↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current methods for using LLMs in complex medical tasks, such as diagnosis, are limited by their inability to adapt to different levels of complexity. Single LLMs often lack the breadth of knowledge required, while static multi-agent systems fail to adjust their collaboration approach based on individual task demands. This leads to suboptimal performance and efficiency.
The paper introduces MDAgents, a novel framework that dynamically assigns collaboration structures (single LLM, multi-disciplinary team, or integrated care team) based on a task’s complexity, mimicking real-world medical decision-making processes. This adaptive approach improves accuracy on several medical benchmarks, achieving up to a 4.2% increase over existing methods and demonstrating an effective balance between accuracy and efficiency by adjusting the number of agents used.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on Large Language Models (LLMs) for healthcare and medical decision-making. It introduces a novel, adaptive multi-agent framework that significantly improves the accuracy of LLM-based medical diagnosis. This work addresses the limitations of existing single-agent and static multi-agent approaches, opening new avenues for developing more robust and reliable AI-driven medical solutions. The findings have direct implications for the development of advanced AI-based clinical tools and will stimulate further investigation into adaptive multi-agent systems for complex problem-solving.
Visual Insights#
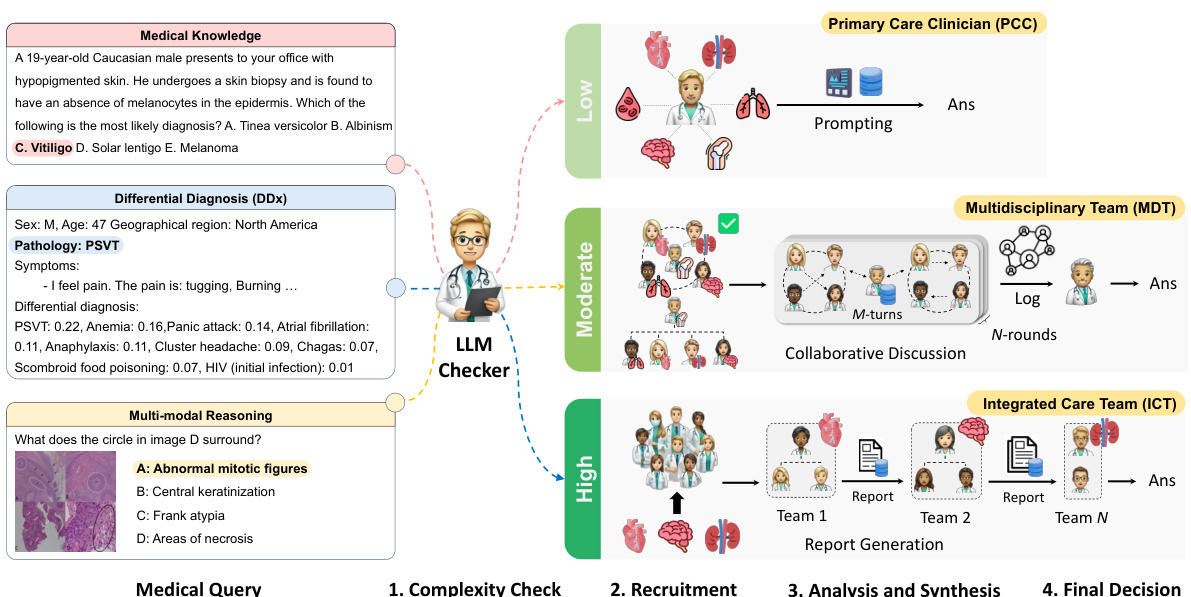
The MDAgents framework is depicted, illustrating its four main stages. First, a medical query is subjected to a complexity check to determine its difficulty level (low, moderate, or high). Based on this assessment, the system recruits agents: a single primary care clinician for low-complexity queries, a multidisciplinary team (MDT) for moderate-complexity queries, or an integrated care team (ICT) for high-complexity queries. The selected agents then perform analysis and synthesis, using various methods including prompting, collaborative discussion, or report generation depending on the complexity level. Finally, the framework arrives at a final decision by synthesizing the outputs from different stages, generating a final answer.
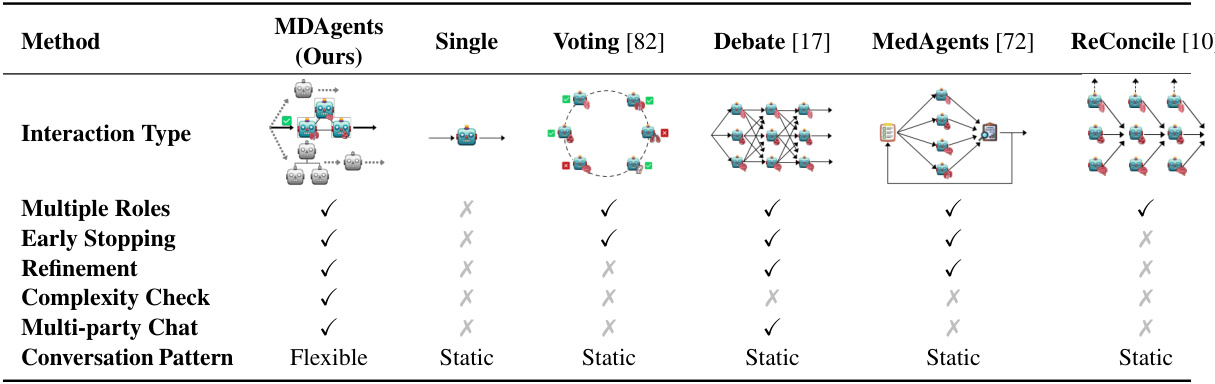
This table compares MDAgents with several existing single-agent and multi-agent LLM frameworks. The comparison highlights key differences in interaction type, the presence of multiple roles for agents, the use of early stopping mechanisms, refinement techniques, explicit complexity checks, multi-party chat capabilities, and the flexibility of the conversation pattern. It demonstrates that MDAgents uniquely incorporates all these crucial features for effective LLM decision-making, making it distinct from prior approaches.
In-depth insights#
Adaptive LLM Teams#
The concept of “Adaptive LLM Teams” introduces a paradigm shift in large language model (LLM) applications, particularly for complex tasks like medical decision-making. Instead of relying on a single, static LLM, adaptive teams dynamically assemble based on task complexity. This approach mirrors real-world collaborative processes, where specialists are brought in based on need. A key advantage is efficiency: simple tasks are handled by a single, generalist LLM, while complex cases engage specialized LLMs, minimizing unnecessary computation. Furthermore, adaptive team composition allows for better accuracy and robustness. The dynamic structure enables the system to leverage the unique strengths of different LLMs, improving overall performance, and offering more resilient solutions than a single LLM could provide. This adaptive framework highlights the potential of mimicking human collaboration to unlock the full capabilities of LLMs in intricate, multifaceted problem-solving domains.
Medical Complexity#
The concept of “Medical Complexity” is crucial to the MDAgents framework, acting as the primary determinant for dynamically tailoring the collaboration structure among LLMs. The framework accurately assesses complexity, assigning straightforward cases to solo LLMs, more intricate scenarios to multi-disciplinary teams (MDTs), and highly complex cases to integrated care teams (ICTs). This adaptive approach mirrors real-world medical decision-making, enhancing efficiency and accuracy by employing the optimal LLM configuration for each specific problem. Ablation studies support the importance of complexity classification, demonstrating significantly improved performance in scenarios with well-defined complexity compared to static agent configurations. Therefore, medical complexity is not merely a classification but a dynamic and critical component determining the effectiveness of the MDAgent framework.
