↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Large language models (LLMs) are typically trained using a next-token prediction loss on all training tokens. However, this approach may be inefficient and suboptimal. Some tokens may not contribute meaningfully to the training process, wasting computational resources and potentially hindering performance. This paper argues that a more selective approach to pretraining can improve both efficiency and results.
This paper proposes a new method called Selective Language Modeling (SLM) which uses a reference model to select tokens for training. This results in significant improvements in data efficiency and performance. Specifically, they introduce a new model called RHO-1 that uses SLM. RHO-1 demonstrates substantial improvements in few-shot and fine-tuned accuracy on various benchmarks, using just 3% of the tokens used by comparable models while being 5-10x faster. This research highlights the potential of data optimization techniques for improving LLM training and performance.
Key Takeaways#
Why does it matter?#
This paper challenges the conventional wisdom in language model pretraining by demonstrating that not all tokens are created equal. Its findings on data efficiency and improved model performance have significant implications for the field, offering new avenues for research in resource-optimized and more effective language model training.
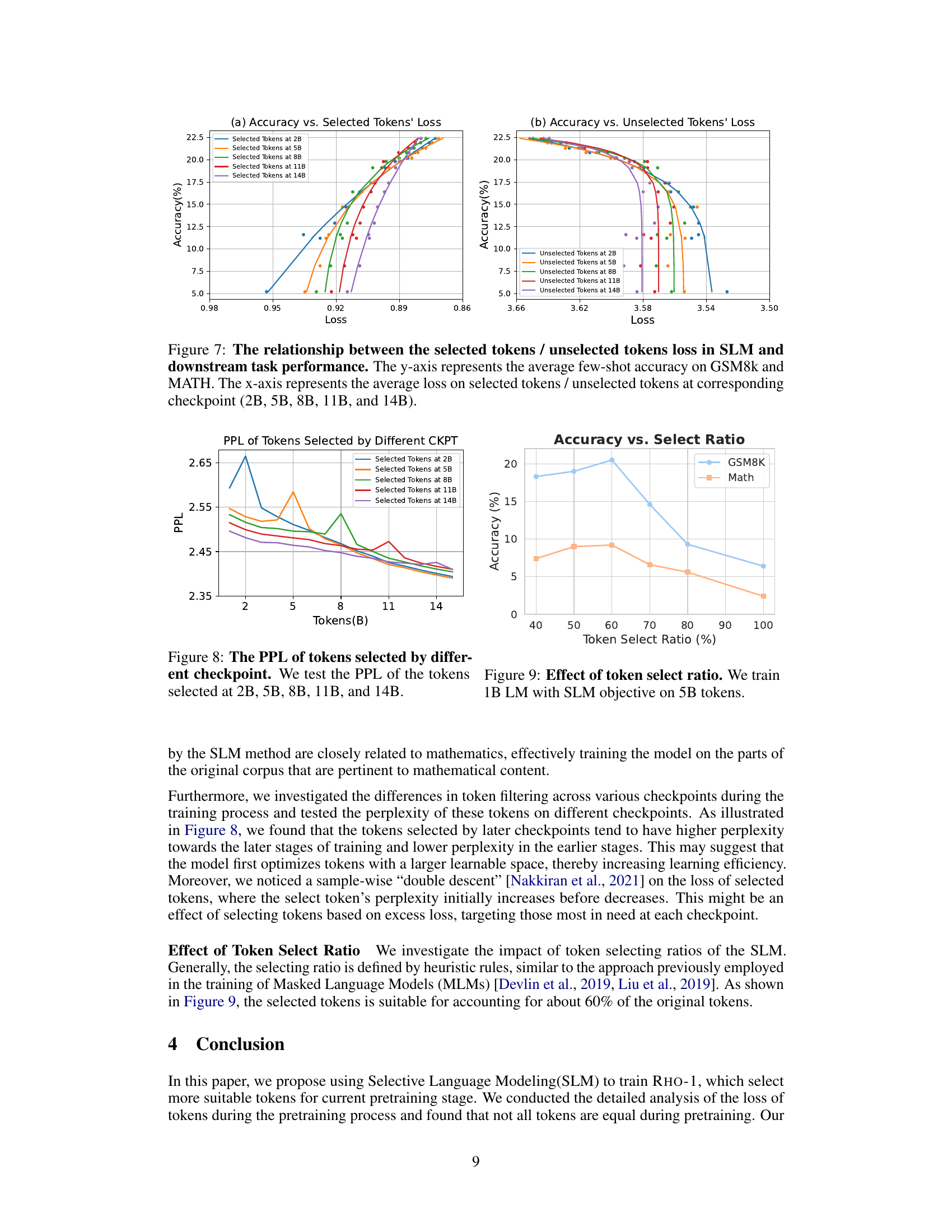
Visual Insights#
This figure compares the performance of the proposed RHO-1 language model with baseline models on two different sizes of language models (1B and 7B parameters). The models were continually pre-trained on 15 billion OpenWebMath tokens. The left panel shows the results for 1B parameter models, and the right panel shows results for 7B parameter models. The x-axis represents the number of tokens (in billions) used for pre-training. The y-axis represents the average few-shot accuracy across several mathematical reasoning benchmarks (GSM8k and MATH). The results show that RHO-1, which uses Selective Language Modeling (SLM), significantly outperforms the baseline models in terms of both accuracy and training speed. For instance, RHO-1 achieves a similar level of accuracy to the DeepSeekMath baseline but with 5 to 10 times fewer tokens.
