↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current code generation models struggle with complex tasks. Two-stage methods decompose problems upfront, while multi-agent approaches collaborate but are resource-intensive. Self-improvement relies on accurate self-tests, which are often unreliable. These limitations motivate the need for more robust and efficient strategies.
FUNCODER addresses these issues by recursively decomposing complex problems into sub-functions, represented in a tree hierarchy. It dynamically introduces new functions during code generation, thus adapting to evolving requirements. Instead of self-testing, FUNCODER employs functional consensus, selecting the most consistent function implementations to mitigate error propagation. This approach significantly improves code generation performance on various benchmarks across multiple model sizes, demonstrating superior capabilities over existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in code generation due to its novel approach to tackling complex programming tasks. FUNCODER’s divide-and-conquer strategy with functional consensus offers a significant advancement over existing two-stage or multi-agent methods. The approach’s effectiveness on both large language models (LLMs) and smaller, open-source models expands the accessibility of advanced code generation techniques. Its focus on handling complex requirements through dynamic function decomposition opens exciting avenues for future research and development in the field.
Visual Insights#

This figure illustrates the FUNCODER framework. The left side shows the divide-and-conquer process where the main function is recursively broken down into smaller sub-functions represented as a tree. The right side shows how the sub-functions are recombined and the best one is selected using functional consensus, which compares the similarity of the functionality between multiple candidates. The bottom-right depicts the hierarchical function writing process.
