↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Unconditional image generation, aiming to model data distribution without human labels, has significantly lagged behind conditional generation. This gap is primarily due to the absence of semantic information provided by labels in the unconditional setting. Existing methods often struggle to generate high-quality images without this crucial guidance.
This work introduces Representation-Conditioned Generation (RCG), a novel framework that addresses this limitation. RCG generates semantic representations using a self-supervised encoder and then employs these representations to condition an image generator. Through extensive experiments on ImageNet, RCG demonstrates substantial improvements in unconditional image generation, achieving state-of-the-art results and narrowing the gap with its class-conditional counterpart.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between conditional and unconditional image generation, a long-standing challenge in the field. By introducing a novel self-supervised method, it unlocks the potential of large-scale unlabeled data for high-quality image generation, opening new avenues for research and applications. Its state-of-the-art results and readily available codebase will significantly impact the generative modeling community.
Visual Insights#
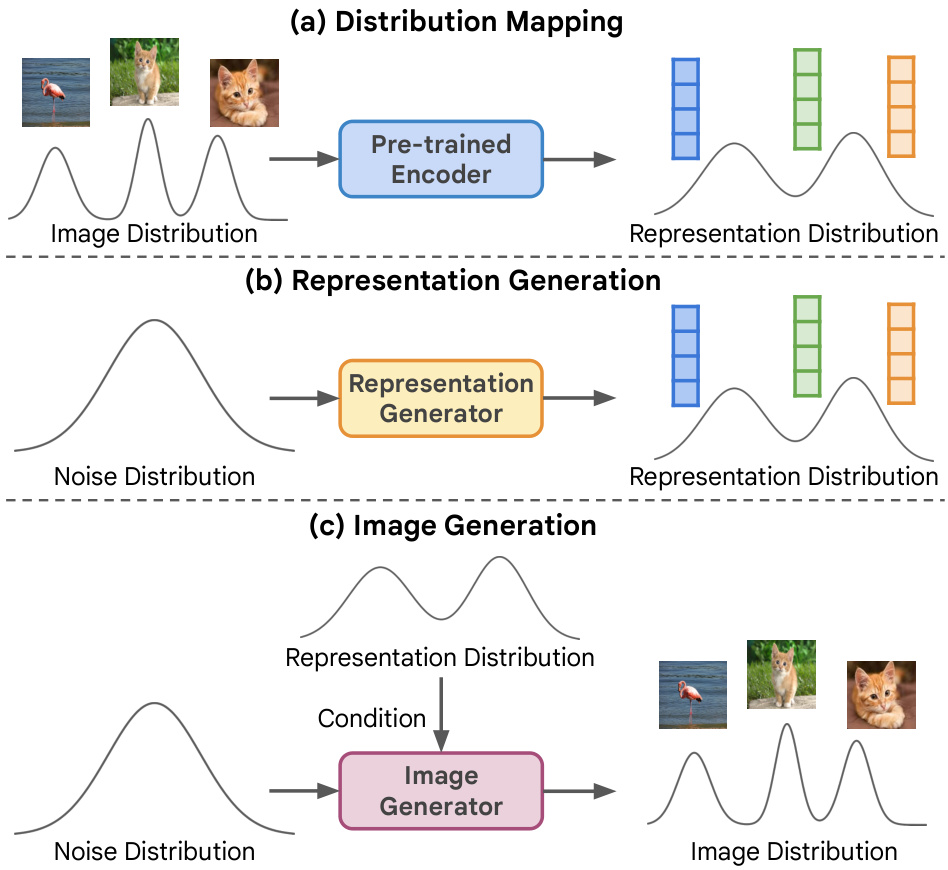
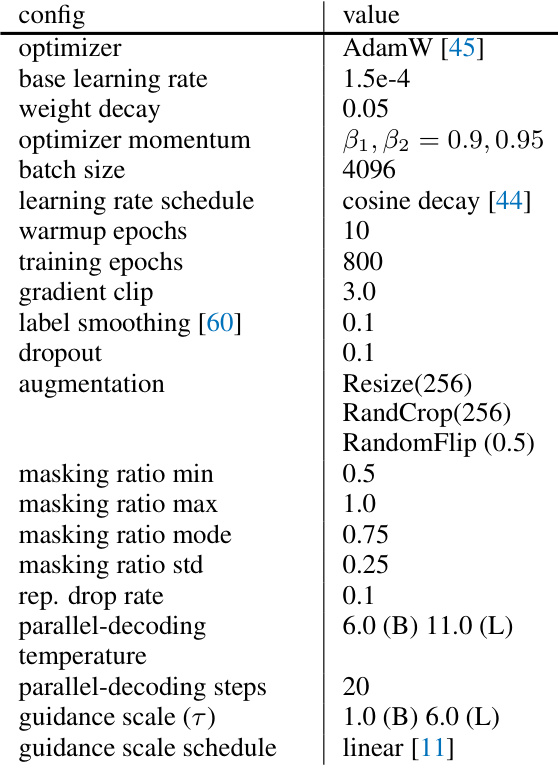
This figure illustrates the Representation-Conditioned Generation (RCG) framework, a three-part process for unconditional image generation. First, a pre-trained self-supervised encoder maps the image distribution to a lower-dimensional representation distribution. Second, a representation generator creates new representations based on a noise distribution, constrained by the learned representation distribution. Finally, an image generator (like ADM, DiT, or MAGE) uses these representations to generate new images, conditioned on this representation.
