↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Autoregressive models for image generation traditionally flatten 2D images into 1D sequences, which leads to issues like ignoring spatial locality and hindering scalability. Diffusion models currently outperform these raster-scan AR approaches. This paper tackles these issues.
The proposed Visual Autoregressive Modeling (VAR) redefines autoregressive learning as a coarse-to-fine process, predicting ’next-scale’ token maps rather than individual tokens. This simple shift allows VAR to learn visual distributions faster and generalize better. On ImageNet 256x256, VAR significantly improves upon the AR baseline and surpasses Diffusion Transformers, demonstrating remarkable performance gains. Importantly, it exhibits scaling laws similar to LLMs, making it a promising direction for scalable and generalizable image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it demonstrates a novel autoregressive image generation method that surpasses existing diffusion models in key aspects. It introduces a paradigm shift and offers valuable insights for researchers aiming to improve image synthesis and achieve better scaling laws. This opens new avenues for research into more efficient and scalable visual generative models and has the potential to significantly impact various downstream visual tasks. It also provides solid evidence supporting similar scaling laws observed in LLMs, thereby bridging the gap between language and computer vision models.
Visual Insights#

This figure showcases image generation results from the Visual Autoregressive (VAR) model. The top row displays images generated at a resolution of 512x512 pixels. The middle row shows images generated at a lower resolution of 256x256 pixels. The bottom row demonstrates the model’s zero-shot image editing capabilities. The figure highlights the model’s ability to generate high-quality images across different resolutions and perform image editing tasks without explicit training.
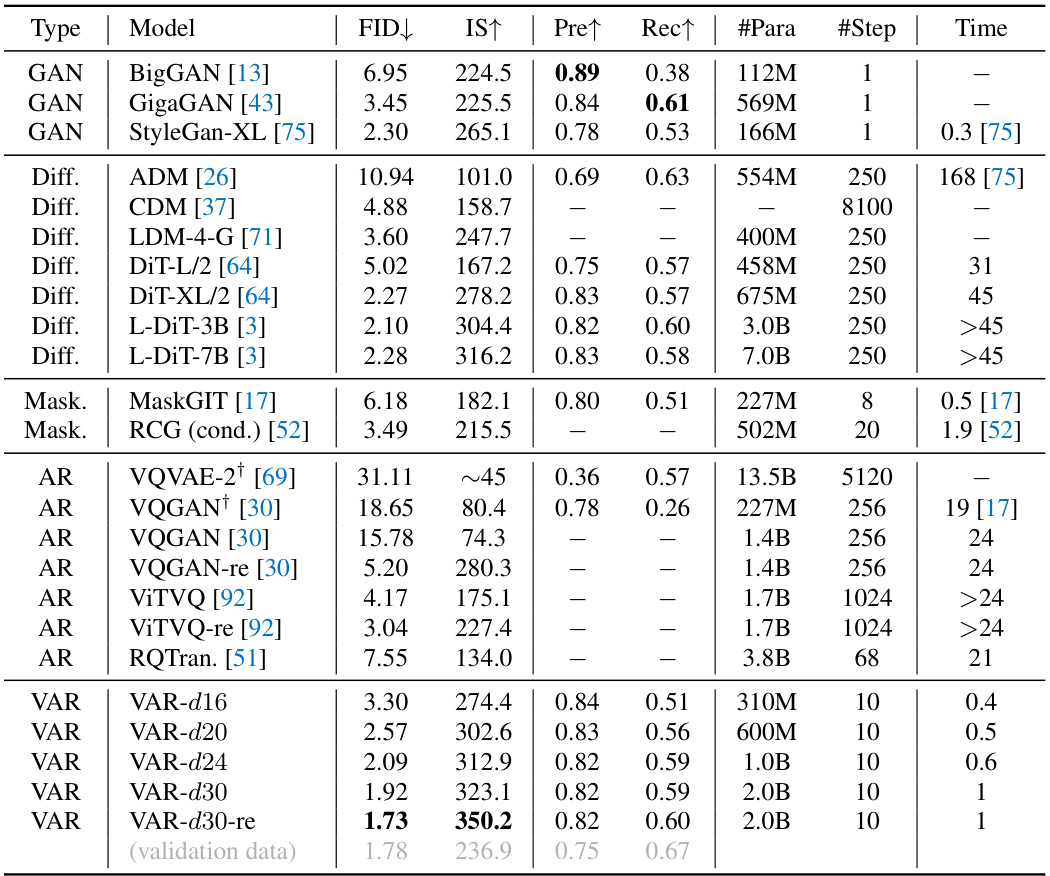
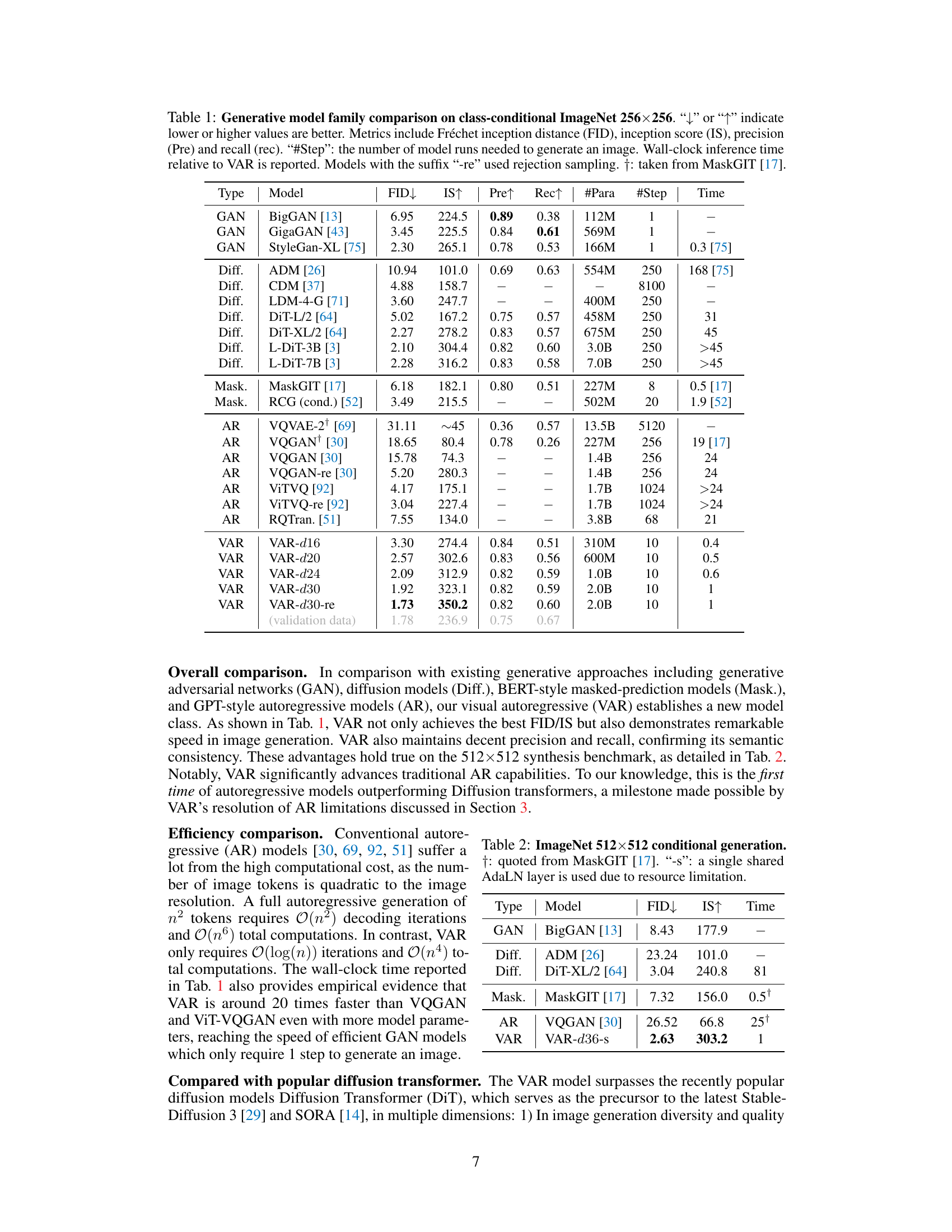
This table compares various image generation models on the ImageNet 256x256 benchmark. It presents key metrics including FID (Fréchet Inception Distance), IS (Inception Score), precision, and recall, along with the number of parameters, steps required for generation, and relative inference time compared to the VAR model. The table helps illustrate the performance and efficiency advantages of the VAR model compared to other state-of-the-art methods.
