↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
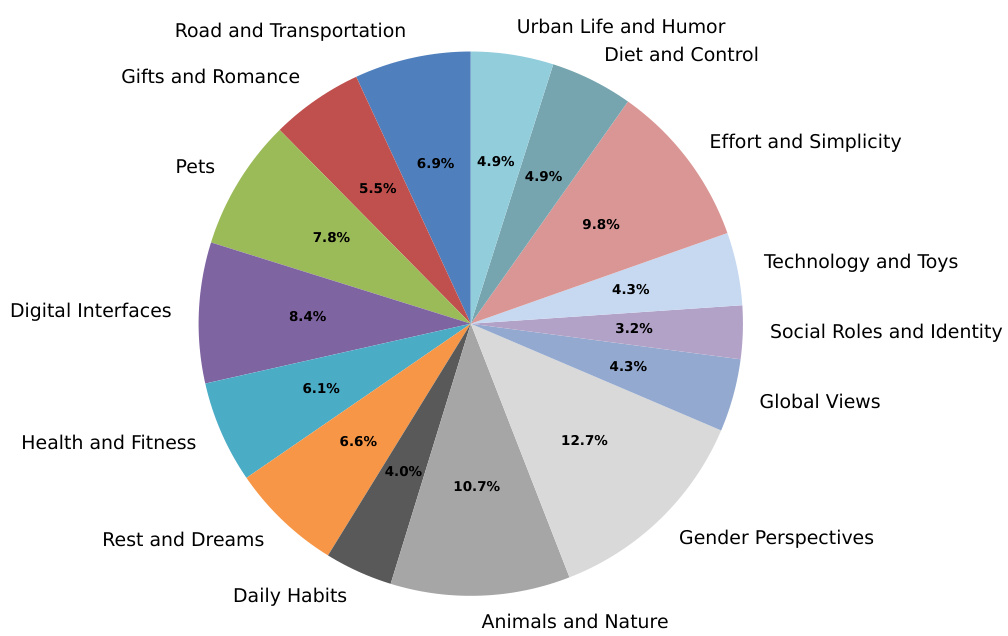
This paper investigates AI’s ability to understand humor stemming from juxtaposition, particularly within the context of comics. Existing AI models often struggle with the complex, nonlinear narratives inherent in this type of humor, which requires deep comprehension of human norms, social cues, and cultural references. The models also have difficulty with non-linear reasoning due to their autoregressive nature.
To address this challenge, the authors introduce YESBUT, a new benchmark dataset containing comics with contradictory narratives. This benchmark includes four tasks designed to assess AI capabilities across various levels of difficulty, ranging from simple literal comprehension to deep narrative understanding. Their experiments reveal significant limitations in current AI’s capacity to grasp this complex form of humor, prompting the development and testing of more sophisticated AI approaches for interpreting human creative expression.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI and humor understanding because it identifies a significant gap in current models’ ability to comprehend nuanced humor, specifically humor derived from juxtaposition in comics. It introduces a novel benchmark (YESBUT) that facilitates future research to improve AI’s capabilities in understanding complex narrative structures and social contexts. This research opens avenues for creating more socially and culturally intelligent AI systems.
Visual Insights#
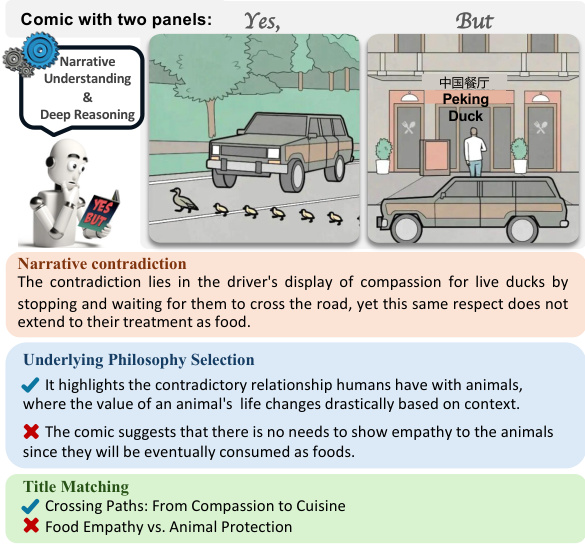
This figure introduces the YESBUT dataset, a benchmark for evaluating AI’s ability to understand comics with contradictory narratives. It shows an example comic with two panels creating a humorous contradiction (a driver stops for ducks but then goes to a Peking Duck restaurant). The caption highlights that the dataset includes tasks assessing different levels of understanding: literal comprehension, narrative reasoning, philosophy identification, and title matching.
