↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
High-quality image generation using diffusion models is computationally expensive due to their iterative sampling process. Existing distillation methods aim to create efficient one-step generators but often compromise on quality or require expensive data preprocessing. This paper introduces DMD2, a new method that tackles these challenges.
DMD2 improves upon existing approaches by removing the computationally intensive regression loss and incorporates a GAN loss to improve image quality. It also introduces a novel training technique to effectively address the input mismatch issue that exists in multi-step generative models. Through these improvements, DMD2 surpasses its teacher model in performance, establishing new benchmarks in both one-step and multi-step image generation, making it a significant advance in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation and deep learning. It significantly advances fast image synthesis techniques, offering a more efficient and scalable alternative to computationally expensive diffusion models. The improved methodology opens exciting new research avenues in efficient model training and high-quality image generation, impacting various applications.
Visual Insights#

This figure showcases the high-quality images generated by a 4-step generator that was created using the DMD2 method. The generator was trained by distilling a larger, more complex model (SDXL). The images are 1024x1024 pixels in resolution. The caption encourages viewers to zoom in to appreciate the fine details of the generated images, demonstrating the high fidelity achieved by the DMD2 technique.
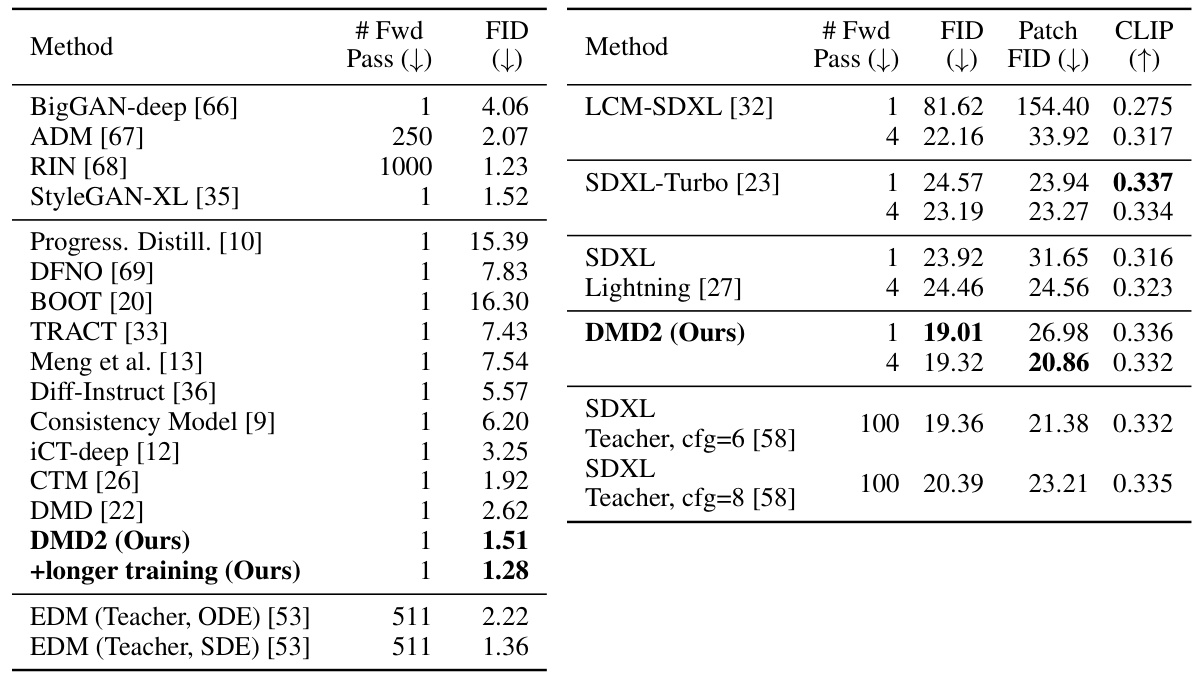
This table compares the FID scores achieved by various image generation methods on the ImageNet-64x64 dataset. It shows the number of forward passes required by each method, and contrasts the performance of the proposed method (DMD2) against several state-of-the-art baselines and the original teacher model. The table highlights DMD2’s superior performance, surpassing even the teacher model in terms of FID score, particularly with longer training.
