↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current decoder-only Transformers for LLMs suffer from massive memory consumption, especially when handling long sequences. This limits the deployment of large, context-rich language models. The pre-filling process for long sequences is also extremely slow, hindering user experience.
To tackle these challenges, this paper introduces YOCO, a new decoder-decoder architecture. YOCO caches key-value pairs only once, significantly reducing memory usage. Its unique computation flow allows for efficient pre-filling, drastically improving inference speed. Experiments demonstrate YOCO’s superior performance in memory efficiency, speed, and language modeling tasks, even handling 1M context lengths with high accuracy.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) due to its significant advancements in memory efficiency and inference speed. YOCO’s novel architecture offers a compelling solution to the memory limitations of LLMs, enabling the deployment of larger, longer-context models on existing hardware. This opens up exciting avenues for future LLM development and applications, particularly in areas demanding extensive context processing.
Visual Insights#

This figure illustrates the YOCO architecture, a decoder-decoder model for language generation. It highlights the two main components: the self-decoder and the cross-decoder. The self-decoder efficiently creates a global key-value (KV) cache. This cache is then reused by the cross-decoder via cross-attention, allowing for efficient long-context processing while maintaining a decoder-only behavior. Both decoders utilize causal masking, preventing information leakage from future tokens during autoregressive generation.
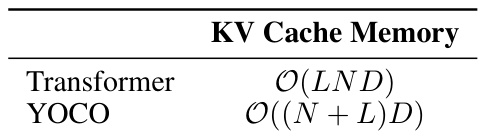
This table compares the memory complexity of key-value (KV) caches between the Transformer and YOCO architectures. It shows that Transformer’s memory usage grows linearly with the sequence length (N), number of layers (L), and hidden dimension (D), while YOCO’s memory usage has a much lower complexity, growing only linearly with N and D, due to its efficient caching mechanism that reuses KV pairs only once.
In-depth insights#
YOCO Architecture#
The YOCO architecture is a novel decoder-only transformer design that significantly improves upon traditional approaches by employing a two-stage decoder structure. It reduces memory consumption by caching key-value pairs only once, using a self-decoder to generate these caches which are then efficiently reused by a cross-decoder via cross-attention. This design retains the benefits of global attention while dramatically reducing memory demands. The computation flow allows for pre-filling to early exit, leading to substantial speed improvements in long-context tasks. YOCO’s flexibility allows for various efficient self-attention mechanisms, like sliding-window attention or gated retention, to be implemented in the self-decoder stage further enhancing its efficiency and scalability. The overall effect is an architecture that excels in long-context scenarios by addressing the memory bottlenecks inherent in standard decoder-only transformers, making it a strong candidate for future large language models.
Memory Efficiency#
The research paper emphasizes memory efficiency as a crucial aspect of its proposed model, YOCO. The core innovation lies in the one-time caching of key-value pairs, significantly reducing memory consumption compared to traditional Transformer architectures. This efficiency stems from the decoder-decoder design. The self-decoder creates global KV caches used by the cross-decoder, eliminating redundant computations and drastically lowering memory demands, particularly crucial for long-context language models. Profiling results showcase YOCO’s superior memory efficiency across various model sizes and context lengths, highlighting orders-of-magnitude improvements in inference memory and serving capacity. The efficient self-attention mechanisms within the self-decoder further contribute to these gains. Overall, the memory savings enabled by YOCO make deploying large language models, especially those capable of handling extended contexts, significantly more feasible.
Prefill Optimization#
Prefill optimization in large language models (LLMs) focuses on accelerating the initial loading of context before text generation. Reducing prefill time is crucial for improving user experience, especially with long contexts, as it directly impacts latency. Strategies often involve modifying the architecture, such as employing a decoder-decoder structure where a self-decoder efficiently pre-computes key-value caches that are reused by a cross-decoder. This avoids redundant computations associated with encoding the history repeatedly. Another approach is to leverage efficient attention mechanisms like sliding-window attention, significantly decreasing memory usage and computation cost. Techniques like early exit in the prefill process are also beneficial. These methods greatly reduce GPU memory consumption while maintaining accuracy and enabling longer contexts. Optimizations must balance speed, memory efficiency, and the quality of the final output, ensuring that the benefits of faster prefill don’t negatively affect the model’s performance on downstream tasks.
Long-Context LLM#
Long-context LLMs represent a significant advancement in large language models, enabling them to process and generate text from significantly longer sequences than previously possible. This enhanced capability is crucial for various applications that involve handling extensive contexts, such as summarizing lengthy documents, facilitating complex conversations, or building advanced question-answering systems. The key challenge lies in managing the computational and memory costs associated with processing such long sequences. Existing architectures often struggle with quadratic complexity in attention mechanisms, making long context processing very expensive. Innovative approaches focus on more efficient attention mechanisms, like sparse attention or linear attention, which aim to reduce the computational burden while maintaining contextual awareness. Another important aspect is memory optimization. Efficient caching strategies and quantization techniques are used to reduce the memory footprint of key-value pairs, avoiding out-of-memory errors. Despite these advancements, significant hurdles remain. Further research must address the trade-offs between accuracy, efficiency, and context length. Additionally, exploring novel architectural designs and training methodologies tailored specifically for long-context scenarios is crucial for realizing the full potential of LLMs in various real-world applications.
