↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Traditional policy learning methods heavily rely on numerous real-world interactions, which is often costly and inefficient. This paper addresses this limitation by proposing Policy Learning from tutorial Books (PLfB), a novel approach that leverages the wealth of knowledge already summarized in tutorial books. The key challenge lies in bridging the significant modality gap between textual knowledge and the policy network.
PLfB tackles this challenge with a three-stage framework: Understanding, Rehearsing, and Introspecting (URI). URI first extracts knowledge from books, then rehearses decision-making trajectories in a simulated environment, and finally distills a policy network. Experiments in Tic-Tac-Toe and football games demonstrate URI’s effectiveness, achieving significant winning rates against existing methods without using any real data. This demonstrates the feasibility and potential of learning policies directly from readily available textual resources.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to policy learning, moving away from the reliance on large amounts of real-world data. This opens up new avenues for research in areas where data collection is expensive or impossible, such as robotics and complex simulations. It also highlights the potential of LLMs in extracting and using knowledge from textual resources for AI tasks.
Visual Insights#
This figure compares policy learning from real-world data (A) with policy learning from tutorial books (B). Panel (A) shows a traditional RL approach where a policy network is trained using data collected from interactions in the real world. Panel (B) shows the PLfB approach, which leverages information from tutorial books to directly learn a policy network. Panel (C) details the three-stage learning methodology for PLfB: Understanding (extracting knowledge from the tutorial book), Rehearsing (generating imaginary trajectories), and Introspecting (distilling a policy network from the imaginary data).