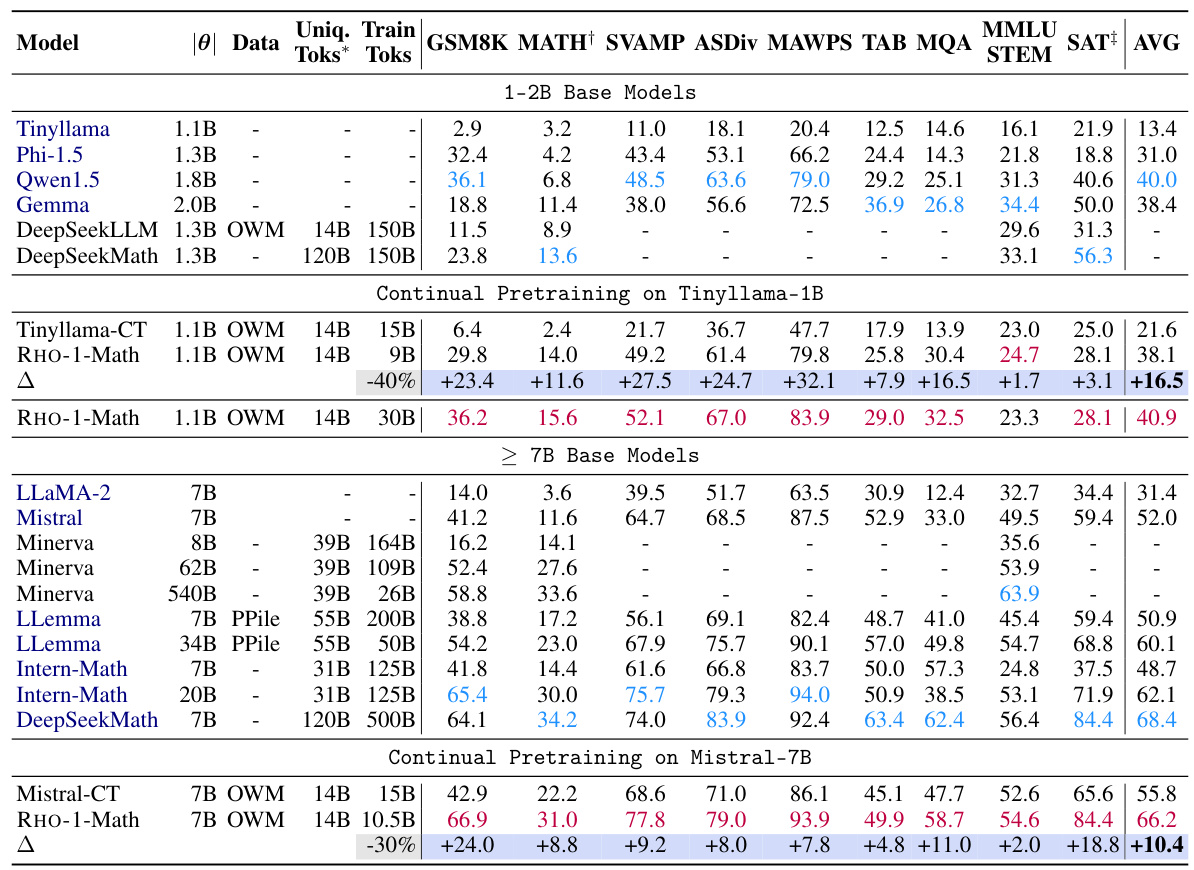
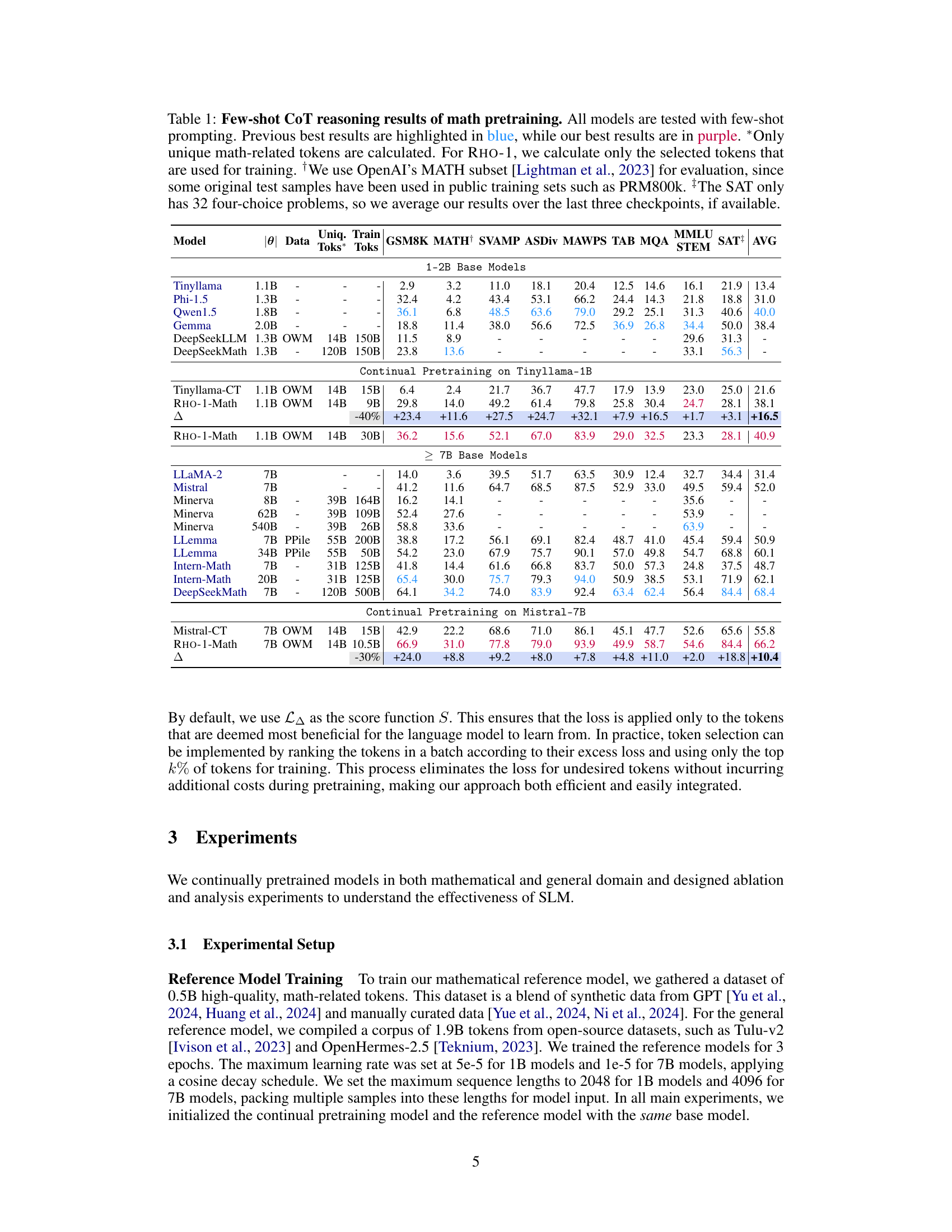
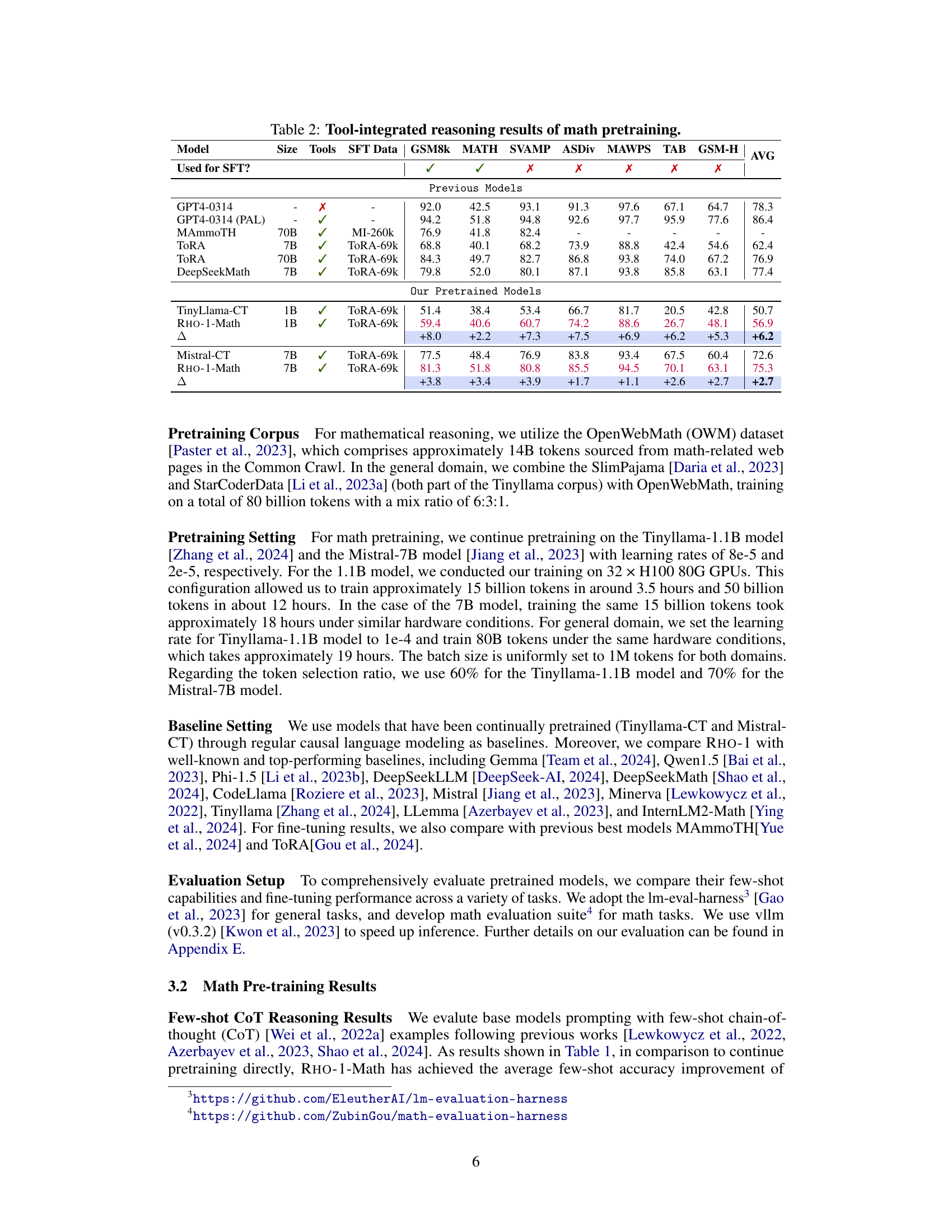
This table presents the few-shot chain-of-thought (CoT) reasoning results on mathematical problems for various language models. It compares the performance of different models, including baselines and the proposed RHO-1 model, across several benchmark datasets. Results are shown for both smaller (1-2B parameters) and larger (>7B parameters) models. The table highlights the improvements achieved by RHO-1 in few-shot settings, particularly the significant gains in accuracy compared to baselines, while using a considerably smaller number of training tokens.
In-depth insights#
Token-Level Training#
Token-level training dynamics offer crucial insights into the language model learning process. Analyzing individual token loss patterns reveals that not all tokens contribute equally to model improvement. Some tokens are easily learned, while others exhibit high or fluctuating loss, indicating a need for more focused training. This uneven contribution highlights the potential inefficiency of traditional methods that apply uniform training to all tokens. A granular approach that distinguishes between easily- and hard-to-learn tokens may significantly improve efficiency and model performance. This granular perspective suggests that the optimization of training should move beyond data- and document-level considerations to leverage token-level insights, leading to more targeted and efficient language model training. This fine-grained analysis allows for the development of novel training strategies such as selective language modeling, focusing training efforts on those tokens that would maximize model improvement, and thus address the limitations of traditional methods.
Selective LM (SLM)#
