↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Reconstructing videos from brain activity (fMRI) is challenging due to the limitations of fMRI temporal resolution, the difficulty in decoding both high-level semantics and low-level perception flows, and the lack of powerful models for handling these challenges. Early attempts failed to produce high-fidelity videos due to imprecise semantic reconstruction and insufficient low-level visual detailing. The existing state-of-the-art model, MinD-Video, although showing promise, still lacks the ability to capture low-level details.
NeuroClips addresses these challenges by employing a novel framework that reconstructs high-fidelity videos by integrating a semantics reconstructor (for keyframes) and a perception reconstructor (for low-level details). The keyframes provide semantic accuracy, while the perception flows ensure smoothness. NeuroClips significantly improves video reconstruction quality in various metrics, demonstrating its effectiveness in capturing both high-level semantics and low-level visual details, achieving smoother and more consistent video reconstruction. Furthermore, it pioneers the use of multi-fMRI fusion to reconstruct longer video sequences.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly advances fMRI-to-video reconstruction, a challenging problem with broad implications for neuroscience and brain-computer interfaces. Its novel framework, NeuroClips, achieves state-of-the-art results, paving the way for more realistic and detailed brain-activity decoding. The findings will spur further research into improved fMRI data acquisition, more sophisticated deep learning models, and enhanced applications of brain imaging.
Visual Insights#
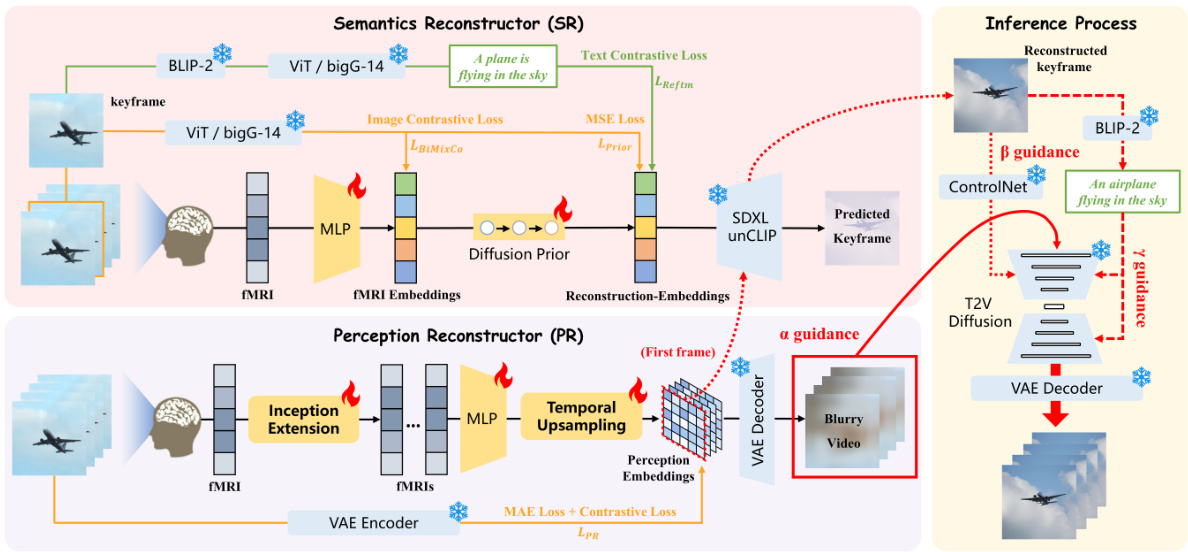
NeuroClips is an fMRI-to-video reconstruction framework that consists of three essential components: Perception Reconstructor (PR), Semantics Reconstructor (SR), and Inference Process. PR generates a blurry but continuous rough video from the perceptual level, while SR reconstructs a high-quality keyframe image from the semantic level. The Inference Process employs a T2V diffusion model and combines the reconstructions from PR and SR to reconstruct the final video with high fidelity, smoothness, and consistency.
