↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Generalized Category Discovery (GCD) faces challenges due to the lack of prior knowledge for new classes, leading to unsynchronized learning between teacher and student models. Traditional teacher-student methods often suffer from inconsistent pattern learning across attention layers, resulting in suboptimal performance. This is because the teacher model often remains static and fails to adapt to the student’s evolving understanding.
To address this, the paper introduces FlipClass, a novel approach that dynamically updates the teacher model based on the student’s attention. This ‘flipped classroom’ strategy leverages an energy-based perspective to align teacher and student attention, thereby promoting consistent pattern recognition and synchronized learning. Extensive experiments show that FlipClass significantly outperforms existing GCD methods across various benchmarks, setting new standards for the field.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in semi-supervised learning and generalized category discovery. It directly addresses the critical issue of learning inconsistencies in teacher-student frameworks, a significant challenge in open-world settings. The proposed method, FlipClass, offers a novel solution with substantial performance improvements, opening new avenues for research in dynamic teacher-student alignment and adaptive learning strategies. The comprehensive analysis and empirical results provide valuable insights and benchmarks for future studies. This work also significantly advances the field’s understanding of attention mechanisms in the context of GCD.
Visual Insights#
This figure demonstrates the differences between traditional Teacher-Student Consistency Models (TSCM) and the proposed FlipClass model in handling new classes during learning. The left panel shows the learning curves of TSCM and FlipClass on the Stanford Cars dataset, highlighting the learning gap and unsynchronized learning in TSCM. The middle panel compares the model performances of TSCM and FlipClass, illustrating how FlipClass addresses the issue of inconsistent feature learning across different classes. The right panel illustrates the inner feedback mechanism of FlipClass, demonstrating how teacher attention is dynamically adapted based on student feedback, thereby achieving synchronized learning.
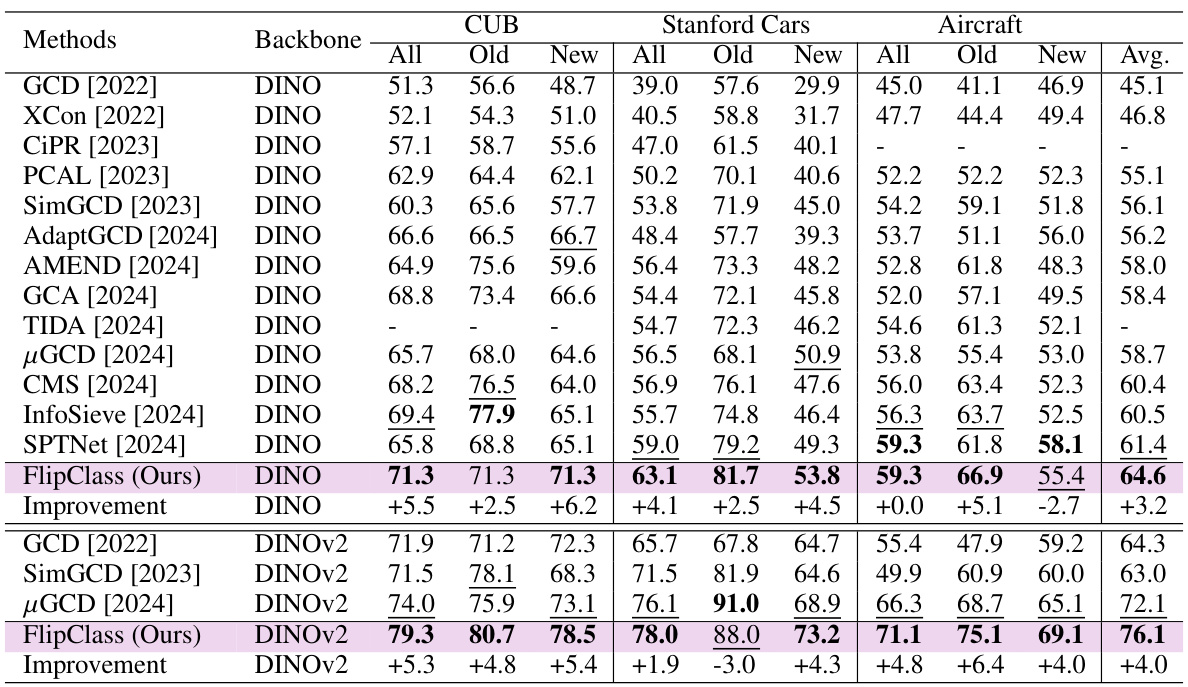
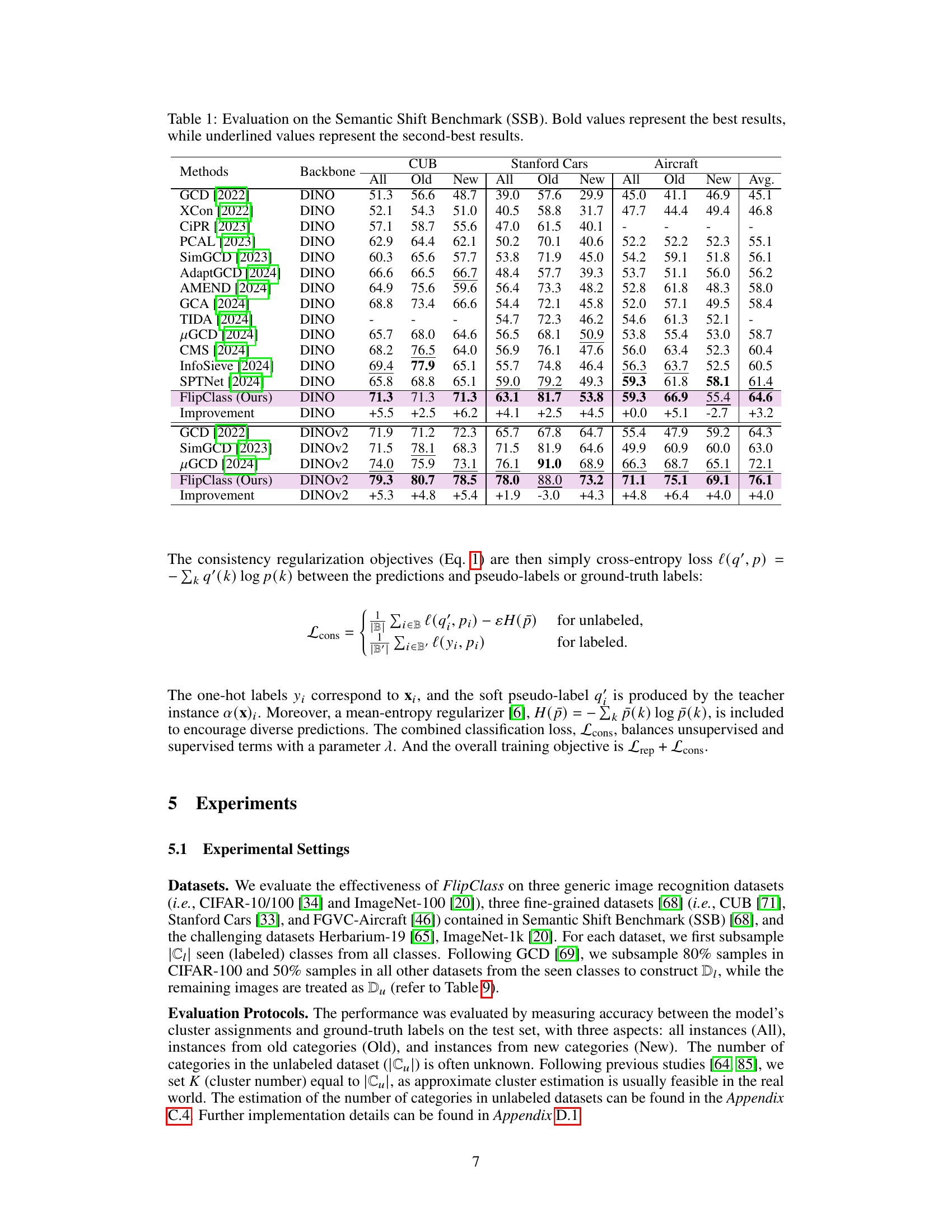
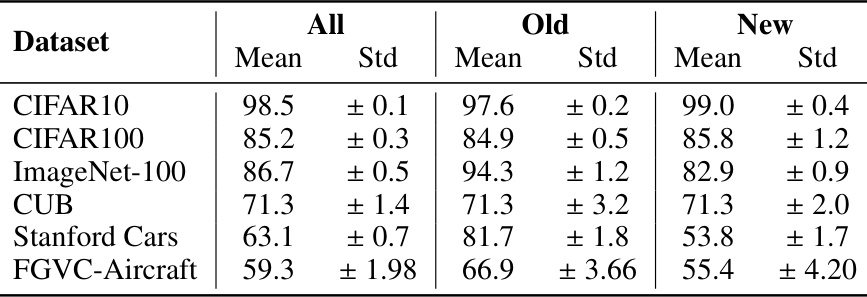
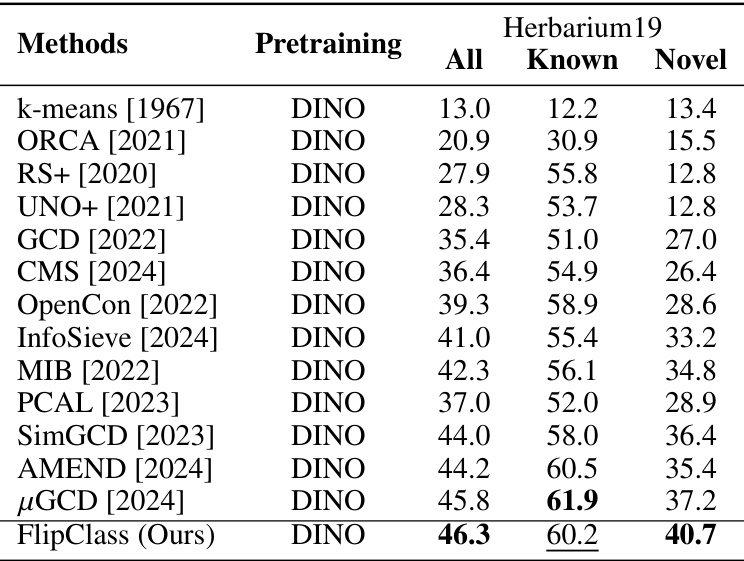
This table presents a comparison of various methods’ performance on the Semantic Shift Benchmark (SSB) dataset. The results are broken down by dataset (CUB, Stanford Cars, Aircraft), and further categorized by overall accuracy, accuracy on ‘Old’ (previously seen) classes, and accuracy on ‘New’ (unseen) classes. Bold values highlight the best performance for each category and underlined values show the second best. This allows for easy comparison of different models in terms of their generalization ability to new categories and their overall performance.
