↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Multimodal fusion and object detection are crucial for autonomous driving. Existing methods often involve complex, multi-stage training processes that hinder broader applications and may lead to suboptimal results. A major issue is that the optimization of individual tasks in such methods can compromise overall efficiency and result in suboptimal solutions.
This paper introduces E2E-MFD, a novel end-to-end algorithm that addresses these challenges. E2E-MFD streamlines the training process by employing synchronous joint optimization across components, avoiding suboptimal solutions associated with individual tasks and using a Gradient Matrix Task Alignment (GMTA) technique to further enhance the optimization process. Extensive testing on public datasets demonstrates that E2E-MFD achieves significant improvements in both image fusion and object detection accuracy compared to state-of-the-art approaches.
Key Takeaways#
Why does it matter?#
This paper is significant for researchers in computer vision and autonomous driving due to its novel approach to multimodal fusion and object detection. E2E-MFD offers a highly efficient and streamlined method, improving accuracy and potentially leading to safer and more reliable autonomous systems. The introduction of GMTA provides a useful technique for handling optimization challenges in multi-task learning settings, applicable beyond the specific application. Future research can build upon E2E-MFD’s foundation to develop more robust and adaptable perception systems.
Visual Insights#
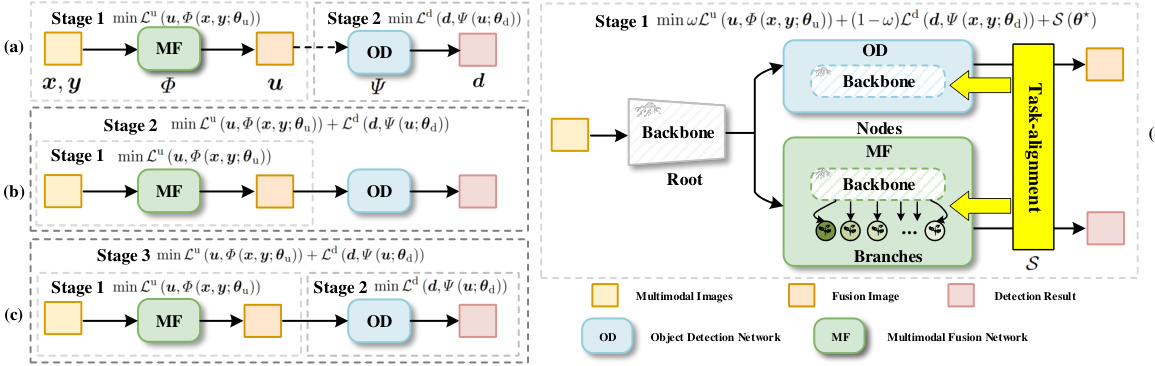
This figure compares different MF-OD (Multimodal Fusion-Object Detection) task paradigms. (a) shows a two-stage approach where multimodal fusion and object detection are performed sequentially as separate tasks. (b) illustrates another two-stage method but with joint cascading, where the object detection network guides the fusion process. (c) presents a multi-stage joint cascade, offering more complex interactions. Finally, (d) highlights the proposed E2E-MFD, which performs multimodal fusion and object detection simultaneously in a single end-to-end framework, streamlining the process and avoiding suboptimal solutions from separate task optimizations.
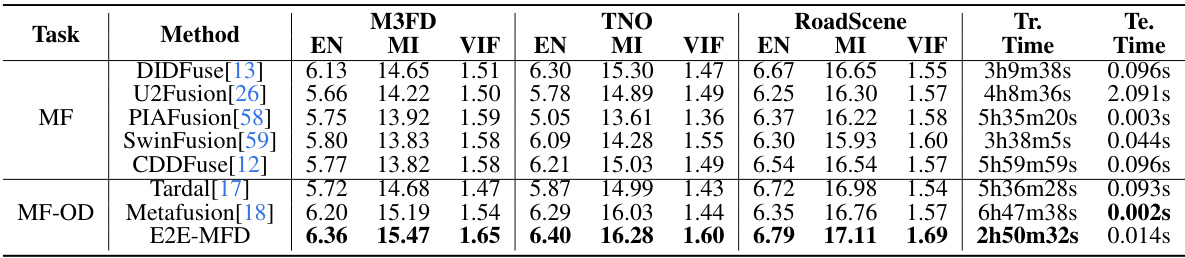
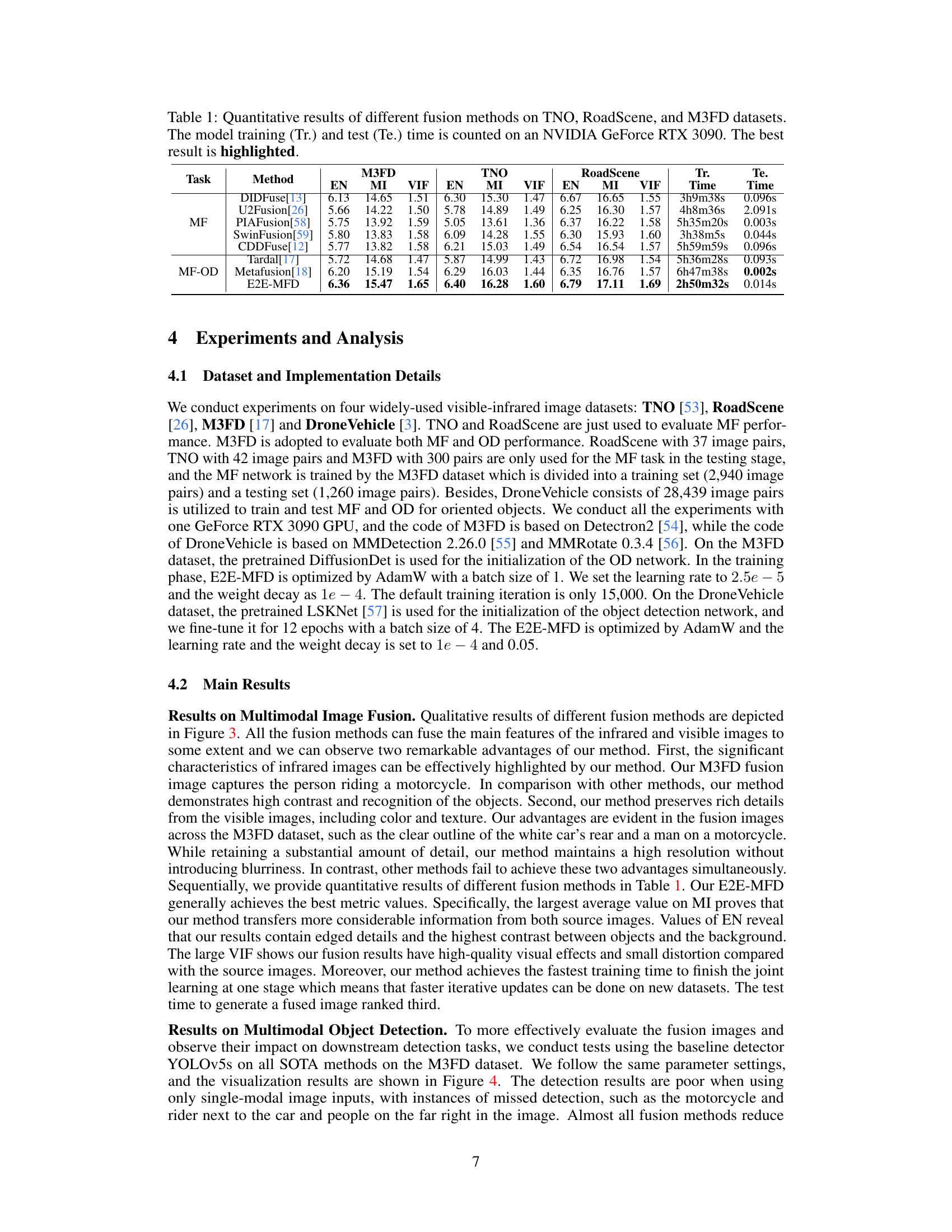
This table presents a quantitative comparison of various multimodal image fusion methods across three datasets: TNO, RoadScene, and M3FD. The metrics used for evaluation are Entropy (EN), Mutual Information (MI), and Visual Information Fidelity (VIF). The table also shows the training and testing times for each method on an NVIDIA GeForce RTX 3090 GPU. The best performance for each metric is highlighted.
In-depth insights#
E2E Fusion: A New Path#
The heading “E2E Fusion: A New Path” suggests a paradigm shift in multimodal data fusion. It likely refers to an end-to-end (E2E) approach, contrasting with traditional, multi-stage methods. Instead of separate fusion and detection steps, this new path probably integrates both processes into a single, unified neural network. This allows for more efficient and effective learning, potentially overcoming suboptimal solutions inherent in staged approaches. Direct fusion of raw sensor data within this network likely leads to richer feature representations, benefiting downstream tasks. However, challenges like the computational cost of E2E models and the potential for overfitting remain. Successfully navigating these challenges would demonstrate a significant advancement in multimodal data processing, offering improvements in speed and performance.