Benchmark Results#
The benchmark results section of a research paper is crucial for evaluating the performance of a proposed model or method. A strong benchmark section will present results across multiple datasets, showing consistent improvements over existing state-of-the-art approaches. Clear visualization of results, such as tables and graphs, is essential, making trends and comparisons easily understandable. The choice of benchmarks should be justified, reflecting a diverse range of relevant tasks and difficulties to demonstrate the method’s generality and robustness. Statistical significance should be reported for all key results, indicating the reliability of the observed improvements. Finally, the discussion should thoroughly analyze the results, highlighting both strengths and weaknesses, potentially attributing performance variations to specific aspects of the methodology, dataset characteristics, or model limitations. A well-structured benchmark analysis instills confidence in the reader, strengthening the paper’s overall impact and credibility.
Ablation Studies#
Ablation studies systematically remove or modify components of a complex system to understand their individual contributions. In the context of a research paper focusing on an adaptive multi-agent framework for medical decision-making, ablation studies would be crucial for isolating the impact of individual components on the system’s overall performance. For example, removing the medical complexity check could reveal its effect on accuracy and resource usage. Similarly, disabling the moderator or recruiter could reveal the contribution of each to the coordination and efficiency of the multi-agent process. Comparing results from these ablation experiments to the full system’s performance can quantify the impact of each component and justify its inclusion in the model. Such studies are essential for evaluating the modularity and robustness of the framework and isolating the most critical elements. The findings of such ablation studies, when detailed and comprehensive, would help to strengthen the validity and understanding of the research findings and improve the trustworthiness of the model. Robustness can be evaluated by testing the model’s sensitivity to the variations in hyperparameters, and thus demonstrating the effectiveness and stability of the model against those parameter changes. Furthermore, ablation studies can offer insightful information that help to improve the model’s design and optimization by identifying potential areas for enhancement and refinement. Finally, well-designed ablation studies would demonstrate the overall efficiency and accuracy trade-offs achieved by the framework. This could be done by showing how varying numbers of agents impact the performance and identifying the optimal agent configuration for specific complexity levels.
Future Research#
Future research directions for this medical decision-making framework using LLMs should prioritize improving the accuracy and reliability of LLM-based diagnoses, perhaps through the use of more specialized medical LLMs and stronger methods for verifying model outputs. Patient-centricity is another key area; the model should incorporate continuous patient and caregiver interaction to better reflect real-world MDM scenarios. Further work is needed to mitigate potential risks, such as model hallucinations, through mechanisms like self-correction and improved uncertainty quantification. Finally, expanding the framework to handle a broader range of medical tasks and modalities and investigating the optimal collaboration strategies for different complexities would further enhance its applicability and utility.
More visual insights#
More on figures
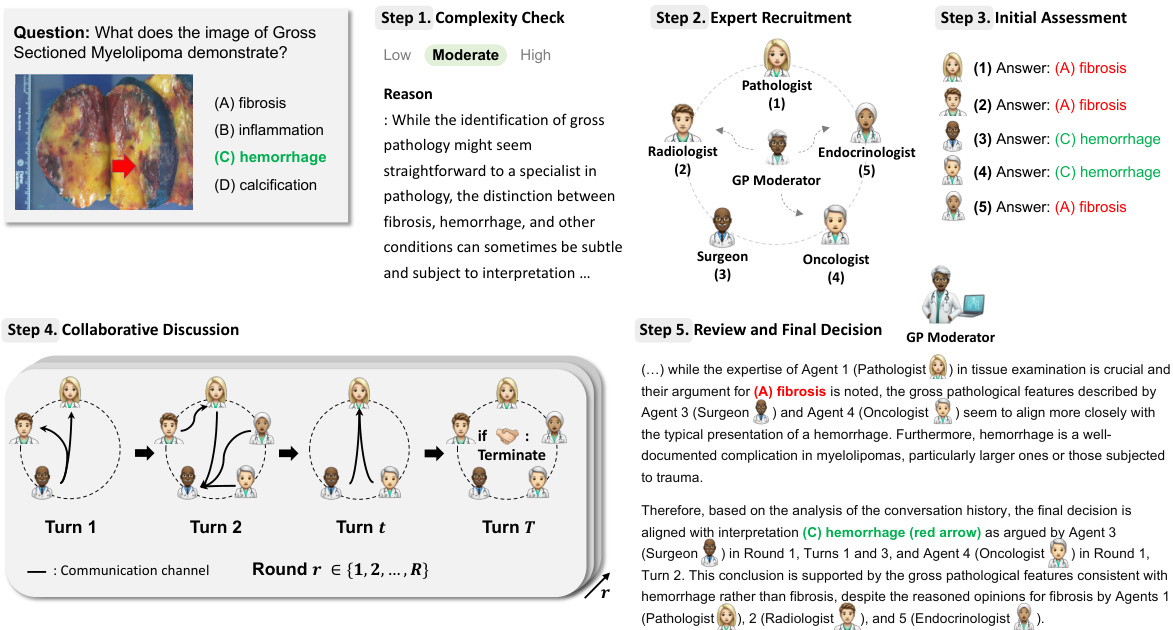
The figure illustrates the MDAgents framework, which takes a medical query as input and goes through four steps to reach a final decision. First, it checks the complexity of the query (low, moderate, or high). Second, it recruits appropriate agents (LLMs) based on the complexity, ranging from a single primary care clinician for simple queries to multidisciplinary or integrated care teams for complex queries. Third, the agents analyze and synthesize information. Finally, a decision is made and reported.
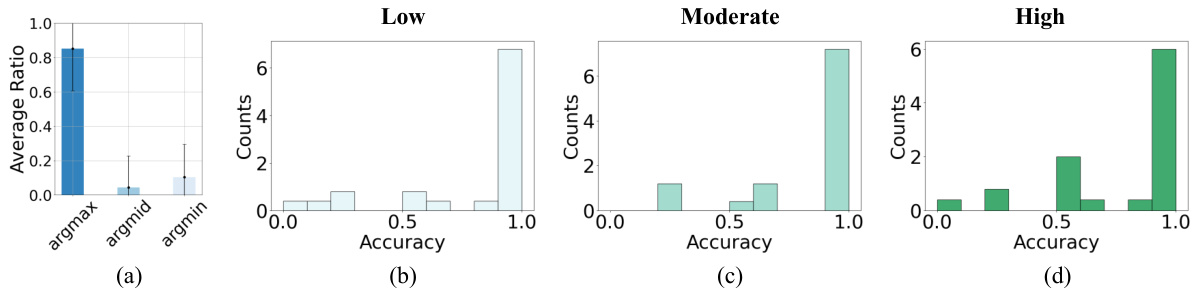
This figure shows the results of an experiment using the MedQA dataset. Part (a) illustrates the LLM’s ability to correctly classify the complexity of medical questions. Parts (b), (c), and (d) show the accuracy of the LLM’s responses for questions of low, moderate, and high complexity, respectively. Each question was attempted 10 times, and the figure shows the accuracy distribution.
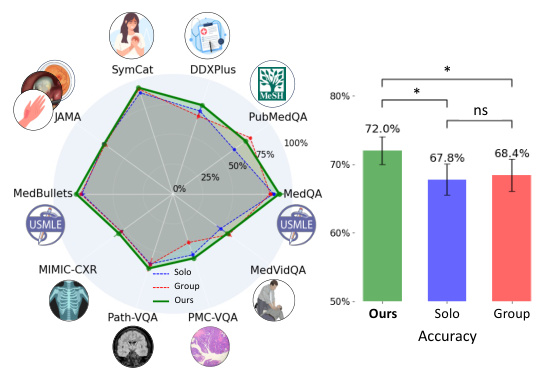
This figure presents a bar chart comparing the accuracy of the proposed MDAgents method against the baseline Solo and Group methods across multiple medical benchmarks. The results visually demonstrate the superior performance of MDAgents in achieving higher accuracy compared to the single-agent and multi-agent baselines. The x-axis represents the different approaches (Ours, Solo, Group), while the y-axis displays the accuracy percentages achieved on the benchmark datasets. The chart highlights the significant improvements obtained by MDAgents, providing a clear visual summary of the performance gains achieved by the adaptive approach.
