↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Visual reprogramming (VR) is a technique that repurposes pretrained models for new tasks by modifying their input or output interfaces. However, current methods often rely on simple one-to-one label mappings, which may overlook complex relationships between the original and new labels and thus limit performance. This research identified this issue as a major drawback of current VR methods.
To overcome this limitation, the paper presents the Bayesian-guided Label Mapping (BLM) method. BLM utilizes a probabilistic mapping matrix to capture the complex relationships between the original and new labels, guided by Bayesian conditional probabilities. Experiments show that BLM significantly improves VR performance across various datasets and models, offering a more flexible and interpretable approach than existing methods. The success of BLM also offers a probabilistic view of VR, showing its promise in improving the interpretability of VR methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on visual reprogramming (VR) and transfer learning. It introduces a novel Bayesian-guided Label Mapping (BLM) method that significantly improves the performance of VR by addressing the limitations of existing one-to-one mapping strategies. This work opens new avenues for research by offering a probabilistic perspective on VR and providing a more interpretable framework for analyzing its effectiveness. The results on multiple datasets and models demonstrate the broad applicability and potential impact of BLM.
Visual Insights#
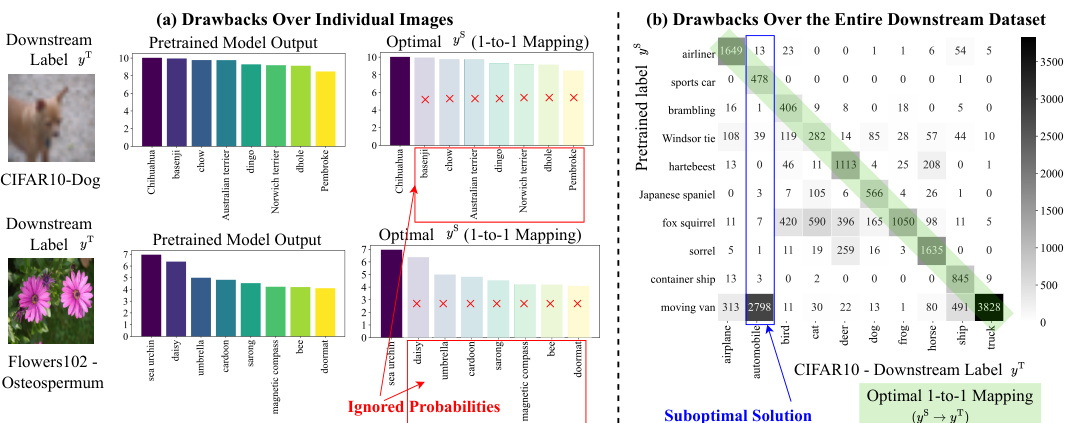
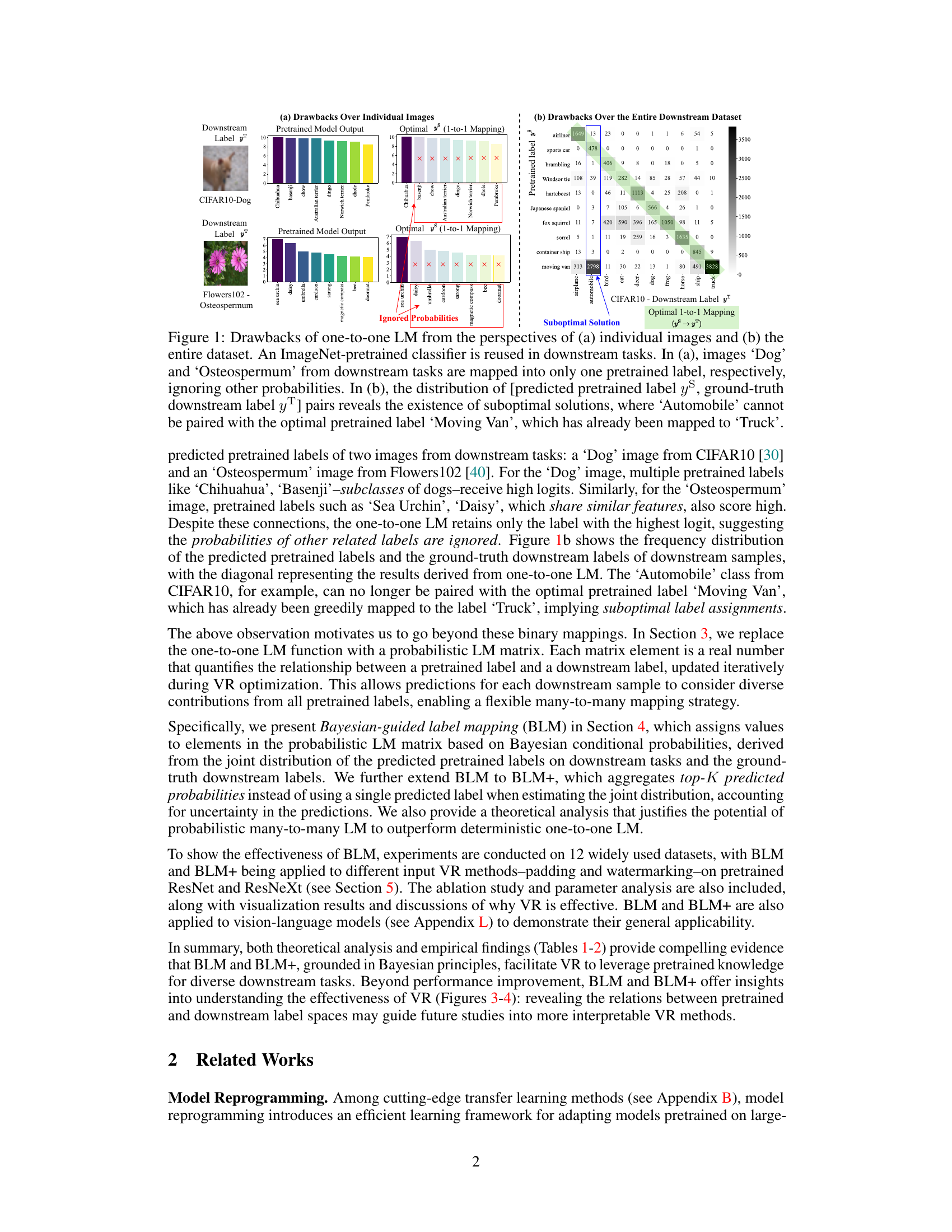
This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows that individual images may have multiple strong activations in the pretrained model’s output, but only one is used in the mapping. Panel (b) shows that using a greedy one-to-one mapping may lead to suboptimal assignments across the dataset, where the best possible mapping isn’t always selected for each downstream label. The examples highlight that one-to-one mappings fail to capture the rich relationships between pretrained and downstream label spaces.