GMTA Optimization#
The Gradient Matrix Task Alignment (GMTA) optimization strategy is a crucial contribution of the paper, addressing the inherent challenge of conflicting gradients in multi-task learning scenarios. GMTA tackles the problem of task dominance, where one task (e.g., object detection) might overshadow the other (e.g., image fusion) during training with shared parameters. By analyzing the gradient matrix, GMTA identifies and mitigates conflicts and imbalances, ensuring that both tasks contribute equally to the optimization process. This is achieved by enforcing a condition where the gradients are orthogonal and of equal magnitude, effectively eliminating optimization barriers. The strategy focuses on minimizing the condition number of the gradient matrix, which quantifies the stability of the linear system. This method promotes efficient convergence to an optimal fusion-detection configuration. The result is a more balanced and harmonious training process, leading to improved performance in both image fusion and object detection tasks. GMTA’s effectiveness is demonstrated experimentally, showing significant improvements compared to methods that do not address the inherent optimization challenges of multi-task learning.
ORPPT Feature Fusion#
The proposed ORPPT (Object-Region-Pixel Phylogenetic Tree) feature fusion method represents a novel approach to multimodal fusion, particularly in the context of visible-infrared image processing. Its core strength lies in the hierarchical processing of features, mirroring the human visual system’s ability to process information from coarse to fine detail. The method starts by extracting features from visible and infrared images using a shared backbone network, ensuring consistency and complementarity. These features are then fed into a tree-like structure where different branches handle different levels of granularity. The initial branch (PFMM) processes the pixel-level information, capturing fine-grained details. Subsequent branches (RFRM) progressively process region-level information, starting with coarser representations and gradually refining them to capture more complex object relationships. This structure ensures that both local pixel-level information and global context are effectively incorporated into the fused image. The fusion is not merely a concatenation of features, but a synergistic integration, making it particularly effective for object detection where both fine-grained texture information and object-level semantics are crucial. The ORPPT approach is particularly relevant for object detection because it ensures sufficient detail is maintained even at larger scales, enhancing the quality and robustness of downstream tasks. However, the complexity of the ORPPT architecture may introduce challenges in training and optimization, particularly concerning computational cost and the balance of information across branches. Further research could focus on optimizing the structure and enhancing the efficiency of the ORPPT to maximize performance and reduce computational needs.