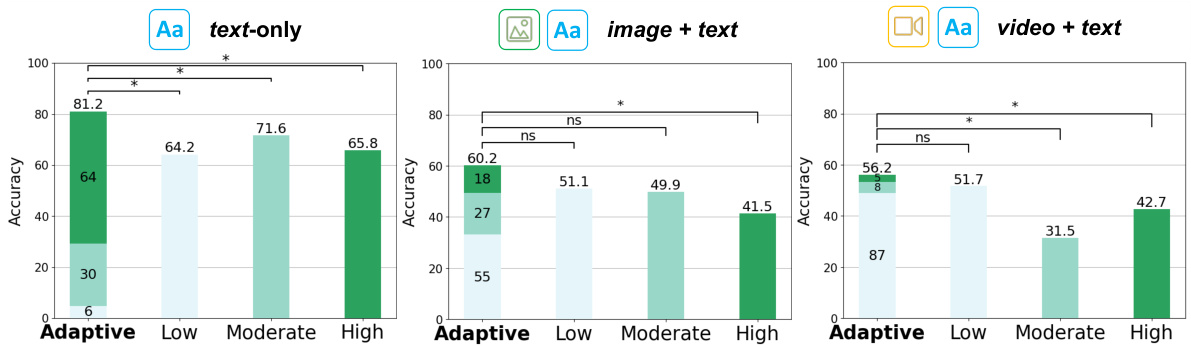
This figure shows the impact of the adaptive complexity selection method on the accuracy of the model across three different data modalities: text-only, image+text, and video+text. It compares the performance of the adaptive method to three static complexity settings (Low, Moderate, High). The results demonstrate that the adaptive method achieves higher accuracy compared to static settings across all modalities, highlighting the effectiveness of dynamically adjusting the complexity level based on the input query.
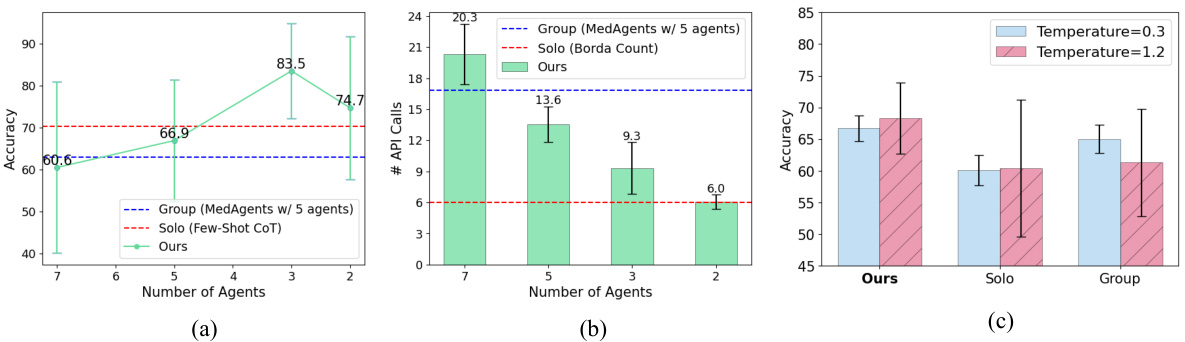
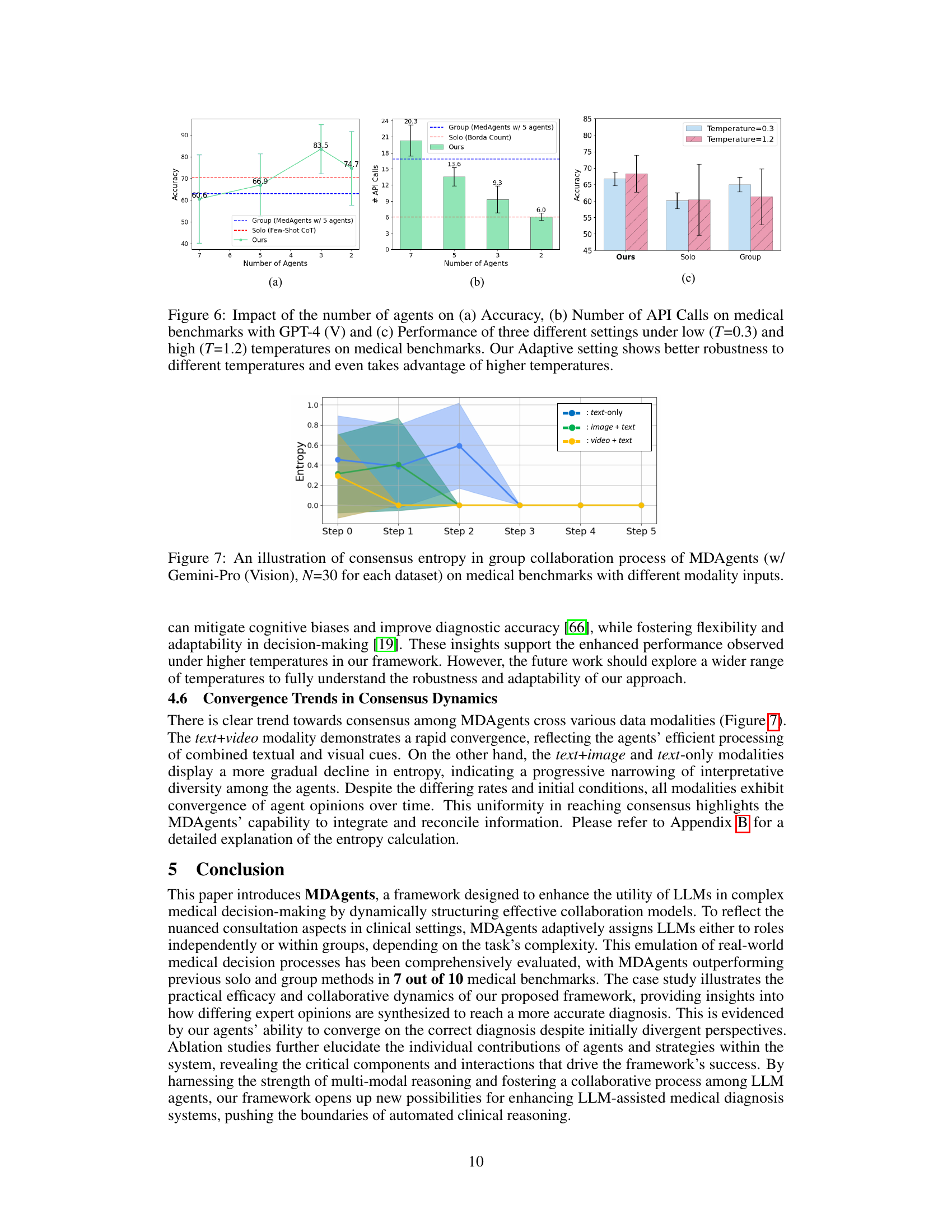
This figure displays the results of experiments comparing the performance of three different settings (Solo, Group, and Ours - Adaptive) across various medical benchmarks. The x-axis represents the number of agents used, while the y-axis in (a) shows the accuracy achieved and in (b) displays the number of API calls made. The results demonstrate that the adaptive method (Ours) consistently outperforms both the solo and group methods in terms of accuracy, while also maintaining efficiency by requiring fewer API calls. The chart (c) illustrates the robustness of the adaptive approach across different temperatures, indicating a better performance under higher temperatures.