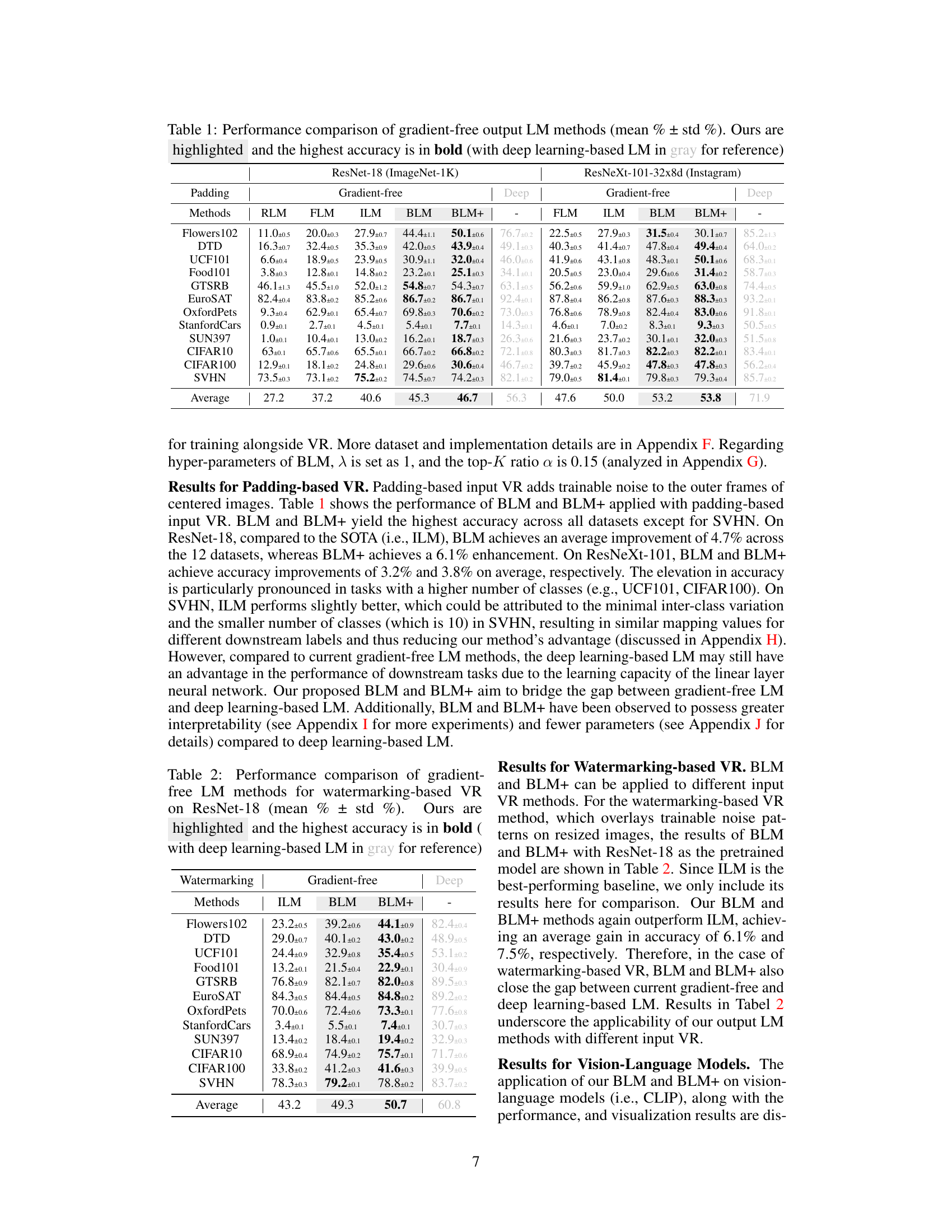
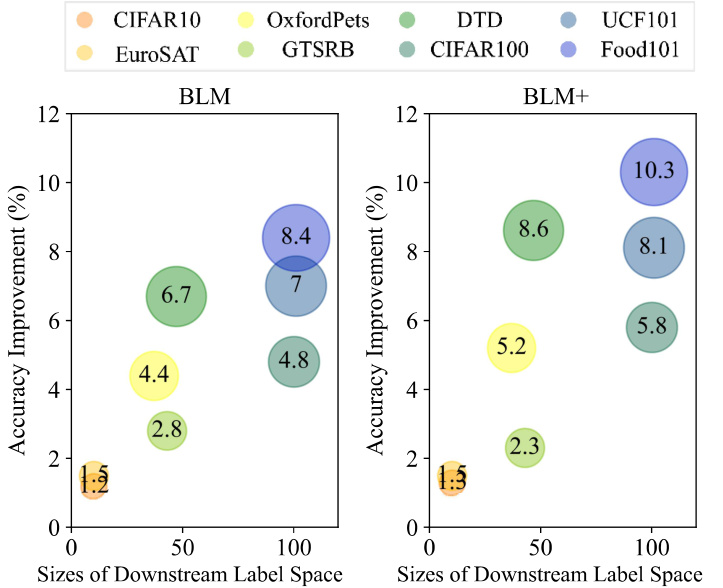
This table compares the performance of different gradient-free output label mapping methods, including the proposed BLM and BLM+, against existing methods (RLM, FLM, ILM) and a deep learning-based approach. The results are shown for various datasets and for both ResNet-18 (pretrained on ImageNet) and ResNeXt-101-32x8d (pretrained on Instagram) as the pretrained models. The table highlights the accuracy and standard deviation for each method on each dataset, indicating the superior performance of BLM and BLM+ in many cases.
In-depth insights#
Bayesian Label Mapping#
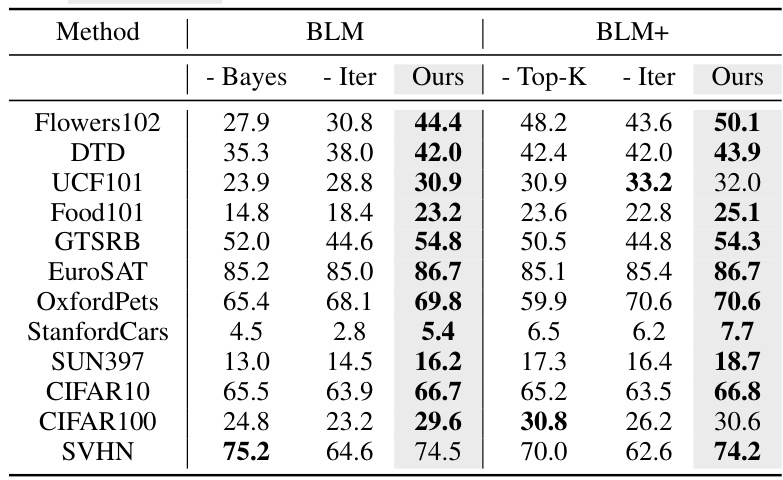
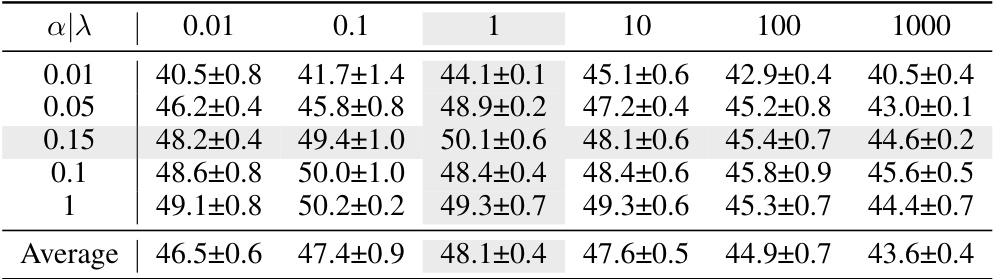
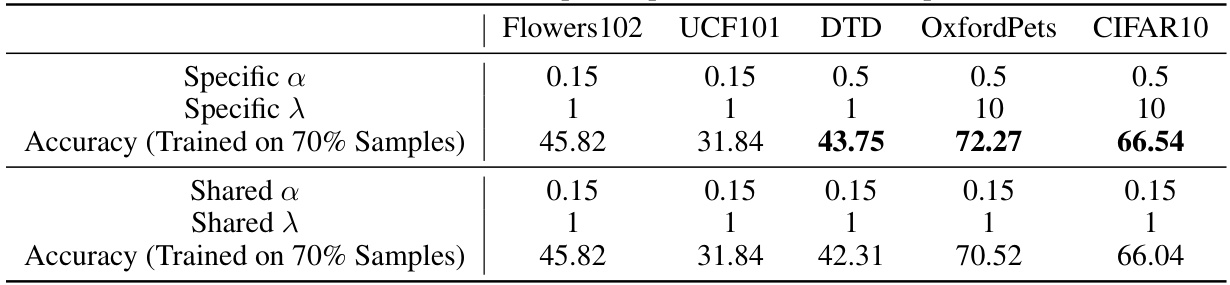
Bayesian label mapping offers a novel approach to visual reprogramming by moving beyond traditional one-to-one mappings between pretrained and downstream labels. It leverages Bayesian conditional probability to construct a probabilistic mapping matrix, where each element quantifies the relationship between individual pretrained and downstream labels. This probabilistic approach accounts for inherent uncertainties and complexities, allowing for flexible many-to-many mappings that outperform deterministic methods. The iterative updating of the matrix further refines the mapping during optimization, improving accuracy and offering a probabilistic lens for understanding visual reprogramming’s effectiveness. This method’s strength lies in its ability to handle complex relationships between labels and its adaptability to various pretrained models and input reprogramming techniques, demonstrating superior performance across diverse tasks and datasets.
Visual Reprogramming#
Visual reprogramming (VR) is a powerful technique that repurposes pretrained models for new tasks without modifying their core parameters. It cleverly adapts the input or output interfaces, allowing the model to perform different functionalities. A common approach involves modifying the input with trainable noise patterns, and mapping the model’s original output labels to the new task’s labels. This process introduces flexibility and efficiency, reducing the need for extensive retraining. However, challenges exist such as finding optimal label mappings and dealing with the complex relationship between pretrained and downstream labels. Bayesian-guided Label Mapping (BLM) is a novel technique that leverages probabilistic relationships and addresses these limitations, enabling more robust and accurate visual reprogramming across diverse applications.
Many-to-many Mapping#
The concept of “many-to-many mapping” in the context of visual reprogramming (VR) offers a powerful alternative to traditional one-to-one mappings between pretrained and downstream labels. One-to-one mappings, while computationally efficient, often oversimplify the complex relationships inherent in real-world data, potentially leading to suboptimal performance. A many-to-many approach acknowledges that a single downstream label might correspond to multiple pretrained labels, and vice versa. This is especially relevant when dealing with hierarchical or semantically related labels. By assigning probabilistic weights to the mappings, a many-to-many approach can effectively capture the uncertainty and nuanced relationships between the label sets, thus improving the overall accuracy and robustness of the VR system. Bayesian methods, for instance, can provide a principled way to learn these probabilistic mappings, incorporating prior knowledge and updating beliefs iteratively based on data. While computationally more intensive than one-to-one methods, the enhanced performance gains often justify the additional cost. The improved performance, interpretability, and flexibility offered by many-to-many mappings highlight their importance for future advancements in visual reprogramming.