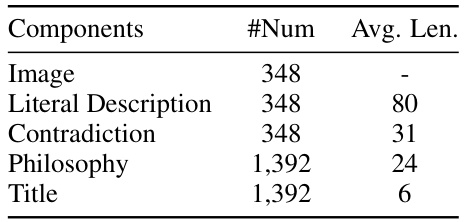
This table presents the statistics of the YESBUT dataset, showing the number of instances and average length for each component. The components include the image, literal description of the comic narrative, the explanation of the contradiction, the underlying philosophy, and the comic title. Average length is measured in words.
In-depth insights#
Humor’s Juxtaposition#
Humor’s juxtaposition, a concept exploring the comedic effect derived from placing contrasting elements together, presents a rich area for investigation. The inherent incongruity creates surprise and unexpectedness, key components of humor. Analyzing this requires understanding not just the individual elements but also the cognitive processes involved in recognizing the contrast and deriving meaning. This includes considering factors such as audience expectations, cultural context, and the nature of the contradiction itself. Nonlinear narratives, often present in jokes and comics, become crucial here, challenging conventional semantic analysis. Research in this area could employ computational models to assess how well AI systems can recognize and understand these complex relationships, thus advancing our comprehension of humor and potentially leading to the creation of more sophisticated and nuanced AI humor generation capabilities. The challenge lies in moving beyond literal understanding to grasp the deep semantic connections and contextual cues that drive the humorous effect of juxtaposed elements. This is a multifaceted problem requiring insights from both linguistics and cognitive science.
YESBUT Benchmark#
The YESBUT benchmark is a novel contribution in assessing AI’s understanding of humor derived from juxtaposition in comics. Its strength lies in focusing on contradictory narratives across two panels, moving beyond single-panel analyses. The benchmark’s design is thoughtful, incorporating tasks of varying complexity, from literal comprehension to deep narrative reasoning, enabling a multi-faceted evaluation of AI capabilities. The inclusion of tasks such as contradiction generation, underlying philosophy selection, and title matching allows for a rich understanding of the model’s comprehension. The benchmark’s careful annotation process and human evaluation further strengthens its validity and reliability. However, a limitation is the dataset size. Future iterations could benefit from expanding the scope to include a broader range of visual humor styles and cultural contexts. Despite its limitations, YESBUT provides a valuable tool for evaluating AI progress in understanding complex aspects of human creative expression.
VLM/LLM Humor Gap#
The “VLM/LLM Humor Gap” highlights the significant discrepancy between human understanding of humor and the capabilities of current Vision-Language Models (VLMs) and Large Language Models (LLMs). While these models excel in various tasks, they struggle with the nuances of humor, especially those involving juxtaposition and nonlinear narratives. This gap stems from several limitations. First, models lack the rich contextual understanding and social reasoning skills needed to interpret subtle humor cues. They often focus on literal interpretations rather than grasping the implied meaning. Second, the architecture of current VLMs and LLMs often hinders their ability to process information non-linearly, which is crucial for understanding jokes based on unexpected twists or contradictions. Bridging this gap requires further research focusing on improving models’ capacity for contextual understanding, social intelligence, and nonlinear reasoning. Developing benchmarks specifically designed to assess humor understanding is also crucial. Such benchmarks, along with datasets annotated for nuanced humor interpretation, can help drive progress towards more sophisticated and human-like AI systems capable of appreciating humor.