CFDP Detection Head#
The concept of a “CFDP Detection Head” suggests a novel approach to object detection, likely integrated within a larger multimodal fusion framework. CFDP, potentially standing for Coarse-to-Fine Diffusion Process, implies a multi-stage detection strategy that starts with a coarse understanding of object locations and progressively refines these estimations. This is in contrast to traditional methods that might employ a single-stage approach or cascaded networks where each stage has to be trained individually. A key advantage might be the improved accuracy due to the iterative refinement process; the initial coarse estimation helps to constrain and guide the fine-grained details. Diffusion models, which are mentioned in context, lend themselves well to this type of approach because of their ability to generate data samples. The use of diffusion models within object detection is still a relatively new area, so this represents a potential innovative contribution. The performance improvements are expected to be particularly noticeable in cases involving challenging conditions like occlusion or when dealing with multiple objects. The “head” designation suggests it’s a modular component that can be readily integrated into various architectures, thereby enhancing their overall accuracy and efficiency.
Future MFD Research#
Future research in Multimodal Fusion Detection (MFD) should prioritize developing more robust and efficient end-to-end models. Current methods often rely on complex, multi-stage architectures, hindering broader applications. A focus on improving the handling of diverse data modalities beyond visible and infrared, such as LiDAR and radar, is crucial. This requires exploring new fusion mechanisms that effectively integrate information from diverse sources with varying levels of noise and uncertainty. Furthermore, enhanced attention mechanisms should be investigated to focus on relevant object regions, improving detection accuracy, especially in challenging conditions. The development of more generalizable and transferable MFD models is key to expand applications to different environmental settings. This necessitates focusing on domain adaptation techniques, and exploring techniques that enable models to learn from limited data. Finally, significant attention needs to be directed toward developing comprehensive evaluation benchmarks and metrics for MFD, facilitating fair comparison and pushing advancements in the field.
More visual insights#
More on figures
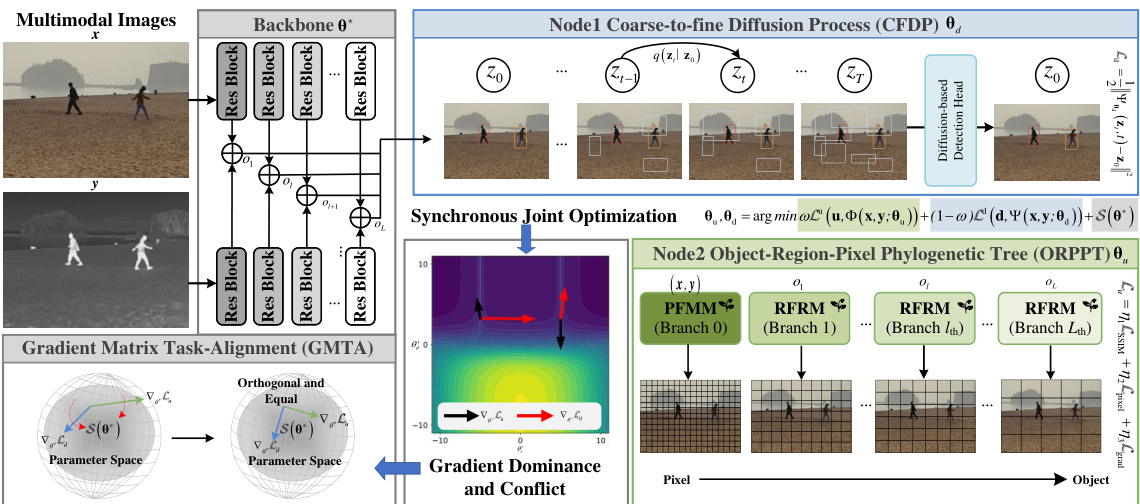
This figure provides a detailed illustration of the E2E-MFD framework’s architecture. It showcases the backbone responsible for extracting features from multimodal images, the Object-Region-Pixel Phylogenetic Tree (ORPPT) for fine-grained image fusion, and the Coarse-to-Fine Diffusion Process (CFDP) for object detection. The diagram highlights the synchronous joint optimization and Gradient Matrix Task-Alignment (GMTA) techniques employed for end-to-end optimization of both tasks. The interplay between these components, their functions, and how they synergistically work together is explicitly shown in the figure.