Future of YOCO#
The future of YOCO, a decoder-decoder architecture for large language models, appears promising. Its core strength, caching key-value pairs only once, drastically reduces memory consumption, enabling efficient long-context processing. Future work could explore optimizations for efficient self-attention within the self-decoder, potentially using techniques like linear attention or sparse attention. Further exploration of distributed training strategies, especially for ultra-long sequences, is crucial to leverage YOCO’s scalability. The integration of YOCO with other advancements in efficient attention, quantization, and hardware acceleration would likely yield substantial performance improvements and broader deployment options. Finally, research into adapting YOCO for tasks beyond language modeling, such as other sequence-to-sequence problems, could unlock its potential in broader AI applications. Ultimately, the success of YOCO will depend on its continued evolution and integration with emerging technologies within the LLM field.
More visual insights#
More on figures

The figure illustrates the two-stage inference process of the YOCO model. The Prefilling stage encodes the input tokens in parallel using only the self-decoder. The Generation stage then generates output tokens one by one using both the self- and cross-decoders. The key point is that the prefilling stage can stop early before fully completing all layers of the self-decoder, significantly speeding up the overall process without altering the final output.
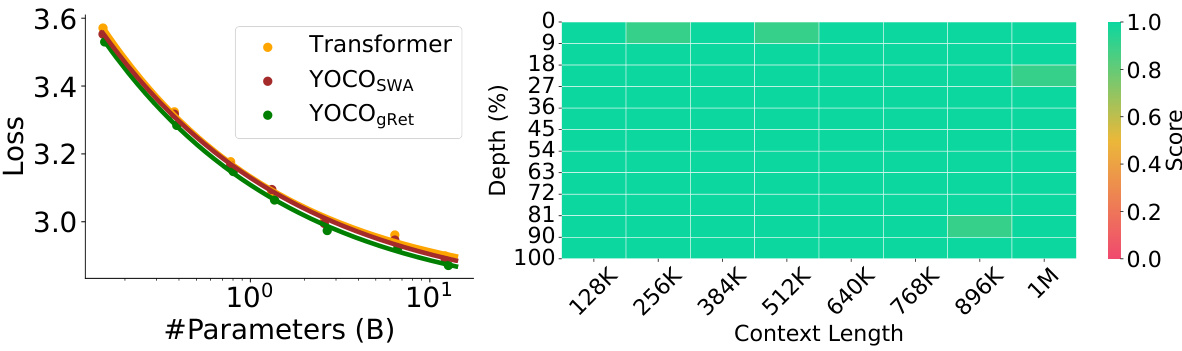
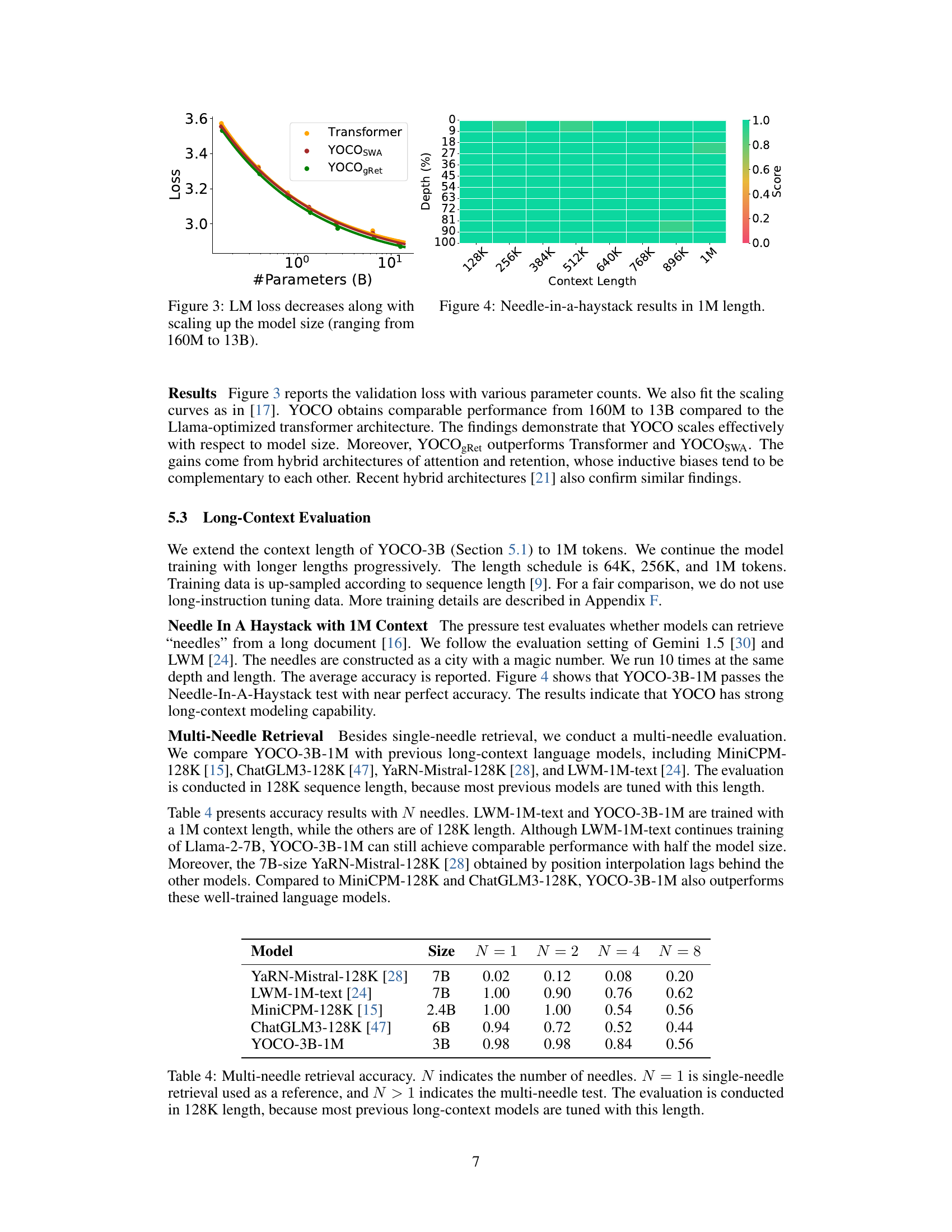
This figure displays the relationship between the number of parameters in a language model and its loss. It shows that as the model size increases (from 160 million to 13 billion parameters), the loss consistently decreases, indicating improved performance. Three model architectures are compared: the standard Transformer, YOCOSWA (You Only Cache Once with Sliding-Window Attention), and YOCOgRet (You Only Cache Once with Gated Retention). YOCOgRet shows the lowest loss across all model sizes, suggesting its superior efficiency and performance.
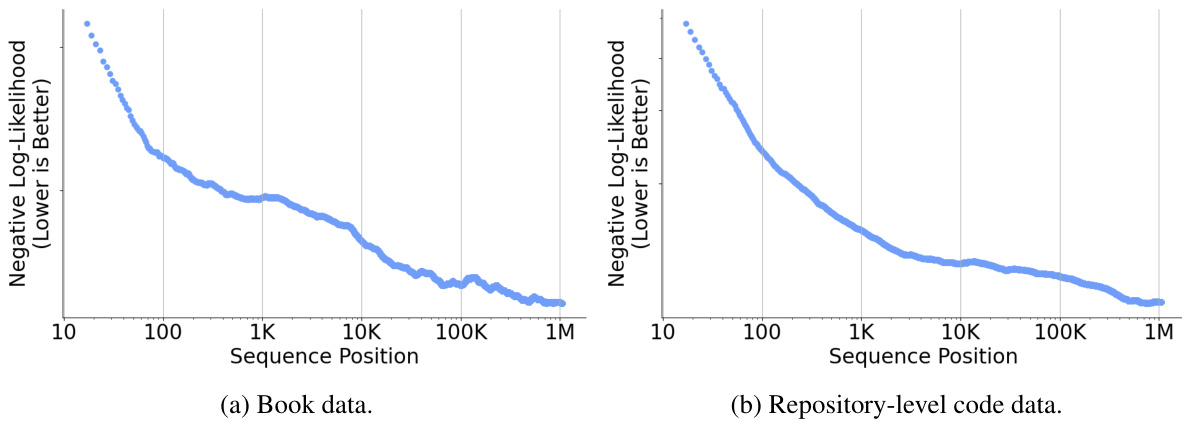
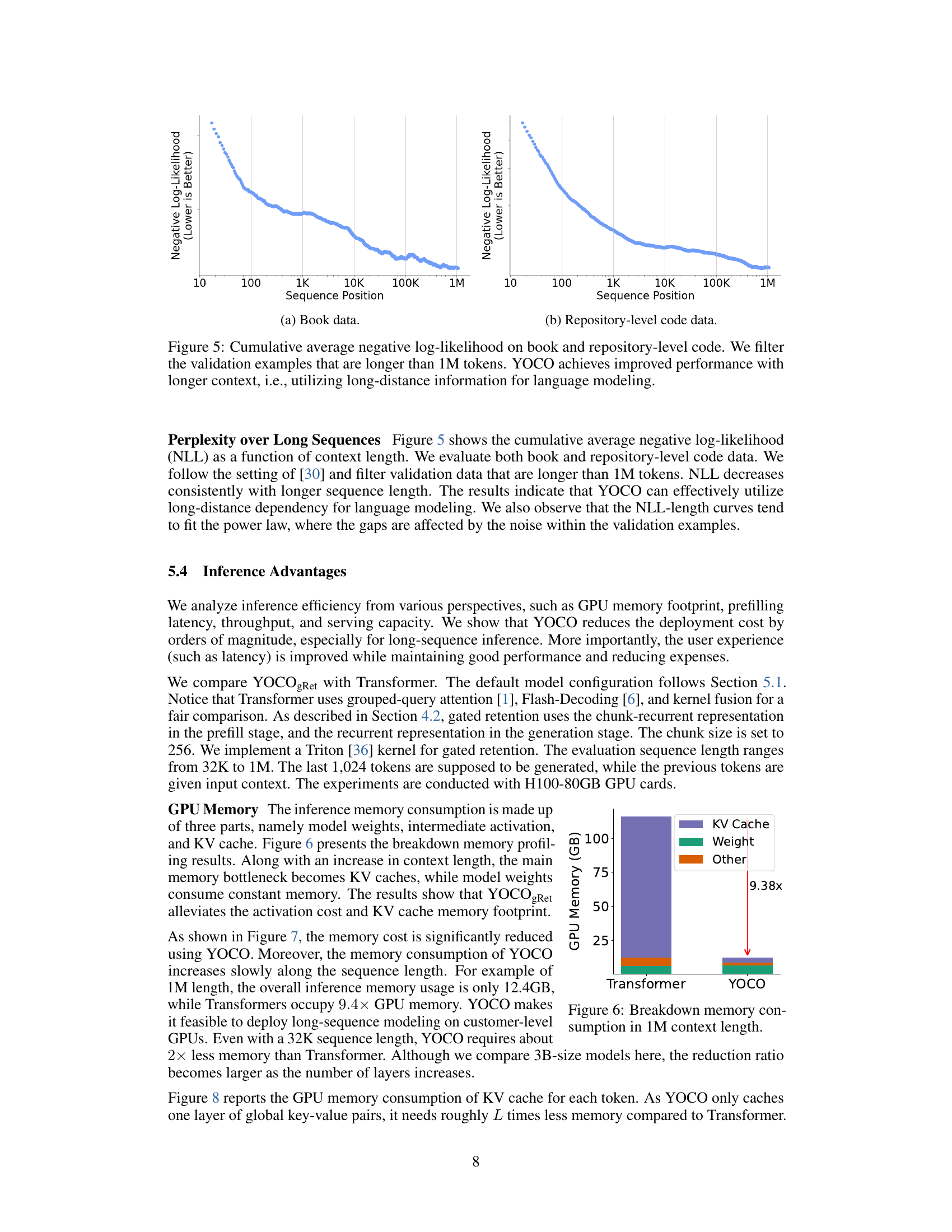
This figure shows two line graphs, one for book data and one for repository-level code data, illustrating the cumulative average negative log-likelihood (NLL) as a function of sequence length. The graphs demonstrate that the NLL generally decreases with longer sequence length, indicating improved performance of the YOCO model in capturing long-range dependencies within text. The filtering of validation examples longer than 1M tokens suggests a focus on evaluating the model’s performance on very long sequences.