In-depth insights#
Teacher-Student GCD#
Teacher-Student Generalized Category Discovery (GCD) leverages a framework where a teacher model, trained on a labeled dataset, guides a student model to classify unlabeled data, including novel categories. The key challenge lies in the inherent open-world nature of GCD, where the teacher’s knowledge is incomplete. This can lead to inconsistencies and impede the student’s learning. Effective teacher-student GCD demands mechanisms to dynamically adapt the teacher’s knowledge based on student feedback, ensuring alignment and synchronized learning. This requires innovative methods to bridge the gap between the teacher’s existing knowledge and the student’s evolving understanding of novel categories. The success of such an approach hinges on the ability to identify and address misalignments in the learning process, ultimately leading to more robust and effective generalized category discovery.
FlipClass: Attention#
FlipClass, as the name suggests, introduces a novel approach to the conventional teacher-student framework in semi-supervised learning, particularly focusing on generalized category discovery. Its core innovation lies in dynamically aligning the teacher’s attention with the student’s attention, which is a departure from the traditional static teacher model. Instead of a static teacher, FlipClass employs an adaptive mechanism where the teacher’s attention is constantly refined based on student feedback. This dynamic alignment is key because the student’s attention is initially less informed than the teacher’s, especially when presented with novel categories. By ensuring a consistent pattern recognition between the teacher and the student across both established and new classes, FlipClass promotes synchronized and effective learning. The alignment strategy is achieved by introducing an energy-based function inspired by Hopfield Networks that optimizes the alignment of attention maps. Experiments on benchmark datasets show that FlipClass outperforms existing methods in generalized category discovery, confirming the effectiveness of its dynamic teacher-student attention alignment strategy.
Prior Gap Bridged#
The concept of “Prior Gap Bridged” in the context of Generalized Category Discovery (GCD) highlights a critical challenge in applying traditional teacher-student learning models to open-world scenarios. Closed-world SSL assumes the teacher possesses prior knowledge of all categories, which is unrealistic in GCD where new, unseen classes emerge. This leads to a significant “prior gap”, where the teacher’s knowledge diverges from the student’s, resulting in unsynchronized learning and suboptimal performance. Bridging this gap is crucial for successful GCD and involves aligning the teacher’s understanding with the student’s evolving knowledge through mechanisms that dynamically update the teacher’s focus based on student feedback. Effective solutions likely necessitate adaptive teacher models that can adjust to the emergence of new categories, unlike traditional static teacher-student approaches. The successful bridging of this prior gap is likely to involve innovative methods focusing on aligning representations, attention mechanisms and dynamically adjusting the learning process to accommodate the uncertainty inherent in discovering new classes.
Consistency Loss#
The concept of “Consistency Loss” is central to semi-supervised learning, particularly within the context of Generalized Category Discovery (GCD). It leverages the idea that consistent predictions should be made for different augmentations of the same data point, even in the absence of explicit labels. In GCD, this is particularly challenging due to the introduction of novel, unlabeled categories. A key aspect is the teacher-student framework where a teacher model, typically trained on weakly-augmented data, provides pseudo-labels to guide the student model trained on strongly-augmented data. The consistency loss then measures the discrepancy between the teacher and student predictions. However, misalignment between the teacher and student’s focus (attention) can hinder this process. Traditional teacher-student approaches often assume a closed-world setting, but in GCD, the teacher may misguide the student in the presence of new categories, leading to suboptimal learning. Effective strategies for aligning the teacher and student attention dynamically, hence dynamically updating the teacher’s knowledge based on student feedback, are crucial for mitigating this problem and ensuring successful GCD. The work emphasizes the importance of handling inconsistent pattern recognition, especially regarding new classes, by promoting synchronized learning and consistent pattern recognition across both familiar and unfamiliar categories.
Future of GCD#
The future of Generalized Category Discovery (GCD) hinges on addressing current limitations and exploring new avenues. Improving robustness to imbalanced datasets and noisy labels is crucial, potentially through advancements in semi-supervised learning techniques and more sophisticated data augmentation strategies. Developing methods that handle class distributions more effectively, especially in open-world scenarios, is paramount. This might involve incorporating prior knowledge or developing more adaptive teacher-student models. Addressing the issue of catastrophic forgetting, where the model forgets previously learned categories when learning new ones, is also key. Research into novel architectures and training strategies that mitigate this issue is needed. Finally, exploring the integration of GCD with other AI paradigms such as large language models and multi-modal learning could unlock entirely new capabilities. By combining the strengths of diverse approaches, researchers can pave the way for robust and versatile GCD systems that can be successfully deployed in a range of real-world applications.
