally occurring differences between models, the researchers introduce synthetically controlled degradations (dropout and input noise) to create a weaker, guiding model. This allows them to test the hypothesis that the quality gap between the models, rather than the specific type of degradation, is crucial for successful autoguidance. The results show that when degradations are compatible, autoguidance effectively undoes the negative impacts, demonstrating that the method’s effectiveness stems from exploiting discrepancies in model performance rather than inherent differences in training objectives.
Image Quality Boost#
The concept of “Image Quality Boost” in the context of diffusion models is a significant area of research. The paper explores how to improve the quality of generated images without sacrificing diversity. Classifier-free guidance (CFG), a popular method, is shown to have limitations, often resulting in overly simplistic images and reduced variation. The core idea presented is autoguidance, a novel approach that guides the generation process using a less-trained, inferior version of the main model itself. This cleverly separates the effects of prompt alignment and quality improvement, which were previously entangled. Autoguidance is shown to drastically enhance the quality of images generated by both conditional and unconditional diffusion models, setting new records on ImageNet benchmarks. This suggests that the inherent quality limitations of CFG may stem from training discrepancies between the conditional and unconditional models. The approach’s success highlights the importance of using a properly degraded guidance model, rather than merely tweaking parameters, to effectively guide generation and significantly boost image quality.
Future Research#
The paper’s ‘Future Research’ section would ideally explore several key areas. Formally proving the conditions under which autoguidance is beneficial is crucial for broader adoption. This requires a deeper theoretical understanding of the interaction between model capacity, training time, and the resulting sampling behavior. Developing practical guidelines for selecting optimal guiding models would make the method more user-friendly, addressing concerns about parameter tuning. The investigation should extend beyond the current benchmarks to evaluate the method’s effectiveness across diverse datasets and model architectures. Combining autoguidance with other techniques, such as noise-level-dependent guidance or classifier guidance intervals, could unlock further improvements in image quality and control. Finally, addressing the potential challenges and ethical considerations associated with the method’s ability to generate highly realistic images is vital. This involves exploring methods for mitigating misuse, such as developing safeguards against malicious applications, and promoting responsible usage guidelines.
More visual insights#
More on figures
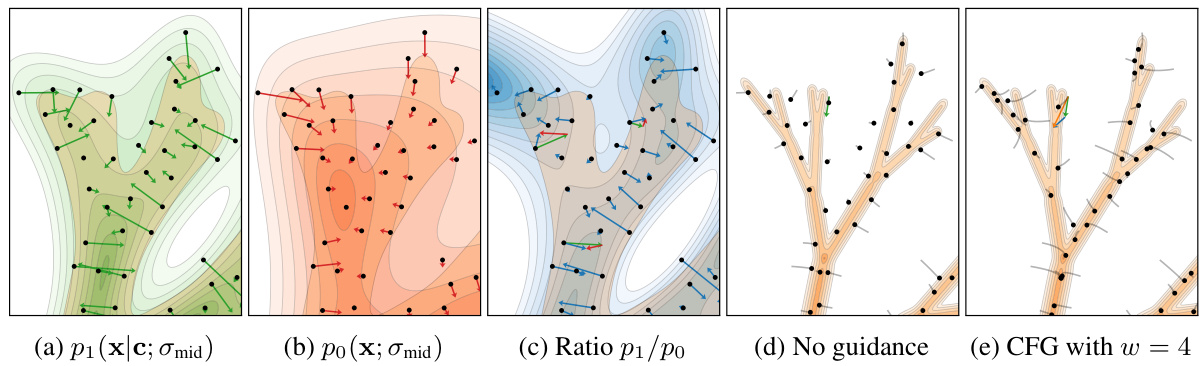
This figure shows a detailed analysis of a 2D toy example to explain how classifier-free guidance (CFG) improves image quality. It compares the learned density of a conditional model (p1) and an unconditional model (po), highlighting the differences in their sharpness and fit to the data. It also illustrates how CFG, through the gradient of the ratio p1/po, pulls samples toward higher-probability regions, improving image quality but potentially reducing diversity. The unguided sampling trajectories and CFG-guided trajectories are visually compared, demonstrating the effect on sample distribution.