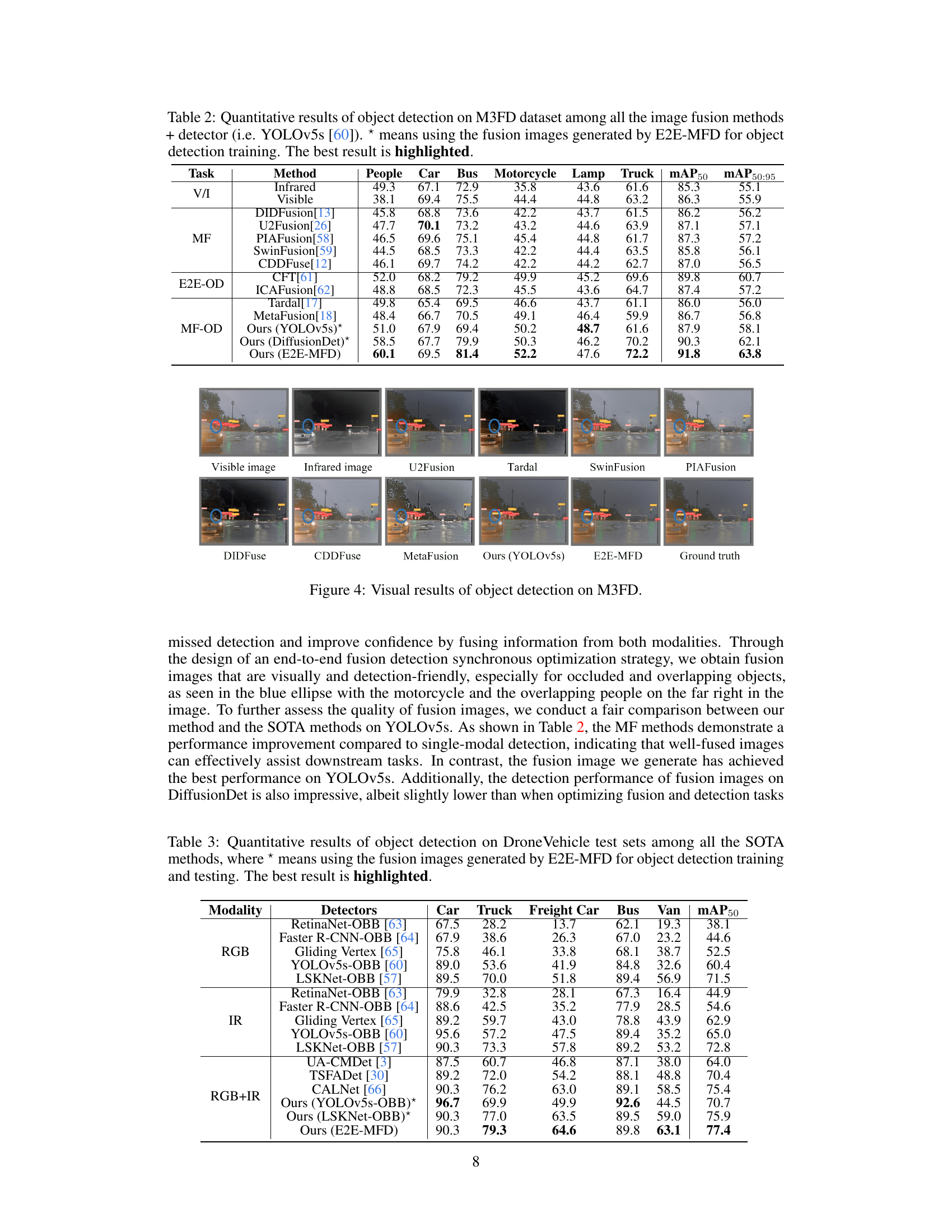
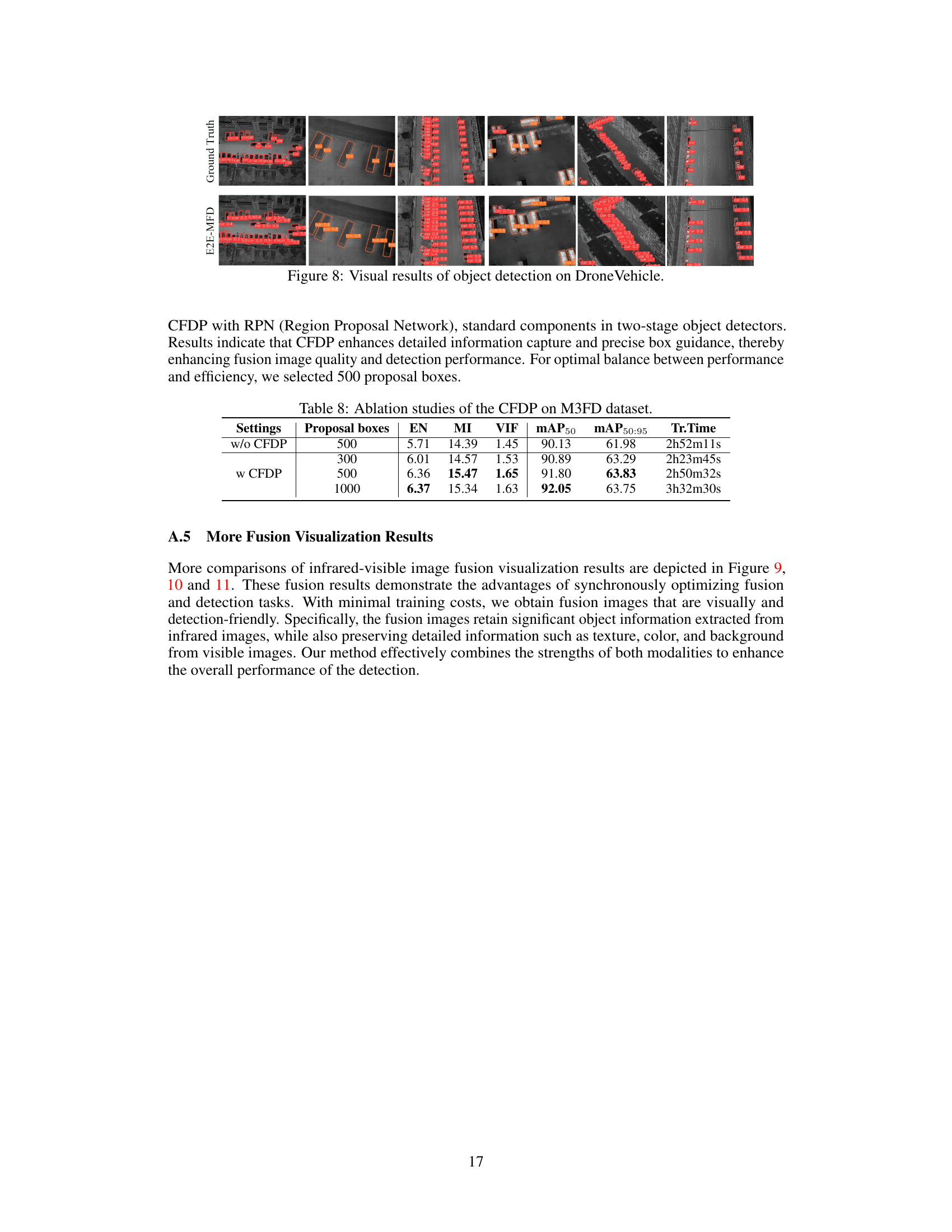
This figure presents a comparison of object detection results on the M3FD dataset using different multimodal image fusion methods. The top row shows the visible and infrared input images, followed by the fusion results from several state-of-the-art methods and the proposed E2E-MFD. The yellow bounding boxes indicate the objects detected by the YOLOv5s object detector, highlighting the effectiveness of each method’s fusion in enabling accurate object localization. The bottom row presents the ground truth bounding boxes for comparison.