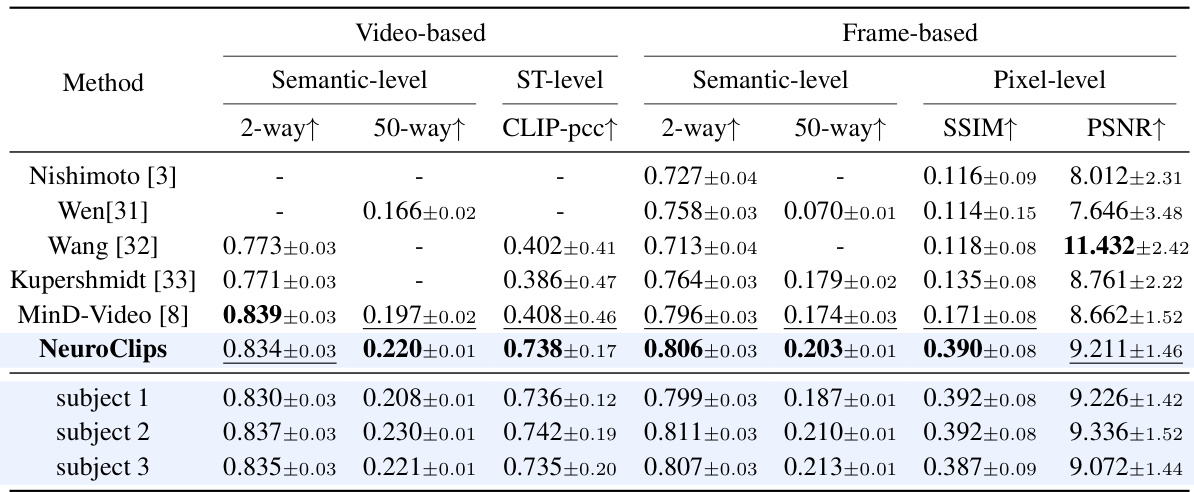
This table presents a quantitative comparison of the NeuroClips model’s video reconstruction performance against several other methods. Metrics are categorized into video-based (semantic-level, spatiotemporal level) and frame-based (semantic-level, pixel-level) evaluations, providing a comprehensive assessment of the model’s accuracy, smoothness, and consistency. The results show NeuroClips outperforms existing state-of-the-art (SOTA) methods across most metrics, especially in terms of structural similarity (SSIM) and spatiotemporal consistency.
In-depth insights#
fMRI-Video Recon#
fMRI-Video Recon presents a significant challenge in neuroscience due to the inherent difficulties in decoding the spatiotemporal dynamics of brain activity. High-fidelity reconstruction demands accurate capture of both high-level semantic information and low-level perceptual details from fMRI data, a task complicated by the low temporal resolution of fMRI compared to video. Current approaches often struggle with achieving smooth, continuous video output, with results frequently appearing jerky and lacking in detail. Advanced deep learning models, such as diffusion models and contrastive learning methods, are crucial for addressing the complexities involved in translating fMRI signals into meaningful video representations. Success hinges on effectively modeling the complex relationship between neural activity and visual perception, requiring innovative methods to bridge the temporal resolution gap and to accurately represent both semantic content and fine-grained visual details. Future advancements will likely involve more sophisticated temporal modeling techniques and possibly the integration of multimodal data to improve reconstruction accuracy and temporal consistency.
NeuroClip Framework#
The NeuroClip framework presents a novel approach to fMRI-to-video reconstruction by addressing the challenge of decoding both high-level semantics and low-level perceptual flows. It leverages a two-pronged strategy: a semantics reconstructor to generate keyframes that capture the high-level semantic content and a perception reconstructor to capture low-level perceptual details for video smoothness. The integration of these keyframes and low-level flows into a pre-trained diffusion model enables the reconstruction of high-fidelity videos. NeuroClip’s innovative architecture shows marked improvements over state-of-the-art models, achieving smoother videos with enhanced semantic accuracy. The use of keyframes aligns with the brain’s inherent processing mechanism making it a biologically plausible approach. Furthermore, the incorporation of multi-fMRI fusion allows for the reconstruction of longer videos, significantly expanding its capabilities. Although promising, NeuroClip’s performance is limited by the relatively small dataset used for training. Future work should focus on expanding the dataset’s size to enable better generalization and address cross-scene limitations.