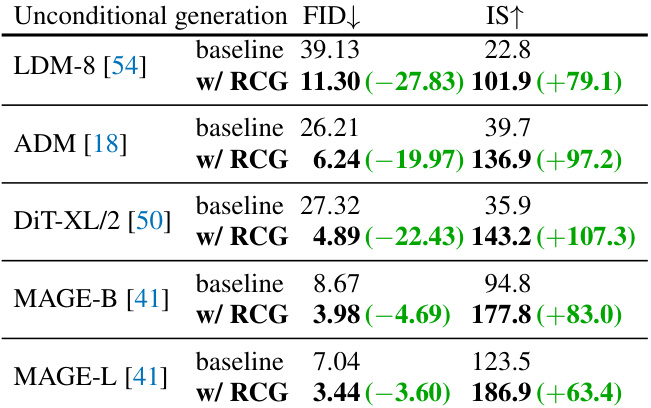
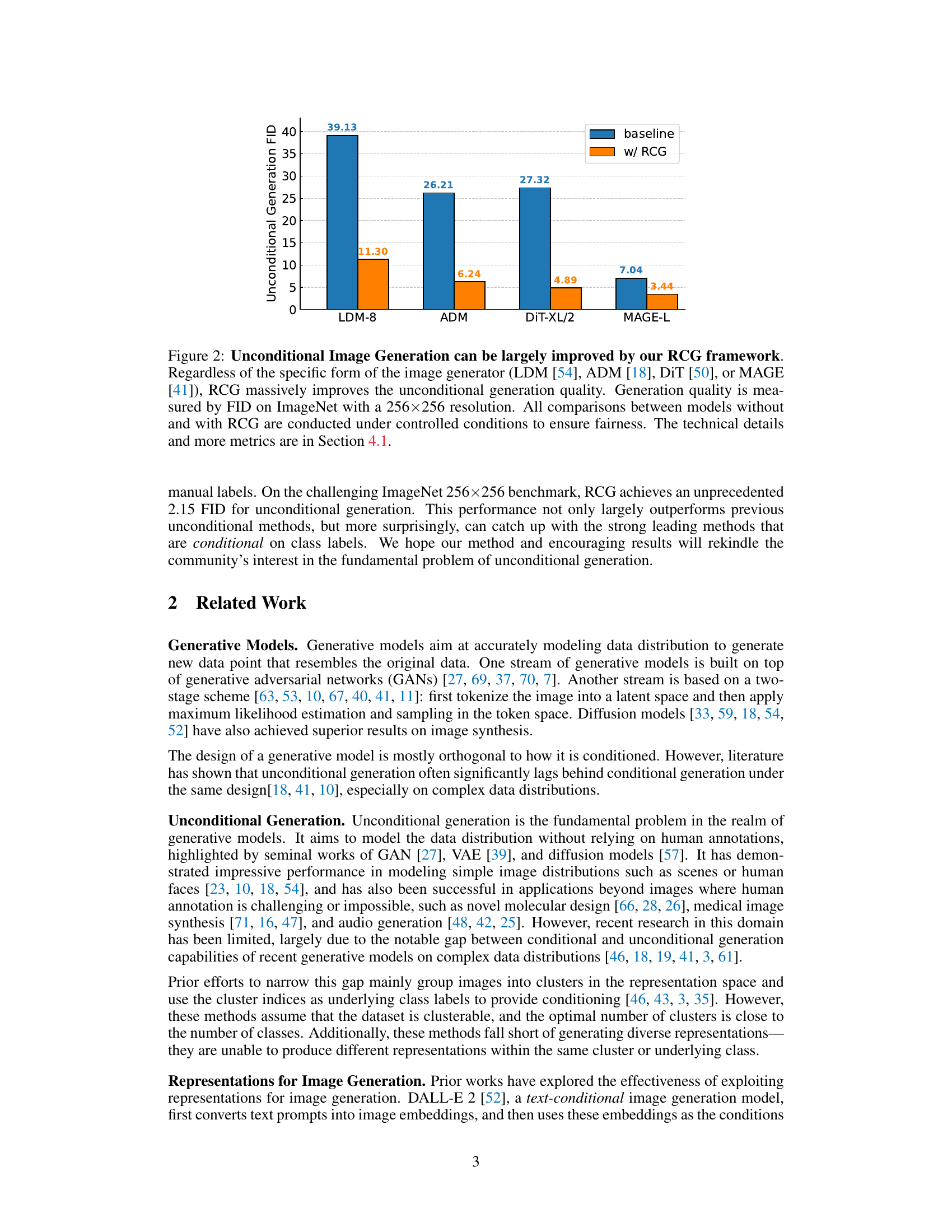
This table shows the improvement in unconditional image generation achieved by using the Representation-Conditioned Generation (RCG) framework. It compares the Fréchet Inception Distance (FID) and Inception Score (IS) for several different image generation models (LDM-8, ADM, DiT-XL/2, MAGE-B, MAGE-L) both with and without RCG. Lower FID scores indicate better image fidelity and higher IS scores indicate higher image diversity and quality. The table highlights the significant reduction in FID achieved with RCG across all models, demonstrating its effectiveness in enhancing unconditional image generation.