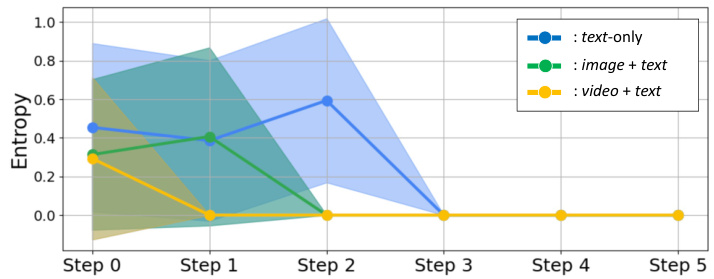
This figure shows the entropy (a measure of uncertainty or disagreement) over time during the collaborative discussion phase of the MDAgents framework. The lines represent the average entropy for different data modalities (text-only, image+text, video+text). The shaded areas represent the standard deviation around the average. The figure demonstrates how the entropy decreases over time (steps 0-5), indicating a convergence of agent opinions and reaching a consensus. The speed of convergence varies based on the data modality, with video+text showing the fastest convergence and text-only the slowest.
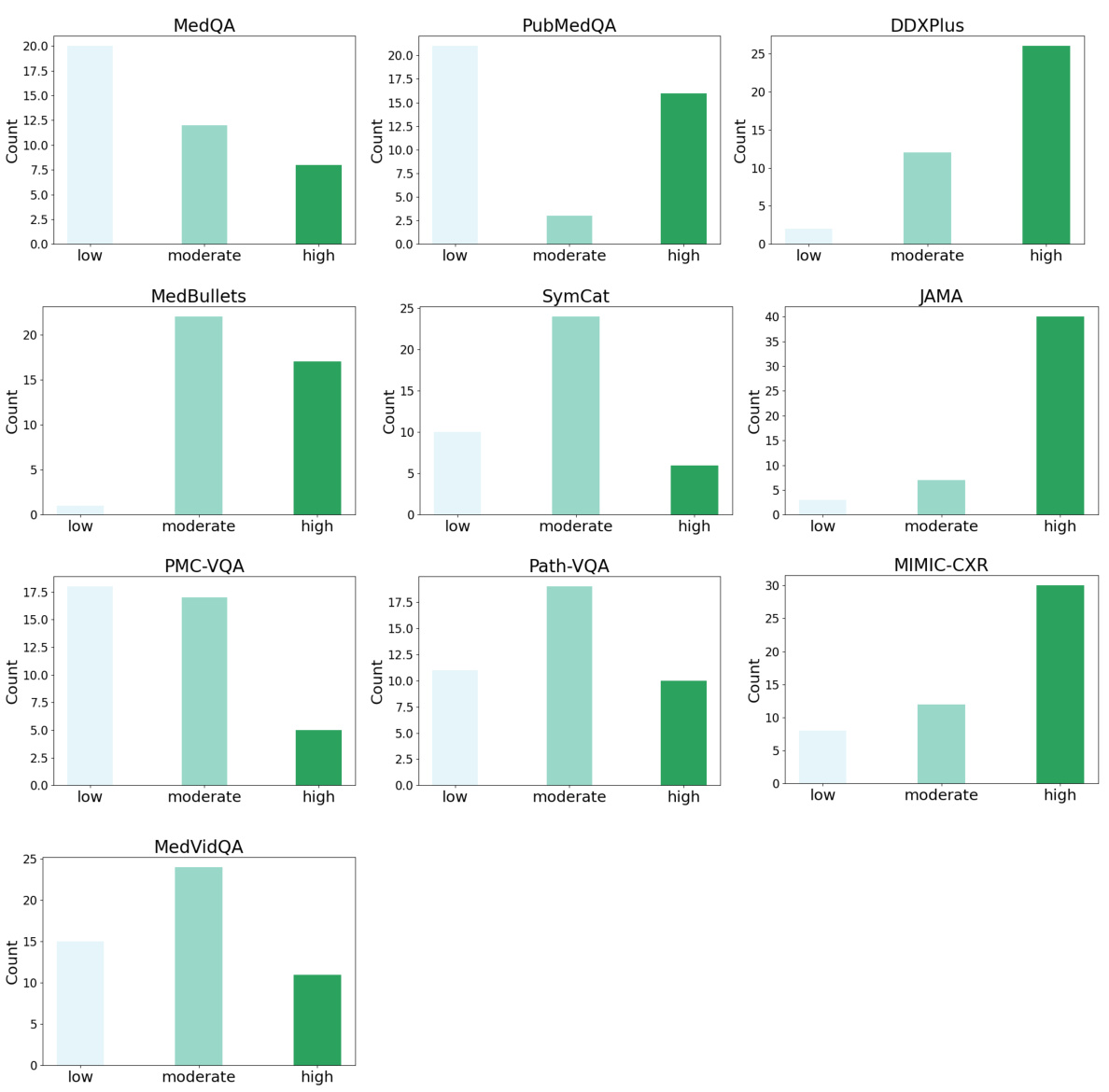
This figure shows the distribution of low, moderate, and high complexity questions in different medical datasets as classified by GPT-4 and Gemini. The complexity levels reflect the difficulty of the questions based on their textual nature, clinical reasoning involved and the inclusion of image or video data. It highlights the diversity in complexity across datasets, indicating the need for an adaptive approach like MDAgents.
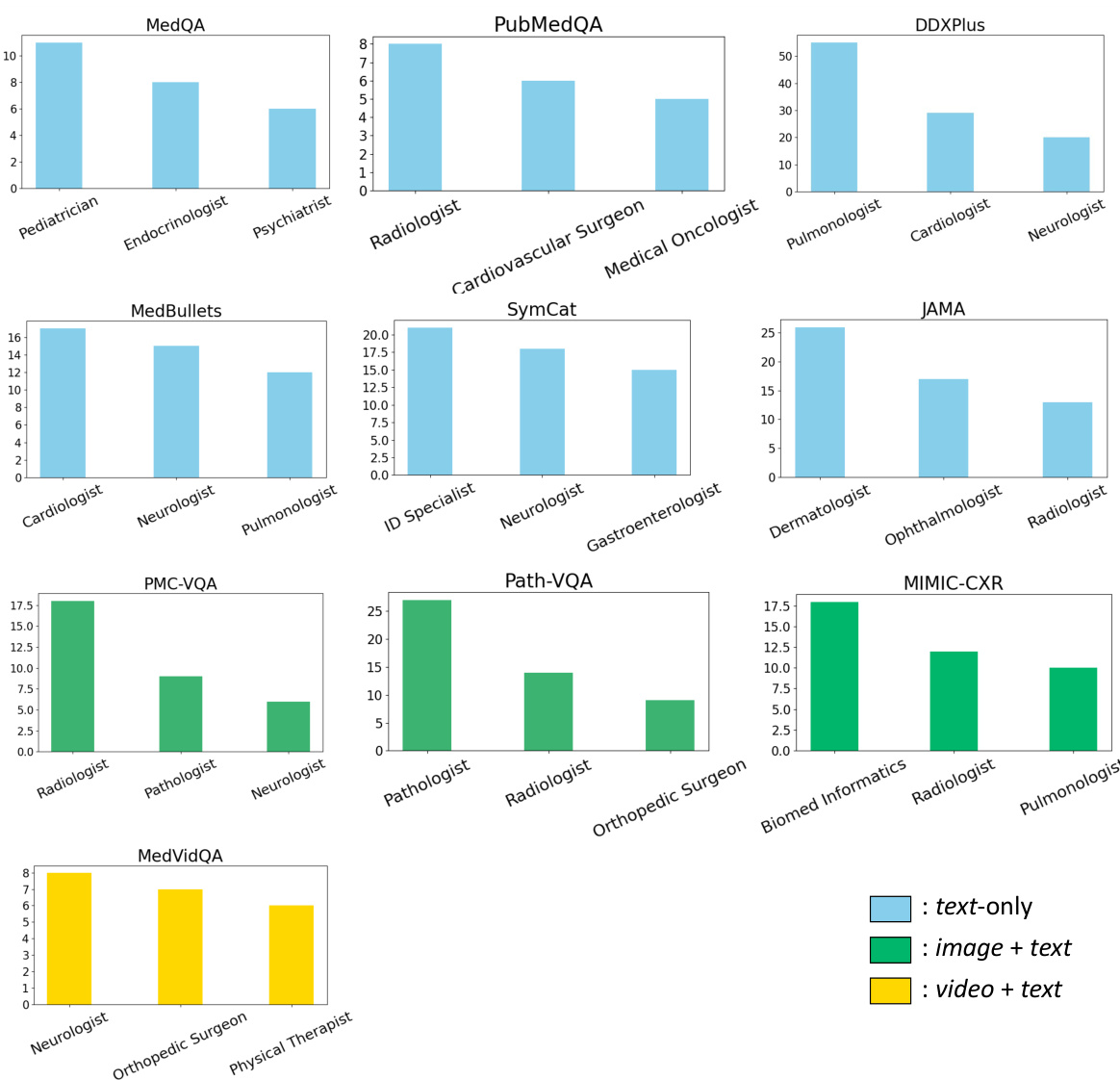
This figure shows the complexity distribution for each dataset as classified by GPT-4(V) and Gemini-Pro (Vision). It highlights the varying levels of complexity across different types of medical tasks, from simple text-based questions (low complexity) to complex tasks involving image and video interpretation (high complexity). The differences reflect the diverse nature of medical question answering, diagnostic reasoning, and medical visual interpretation.