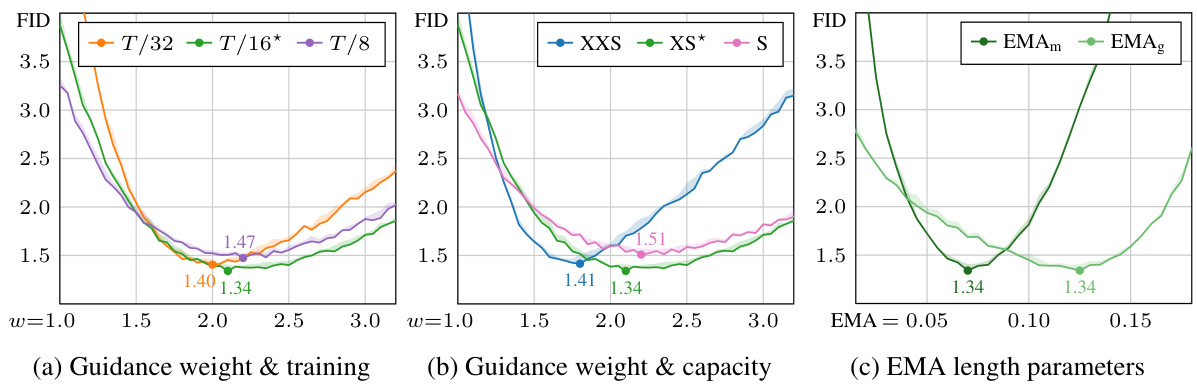
This figure analyzes the sensitivity of the autoguidance method’s performance to different hyperparameters using the EDM2-S model on the ImageNet-512 dataset. It shows three subplots: (a) FID scores varying with guidance weight and the relative training time of the guiding model; (b) FID scores varying with guidance weight and the capacity of the guiding model; (c) FID scores varying with the EMA length parameters (for both main and guiding models). The shaded areas represent the range of FID values across three trials, illustrating the method’s robustness.

This figure displays example image generation results for four classes from the ImageNet-512 dataset using the EDM2-S model. It compares the results of using classifier-free guidance (CFG) and the authors’ proposed autoguidance method. Each row represents a different method, with the columns showing how the generated images vary as the guidance weight increases (from w=1 to w=3). The figure visually demonstrates that autoguidance generates more diverse and stylistically varied images compared to CFG, which tends toward more canonical representations.

This figure shows the results of using different guidance weights (w) on DeepFloyd IF image generation model for a specific prompt. It compares the results of using Classifier-free Guidance (CFG), Autoguidance (a new method proposed in the paper), and interpolations between the two methods. The figure demonstrates how different methods and varying guidance weights influence the generated image’s style and composition. It highlights that autoguidance preserves image style better than CFG, while both methods improve image quality with higher guidance weights.

This figure shows additional qualitative results obtained using DeepFloyd IF, a large-scale image generation model. It demonstrates the effects of classifier-free guidance (CFG) and the authors’ proposed method, ‘autoguidance’, on image generation, showing interpolations between the two techniques. The rows represent increasing guidance weights (1 to 4), while the columns show the results from pure CFG on the left, pure autoguidance on the right, and interpolations in the middle.

This figure shows example image generation results using two different methods: classifier-free guidance (CFG) and the authors’ proposed autoguidance method. Four different ImageNet-512 classes (Tree frog, Palace, Mushroom, Castle) are used as image generation prompts. The horizontal axis shows increasing values of the guidance weight (w), and each row demonstrates the results using CFG (top row) versus autoguidance (bottom row). The figure demonstrates that, while both methods improve image quality with increasing guidance weight, autoguidance maintains greater diversity in image generation than CFG.