The core idea behind Selective Language Modeling (SLM) is to improve the efficiency and effectiveness of language model pre-training by selectively focusing on the most useful tokens during the training process. Instead of uniformly applying a next-token prediction loss to all tokens, as in traditional methods, SLM uses a reference model to score tokens based on their relevance. This scoring mechanism allows the model to prioritize training on tokens that align with the desired data distribution, leading to a more focused learning process. By concentrating on high-value tokens, SLM potentially reduces the computational cost associated with processing irrelevant or noisy data. This approach is particularly beneficial when dealing with massive datasets where many tokens offer minimal improvement in model performance. Ultimately, SLM aims to enhance both data efficiency and the overall performance of pre-trained language models, potentially achieving state-of-the-art results with significantly fewer training tokens.
Math & General Data#
A hypothetical section titled “Math & General Data” in a research paper would likely explore the use of distinct datasets for training language models. It would likely delve into the characteristics of mathematical datasets, highlighting their unique structure and symbolic nature, often involving sequential reasoning and complex formulas. Contrastingly, general data would represent a broader collection of text and code, potentially including noise and inconsistencies, requiring more sophisticated cleaning and preprocessing techniques. The core of this section would analyze how these datasets impact model performance across various tasks, comparing results on specialized math benchmarks and broader language understanding tests. This might show that while mathematical datasets enhance the model’s proficiency in symbolic manipulation and reasoning, general data improves versatility and robustness for other tasks. The study might also examine the optimal balance between these data types to achieve a model that is both specialized and generally competent, and finally discuss the challenges and opportunities of creating a unified training methodology that integrates both distinct data modalities.