In-depth insights#
DMD2: Refined Distillation#
The hypothetical heading “DMD2: Refined Distillation” suggests an improved version of Distribution Matching Distillation (DMD), focusing on enhancing the distillation process for generating high-quality images. This likely involves addressing limitations of the original DMD, such as reliance on computationally expensive regression loss and inability to surpass the teacher model’s performance. DMD2 might introduce novel techniques to overcome these hurdles, potentially through alternative loss functions, more efficient training strategies, or incorporation of GAN-based approaches. The refinement could also involve enabling multi-step generation in the student model, improving training stability, and increasing overall efficiency while maintaining or surpassing the visual fidelity of the original model. Key innovations within DMD2 would likely center around leveraging the advantages of distribution matching while mitigating its shortcomings to achieve state-of-the-art results in image synthesis.
GAN Loss Integration#
Integrating GAN loss into a diffusion model distillation framework offers a compelling approach to enhance the quality and stability of the distilled model. By adding a discriminator that distinguishes between real images and those generated by the student model, the training process receives additional supervisory signals, pushing the student beyond simply mimicking the teacher’s sampling trajectory. This approach is particularly valuable when aiming to surpass the teacher’s performance, which is a primary goal of many distillation methods. However, careful consideration must be given to the interaction between the GAN loss and the distribution matching objective already present in the distillation process. An improperly balanced approach could lead to instability or suboptimal performance. The success of this strategy hinges on achieving a good balance between the two loss functions, potentially requiring meticulous hyperparameter tuning and potentially a two-time scale update rule to prevent the discriminator from over-powering the generator. Successfully integrating GAN loss could address inherent limitations in solely using distribution matching, and unlock significantly improved visual quality and performance in the distilled diffusion models. Furthermore, the addition of the GAN loss can help mitigate approximation errors in the teacher’s score function estimation.
Multi-Step Sampling#
Multi-step sampling methods in diffusion models offer a compelling approach to balancing the speed of one-step generation with the superior quality of models using many sampling steps. The core challenge lies in bridging the training and inference gap. Standard training involves denoising from real, noisy images, while inference begins from pure noise. This mismatch can significantly degrade the quality of generated images. To address this, methods that simulate inference-time conditions during training are crucial; using backward simulation to generate synthetic noisy images for training aligns the training and inference processes, greatly improving overall results. This addresses the crucial issue of input mismatch that plagues many multi-step techniques. While multi-step sampling enhances visual quality and fidelity compared to one-step methods, careful consideration of computational cost and training stability is required. The tradeoff between sampling efficiency and image quality is a significant factor in model selection and application.
Ablation Study Results#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, an ‘Ablation Study Results’ section would detail the impact of removing specific elements, such as different loss functions, regularization techniques, or model architectures, on the overall performance. A well-conducted ablation study should reveal which components are crucial for achieving optimal results and which are less important or even detrimental. The results would typically be presented quantitatively, using metrics such as FID or Inception scores, comparing the full model’s performance to those of the variants with components removed. Careful analysis of these results helps to identify the key factors responsible for the model’s success or failure, providing valuable insights into the model’s design and underlying mechanisms. Furthermore, a thorough ablation study can highlight potential areas for future improvement, indicating where resources might be best allocated to further enhance the model’s capabilities.
Future Research#
Future research directions stemming from this work could explore several avenues. Improving the training stability of distribution matching distillation without relying on regression losses remains crucial, especially for very large models. Investigating alternative loss functions or training techniques that address the inherent instabilities could yield significant improvements. Addressing the trade-off between sample quality and diversity is another key area. While the current method achieves high-quality results, exploring methods that enhance diversity without sacrificing quality would be valuable. Finally, extending the approach to other generative models beyond diffusion models and exploring its application in other generation tasks such as video and 3D model synthesis would broaden the impact and provide further insights into the effectiveness of distribution matching distillation.
More visual insights#
More on figures

This figure showcases the high-quality 1024x1024 images generated by a 4-step generator, trained using the DMD2 method. The images demonstrate the model’s ability to produce diverse and detailed outputs, showcasing its ability to capture various artistic styles and subject matter. The caption encourages viewers to zoom in to appreciate the fine details within each image.