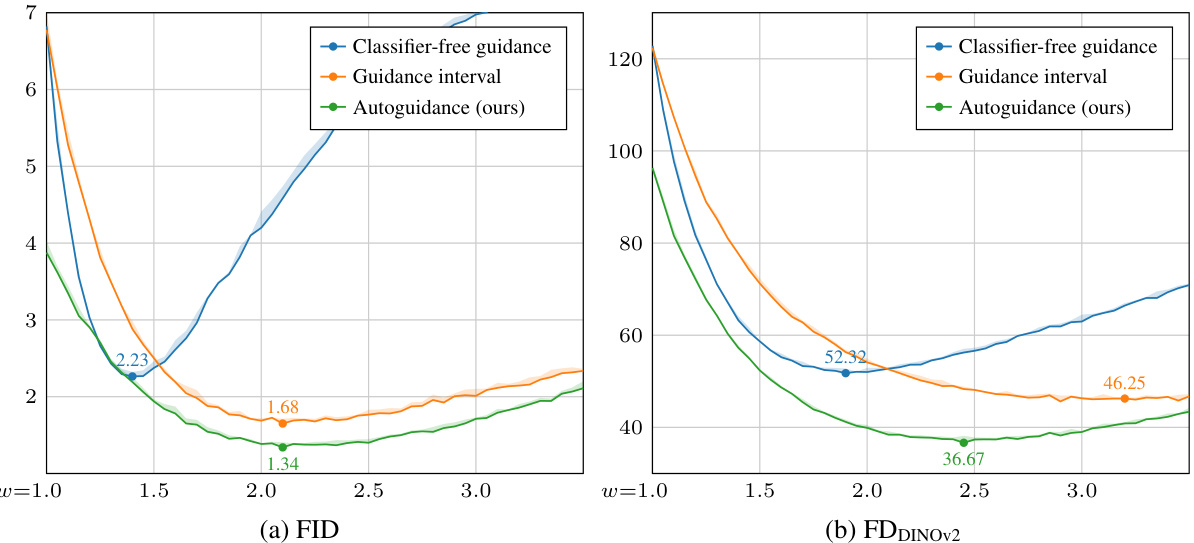
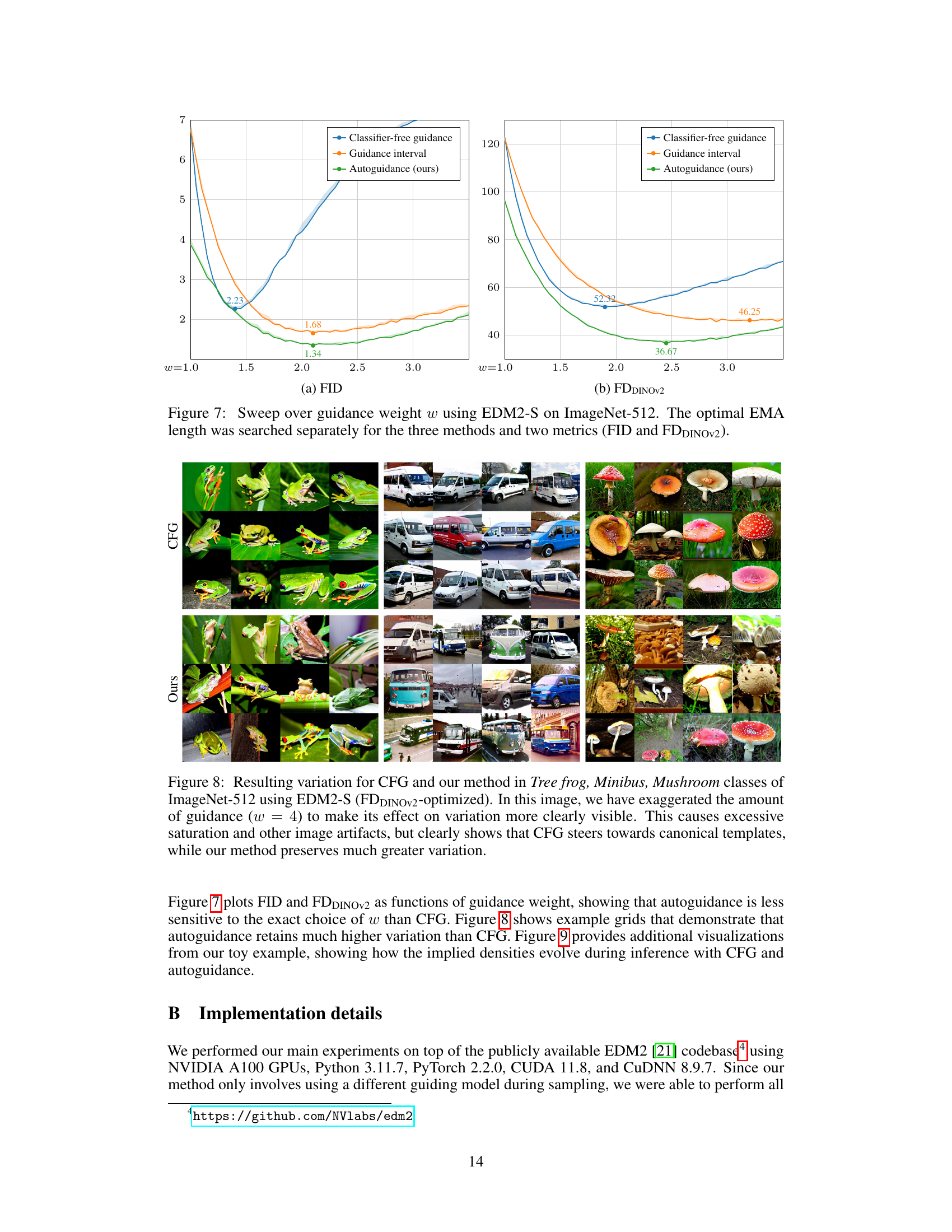
This figure shows the sensitivity analysis of the FID and FDDINOV2 scores with respect to the guidance weight (w) for three different guidance methods: Classifier-free guidance, Guidance interval, and Autoguidance (the proposed method). The EDM2-S model was used on the ImageNet-512 dataset. For each method, the optimal EMA length was determined independently for FID and FDDINOV2 to ensure fair comparison. The plot reveals the performance of each method across a range of guidance weights, illustrating their relative strengths and weaknesses in balancing image quality and diversity.