SLM Efficiency Gains#
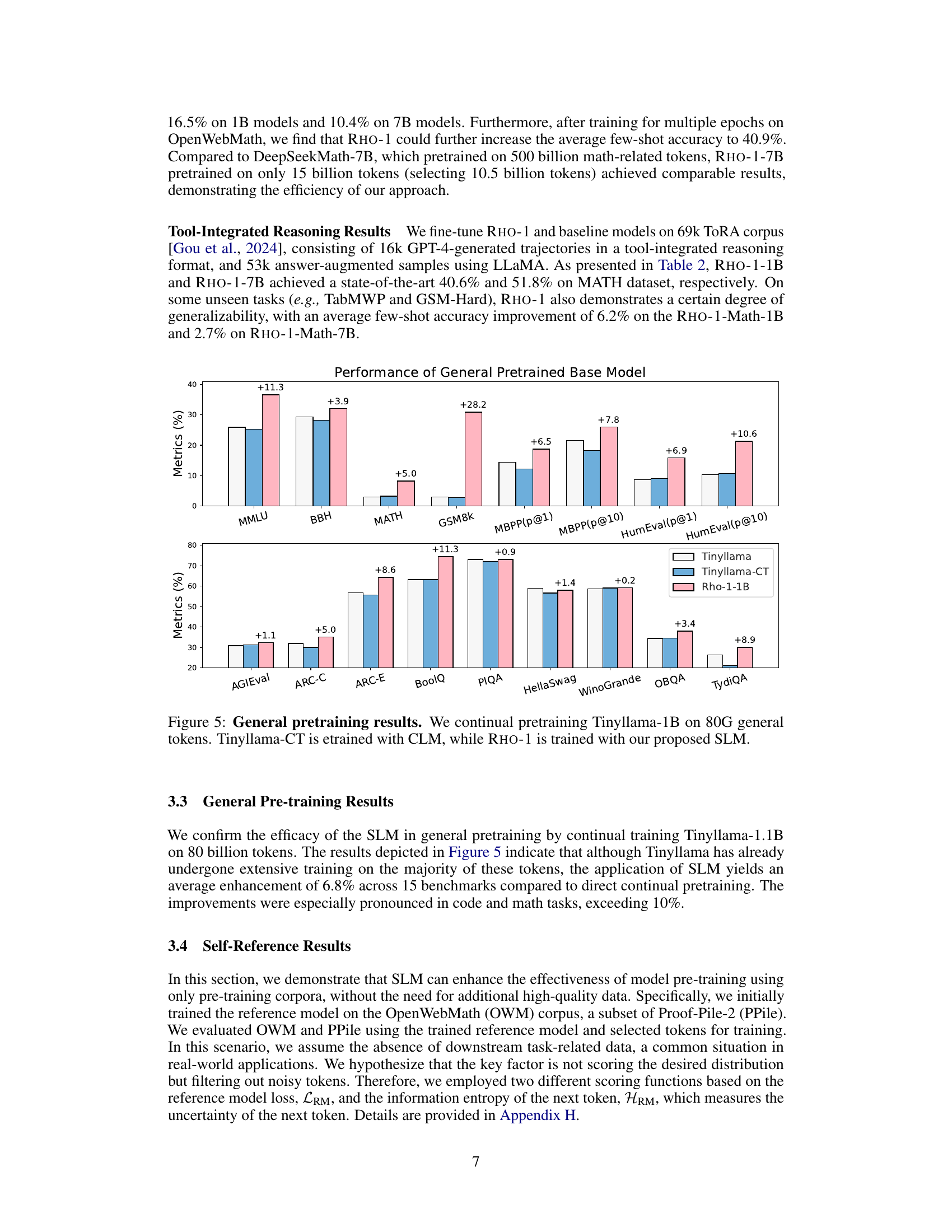
Selective Language Modeling (SLM) promises significant efficiency gains in large language model pretraining by focusing computational resources on the most valuable tokens. SLM’s core advantage lies in its ability to filter out noise and less informative tokens, thereby reducing wasted computation and improving data efficiency. This targeted approach contrasts with traditional methods that uniformly process all tokens, leading to potential overfitting and slower convergence. The results show that SLM achieves comparable or superior performance with drastically fewer training tokens, highlighting its potential for cost reduction and improved resource utilization in large-scale model training. This efficiency is further amplified by the substantial speed improvements observed, demonstrating the practical benefits of focusing training on the most informative parts of the data.
Future of SLM#
The future of Selective Language Modeling (SLM) holds significant promise. Improving token selection mechanisms is crucial; exploring more sophisticated scoring functions beyond simple loss differences could drastically improve accuracy and efficiency. Incorporating external knowledge sources, such as knowledge graphs or structured databases, into the scoring process could refine token selection, making it contextually aware and potentially reducing reliance on large reference models. Extending SLM to other modalities (image, audio, video) is another exciting avenue, allowing for more robust and comprehensive multimodal understanding. The development of more efficient training algorithms optimized for the SLM objective is necessary for scalability to larger models and datasets. Lastly, robustness testing and error analysis are essential to ensure that SLM performs reliably across a wide range of tasks and datasets. Addressing these challenges could establish SLM as a transformative paradigm shift in pre-training language models.
More visual insights#
More on figures
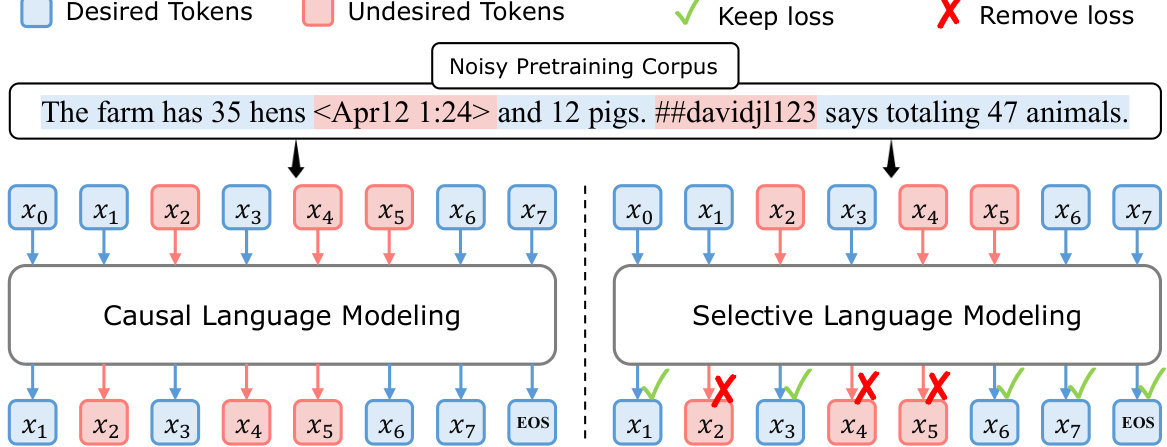
This figure illustrates the difference between traditional causal language modeling (CLM) and the proposed selective language modeling (SLM). CLM trains on all tokens in a corpus, while SLM selectively trains on useful tokens identified by a reference model. The figure uses a sample sentence to show how SLM filters out noisy tokens from the pretraining corpus, resulting in a more focused training process.