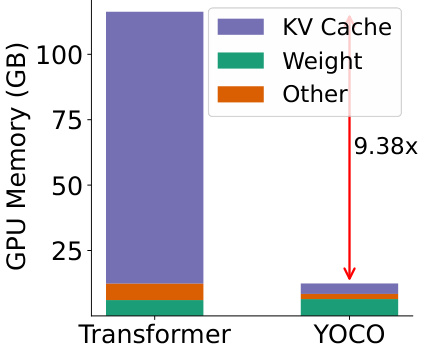
The figure shows the breakdown of GPU memory usage for both Transformer and YOCO models with a context length of 1M tokens. The Transformer model’s memory is dominated by KV Cache, while YOCO significantly reduces the KV Cache memory usage. This illustrates the main memory saving advantage of the proposed YOCO architecture.
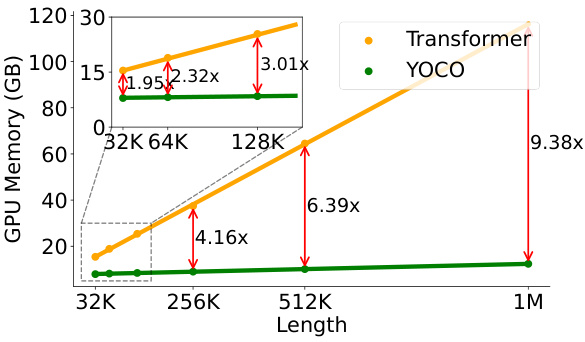
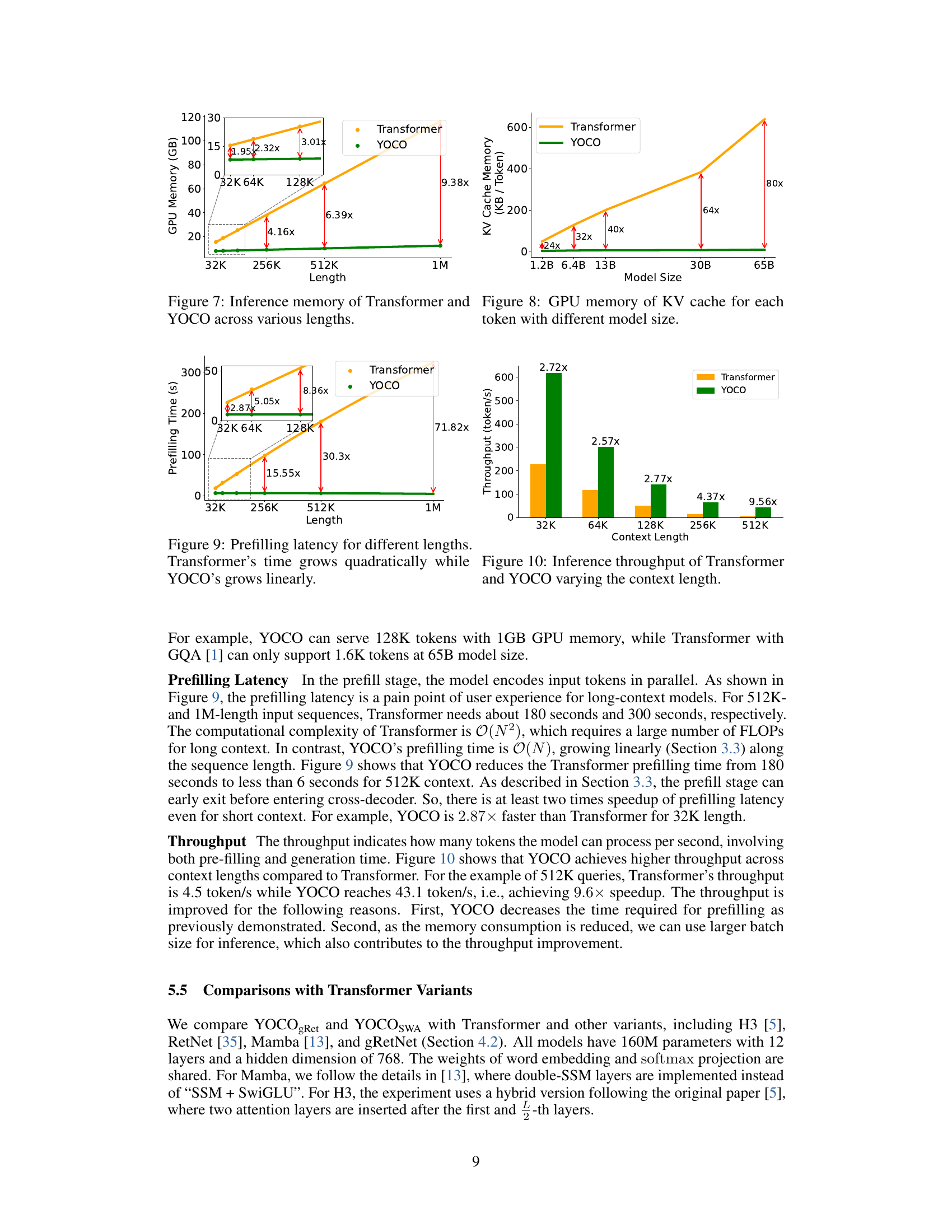
This figure compares the GPU memory usage of the Transformer and YOCO models across different context lengths (32K, 64K, 128K, 256K, 512K, and 1M tokens). It visually demonstrates that YOCO’s memory consumption remains relatively constant regardless of the context length, while the Transformer’s memory usage increases dramatically. The inset shows a zoomed-in view of the memory usage for shorter context lengths (32K, 64K, and 128K tokens). The red arrows highlight the fold increase in memory consumption for Transformer compared to YOCO at each context length. The results underscore YOCO’s significant advantage in memory efficiency, especially when handling long sequences.

