↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Researchers frequently use surveys to assess large language models (LLMs), comparing their responses to human populations to understand their biases. However, this methodology is flawed because of the systematic biases in LLMs’ responses.
This paper investigates this issue using the American Community Survey, a well-established demographic survey. The authors systematically tested 43 LLMs, finding two dominant patterns: ordering and labeling biases and the tendency of models to produce uniformly random responses when these biases were removed. This challenges the assumption that LLM survey responses accurately reflect human populations.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers using surveys to analyze LLMs because it reveals significant systematic biases in model responses, challenging the validity of existing alignment metrics. It highlights the need for more robust methodologies and opens new avenues for investigating the true capabilities and limitations of LLMs.
Visual Insights#

This figure illustrates the methodology used in the paper. The American Community Survey (ACS) is used as a benchmark to evaluate the responses of large language models (LLMs). The process starts with a question from the ACS, which is then given to a sample of the American population and the aggregate responses are collected. The same question is also posed to an LLM to elicit its response. Finally, the figure asks whether the distribution of the LLM’s responses is comparable to that of the human population. This comparison is central to the paper’s analysis of the models’ alignment to the human responses.

This figure displays the accuracy of a discriminator model in distinguishing between human survey responses (from the ACS) and synthetic responses generated by various language models. The results show that the models’ synthetic responses are easily distinguishable from the human responses, even after adjusting for bias, demonstrating a significant difference in data distributions. The accuracy is compared to a baseline accuracy obtained from distinguishing between the data for individual US states and the remainder of the ACS data.
In-depth insights#
LLM Survey Biases#
The study of Large Language Model (LLM) biases using surveys reveals a critical methodological challenge. Initial findings suggesting that LLMs reflect specific demographic viewpoints are largely confounded by systematic biases inherent in the survey design and LLM response mechanisms. These biases include strong preferences for answers labeled ‘A’ (A-bias) and an influence of answer order, leading to skewed results. When these biases are statistically corrected through methods like randomized answer ordering, LLMs tend toward uniformly random responses, irrespective of model size or training data. This highlights that simple explanations, such as alignment with subgroups having response distributions closest to uniformity, are sufficient to account for many observed trends. The results raise crucial questions about the validity of using surveys to infer LLM alignment with human populations and suggest a need for more robust methodologies to investigate and mitigate these biases in future research. Careful attention must be paid to the design of prompts and methodologies to avoid misleading conclusions about the values and beliefs represented by LLMs.
Prompt Engineering#
Prompt engineering, in the context of large language models (LLMs), is the art and science of crafting effective prompts to elicit desired outputs. Careful prompt design is crucial because subtle changes in wording or structure can significantly impact the model’s response. This paper highlights how even seemingly minor variations, like answer choice ordering or labeling, can introduce systematic biases in LLM responses. The authors demonstrate that models are highly susceptible to these biases, often favoring answers labeled ‘A’ or those listed first, regardless of their semantic meaning. This finding underscores the importance of rigorous methodology in evaluating LLMs, as naive prompting techniques can lead to misleading conclusions about their alignment with human values or demographics. Randomized answer ordering and label randomization are proposed as techniques to mitigate these biases, and the implications of these findings for survey-based alignment metrics are discussed. The research suggests that prior studies might have misinterpreted survey-derived results due to overlooking these systematic prompt-induced biases.
Bias Mitigation#
The concept of bias mitigation is central to responsible AI development, and this paper explores it within the context of large language models (LLMs) and their responses to surveys. The core challenge lies in disentangling genuine model biases from artifacts introduced by survey design and prompting techniques. The authors meticulously investigate the impact of answer ordering and labeling, demonstrating how seemingly minor changes can significantly skew results. Randomizing answer order is proposed as a method to mitigate biases, but its effectiveness is debated, particularly considering that instruction-tuned models still show substantial discrepancies compared to human responses even after such adjustments. The study highlights the complexity of evaluating LLM alignment with human populations, suggesting that simple metrics based on survey data may be inadequate due to confounding factors, and that further investigation is needed to establish better evaluation practices.