Nonlinear Reasoning#
Nonlinear reasoning, in the context of AI and specifically in understanding humor, presents a significant challenge. Linear models struggle because humor often relies on unexpected juxtapositions and shifts in perspective, requiring the AI to move beyond straightforward, sequential processing. To grasp a joke, an AI needs to integrate information from disparate parts of a narrative, not just process it chronologically. This involves recognizing subtle contradictions, implicit meanings, and complex relationships between seemingly unrelated elements, which requires a more sophisticated cognitive architecture. Successfully implementing nonlinear reasoning in AI would entail developing models capable of bidirectional processing and multi-layered representation, allowing for a more fluid and contextual understanding of information. This could involve incorporating techniques from graph theory or other non-linear mathematical frameworks to model the interconnectedness of ideas. Deep learning models, with their ability to learn complex patterns, may offer one pathway, but will likely require further adaptations to address the specific requirements of nonlinear reasoning within the context of complex narratives like those found in humor.
Future Directions#
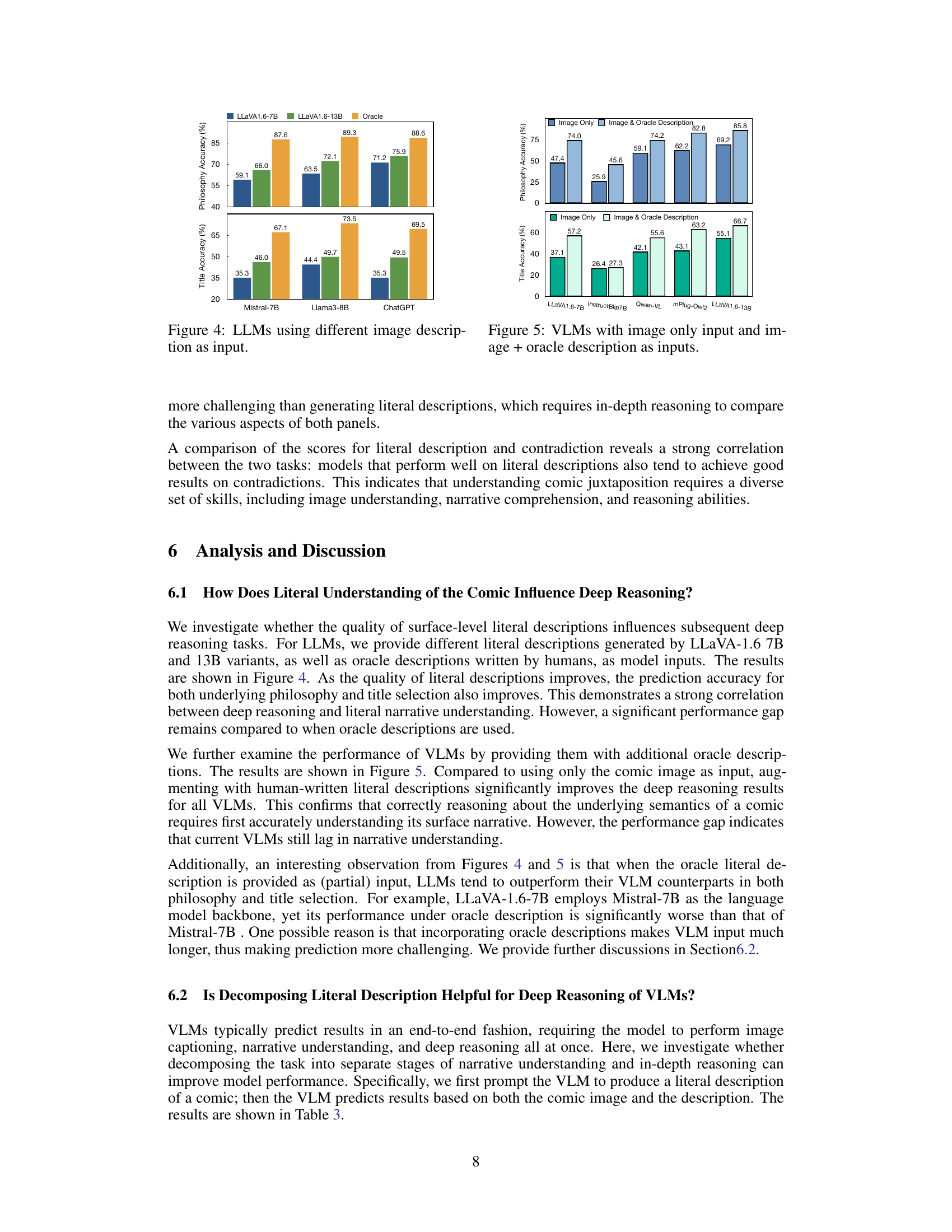
Future research should prioritize addressing the limitations revealed in this study. Improving visual interpretation capabilities of AI models is crucial; they frequently misinterpret visual elements, leading to flawed narrative comprehension. Enhancing the models’ ability to understand nuanced human emotions and social contexts is equally