In-depth insights#
Unconditional Gen#
Unconditional generative models, a long-standing challenge in AI, aim to learn data distributions without relying on human-annotated labels. This approach holds the promise of harnessing vast amounts of unlabeled data, a significant advantage. However, the quality of generated samples from unconditional models has historically lagged behind that of their conditional counterparts. This paper addresses this gap by proposing a novel framework, Representation-Conditioned Generation (RCG). RCG leverages pre-trained self-supervised encoders to generate semantic representations, effectively providing a form of implicit conditioning without explicit labels. By conditioning an image generator on these representations, RCG achieves significantly improved unconditional generation quality, demonstrated by state-of-the-art results on ImageNet. This work provides a substantial advance in the field, highlighting the potential of self-supervised learning to overcome limitations in unconditional generation and paving the way for generating high-quality images solely from unlabeled data. The key innovation lies in bridging the gap between unsupervised and conditional generation by cleverly using the semantic information implicitly contained within self-supervised representations.
RCG Framework#
The RCG framework presents a novel approach to unconditional image generation by cleverly sidestepping the limitations of traditional methods. Instead of directly modeling the complex high-dimensional image distribution, RCG decomposes the problem into two simpler subtasks. First, it leverages a pre-trained self-supervised encoder to map the image distribution into a lower-dimensional representation space, effectively capturing semantic information without human annotation. A representation generator then produces unconditional representations within this space, which are used to condition an image generator. This two-stage process allows the model to learn the representation distribution effectively and then map those representations back to images. The framework’s modularity is a key strength, enabling the use of various image generators. This allows RCG to achieve state-of-the-art FID scores, surpassing previous unconditional methods and demonstrating that self-supervised representations can provide effective conditioning, closing the gap with conditional methods. The elegance of RCG lies in its simplicity and effectiveness.
Empirical Results#
An ‘Empirical Results’ section in a research paper would typically present quantitative and qualitative findings. Quantitative results might involve tables and figures showcasing key metrics (e.g., precision, recall, F1-score, accuracy, AUC, etc.) and statistical significance tests. The discussion should go beyond simply reporting numbers, offering insightful analysis of trends, patterns, and unexpected findings. For instance, it’s crucial to explain any discrepancies between expected and observed results, potential reasons for the discrepancies, and limitations of the methodology. Qualitative results could involve visualizations (e.g., images generated by a model, heatmaps illustrating attention mechanisms, etc.) and a textual description interpreting these visuals. The analysis should highlight the strengths and weaknesses revealed by the qualitative results and link them to the quantitative findings to paint a comprehensive picture of the work’s success and challenges. Overall, a robust empirical results section is clear, concise, well-organized, and insightful. It avoids overly technical jargon, making the results easily understandable for a broad audience. Finally, the interpretation of the results should be balanced, acknowledging both successes and limitations.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending RCG to other modalities beyond images, such as audio or video generation, would be a significant advancement. This would involve adapting the representation generator and image generator to handle the unique characteristics of different data types. Investigating alternative self-supervised learning methods for representation generation is crucial, potentially leading to improved semantic information capture and higher-quality generation. Improving the efficiency of RCG, both in terms of training time and computational cost, is important for practical applications, especially with very large datasets. Finally, developing more sophisticated guidance mechanisms for the image generation stage could lead to increased control over the generated samples, potentially bridging the remaining gap between unconditional and conditional generation.
Limitations#
A critical analysis of limitations in a research paper requires a nuanced understanding of the work’s scope and methodology. Identifying limitations isn’t about finding flaws, but acknowledging the boundaries of the research. A thoughtful limitations section should discuss assumptions made during model development (e.g., data distribution, independence assumptions). Addressing the generalizability of findings to other datasets or scenarios is crucial. For instance, if the model performed exceptionally well on a specific dataset, but the characteristics of that dataset might not be representative of real-world situations, that limitation should be explicitly acknowledged. Similarly, computational constraints should be mentioned if they impacted the scope or scale of the experiments. The availability of resources can influence the complexity of the model and the scale of evaluation. Furthermore, a discussion of potential biases inherent in the dataset or the methodology used is necessary for a transparent evaluation. Lastly, future research directions should be proposed to mitigate these limitations and highlight pathways for improvement. By thoroughly addressing limitations, researchers contribute to a more comprehensive and robust understanding of the research findings and pave the way for improved future work.