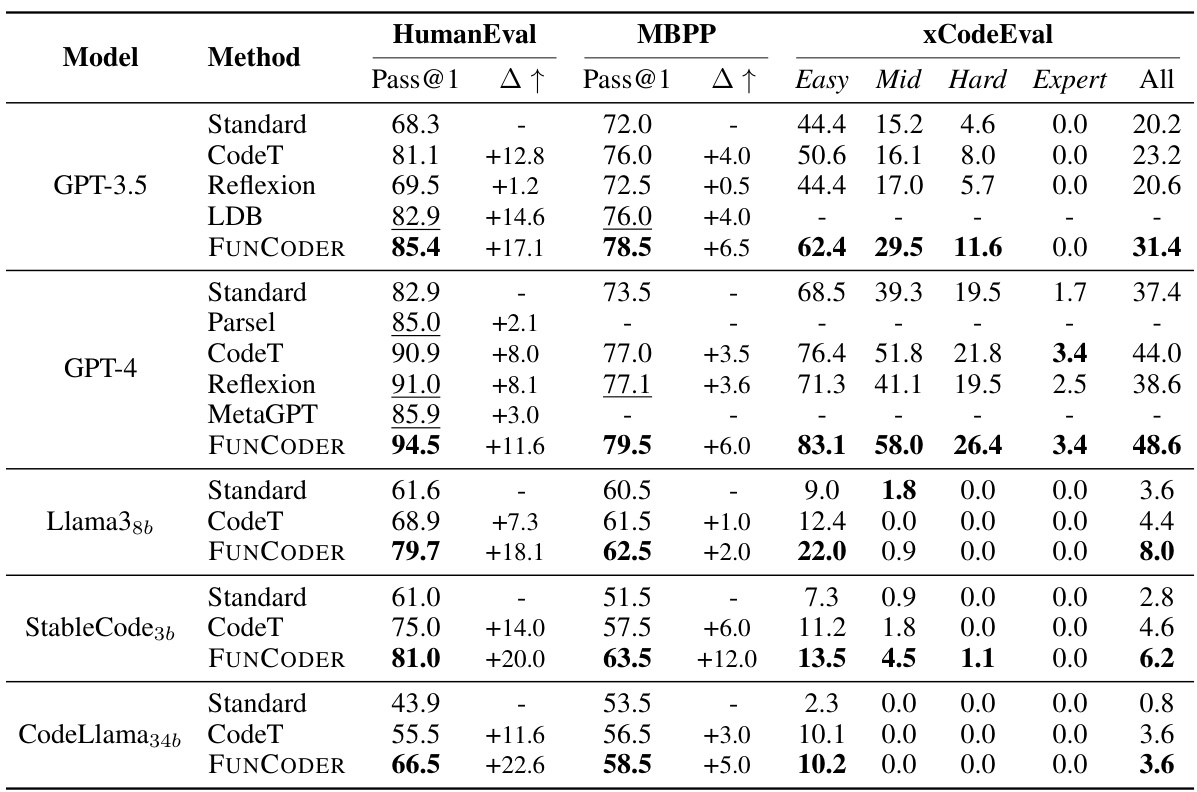
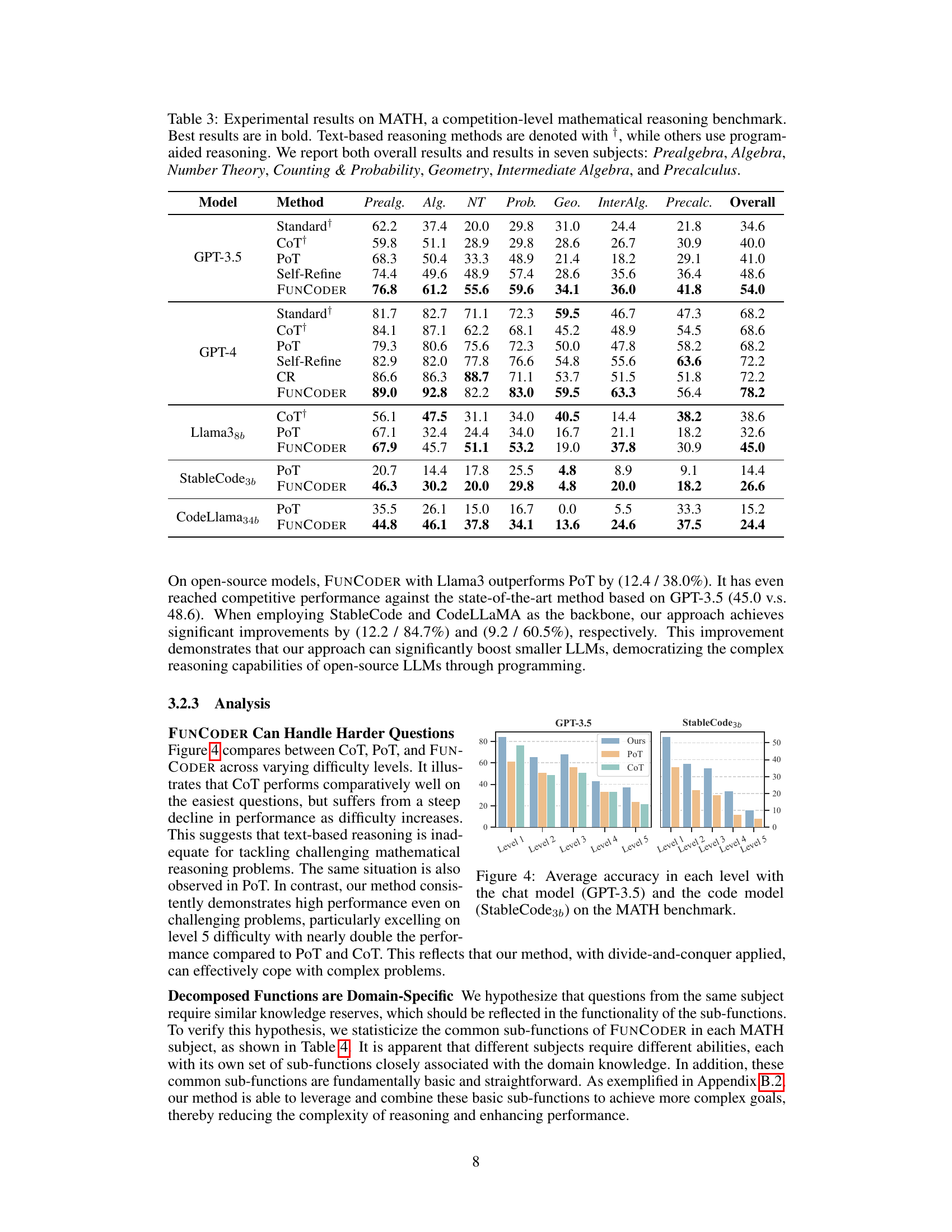
This table presents the performance of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on three benchmarks (HumanEval, MBPP, and xCodeEval) using two different language models (GPT-3.5 and GPT-4). For each method and benchmark, the table shows the Pass@1 score (the percentage of times the method generated a correct program on the first attempt), and the improvement over the standard method (Δ↑). The best results for each benchmark are highlighted in bold.
In-depth insights#
FuncODER Framework#
The FuncODER framework presents a novel approach to code generation by integrating divide-and-conquer with functional consensus. Instead of relying on a pre-planned decomposition, FuncODER dynamically introduces new functions to tackle sub-problems, recursively breaking down complex tasks into smaller, manageable units. This iterative, bottom-up approach offers greater flexibility and adaptability compared to two-stage methods. The core innovation lies in the functional consensus mechanism which samples multiple function implementations for each sub-problem and selects the one demonstrating the highest similarity to others, thereby mitigating error propagation and improving overall program correctness. This contrasts with self-testing approaches that can be unreliable. FUNCODER’s recursive decomposition and consensus mechanism are crucial for handling complex requirements, significantly improving performance on various code generation benchmarks and showcasing applicability to smaller, open-source models.