important for accurate interpretation of humor stemming from juxtaposition. Investigating the efficacy of decomposing the complex task into smaller, more manageable stages, such as separate modules for literal understanding and deep reasoning, could improve performance. Further research should explore the effect of incorporating more sophisticated contextual reasoning and world knowledge into the models. This could involve leveraging techniques like multi-agent debate or incorporating external knowledge bases to enhance the models’ ability to grasp the complexities of human humor. Finally, a larger, more diverse dataset is needed, ensuring better representation of various humor styles and cultural contexts. This comprehensive approach would lead to a more robust and nuanced understanding of human creative expressions by AI.
More visual insights#
More on figures

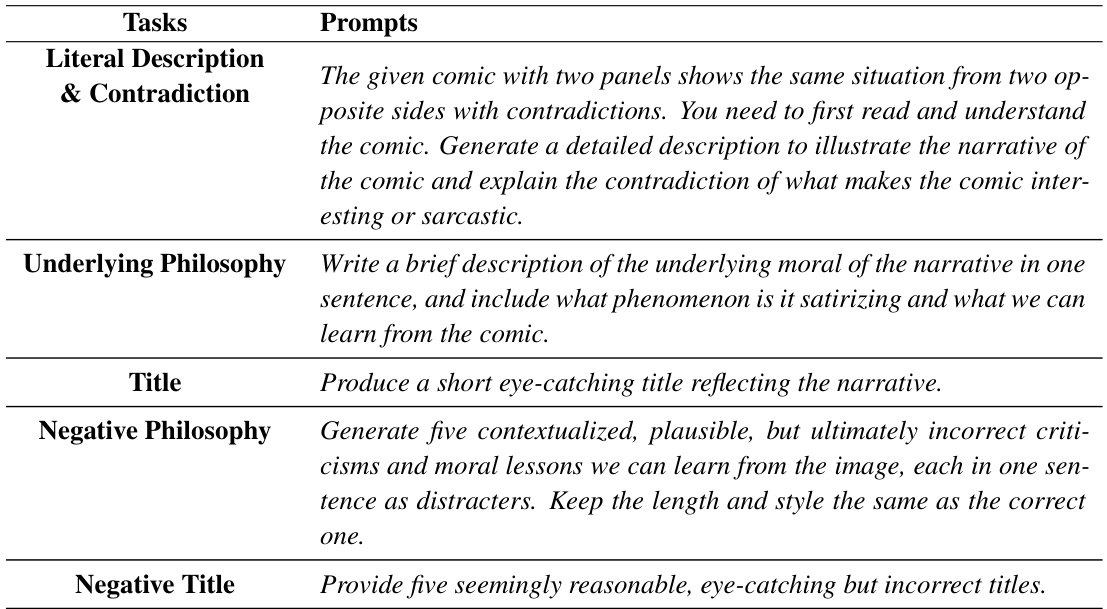
This figure illustrates the data annotation pipeline used in the YESBUT dataset creation. It details the three steps involved: 1) Narrative Description Writing (including literal description and contradiction identification), 2) Deep Content Writing (including underlying philosophies and title generation), and 3) Quality Check (ensuring bias reduction, length control, style consistency and readability). The figure shows example annotations for each component, highlighting positive (Pos) and negative (Neg) options for the underlying philosophy and title selection tasks. This visual representation clearly outlines the multi-stage process of generating high-quality annotations for the YESBUT dataset, emphasizing both human and AI collaboration.