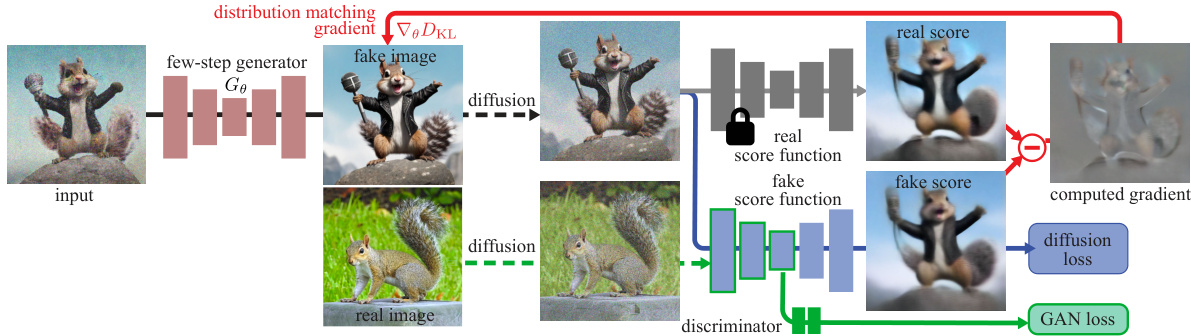
This figure illustrates the DMD2 method, which improves upon the original DMD method. The core idea is to train a more efficient generator (the student) to mimic the output distribution of a more computationally expensive diffusion model (the teacher). This is done in two steps: (1) training the generator using a combination of distribution matching and GAN losses; and (2) training a score function and GAN discriminator to improve the estimation of the generated sample distribution and enhance the overall training stability.

This figure illustrates the problem of training-inference mismatch in multi-step diffusion models and proposes a solution. The left side shows the traditional approach where the training uses forward diffusion, resulting in a domain gap between training and inference. The right side shows the proposed solution using backward simulation during training which aligns the training and inference inputs, thereby reducing the domain gap and improving performance.
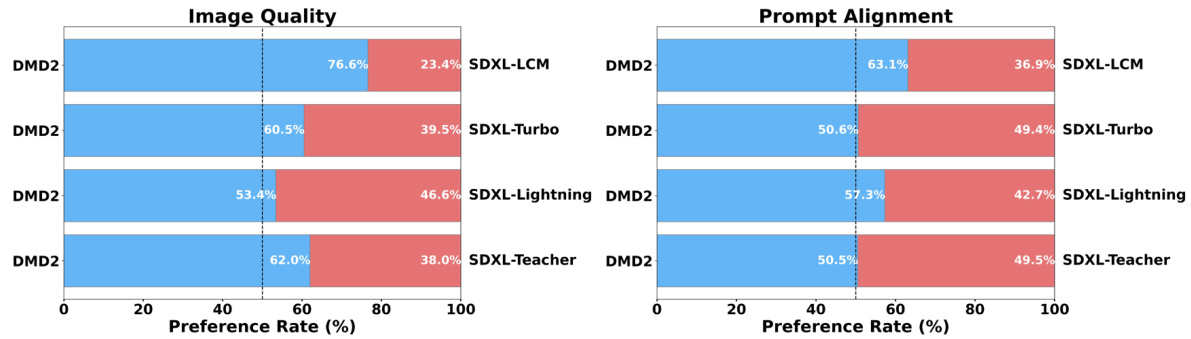
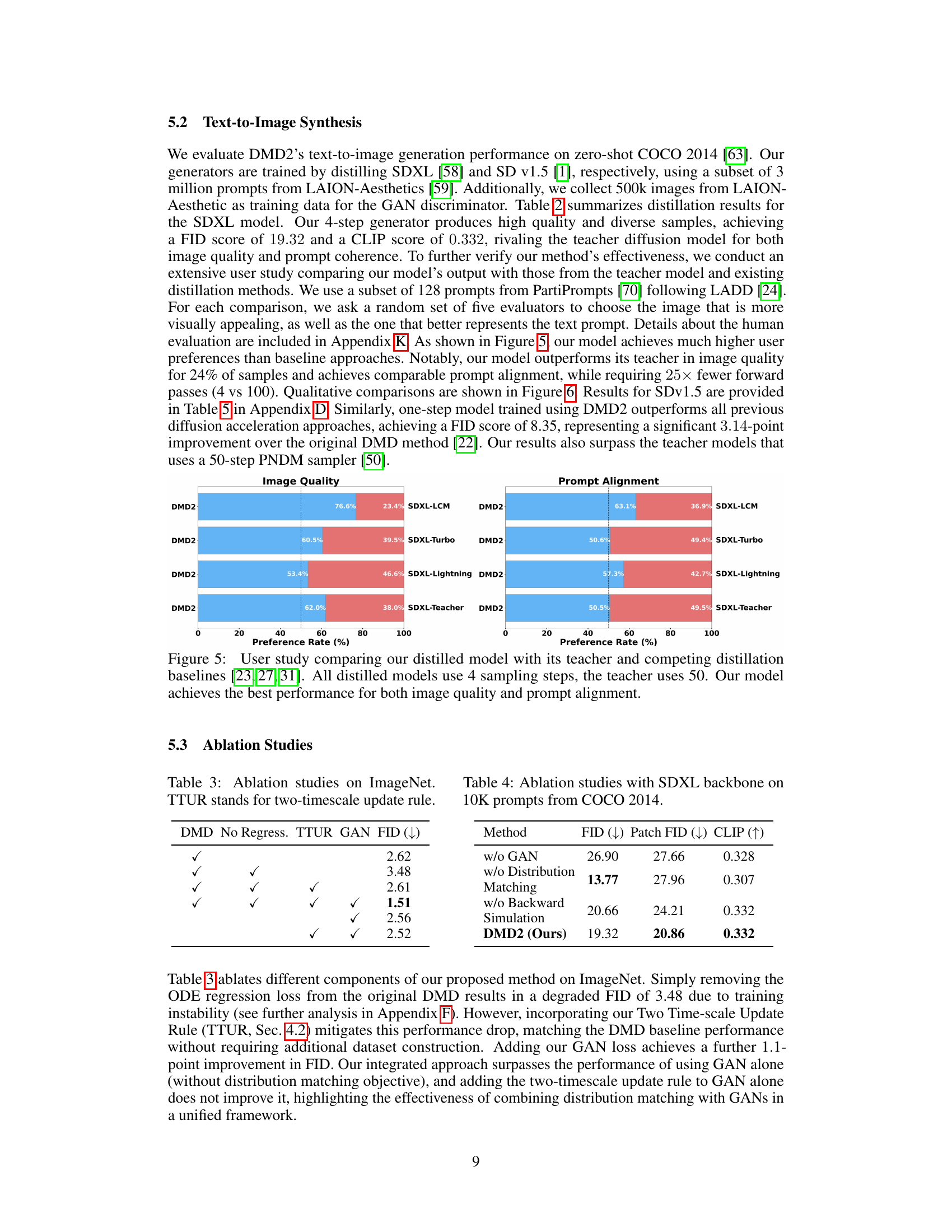
This figure presents the results of a user study comparing the image quality and prompt alignment of the proposed DMD2 model against several competing distillation methods and the original teacher model. The study reveals that DMD2 achieves superior performance compared to all the alternatives across both metrics, even though it uses fewer sampling steps than the original teacher model.

This figure compares images generated by the proposed method (DMD2), three other state-of-the-art diffusion models, and the teacher model (SDXL). All models used the same text prompts and noise inputs. The comparison highlights the superior realism and text alignment of DMD2, even though it uses only 4 sampling steps compared to the teacher model’s 50.