More visual insights#
More on figures
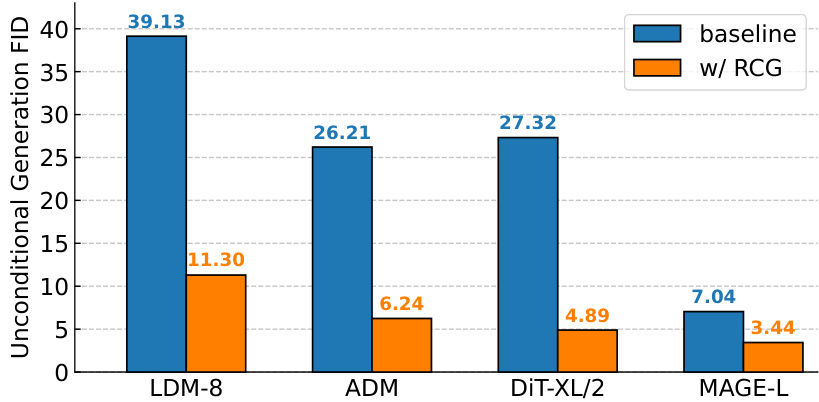
The figure shows a bar chart comparing the FID scores (Fréchet Inception Distance, a metric for evaluating the quality of generated images) for unconditional image generation using different image generators (LDM-8, ADM, DiT-XL/2, MAGE-L) with and without the RCG framework. The RCG method significantly reduces the FID scores across all generators, demonstrating its effectiveness in improving the quality of unconditional image generation.
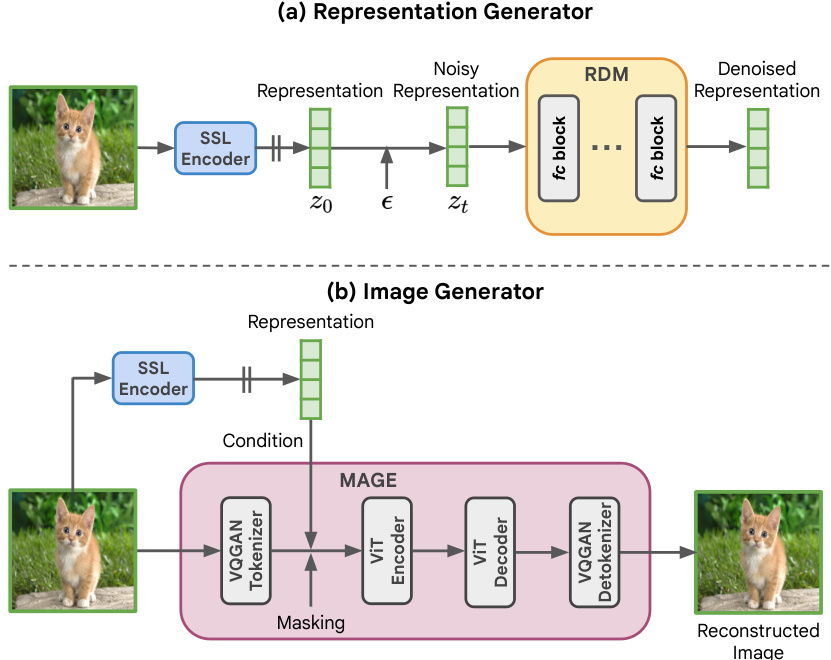
This figure illustrates the training framework of the Representation-Conditioned Generation (RCG) model. It shows two main components: a representation generator and an image generator. The representation generator takes representations from a pre-trained self-supervised encoder and adds Gaussian noise. It then trains a network to denoise these representations. The image generator uses the same pre-trained encoder and takes the denoised representation as a condition. It also takes a masked tokenized image as input and trains a network to reconstruct the full image based on the representation and the masked input.
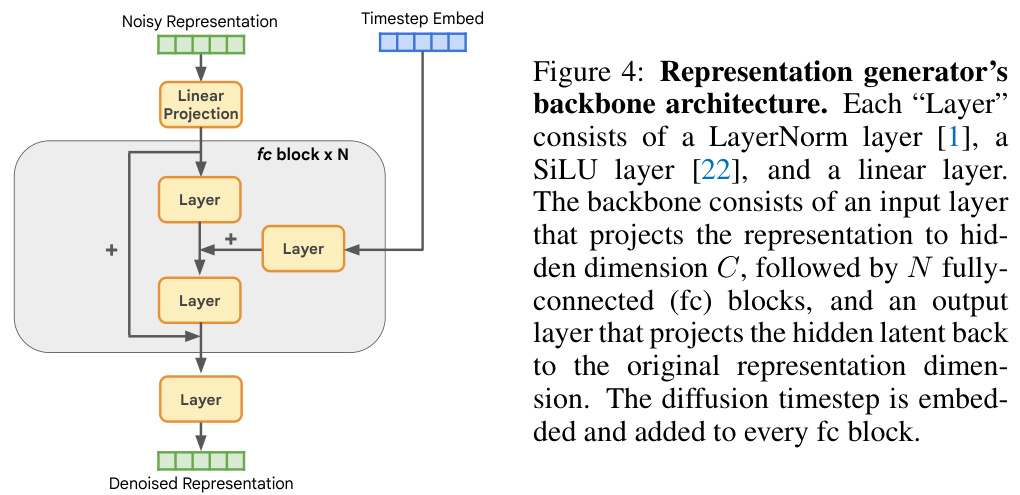
This figure shows the architecture of the representation generator in RCG. The backbone consists of an input layer, N fully-connected blocks, and an output layer. Each fully-connected block contains a LayerNorm, SiLU activation, and a linear layer. The diffusion timestep is embedded and added to each fully-connected block. This architecture generates representations without explicit conditioning.