Alignment Metrics#
The concept of “Alignment Metrics” in the context of Large Language Models (LLMs) is crucial for evaluating how well a model’s output aligns with human values and intentions. A common approach involves using surveys to gauge the model’s responses on various topics and comparing them to the responses of human populations. However, this paper reveals significant limitations in using survey-based alignment metrics, highlighting inherent biases in LLMs that lead to responses more closely aligned with uniform distributions than with actual human demographics. The study emphasizes the confounding influence of ordering and labeling biases in survey design, showcasing how these biases disproportionately affect the seemingly aligned results. Therefore, simply relying on aggregate statistics from survey-based responses can be misleading. The paper advocates for a more cautious interpretation of alignment metrics, suggesting that existing methods may not accurately capture the desired alignment and may be more reflective of model biases and artifacts than genuine alignment.
Future Directions#
Future research should prioritize addressing the limitations uncovered in this study. Improving the robustness of survey-based LLM evaluation is crucial; this may involve developing new prompting strategies that mitigate systematic biases like ordering and labeling effects. Furthermore, exploring alternative evaluation methodologies that go beyond simple survey responses is necessary. Investigating the relationship between model architecture, training data, and response patterns could unveil deeper insights into how LLMs generate biased answers. Finally, developing techniques to accurately estimate the demographics a model best represents is vital, particularly in light of the limitations of current entropy-based alignment metrics. This could involve statistical modeling, incorporating diverse datasets, or exploring methods to directly measure demographic alignment.
More visual insights#
More on figures
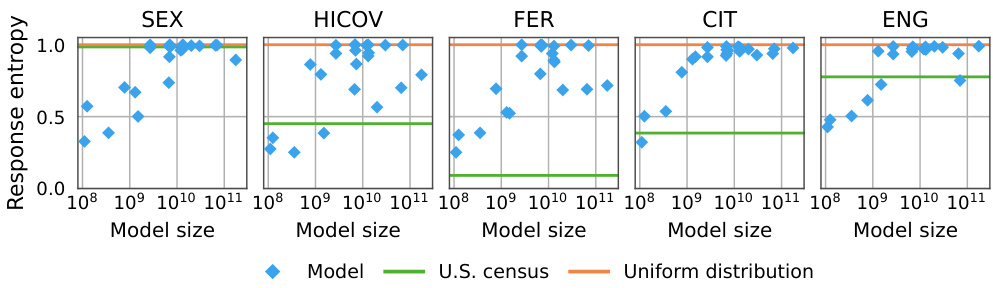
This figure displays the entropy of language model responses to the American Community Survey (ACS) questions. The x-axis represents the model size, and the y-axis shows the entropy of the responses. Each point represents a model’s response to a question. The figure demonstrates that the entropy of model responses generally increases with model size, following a roughly logarithmic trend. This increase in entropy is consistent across all questions, even though the entropy of human responses to the same questions varies substantially. The figure highlights a significant difference between the entropy of language model responses and the entropy of the corresponding U.S. Census data, implying that there might be systematic biases affecting model responses.

This figure shows the entropy of language models’ responses to the American Community Survey (ACS) questions. The top panel (a) displays the entropy for five example questions, demonstrating that the entropy tends to increase with model size. The bottom panel (b) shows this trend across all ACS questions, with model size on the x-axis and normalized response entropy on the y-axis. This figure highlights the substantial differences in entropy between the models and the U.S. census data, indicating that model responses are not reflecting the true distribution of responses in the human population. The models generally show much higher entropy, which suggests that the models are producing responses that are more uniform rather than reflecting the nuances found in the census data.