This figure compares the image variations generated by Classifier-Free Guidance (CFG) and the proposed Autoguidance method. By increasing the guidance weight (w=4), the differences are highlighted. CFG produces images that are more similar to each other, sticking to what seems to be canonical representations of each class. Conversely, Autoguidance maintains a higher degree of variation, despite the high guidance weight, avoiding overly simplified or stereotypical results. The excessive saturation observed with the high w value is an artifact of this exaggerated testing.
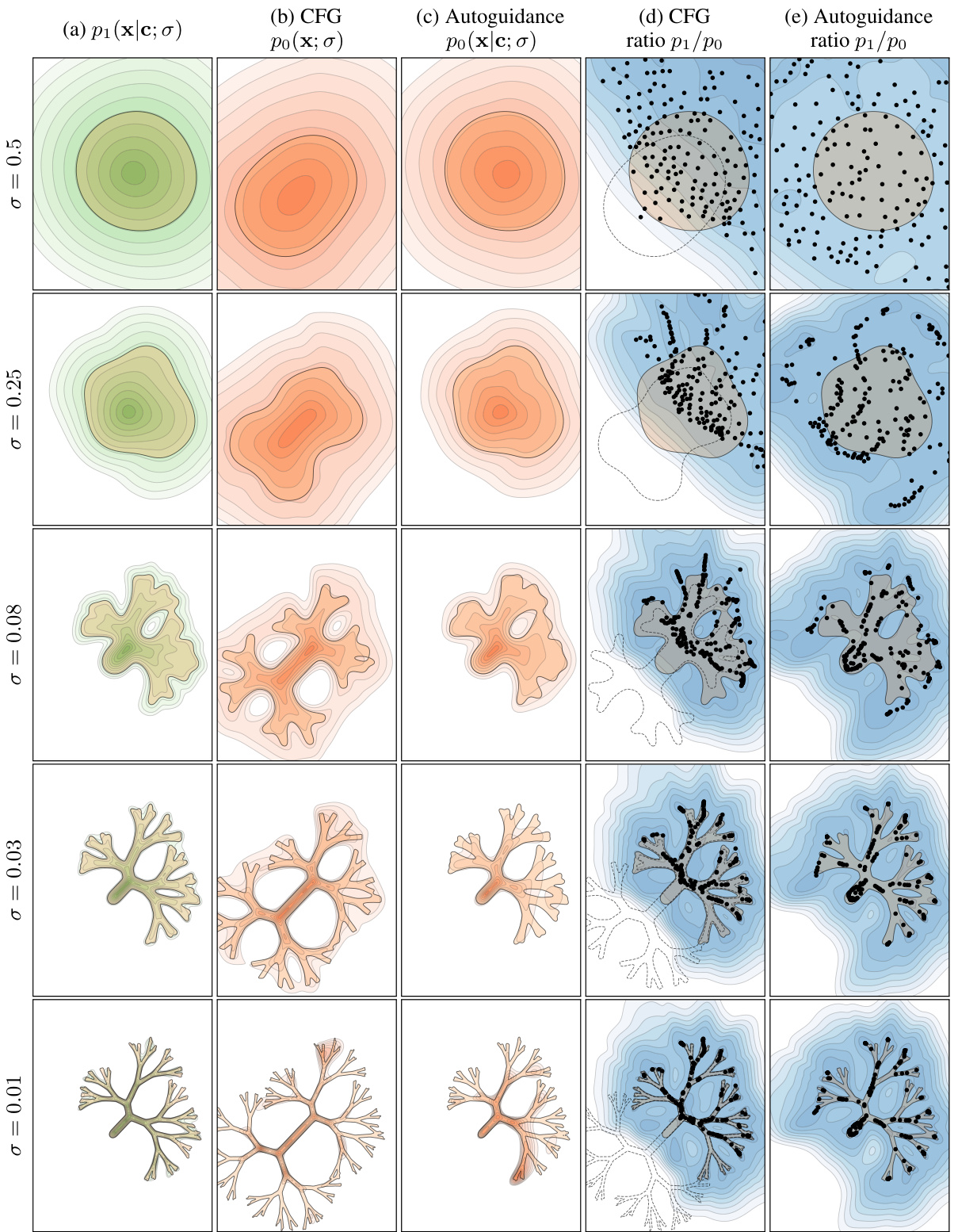