More visual insights#
More on figures
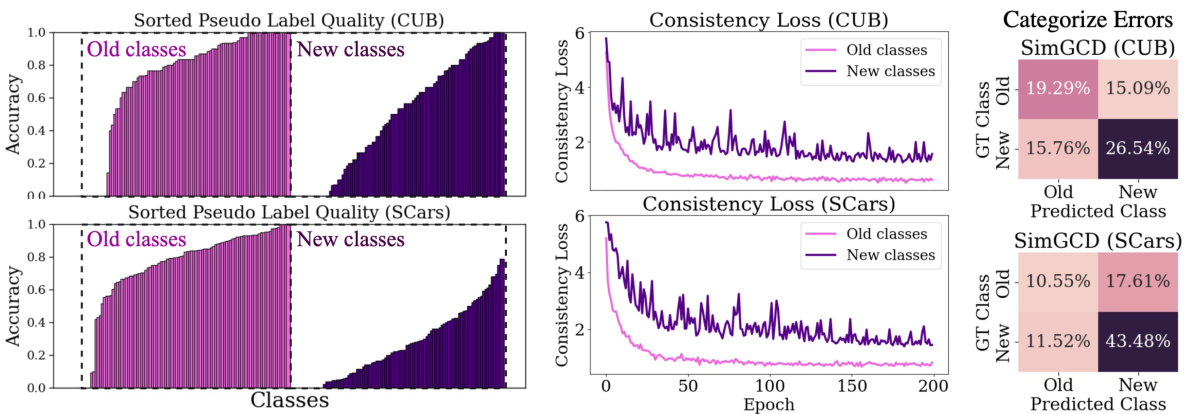
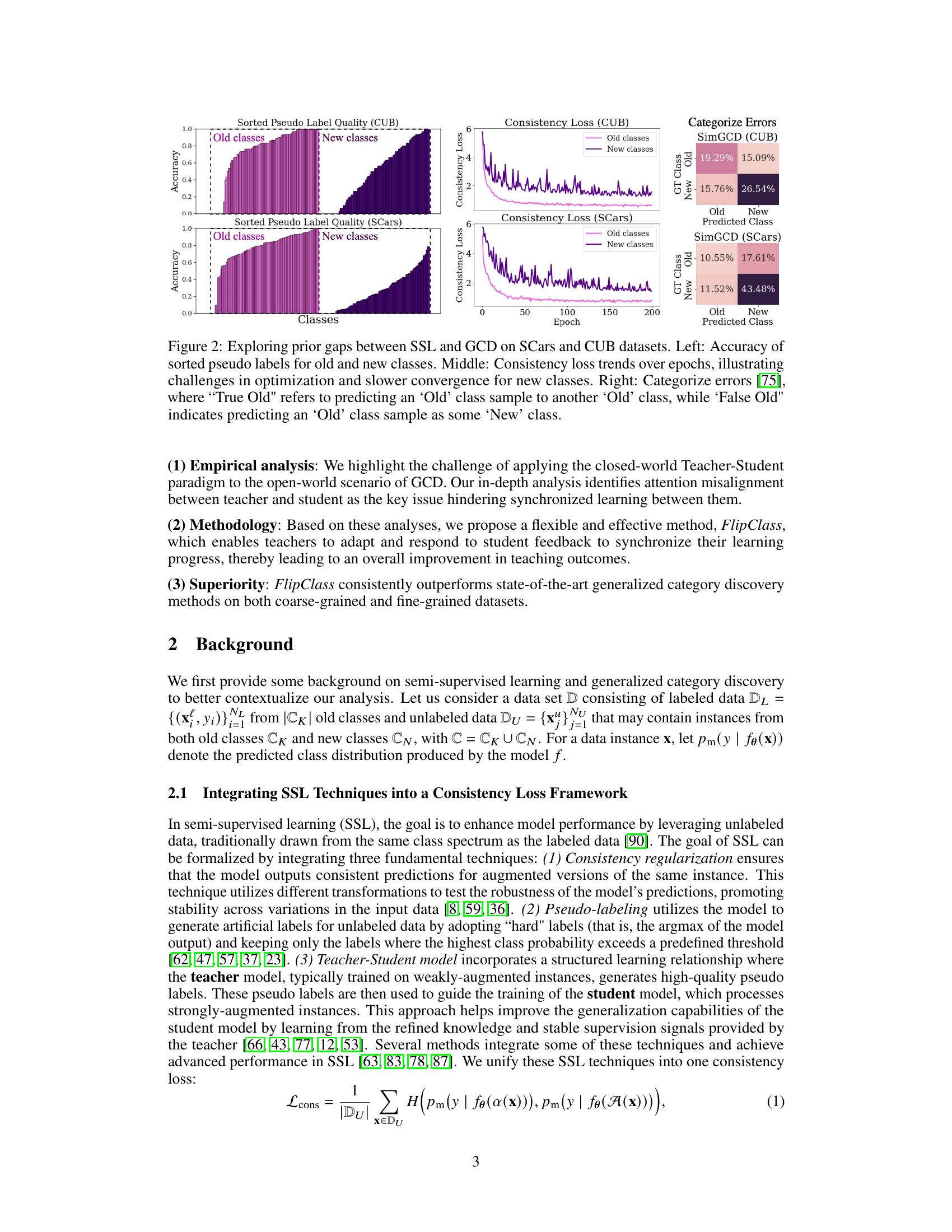
This figure demonstrates the challenges of applying traditional semi-supervised learning (SSL) methods to the task of Generalized Category Discovery (GCD). The left panel shows that the quality of pseudo-labels generated by SSL models is significantly lower for new classes than for old classes. The middle panel shows that the consistency loss, a common objective function in SSL, converges slower for new classes in GCD. The right panel shows that SSL models tend to misclassify new classes as old classes more frequently than vice versa, indicating a bias towards previously seen categories.
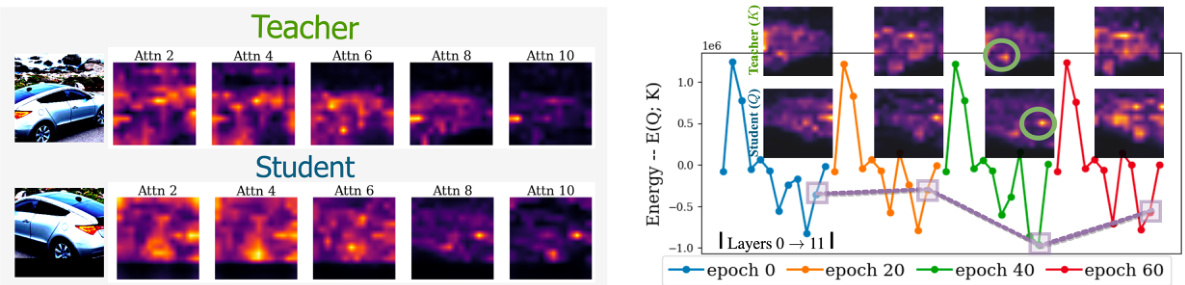
The figure demonstrates the attention heatmaps for both teacher and student models across different attention layers (left). The heatmaps visually represent where the models focus their attention on the input image. The right side shows the energy trend across training epochs. Lower energy indicates better alignment and less discrepancy between the teacher and student’s pattern recognition. The visualization highlights how the proposed method aligns teacher and student attention, improving learning consistency.
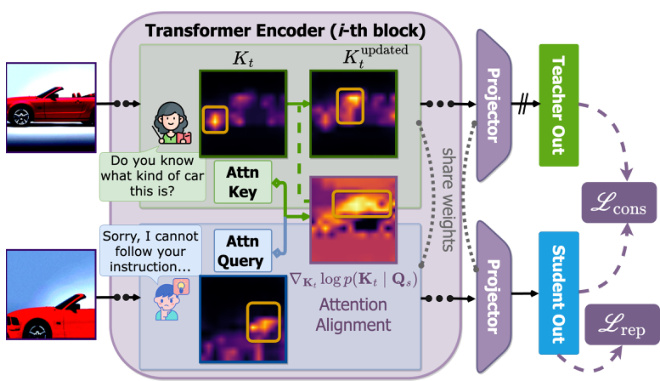
This figure illustrates the FlipClass framework, which dynamically updates the teacher’s attention based on student feedback. The teacher’s attention is adjusted to align with the student’s attention, promoting synchronized learning. The framework consists of a transformer encoder, projectors for the teacher and student, and a consistency loss (Lcons) and a representation learning loss (Lrep). The consistency loss ensures that the teacher and student produce consistent predictions, while the representation learning loss encourages the model to learn effective representations.