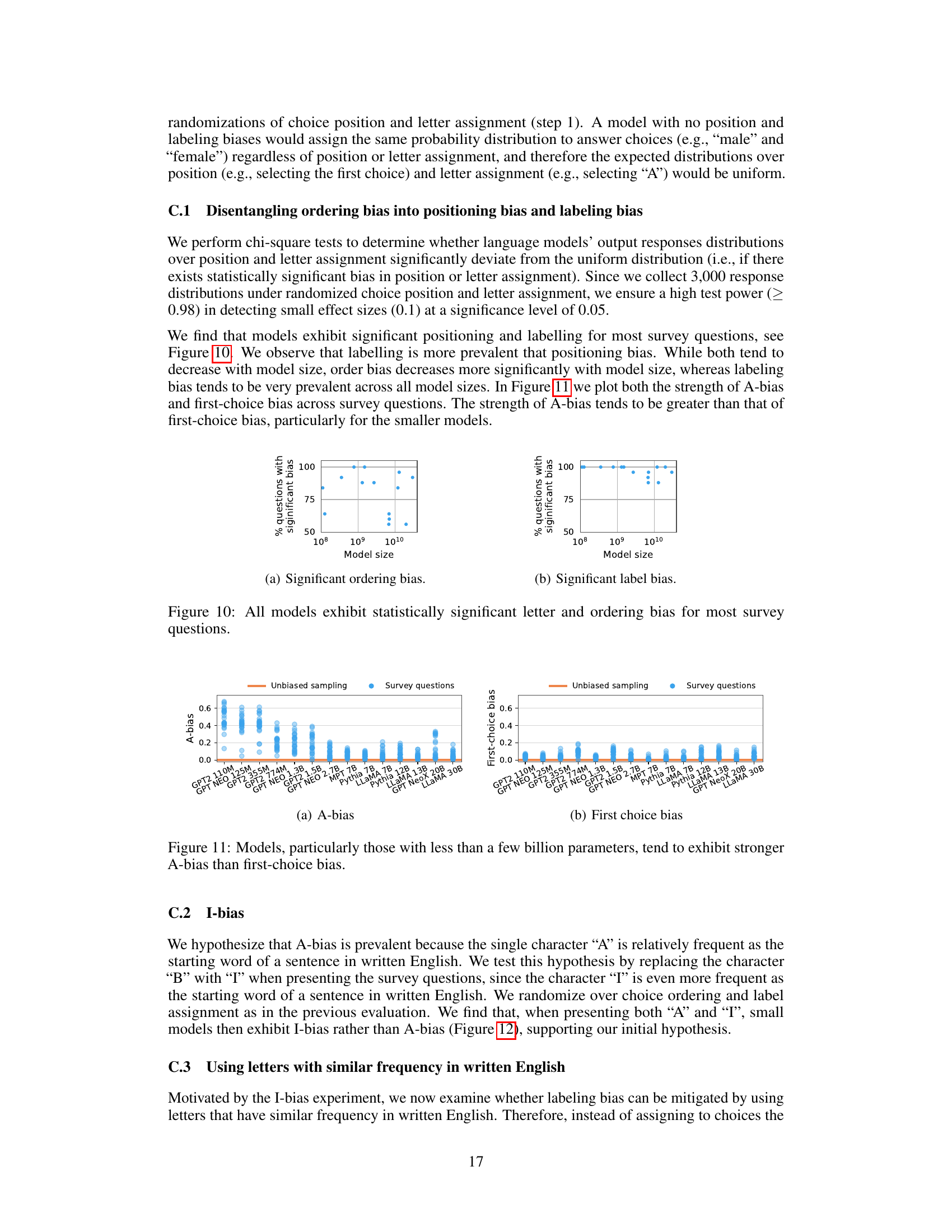
This figure shows the A-bias of various language models across 25 questions from the American Community Survey (ACS). A-bias measures the tendency of a model to select the answer option labeled ‘A’, regardless of the question’s content. Each dot represents a model’s A-bias for a single question. The models are ordered by their size (number of parameters). The figure highlights that all models exhibit a significant A-bias, indicating a systematic bias towards selecting option ‘A’. This bias is not related to the questions’ meaning, but rather to the position and labeling of answer choices.