In-depth insights#
Visual AR Paradigm#
The proposed “Visual AR Paradigm” reimagines autoregressive image generation as a multi-scale, coarse-to-fine process, diverging from traditional raster-scan approaches. This shift is crucial because it addresses inherent limitations of existing methods, such as the violation of the unidirectional dependency assumption in standard AR models and the disruption of spatial locality due to image flattening. By predicting the next-scale token map instead of individual tokens, the paradigm preserves spatial coherence and facilitates parallel processing. This leads to significant improvements in efficiency and scalability, evidenced by the clear power-law scaling behavior observed in experiments. The superior performance of the Visual AR Paradigm, demonstrated through achieving state-of-the-art FID/IS scores while surpassing diffusion transformers in speed and data efficiency, showcases its potential to redefine how large-scale visual generation models are developed and deployed.
Next-Scale Prediction#
The concept of “Next-Scale Prediction” presents a novel approach to autoregressive image generation. Instead of the traditional raster-scan method processing images pixel by pixel, this method tackles image generation by predicting the next scale or resolution. This coarse-to-fine strategy mirrors human perception, starting with a rough outline and gradually refining details at higher resolutions. This paradigm shift offers several key advantages: Firstly, it leverages the inherent hierarchical structure of images, improving learning efficiency and generalization. Secondly, it facilitates parallel processing at each scale, leading to faster inference speeds compared to the sequential nature of next-token prediction. Finally, the reduced computational complexity associated with this approach makes scaling up the model to higher resolutions more feasible. This technique shows immense potential for surpassing traditional raster-scan based autoregressive models in terms of efficiency and scalability.
Scaling Laws in VAR#
The exploration of scaling laws in Visual Autoregressive (VAR) models reveals crucial insights into their scalability and performance. The observed power-law relationships between model size and metrics like test loss and token error rate are strong evidence of efficient scaling, mirroring trends seen in large language models (LLMs). This finding suggests that increasing VAR model size leads to consistent improvements, and offers guidance for resource allocation in model development. The near-linear correlations observed between computational resources and performance further indicate that VAR models exhibit the desirable property of efficient scaling, which is crucial for achieving enhanced visual generation capabilities. This analysis paves the way to predict the performance of larger models with improved resource allocation. These results significantly advance our understanding of the potential of autoregressive architectures for image generation.
Zero-Shot Abilities#
Zero-shot capabilities in AI models signify the ability to perform tasks or apply to domains unseen during training. This is a crucial benchmark of generalization, showcasing a model’s understanding beyond rote memorization. In the context of image generation, zero-shot capabilities would mean a model’s capacity to generate images of novel classes or perform image manipulation tasks (like inpainting or editing) without explicit training examples for those specific tasks. Successful zero-shot image generation relies on a strong representation learning process, where the model captures underlying concepts and relationships from its training data, enabling it to extrapolate to unseen scenarios. This is often assessed through evaluating performance on downstream tasks and evaluating various metrics such as FID (Fréchet Inception Distance) and Inception Score. The success of zero-shot abilities hinges on the quality of visual features extracted and the model’s capacity to utilize this information for flexible and nuanced generation. Limitations might include a drop in performance compared to fine-tuned models and difficulties in handling complex or highly specific requests.
Future of Visual AR#
The future of Visual Autoregressive (VAR) models is bright, promising significant advancements in image generation. Scaling laws, already observed in large language models, are likely to continue driving improvements in VAR, leading to even higher-resolution and higher-fidelity images with less computational cost. Zero-shot generalization will likely improve, allowing VAR models to tackle more downstream tasks effectively, such as image editing and in-painting, without requiring specific training. Multimodal integration is also a key area, with VAR potentially merging seamlessly with other modalities such as text and video, leading to more versatile and creative applications. However, challenges remain. Addressing the inherent limitations of autoregressive approaches such as computational cost and the need for unidirectional processing is crucial for achieving true scalability and efficiency. Furthermore, mitigating potential biases and ethical concerns inherent to any generative model, particularly ones trained on large datasets, is paramount for responsible deployment.