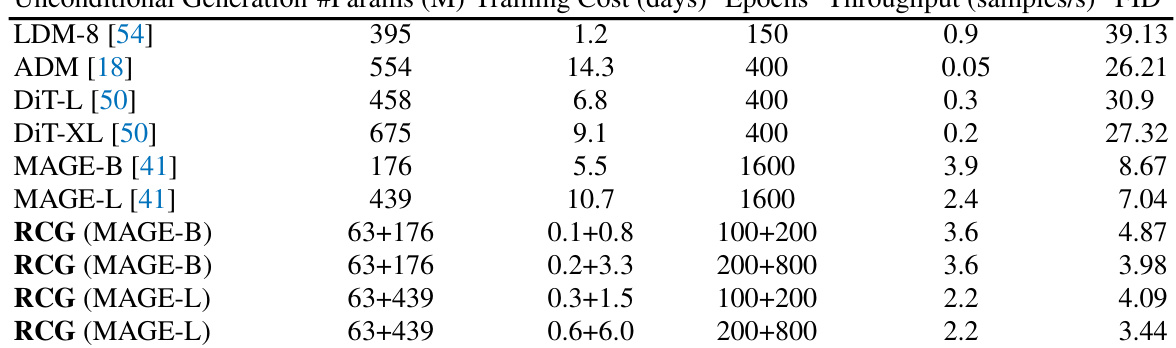
This figure compares the training cost and the unconditional generation FID of several unconditional image generation models, including those enhanced by RCG. RCG significantly reduces the FID (Frechet Inception Distance, a metric of image generation quality) with less training time compared to the baselines. This highlights the efficiency of RCG in achieving high-quality unconditional generation.

This figure demonstrates the ability of RCG to generate multiple images from a single representation, showing that the model can produce images with diverse appearances while maintaining semantic consistency. The images in each row share a common semantic core (as indicated by the reference image on the left), while exhibiting variations in style, pose, and other details. This highlights the model’s ability to capture high-level semantic understanding while allowing for diverse low-level variations.

This figure shows the results of RCG when generating images using interpolated representations from two different source images. As the interpolation weight changes from 0.0 (representing the first image) to 1.0 (representing the second image), the generated images smoothly transition semantically between the characteristics of the two source images. This demonstrates the ability of RCG to generate semantically coherent and smoothly interpolating images in its representation space. Each row shows interpolation between a pair of images from different ImageNet classes.

This figure shows a grid of images generated by the Representation-Conditioned Generation (RCG) model on the ImageNet dataset. The images are 256x256 pixels and demonstrate the model’s ability to generate high-quality, diverse images without the need for human-provided labels. This highlights a key aspect of RCG: its ability to model complex data distributions and generate realistic images, thus addressing the problem of unconditional image generation.

This figure shows a grid of 100 images generated by the Representation-Conditioned Generation (RCG) model on the ImageNet dataset. Each image is 256x256 pixels. The images demonstrate the model’s ability to generate diverse and realistic images without relying on human-annotated labels. The variety of objects and scenes showcases the model’s capacity to learn and model complex data distributions.

This figure shows example images generated by the Representation-Conditioned Generation (RCG) model with class conditioning. It demonstrates the model’s ability to generate images of different classes with high fidelity and diversity. Each row represents images generated for a specific class, showcasing the model’s capability to generate multiple variations of the same class, reflecting the diversity within each category.

This figure shows examples of images generated by the Representation-Conditioned Generation (RCG) model when conditioned on class labels. It demonstrates the model’s ability to generate diverse and high-quality images for various classes, showcasing its effectiveness in class-conditional generation.

This figure shows several examples of images generated by the Representation-Conditioned Generation (RCG) model on the ImageNet dataset at a resolution of 256x256 pixels. The images demonstrate the model’s ability to generate diverse and realistic images without relying on any human-provided labels or class information. The diversity in the generated images showcases the model’s ability to capture the underlying data distribution effectively, generating a wide variety of images that are both realistic and semantically meaningful. The lack of human annotation highlights the model’s capability to perform unconditional image generation.

This figure shows the results of class-unconditional image generation on ImageNet 256x256 dataset using the proposed Representation-Conditioned Generation (RCG) method. It compares the image generation results with and without classifier-free guidance (CFG). The results demonstrate that RCG achieves strong generation quality even without CFG, and that incorporating CFG further improves the quality of generated images. Three categories of images are shown, for each category, the images in the left column are generated without guidance, and the images in the right column are generated with guidance.