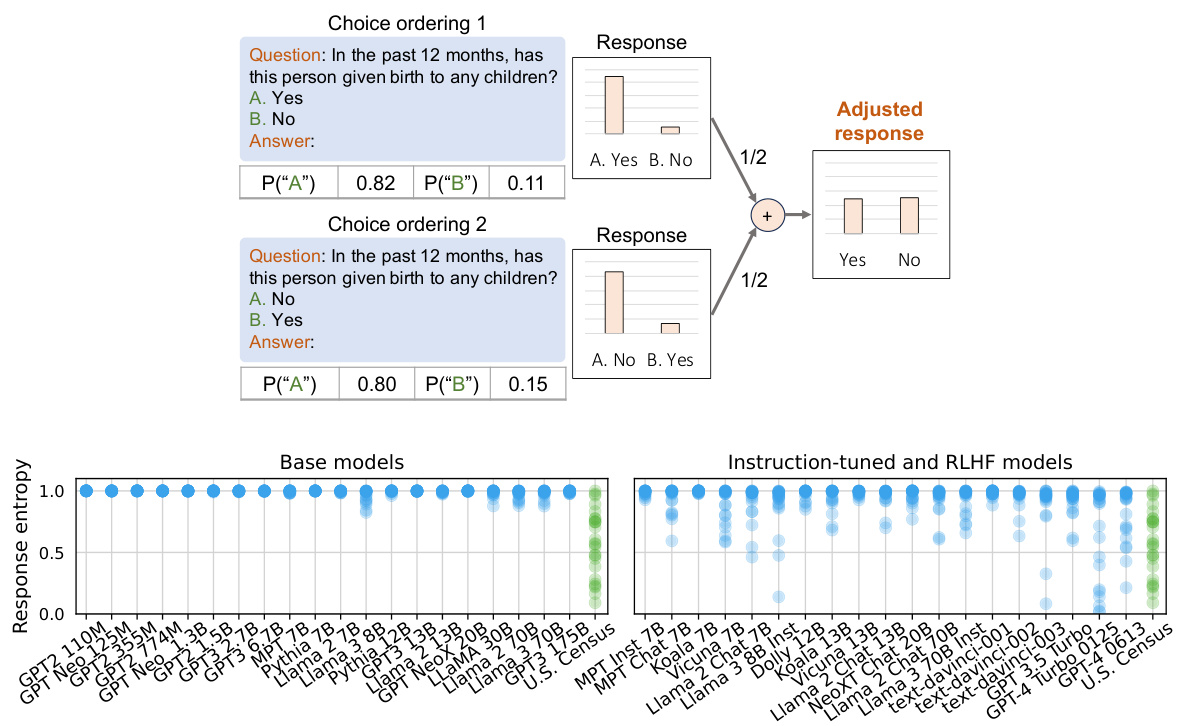
The figure shows the entropy of model responses to the ACS questions after adjusting for ordering bias by averaging responses across all possible answer orderings. The top panel illustrates the adjustment process. The bottom panel shows that after adjustment, base models exhibit nearly uniform entropy across questions, while instruction-tuned models show substantially higher variance in entropy across questions.

This figure displays the KL divergence between adjusted model responses and three different baselines: the overall US census, individual US states, and a uniform distribution. The smaller the KL divergence, the more similar the model’s response distribution is to the baseline. The key finding is that across all models, the adjusted responses are far more similar to the uniform baseline than to any human population (US census or individual states). This highlights the significant difference between model and human response distributions, even when adjusting for systematic biases.

This figure shows the KL divergence between models’ adjusted responses and different census subgroups (U.S. states) plotted against the entropy of the subgroups’ responses. The results reveal a strong negative correlation between the KL divergence and the entropy of the subgroups. This suggests that models are more similar to subgroups with higher entropy (more uniform responses) regardless of model architecture or training methods. This finding indicates that simple entropy, rather than specific demographic features, primarily accounts for alignment.