More visual insights#
More on figures
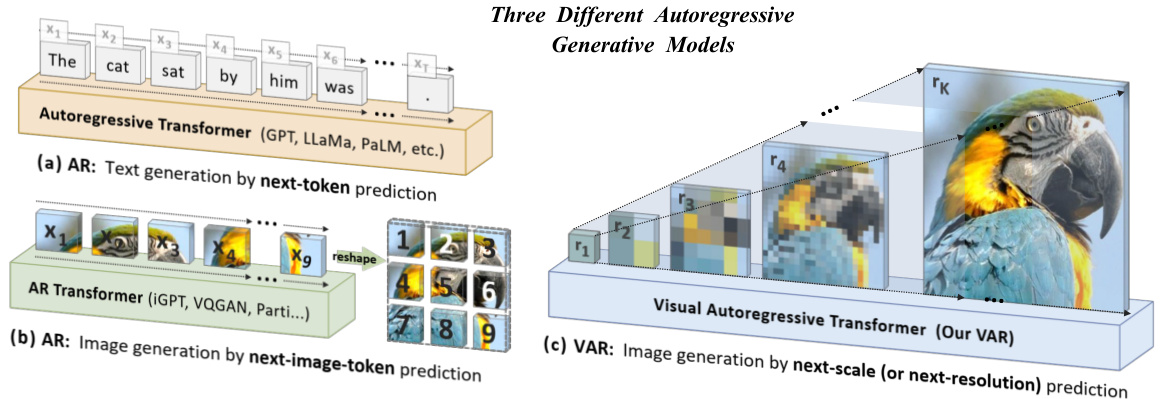
This figure compares three different autoregressive generative models: standard autoregressive text generation (next-token prediction), standard autoregressive image generation (next-image-token prediction), and the proposed visual autoregressive image generation (next-scale prediction). The figure illustrates how the input data is processed in each model and highlights the key differences, especially in how VAR leverages a multi-scale VQVAE for efficient and high-resolution image generation.
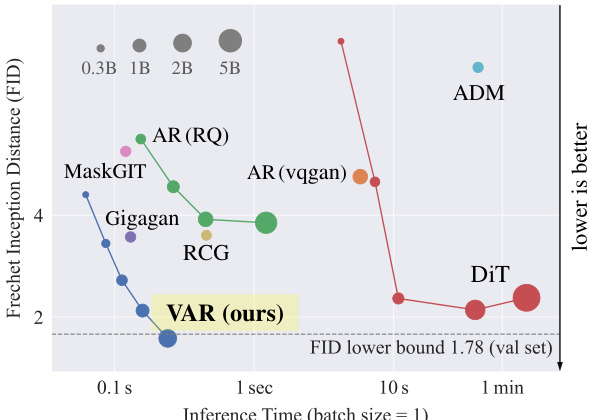
This figure compares different image generation models on the ImageNet 256x256 dataset using Fréchet Inception Distance (FID) as a metric for image quality. It demonstrates how VAR (Visual Autoregressive) model significantly outperforms other models, including various Autoregressive (AR) models and Diffusion Transformers (DiT). Specifically, the VAR model with 2 billion parameters achieves a FID of 1.73, which is substantially lower than other models, indicating superior image quality. The x-axis represents the inference time, showing that VAR is also more efficient.
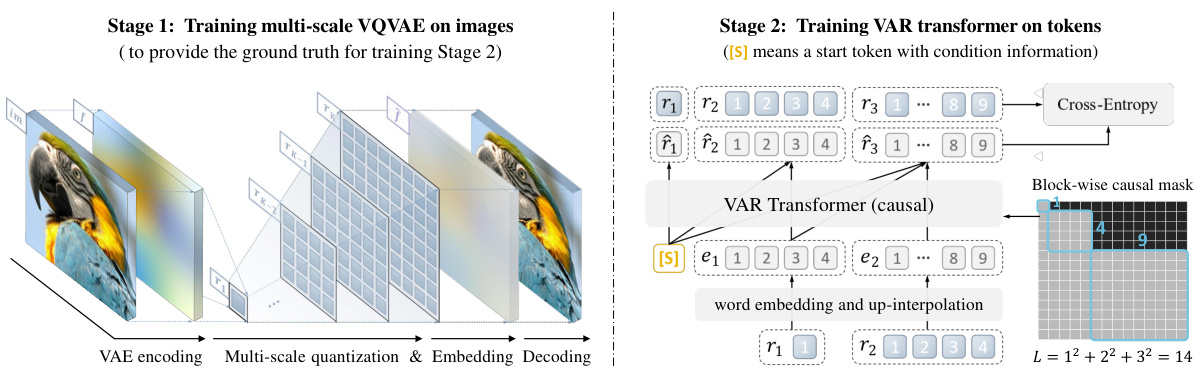
This figure illustrates the two-stage training process of the Visual Autoregressive (VAR) model. Stage 1 involves training a multi-scale VQ autoencoder to encode images into multiple token maps. Stage 2 trains a VAR transformer using a next-scale prediction approach, where the transformer predicts the next higher-resolution token map based on previous maps. The use of a causal attention mask is highlighted.