BLM Algorithm Details#
The BLM (Bayesian-guided Label Mapping) algorithm is a crucial component of the visual reprogramming framework, offering a probabilistic approach to address the limitations of traditional one-to-one label mapping methods. Instead of a deterministic, one-to-one mapping between pretrained and downstream labels, BLM constructs a probabilistic mapping matrix. Each element in this matrix represents the probability of a given pretrained label corresponding to a specific downstream label, reflecting the complex, often many-to-many relationships between the label spaces. This probabilistic approach is guided by Bayesian conditional probability, leveraging the joint distribution of predicted pretrained labels and ground-truth downstream labels. BLM iteratively refines this probabilistic matrix during optimization, allowing it to adapt and accurately capture the label relationships in various downstream tasks. The use of Bayesian principles provides a statistically sound foundation for the BLM algorithm, enhancing the flexibility and accuracy of visual reprogramming compared to existing methods.
Future Research#
Future research directions stemming from this Bayesian-guided label mapping (BLM) for visual reprogramming could explore more sophisticated probabilistic models for the label mapping matrix, potentially incorporating hierarchical relationships between pretrained and downstream labels or leveraging techniques from graph neural networks. Investigating the generalizability of BLM across diverse pretrained models and downstream tasks beyond those evaluated in the paper is crucial. Further analysis into the theoretical connections between BLM and other transfer learning techniques, such as domain adaptation, is warranted to better understand its strengths and limitations. Finally, research could focus on developing efficient algorithms to scale BLM to extremely large label spaces, a practical limitation of the current approach. These directions would enhance BLM’s robustness, applicability, and theoretical underpinnings.
More visual insights#
More on figures
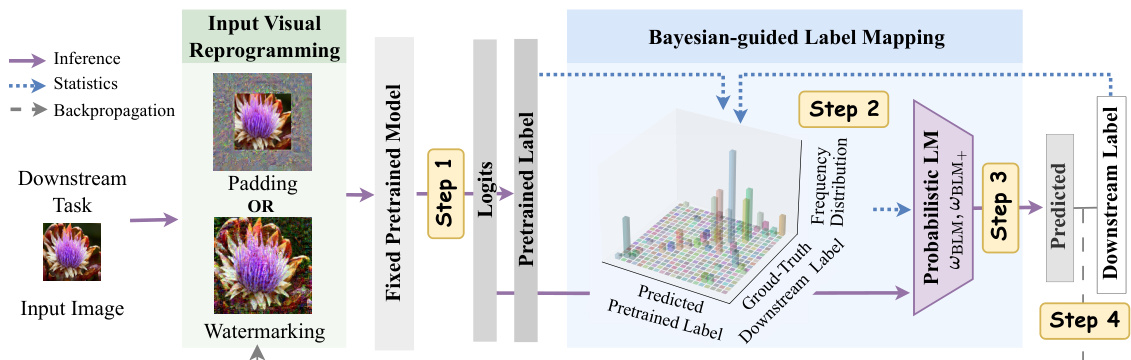
This figure illustrates the learning process of Bayesian-guided Label Mapping (BLM) and its enhanced version BLM+. It details the four steps involved: 1) Input image with VR patterns goes into a pretrained model, generating logits and predicted pretrained labels; 2) BLM/BLM+ estimates the probabilistic label mapping matrix using ground-truth downstream labels and predicted pretrained labels; 3) BLM/BLM+ reweights the output logits of the pretrained model for the downstream labels; 4) Backpropagation updates the input visual reprogramming patterns. This iterative process refines the label mapping and the input VR to optimize the performance on the downstream task.

This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows that individual images may have multiple relevant pretrained labels, but only the highest-scoring one is used. Panel (b) demonstrates how the greedy one-to-one mapping can lead to suboptimal assignments across the entire dataset, as the best pretrained label for one downstream category might already be assigned to another.
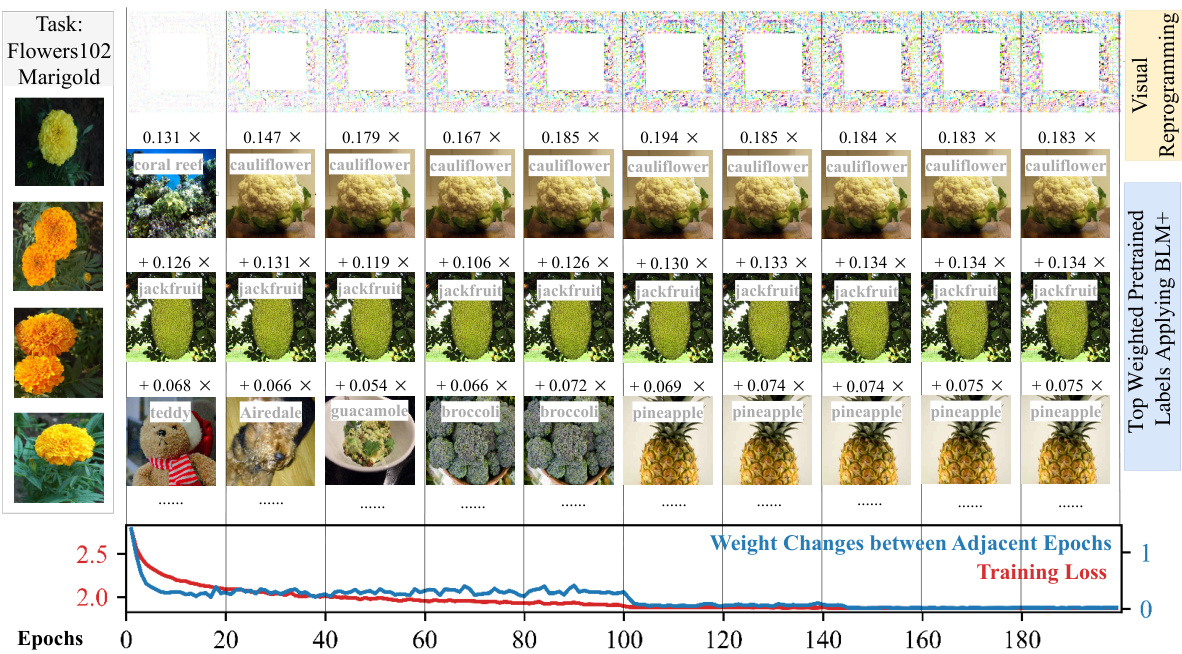
This figure visualizes the learning process of the BLM+ method. It shows how the input visual reprogramming patterns and the top-weighted pretrained labels change over training epochs. The decrease in training loss demonstrates the model’s improvement. The Euclidean norm of the weight changes in the probabilistic label mapping matrix (WBLM+) indicates the stability of the learning process. The example uses the ‘Marigold’ label from a dataset, with ResNet-18 as the pretrained model.
