↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Generating realistic talking faces from audio has been a challenge, with existing methods often falling short in terms of natural facial expressions and efficient generation. Many methods struggle to synchronize lip movements accurately with audio, and generated videos may appear stiff or unconvincing. Prior work has mainly focused on lip synchronization, neglecting the importance of natural head movement and overall facial expressiveness, leading to an unsatisfying user experience.
The paper introduces VASA-1, a novel framework that addresses these issues. It uses a diffusion-based model operating in a disentangled latent space to effectively generate lip movements and facial expressions synchronized with audio, plus natural head motions. The framework also incorporates optional control signals, resulting in high-quality, lifelike talking faces generated at up to 40 FPS with minimal latency. VASA-1 demonstrates superior performance compared to existing methods across various metrics, marking significant advancement in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision, graphics, and AI due to its significant advancement in real-time talking face generation. It introduces a novel framework (VASA-1) that surpasses existing methods in realism and efficiency, opening avenues for realistic avatar creation in various applications such as virtual assistants, video conferencing, and interactive storytelling. The high-quality, real-time generation capabilities and the innovative disentangled latent space learning are particularly noteworthy contributions.
Visual Insights#

This figure showcases the results of the VASA-1 model. Given a single portrait image and an audio clip (with optional control signals), the model generates a high-quality, lifelike talking face video at 512x512 resolution and up to 40 frames per second. The generated faces realistically mimic human facial expressions and head movements.
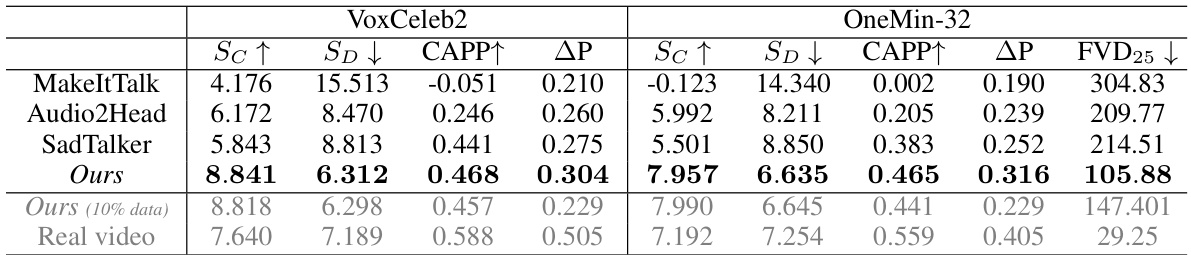
This table presents a quantitative comparison of the proposed method (Ours) against three other state-of-the-art methods (MakeItTalk, Audio2Head, SadTalker) for generating audio-driven talking faces. The comparison is performed on two benchmarks: VoxCeleb2 and OneMin-32. The metrics used for evaluation include audio-lip synchronization (Sc↑ and SD↓), audio-pose alignment (CAPP↑), pose variation intensity (ΔP), and Fréchet Video Distance (FVD25↓). Higher values for Sc and CAPP indicate better performance, while lower values for SD, ΔP, and FVD indicate better performance. The results demonstrate that the proposed method significantly outperforms existing methods on both benchmarks.
In-depth insights#
Audio-Driven Faces#
Audio-driven face generation is a rapidly evolving field with significant implications for communication and entertainment. The goal is to create realistic and expressive talking faces driven solely by audio input, eliminating the need for cumbersome video capture and manual animation. This technology has numerous potential applications, such as virtual avatars for video conferencing, interactive characters in video games, and assistive technologies for individuals with communication impairments. However, several significant challenges need to be addressed. Achieving high fidelity in lip synchronization is crucial, but equally important is the generation of natural head movements and facial expressions that complement the speech. Disentangling various factors such as identity, expression, and pose within the facial representation is key to generating diverse and nuanced animations. Furthermore, ensuring the efficiency of the generation process is vital for real-time applications, making the research on optimized algorithms and lightweight models especially important. The responsible use of this technology needs careful consideration, acknowledging the potential for misuse in creating deepfakes and emphasizing the importance of safeguards against malicious applications.
Diffusion Model#
Diffusion models are a powerful class of generative models that have gained significant traction in recent years, particularly in image generation. They work by gradually adding noise to data until it becomes pure noise, and then learning to reverse this process to generate new data samples. The beauty of this approach lies in its simplicity and its ability to generate high-quality, diverse samples. A key advantage is their capacity for high-resolution generation, surpassing other methods in image clarity and detail. However, the training process is computationally expensive, requiring extensive resources and time. Furthermore, controllability remains a challenge, with fine-grained manipulation of generated outputs often proving difficult. While significant progress has been made, research continues to focus on improving efficiency, enhancing controllability, and exploring new applications of diffusion models across various domains.