This figure visualizes the impact of scaling up both model size and training compute on the quality of images generated by the VAR model. It shows image samples generated by VAR models with different depths (6, 16, 26, 30) at various training stages (20%, 60%, 100% of total tokens). The improved visual fidelity and coherence demonstrate a clear positive correlation between model scale and image quality.
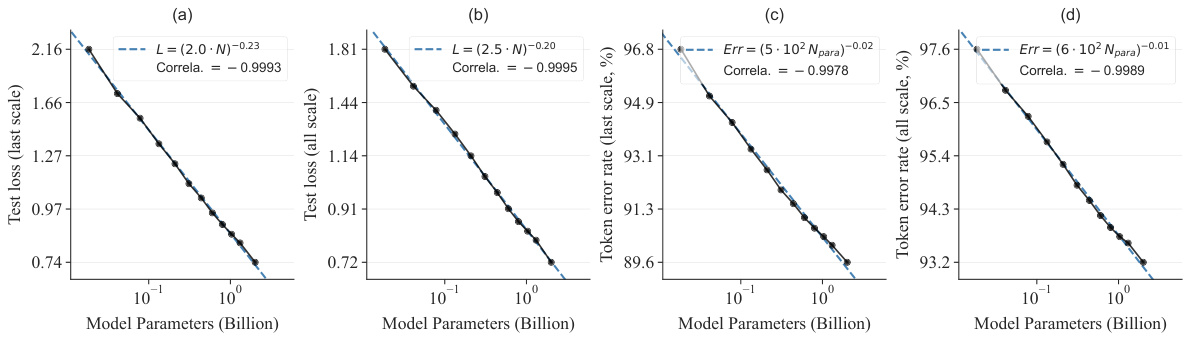
This figure shows the scaling laws observed when training VAR transformers of different sizes. The plots demonstrate a power-law relationship between the model’s size (number of parameters) and its performance metrics: test loss and token error rate. The near-perfect correlation coefficients highlight the strong linear relationship between the logarithm of the model size and the logarithm of the loss/error, validating the scalability of the VAR model.
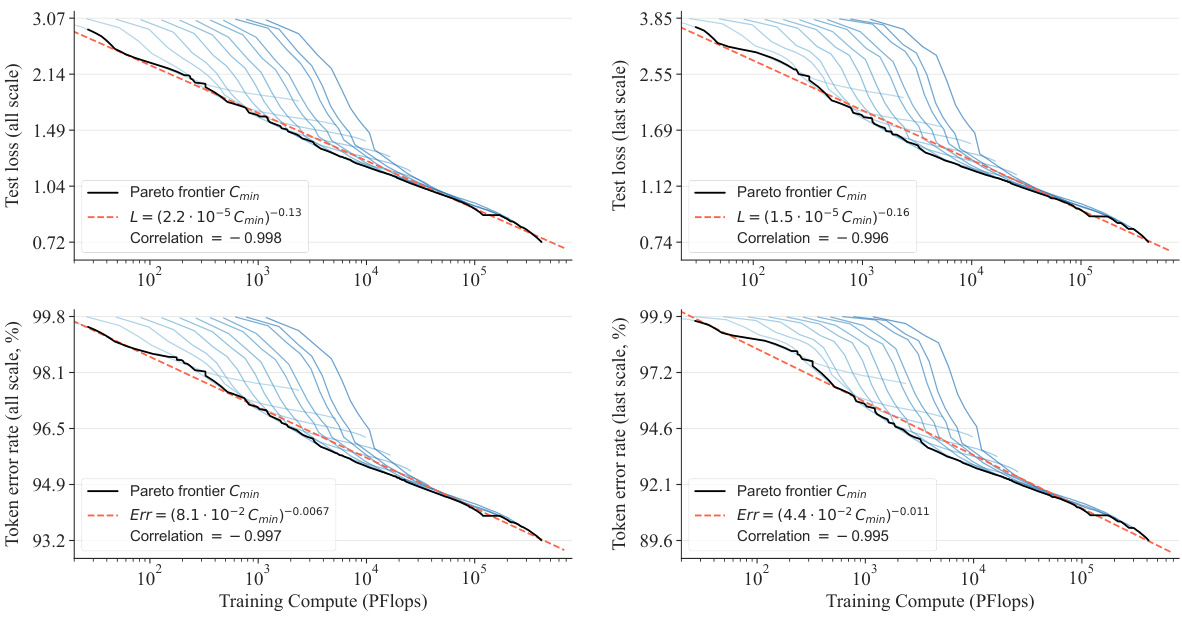
This figure shows the scaling laws observed when training compute (Cmin) is optimized. The plots demonstrate a strong power-law relationship between compute and both test loss (L) and token error rate (Err), regardless of whether the loss is calculated for all scales or just the final scale. The high correlation coefficients (near -0.99) confirm the strong linear relationship between logarithmic values of Cmin, L, and Err, providing strong evidence for the power-law scaling behavior of VAR models.