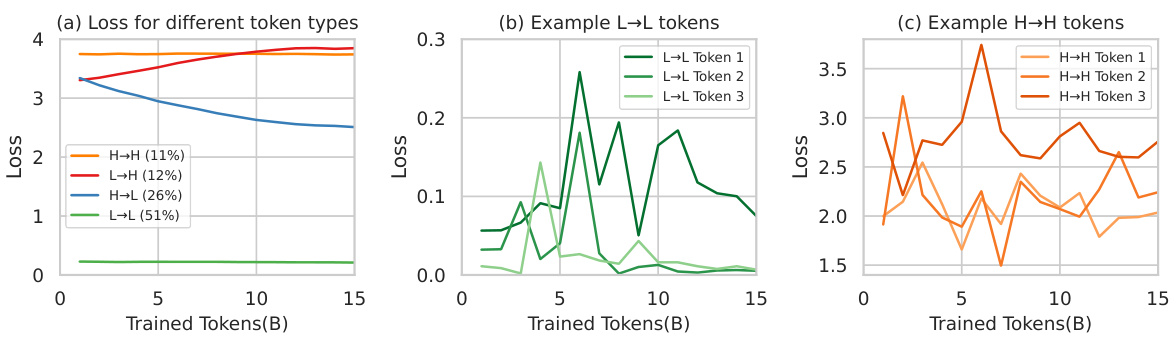
This figure visualizes the training dynamics of different token categories in a language model. Tokens are categorized into four groups based on their loss trajectory during pretraining: high-to-high (H→H), low-to-high (L→H), high-to-low (H→L), and low-to-low (L→L). The plots show the average loss for each category across training steps. Subplots (b) and (c) provide examples of the loss fluctuation patterns for specific tokens within the L→L and H→H categories, respectively, highlighting the variability in individual token learning curves.

This figure illustrates the three-step process of Selective Language Modeling (SLM). First, a reference model is trained on high-quality data. This model is then used to score each token in a larger pre-training corpus based on its loss. Finally, a language model is trained using only the tokens with high scores (determined by the reference model). This method focuses training on high-value, clean tokens, improving data efficiency and model performance.
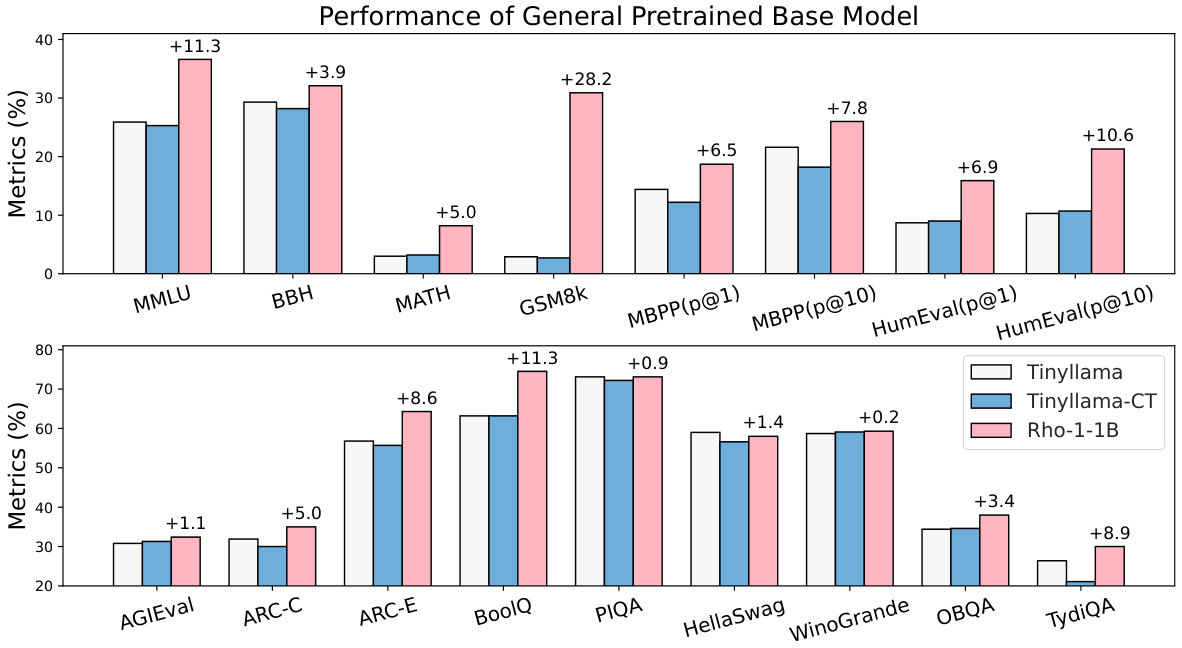
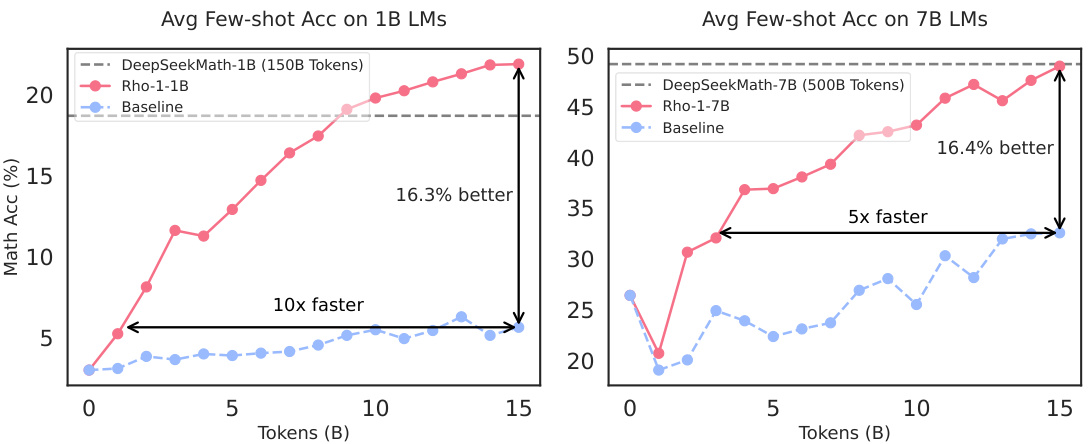
This figure shows the results of continual pretraining language models (LMs) of size 1B and 7B parameters on the OpenWebMath dataset. Two training methods are compared: a baseline using causal language modeling (CLM) and the proposed Selective Language Modeling (SLM) used to train the RHO-1 model. The graphs plot average few-shot accuracy against the number of training tokens (in billions). The results demonstrate that SLM significantly improves few-shot accuracy compared to the CLM baseline, achieving similar performance with 5-10 times fewer tokens.