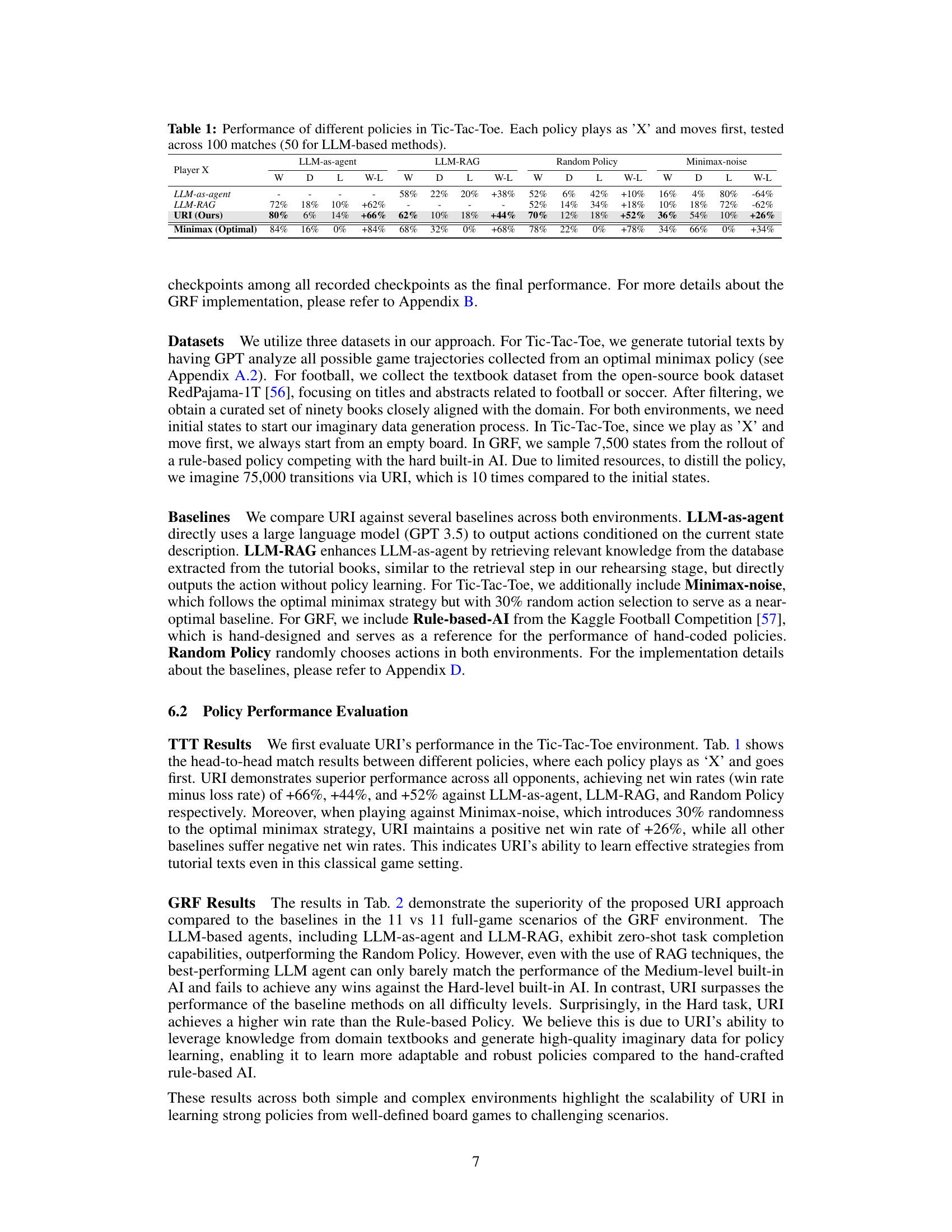
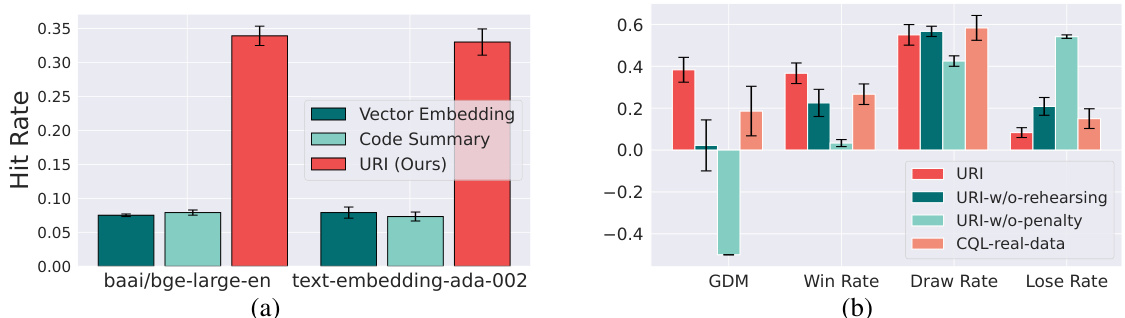
This table presents the win, draw, loss rates and net win rates of different Tic-Tac-Toe playing policies. Each policy starts as ‘X’ and goes first. The policies compared are LLM-as-agent, LLM-RAG, URI (the authors’ proposed method), Minimax (optimal policy), and a Minimax policy with added noise. The table shows the head-to-head performance of each policy against the others, highlighting URI’s superior performance in achieving high net win rates against various baselines, even when compared to a near-optimal policy with added randomness.
In-depth insights#
PLfB Framework#
The PLfB (Policy Learning from Books) framework presents a novel approach to policy learning, drawing inspiration from how humans learn from tutorials. Its core innovation lies in leveraging Large Language Models (LLMs) to bridge the gap between textual knowledge and the creation of effective policy networks. Instead of relying on extensive real-world interactions, the framework uses a three-stage process: Understanding, which extracts and structures knowledge from tutorial books; Rehearsing, which generates synthetic data through imaginary gameplay; and Introspecting, which refines the generated policy network using offline reinforcement learning techniques to account for inaccuracies in the simulated data. This approach is particularly valuable in scenarios where real-world data is expensive, dangerous, or impossible to acquire, offering a path to efficient and generalized offline policy learning.
URI Methodology#
The URI (Understanding, Rehearsing, Introspecting) methodology is a novel three-stage framework for policy learning directly from tutorial books. The Understanding stage leverages LLMs to extract and structure knowledge from the text, creating a knowledge base. This is crucial as it translates human-readable instructions into a format usable by the machine learning model. The Rehearsing stage is equally important; it uses the knowledge base to generate simulated interactions within the game environment, creating a synthetic dataset. This process mimics human learning by allowing the agent to practice decision-making without the cost and limitations of real-world interactions. Finally, the Introspection stage refines the learned policy using offline reinforcement learning techniques on the simulated dataset. This step addresses potential inaccuracies in the simulated data and helps produce a more robust and effective policy. The entire framework demonstrates a powerful approach to bridging the gap between textual knowledge and reinforcement learning, enabling agents to learn complex skills from readily available resources.