Multi-fMRI Fusion#
The section on “Multi-fMRI Fusion” presents a novel approach to reconstructing longer videos from fMRI data than previously possible. The core innovation lies in addressing the limitation of standard fMRI, which has a temporal resolution too low to directly decode extended video sequences. Instead of solely relying on single fMRI frames, NeuroClips leverages semantic similarity between consecutive fMRI scans to seamlessly fuse them, generating a more coherent and extended video output. This is achieved by comparing the semantic content (using CLIP embeddings) of reconstructed keyframes from adjacent fMRI segments. If the keyframes are semantically similar, indicating consistency in the visual scene, the end of the first video clip is seamlessly fused with the beginning of the next, extending the video timeline. This technique overcomes the computational cost of directly processing long fMRI sequences, a major hurdle in previous fMRI-to-video approaches. The result is a significant advancement, enabling the reconstruction of longer videos (up to 6 seconds) at higher frame rates (8 FPS), showcasing NeuroClips’ ability to generate more realistic and extended video representations from continuous brain activity.
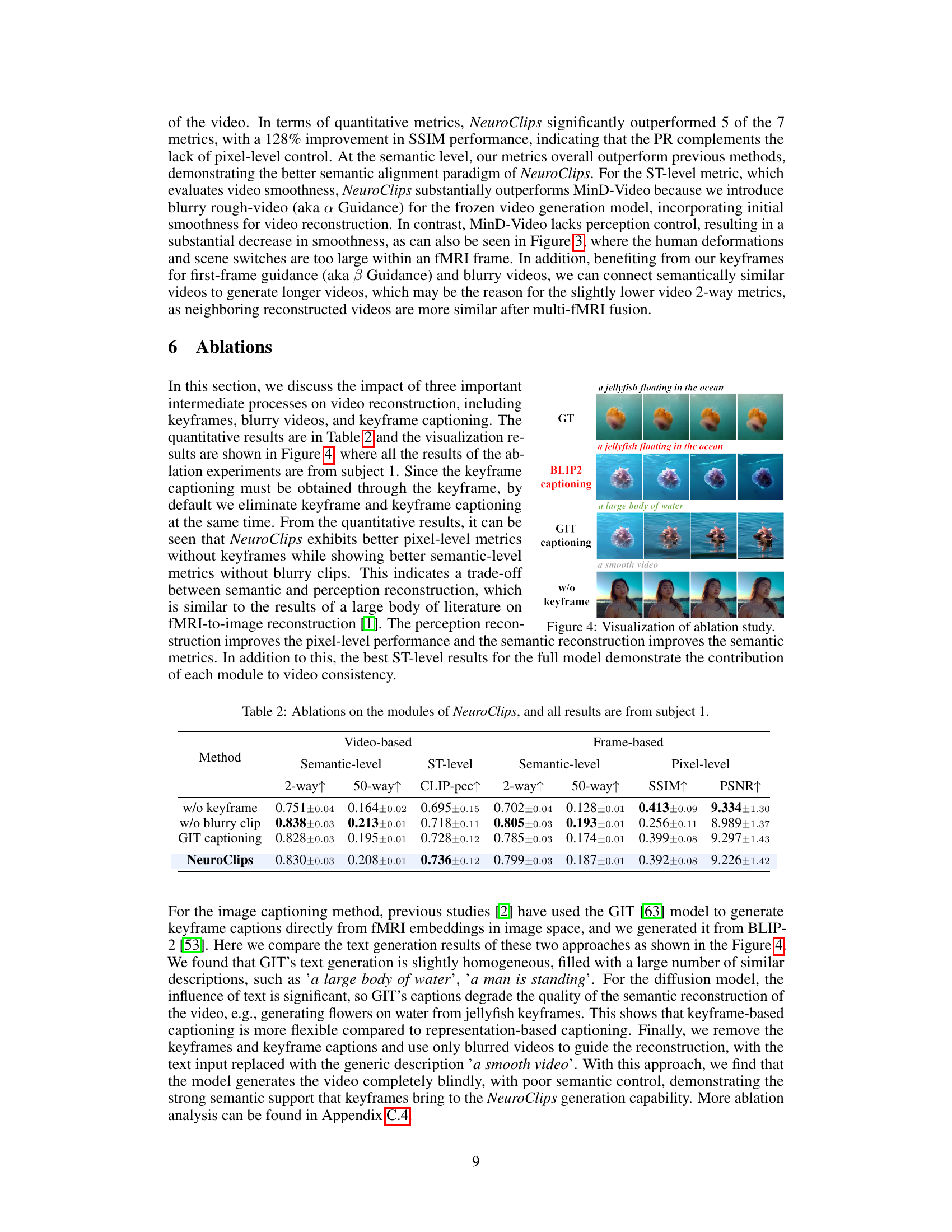
Ablation Studies#
Ablation studies systematically remove components of a model to understand their individual contributions. In this context, it would involve removing parts of the fMRI-to-video reconstruction pipeline (e.g., the perception reconstructor, semantics reconstructor, or specific modules within them) and evaluating the impact on performance metrics like SSIM, PSNR, and various semantic/video consistency scores. Key insights would stem from identifying which components are critical for achieving high-fidelity and smooth video reconstruction. For instance, removing the perception reconstructor might significantly reduce temporal consistency, while removing the semantics reconstructor could hurt semantic accuracy. Analyzing the trade-offs between different components would highlight design choices and potential areas for future improvement. The study would likely demonstrate the necessity of both low-level perceptual flow and high-level semantic information for successful reconstruction; neither alone suffices. Quantifying the impact of each component allows for a principled understanding of model architecture and informs future research directions. The use of ablation analysis contributes to the overall robustness and credibility of the proposed NeuroClips framework.