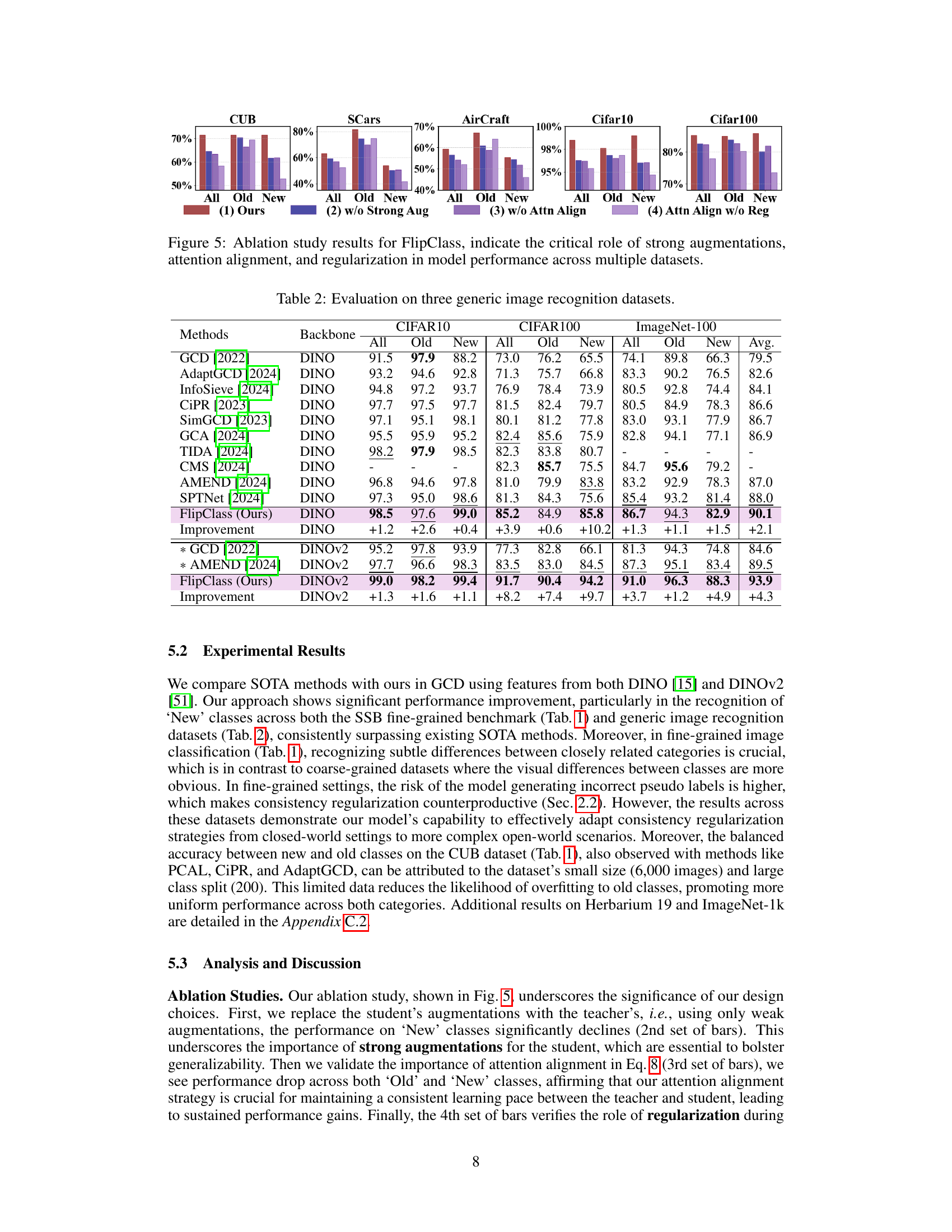
The figure shows the ablation study results for the FlipClass model. It demonstrates the importance of three key components: strong augmentations, attention alignment, and regularization. Removing any one of these components significantly reduces the model’s performance across multiple datasets (CUB, SCars, Aircraft, CIFAR-10, and CIFAR-100). The results highlight the synergistic effect of these components in achieving high accuracy, especially for new classes.

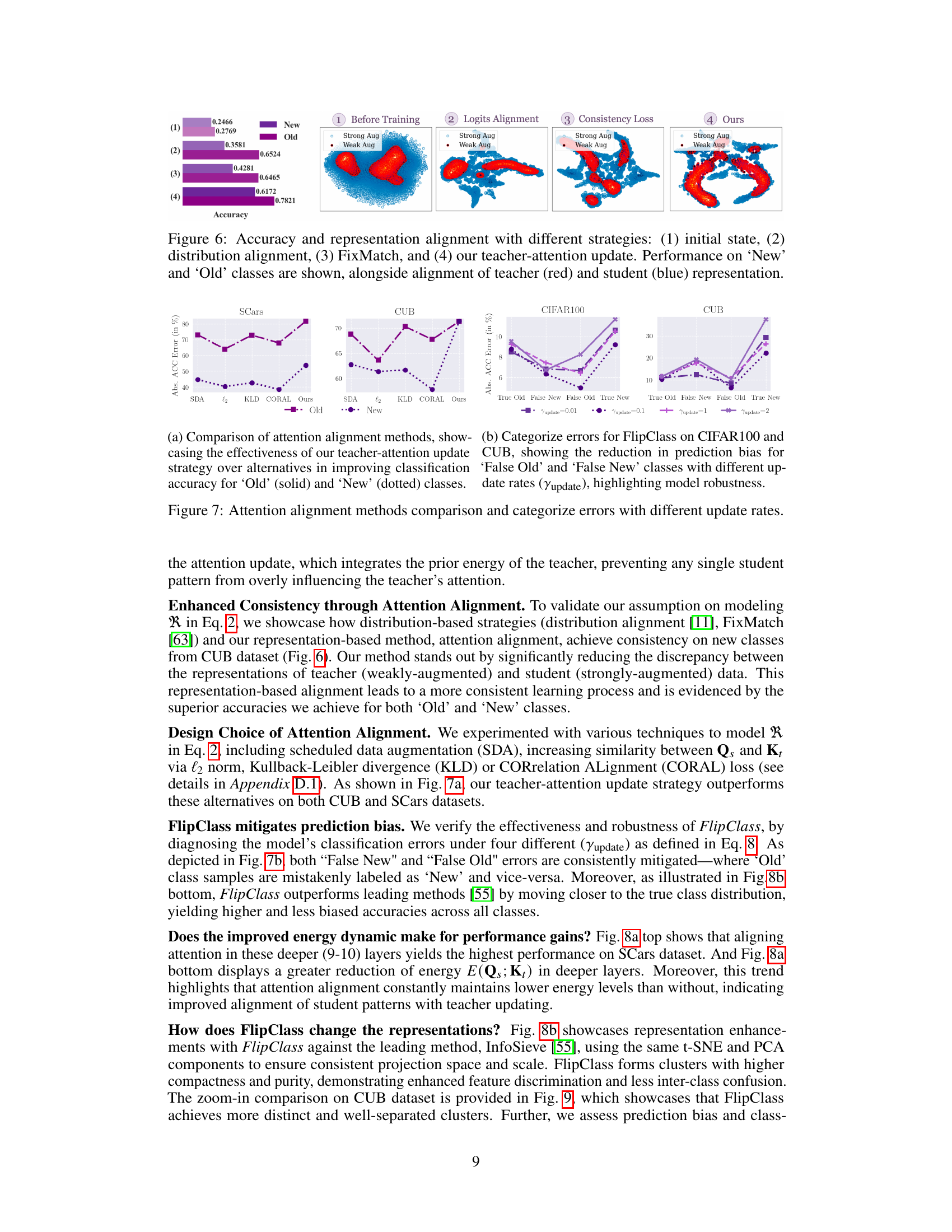
This figure shows the comparison of accuracy and representation alignment among different strategies: initial state, logits alignment, consistency loss, and the proposed method (FlipClass). The visualization uses t-SNE to project high-dimensional feature embeddings into 2D space for both teacher and student models, colored red and blue respectively. The color intensity represents the density of data points. The figure demonstrates how the proposed method improves representation alignment and accuracy, especially for ‘New’ classes, which lack explicit supervision.

This figure compares different attention alignment methods and analyzes the categorization errors with various update rates. Subfigure (a) shows a comparison of attention alignment methods, highlighting the effectiveness of the proposed teacher-attention update strategy. Subfigure (b) displays categorization errors on CIFAR100 and CUB datasets, illustrating how different update rates affect the model’s robustness and reduce prediction bias for ‘False Old’ and ‘False New’ classes.