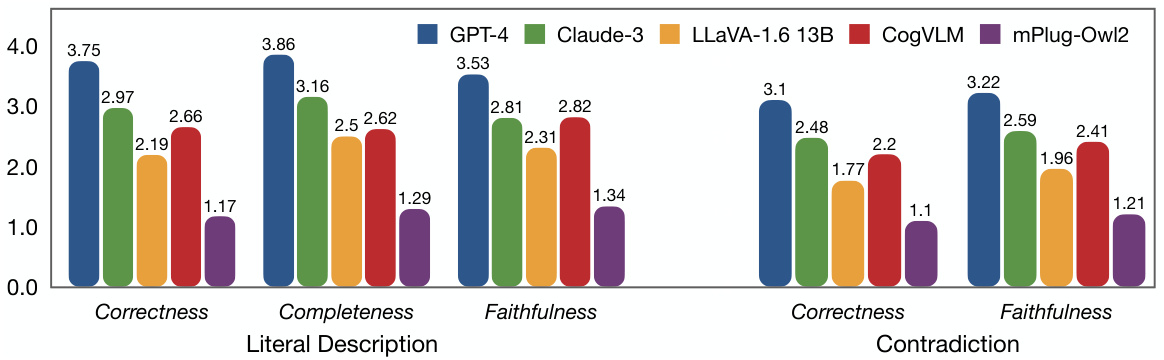
This figure presents the results of a human evaluation assessing the quality of literal descriptions and contradiction generations produced by different vision language models. The evaluation metrics used were Correctness, Completeness, and Faithfulness for literal descriptions, and Correctness and Faithfulness for contradiction generation. The bars represent the average scores for each model across these metrics. The figure visually demonstrates the relative performance of various models on these two tasks, indicating variations in their ability to accurately and comprehensively capture the narrative nuances and contradictory elements in comic strips.
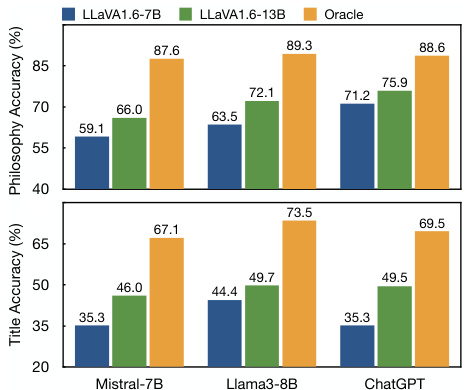
This figure displays the results of experiments using different Large Language Models (LLMs) with varying image descriptions as input. The x-axis shows the different LLMs used: Mistral-7B, Llama3-8B, and ChatGPT. The y-axis represents the accuracy percentages for both Philosophy Selection and Title Matching tasks. The bars for each LLM represent three conditions: using the LLaVA1.6-7B generated descriptions, the LLaVA1.6-13B generated descriptions, and finally, using human-written oracle descriptions. The figure demonstrates how the quality of the input description affects the performance of LLMs in the deep reasoning tasks.