This figure shows an ablation study on the SDXL model, comparing the impact of removing different components of the proposed DMD2 method (distribution matching, GAN loss, and backward simulation). Each set of images was generated using the same noise and text prompts. The results visually demonstrate that each of these components is crucial for maintaining high-quality image generation with good aesthetic qualities and proper alignment to the given text prompts.

This figure showcases the high-quality images generated by a 4-step generator trained using the proposed DMD2 method. The generator is distilled from the state-of-the-art SDXL diffusion model, demonstrating significant efficiency gains while maintaining exceptional visual quality. The caption encourages viewers to zoom in to appreciate the detail in the generated images.

This figure compares image generation results from the authors’ model (DMD2), competing methods, and the teacher model (SDXL). All models were given the same prompts and noise, but the authors’ model used only 4 sampling steps while the teacher model used 50 steps, demonstrating significant efficiency gains. The image quality and text alignment of the DMD2 model are highlighted as superior.

This figure compares image generation results from four different methods: the authors’ proposed DMD2 model, three other state-of-the-art competing methods, and the original SDXL teacher model. All models were prompted with the same text and noise input. The images demonstrate that the proposed DMD2 model produces images of superior quality and better alignment with the text prompt.

This figure shows the ablation study results for SDXL model. Four images are generated with the same prompt using four different training methods. The first one is the full DMD2 model, and the other three omit one component of the DMD2: distribution matching, GAN, and backward simulation. By comparing the images, one can observe that each component contributes to the image quality, demonstrating the effectiveness of the full DMD2 method.