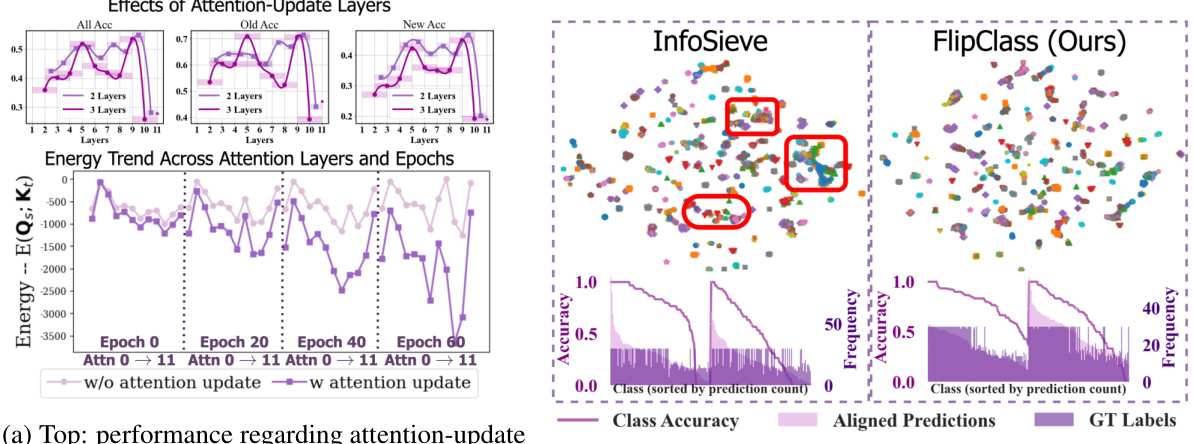
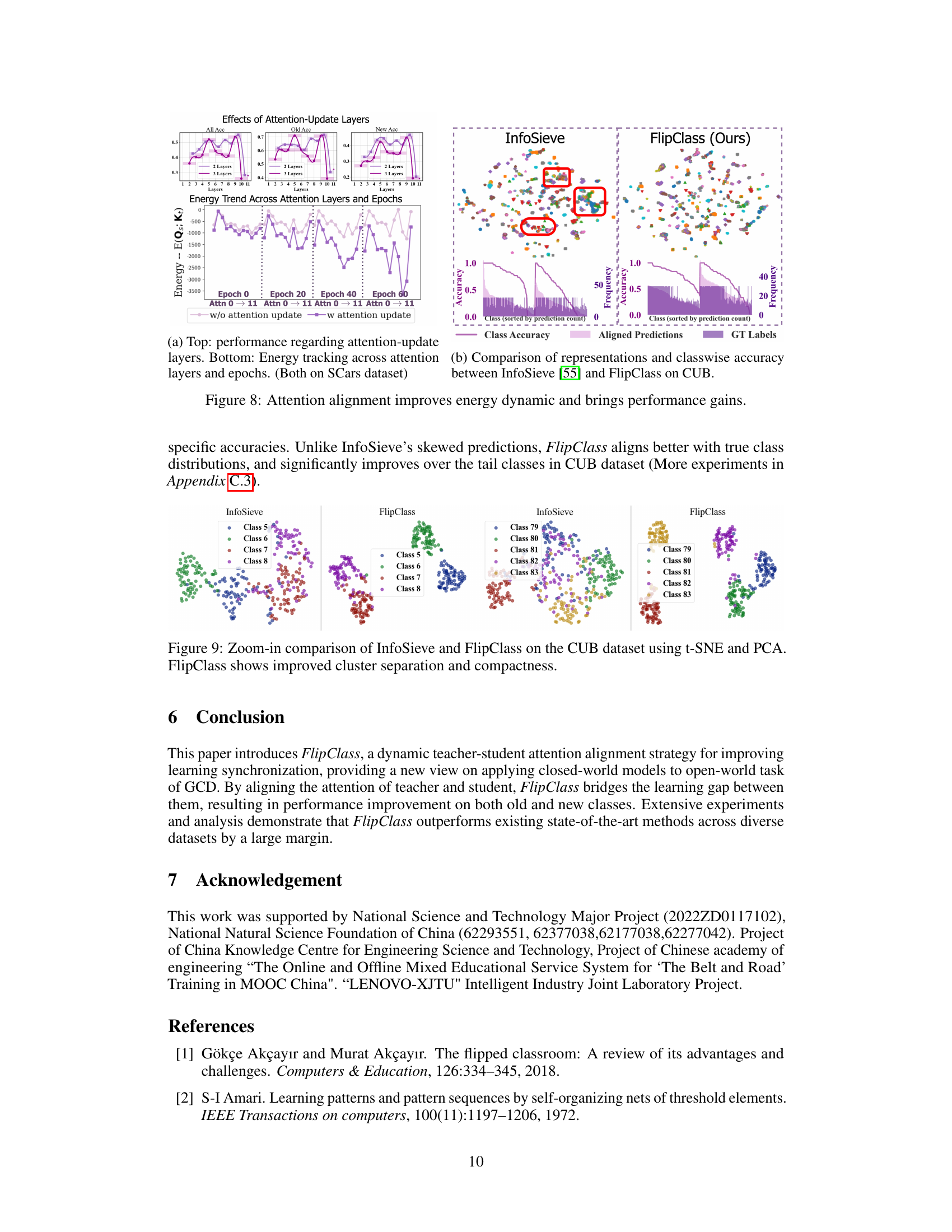
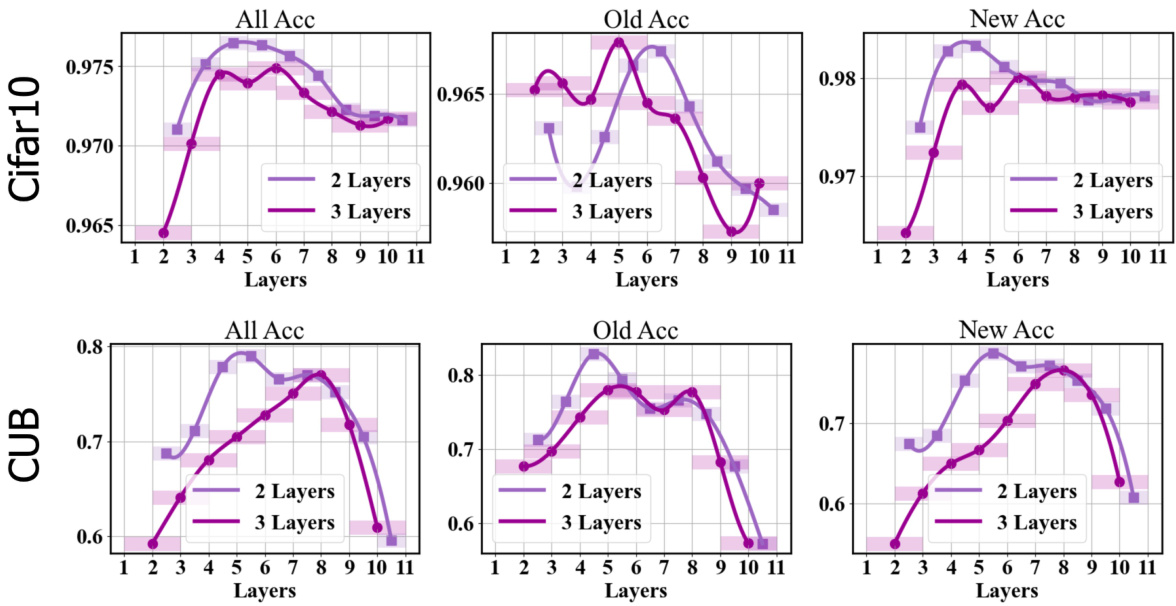
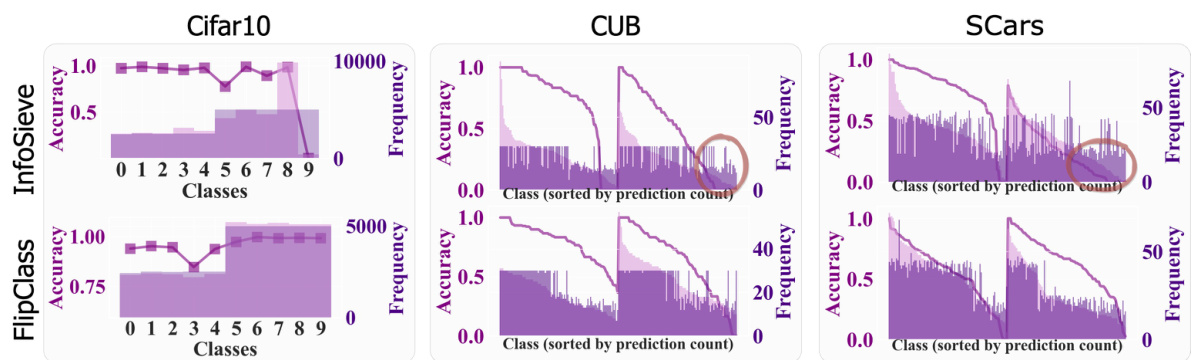
The figure demonstrates that aligning attention between the teacher and student improves energy dynamics and enhances performance. The left part shows the performance regarding attention-update layers across different epochs, indicating that deeper layers (8-11) generally yield better accuracy. The right part compares the representation quality and class-wise accuracy between InfoSieve and FlipClass, demonstrating that FlipClass offers superior representation learning and accuracy. Specifically, FlipClass’s representations are more compact, resulting in less confusion between classes, and it performs significantly better on tail classes.