More on tables
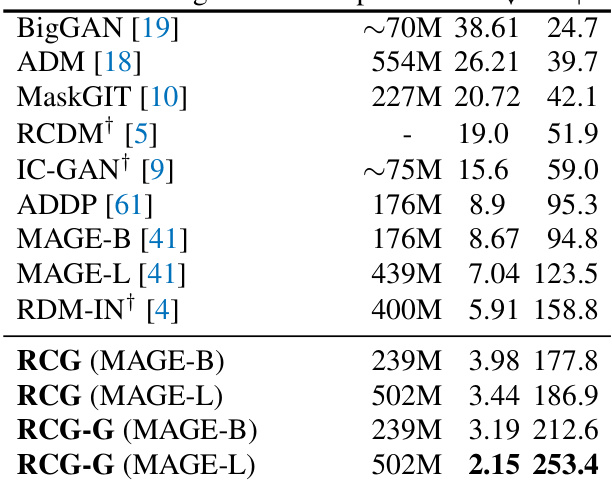
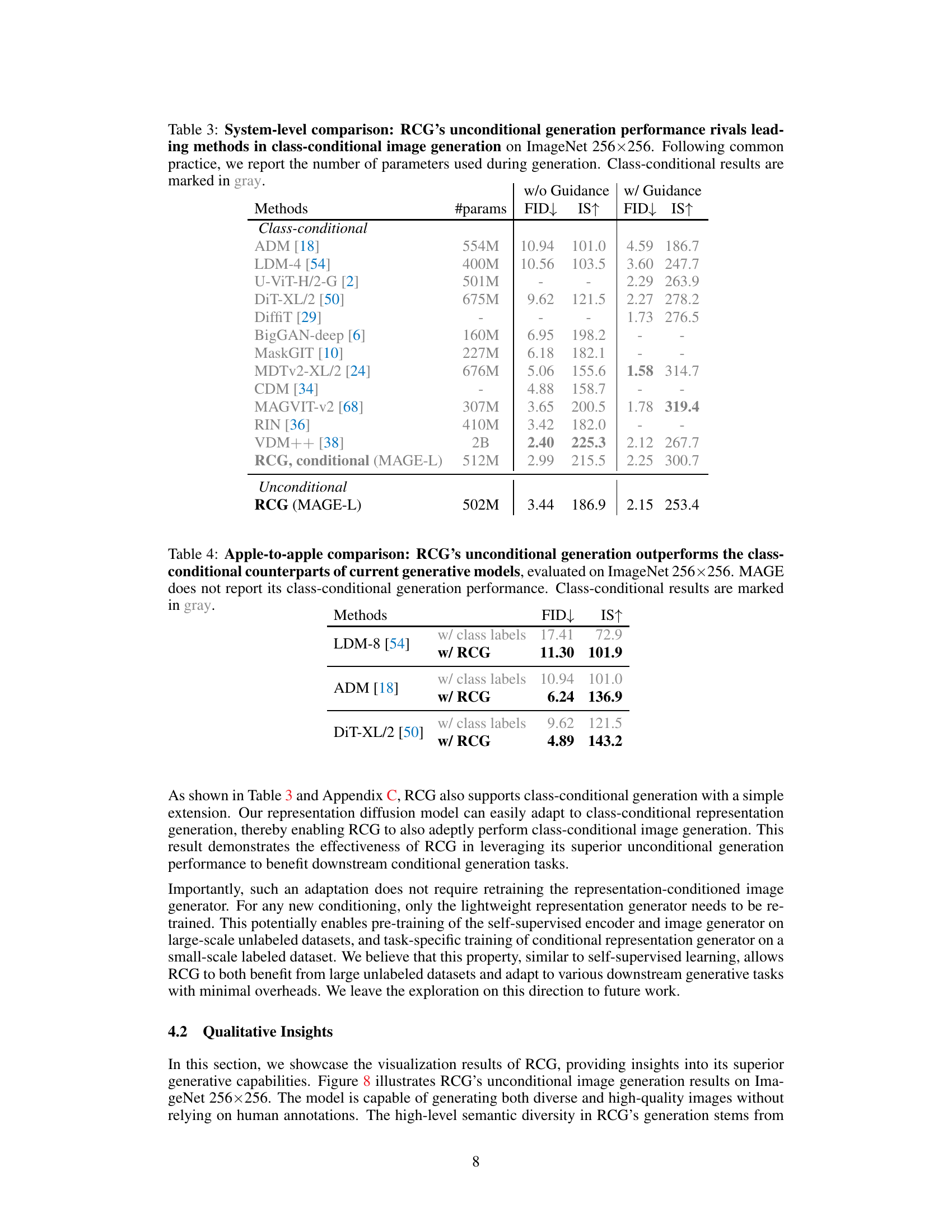
This table compares the performance of RCG with other state-of-the-art unconditional image generation models on the ImageNet 256x256 dataset. It shows that RCG significantly improves the FID (Frechet Inception Distance) and IS (Inception Score), key metrics for evaluating the quality and diversity of generated images. The table highlights the significant reduction in FID achieved by RCG compared to previous methods, indicating a substantial improvement in image generation quality. It also shows the number of parameters used by each model.