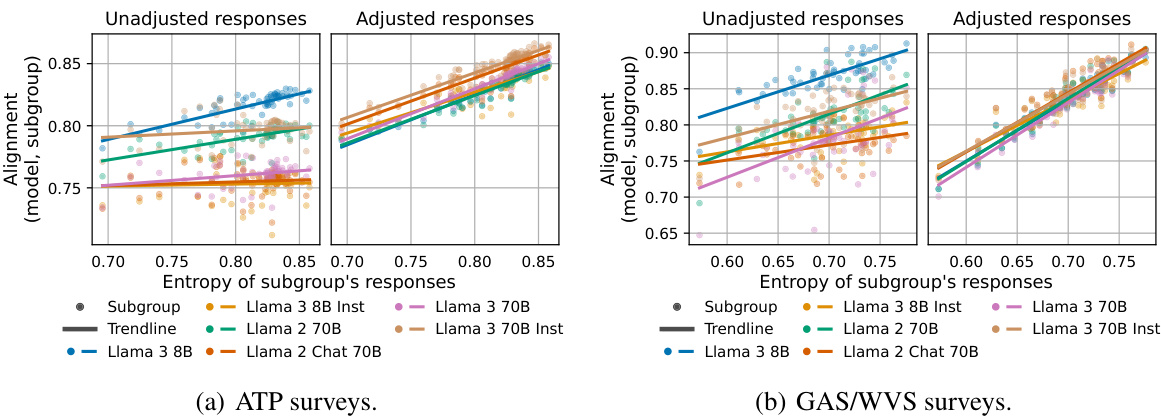
This figure shows the relationship between the alignment of language models with different demographic subgroups and the entropy of those subgroups’ responses. The plots display the Kullback-Leibler (KL) divergence between model responses and various reference populations (overall U.S. census, individual states) for both unadjusted and adjusted model responses. The main observation is that the model’s alignment with a subgroup is strongly correlated with the entropy of that subgroup’s responses, regardless of model size or training method (instruction tuning or RLHF). This suggests that alignment scores primarily reflect the entropy of the reference population rather than genuine model alignment with specific demographic characteristics.

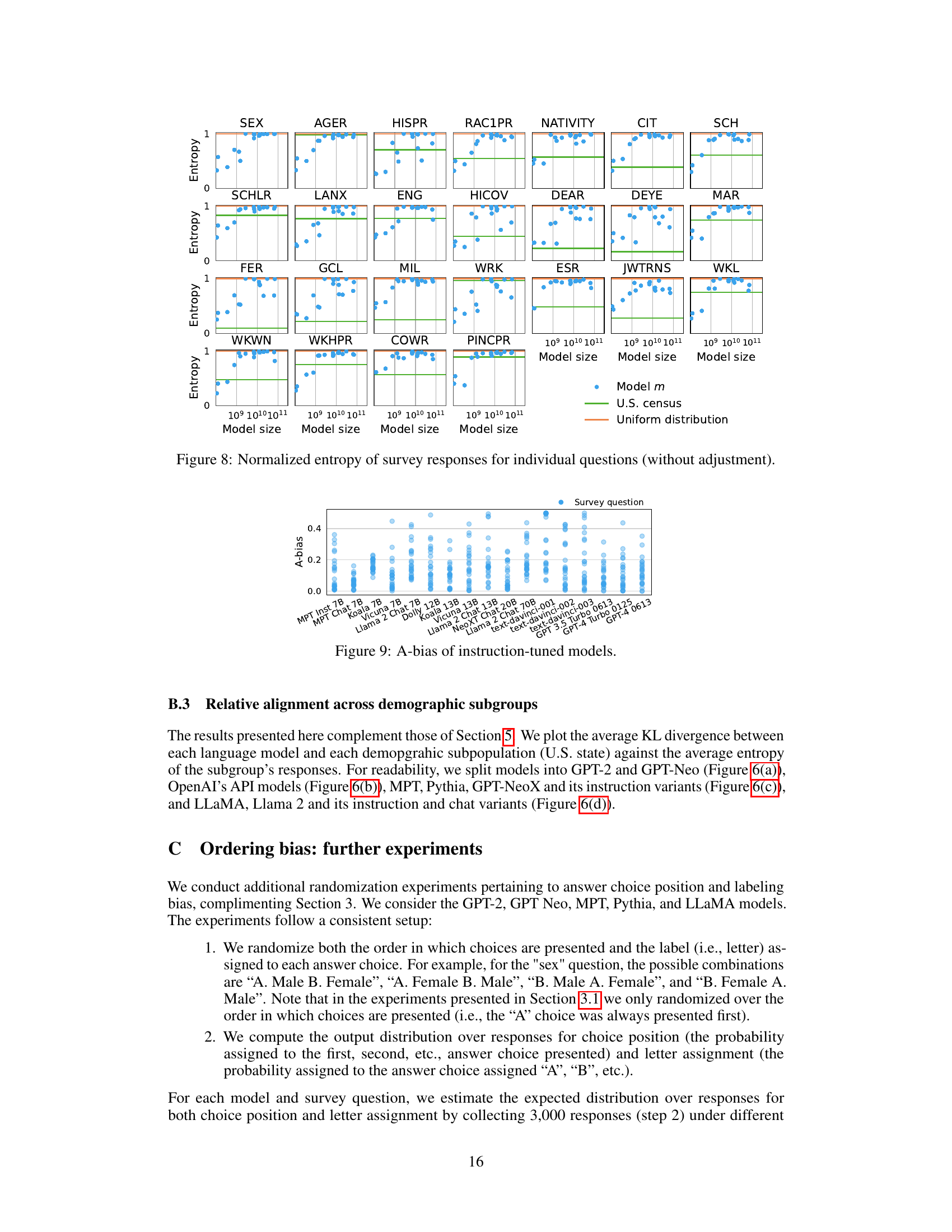
This figure shows the normalized entropy of language models’ responses to individual questions from the American Community Survey (ACS) without adjusting for response biases. The x-axis represents model size, and the y-axis represents the normalized entropy of