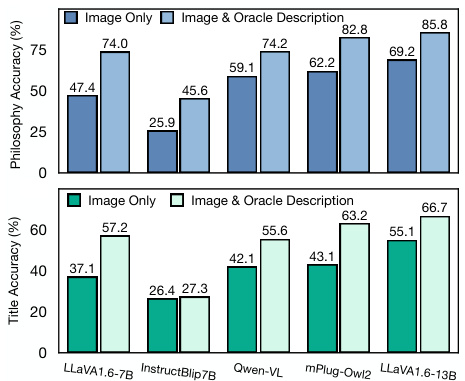
This figure displays the results of experiments evaluating the performance of various Vision-Language Models (VLMs) on two tasks: Underlying Philosophy Selection and Title Matching. Two sets of results are shown for each model. The first uses only the image as input to the model. The second uses both the image and a human-written, ‘oracle’, description of the comic’s literal narrative as input. The bar chart shows that in both tasks, augmenting the model input with the oracle description significantly improves the model’s accuracy.

This figure introduces the YESBUT dataset, a benchmark for evaluating AI models’ ability to understand comics with contradictory narratives. It shows an example comic with two panels creating a humorous contradiction (a driver stopping for ducks, then going to a Peking Duck restaurant). The caption highlights that the dataset includes tasks assessing different levels of comprehension, from literal understanding to deeper narrative reasoning. These tasks include writing a literal description, identifying the contradiction, selecting the underlying philosophy, and matching the comic with an appropriate title.

This figure introduces the YESBUT dataset, which contains comics with two panels that create humorous contradictions. The dataset is designed to assess AI’s ability to understand humor through juxtaposition. The example comic shows a driver stopping for ducks to cross the road (Yes), then going to a Peking Duck restaurant (But), highlighting the contradiction between showing compassion for live ducks and consuming them as food. Three tasks evaluate AI performance: understanding the narrative, selecting the underlying philosophy, and matching a title to the comic.
The figure shows a sample comic from the YESBUT dataset, which is used to evaluate AI models’ ability to understand humor in comics using juxtaposition. The comic consists of two panels that present a contradictory narrative, creating a humorous effect. The figure also illustrates the different tasks included in the YESBUT benchmark. These tasks assess AI capabilities in recognizing and interpreting the humor in the comic, at varying levels of difficulty, from literal content comprehension to deep narrative reasoning. The tasks range from generating a description of the literal content to identifying the underlying philosophical theme or title that best fits the comic’s overall meaning.

This figure introduces the YESBUT dataset, which is a benchmark for evaluating AI models’ ability to understand humor in comics. The dataset consists of two-panel comics with contradictory narratives. The figure shows an example comic, along with descriptions of tasks designed to assess different levels of comprehension—from literal understanding to deeper narrative reasoning.

This figure introduces the YESBUT dataset, which contains comics with two panels that present contradictory narratives. The example comic shows a driver stopping for ducks to cross the road (panel 1, ‘Yes’) and then going to a Peking Duck restaurant (panel 2, ‘But’), highlighting a humorous contradiction. The dataset is used to assess AI models’ ability to understand humor from juxtaposition in comics. The figure also details three tasks designed to evaluate different levels of comprehension: narrative understanding, underlying philosophy selection and title matching. Each task requires a different level of deep reasoning and understanding of the comic.

This figure introduces the YESBUT dataset, which contains comics with two panels that create a humorous contradiction. The dataset is used to assess AI models’ ability to understand this type of humor. The caption highlights that the dataset is used for evaluating AI’s capabilities in various tasks, including narrative understanding, selecting the underlying philosophy, and title matching, thus testing different levels of comic comprehension.