Future Research#
Future research directions stemming from this fMRI-to-video reconstruction work could explore several avenues. Improving cross-scene reconstruction is crucial, as current methods struggle with transitions between distinct scenes within a video. This requires addressing the inherent limitations in fMRI’s temporal resolution and developing more sophisticated models capable of handling abrupt changes in neural activity. Scaling up to longer videos is another important goal. While the paper makes progress, efficiently generating longer, high-fidelity videos remains a challenge. This may involve exploring more advanced temporal modeling techniques or investigating multi-modal fusion strategies that incorporate additional information sources beyond fMRI data. Furthermore, enhanced semantic understanding warrants further investigation. The current models, while showing improved results, could benefit from more robust semantic encoding and decoding to minimize ambiguities and inaccuracies in reconstruction. Finally, generalization across subjects needs improvement. The models currently show some inter-subject variability. Further research could focus on developing techniques to improve subject-independent reconstruction, perhaps by incorporating more individualized brain mapping or physiological data into the reconstruction process. This would improve the clinical applicability of this technology.
More visual insights#
More on figures
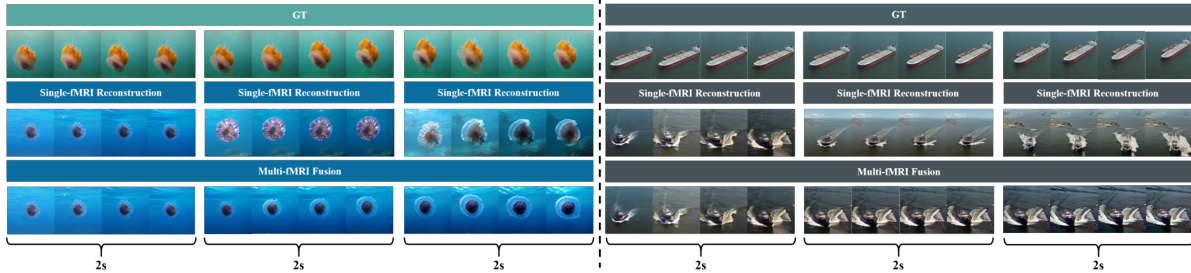
This figure demonstrates the effectiveness of the proposed Multi-fMRI fusion method for generating longer videos (up to 6 seconds). The top row shows the ground truth video frames. The middle row shows the results from reconstructing videos using single fMRI scans, showing limitations in generating consistent and longer videos. The bottom row showcases the results obtained using Multi-fMRI fusion, indicating improved generation of longer, continuous video clips by leveraging semantic relevance between adjacent fMRI frames.