responses, which ranges from 0 to 1 (0 being completely deterministic and 1 being completely uniform). Each plot corresponds to a different ACS question. The green lines indicate the entropy of the human responses obtained from the U.S. Census, and the orange lines represent the uniform distribution (expected value of entropy if responses were random). The plot shows that the entropy of responses differs substantially across questions, even when the questions are presented independently to the model, and the difference increases with model size.
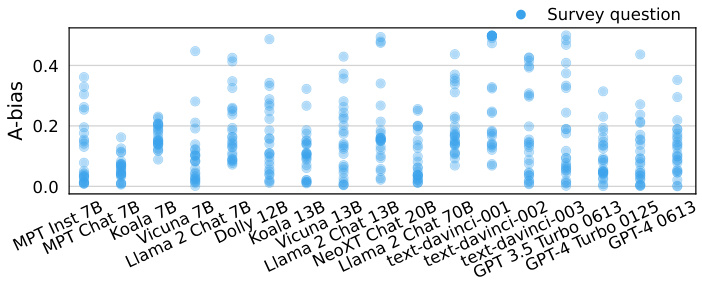
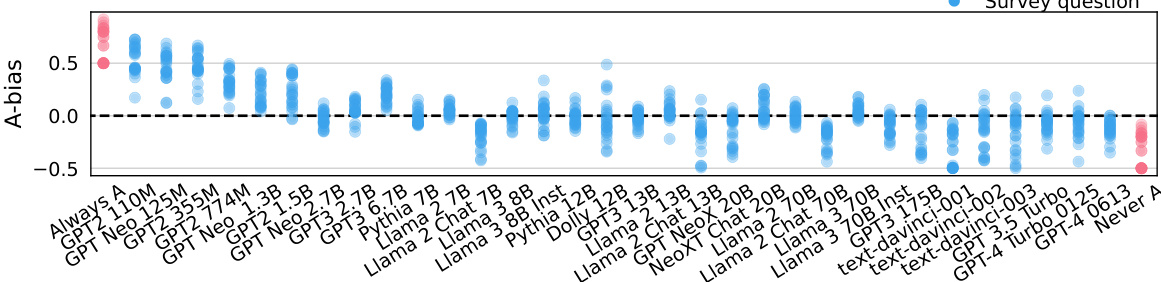
This figure shows the A-bias (the tendency of a model to pick the answer choice labeled ‘A’) for each question and model. Models are ordered by size. The chart illustrates that all models exhibit substantial A-bias, indicating a systematic bias towards selecting the option labeled with ‘A’, regardless of the actual question or model size. This highlights a significant limitation in using survey responses directly from LLMs as a reliable representation of human opinions.