LLM-based Learning#
LLM-based learning represents a paradigm shift in how we approach AI, moving away from traditional methods that heavily rely on large, meticulously labeled datasets. Large Language Models (LLMs), pre-trained on massive text corpora, offer the potential to learn complex tasks with significantly less data. This is achieved by leveraging the knowledge implicitly encoded within the LLM’s weights, allowing for few-shot or even zero-shot learning. Instead of training a model from scratch, LLM-based approaches often involve fine-tuning a pre-trained LLM on a smaller, task-specific dataset or using the LLM to generate synthetic data for training other models. The key advantage lies in the potential for faster development cycles and reduced reliance on extensive data annotation, making LLM-based approaches attractive for domains where data is scarce or expensive to obtain. However, challenges remain, including potential biases inherited from the pre-training data, the computational cost associated with using LLMs, and the need for careful prompt engineering to guide the LLM effectively. Further research is crucial to explore the full potential of LLM-based learning while mitigating these limitations.
Experimental Results#
A thorough analysis of the ‘Experimental Results’ section would delve into the methodologies used, the metrics chosen, and the extent to which the results support the paper’s claims. It’s crucial to evaluate the statistical significance of the findings, looking for p-values, confidence intervals, and effect sizes. Any limitations of the experimental design or potential biases should be critically examined. A comparison to prior work or established baselines is necessary to demonstrate the novelty and impact of the results. Furthermore, a discussion of unexpected findings or discrepancies between expected and actual results is needed. Visualizations (graphs and tables) should be assessed for clarity and accuracy, making sure they appropriately convey the information. Ultimately, a strong ‘Experimental Results’ section provides a robust validation of the hypotheses, paving the way for a convincing and reliable contribution to the field.
Future of PLfB#