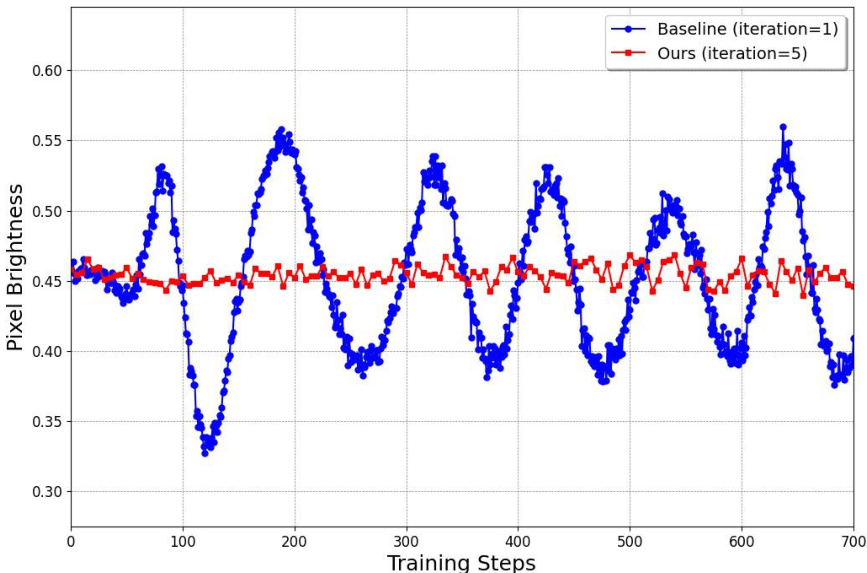
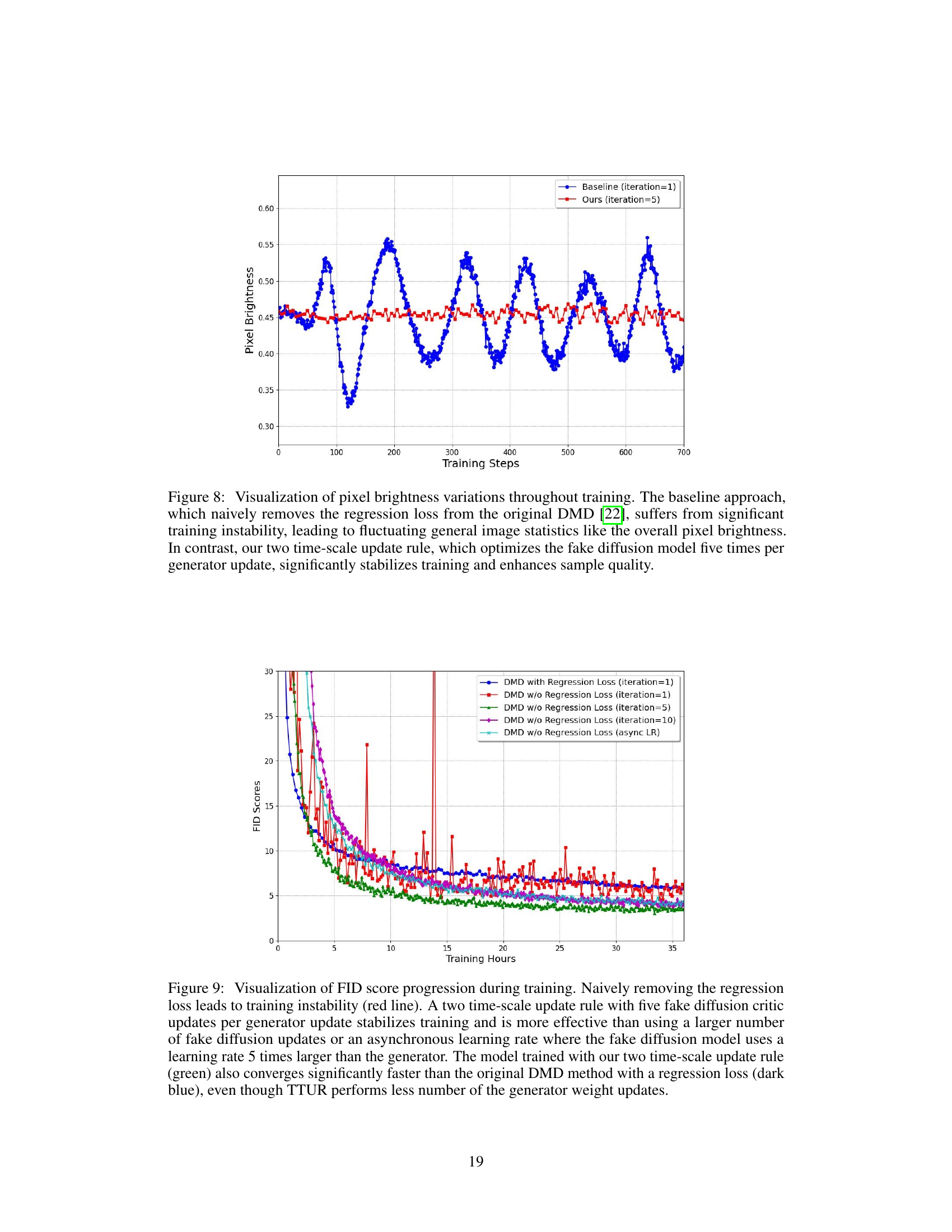
The figure shows the pixel brightness variation during the training process. The baseline method (without the regression loss) shows significant instability, while the proposed method (with a two timescales update rule) displays stable and enhanced training.