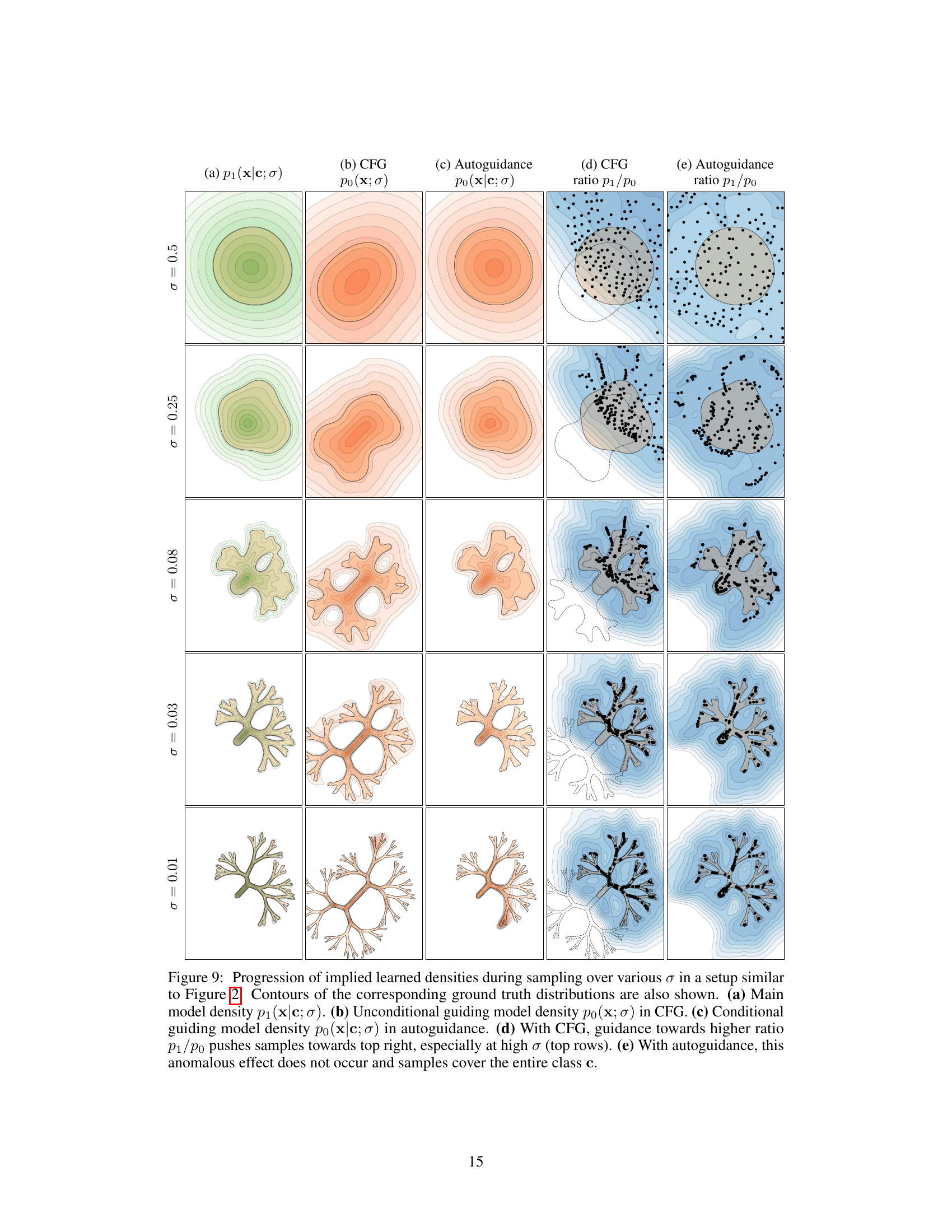
Figure 9 compares the evolution of the implied densities during sampling, using the standard CFG and the proposed autoguidance method. The figure shows how the model densities (main and guiding models) and the ratio of conditional to unconditional model densities change over the course of the sampling process. The results indicate that with CFG, samples are pulled towards the high-density regions which cause the reduction in diversity. In contrast, autoguidance successfully avoids this effect and samples cover the entire class.
Full paper#