The future of Policy Learning from Books (PLfB) is bright, with immense potential for advancement. Further research should focus on enhancing the integration of multimodal data, such as videos and audio tutorials, to create a richer learning environment beyond textual information. Improving the robustness of LLMs is crucial; current limitations in hallucination and inconsistency can hinder accurate knowledge extraction and policy generation. Developing more sophisticated methods for handling uncertainty in the imaginary data generated during the rehearsing phase is vital for reliable policy distillation. The development of benchmark tasks that span a wider range of complexity and real-world applicability is necessary to demonstrate PLfB’s scalability and generalizability beyond simple games. Addressing the ethical considerations surrounding biases in LLMs and ensuring fairness in generated policies is paramount. Ultimately, the success of PLfB hinges on overcoming these challenges and expanding its capabilities to tackle increasingly complex decision-making tasks in diverse real-world applications.
More visual insights#
More on figures
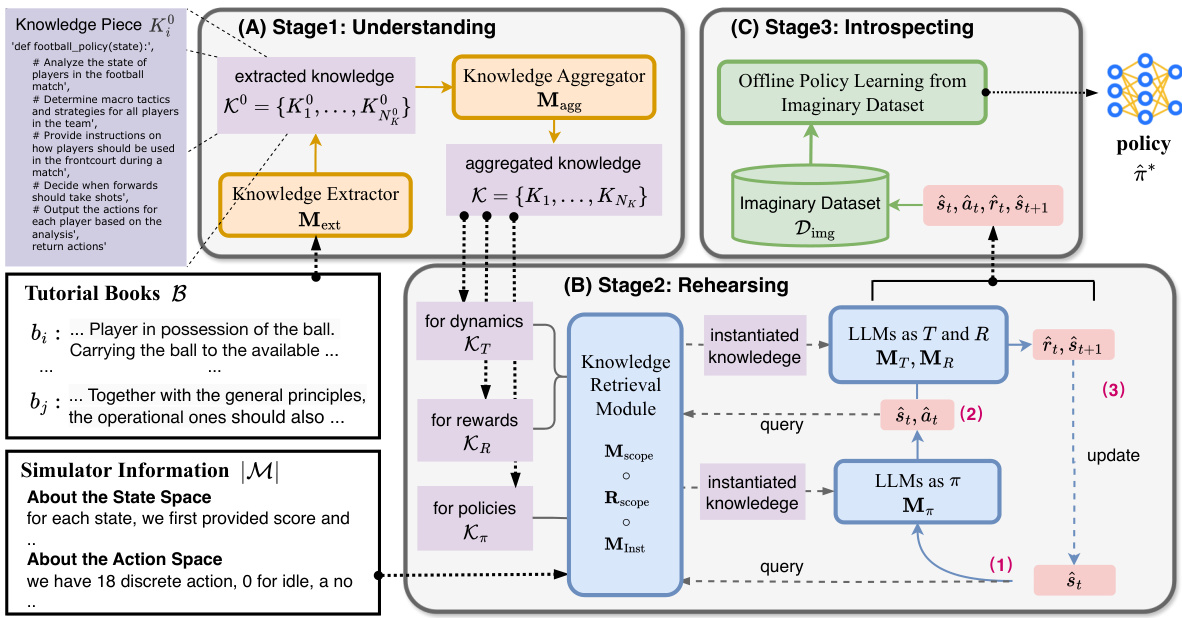
This figure illustrates the three main stages of the URI (Understanding, Rehearsing, and Introspecting) framework for Policy Learning from Tutorial Books (PLfB). Stage 1 (Understanding) shows how knowledge is extracted from tutorial books and organized into a pseudo-code knowledge database. Stage 2 (Rehearsing) depicts the use of this database to generate an imaginary dataset via simulated interactions using LLMs to model the policy, dynamics, and reward functions. Finally, Stage 3 (Introspecting) demonstrates how offline reinforcement learning is used to refine the policy based on the imaginary dataset, addressing inaccuracies in the simulated data.
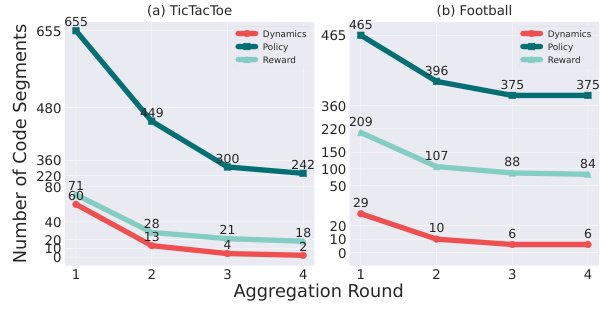
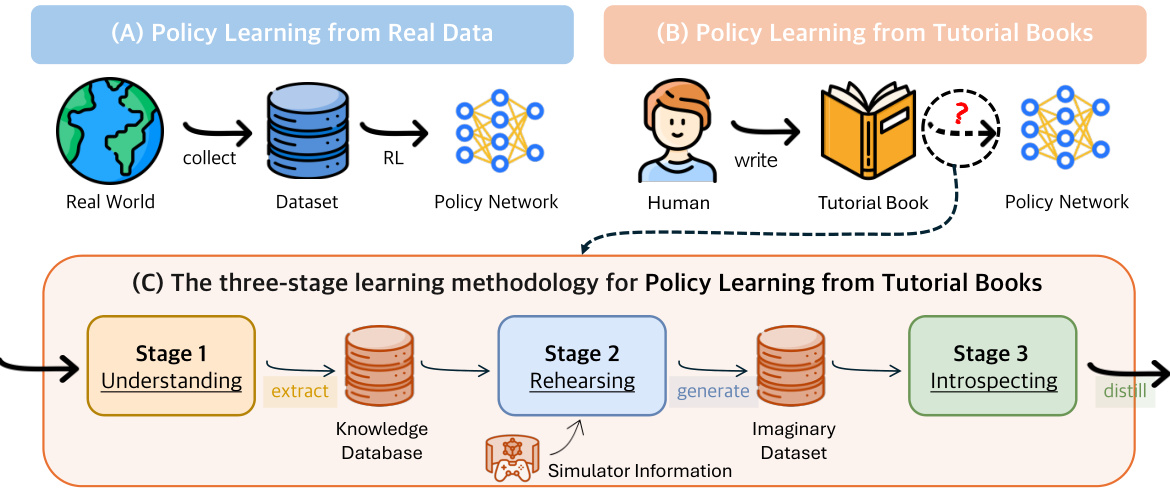
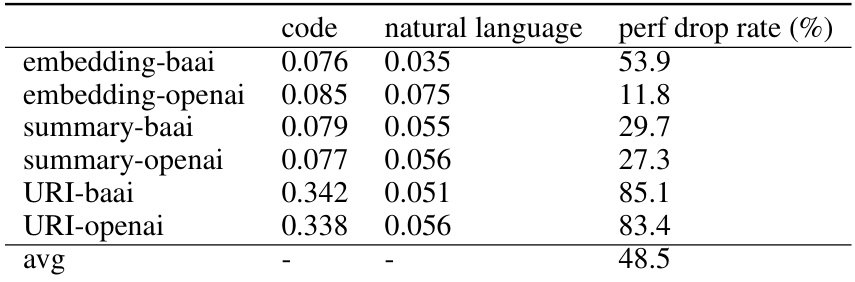
This figure shows the number of code segments at each aggregation round during the knowledge aggregation process for both Tic-Tac-Toe and Football games. It illustrates how the iterative aggregation process effectively consolidates the initial large number of code segments into a smaller, more concise representation of the knowledge. The reduction in the number of segments highlights the effectiveness of the aggregation process in refining and summarizing the extracted knowledge from tutorial books.
This figure illustrates the three-stage learning methodology for Policy Learning from Tutorial Books (PLfB) proposed in the paper. Stage 1 (Understanding) extracts knowledge from tutorial books and structures it into a pseudo-code knowledge database. Stage 2 (Rehearsing) uses this database to generate imaginary datasets by simulating decision-making trajectories. Finally, Stage 3 (Introspecting) refines the policy network by learning from the imaginary data, correcting any inconsistencies or errors.