This figure visualizes the effect of scaling up the model size (N) and training compute (C) on the quality of images generated by the VAR model. It shows image samples generated by VAR models with different depths (16, 20, 24, 30) and training stages (20%, 60%, 100% of training tokens). The improved visual fidelity and detail in images from larger models and with more training demonstrate the scaling law behaviour of the model.
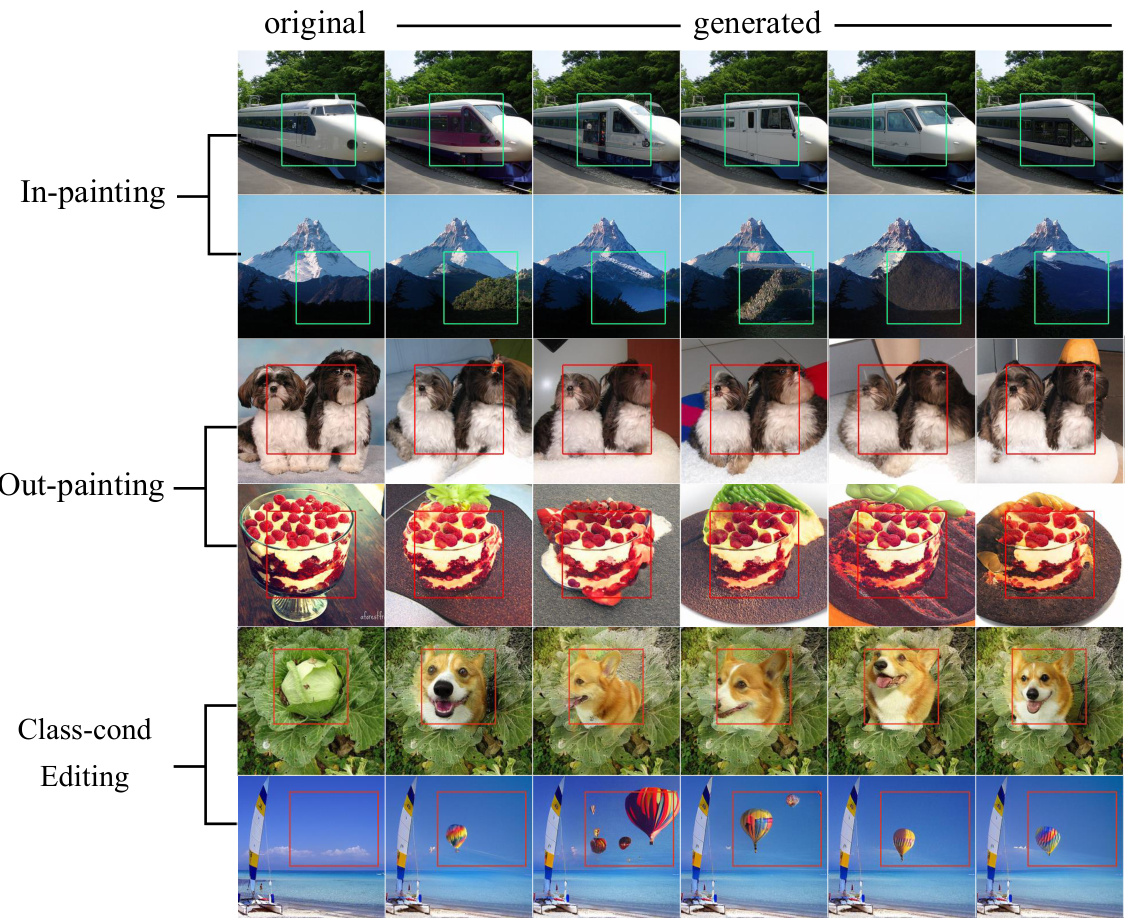
This figure shows the zero-shot generalization ability of the Visual Autoregressive (VAR) model on three downstream tasks: image in-painting, out-painting, and class-conditional image editing. In each task, the model is given an image with masked or specified regions, and it successfully generates realistic and coherent results without any further training or fine-tuning. This demonstrates that the VAR model learns a generalizable representation of images that can be applied to various tasks.