More on tables
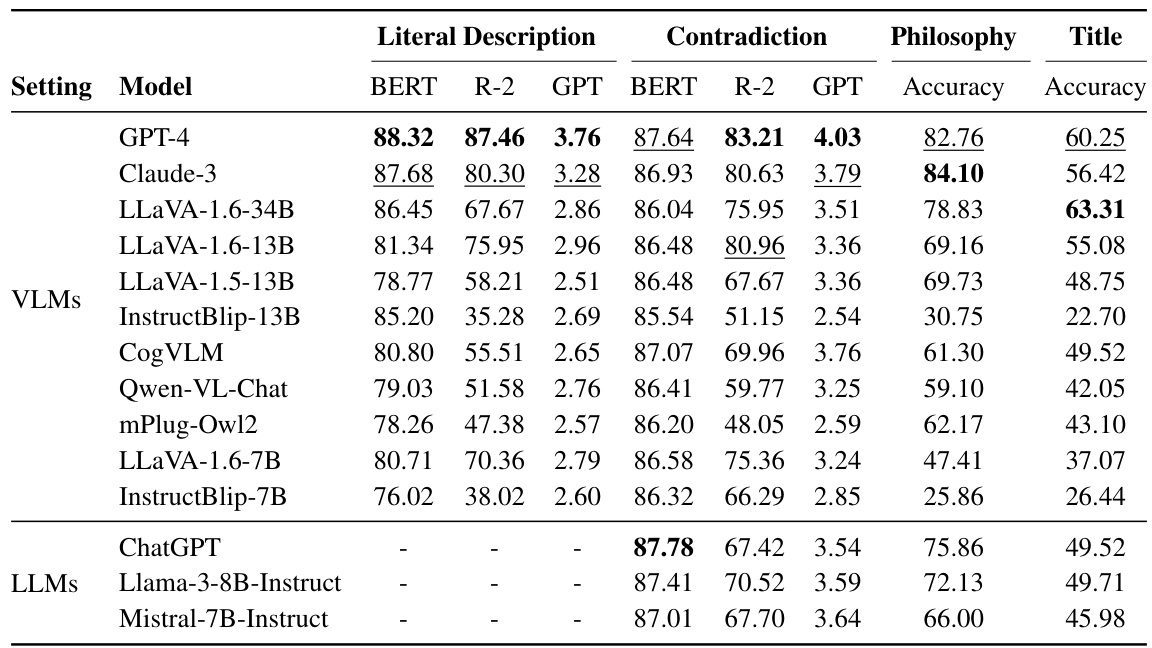
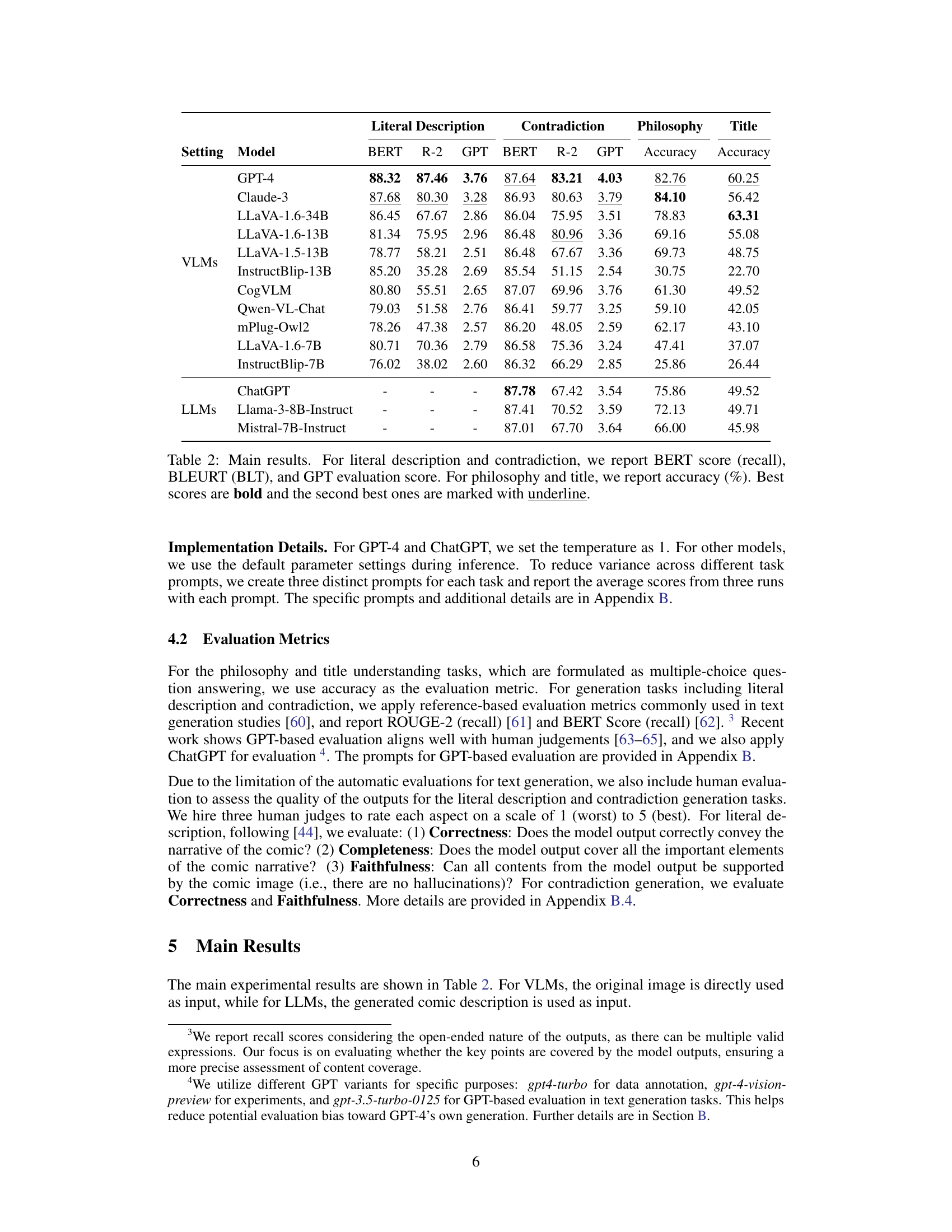
This table presents the main results of the experiments conducted in the paper. It shows the performance of various large language models (LLMs) and large vision-language models (VLMs) on four different tasks related to understanding comics: Literal Description, Contradiction, Underlying Philosophy Selection, and Title Matching. The results are presented in terms of accuracy (%) for the philosophy and title tasks, and BERT score (recall), BLEURT (BLT), and GPT evaluation score for the literal description and contradiction tasks. The best and second-best scores for each task and model are highlighted in bold and underlined, respectively. The table allows for a direct comparison of model performance across different tasks and model types.
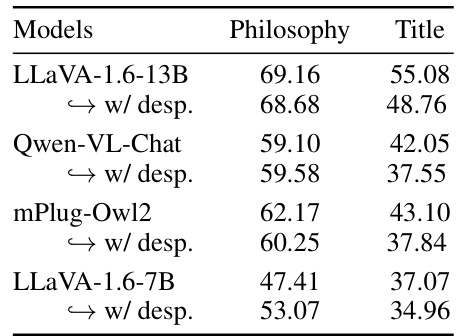
This table presents the main results of the experiments conducted in the paper. It shows the performance of various large language models (LLMs) and large vision-language models (VLMs) on four different tasks related to understanding comics: Literal Description, Contradiction Generation, Underlying Philosophy Selection, and Title Matching. The metrics used to evaluate performance vary depending on the task and include accuracy, BERT score, BLEURT score and GPT evaluation scores. The table highlights the superior performance of commercial models (GPT-4, Claude-3) compared to open-sourced models, especially in the more complex tasks involving deep reasoning. The inclusion of oracle comic descriptions is also examined, showcasing their positive impact on overall performance.
This table presents statistics for the YESBUT dataset, showing the number of samples for each component (image, literal description, contradiction, philosophy, and title) and the average length (in words) of the literal descriptions.
Full paper#