This figure illustrates the three-stage learning methodology for Policy Learning from Tutorial Books (PLfB). Stage 1 (Understanding) extracts knowledge from tutorial books and organizes it into a structured knowledge database. Stage 2 (Rehearsing) uses this database to generate imagined decision-making trajectories with the help of LLMs. Finally, Stage 3 (Introspecting) uses these trajectories to refine a policy network for decision-making.

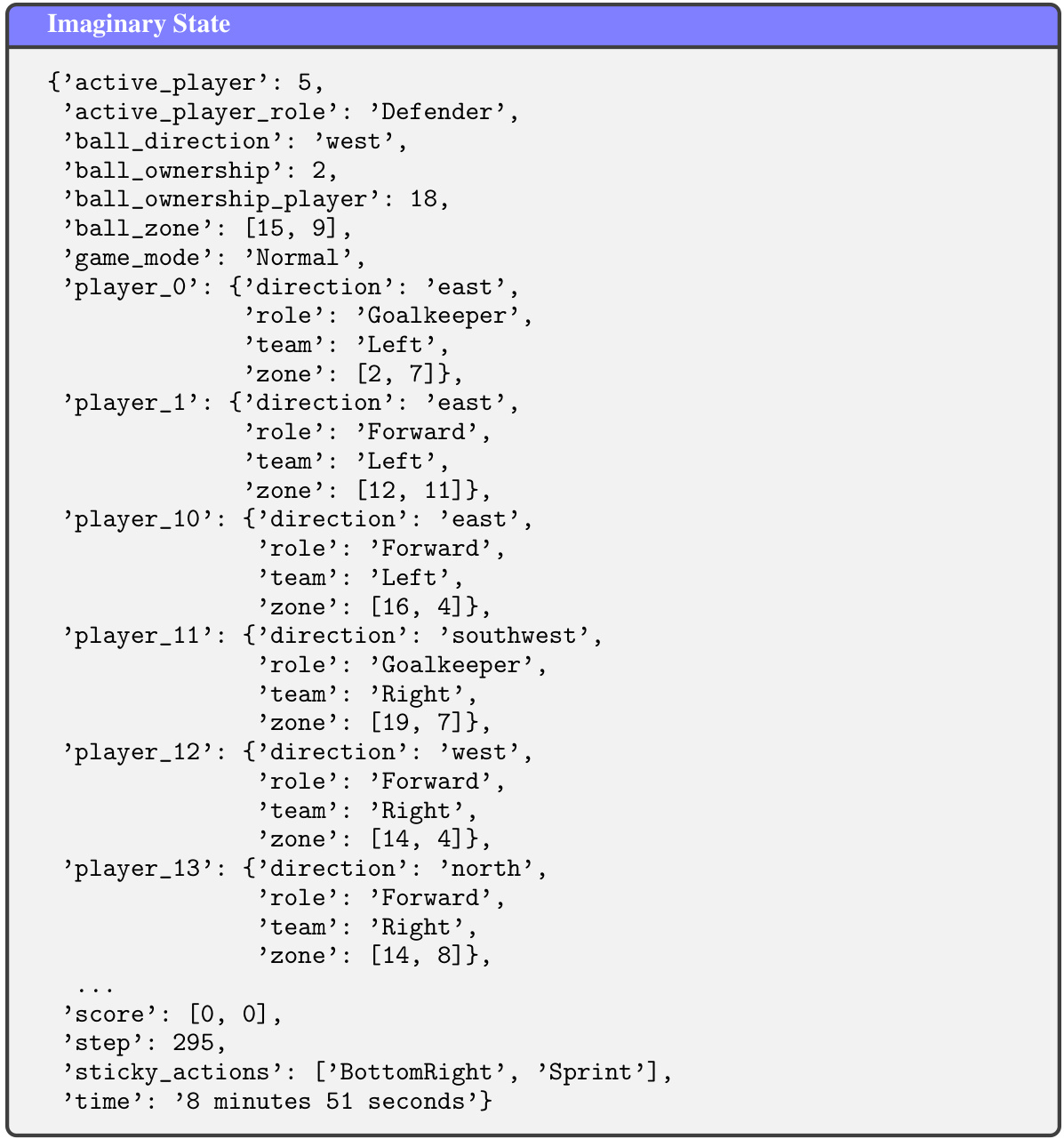
This figure visualizes the results of t-SNE dimensionality reduction applied to real and imaginary datasets from the Google Research Football environment. The real data points represent trajectories collected from a rule-based policy. The imaginary data points are generated by the URI method and are further categorized into ’low-uncertainty’ and ‘high-uncertainty’ subsets based on uncertainty estimates (RT and RR). The figure shows a 2D projection of the high-dimensional data, highlighting the similarity in distribution between real and imaginary data, while also identifying areas where the imaginary data deviates significantly, indicating uncertainty.
This figure compares policy learning from real-world data (using reinforcement learning) with policy learning from tutorial books. Panel (A) shows the traditional RL approach of collecting data from real-world interactions to train a policy network. Panel (B) illustrates the proposed approach, where a policy network is learned directly from tutorial books. Panel (C) details the three-stage learning methodology: understanding (extracting knowledge from the books), rehearsing (generating imaginary trajectories using the knowledge), and introspecting (distilling a policy network from the imaginary data).
This figure compares traditional policy learning from real-world data with the proposed method, Policy Learning from tutorial Books (PLfB). (A) shows the standard RL approach of collecting data from real-world interactions to train a policy network. (B) shows the PLfB approach which utilizes tutorial books to derive a policy network. (C) details the three stages of the PLfB method: Understanding, Rehearsing, and Introspecting. This framework mimics the human learning process where knowledge is extracted from books (understanding), imaginary scenarios are played out (rehearsing), and the policy is refined based on those scenarios (introspecting).