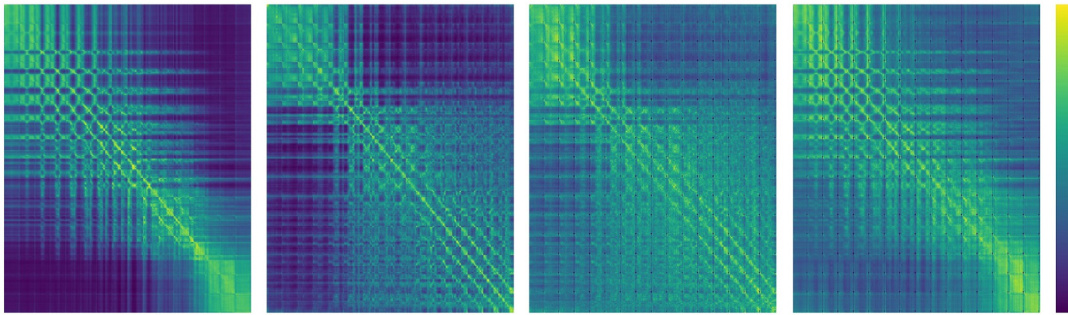
This figure visualizes the attention scores in the last self-attention layer of the VQGAN encoder. The heatmaps show how strongly each token attends to other tokens in four randomly selected 256x256 images from ImageNet’s validation set. This helps illustrate the level of token dependency in the VQGAN model.

This figure compares image generation results from four different models: BigGAN, VQVAE-2, MaskGIT, and VAR (the authors’ model). Each model generated images of Bald Eagles, Jellyfish, and Ducks. The comparison highlights the superior quality and detail of the images generated by the VAR model.

This figure shows a collection of 256x256 images generated using the Visual Autoregressive (VAR) model, trained on the ImageNet dataset. The images depict a wide variety of subjects and scenes, demonstrating the model’s ability to generate diverse and visually appealing images. The caption also indicates that higher resolution (512x512) samples are available in supplementary material.
More on tables
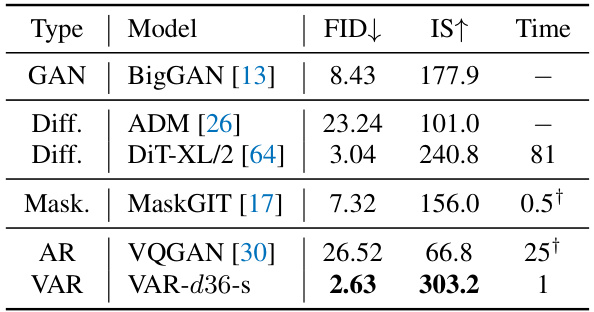
This table compares the performance of various image generation models on the ImageNet 512x512 dataset. The metrics used are Fréchet Inception Distance (FID), Inception Score (IS), and inference time. The table highlights the superior performance of the VAR model compared to other methods, including GANs, diffusion models, masked prediction models, and traditional autoregressive (AR) models. The ‘-s’ notation indicates a resource-constrained setting for a particular model variant.