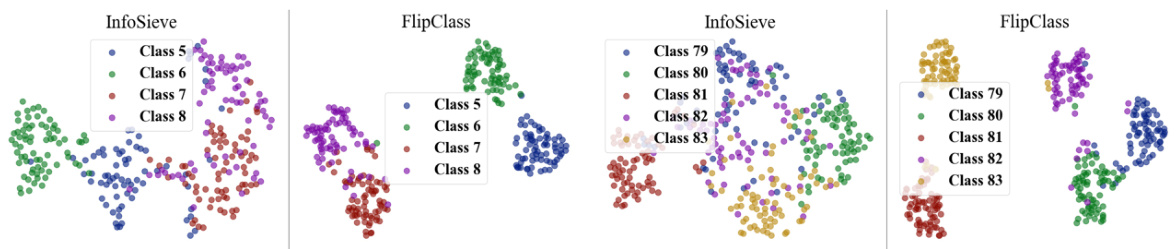
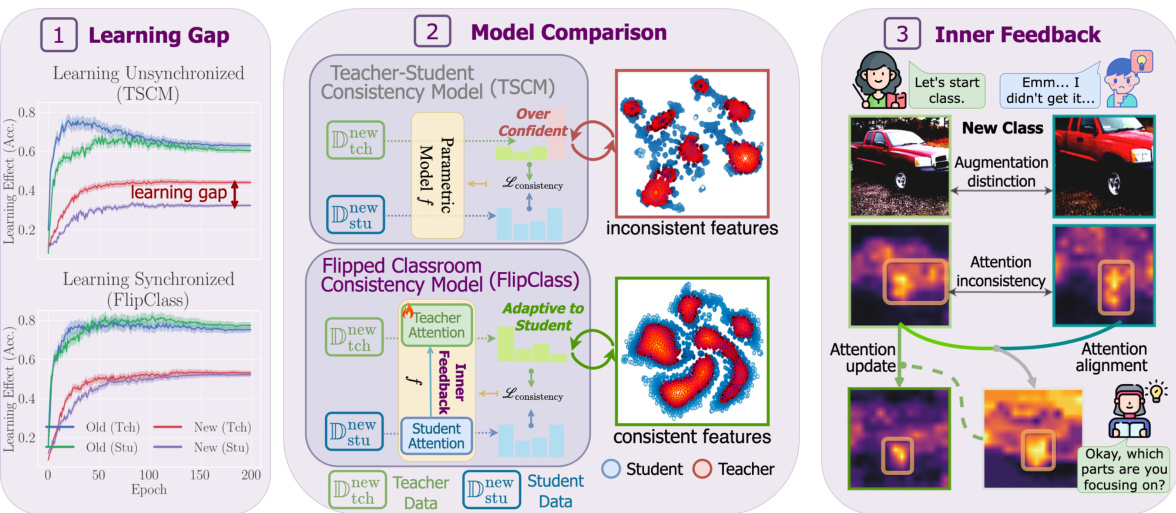
This figure compares the visualization of the CUB dataset’s features using t-SNE and PCA dimensionality reduction techniques by InfoSieve and FlipClass. The visualization highlights that FlipClass produces more distinct and well-separated clusters, indicating improved cluster separation and compactness compared to InfoSieve.
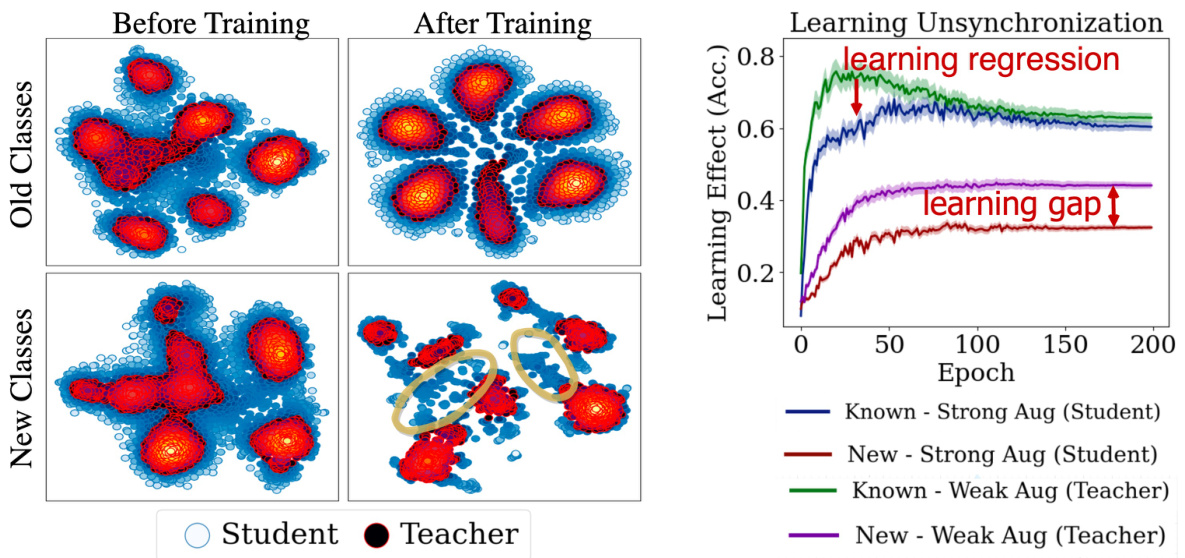
This figure shows the comparison of representation discrepancy between old and new classes before and after training. The left part shows the misalignment of student and teacher representations, especially for new classes. The right part shows the learning unsynchronization between teacher and student. The learning gap and learning regression indicate the learning progress is not synchronized, especially for new classes.
This figure shows a comparison of the learning curves between traditional Teacher-Student Consistency Models (TSCM) and the proposed FlipClass model. The left panel demonstrates the learning gap and unsynchronized learning in the TSCM approach, particularly for new classes. The middle panel highlights the superior performance of FlipClass in aligning teacher and student learning, resulting in improved consistency. The right panel illustrates the inner feedback mechanism of FlipClass, where the teacher dynamically adjusts its attention based on student feedback, promoting synchronized learning and consistency between old and new classes.
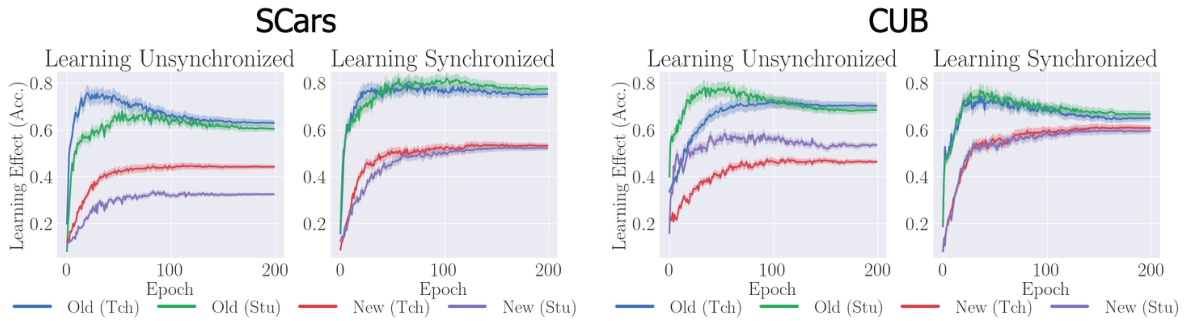
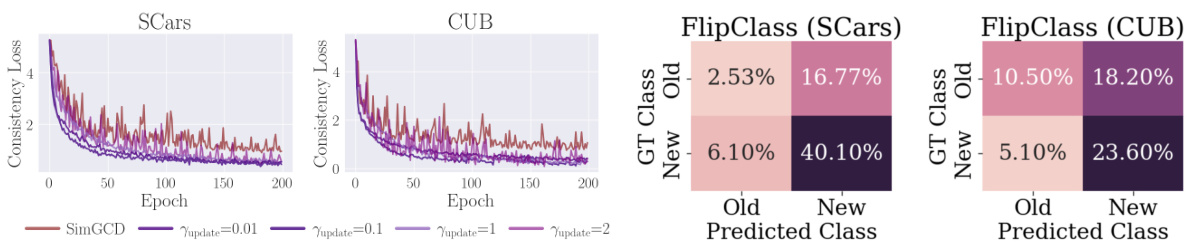
This figure compares the learning curves of the traditional Teacher-Student Consistency Model (TSCM) and the proposed FlipClass model on the Stanford Cars and CUB datasets. The learning curves show the accuracy of the teacher and student models over epochs for both old and new classes. FlipClass demonstrates significantly better synchronized and stable learning compared to the TSCM, indicating that its attention alignment strategy leads to more consistent and effective learning across all classes.