The figure compares the GPU memory usage of key-value (KV) caches per token for Transformer and YOCO models of various sizes. The Y-axis represents the KV cache memory in kilobytes per token, and the X-axis shows the model size in billions of parameters. It demonstrates that YOCO’s KV cache memory usage remains relatively constant across different model sizes, while the Transformer’s KV cache memory usage increases significantly with model size. The red arrows indicate the magnitude of the memory reduction achieved by YOCO compared to Transformer at each model size.

This figure compares the prefilling latency (time taken to prepare the model for text generation) of Transformer and YOCO models for various sequence lengths (32K to 1M tokens). The key takeaway is that the Transformer’s prefilling time increases quadratically with the sequence length, while YOCO’s prefilling time increases linearly. This illustrates a significant advantage of YOCO in terms of efficiency and speed when handling long sequences.
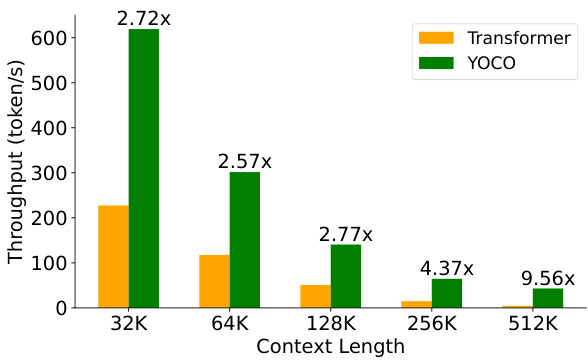
The bar chart compares the throughput (tokens/second) of the Transformer and YOCO models for different context lengths (32K, 64K, 128K, 256K, and 512K). YOCO demonstrates significantly higher throughput than Transformer across all context lengths, with the improvement increasing as context length increases. The figure highlights the superior efficiency of YOCO in processing long sequences.