This figure compares video reconstruction results of NeuroClips with several other state-of-the-art methods on the cc2017 dataset. The left side shows comparisons with earlier methods, highlighting the improvements in detail and consistency achieved by NeuroClips. The right side offers further comparisons with more recent top-performing methods, again emphasizing NeuroClips’ superior performance, particularly its ability to maintain detail consistency (e.g., facial features) that other methods lack. The image demonstrates NeuroClips’ ability to reconstruct videos with high-fidelity and smoothness.

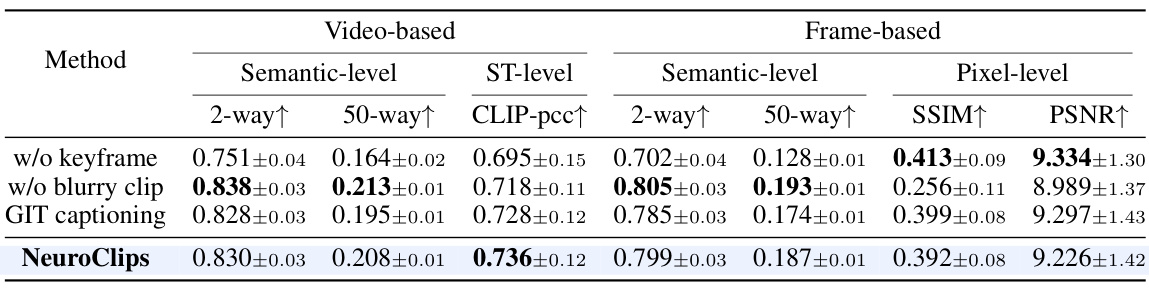
This figure visualizes the ablation study by comparing the video reconstruction results with different components removed. It shows the impact of keyframes, blurry videos, and keyframe captioning on the final video quality. The results highlight the trade-offs between semantic and perceptual reconstruction and the importance of each component for achieving high-fidelity and smooth video reconstruction.
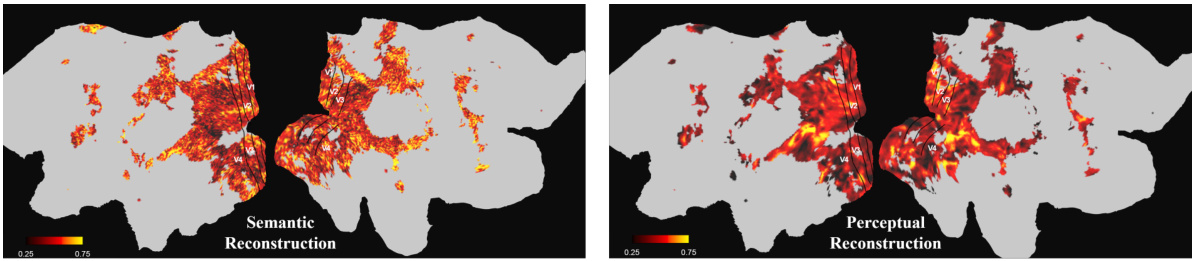
This figure visualizes the voxel-level weights learned by the model for both semantic and perceptual reconstruction tasks on a brain flatmap for subject 1. The color intensity represents the weight magnitude, showing which brain regions contributed most strongly to the respective tasks. Warmer colors (reddish-orange) indicate higher weights. The left panel shows the weights for semantic reconstruction, demonstrating higher activation in higher-level visual areas. The right panel shows weights for perceptual reconstruction, highlighting activation in lower-level visual areas. This visualization provides insights into the model’s neural interpretability by illustrating which brain regions were crucial for each task.