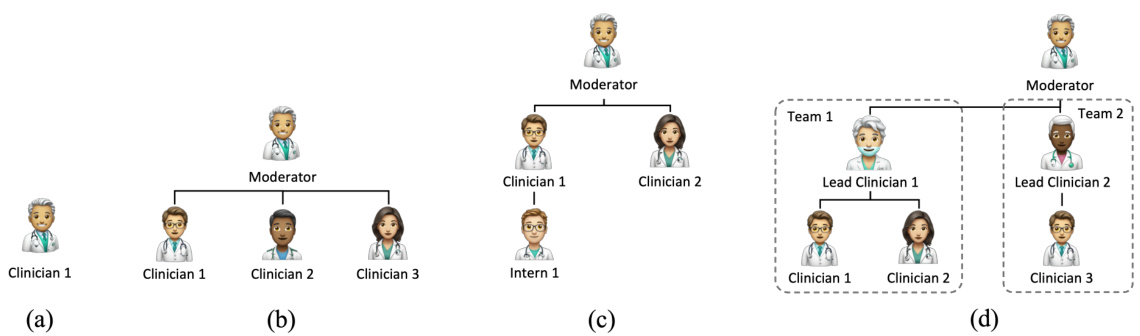
This figure illustrates the different agent structures used in the MDAgents framework depending on the complexity of the medical query. (a) shows a single Primary Care Clinician for low-complexity queries. (b) depicts a Multi-disciplinary Team (MDT) for moderate complexity, where multiple specialists collaborate. (c) presents a hierarchical MDT for more complex scenarios. (d) illustrates an Integrated Care Team (ICT), the most complex structure, involving multiple teams and specialists for high-complexity queries.

The MDAgents framework is shown, illustrating its four key steps. First, the complexity of the medical query is checked. Then, based on the complexity, agents (LLMs) are recruited; a single agent for low-complexity queries, or teams of agents (MDT or ICT) for moderate or high-complexity queries, respectively. Next, analysis and synthesis occur within the recruited agents, followed by a final decision and report generation. This dynamic process mimics the way human clinicians approach medical decision-making.

This figure illustrates the MDAgents framework’s four main steps for medical decision-making. It starts by checking the complexity of the medical query. Based on this complexity, the appropriate team of LLMs (Primary Care Clinician, Multidisciplinary Team, or Integrated Care Team) is recruited to analyze and synthesize information to arrive at a final decision. The framework adapts its approach based on the complexity of the task, mirroring real-world medical decision-making processes.
This figure illustrates the MDAgents framework, which consists of four main steps: 1) assessing the complexity of a given medical query; 2) recruiting a team of LLMs (Large Language Models) tailored to the query’s complexity (a solo LLM for simple queries, a multidisciplinary team (MDT) for moderate queries, and an integrated care team (ICT) for complex queries); 3) analyzing and synthesizing information from various sources using the recruited LLMs; and 4) making a final decision based on the integrated information.