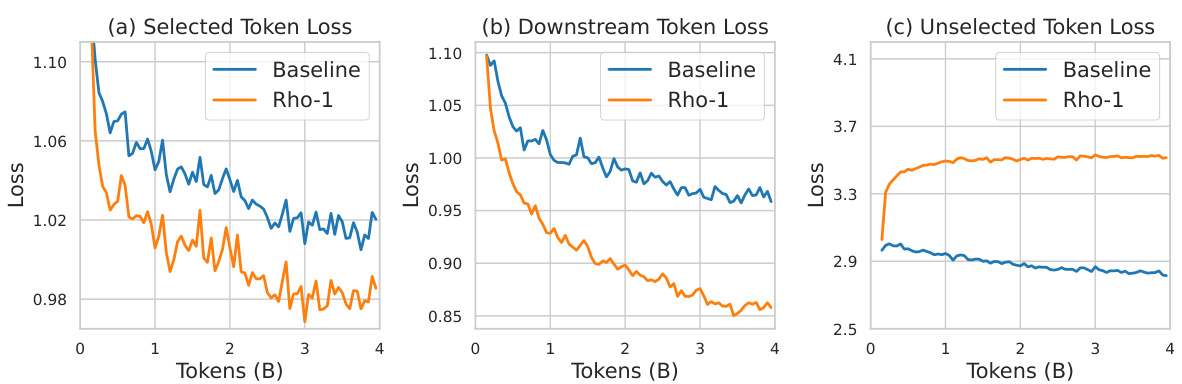
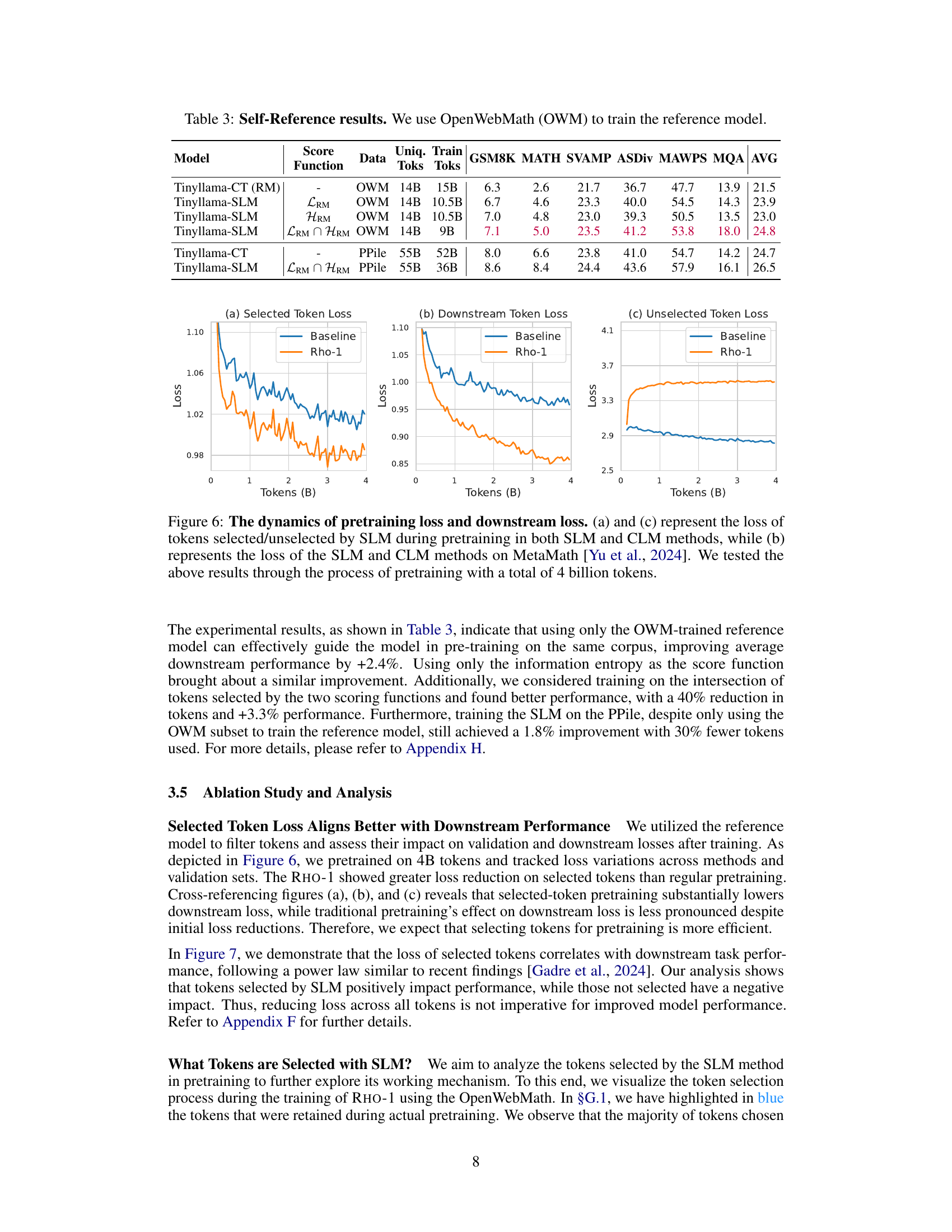
This figure shows a comparison of the training loss and downstream task loss between the SLM (Selective Language Modeling) and the CLM (Causal Language Modeling) methods. The left panel (a) displays the loss for the tokens selected by SLM during pretraining. The middle panel (b) illustrates the downstream task loss for both methods on the MetaMath dataset. The right panel (c) shows the loss for the tokens not selected by SLM. The results demonstrate that SLM leads to lower training loss and better downstream task performance. A total of 4 billion tokens were used during the pretraining process.
This figure shows the results of continual pre-training language models (LMs) of size 1B and 7B parameters on a 15B token OpenWebMath dataset. Two pre-training methods are compared: causal language modeling (baseline) and Selective Language Modeling (SLM), which is the core contribution of the paper. The results demonstrate that the SLM method significantly improves few-shot accuracy on two downstream tasks (GSM8k and MATH) with a speedup of 5 to 10 times compared to the baseline.