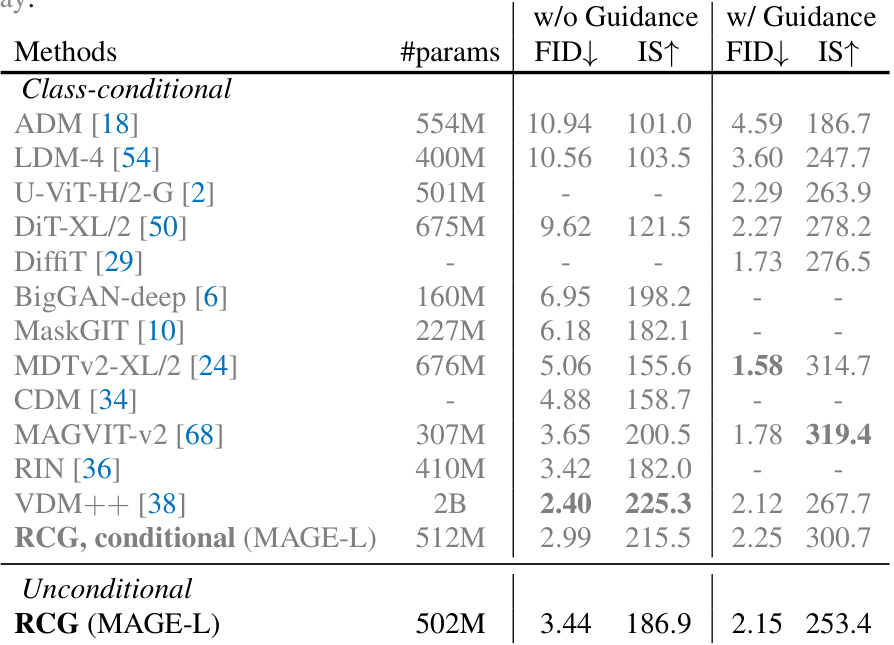
This table presents a comparison of the unconditional image generation performance of several generative models, both with and without the proposed Representation-Conditioned Generation (RCG) method. The models compared include LDM-8, ADM, DiT-XL/2, and MAGE-L. The performance is measured by FID (Frechet Inception Distance) and IS (Inception Score), common metrics for evaluating the quality and diversity of generated images. Lower FID values and higher IS values indicate better performance. The table demonstrates that RCG significantly improves the FID and IS scores of all the models tested, showing its effectiveness in enhancing unconditional image generation.
This table compares the Fréchet Inception Distance (FID) and Inception Score (IS) for unconditional image generation using several different generative models, both with and without the Representation-Conditioned Generation (RCG) framework proposed in the paper. It demonstrates that RCG significantly improves the FID (lower is better) and IS (higher is better) scores across different models, highlighting the effectiveness of the RCG method for improving unconditional image generation.
This table presents a comparison of the unconditional image generation performance (measured by FID and IS) of several state-of-the-art generative models, both with and without the RCG framework. The results demonstrate that RCG consistently improves the performance of various generative models, regardless of their specific architecture, on the challenging ImageNet 256x256 dataset. The improvement in FID indicates a substantial increase in the quality and fidelity of the generated images, while the improved IS suggests a greater diversity of generated samples.
This table presents a comparison of the unconditional image generation performance (measured by FID and IS) of several generative models (LDM-8, ADM, DiT-XL/2, and MAGE-L) both with and without the proposed RCG framework. The results demonstrate that RCG consistently enhances the quality of unconditional image generation across different models, significantly reducing the FID scores.