More on tables
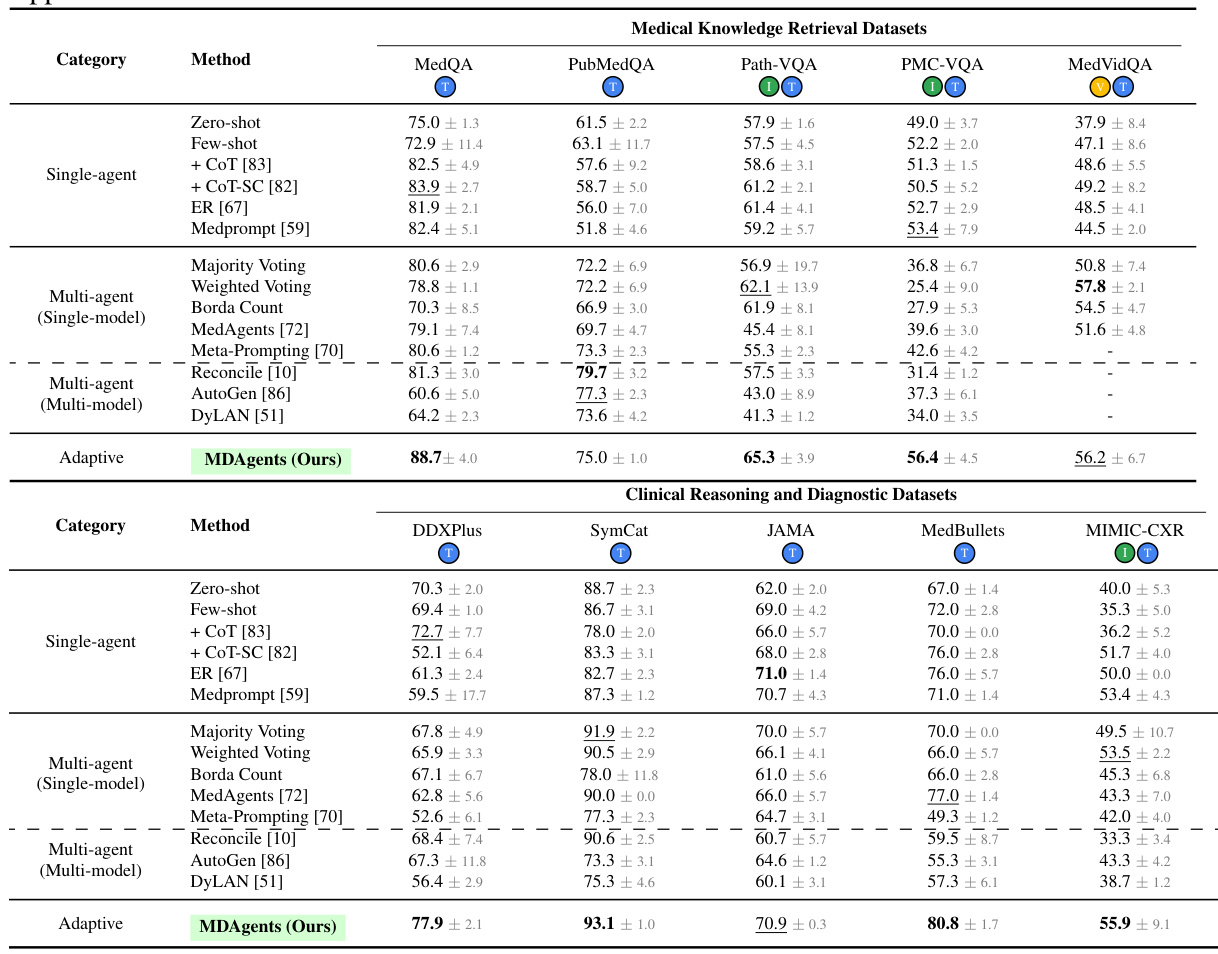
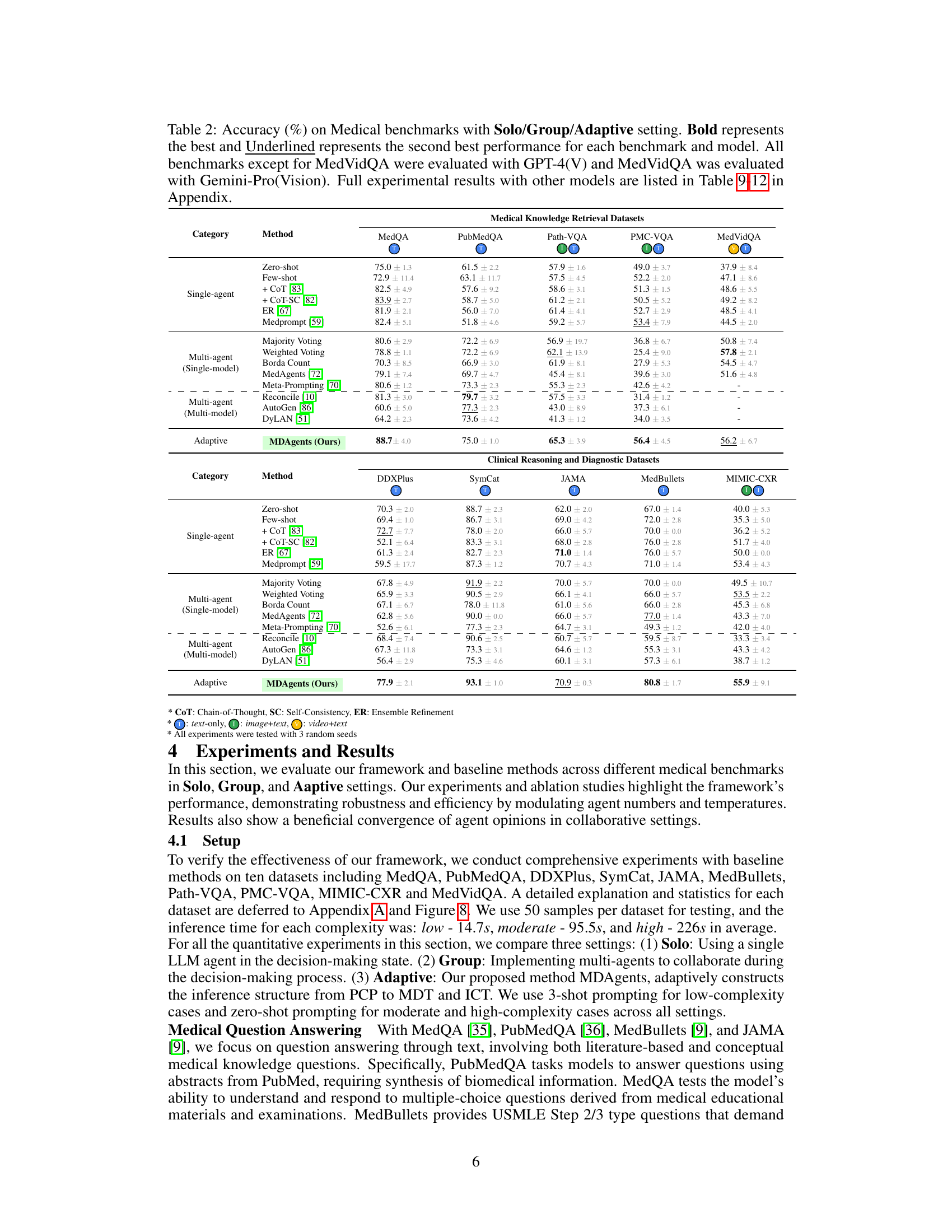
This table presents the accuracy results of different methods (Solo, Group, and Adaptive) on ten medical benchmarks. The benchmarks are categorized into medical knowledge retrieval and clinical reasoning/diagnostic tasks. The table highlights the best performing method for each benchmark, indicating the effectiveness of the adaptive approach compared to single-agent and multi-agent baselines. Detailed results with additional models are available in the appendix.

This table presents the ablation study results, showing the impact of adding external medical knowledge (MedRAG) and moderator reviews to the MDAgents framework. It shows the average accuracy improvement across all datasets when incorporating these additions individually and together.
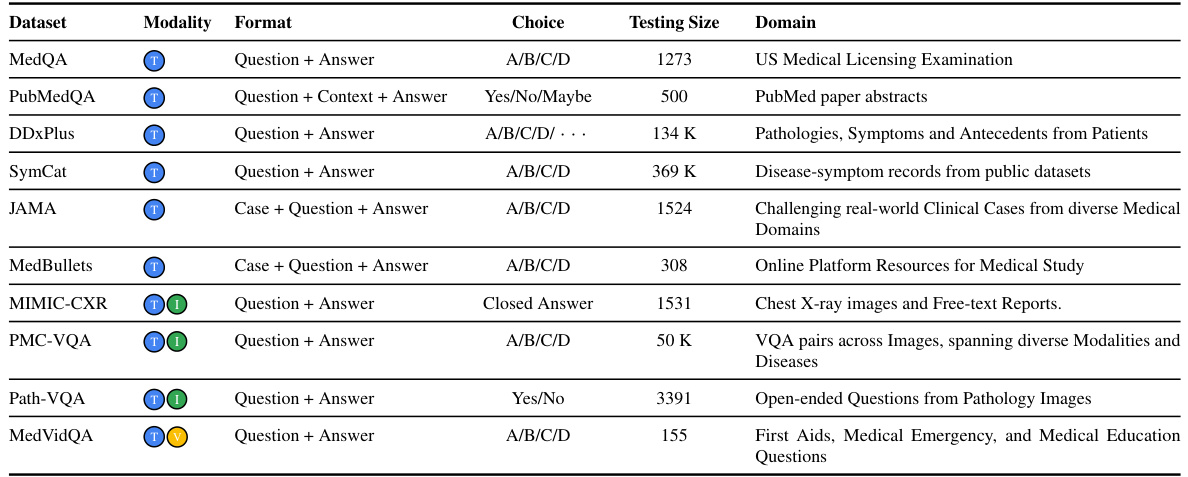
This table presents the accuracy results of different methods (Solo, Group, and Adaptive) on ten medical benchmarks. The benchmarks cover various medical tasks including question answering, diagnosis, and visual interpretation. The table highlights the superior performance of the MDAgents (Adaptive) approach compared to solo and group methods, indicating the effectiveness of the adaptive collaboration strategy.
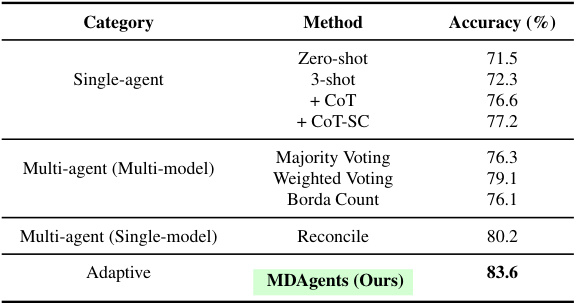
This table presents a comprehensive evaluation of various methods on the complete MedQA 5-options dataset using the GPT-40 mini model. It compares the accuracy of different single-agent and multi-agent approaches, including MDAgents, highlighting the superior performance of MDAgents in achieving an accuracy of 83.6%.