Divide & Conquer#
The “Divide & Conquer” strategy, a cornerstone of algorithm design, is brilliantly adapted in this research for code generation. The approach recursively decomposes complex programming tasks into smaller, more manageable sub-problems, represented as functions. This decomposition simplifies the problem, enabling large language models (LLMs) to generate code for these smaller functions more effectively. The core innovation lies in the dynamic nature of this decomposition, where new functions are introduced iteratively based on the code generation process, rather than relying on a predefined plan. This allows for adaptability and increased accuracy. However, the paper also addresses the risks of error propagation inherent in such a recursive approach. It mitigates these risks by employing a “functional consensus” mechanism, which samples and selects the most consistent function implementations from multiple candidates, improving overall reliability and correctness.
Functional Consensus#
The concept of “Functional Consensus” presents a novel approach to enhancing the reliability of code generation by large language models (LLMs). Instead of relying solely on self-testing, which can be unreliable, this method emphasizes achieving consensus among multiple generated functions. The core idea is to evaluate several different implementations of a function, selecting the one that exhibits the greatest similarity in behavior to others. This is achieved through a similarity metric that measures the agreement of outputs across various inputs for different implementations. By selecting a function exhibiting widespread agreement, the approach mitigates the risk of errors from outlier implementations propagating through the program’s execution. This divide-and-conquer strategy, combined with functional consensus, aims to build more robust programs by managing complexity and reducing error propagation, particularly in complex coding scenarios. The selection process promotes consistency and reduces reliance on potentially faulty self-tests.
LLM Generalization#
LLM generalization, the ability of large language models to perform well on tasks unseen during training, is a crucial area of research. A key challenge lies in the inherent complexity of real-world tasks, which often involve nuanced language, varied data formats, and combinations of reasoning abilities. Current LLMs often struggle to generalize effectively, exhibiting significant performance drops when faced with data or tasks outside their training distribution. Improving generalization requires addressing factors such as data bias, model architecture, and training methodology. Techniques like data augmentation, multi-task learning, and meta-learning have shown promise in enhancing generalization capabilities. Furthermore, research into more robust model architectures, perhaps inspired by biological neural networks, may be crucial. Understanding and mitigating the effects of data bias is also critical for ensuring that LLMs generalize in a fair and equitable manner. Ultimately, achieving true LLM generalization will likely require a combined approach that addresses all these interconnected factors.
Future Work#
Future research directions stemming from this divide-and-conquer code generation framework could explore several promising avenues. Improving the efficiency and scalability of the functional consensus mechanism is crucial for handling very large and complex programs. Investigating alternative consensus strategies beyond simple similarity comparison, perhaps incorporating semantic analysis or execution traces, might enhance robustness and accuracy. Another important direction involves extending the framework to support diverse programming paradigms beyond imperative and functional approaches. Adapting the divide-and-conquer strategy for object-oriented or logic programming would significantly broaden the applicability of the method. The generation of more reliable and informative unit tests remains a key challenge. Exploring techniques to automatically assess test quality and reduce the incidence of misleading or incorrect tests would be valuable. Finally, it will be beneficial to investigate the framework’s ability to handle uncertain or ambiguous requirements. Incorporating techniques for handling incomplete or contradictory specifications would significantly enhance its capabilities for practical application in real-world software development.
More visual insights#
More on figures

This figure illustrates the FUNCODER framework. The left side shows the divide-and-conquer process where the main function is recursively broken down into smaller sub-functions represented as a tree. Each sub-function addresses a specific sub-goal. The right side demonstrates the conquer phase. After the sub-functions are solved, FUNCODER recomposes them to achieve the main objective. Finally, FUNCODER uses functional consensus to select the best-performing function among multiple implementations.

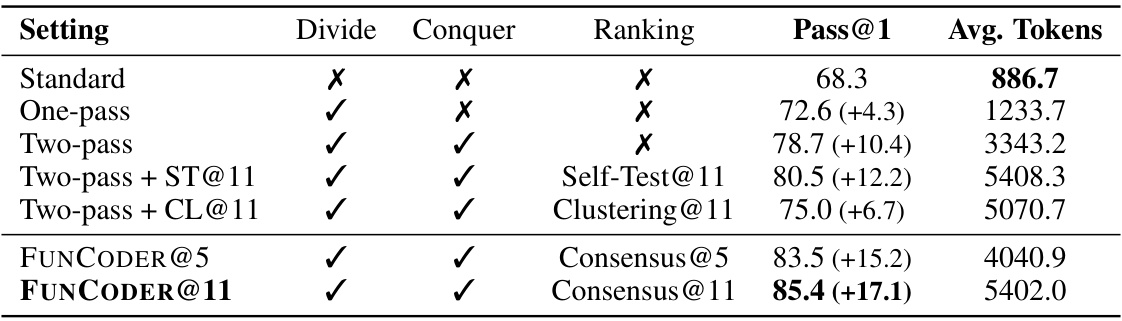
This figure shows the results of two analyses. (a) shows a preliminary study on the effectiveness of using self-testing to evaluate the programs generated by Large Language Models (LLMs). The results are divided into different categories based on whether the programs and/or their self-tests passed or failed. (b) illustrates the effectiveness of different ranking strategies used in the paper to select the best-performing functions. The strategies are: functional consensus, self-testing, and random selection. The Pass@k metric is used to evaluate the top k functions. The results suggest that the functional consensus approach is superior to both the self-testing method and random selection.