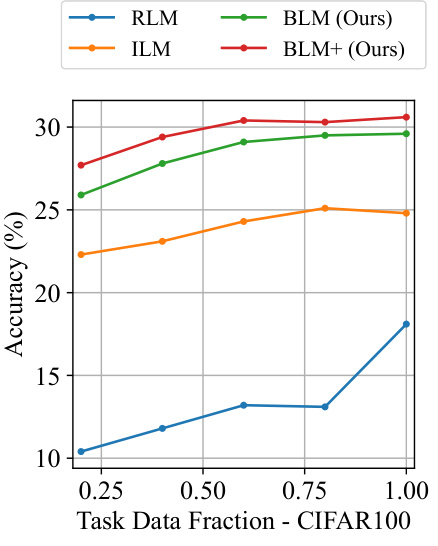
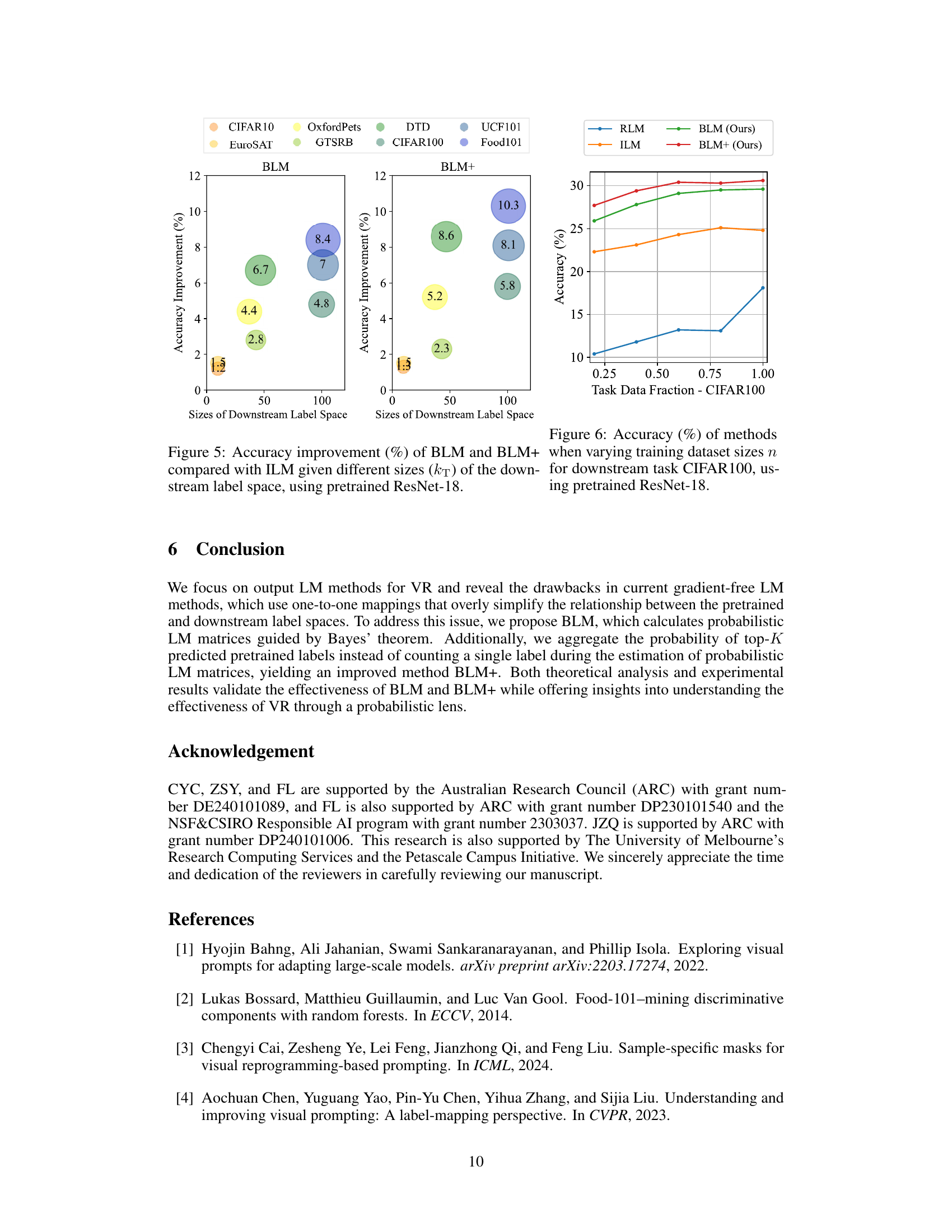
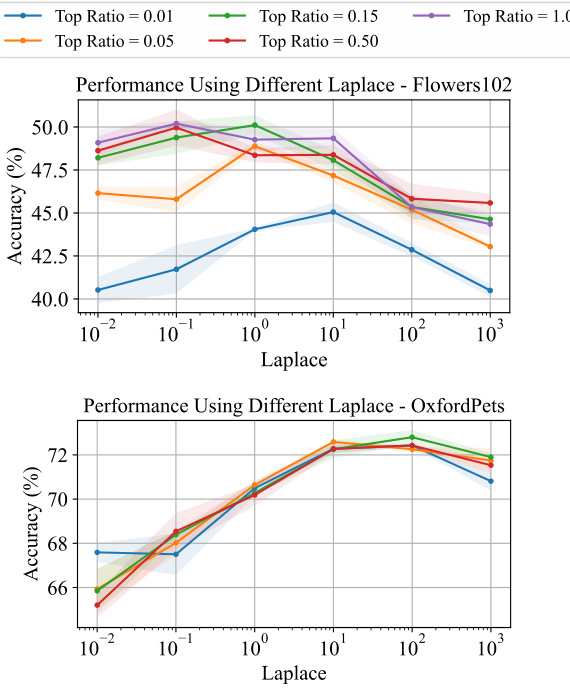
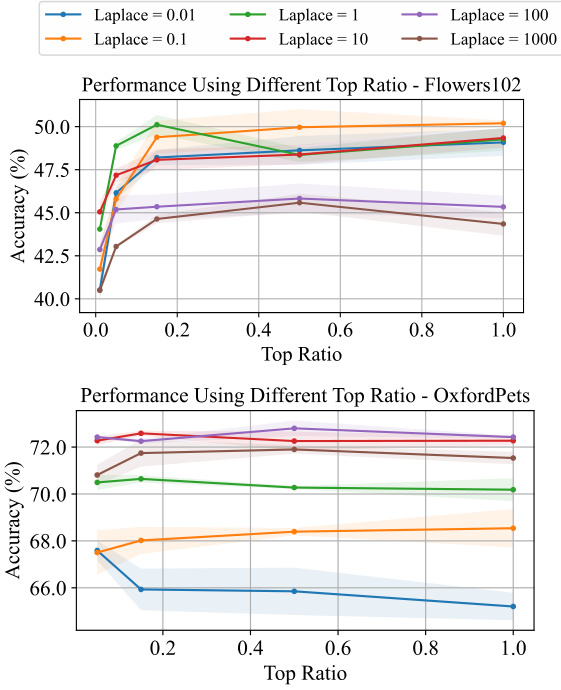
This figure shows the accuracy of different label mapping methods (RLM, ILM, BLM, BLM+) on the CIFAR100 dataset when varying the size of the training dataset. It demonstrates the robustness of BLM and BLM+ to smaller training datasets, maintaining comparatively high accuracy even with only 40% of the full training data compared to RLM and ILM.
This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows that using only the highest-probability pretrained label ignores other potentially relevant labels for a given downstream image. Panel (b) demonstrates that a greedy one-to-one mapping can lead to suboptimal assignments, as the best pretrained label for one downstream label might already be assigned to another.
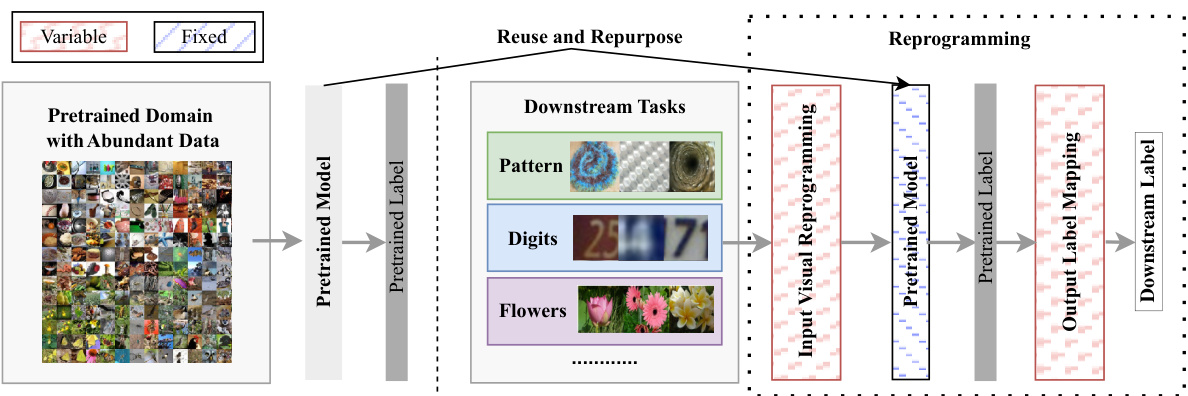
This figure illustrates the visual reprogramming (VR) process. The left side shows a pretrained model trained on a large dataset. The right side shows various downstream tasks with different input images and labels. The key idea is that the pretrained model remains fixed; however, the input data is modified using an ‘input visual reprogramming’ module, and the output is adapted using an ‘output label mapping’ module to produce results relevant to the downstream task. The figure highlights the flexibility of VR in adapting pretrained models to diverse new applications without retraining.
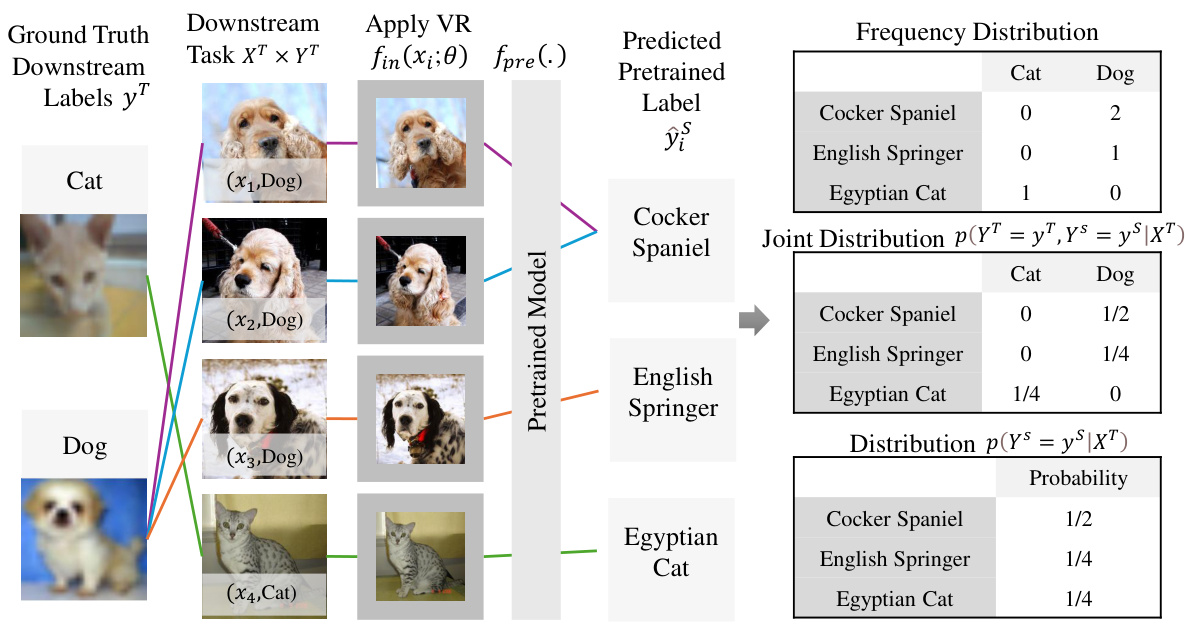
This figure shows the drawbacks of using a one-to-one label mapping (LM) strategy in visual reprogramming (VR). Subfigure (a) illustrates how this approach can overlook important relationships between pretrained and downstream labels when applied to individual images; for example, only considering the highest logit for each image, disregarding other potentially relevant labels. Subfigure (b) demonstrates this limitation at a dataset level by showing suboptimal solutions where the optimal pretrained label is already assigned to a different downstream label, leading to mismatches and reduced performance. The visualization highlights that a one-to-one mapping is insufficient for capturing the complex many-to-many relationships between pretrained and downstream labels.