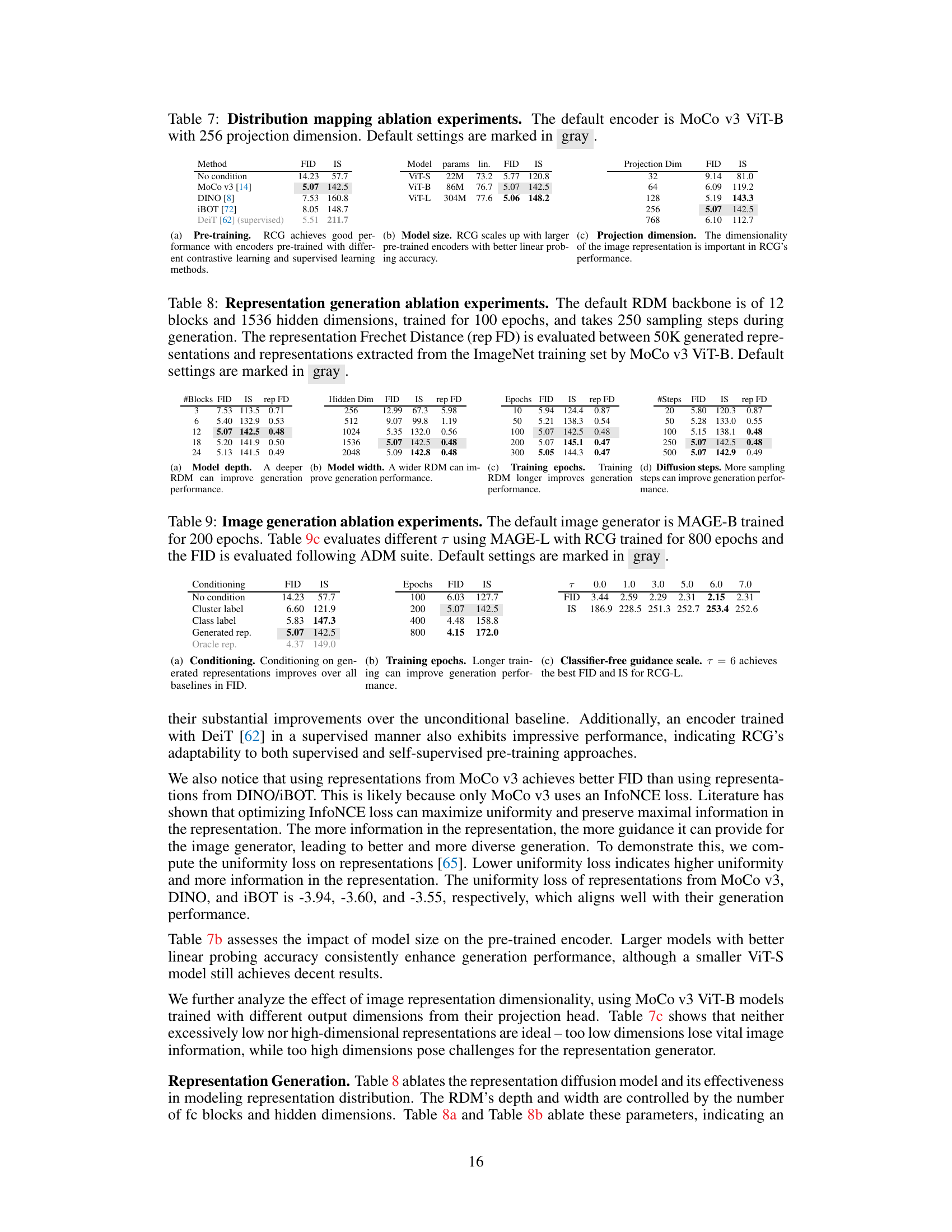
This table presents an ablation study on the image encoder component of the RCG framework. It compares the performance (FID and IS scores) of the RCG model using different pre-trained encoders: MoCo v3, DINO, iBOT, and a supervised DeiT model. The table also explores the impact of the projection dimension of the image representation on the model’s performance.

This table presents a comparison of the unconditional image generation performance (measured by FID and IS) of four different generative models (LDM-8, ADM, DiT-XL/2, and MAGE-L) with and without the proposed RCG framework. It demonstrates that RCG consistently improves the FID scores of all models, signifying a substantial enhancement in image generation quality. The improvement is substantial in all cases.

This table compares the FID and IS scores for unconditional image generation using four different image generator models (LDM-8, ADM, DiT-XL/2, and MAGE-L) with and without the RCG framework. The results demonstrate that RCG consistently improves the unconditional image generation quality regardless of the specific image generator used, significantly reducing the FID scores and increasing the IS scores. The numbers in parentheses show the amount of improvement by RCG.

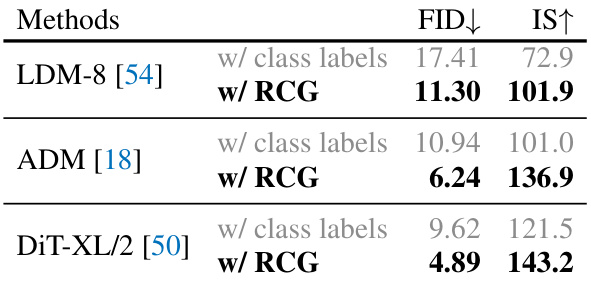
This table presents the FID scores achieved by different methods on CIFAR-10 and iNaturalist 2021 datasets. The baseline represents the FID of unconditional image generation using the respective original model. The ‘w/ RCG’ column shows the FID after applying the Representation-Conditioned Generation (RCG) method proposed in the paper. The ‘w/ class labels’ column indicates the FID obtained using the models with class labels as conditioning.
This table presents a comparison of the unconditional image generation performance (measured by FID and IS) of several generative models on ImageNet 256x256, both with and without the proposed Representation-Conditioned Generation (RCG) method. It demonstrates that RCG significantly improves FID scores across different image generators, indicating its effectiveness in enhancing unconditional image generation quality.

This table presents a comparison of the unconditional image generation performance (measured by FID and IS) of four different generative models (LDM-8, ADM, DiT-XL/2, and MAGE-L) with and without the proposed Representation-Conditioned Generation (RCG) framework. It demonstrates the substantial improvement in FID scores achieved by incorporating RCG across all four models, highlighting RCG’s effectiveness in enhancing unconditional image generation quality.
Full paper#