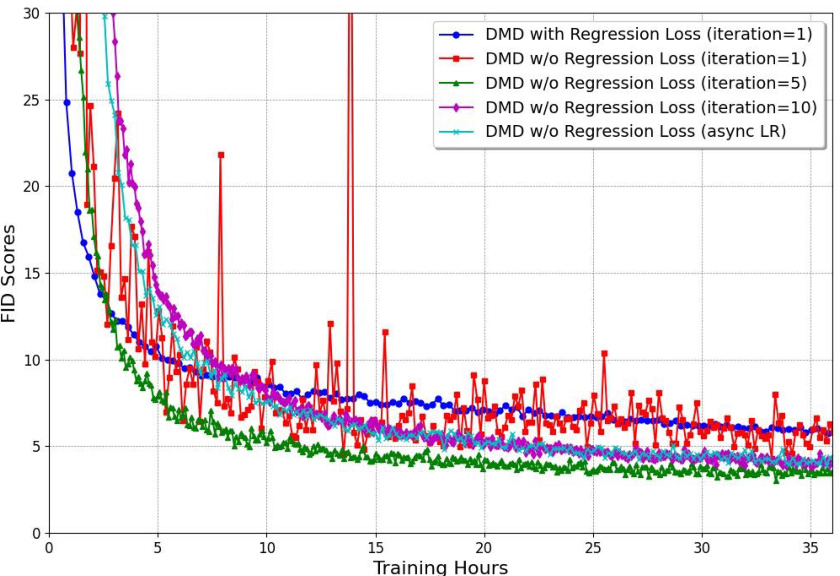
This figure shows the FID score (a metric measuring the quality of generated images) over training time for different training strategies. The baseline (red) shows instability when the regression loss is removed, while the proposed two timescales update rule (green) is more stable and converges faster. It also shows the benefit of the two timescales approach over other strategies, even if those other strategies might use more updates. The y-axis represents FID score. The x-axis represents training time (in hours).

This figure compares images generated by the proposed DMD2 model, several other methods, and the teacher SDXL model for various prompts. The key takeaway is that DMD2 produces images of comparable or higher quality to the teacher model with significantly fewer sampling steps, showcasing its effectiveness in distillation.

This figure shows a grid of 12 diverse 1024x1024 images generated by a single-step generator trained using the DMD2 method. The images demonstrate the model’s ability to generate high-resolution images with a wide range of styles, subject matters, and artistic techniques. The caption encourages viewers to zoom in to better appreciate the detail in each image. The variety showcased suggests successful distillation of a complex teacher model into a significantly faster, single-step generator.

This figure displays a collection of 1024x1024 images generated by a 4-step generator, which is a model trained using a novel distillation technique. The images are diverse and showcase a wide range of subjects, demonstrating the quality and capabilities of the generator.
This figure illustrates the DMD2 method, showing how a costly diffusion model is distilled into a more efficient one- or multi-step generator. The training process involves two alternating steps: optimizing the generator with a distribution matching objective and a GAN loss, and training a score function and GAN discriminator to improve the quality and stability of the generated images. The generator can be either a one-step or a multi-step model.
More on tables
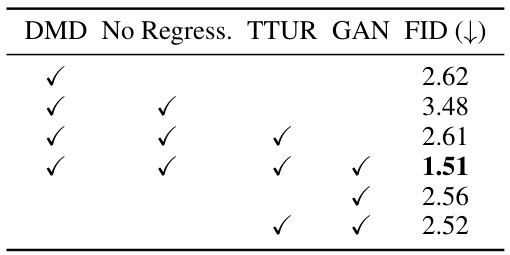
This table presents the results of ablation studies conducted on the ImageNet dataset to evaluate the impact of different components of the proposed DMD2 method. It shows the FID scores achieved by models trained with and without specific components such as the regression loss, the two-timescale update rule (TTUR), and the GAN loss. The table helps to understand the individual contributions of each component in improving the overall performance of the model.
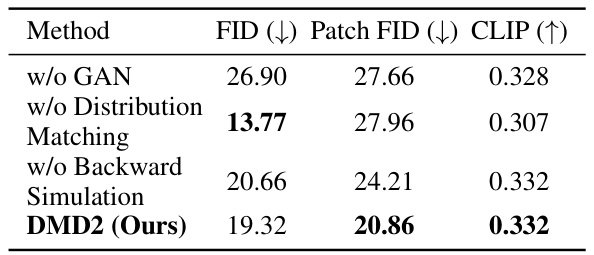
This table presents the ablation study results using the SDXL backbone on 10K prompts from the COCO 2014 dataset. It shows the impact of removing different components of the proposed DMD2 method on the FID, Patch FID, and CLIP scores. By comparing the performance of models with and without specific components (GAN, distribution matching, backward simulation), this table illustrates the contribution of each component to the overall performance of the DMD2 model.