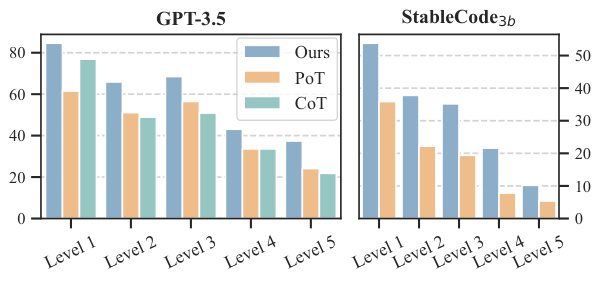
This figure presents the results of two studies. (a) shows a preliminary analysis of the reliability of self-testing in code generation. LLMs were used to generate unit tests for programs, and these programs were then evaluated on these generated tests. The results show that the pass rate on these self-generated tests was much lower than on actual system tests. (b) compares the effectiveness of different ranking strategies in selecting the best program from a set of candidates. Three strategies were compared: functional consensus, self-testing, and random selection. The results demonstrate that functional consensus provides superior performance in identifying high-quality programs, particularly in Pass@k evaluation metrics.
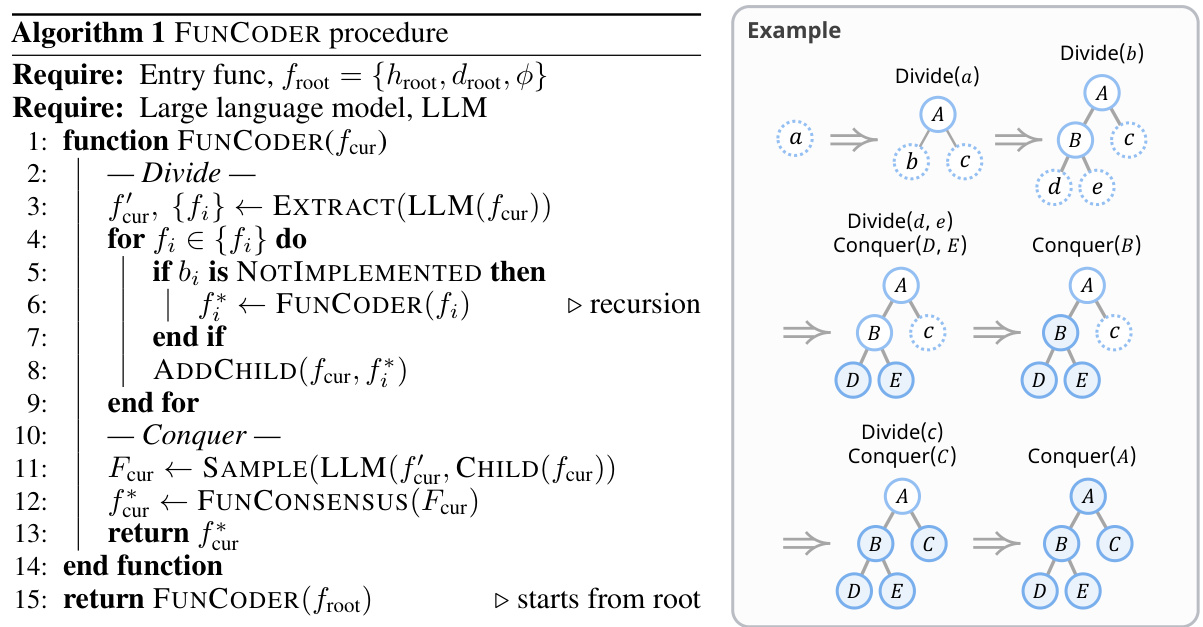
This figure illustrates the FUNCODER framework. The left side shows the divide-and-conquer strategy where the main function is recursively broken down into smaller sub-functions represented in a tree hierarchy. The right side depicts the consensus mechanism, where multiple implementations of sub-functions are generated and the best one is selected based on functional similarity. The bottom-right shows how FUNCODER generates code by writing functions at different hierarchical levels.