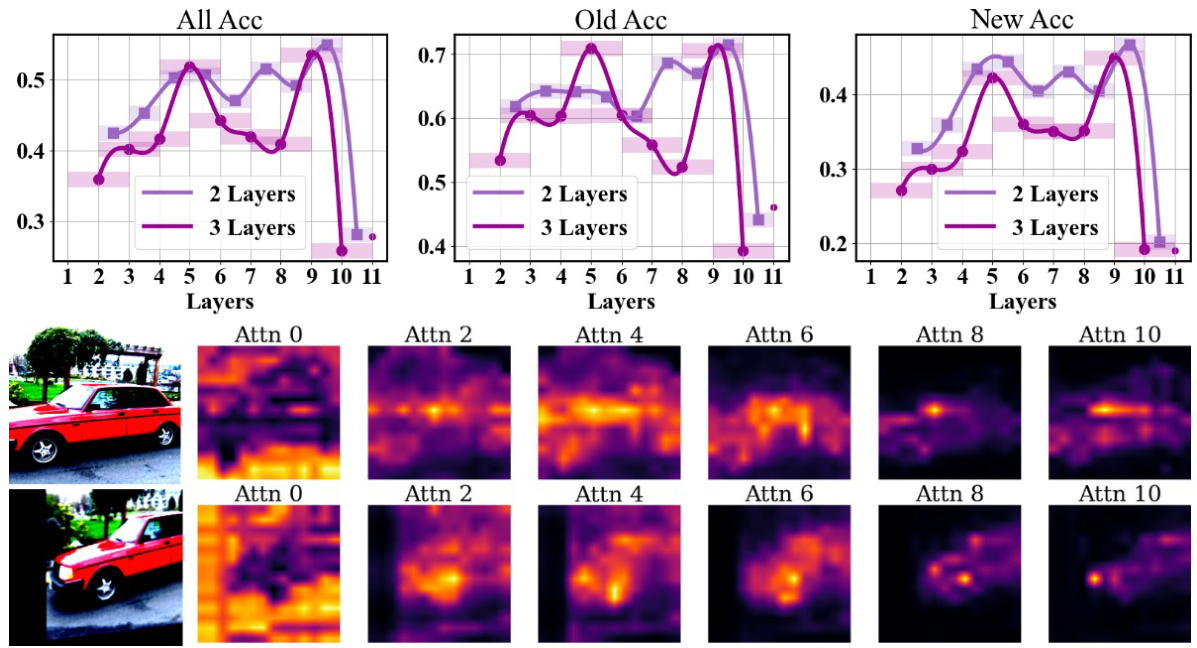
This figure shows the attention heatmaps for different layers in the vision transformer network when processing images from the Stanford Cars dataset. The heatmaps reveal a pattern where deeper layers focus more on specific, localized features (like a car’s headlights or wheels), while shallower layers attend to more general features (like the overall shape or color of the car). This is evidence that attention alignment is effective at improving transfer learning and helping the model recognize both old and new car classes more effectively. The aligned attention improves performance because it addresses the learning gap and discrepancies often encountered with existing semi-supervised learning techniques in open-world scenarios.
This figure compares the performance of traditional Teacher-Student Consistency Models (TSCM) and the proposed FlipClass model on the Stanford Cars dataset. The left panel shows the learning curves, highlighting the significant learning gap and unsynchronized learning in TSCM compared to FlipClass. The middle panel illustrates the model comparison, emphasizing the difference in how TSCM and FlipClass handle data from new classes (Dnew). The right panel visually explains FlipClass’s inner feedback mechanism, demonstrating how it dynamically updates the teacher’s attention to align with the student’s focus, achieving better learning synchronization.
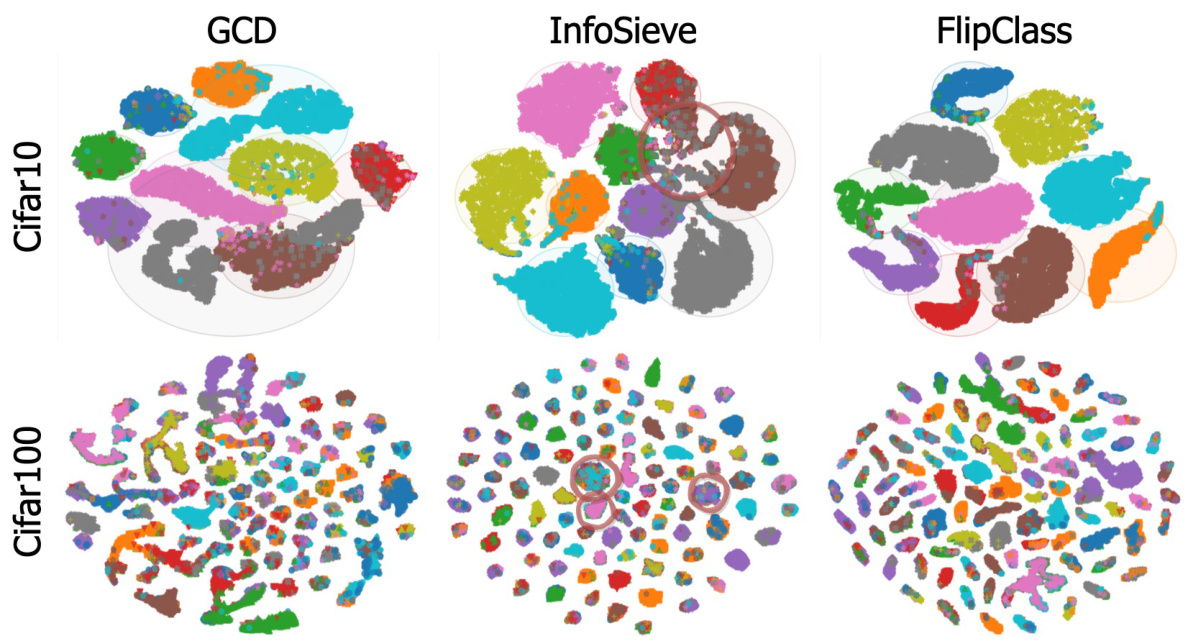
This figure compares the clustering performance of three different methods: GCD, InfoSieve, and FlipClass, on the Cifar-10 and Cifar-100 datasets. Each method’s output is visualized using t-SNE, a dimensionality reduction technique. The plots show how well each method separates the data points into their respective clusters based on class labels. By visually comparing the cluster distributions, we can gain insights into the effectiveness of each method in clustering data points of similar classes together, and separating clusters of different classes.
This figure compares the learning effects of traditional Teacher-Student Consistency Models (TSCM) and the proposed FlipClass model on the Stanford Cars dataset. The left panel shows the learning curves, highlighting the learning gap and unsynchronized learning of TSCM compared to the synchronized learning of FlipClass. The middle panel visually compares the two models, demonstrating FlipClass’s improved consistency in handling new classes. The right panel illustrates the inner feedback mechanism of FlipClass, emphasizing how teacher attention dynamically adapts to student attention, leading to better alignment and learning.
This figure compares the performance of traditional teacher-student models and the proposed FlipClass model in Generalized Category Discovery (GCD). The left panel shows the learning curves, demonstrating that FlipClass achieves better learning synchronization between the teacher and student. The middle panel illustrates how FlipClass addresses the challenges of inconsistent pattern learning. Finally, the right panel details the inner feedback mechanism in FlipClass, showing how teacher attention adapts based on student feedback.
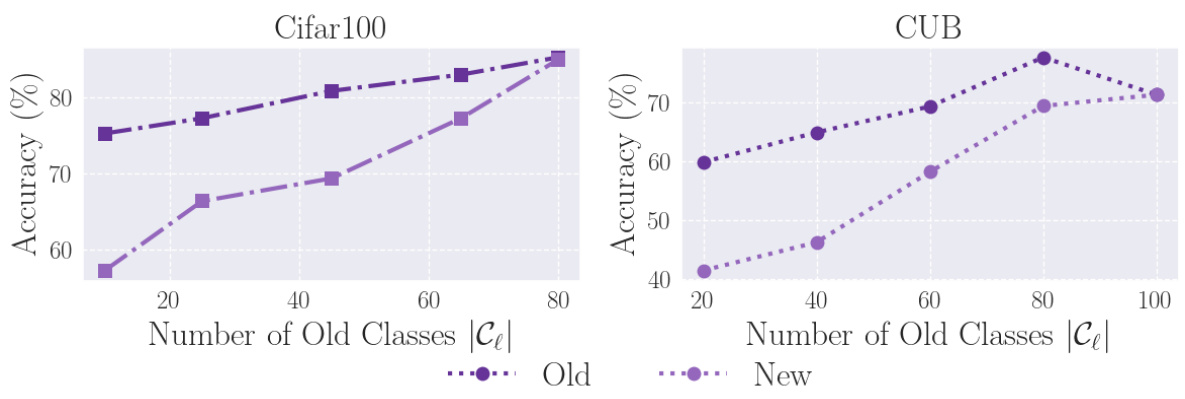
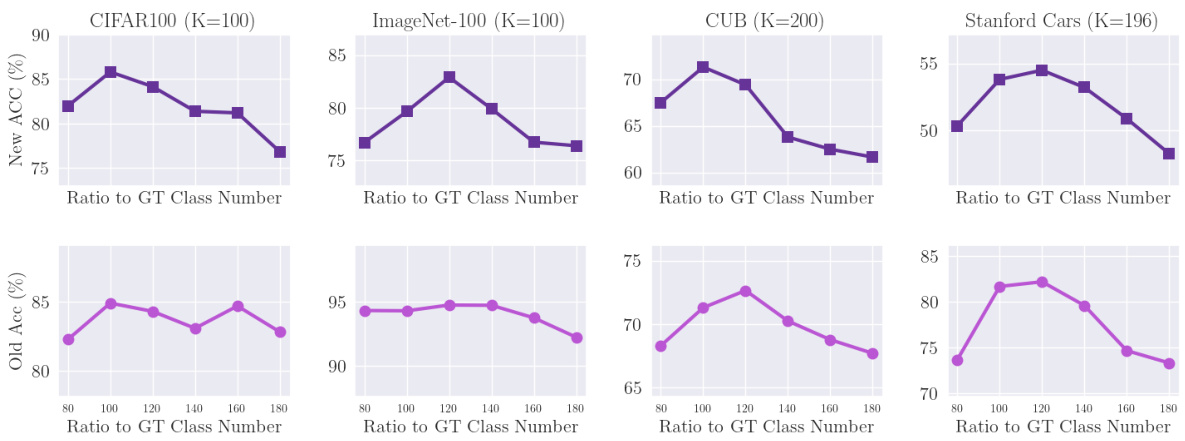
This figure shows the performance of FlipClass on Cifar-100 and CUB datasets when varying the number of old classes used for training. The results show that the performance is relatively stable across different proportions of old classes, demonstrating the robustness of FlipClass in handling various numbers of known classes.