This figure compares policy learning from real-world data and policy learning from tutorial books. (A) shows the traditional approach of collecting real-world data, training a policy network, and applying it to the real world. (B) shows the proposed method of using tutorial books to generate a policy network. (C) details the three stages of the proposed approach: understanding the information in the books, rehearsing decision-making, and introspecting to improve the network.

This figure compares policy learning from real-world data with policy learning from tutorial books. Panel (A) shows the traditional approach using real-world interaction and RL to generate a policy network. Panel (B) illustrates the novel approach of Policy Learning from Tutorial Books (PLfB), using tutorial books as input. Panel (C) details the three-stage learning methodology of PLfB, which involves understanding the content from the books, rehearsing imaginary decision-making trajectories, and introspecting over those to distill a final policy network.

This figure compares policy learning from real-world data and policy learning from tutorial books. Panel (A) shows traditional policy learning using reinforcement learning (RL) with real-world interactions and data collection. Panel (B) shows policy learning from tutorial books using the proposed method, bypassing real-world interaction. Finally, Panel (C) details the three-stage framework (Understanding, Rehearsing, and Introspecting) used in the proposed method for policy learning from tutorial books.

This figure compares traditional policy learning from real-world data with the proposed method of policy learning from tutorial books (PLfB). Panel (A) shows the standard RL approach where a policy network is trained using data collected from real-world interactions. Panel (B) depicts the PLfB approach where a policy network is learned using only knowledge extracted from tutorial books. Panel (C) illustrates the three-stage learning framework of PLfB: Understanding, Rehearsing, and Introspecting. The diagram shows how knowledge is extracted from the books, used to generate imaginary datasets, and finally distilled into a policy network.

This figure compares policy learning from real-world data using reinforcement learning (RL) with policy learning from tutorial books using the proposed method. Panel (A) shows the traditional RL approach, where data from real-world interactions is used to train a policy network. Panel (B) illustrates the proposed approach, where knowledge from tutorial books is used. Panel (C) details the three-stage learning methodology (Understanding, Rehearsing, Introspecting) used to derive a policy network from the tutorial books.

Figure 1 compares policy learning from real-world data and policy learning from tutorial books. (A) shows traditional policy learning from real-world data through reinforcement learning (RL), where an agent interacts with an environment and learns a policy. (B) shows the proposed policy learning from tutorial books (PLfB), where an agent learns a policy directly from tutorial books. (C) illustrates the proposed three-stage framework for PLfB: Understanding, Rehearsing, and Introspecting.