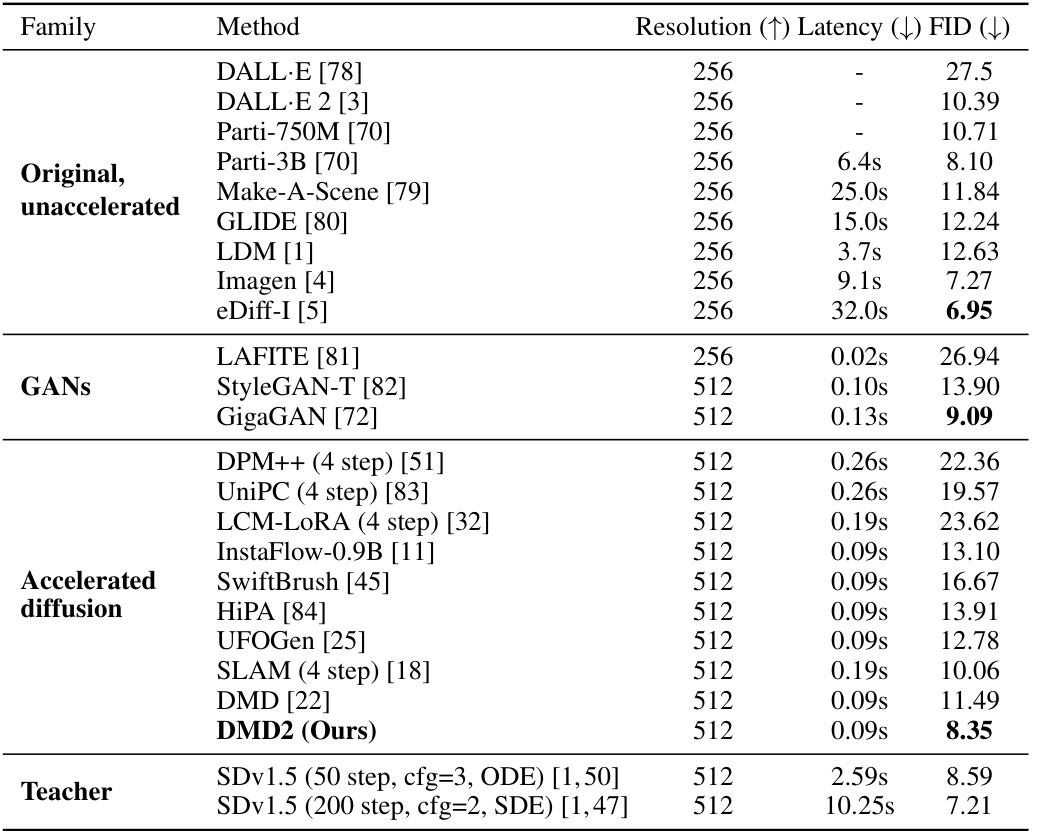
This table compares the image quality of various text-to-image generation methods on 30K prompts from the COCO 2014 dataset. The comparison includes original, unaccelerated methods; GAN-based methods; accelerated diffusion methods; and the teacher model. Metrics include resolution, latency, and FID score. The table is organized by family of methods for easier comparison and analysis.