Latent Space#
A latent space is a crucial concept in the paper, enabling the representation of complex facial dynamics and head movements in a lower-dimensional space. Disentanglement within this space is a major goal, separating identity, pose, and dynamic features for better control and quality in video generation. The paper innovates by creating a holistic latent space, modeling all dynamic aspects jointly rather than separately. This approach, facilitated by a 3D-aided representation, allows for more natural and expressive talking face videos. The method of constructing this space (using face videos and novel loss functions) is a key contribution. The expressiveness of the space allows for fine-grained control and detailed nuances in the generated video, directly impacting the realism of the output. Ultimately, the latent space acts as the foundation for the diffusion-based generation model, making it the core of the entire system.
Real-time Gen#
The concept of “Real-time Gen,” applied to a research paper likely focusing on generative models, suggests a system capable of producing outputs, such as images or videos, immediately or with minimal latency. This is a significant advancement over traditional methods which may require substantial processing time. The efficiency is crucial for real-world applications like interactive systems, virtual assistants, or live content generation where immediate feedback and response are essential. The paper likely details the algorithms and optimizations used to achieve real-time performance, potentially including hardware acceleration or novel computational techniques. Success hinges on striking a balance: generating high-quality outputs without compromising speed; the research will likely focus on this trade-off, presenting quantitative metrics like frames per second (FPS) and qualitative assessments of output quality. A core aspect of “Real-time Gen” would be scalability—how well the system maintains performance as complexity (input size, model parameters) increases. Challenges might include managing memory constraints, ensuring responsiveness under fluctuating input rates, and implementing robust error handling.
Ethical AI#
Ethical considerations in AI, especially concerning generative models like the one presented, necessitate careful attention. Bias in training data can lead to unfair or discriminatory outputs, demanding rigorous dataset curation and bias mitigation strategies. Misinformation and deepfake generation are significant risks; the potential for misuse demands proactive measures, such as incorporating detection mechanisms and responsible model release protocols. Transparency is key: clearly articulating limitations, potential biases, and intended applications ensures responsible development. Furthermore, algorithmic accountability is crucial; establishing methods to trace outputs to their origins and assess potential harm is necessary. Finally, the broader societal impact – positive and negative – must be considered, with appropriate safeguards to prevent harmful applications and promote equitable access to the technology’s benefits.
More visual insights#
More on figures
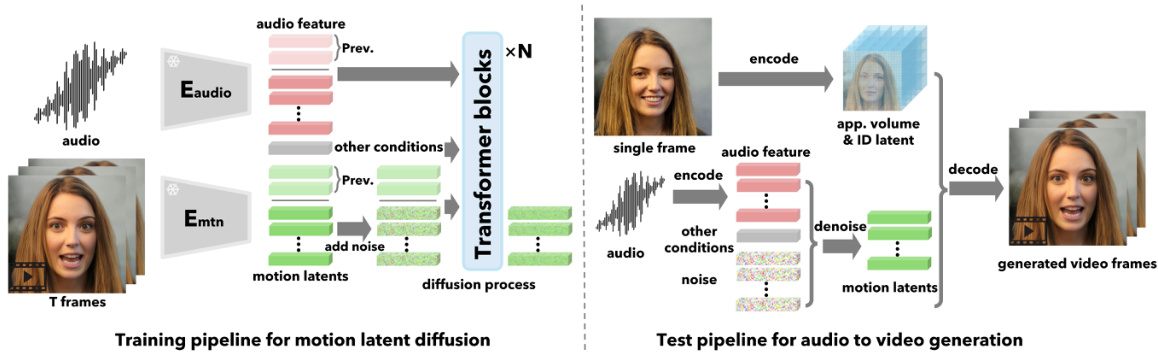
This figure illustrates the VASA-1 framework’s architecture. The left side shows the training pipeline for motion latent diffusion, where a video’s motion latents are fed into a transformer network and undergo a diffusion process (adding and removing noise) conditioned on audio features and other control signals. The right side depicts the test pipeline, which takes a single image and audio as input, extracts the relevant latent codes (appearance, identity, and motion), applies a denoising process through the transformer network, and finally reconstructs the output video frames using a decoder. The figure visualizes the core idea of generating high-quality talking face videos by modeling and controlling facial dynamics in a latent space.

This figure shows the results of generating talking faces with different control signals using the VASA-1 model. The top row demonstrates control over gaze direction, the middle row shows control over head distance from the camera, and the bottom row demonstrates control over the emotional expression of the face.

This figure shows the ablation study of the loss function lconsist, which is designed to disentangle facial dynamics from head pose. The experiment transfers only facial dynamics from a source image to a target image while keeping the target’s head pose unchanged. Comparing the results with and without lconsist, we can see that lconsist is essential for decoupling subtle facial dynamics from head pose, resulting in more natural and realistic facial expressions.