More on tables
This table presents the performance of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various benchmarks (HumanEval, MBPP, xCodeEval) using two different large language models (GPT-3.5 and GPT-4). Pass@1 represents the percentage of test cases where the generated code passed on the first attempt. The table shows the improvement of FUNCODER over existing state-of-the-art methods, highlighting its superior performance across multiple benchmarks and models.

This table presents the results of experiments conducted on code generation benchmarks using various models and methods. The Pass@1 metric, representing the percentage of test cases passed on the first attempt, is used to evaluate performance. The table compares the performance of FUNCODER against several baseline methods, including standard prompting, CodeT, Reflexion, and MetaGPT, across benchmarks like HumanEval, MBPP, and xCodeEval. The results for different models (GPT-3.5, GPT-4, Llama, StableCode, and CodeLlama) are shown, highlighting FUNCODER’s improvements in accuracy.

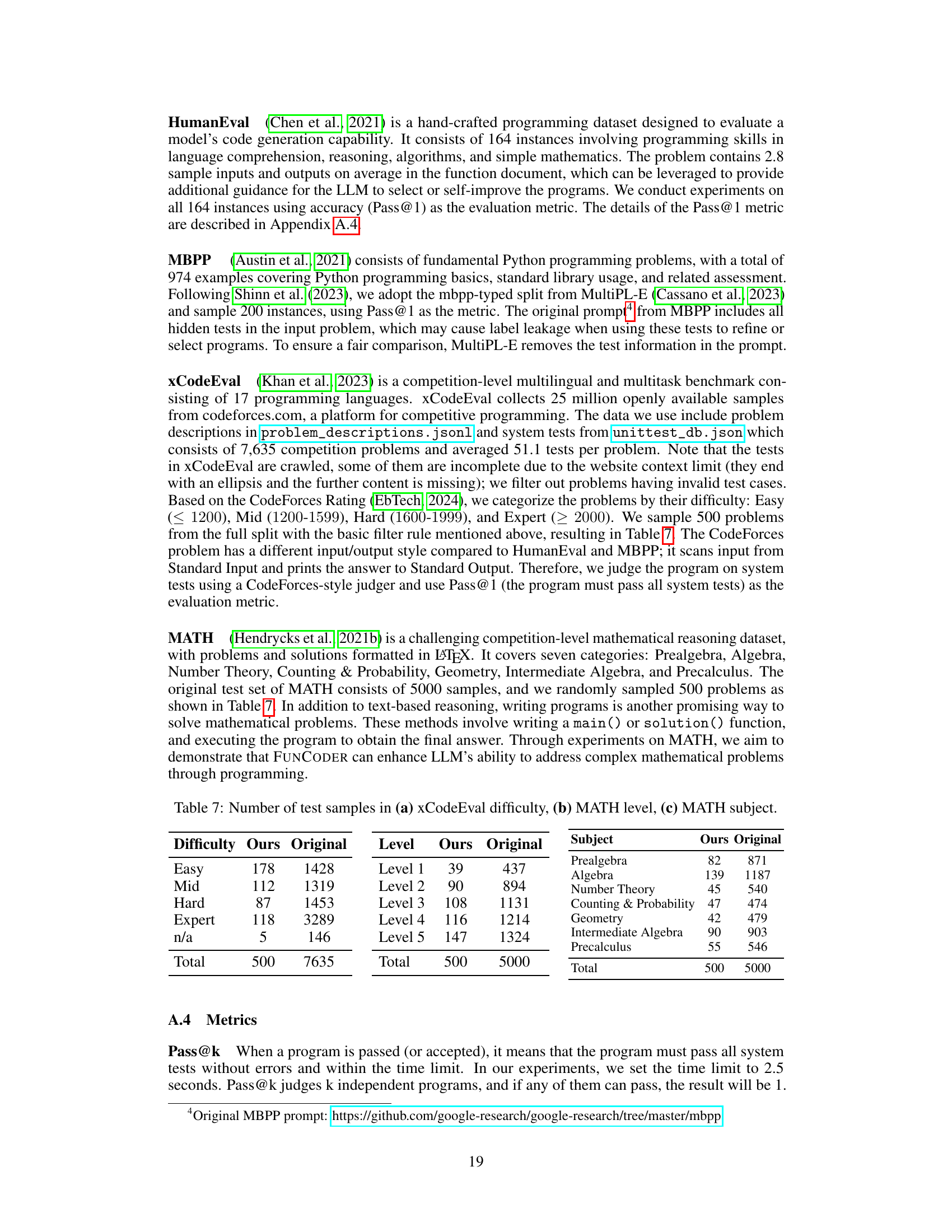
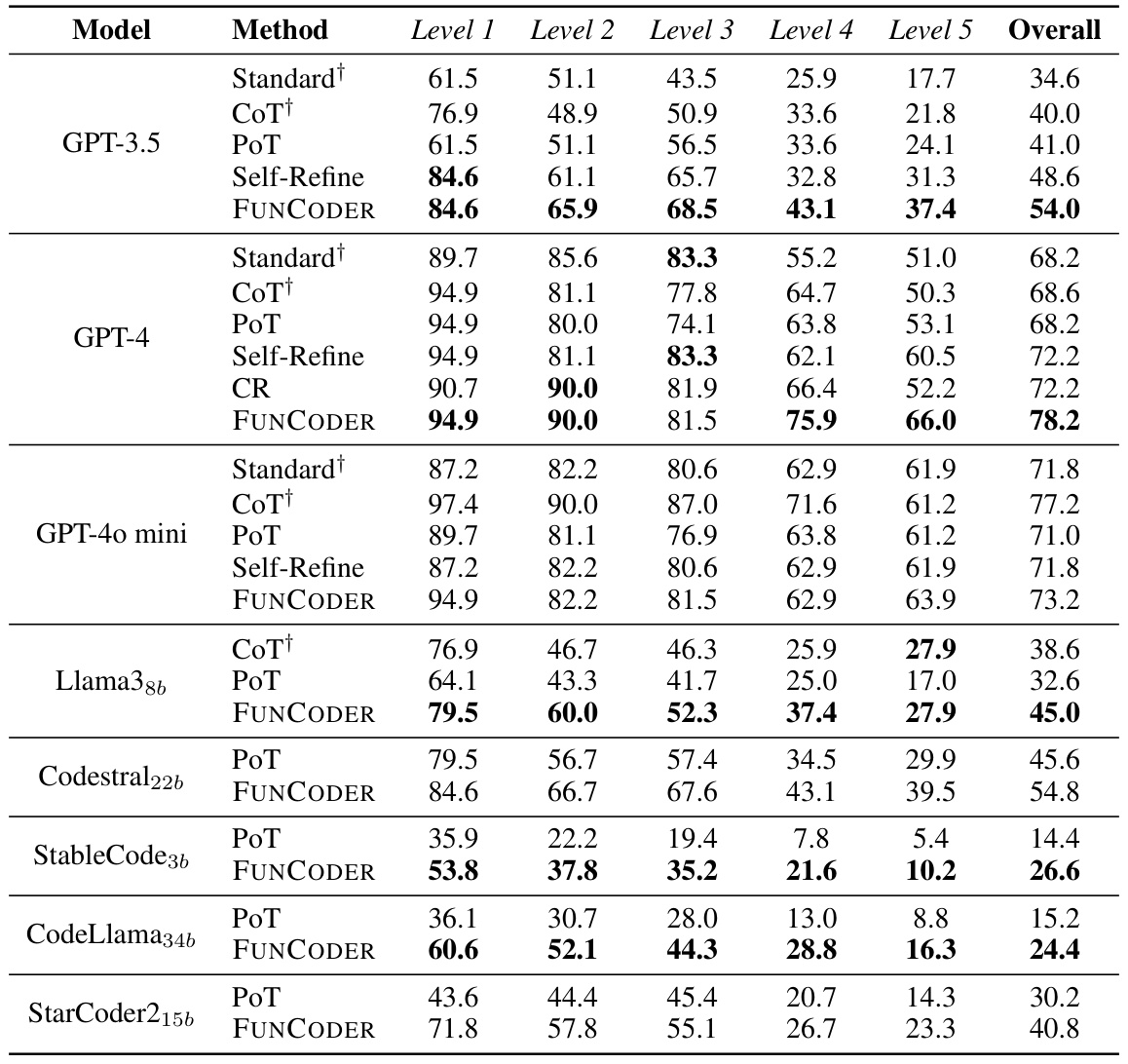
This table presents the performance comparison of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) using various language models (GPT-3.5, GPT-4, Llama3, StableCode, and CodeLlama) across four code generation benchmarks (HumanEval, MBPP, xCodeEval, and MATH). Pass@1, representing the percentage of test cases where the model generates correct code on the first attempt, is used as the evaluation metric. Results from the original paper are underlined for easy comparison, and the best results for each benchmark and model are highlighted in bold.

This table presents the results of code generation experiments using various models and methods on three benchmarks: HumanEval, MBPP, and xCodeEval. The Pass@1 metric indicates the percentage of test cases where the generated code passed on the first attempt. The table compares the performance of FUNCODER against several baseline methods, including standard prompting, CodeT, and Reflexion. Results are shown for both GPT-3.5 and GPT-4, as well as several open-source models. Underlined values represent results from the original papers, while bolded values indicate the best results achieved in each category.