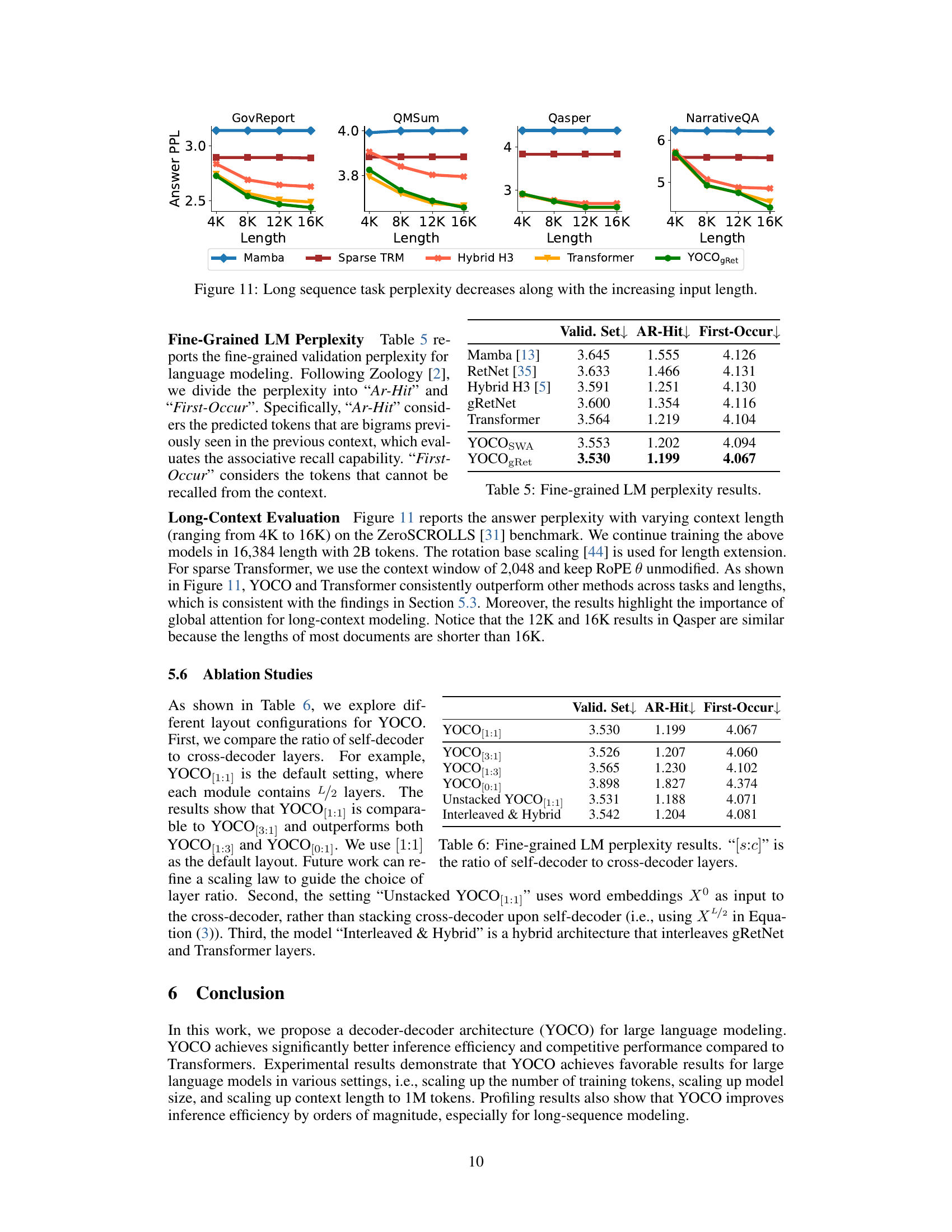
This figure shows the results of long sequence task perplexity on four different datasets (GovReport, QMSum, Qasper, NarrativeQA) with different context lengths (4K, 8K, 12K, 16K). It compares the performance of several models: Mamba, Sparse TRM, Hybrid H3, Transformer, and YOCOgRet. The graph illustrates how the perplexity (a measure of how well a model predicts a sequence) changes as the context length increases. Generally, lower perplexity indicates better performance. The graph visually demonstrates the trend of decreasing perplexity as context length increases for all models, highlighting the impact of context length on language modeling performance.

This figure illustrates the YOCO architecture, a decoder-decoder model. The self-decoder layer efficiently encodes the global key-value (KV) cache which is then reused by the cross-decoder layer through cross-attention. Both layers utilize causal masking. The result is a model that functions like a decoder-only Transformer but with the memory efficiency of only caching KV pairs once.
More on tables

This table compares the time complexity of the attention modules in Transformer and YOCO models during the pre-filling stage. It shows that Transformer’s pre-filling time is proportional to the square of the sequence length (N), while YOCO’s is linear with respect to N, indicating a significant improvement in efficiency for longer sequences.