This figure shows a comparison of object detection results on the M3FD dataset using different image fusion methods. It visually demonstrates how various methods perform in detecting objects (cars, buses, motorcycles, etc.) in visible and infrared images. The ground truth bounding boxes are also shown for comparison, allowing for a qualitative assessment of each method’s accuracy and ability to handle challenging conditions like occlusions or low light.
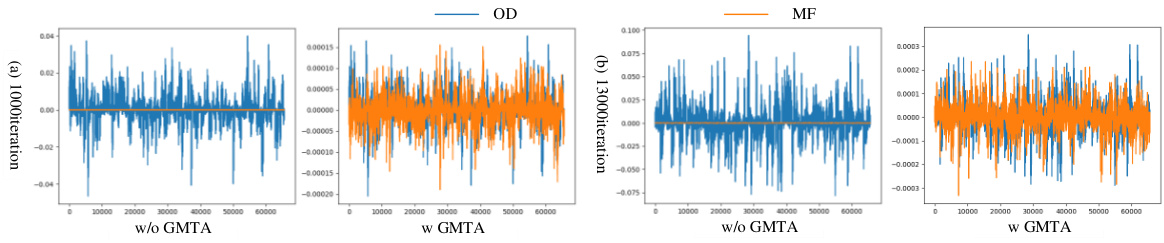
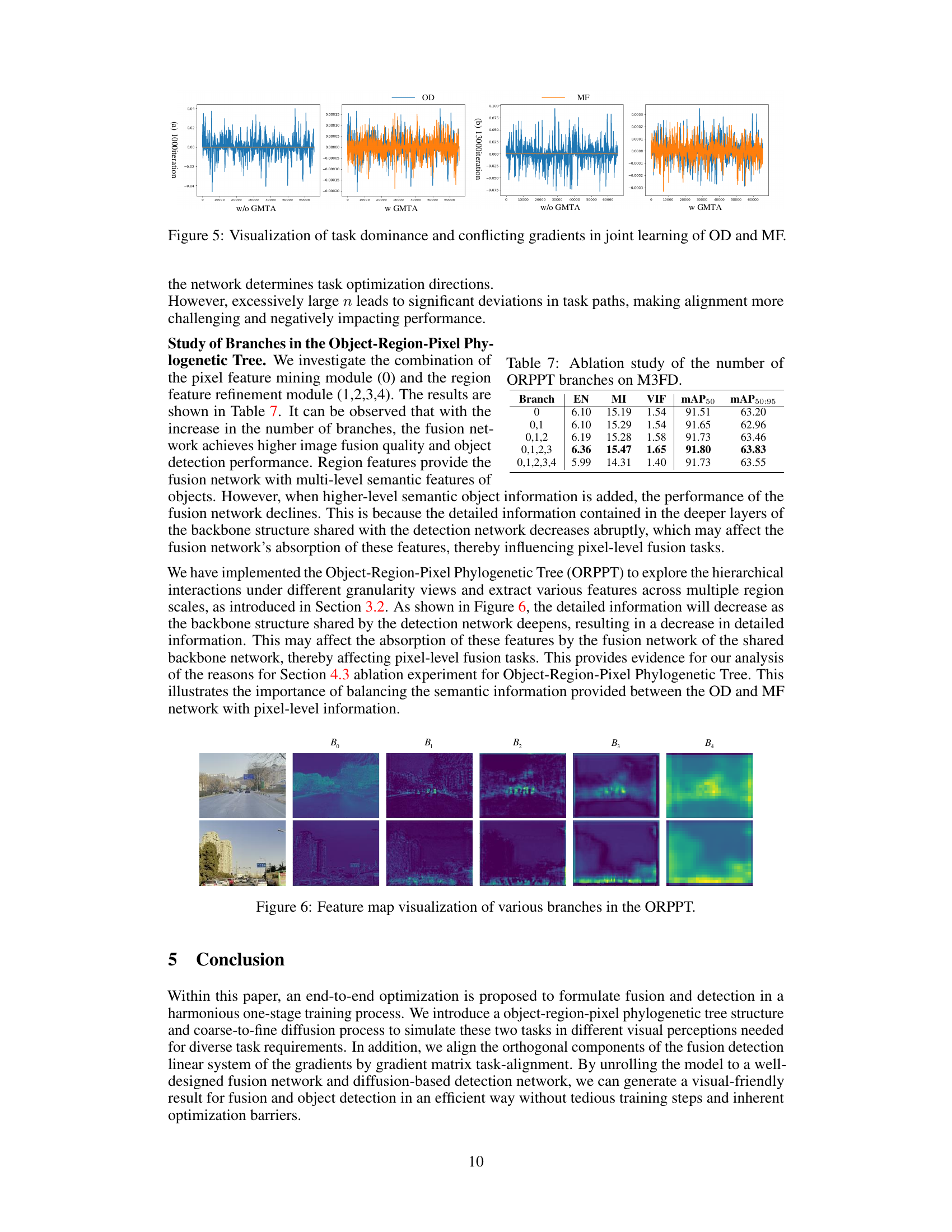
This figure visualizes the gradient values of shared parameters computed by the object detection (OD) loss function (blue) and the multimodal fusion (MF) loss function (orange) during the training process. It demonstrates that without Gradient Matrix Task Alignment (GMTA), the gradients of the OD task dominate, potentially hindering the learning of the MF task. With GMTA, a better balance is achieved, mitigating the impact of conflicting gradients and leading to a more effective optimization of both tasks. The plots show the gradient values over the course of 60,000 training iterations.