This table presents the performance comparison of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various models (GPT-3.5, GPT-4, Llama38b, StableCode36, and CodeLlama346) across three benchmarks (HumanEval, MBPP, and xCodeEval). For each model and method, the Pass@1 score (percentage of correctly generated code) is given, along with the improvement (Δ↑) compared to the standard method. The best results for each benchmark are highlighted in bold.

This table presents the results of code generation experiments using various models and methods. It compares the performance of FUNCODER against several baselines across four benchmarks: HumanEval, MBPP, xCodeEval, and a combined ‘All’ score. Pass@1 represents the percentage of test cases where the model correctly generates code on the first attempt. The table shows the improvement of FUNCODER over existing methods. Results from the original paper are highlighted, and the best-performing results are bolded for easy comparison.

This table presents the performance of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various models (GPT-3.5, GPT-4, Llama, StableCode, and CodeLlama) across three benchmarks (HumanEval, MBPP, and xCodeEval). The Pass@1 metric indicates the percentage of correctly generated programs. The table highlights the improvements achieved by FUNCODER compared to other methods on each benchmark and model. Results from the original paper are underlined for comparison, and the best-performing method for each row is shown in bold.
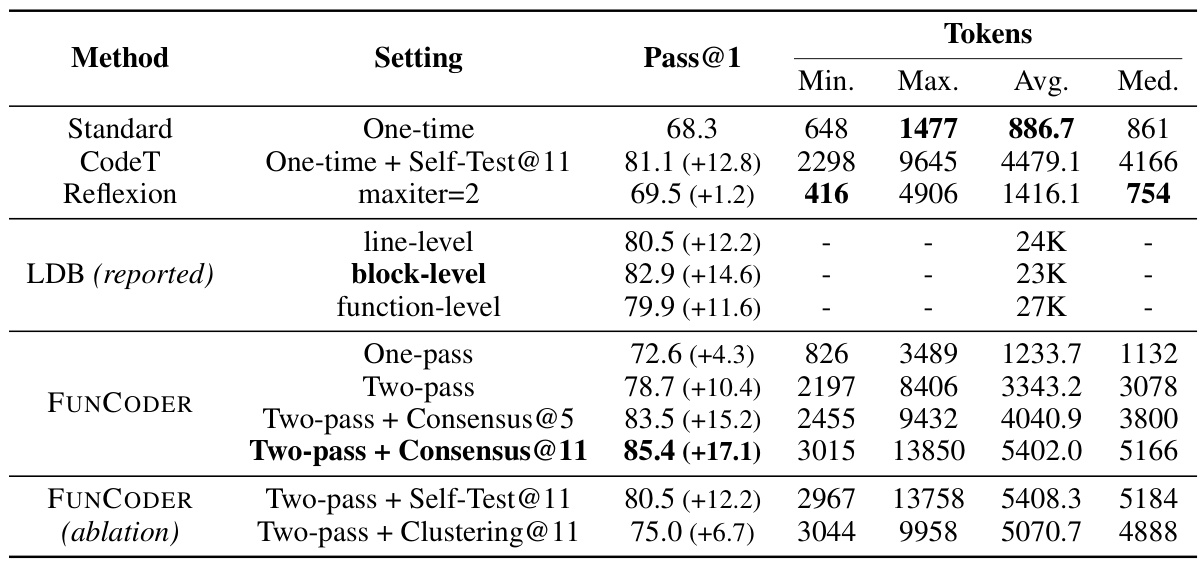
This table presents the performance comparison of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various benchmarks (HumanEval, MBPP, xCodeEval) using two different Language Models (GPT-3.5 and GPT-4). It shows the Pass@1 score (percentage of correctly generated programs) and the improvement (Δ↑) achieved by each method compared to the standard approach for each benchmark. The best result for each model/benchmark combination is shown in bold. Results from other studies are underlined for easy comparison.

This table presents the performance comparison of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various benchmarks (HumanEval, MBPP, xCodeEval) using two large language models (GPT-3.5 and GPT-4). For each model and method, it shows the Pass@1 score (percentage of correctly generated programs), along with the improvement (Δ↑) compared to the standard method. The table highlights the best-performing method for each benchmark and model in bold, illustrating the effectiveness of FUNCODER compared to existing techniques.