This figure compares the few-shot accuracy of 1B and 7B language models (LMs) trained with and without Selective Language Modeling (SLM) on the OpenWebMath dataset. The baseline models use causal language modeling. The results show that SLM significantly improves few-shot accuracy (by over 16%) and achieves comparable performance to baseline models at a 5-10x faster training speed. The x-axis represents the number of tokens (in billions) used for pretraining, and the y-axis represents the average few-shot accuracy.
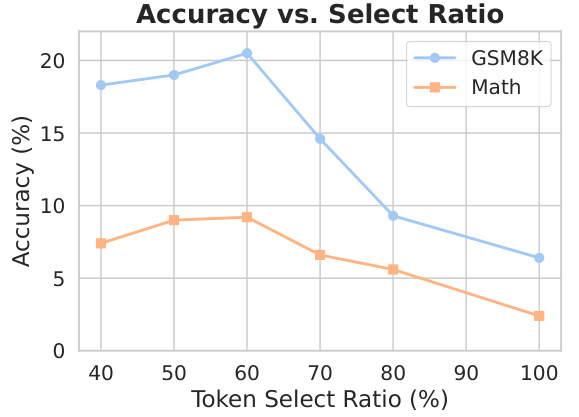
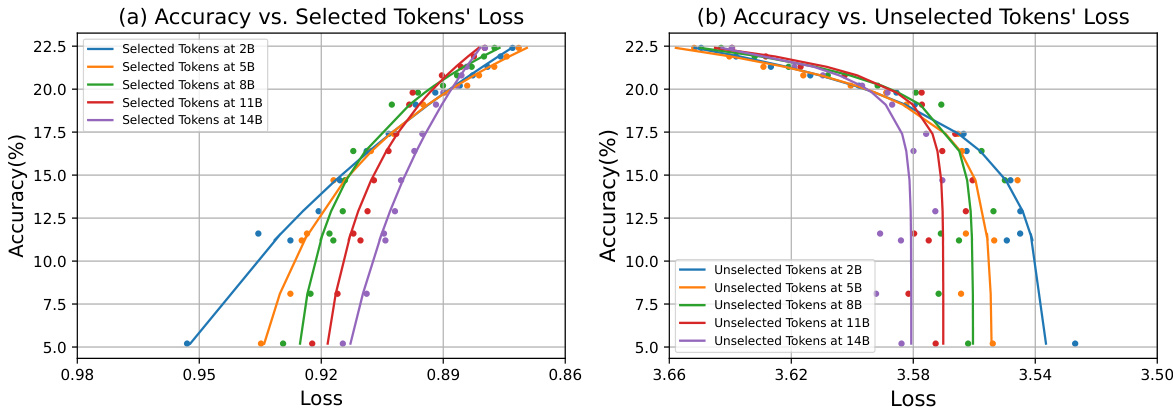
This figure shows the impact of different token selection ratios on the performance of a 1B parameter language model trained using the Selective Language Modeling (SLM) objective. The x-axis represents the percentage of tokens selected for training, while the y-axis shows the accuracy achieved on the GSM8K and MATH datasets. The results suggest an optimal token selection ratio exists, beyond which performance starts to decrease.
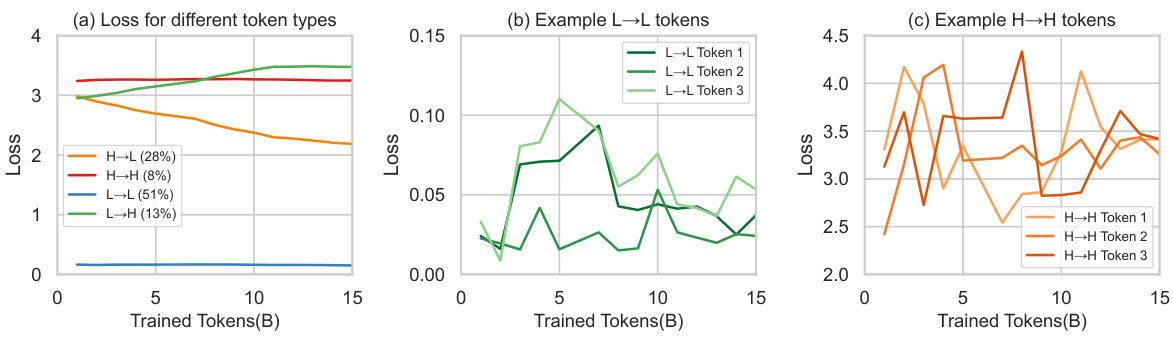
This figure visualizes the loss curves of four token categories during the language model pretraining. Panel (a) shows the average loss for each category (H→H, L→H, H→L, L→L) across the entire training process. Panels (b) and (c) provide example loss curves for individual tokens in the L→L and H→H categories, respectively, illustrating the inconsistent patterns observed for some tokens.
More on tables
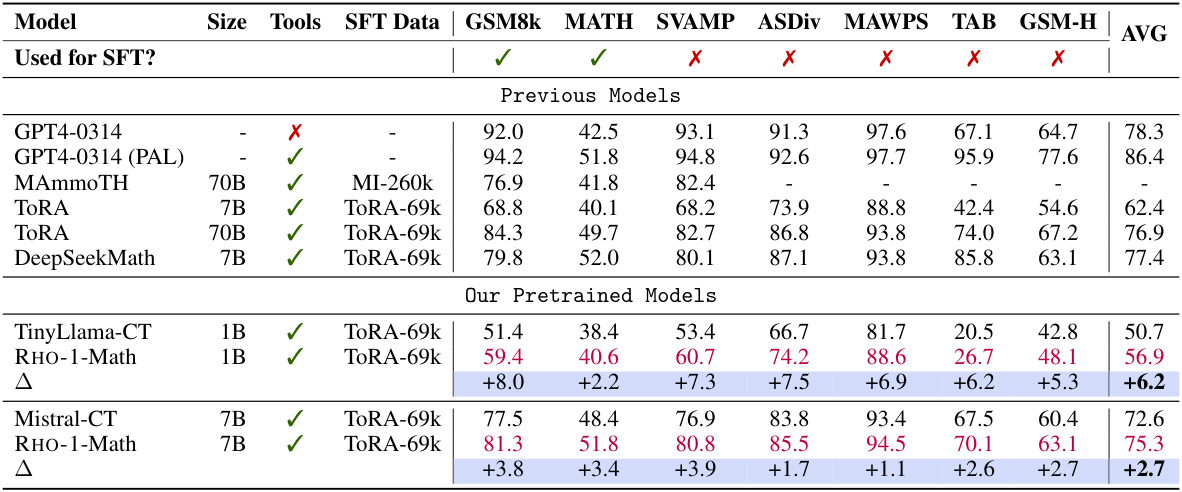
This table presents the few-shot chain-of-thought (CoT) reasoning results on math pre-training for various language models. It compares the performance of the proposed RHO-1 model against several baseline and state-of-the-art models across various math benchmarks (GSM8k, MATH, SVAMP, ASDiv, MAWPS, TAB, MQA, STEM, SAT). The results show the few-shot accuracy for each model, highlighting the improvement achieved by RHO-1, especially when considering its significantly reduced number of training tokens compared to other models. The table also indicates the number of unique training tokens used by each model.