This table presents the accuracy results of different methods (Solo, Group, and Adaptive) on ten medical benchmarks. It shows the performance comparison of several baseline methods and MDAgents under different settings. The results highlight the superior performance of MDAgents, particularly on benchmarks requiring medical knowledge and multi-modal reasoning.

This table presents ablation study results, showing the impact of adding a moderator’s review and/or MedRAG (Retrieval-Augmented Generation) to the MDAgents framework. It shows that both methods improve accuracy, and combining them yields the highest accuracy.

This table presents the accuracy results for various collaborative settings in handling high-complexity image+text tasks. It compares sequential vs. parallel processing approaches, with and without discussion among agents. The results highlight the significant impact of enabling discussion in both sequential and parallel settings, leading to improved accuracy.
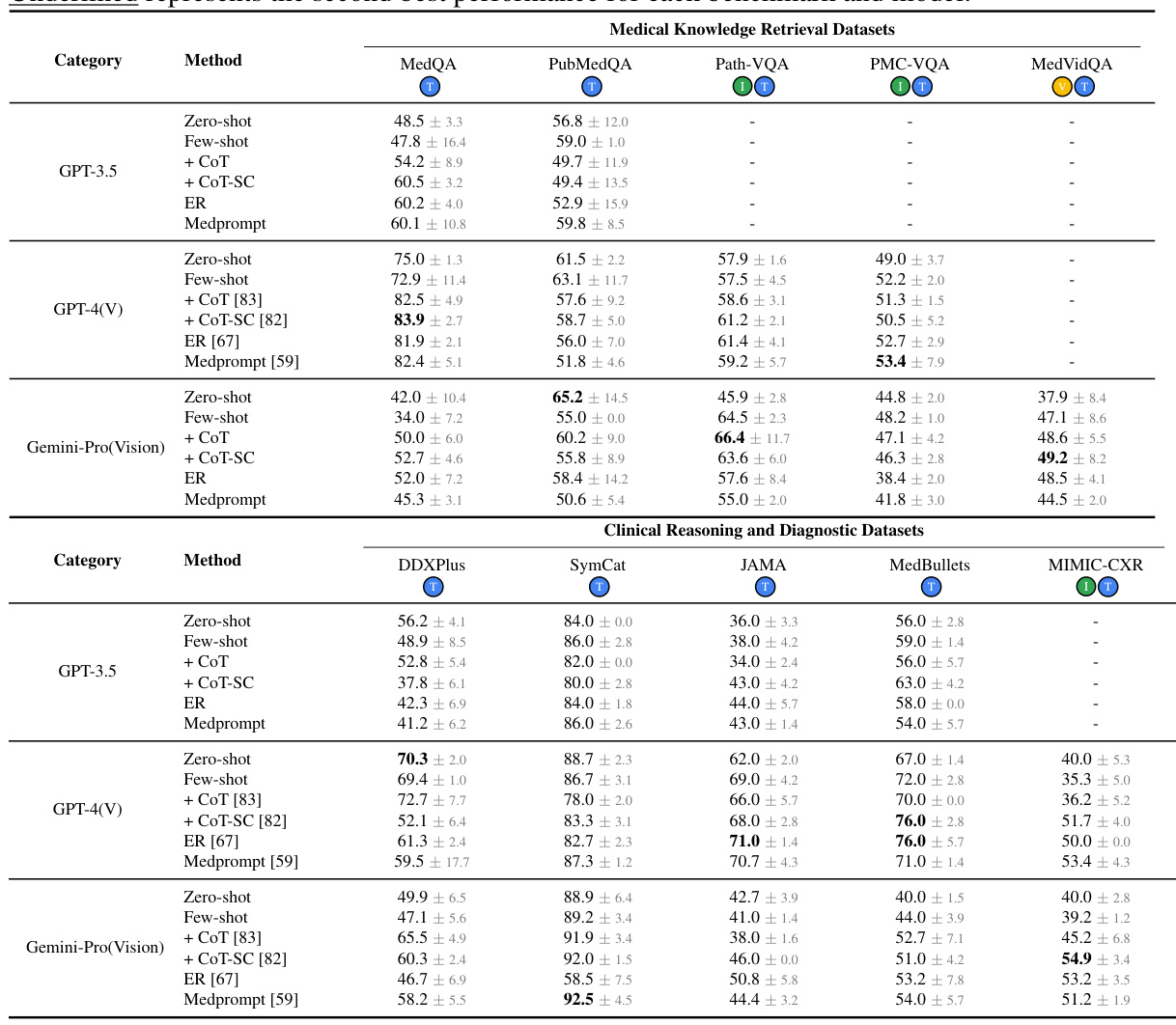
This table presents the accuracy of different methods (Solo, Group, and Adaptive) on various medical benchmarks. It shows the performance of different LLMs (GPT-3.5, GPT-4, and Gemini) using several techniques (zero-shot, few-shot, chain-of-thought, self-consistency, ensemble refinement, and MedPrompt). The adaptive method (MDAgents) is compared against single-agent and multi-agent baselines. Bold indicates the best performance for each benchmark, and underlined indicates the second-best.
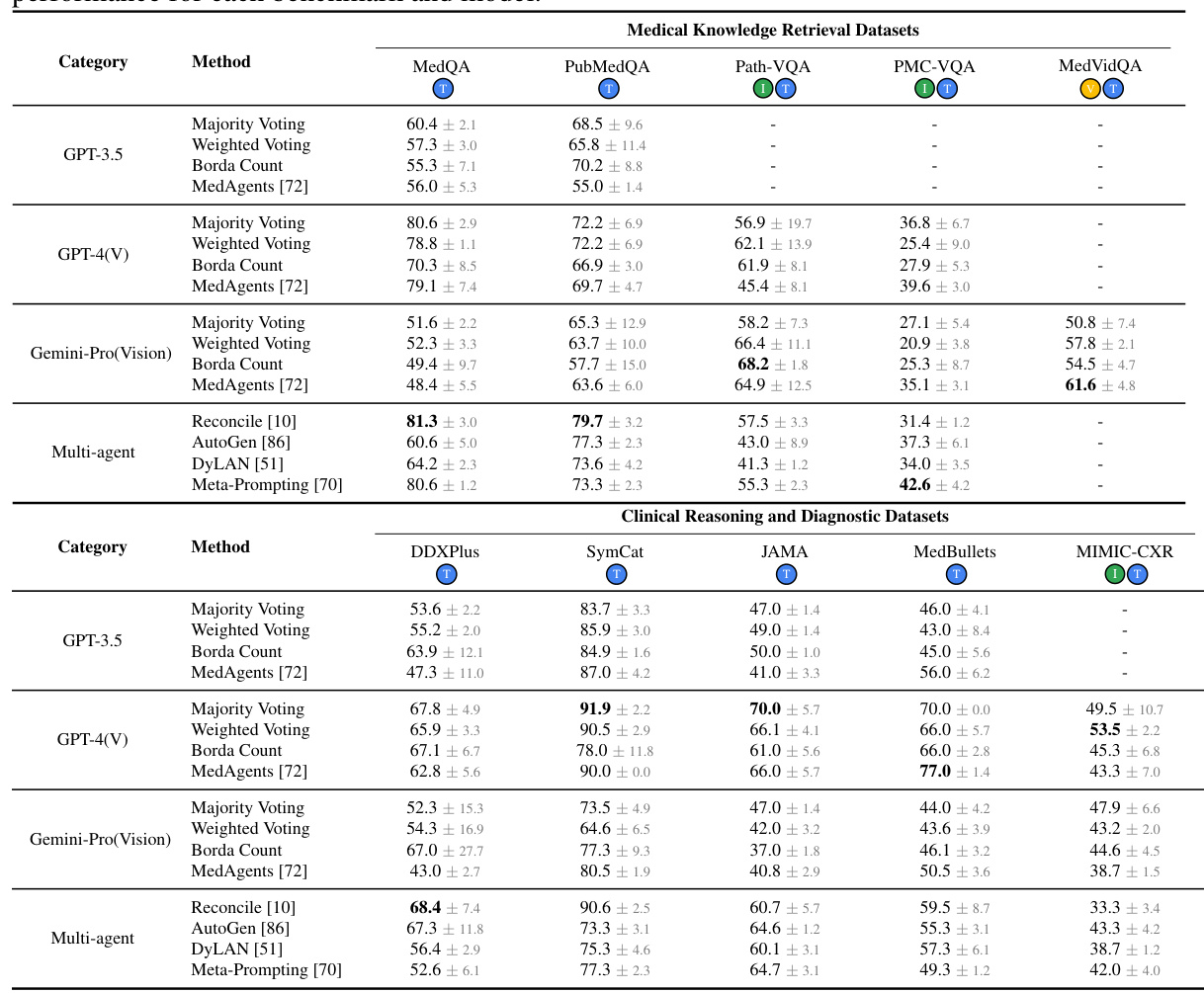
This table presents the accuracy results of different methods (Solo, Group, and Adaptive) on ten medical benchmarks. The benchmarks cover various tasks, including medical knowledge retrieval, clinical reasoning, and medical visual interpretation. The table highlights the best-performing method for each benchmark and shows the impact of different model settings and the adaptive approach.