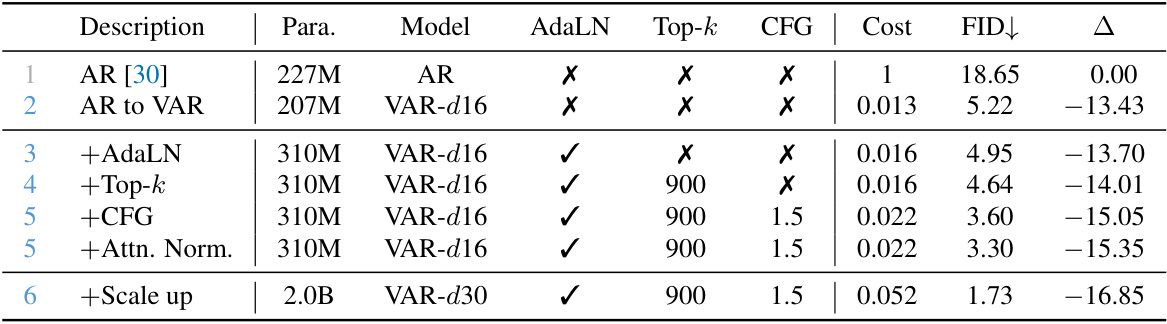
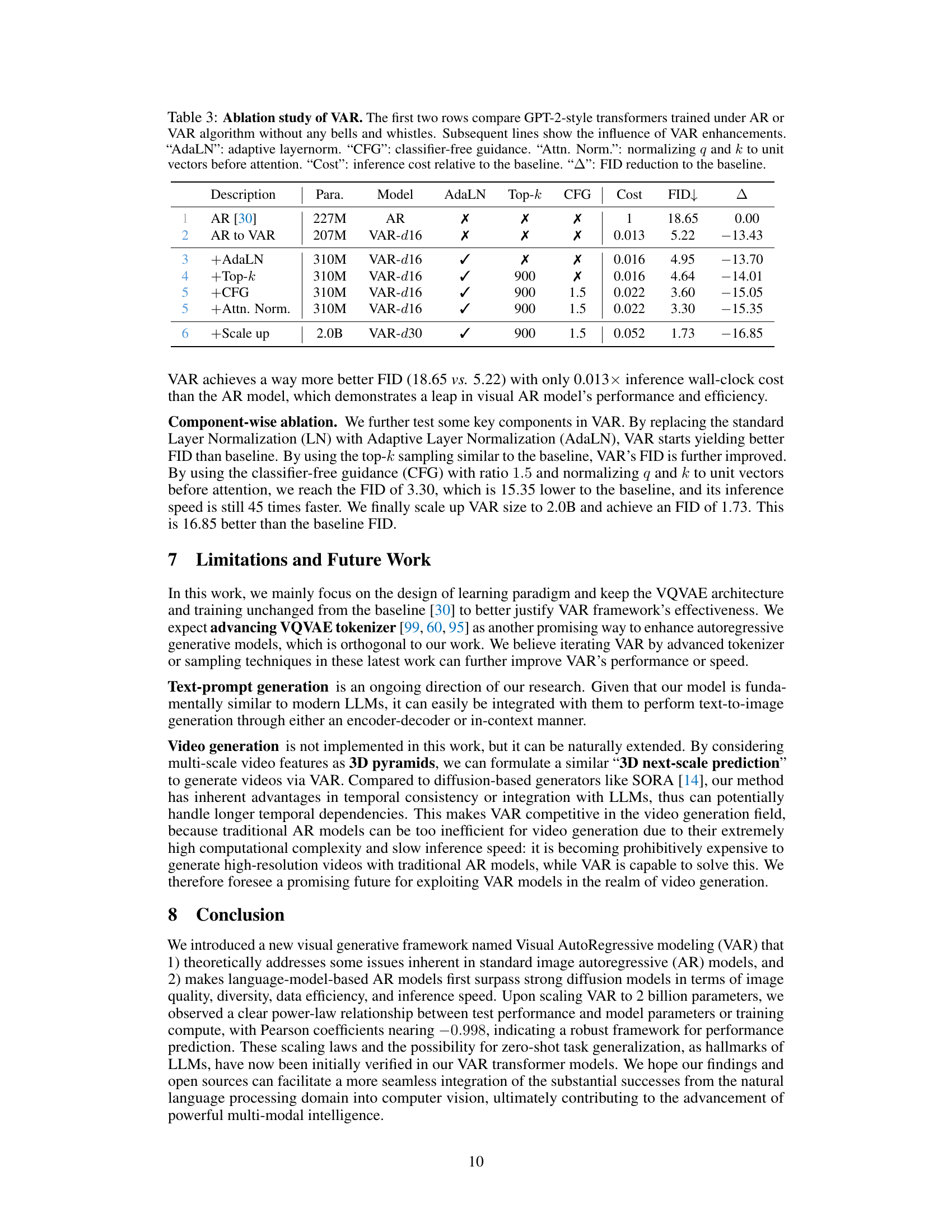
This table presents an ablation study of the VAR model, comparing its performance against a baseline AR model and exploring the effects of various components (AdaLN, Top-k sampling, CFG, Attention Normalization) and scaling up the model size. It quantitatively shows the improvement in FID (Fréchet Inception Distance) achieved by each addition or modification and the associated increase in computational cost.
Full paper#