This figure compares policy learning from real-world data with policy learning from tutorial books. Panel (A) shows a typical reinforcement learning setup using real-world interactions to learn a policy network. Panel (B) illustrates the proposed approach, which leverages tutorial books to learn a policy network without the need for real-world interaction. Panel (C) details the three-stage learning methodology of the proposed approach, including the Understanding, Rehearsing, and Introspecting stages.
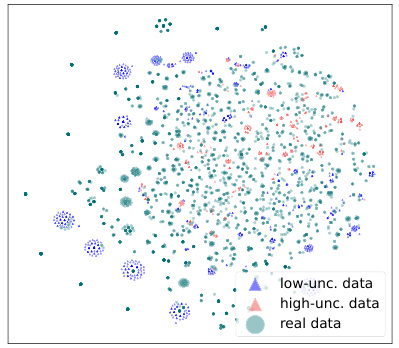
This figure visualizes the results of t-SNE dimensionality reduction applied to real and imaginary datasets from the Google Research Football environment. The ‘real data’ points represent data collected from a rule-based policy. The imaginary data is further split into ’low-unc. data’ (low uncertainty) and ‘high-unc. data’ (high uncertainty) based on uncertainty scores from the model. The visualization shows that the imaginary data generally follows a similar distribution to the real data, indicating that the model successfully generates realistic data. Yellow dashed circles highlight areas where the imaginary data deviates from the real data, indicating where the model’s uncertainty is highest.
More on tables
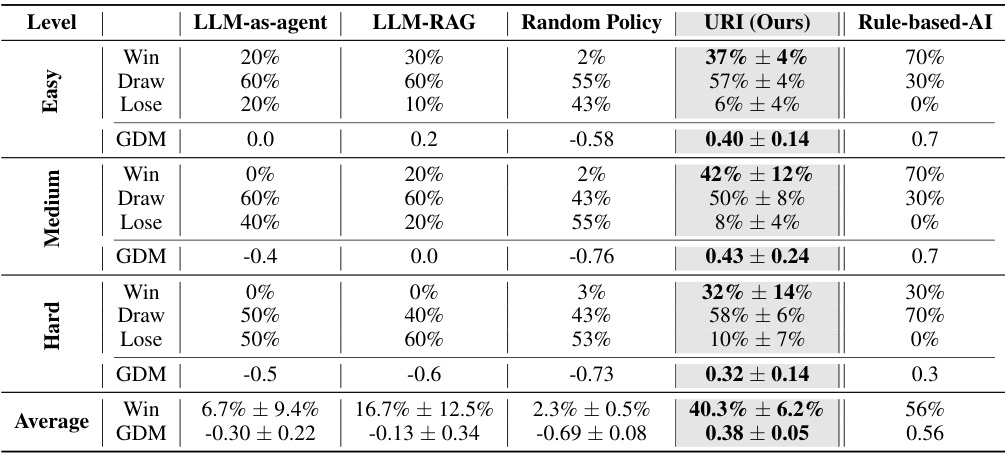
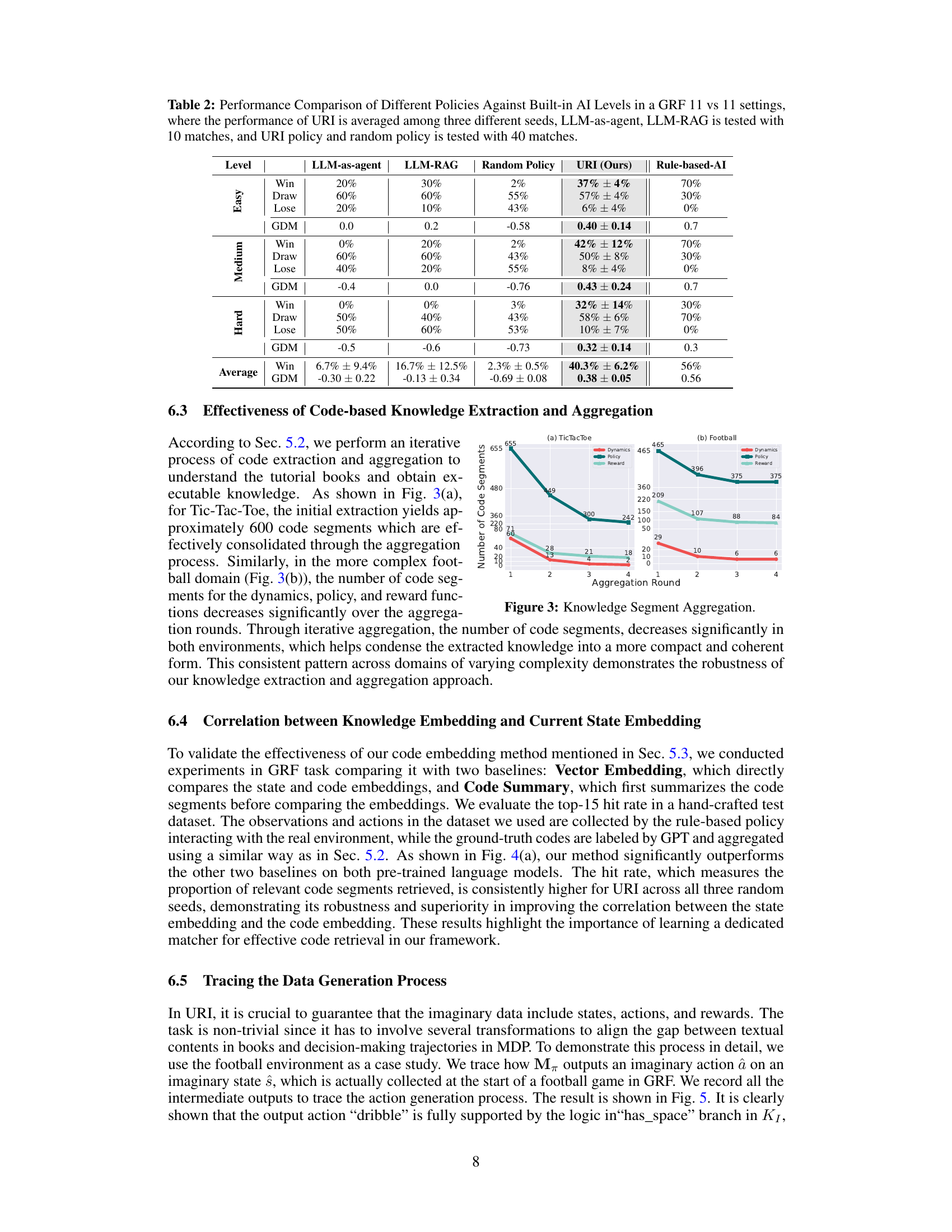
This table compares the performance of different policy approaches against various levels of built-in AI opponents within the Google Research Football (GRF) 11 vs 11 game environment. The policies tested include LLM-as-agent, LLM-RAG, Random Policy, and the proposed URI method. Results are shown in terms of win rate, draw rate, loss rate, and goal difference per match (GDM), averaged over multiple matches for each policy and AI difficulty level.