This figure displays two subfigures. Subfigure (a) shows the entropy of responses for five example questions from the American Community Survey (ACS) for different language models. The x-axis represents the model size, and the y-axis represents the normalized entropy of the model responses. The plot shows that the entropy tends to increase with model size, regardless of the inherent variability in responses for each question in the U.S. census data. Subfigure (b) extends this analysis to all ACS questions, showing the same trend of increasing entropy with model size, again highlighting a difference between model responses and the U.S. census distribution.

This figure shows the entropy of language model responses to questions from the American Community Survey (ACS) when prompted in a naive way (without modifications to the prompt or answer order). The top panel shows entropy for five example questions. The bottom panel shows the entropy across all 25 questions for various models of different sizes. The plot highlights that entropy of model responses increases with model size, a trend that is independent of the actual distribution of answers in the US census data. This suggests that other factors (biases) play a larger role than the models’ knowledge about human demographics when considering entropy.

This figure shows the entropy of language models’ responses to questions from the American Community Survey (ACS) when prompted without any randomization of answer order. The top panel (a) displays the entropy for five specific ACS questions, demonstrating that the entropy increases with the model size for each question. The bottom panel (b) shows the entropy across all ACS questions, again demonstrating a log-linear increase in entropy with model size. The U.S. census data is included as a baseline for comparison, revealing that the variability in entropy across the ACS questions is significantly lower for the language models than in the human population represented by the census data.

This figure shows the A-bias (the tendency of models to pick answer choice A) for different language models across 25 questions from the American Community Survey. Each dot represents a model’s A-bias for a single question, with models ordered by size. The extreme values (always answering A and never answering A) illustrate the range of possible A-biases. The figure demonstrates that all language models show a substantial A-bias.