More on tables
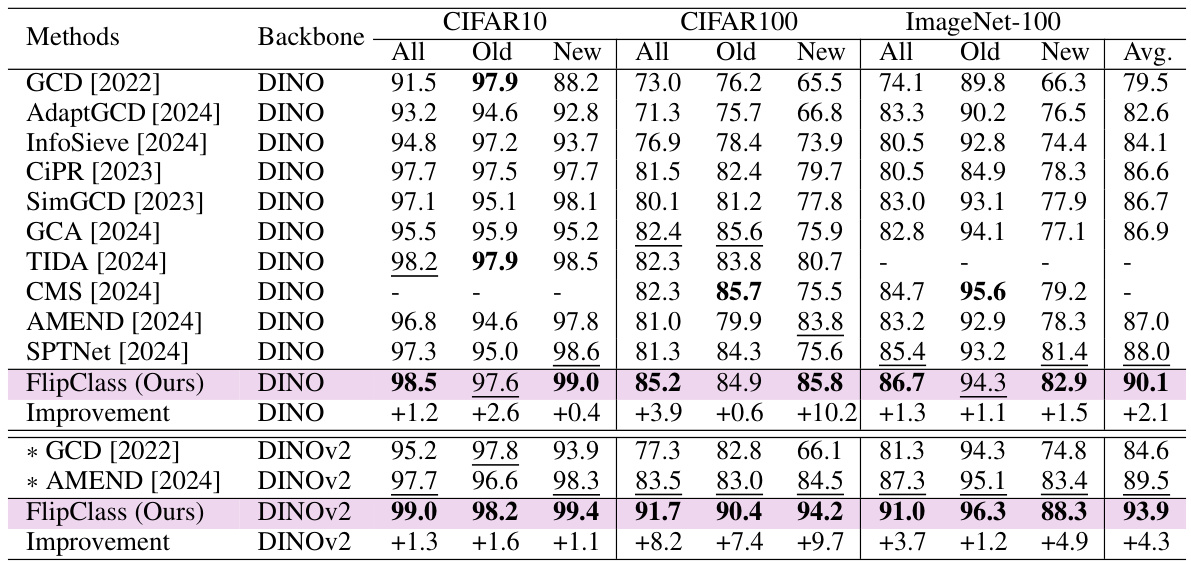
This table presents the performance of various methods on the Semantic Shift Benchmark (SSB), a dataset designed to evaluate the ability of models to generalize to new categories. The results are broken down by dataset (CUB, Stanford Cars, Aircraft), and performance is measured across all classes, old classes (seen during training), and new classes (unseen during training). Bold values indicate the best performance for each metric, and underlined values indicate the second-best. The table allows for a comparison of different methods’ ability to handle both previously seen and novel categories.

This table presents the performance comparison of various methods on the Semantic Shift Benchmark (SSB) dataset for generalized category discovery. The results are broken down by dataset (CUB, Stanford Cars, Aircraft), and further categorized into overall accuracy (‘All’), accuracy on known classes (‘Old’), and accuracy on novel classes (‘New’). Bold values highlight the best performance for each category, while underlined values show the second-best performance. The results show the effectiveness of the proposed method, FlipClass, compared to several state-of-the-art approaches.

This table presents the performance comparison of various methods on the Semantic Shift Benchmark (SSB) dataset for generalized category discovery. The results are categorized by dataset (CUB, Stanford Cars, Aircraft), and further broken down into overall accuracy, and accuracy for old and new categories. Bold values indicate the best result for each category and underlined values indicate the second-best result. This table shows that FlipClass significantly outperforms other state-of-the-art methods across various datasets and metrics.
This table presents the performance evaluation results of various methods on the Semantic Shift Benchmark (SSB) dataset. The results are categorized into overall accuracy (All), accuracy on old classes (Old), and accuracy on new classes (New). The best and second-best results are highlighted in bold and underlined, respectively. Different backbones are used for different models. The table shows the effectiveness of different GCD methods on three fine-grained image recognition datasets: CUB, Stanford Cars, and Aircraft.
This table presents the performance comparison of various methods on the Semantic Shift Benchmark (SSB) dataset, across three fine-grained image recognition datasets: CUB, Stanford Cars, and Aircraft. The performance is measured by accuracy (All, Old, and New classes) and averaged across all three datasets. Bold values indicate the best performance, while underlined values show the second best performance for each category.
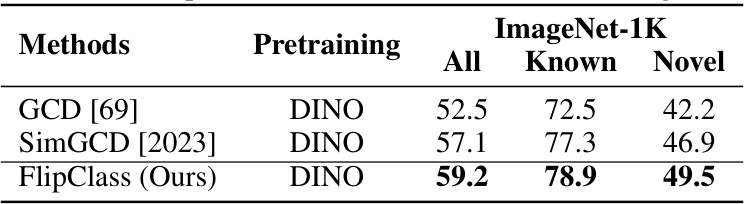
This table presents the results of various methods on the Semantic Shift Benchmark (SSB), a dataset designed for evaluating generalized category discovery (GCD) methods. The table shows the accuracy achieved by each method on three different datasets (CUB, Stanford Cars, and Aircraft) for all images, images from known classes, and images from novel classes. The results are categorized by the backbone used (DINO or DINOv2). Bold values highlight the best performance for each category, while underlined values indicate the second-best performance. This allows for a comparison of the proposed FlipClass method against state-of-the-art GCD approaches.
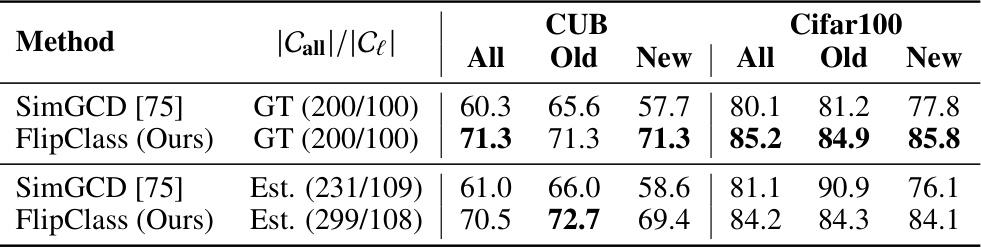
This table presents the performance comparison of various methods on the Semantic Shift Benchmark (SSB) dataset. The methods are evaluated across three different fine-grained image recognition datasets: CUB, Stanford Cars, and Aircraft. Performance is measured by accuracy, broken down into overall accuracy, accuracy on old classes, and accuracy on new classes. Bold values highlight the best performance for each category, and underlined values show the second-best performance. The table provides an overall comparison of the different methods for generalized category discovery.

This table presents the results of the proposed FlipClass model and other state-of-the-art methods on the Semantic Shift Benchmark (SSB) dataset. The SSB dataset consists of three fine-grained image recognition datasets: CUB, Stanford Cars, and Aircraft. The table shows the accuracy of each method on each dataset, broken down by all classes (‘All’), old classes (‘Old’), and new classes (‘New’). Bold values indicate the best performance for each category, while underlined values show the second-best performance.
Full paper#