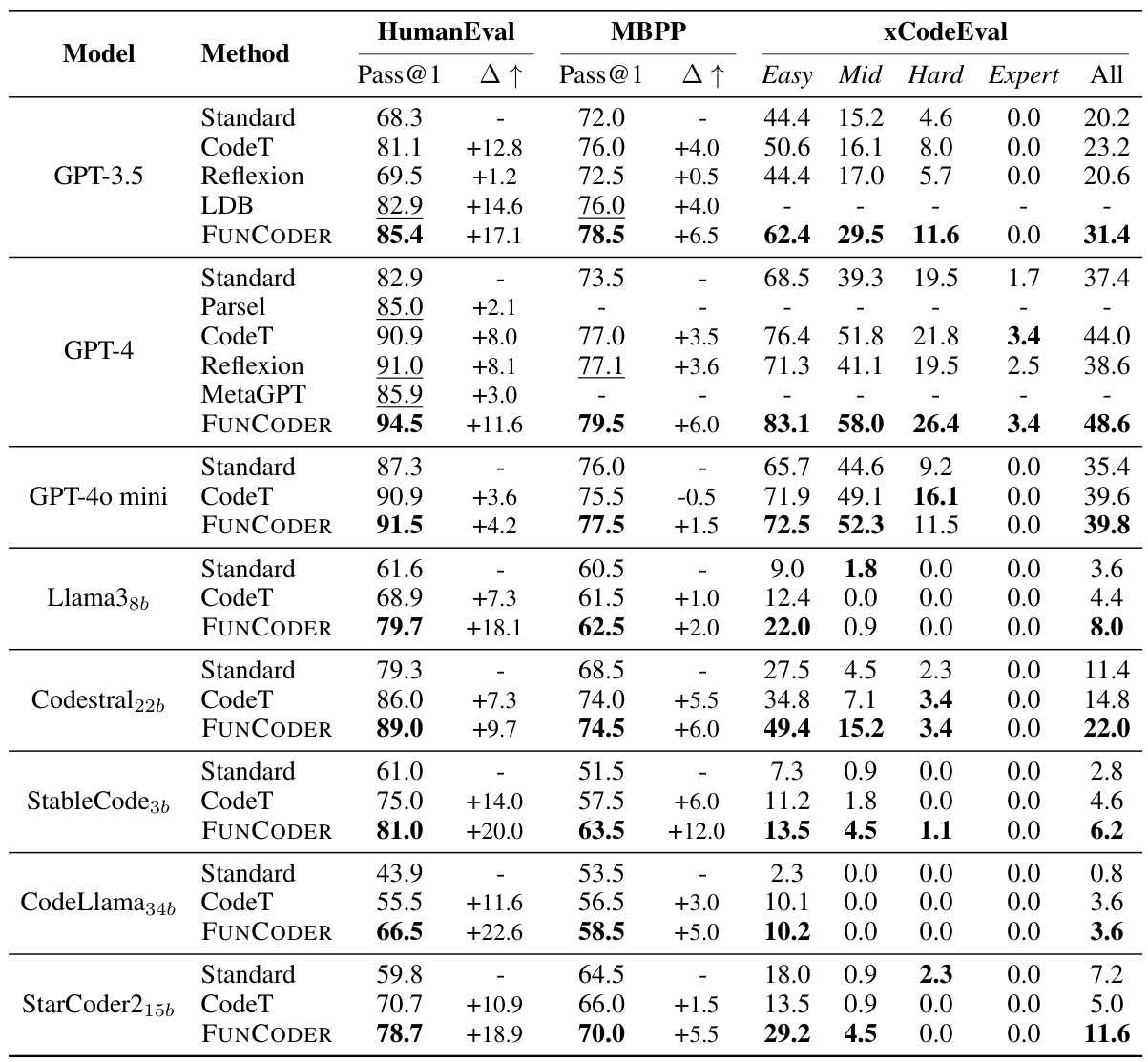
This table presents the performance comparison of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various models (GPT-3.5, GPT-4, Llama3, StableCode36, and CodeLlama346) across multiple benchmarks (HumanEval, MBPP, and xCodeEval). Pass@1 represents the percentage of test cases where the generated code correctly solves the problem on the first attempt. The table shows the improvement of FUNCODER over the baselines across all benchmarks and models. The best performance for each setting is highlighted in bold.

This table presents the performance comparison of different code generation methods (Standard, CodeT, Reflexion, LDB, Parsel, MetaGPT, and FUNCODER) on various models (GPT-3.5, GPT-4, Llama, StableCode, and CodeLlama) across three benchmarks (HumanEval, MBPP, and xCodeEval). The Pass@1 metric indicates the percentage of correctly generated programs. The table highlights FUNCODER’s superior performance compared to other methods, especially on more complex tasks.
This table presents the results of various code generation methods on different benchmarks (HumanEval, MBPP, xCodeEval). It compares the performance of different models (GPT-3.5, GPT-4, Llama, StableCode, CodeLlama) using the Pass@1 metric (the percentage of times the top-ranked generated code passes all the tests). The table highlights the improvement achieved by the proposed FUNCODER method compared to existing state-of-the-art methods. Underlined values indicate results from the original papers being referenced, while bold values are the best results in the table.
Full paper#