This figure displays two subfigures showing the entropy of the language models’ responses to the American Community Survey (ACS) questions. Subfigure (a) shows the entropy for five specific questions across different model sizes, while subfigure (b) presents the entropy for all ACS questions ordered by model size. The key finding is that the entropy of models’ responses tends to increase log-linearly with model size, a trend that holds regardless of the inherent entropy present in the corresponding U.S. Census data. This suggests a potential systematic bias in the models’ responses rather than a true reflection of the underlying data.
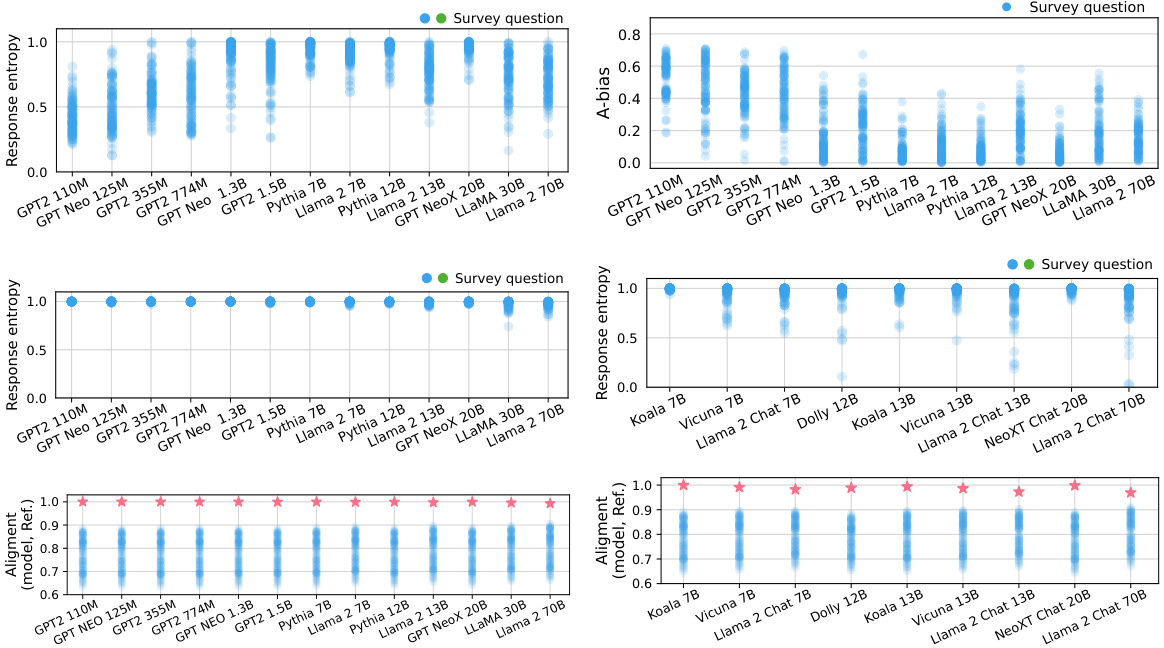
This figure shows the entropy of language models’ responses to American Community Survey (ACS) questions, plotted against the models’ size (number of parameters). The left panel (a) displays the entropy for five specific ACS questions across a range of model sizes. The right panel (b) shows the overall entropy across all ACS questions for various model sizes, highlighting the increase in entropy with model size. The figure also includes the entropy of the U.S. census responses as a reference, demonstrating that models’ responses, even larger ones, exhibit higher variability than those found in actual human responses.
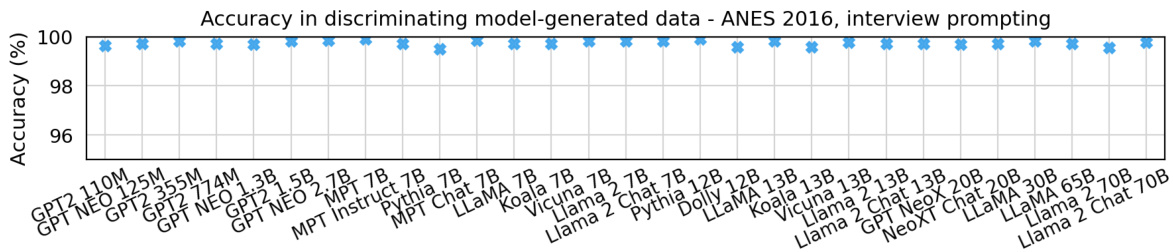
This figure displays the accuracy of a discriminator model in distinguishing between datasets of survey responses generated by various language models and responses from the 2016 American National Election Studies (ANES) survey. The responses were generated using an interview-style prompting method with randomized choice ordering. High accuracy indicates significant differences between model-generated responses and human responses from the ANES dataset. The x-axis lists various language models, and the y-axis represents the accuracy of the discriminator in percentages.
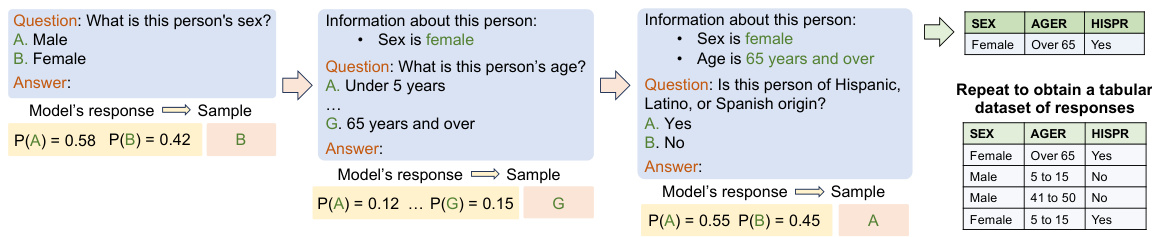
This figure illustrates the methodology used in the paper for sequentially sampling model responses to survey questions. The process begins by asking a single question from the survey. The responses from the model are sampled, and the answer is recorded. This answer, along with the original question, is then included in the next prompt as context. This continues until the entire survey is completed. The result is a tabular dataset containing the models’ responses to all questions in the survey.
Full paper#