This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows that using only the single most likely pretrained label ignores other potentially relevant labels. Panel (b) demonstrates that a greedy one-to-one mapping can lead to suboptimal solutions where the best pretrained label for a downstream class is already assigned to another class. This motivates the need for a more flexible many-to-many mapping approach.
This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows that individual images can have multiple relevant pretrained labels, but only the highest-scoring one is used, ignoring potentially useful information. Panel (b) demonstrates that a greedy one-to-one mapping can lead to suboptimal assignments across the entire dataset because once a pretrained label is assigned to a downstream label, it is unavailable for other potential pairings, even if it would be a better match.
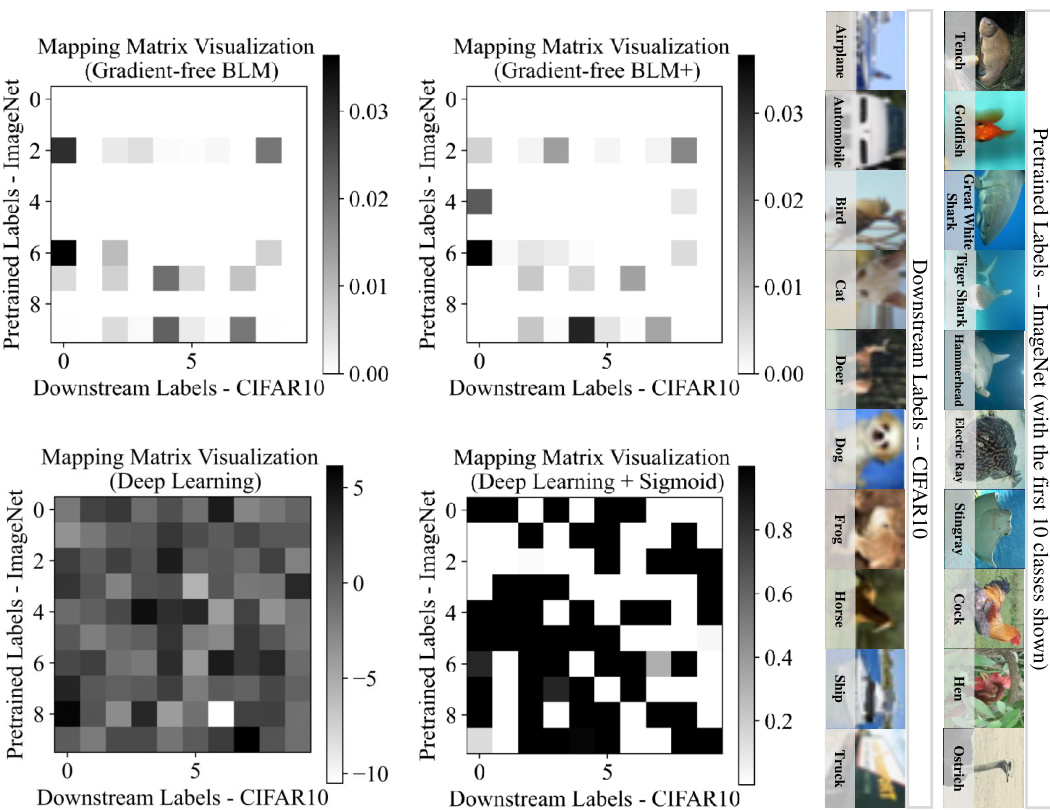
This figure shows the drawbacks of using a one-to-one label mapping (LM) strategy in visual reprogramming (VR). The left subfigure (a) illustrates how individual images might be incorrectly mapped to a single pretrained label, ignoring other potentially relevant labels. The right subfigure (b) shows that the one-to-one mapping can lead to suboptimal solutions across the entire dataset, as evidenced by the frequency distribution of pretrained and downstream labels.

This figure illustrates the limitations of using a one-to-one label mapping approach in visual reprogramming. Panel (a) shows that individual images might have multiple relevant pretrained labels, but only the highest-scoring one is used, ignoring potentially valuable information. Panel (b) demonstrates that a greedy one-to-one mapping can lead to suboptimal solutions across the entire dataset, where the optimal pretrained label for a downstream class is already assigned to another downstream class. This highlights the need for a more nuanced, many-to-many mapping approach.

This figure illustrates the limitations of using a one-to-one label mapping (LM) strategy in visual reprogramming (VR). Panel (a) shows how a single pretrained label is assigned to multiple downstream labels, ignoring the nuances within the pretrained model’s predictions. Panel (b) demonstrates that a greedy one-to-one mapping can lead to suboptimal solutions where the best pretrained label for a downstream task is already assigned to another downstream label. The figure highlights the need for a more flexible, many-to-many mapping approach.

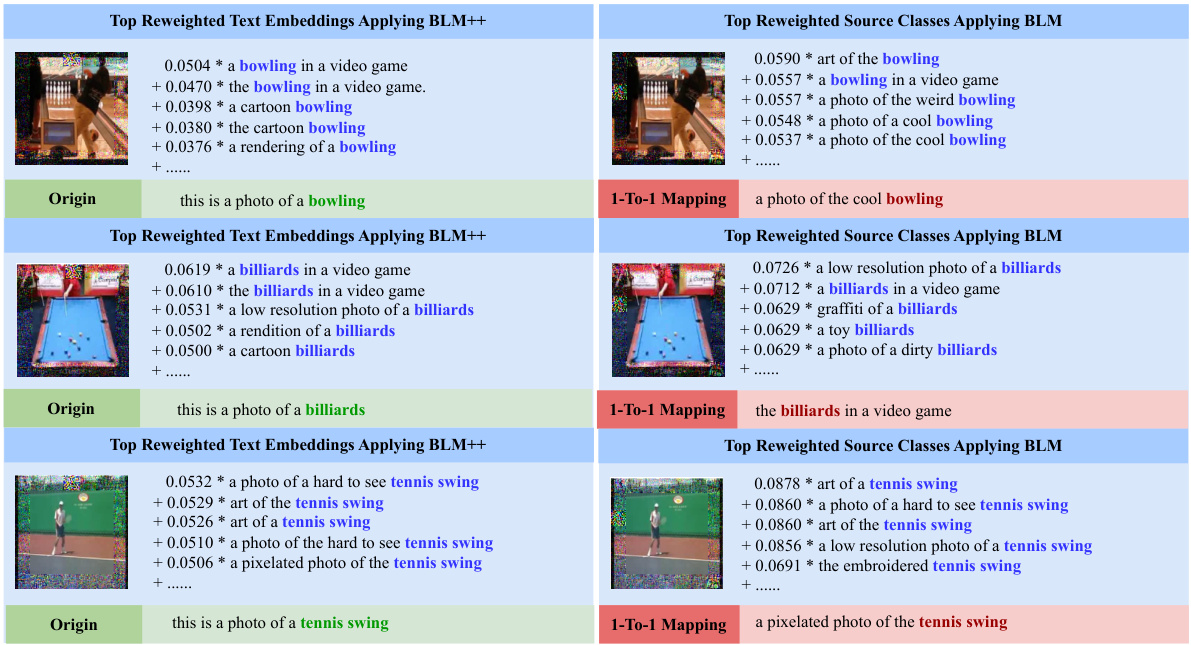
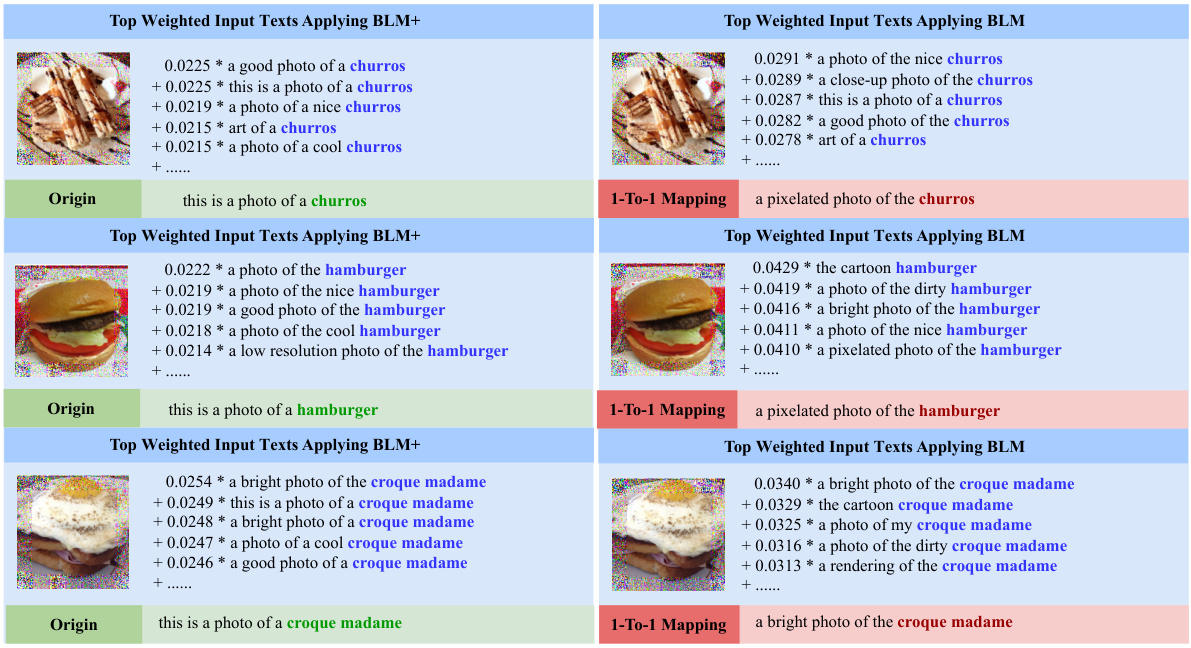
This figure visualizes the top weighted pretrained labels and their corresponding weights for three example downstream labels using both BLM and BLM+. It shows how the methods assign weights to various pretrained labels based on their relevance to the downstream label. The examples used are ‘Edamame’, ‘Fibrous’, and ‘Dog’, highlighting the many-to-many relationships learned by the probabilistic label mapping.