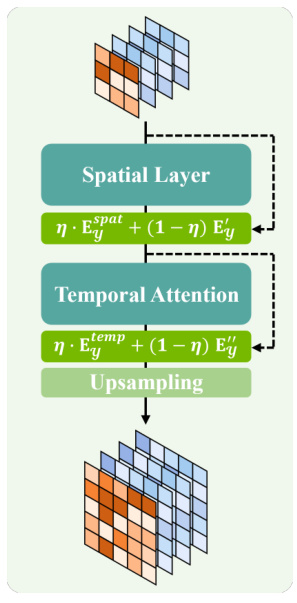
This figure shows the detailed architecture of the Temporal Upsampling module used in the Perception Reconstructor of the NeuroClips framework. The module consists of four main components: a Spatial Layer, a Temporal Attention mechanism, a learnable Residual Connection, and an Upsampling layer. The input is a five-dimensional fMRI embedding (Ey). The Spatial Layer processes this embedding, followed by a learnable residual connection, then Temporal Attention is applied, with another residual connection. Finally, the result is upsampled to the target dimensions. This multi-step process is designed to effectively align fMRI data with the VAE’s pixel space while maintaining temporal consistency and preventing overfitting to noise. Each layer’s input and output dimensions are also shown, along with the equations for the residual connections (using a mixing coefficient η).

This figure displays four pairs of ground truth keyframes and their corresponding reconstructed keyframes generated by the model. Each pair is accompanied by a text description that matches the visual content of the keyframes. The figure aims to demonstrate the model’s ability to reconstruct keyframes that accurately reflect the semantic content and visual details of the original video frames.

This figure shows a visual comparison of video reconstruction results obtained using NeuroClips and other state-of-the-art methods on the cc2017 dataset. The left side compares NeuroClips with earlier methods, highlighting the improvement in detail and consistency. The right side provides additional comparisons with other top-performing methods, further demonstrating NeuroClips’ superior performance in generating high-fidelity and smooth videos.

This figure shows a comparison of video reconstruction results from different methods on the cc2017 dataset. The left side compares NeuroClips’s results to those of several earlier methods, highlighting its improved performance in terms of detail and consistency. The right side provides additional comparisons against state-of-the-art (SOTA) methods, further emphasizing NeuroClips’ superiority in reconstructing high-fidelity videos from fMRI data.