This figure shows example results of the VASA-1 model. Given a single image of a person, an audio clip, and optional control signals, the model generates a high-quality, lifelike talking face video at a resolution of 512x512 pixels and a frame rate of up to 40 FPS. The generated faces exhibit realistic facial expressions and head movements, demonstrating the model’s ability to produce highly lifelike results.

This figure demonstrates the disentanglement between head pose and facial dynamics in the VASA-1 model. It shows three sets of generated video frames: 1) the original sequence with both natural head pose and facial dynamics, 2) the same sequence but with fixed facial dynamics and only changing head pose, and 3) the same sequence with fixed head pose and only varying facial dynamics. This highlights the model’s ability to control these aspects independently.

This figure demonstrates the robustness of the VASA-1 model by showing generation results using various out-of-distribution inputs, including non-photorealistic images and audio containing singing and non-English speech. Despite not being trained on such data, the model maintains high-quality video output synchronized with the audio.

This figure compares the visual results of four different talking face generation methods (MakeItTalk, Audio2Head, SadTalker, and the proposed method) for the same input audio segment saying ‘push ups’. It demonstrates the differences in lip synchronization, facial expressions, and head movements produced by each method. The supplementary video provides a more detailed visual comparison of the generated videos.

This figure compares the results of four different methods for generating talking head videos. The input for all methods is the same audio segment, which says ‘push ups’. The figure shows a sequence of frames generated by each method, allowing for a visual comparison of the lip synchronization, head pose, and overall realism of the generated videos. The methods compared are MakeItTalk, Audio2Head, SadTalker, and the authors’ proposed method. The supplementary video provides a more comprehensive comparison because it includes the audio.

This figure compares the results of four different methods for generating talking head videos from audio: MakeItTalk, Audio2Head, SadTalker, and the authors’ method. The audio input is the phrase ‘push ups.’ Each row represents a different method, showing a sequence of frames generated for that audio clip. The figure highlights the differences in the visual quality, realism, and synchronization between audio and visual movements across the different methods. A supplementary video is suggested for a more comprehensive comparison.

This figure compares the results of four different methods for generating talking faces from audio: MakeItTalk, Audio2Head, SadTalker, and the authors’ method (Ours). The input audio segment is the phrase ’lots of questions’. The figure shows a sequence of frames for each method, allowing for a visual comparison of lip synchronization, facial expressions, and overall realism. The authors recommend viewing the supplementary video for a more thorough assessment.
More on tables
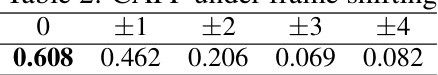
This table presents the results of an ablation study evaluating the sensitivity of the CAPP (Contrastive Audio and Pose Pretraining) metric to temporal misalignment in audio-pose pairs. The CAPP score is calculated for various levels of manual frame shifting (+/-1, +/-2, +/-3, +/-4 frames) applied to ground-truth audio-pose pairs, revealing its robustness and sensitivity to temporal alignment.
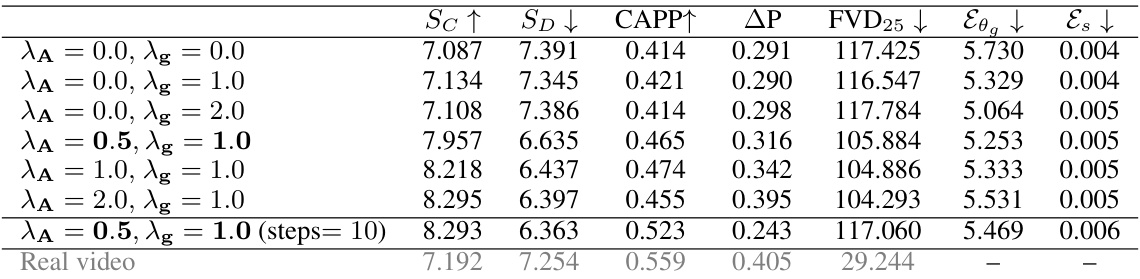
This table presents a quantitative comparison of the proposed method (Ours) with three other state-of-the-art methods (MakeItTalk, Audio2Head, SadTalker) on two benchmark datasets (VoxCeleb2 and OneMin-32). The comparison uses several metrics to evaluate different aspects of the generated videos: audio-lip synchronization (Sc and SD), audio-pose alignment (CAPP), pose variation intensity (ΔP), and overall video quality (FVD25). Higher scores in Sc and CAPP indicate better synchronization, while lower scores in SD, ΔP, and FVD25 signify better quality. The results show that the proposed method outperforms existing methods across all metrics and benchmarks.
Full paper#



