This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows how individual images might be incorrectly mapped to a single pretrained label, even though other pretrained labels might be more suitable. Panel (b) demonstrates that using a greedy one-to-one mapping for the entire dataset can lead to suboptimal solutions where the best pretrained label for a downstream label is already assigned to another downstream label. These issues highlight the need for a more flexible many-to-many mapping strategy.

This figure illustrates the limitations of using a one-to-one label mapping (LM) strategy in visual reprogramming (VR). Subfigure (a) shows how a single pretrained label is assigned to multiple downstream labels, ignoring the probabilistic nature of the relationship. Subfigure (b) demonstrates that a greedy one-to-one mapping can lead to suboptimal assignments due to the many-to-many nature of the actual label relationships between the pretrained model and downstream tasks.
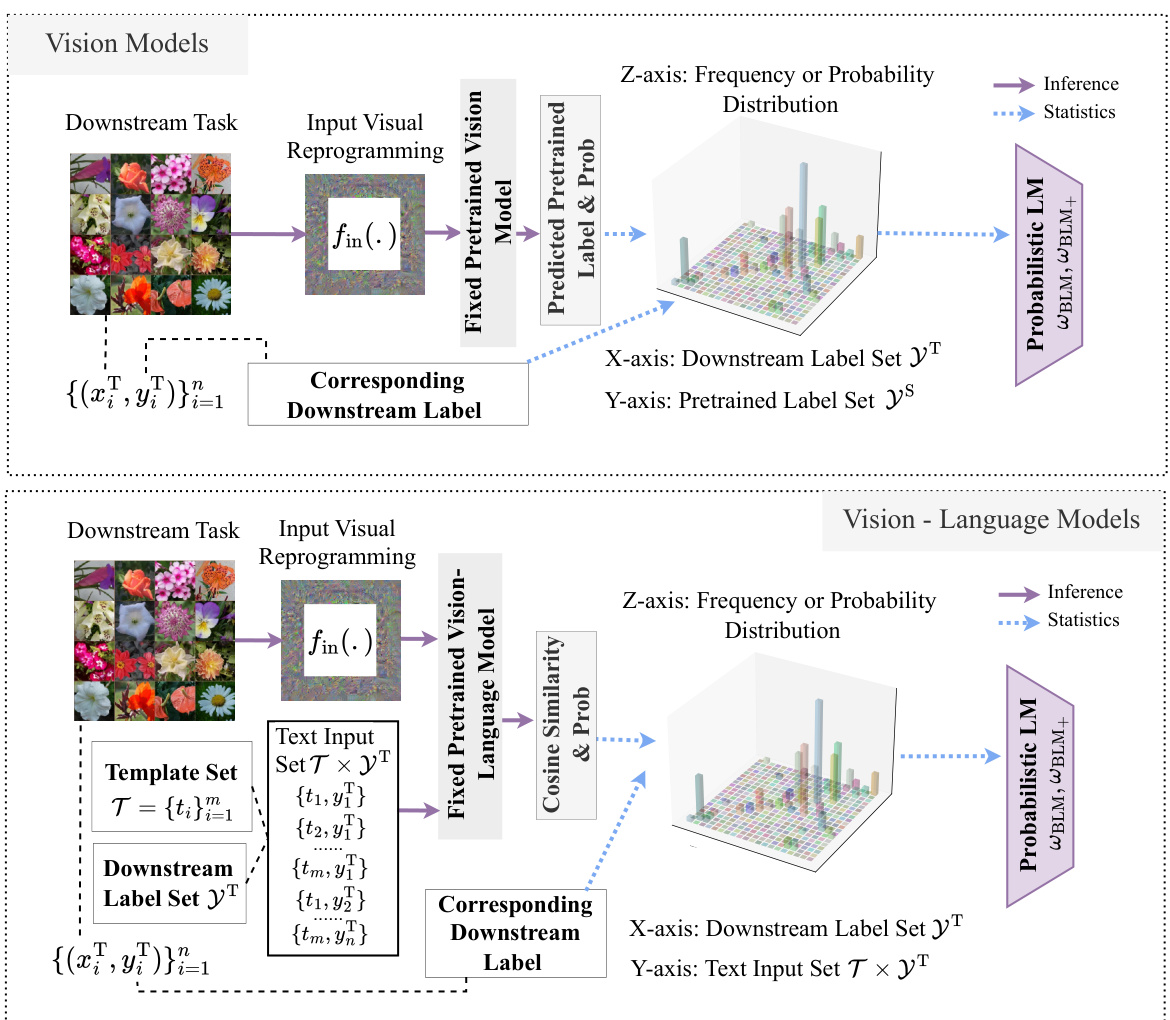
This figure illustrates the step-by-step process of the Bayesian-guided Label Mapping (BLM) and BLM+ methods. It starts by inputting images with added VR patterns into a pretrained model, generating logits and predicted labels. These are then used to estimate the probabilistic label mapping matrices WBLM and WBLM+. Finally, these matrices are used to refine the predictions for the downstream labels, and backpropagation updates the input VR patterns.

This figure illustrates the limitations of using one-to-one label mapping in visual reprogramming. Panel (a) shows how individual images might be incorrectly mapped to a single pretrained label, even though other pretrained labels might be more appropriate. Panel (b) demonstrates how these suboptimal mappings can affect the overall performance, showing a many-to-many relationship between pretrained and downstream labels is overlooked by the one-to-one approach.

This figure illustrates the limitations of using a one-to-one label mapping (LM) strategy in visual reprogramming (VR). The left subplot shows how a single pretrained label is assigned to multiple downstream labels, ignoring the nuanced relationships and probabilities within the predicted output. The right subplot shows that even when using the optimal one-to-one mapping, some downstream labels cannot be effectively mapped due to conflicts and limitations inherent in the one-to-one strategy. This highlights the need for a more flexible, many-to-many approach like the Bayesian-guided Label Mapping (BLM) proposed in the paper.
This figure shows the drawbacks of using a one-to-one label mapping in visual reprogramming. Subfigure (a) demonstrates how individual images might be mislabeled because the one-to-one mapping ignores the probabilities of other relevant pretrained labels. Subfigure (b) illustrates how a greedy one-to-one mapping can lead to suboptimal solutions for the entire dataset by preventing optimal pairings between pretrained and downstream labels.