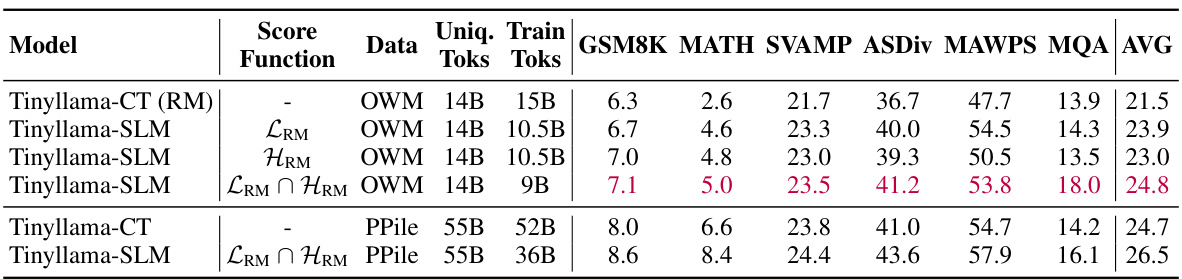
This table presents the few-shot chain-of-thought (CoT) reasoning results on the MATH dataset for various language models, including base models and those continually pre-trained with the proposed Selective Language Modeling (SLM) method. It compares the performance of RHO-1 models against existing state-of-the-art models in terms of accuracy on several math reasoning benchmarks. The table highlights the improvements achieved by RHO-1, particularly its efficiency in achieving comparable performance to much larger models with significantly fewer training tokens. The table also notes that the SAT results are averaged across the last three checkpoints due to the limited number of questions in the dataset.
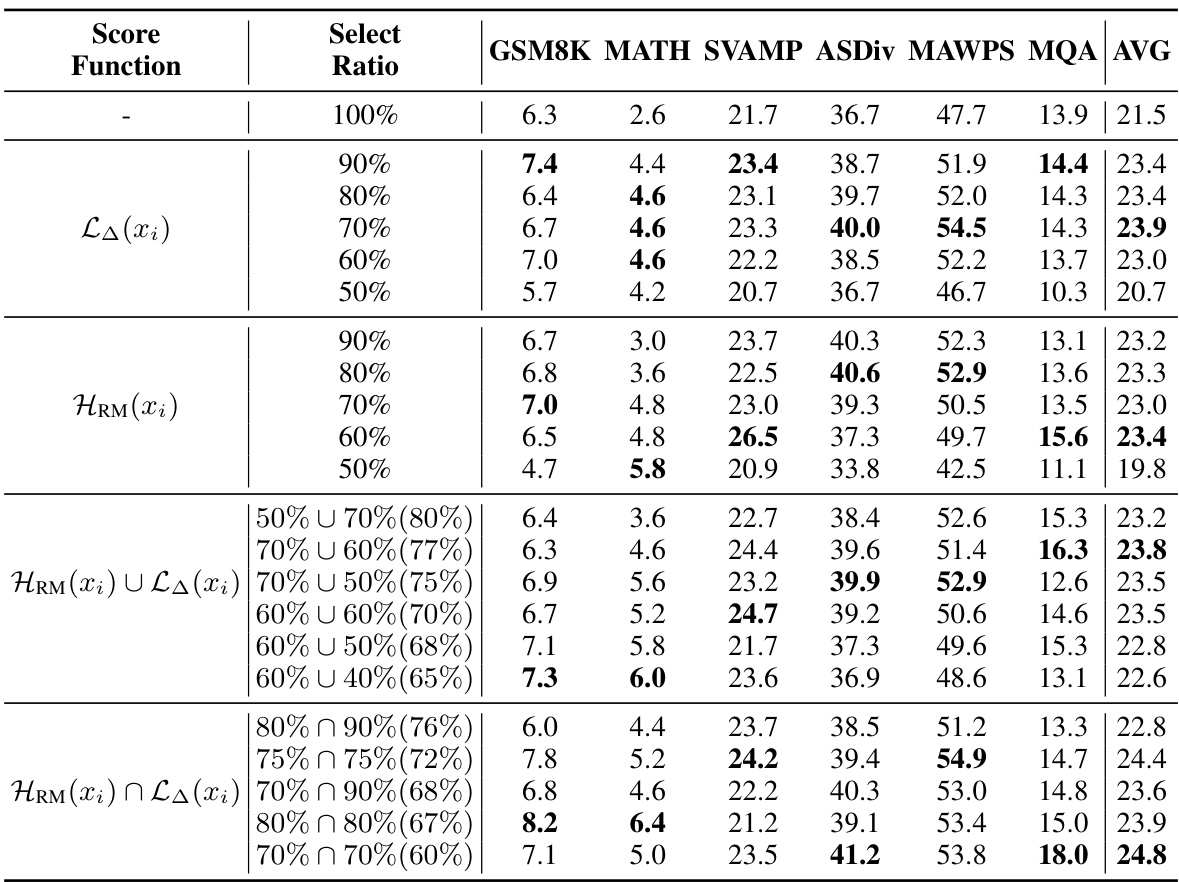
This table presents the few-shot chain-of-thought (CoT) reasoning results on mathematical reasoning tasks for various language models. It compares the performance of the proposed RHO-1 model against several baseline and state-of-the-art models. Results are shown for various metrics across multiple benchmarks, highlighting the improvement achieved by RHO-1, especially considering its reduced training data usage.

This table presents the few-shot chain-of-thought (CoT) reasoning results on mathematical problems for various language models. It compares the performance of the proposed RHO-1 model against several existing models, highlighting the improvements achieved through selective language modeling (SLM). The table shows results across multiple benchmarks (GSM8K, MATH, SVAMP, etc.) and includes model size and training data information to facilitate a comprehensive comparison. The use of unique math tokens and averaging over multiple checkpoints (for SAT) adds nuance and clarity to the evaluation.
Full paper#