This table compares the performance of different policy approaches (LLM-as-Agent, LLM-RAG, Random Policy, URI, and Rule-based-AI) against various difficulty levels (Easy, Medium, Hard) of built-in AI opponents in the Google Research Football environment. The table shows win rates, draw rates, loss rates, and goal difference per match (GDM) for each policy and difficulty level. The URI policy’s performance is averaged over three different random seeds.

This table presents the performance comparison of different Tic-Tac-Toe playing policies. Each policy starts as ‘X’ and makes the first move. The results are based on 100 matches played for each policy; however, for LLM-based methods, only 50 matches were used for performance evaluation. The table shows win rate (W), draw rate (D), and loss rate (L) for each policy and the net win rate (W-L) representing the difference between the win rate and loss rate.

This table presents the win rate, draw rate, loss rate, and net win rate for different Tic-Tac-Toe playing policies, including LLM-as-agent, LLM-RAG, URI (the proposed method), Minimax (optimal policy), and Random Policy. Each policy plays as ‘X’ and goes first. The results are based on 100 matches for each policy (50 for the LLM-based methods), demonstrating the relative performance of different approaches in this relatively simple game.

This table presents the performance comparison of different policies in the game of Tic-Tac-Toe. Each policy plays as ‘X’ and makes the first move. The results are based on 100 matches for each policy, with LLM-based methods using 50 matches. The table shows the win rate (W), draw rate (D), loss rate (L), and the net win rate (W-L) for each policy against various opponents. The policies compared include LLM-as-agent, LLM-RAG, URI (the proposed method), Minimax (the optimal policy), and Random Policy.
This table presents the win, draw, loss rates and win-loss difference of different Tic-Tac-Toe policies, tested in 100 matches. Each policy plays as ‘X’ and starts first. The policies include LLM-as-agent, LLM-RAG, the proposed URI method, a minimax policy (optimal strategy), and a noisy minimax policy which adds 30% randomness to mimic imperfect human play. The table shows URI performs comparably to optimal minimax against different opponents while other baseline methods significantly underperform.

This table compares the performance of different game-playing policies in the game of Tic-Tac-Toe. Each policy starts as player X and goes first. The table shows the win, draw, and loss rates for each policy against several opponents. The ‘W-L’ column represents the net win rate (win rate minus loss rate). The results are based on 100 matches for each policy, with 50 matches used for the LLM-based methods.

This table presents the win rate, draw rate, loss rate, and net win rate of different Tic-Tac-Toe playing policies against various opponents. Each policy starts as ‘X’ and makes the first move. The policies compared are LLM-as-agent, LLM-RAG, URI (the authors’ proposed method), Minimax (optimal strategy), and Random Policy. The results highlight the superior performance of URI compared to the other methods.

This table presents a comparison of the performance of different policies (LLM-as-agent, LLM-RAG, Random Policy, URI, and Rule-based-AI) against various difficulty levels (Easy, Medium, Hard) of the built-in AI in the Google Research Football (GRF) 11 vs 11 environment. The URI policy’s performance is averaged across three different random seeds. LLM-as-agent and LLM-RAG were each tested in 10 matches, while the URI and Random policies were each tested in 40 matches. The metrics used for comparison include win rate, draw rate, loss rate, and Goal Difference per Match (GDM).
Full paper#