This figure displays visual comparisons of video reconstruction results. The left side shows NeuroClips’ results against several earlier methods, highlighting improvements in detail and consistency. The right side provides additional comparisons with state-of-the-art (SOTA) methods, further emphasizing NeuroClips’ superior performance in terms of high-fidelity reconstruction and smoothness.

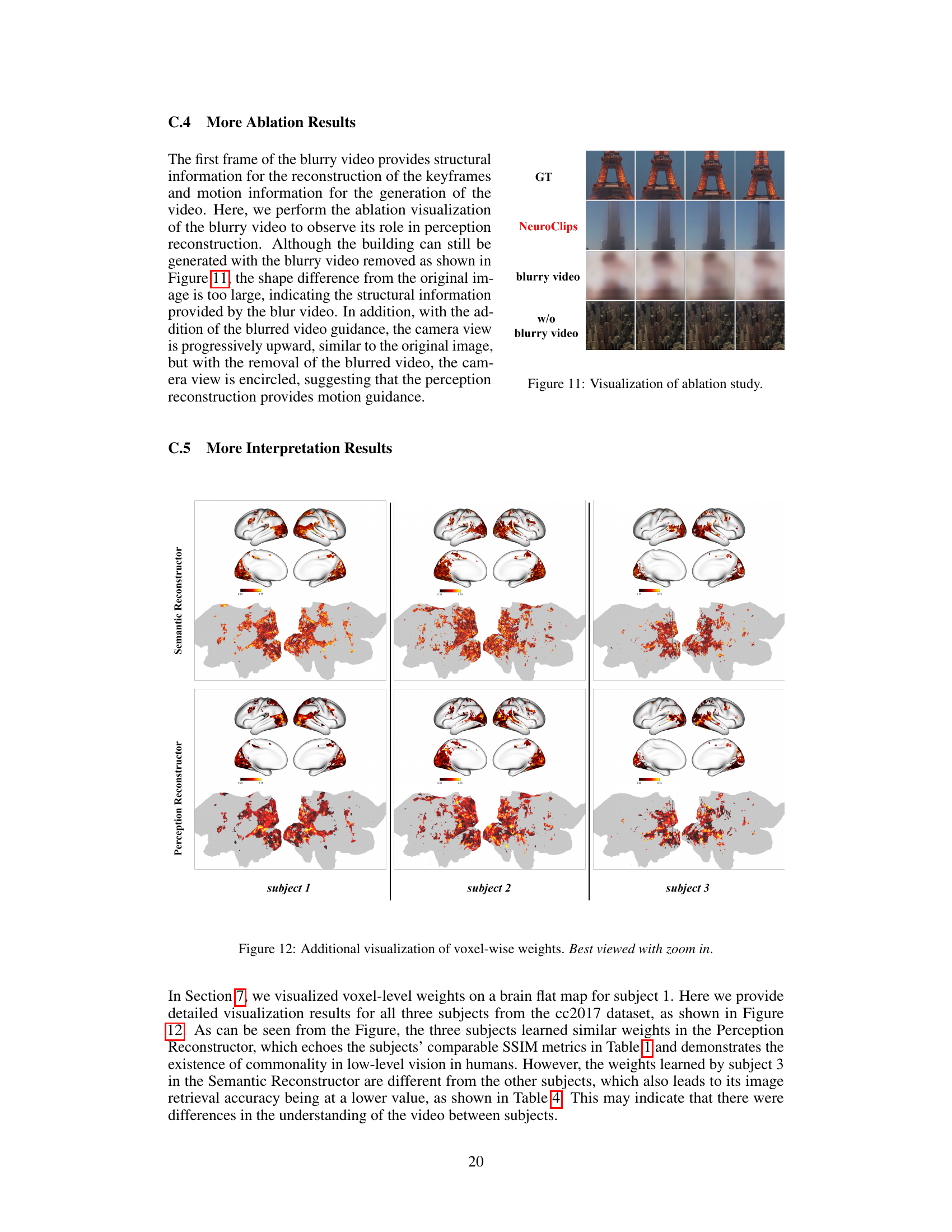
This figure visualizes the ablation study on the blurry video. The top row shows the ground truth video frames of the Eiffel Tower. The second row displays the video frames reconstructed by NeuroClips. The third row shows the blurry video frames generated by the Perception Reconstructor. The bottom row shows the video frames reconstructed without the blurry video. The figure demonstrates that the blurry video plays a crucial role in ensuring the smoothness and structural consistency in video reconstruction.
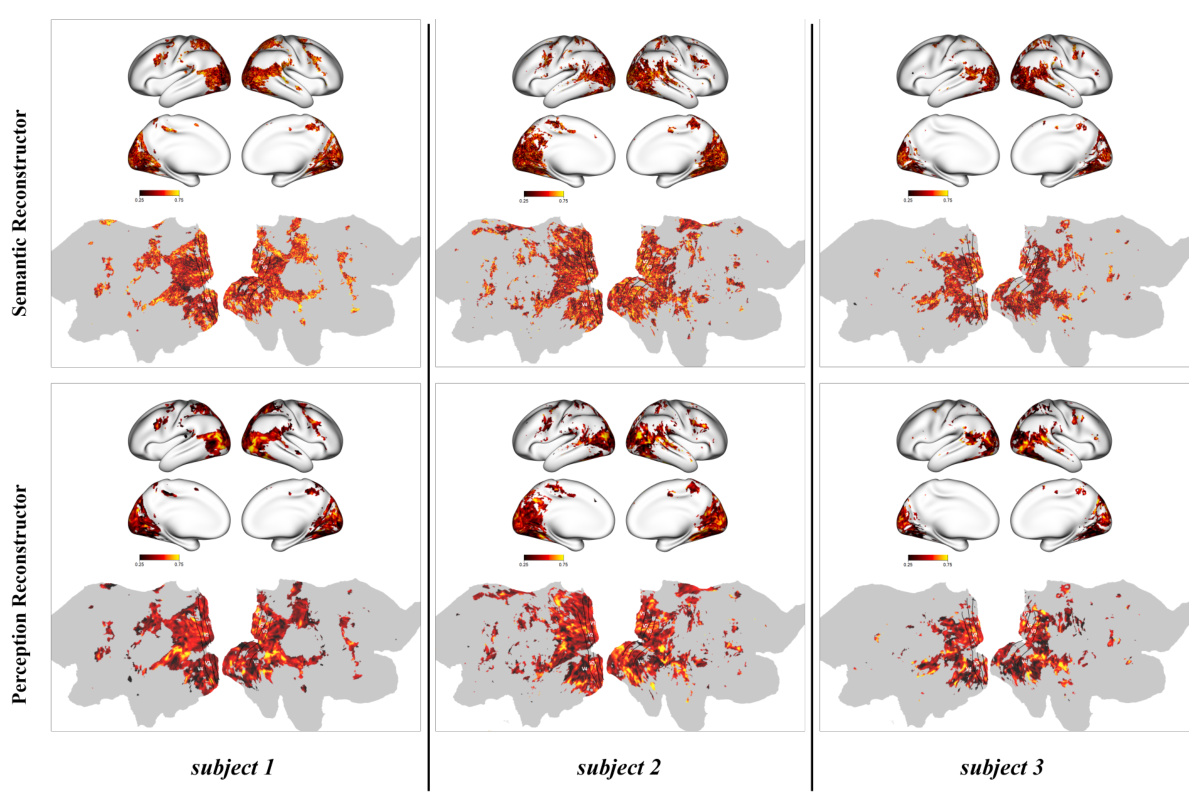
This figure visualizes the voxel-level weights learned by the model for both semantic and perceptual reconstruction tasks. It shows the distribution of weights across the brain’s cortical surface for subject 1. The colormap indicates the magnitude of the weights, with warmer colors representing higher weights. The visualization helps understand which brain regions are most important for the model’s performance in reconstructing different aspects of the video. Higher weights in the higher visual cortex are observed for semantic reconstruction, and higher weights in the lower visual cortex are observed for perceptual reconstruction, which aligns with our understanding of how the brain processes visual information.