This figure visualizes the feature maps generated by different branches of the Object-Region-Pixel Phylogenetic Tree (ORPPT) in the E2E-MFD model. The ORPPT is a novel component designed to extract features at multiple granularities (from coarse to fine). Each branch represents a different level of granularity, allowing the model to capture both global context and detailed local information. The figure showcases how the feature maps change across different branches, illustrating the ORPPT’s ability to capture a multi-scale representation of the input images which is important for both image fusion and object detection tasks.

This figure illustrates the architecture of the E2E-MFD framework. It shows how multimodal images are processed through a backbone network to extract features. These features are then fed into two parallel networks: a fine-grained fusion network (ORPPT) and a diffusion-based object detection network (CFDP). Both networks are jointly optimized using a Gradient Matrix Task-Alignment (GMTA) technique, enabling end-to-end learning. The ORPPT focuses on detailed image fusion, while CFDP handles object detection. This synchronous optimization aims for improved performance in both tasks.

This figure shows a comparison of object detection results on the M3FD dataset using different image fusion methods. The top row displays the ground truth bounding boxes for the objects in the images. The bottom row displays the object detection results obtained by using the YOLOv5s detector on images produced by various image fusion methods, including the proposed E2E-MFD method. The figure visually demonstrates how the quality of the fused images impacts the accuracy of object detection. E2E-MFD produces images that yield more accurate object detection, especially in challenging scenarios with occlusion and overlapping objects.

This figure shows a comparison of object detection results on the M3FD dataset using various image fusion methods. Each row represents a different scene. The first two columns show the visible and infrared images respectively. The subsequent columns demonstrate the fused images produced by different methods (U2Fusion, Tardal, SwinFusion, PIAFusion, DIDFuse, CDDFuse, MetaFusion, YOLOv5s with E2E-MFD fusion, and finally the E2E-MFD method). The red bounding boxes indicate the detected objects. The figure highlights the improved object detection accuracy achieved by the E2E-MFD method, especially for small or occluded objects, compared to other state-of-the-art methods.

This figure shows a qualitative comparison of image fusion results from different methods on the M3FD dataset. Each row represents a different image pair (visible and infrared). The first two columns show the original visible and infrared images. The remaining columns display the fused images generated by several state-of-the-art multimodal fusion techniques, including the proposed E2E-MFD method. The figure visually demonstrates the performance of each method in terms of detail preservation, contrast enhancement, and overall visual quality of the fused image.

This figure displays visual comparisons of object detection results on the M3FD dataset, using different image fusion methods. The results demonstrate that the proposed E2E-MFD approach produces superior object detection outcomes, with clearer object boundaries and reduced missed detections compared to existing methods. This highlights the advantage of the end-to-end synchronous fusion and detection framework in improving the overall detection performance.

This figure shows a comparison of object detection results on the M3FD dataset using different image fusion methods. Each row represents a different scene, with the first two columns showing the visible and infrared images, respectively, followed by fusion images from various methods (U2Fusion, Tardal, SwinFusion, PIAFusion, DIDFuse, CDDFuse, MetaFusion, YOLOv5s using E2E-MFD fused image and finally E2E-MFD). The last column displays the ground truth bounding boxes for comparison. The results visually demonstrate how different fusion techniques affect the object detection performance, highlighting the strengths of the E2E-MFD approach in providing clearer object boundaries and improved detection accuracy.