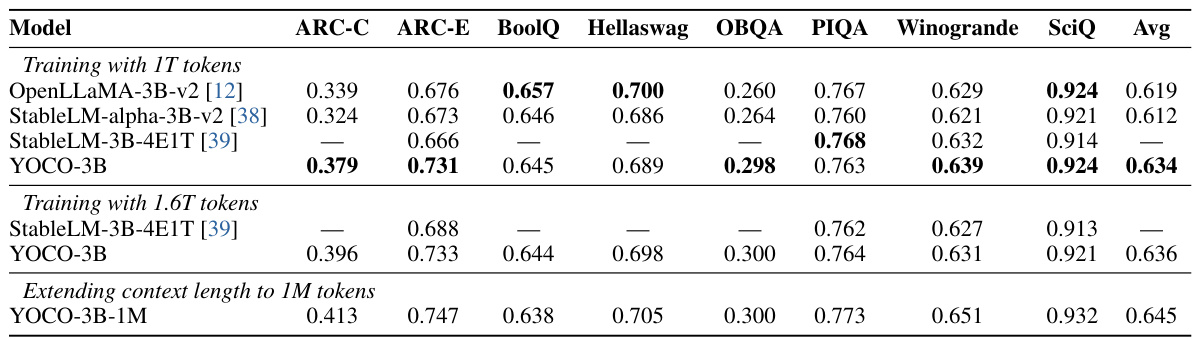
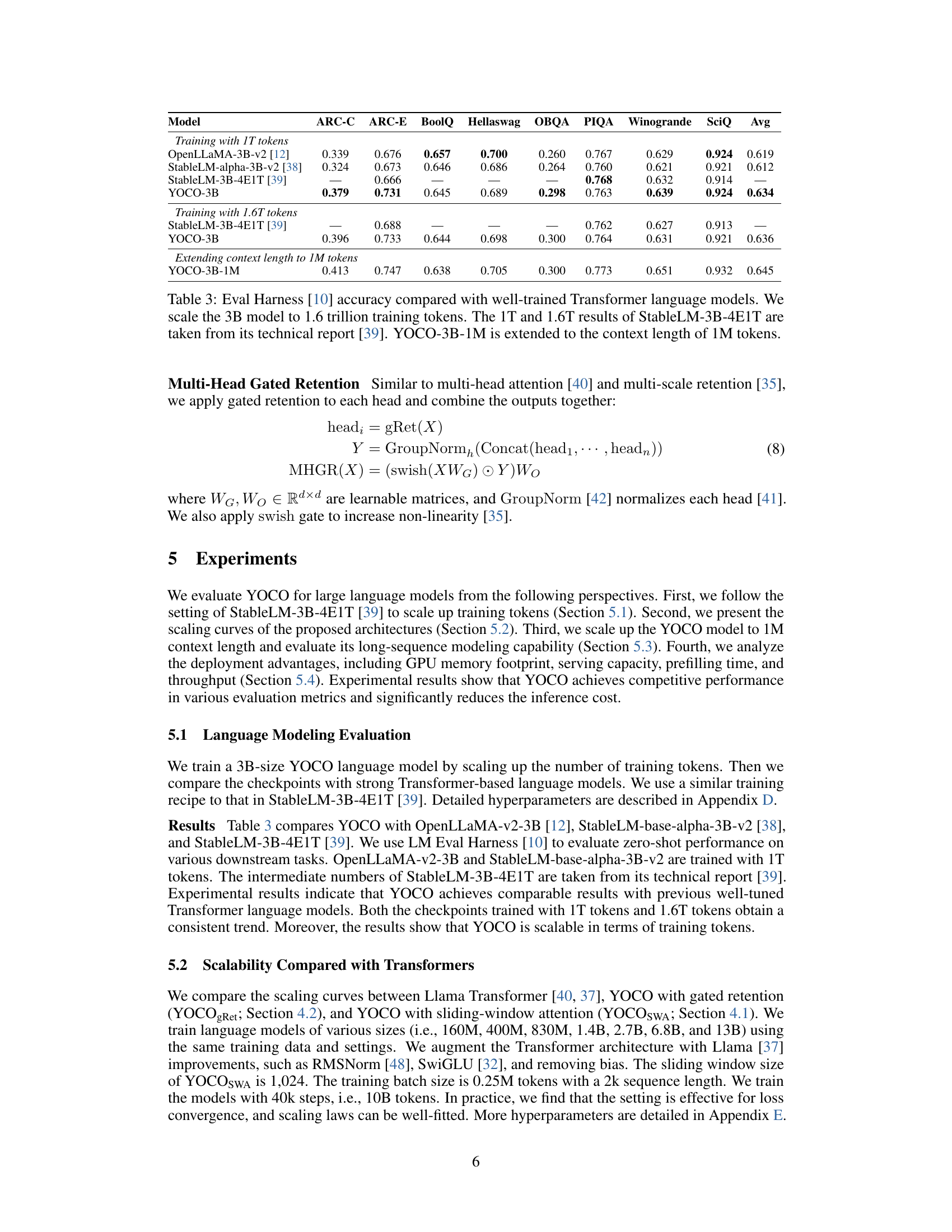
This table compares the performance of the YOCO-3B model against other well-trained Transformer language models on the Eval Harness benchmark. The comparison is done for various training token sizes (1T and 1.6T) and context lengths (up to 1M tokens). It demonstrates that YOCO-3B achieves competitive performance compared to existing large language models, even when scaled to large training datasets and long contexts.