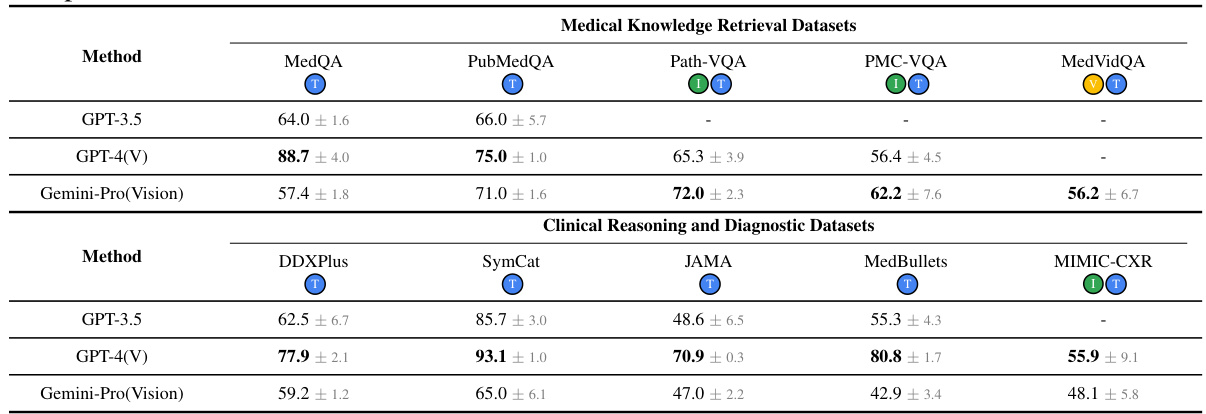
This table presents the accuracy results achieved by various methods (Solo, Group, and Adaptive) across ten different medical benchmarks. The benchmarks are categorized into Medical Knowledge Retrieval and Clinical Reasoning & Diagnostic datasets. The table highlights the best-performing method for each benchmark, indicating the effectiveness of the adaptive approach in comparison to traditional single-agent and fixed multi-agent methods.
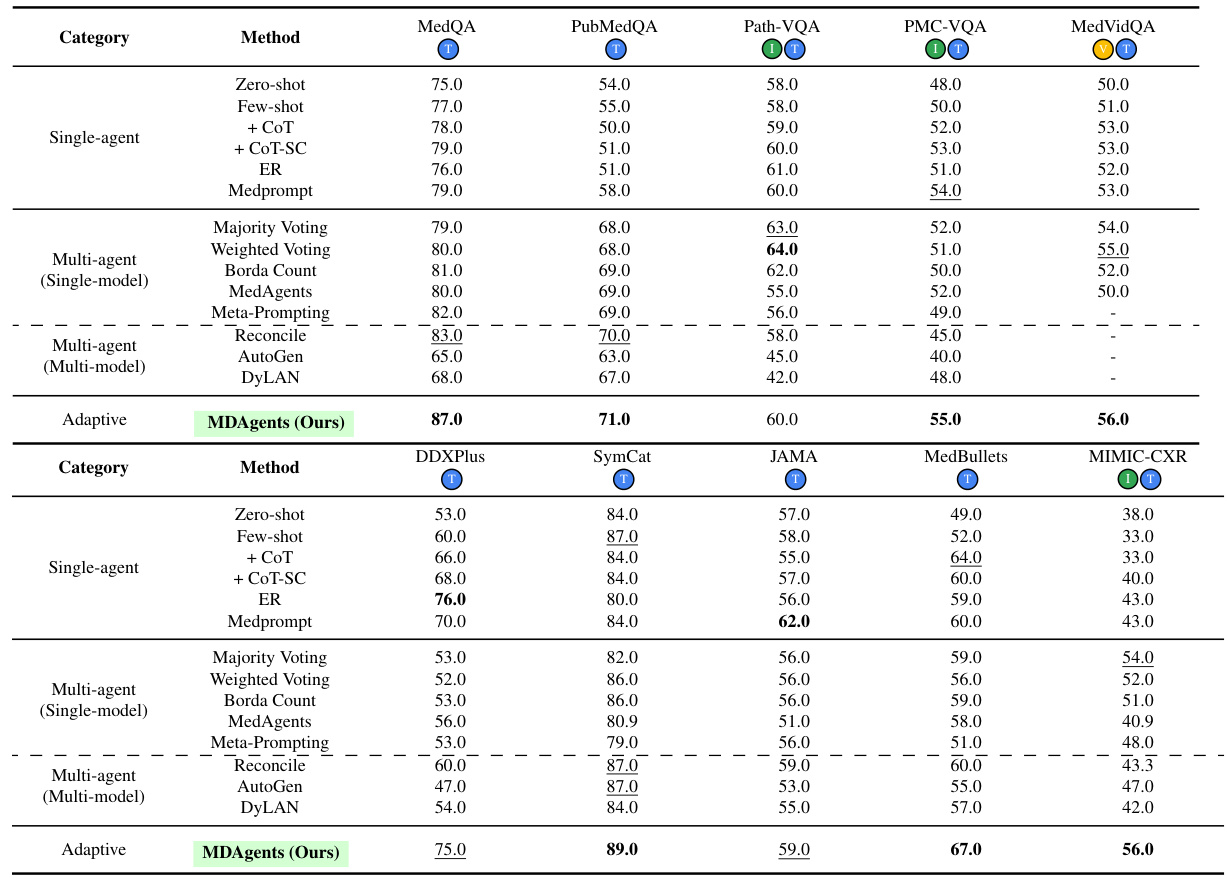
This table presents the accuracy results of different methods (Solo, Group, and Adaptive) on ten medical benchmarks. It shows the performance of various methods, including baseline methods and the proposed MDAgents framework, for each benchmark. The best and second-best performing models are highlighted for each benchmark and method. The table also notes the specific LLMs used for each benchmark.

This table presents the accuracy of different methods (Zero-shot, Few-shot, CoT, CoT-SC, ER, Medprompt, Majority Voting, Weighted Voting, Borda Count, MedAgents, Meta-Prompting, Reconcile, AutoGen, DyLAN, and MDAgents) on 10 medical benchmarks categorized into Medical Knowledge Retrieval and Clinical Reasoning & Diagnosis. The results show the performance of each method across three settings: Solo (single LLM agent), Group (multiple LLMs collaborating), and Adaptive (MDAgents, dynamically adjusting the collaboration structure). Different LLMs (GPT-4, Gemini) were used depending on the benchmark. Bold values show the best performance for each benchmark and model.
Full paper#