More on tables
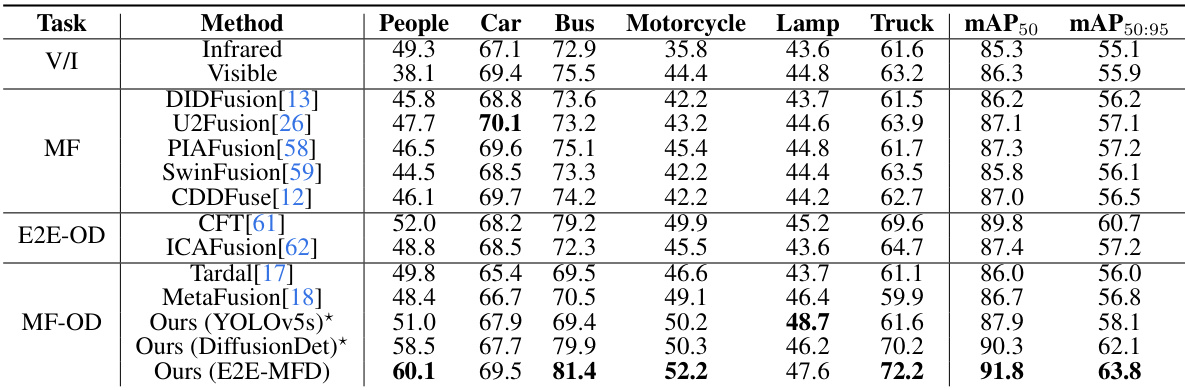
This table presents a comparison of object detection performance on the M3FD dataset using different image fusion methods. The results show the mean average precision (mAP) for various object categories (people, car, bus, motorcycle, lamp, truck) using both the mAP50 and mAP50:95 metrics. The table includes results for using only infrared or visible images, several state-of-the-art (SOTA) fusion methods, end-to-end object detection (E2E-OD) methods, and the proposed E2E-MFD method. The asterisk (*) indicates that the YOLOv5s detector was trained using images produced by E2E-MFD fusion. The best performance for each category is highlighted.
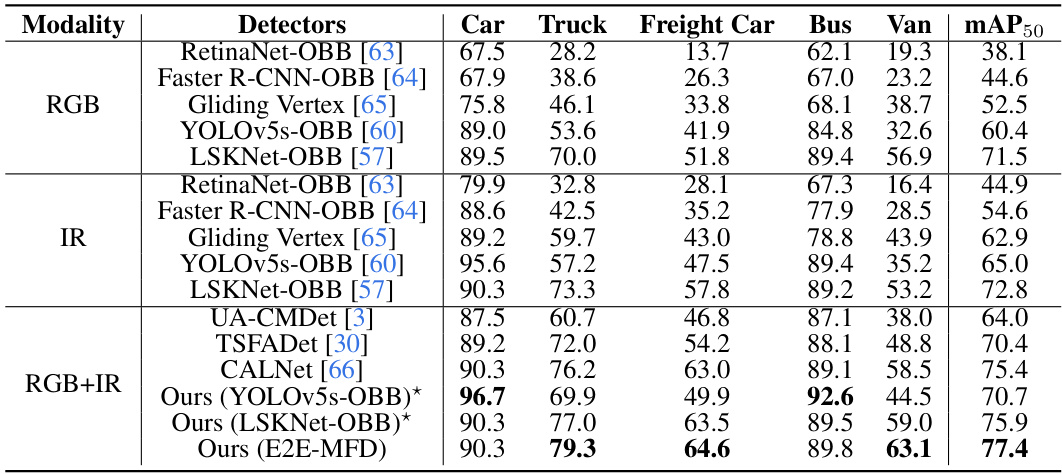
This table presents a quantitative comparison of object detection performance on the DroneVehicle dataset. It compares various state-of-the-art (SOTA) object detection methods across different modalities (RGB, IR, and RGB-IR fusion). The table shows the mean Average Precision (mAP50) scores for each method and modality on the detection of five object classes: Car, Truck, Freight Car, Bus, and Van. The results highlight the improvement in object detection performance achieved by using the fusion images generated by the proposed E2E-MFD method. The best performing method for each class is highlighted.
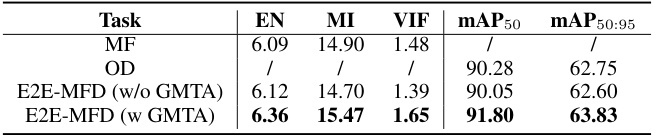
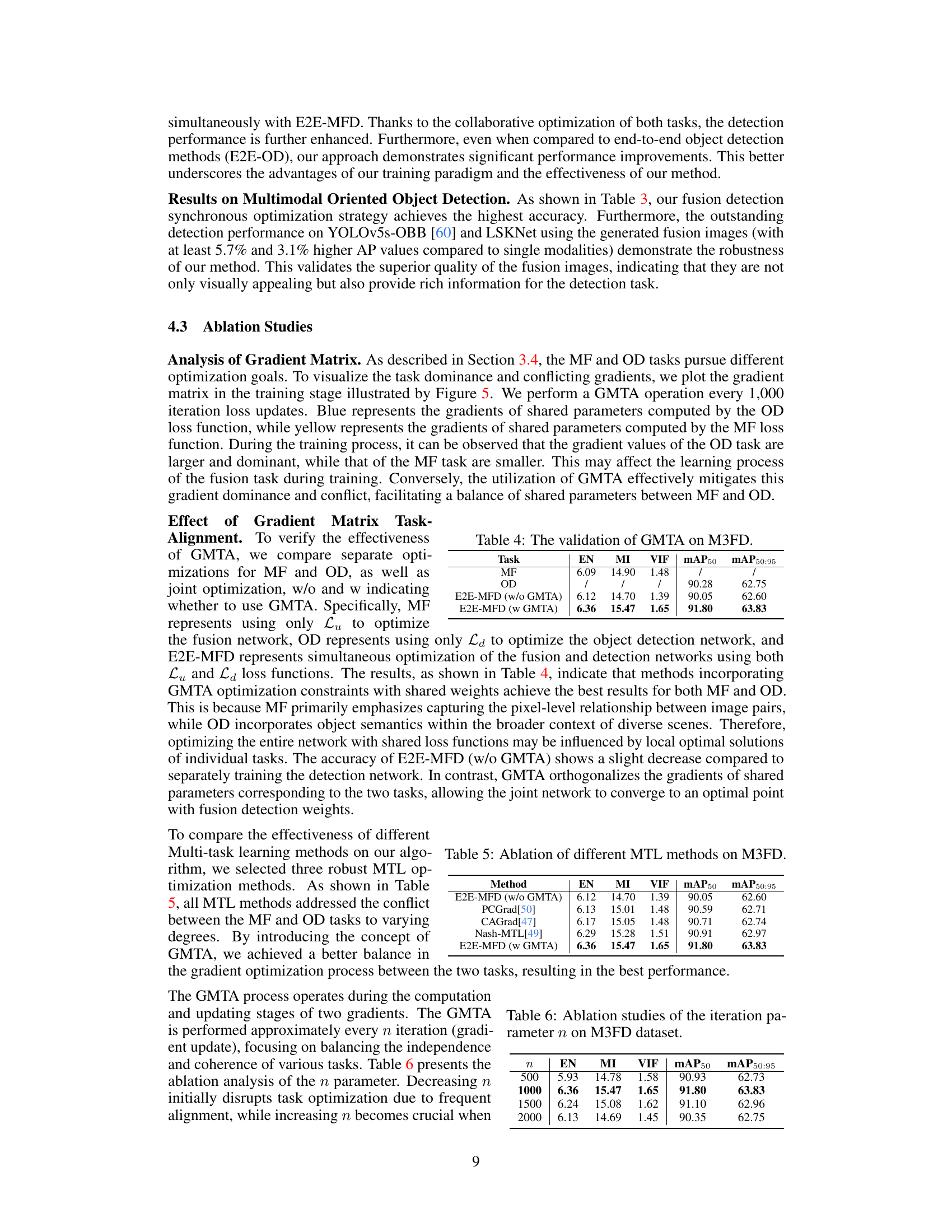
This table presents the quantitative results of the experiments conducted to validate the effectiveness of the Gradient Matrix Task-Alignment (GMTA) method on the M3FD dataset. It compares the performance of the E2E-MFD model with and without GMTA, showing metrics such as EN, MI, VIF, mAP50, and mAP50:95 for both Multimodal Fusion (MF) and Object Detection (OD) tasks. The results demonstrate that using GMTA improves the model’s overall performance.
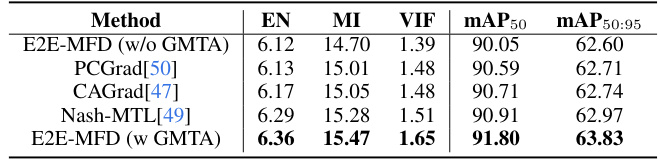