This figure illustrates the limitations of using a one-to-one label mapping in visual reprogramming. Panel (a) shows how individual images can be misrepresented because the highest-probability pretrained label is selected, ignoring other potentially relevant labels. Panel (b) shows how the one-to-one mapping can lead to suboptimal assignments across the entire dataset, where some downstream labels might not be optimally mapped to any pretrained label because the best pretrained label for the downstream label was already assigned in the mapping.
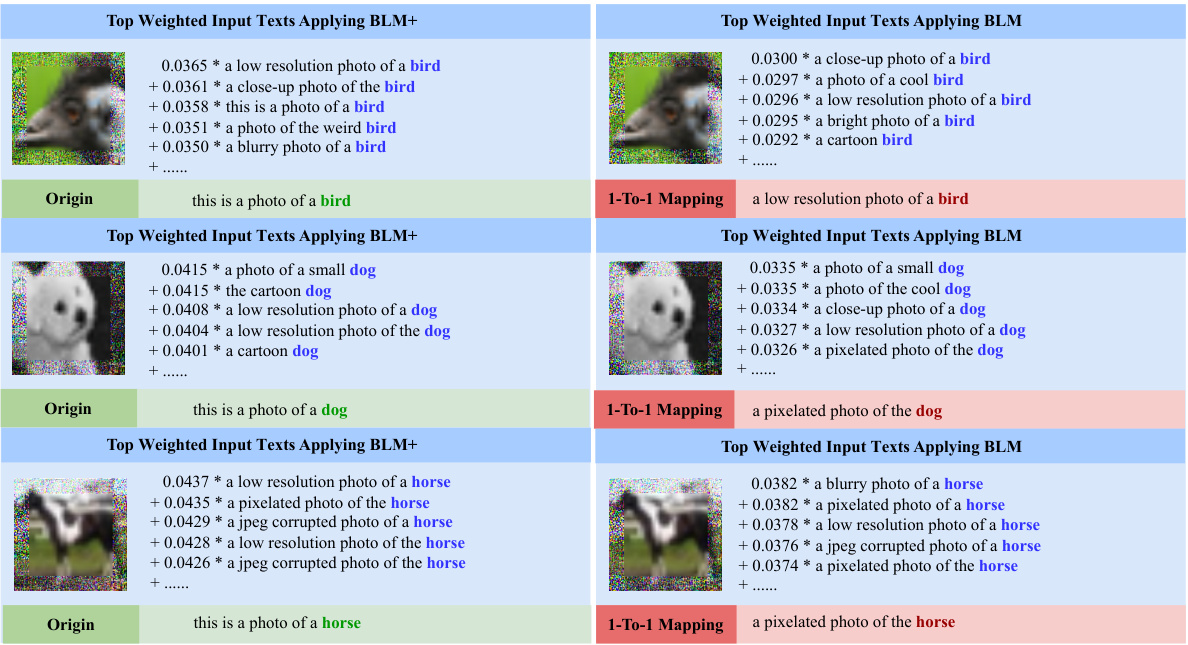
This figure visualizes the top weighted pretrained labels and their corresponding weights obtained from BLM and BLM+ for three downstream labels: Edamame, Fibrous, and Dog. The weights represent the contribution of each pretrained label to the prediction of the downstream label. This visualization helps illustrate how BLM and BLM+ move beyond a one-to-one mapping between pretrained and downstream labels and instead consider multiple relationships. ResNet-18 pretrained on ImageNet is the model used.
More on tables
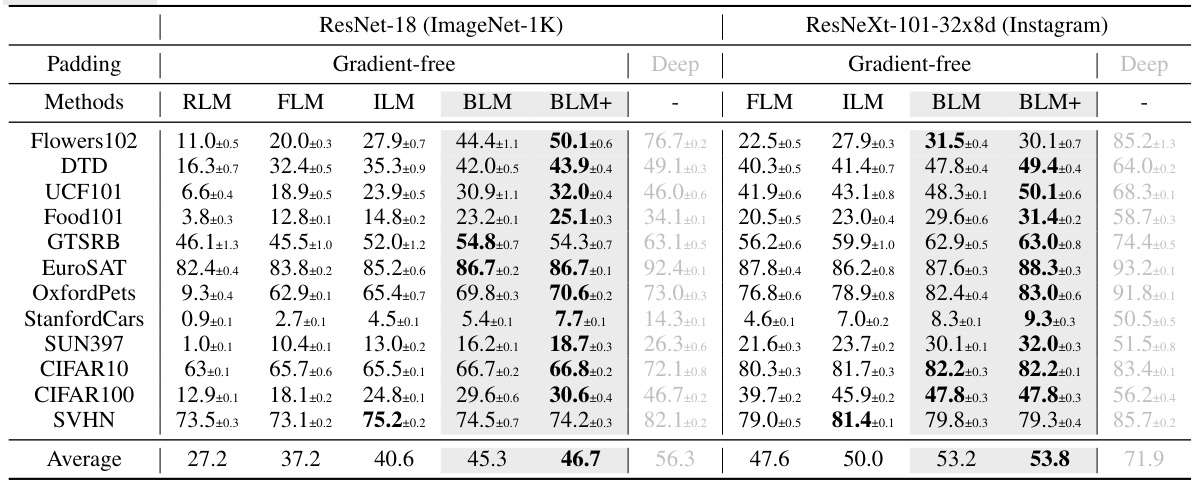
This table presents the comparison results of different gradient-free output label mapping methods. The table shows the performance (mean accuracy ± standard deviation) of different methods on twelve different datasets using two different pretrained models (ResNet-18 and ResNeXt-101-32x8d). The results are shown separately for padding-based input VR. The highest accuracy for each dataset is shown in bold. The results for a deep learning-based method are shown in gray for comparison.
This table presents a comparison of different gradient-free output label mapping methods for visual reprogramming, including the proposed BLM and BLM+ methods. It shows the average accuracy and standard deviation across twelve benchmark datasets for padding-based visual reprogramming using ResNet-18 and ResNeXt-101-32x8d pretrained models. The table highlights the superior performance of the proposed BLM and BLM+ methods compared to existing methods (RLM, FLM, ILM) and also includes results from deep learning-based methods for comparison.
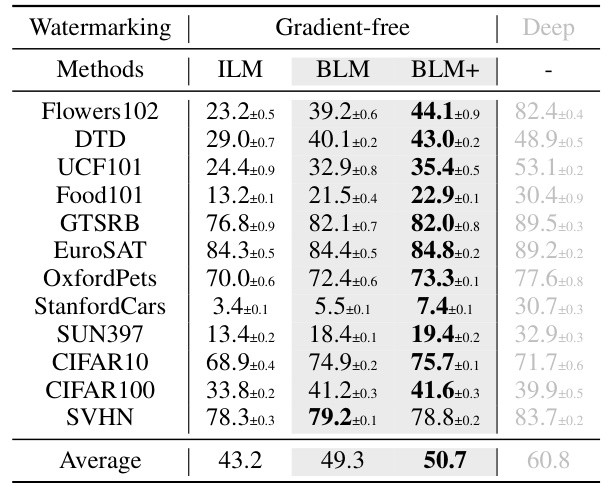
This table presents a comparison of different gradient-free output label mapping methods for visual reprogramming. It shows the mean accuracy (with standard deviation) achieved by various methods (RLM, FLM, ILM, BLM, and BLM+) on 12 different datasets using ResNet-18 and ResNeXt-101-32x8d pretrained models. The results are shown separately for padding-based and watermarking-based visual reprogramming. The highest accuracy for each dataset and method is highlighted in bold. For comparison, results using deep learning-based methods are also included in gray.

This table compares the performance of different gradient-free output label mapping methods, including the proposed BLM and BLM+, against existing methods like RLM, FLM, and ILM. The comparison is done across various datasets using two different input visual reprogramming methods (padding and watermarking) and two different pretrained vision models (ResNet-18 and ResNeXt-101-32x8d). The table shows the mean accuracy and standard deviation for each method on each dataset, highlighting the best-performing method in bold. Deep learning-based methods are also included for a comparative reference, shown in gray.

This table compares the performance of different gradient-free output label mapping methods, including RLM, FLM, ILM, BLM, and BLM+, on various downstream tasks using ResNet-18 and ResNeXt-101-32x8d pretrained models. The results are presented as mean accuracy ± standard deviation across multiple runs. The table highlights the superior performance of the proposed BLM and BLM+ methods, with the highest accuracy values shown in bold. Deep learning based methods are also included for comparison.