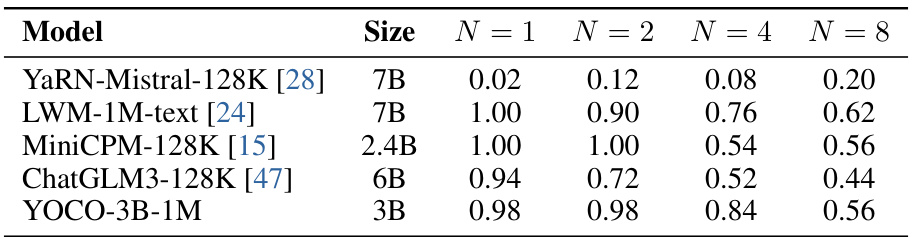
This table presents the multi-needle retrieval accuracy of several long-context language models, including YOCO-3B-1M, on a 128K sequence length. The accuracy is measured by the number of correctly retrieved needles (N) out of a total number of needles, with N ranging from 1 to 8. The results show YOCO’s strong performance even compared to larger models.

This table presents the fine-grained Language Model perplexity results for various models including Mamba, RetNet, Hybrid H3, gRetNet, Transformer, YOCOSWA, and YOCOgRet. The perplexity is broken down into ‘AR-Hit’, which measures the model’s ability to recall previously seen bigrams, and ‘First-Occur’, which measures the perplexity of tokens not previously seen. Lower perplexity values indicate better performance.
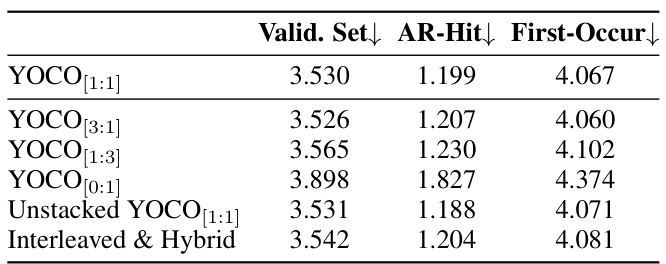
This table presents the results of a fine-grained language model perplexity evaluation. It compares different configurations of the YOCO model, varying the ratio of self-decoder to cross-decoder layers. The metrics used are AR-Hit (autoregressive hit rate) and First-Occur (first occurrence rate), indicating the model’s ability to recall previously seen tokens and handle novel tokens respectively. The table shows the impact of the layer ratio on the model’s performance.

This table compares the performance of the YOCO-3B model with other well-trained Transformer language models on the Eval Harness benchmark. It shows accuracy results for various tasks across three different model configurations: the 3B model trained on 1T tokens, the 3B model trained on 1.6T tokens, and the 3B model trained on 1.6T tokens with a context length extended to 1M. The results demonstrate the performance of YOCO-3B, and how it scales up with increased training tokens and context length.
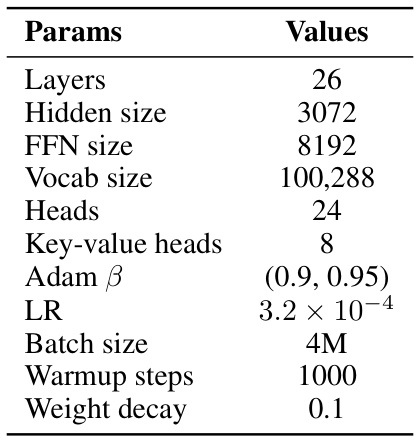
This table shows the hyperparameters used for training the YOCO-3B language model, which is the main model evaluated in Section 5.1 of the paper. The hyperparameters cover various aspects of the training process, including the model architecture (number of layers, hidden size, FFN size, number of heads, etc.), the optimizer used (AdamW, along with its beta values), the learning rate, the batch size, the warmup steps, and the weight decay. These parameters were chosen to achieve the reported results in Section 5.1. This model is trained and evaluated with one trillion tokens (1T).

This table shows the different model sizes that were used in the scaling curve experiments of Section 5.2 of the paper. The table lists the number of parameters (size), hidden dimension, the number of layers, and the number of heads for each of the models used in the experiment. These parameters were varied to show how YOCO scales with respect to model size.
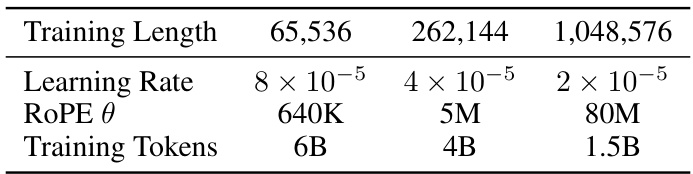
This table shows the hyperparameters used for extending the context length to 1M tokens in Section 5.3 of the paper. Specifically, it details the learning rate, RoPE θ (Rotary Position Embedding parameter), and the total number of training tokens used at each stage of the length extension schedule (64K, 256K, and 1M tokens). These parameters were adjusted progressively as the model’s context length increased.
Full paper#