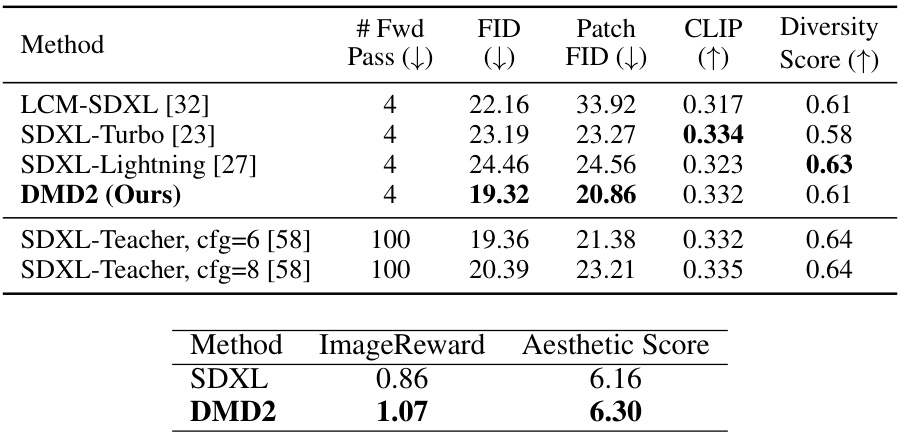
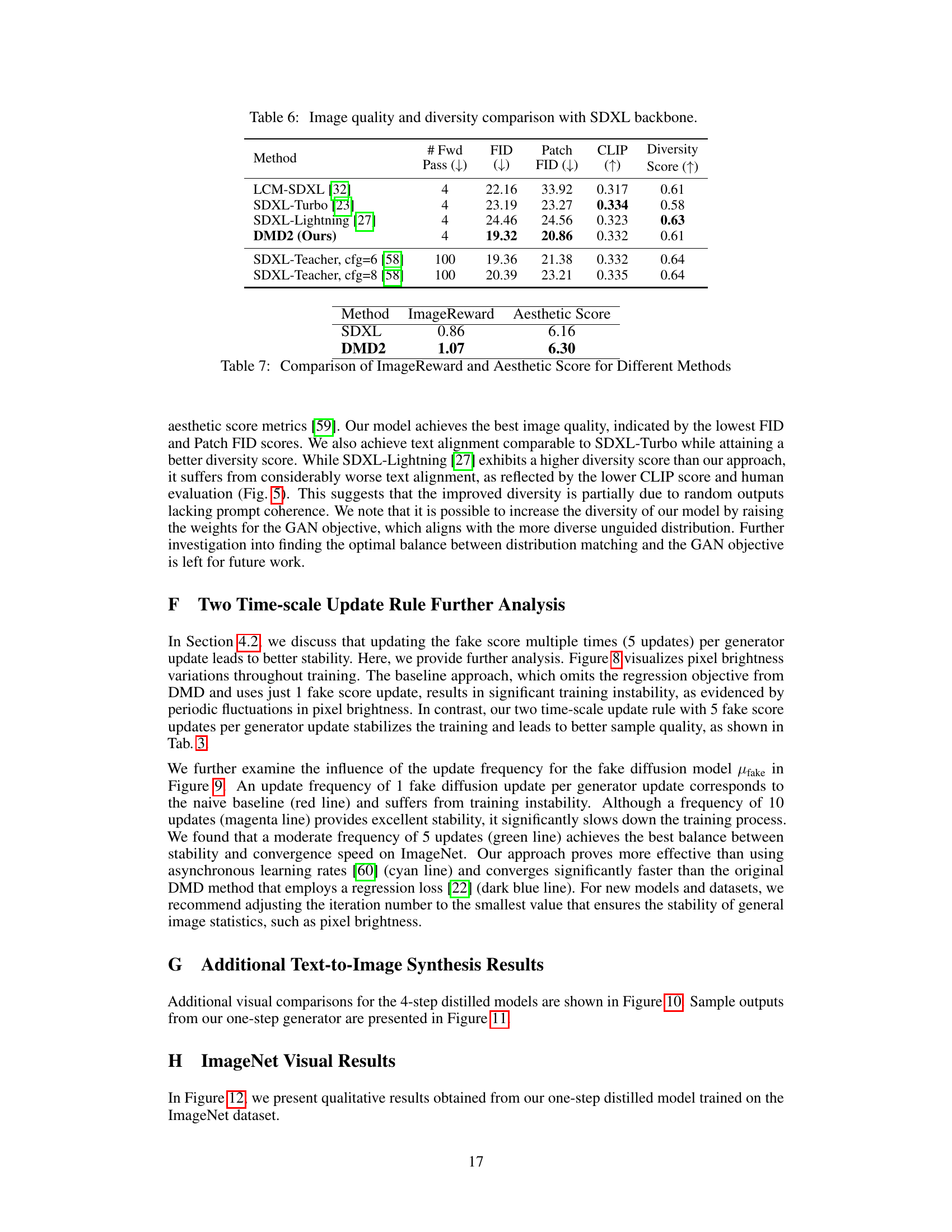
This table compares the image quality and diversity of different models, including the proposed DMD2 model and several baseline models, using SDXL as the backbone. The metrics used for comparison are FID (Fréchet Inception Distance), Patch FID, CLIP score, and diversity score. The FID and Patch FID scores measure the visual quality of the generated images, while the CLIP score and diversity score assess how well the generated images align with the text prompts and how diverse they are, respectively. Lower FID and Patch FID scores indicate better image quality, higher CLIP scores represent better text alignment, and higher diversity scores suggest greater variety in the generated images.
Full paper#