This table presents the ablation study of different multi-task learning (MTL) methods used in the E2E-MFD model. It compares the performance of E2E-MFD without GMTA, and with various other MTL techniques (PCGrad, CAGrad, Nash-MTL) against the E2E-MFD with GMTA. The metrics used for comparison include Entropy (EN), Mutual Information (MI), Visual Information Fidelity (VIF), mean Average Precision at 50% Intersection over Union (mAP50), and mean Average Precision at 50-95% Intersection over Union (mAP50:95). The results demonstrate the effectiveness of the proposed Gradient Matrix Task-Alignment (GMTA) technique for optimizing the performance of the multimodal fusion detection model.
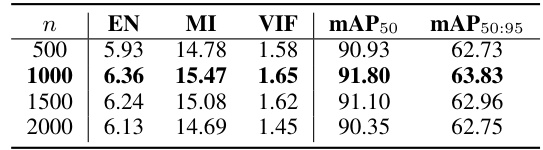
This table presents the ablation study of the iteration parameter n in the Gradient Matrix Task-Alignment (GMTA) method. It shows the impact of different iteration values (n = 500, 1000, 1500, 2000) on the performance metrics: Entropy (EN), Mutual Information (MI), Visual Information Fidelity (VIF), mean Average Precision at 50% IoU (mAP50), and mean Average Precision from 50% to 95% IoU (mAP50:95). The results demonstrate how the frequency of GMTA application affects the balance between the fusion and detection tasks and overall performance.
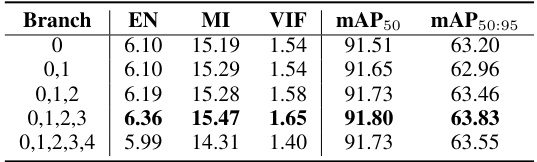
This table presents the ablation study of the number of branches in the Object-Region-Pixel Phylogenetic Tree (ORPPT) on the M3FD dataset. It shows the impact of varying the number of branches (from 0 to 4) on the performance of the multimodal fusion and object detection tasks. The metrics used are Entropy (EN), Mutual Information (MI), Visual Information Fidelity (VIF), mean Average Precision at 50% IoU (mAP50), and mean Average Precision at 50%-95% IoU (mAP50:95). The results indicate the optimal number of branches for balancing performance across different metrics.

This table presents the results of ablation studies conducted on the Coarse-to-Fine Diffusion Process (CFDP) component of the E2E-MFD model. The study varied the number of proposal boxes used (300, 500, and 1000) and whether CFDP was used at all. The table reports the values for Entropy (EN), Mutual Information (MI), Visual Information Fidelity (VIF), mean Average Precision at 50% IoU (mAP50), and mean Average Precision at 50%-95% IoU (mAP50:95). Training time (Tr.Time) is also provided. The results show the impact of CFDP on the performance metrics and the effect of the number of proposal boxes on the model’s overall performance.
Full paper#