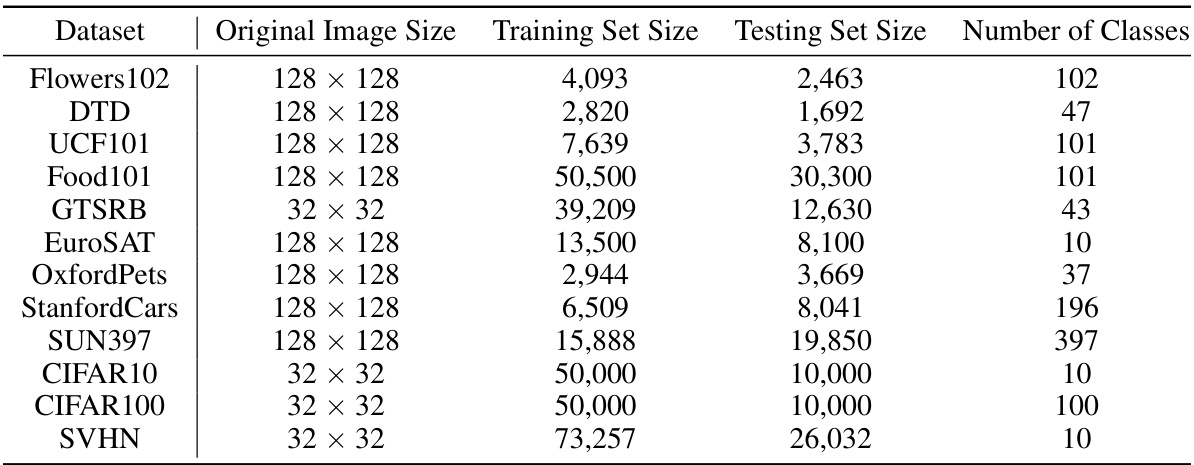
This table compares the performance of different gradient-free output label mapping methods for visual reprogramming. It shows the average accuracy (mean ± standard deviation) across twelve different datasets for both ResNet-18 and ResNeXt-101 pretrained models. The methods compared include Random Label Mapping (RLM), Frequent Label Mapping (FLM), Iterative Label Mapping (ILM), Bayesian-guided Label Mapping (BLM), and Bayesian-guided Label Mapping+ (BLM+). The table highlights the superior performance of BLM and BLM+ compared to existing methods. Deep learning-based methods are included in grey for additional context.
This table presents the performance comparison of different gradient-free output label mapping methods, including the proposed BLM and BLM+, against existing methods like RLM, FLM, and ILM. The results are shown for two different pretrained models (ResNet-18 and ResNeXt-101-32x8d) and two input VR methods (padding and watermarking) across 12 benchmark datasets. The highest accuracy for each dataset and method is highlighted in bold, providing a clear view of the relative performance improvements achieved by BLM and BLM+. Deep learning based methods are also shown for comparison.
This table compares the performance of different gradient-free output label mapping methods (RLM, FLM, ILM, BLM, BLM+) for visual reprogramming on 12 datasets using ResNet-18 and ResNeXt-101-32x8d pretrained models. The table shows the average accuracy and standard deviation for each method on each dataset, highlighting the proposed BLM and BLM+ methods in bold when they achieve the highest accuracy. A comparison to deep learning-based methods is also included in gray.

This table compares the performance of different gradient-free output label mapping methods, including the proposed BLM and BLM+, against existing methods like RLM, FLM, and ILM. The results are presented as the mean accuracy and standard deviation across twelve different datasets, using two different pretrained models (ResNet-18 and ResNeXt-101-32x8d). The table is split to show results with padding-based input visual reprogramming and watermarking-based input visual reprogramming. The highest accuracy for each dataset is highlighted in bold, providing a clear comparison of the effectiveness of the proposed BLM and BLM+ methods compared to the baselines. Deep learning-based methods are included in gray for additional context.
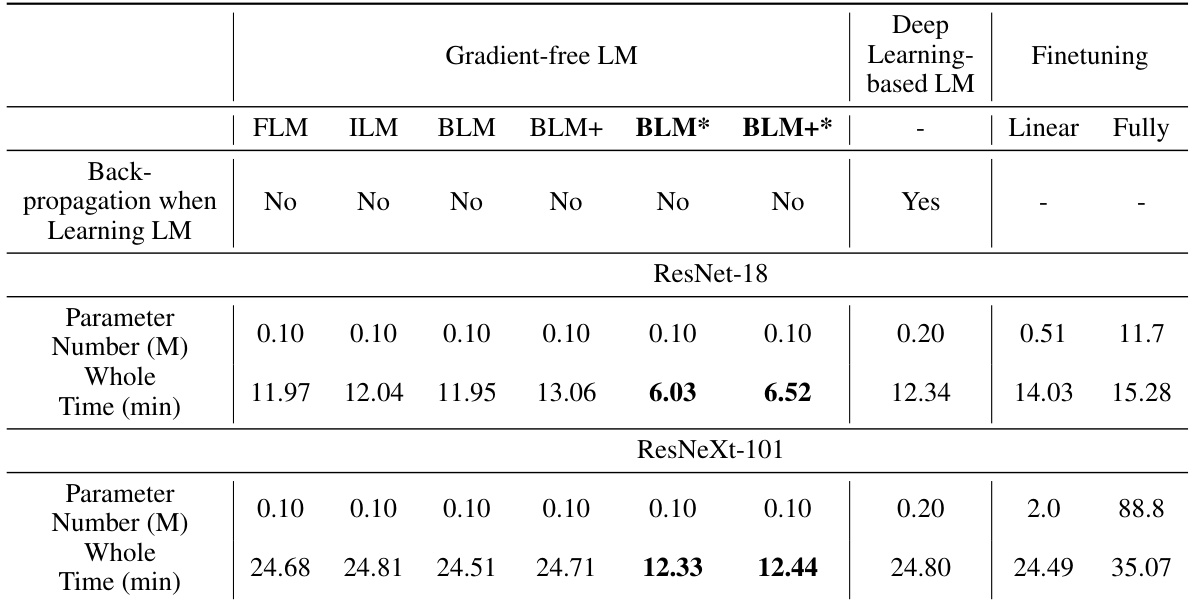
This table compares the performance of various gradient-free output label mapping (LM) methods, including the proposed Bayesian-guided Label Mapping (BLM) and its enhanced version (BLM+), against existing methods like Random Label Mapping (RLM), Frequent Label Mapping (FLM), and Iterative Label Mapping (ILM). The results are shown for two different pretrained models (ResNet-18 and ResNeXt-101) across twelve different downstream datasets, using the padding-based visual reprogramming (VR) method. The table highlights the superior performance of BLM and BLM+ compared to the baselines, demonstrating their effectiveness in improving visual reprogramming performance.
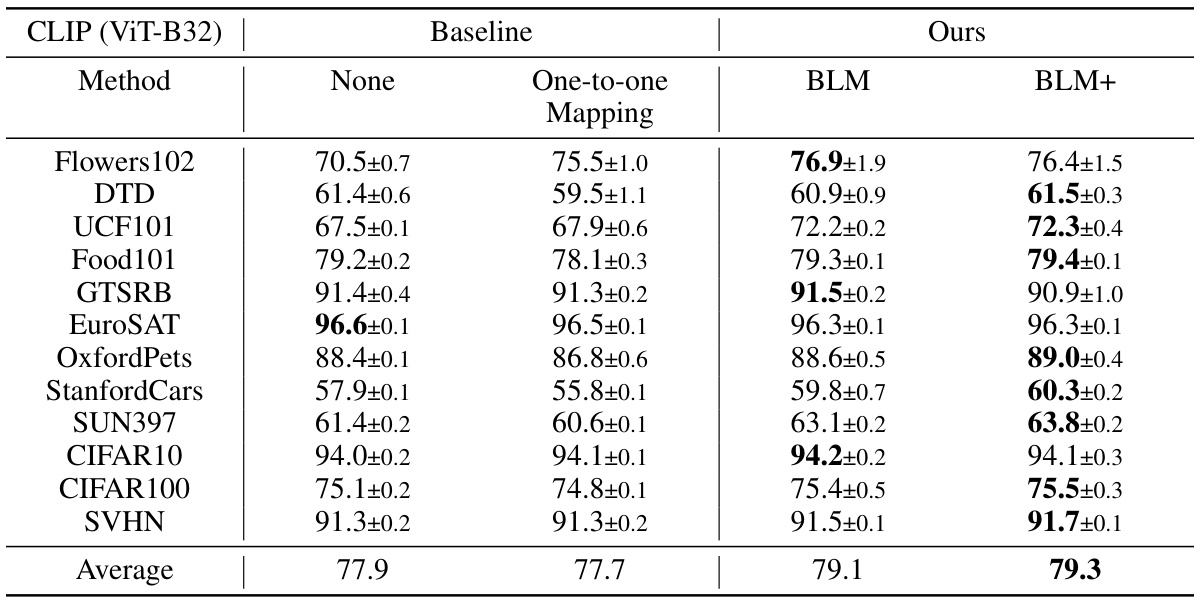
This table compares the performance of different gradient-free output label mapping (LM) methods for visual reprogramming (VR) on 12 different datasets. The methods compared include Random Label Mapping (RLM), Frequent Label Mapping (FLM), Iterative Label Mapping (ILM), and the proposed Bayesian-guided Label Mapping (BLM) and BLM+. Results are shown for both padding-based and watermarking-based VR methods, using ResNet-18 and ResNeXt-101-32x8d pretrained models. The table highlights the superior performance of BLM and BLM+ compared to existing methods across most datasets. Deep learning-based LM results are included for reference, showing that BLM and BLM+ bridge the gap in performance between gradient-free and deep learning-based approaches.
Full paper#