This figure shows the results of using SDXL unCLIP to generate images from both COCO and cc2017 datasets. The left side shows the process using an image from COCO dataset. The right side shows the same process using an image from cc2017 dataset. Both sides show the input image, the embedding generated by ViT/bigG-14, and the final image generated by SDXL unCLIP. The consistency across different datasets demonstrates that SDXL unCLIP has strong generalization capabilities, which is crucial for the accurate generation of keyframes in the NeuroClips framework.
More on tables
This table provides a quantitative comparison of the NeuroClips model’s video reconstruction performance against several other state-of-the-art methods. The metrics used assess performance across semantic, frame-based, and pixel-level criteria, providing a comprehensive evaluation of video quality and accuracy. The results are presented for three subjects, highlighting the consistency and effectiveness of the proposed approach.

This table quantitatively compares the performance of the proposed NeuroClips model against seven other state-of-the-art methods for fMRI-to-video reconstruction. It assesses performance across various metrics, categorized as semantic-level (measuring the accuracy of semantic reconstruction), frame-based (evaluating the quality of individual frames using SSIM and PSNR), pixel-level (assessing visual fidelity of reconstructed frames) and video-based (evaluating overall video quality using metrics like spatiotemporal consistency). The results are presented in terms of different evaluation metrics for a 2-way and 50-way classification, CLIP-pcc, and ST-level metrics. Results highlight the significant improvements achieved by NeuroClips across multiple assessment dimensions.

This table compares the performance of NeuroClips against other methods for fMRI-to-video reconstruction across various metrics. Metrics are categorized into semantic-level, frame-based, and pixel-level evaluations. Results are presented for the 2-way and 50-way classification tasks, CLIP-pcc for video smoothness, SSIM and PSNR for pixel-level quality, and ST-level for spatiotemporal consistency. The best and second-best performances are highlighted.
Full paper#