↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current LLM prompting methods struggle with complex reasoning tasks due to limitations in planning and error correction. They often rely on sequential rationale generation, making error correction difficult and leading to inaccurate final answers. Human reasoning, however, often involves a more structured approach of breaking down problems into smaller, more manageable sub-problems and iteratively refining solutions based on feedback. This is a more adaptive and robust process.
DeAR (Decompose-Analyze-Rethink) addresses this by introducing a novel tree-based reasoning framework. DeAR iteratively builds a reasoning tree by decomposing complex questions into simpler sub-questions (Decompose), generating and self-checking rationales (Analyze), and updating the reasoning process based on feedback from child nodes (Rethink). This approach significantly enhances reasoning accuracy and efficiency across various LLMs and datasets by enabling timely error correction and constructing more adaptive and accurate logical structures.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and complex reasoning. It directly addresses the limitations of existing LLM prompting methods by introducing a novel, human-like reasoning framework. This provides a significant advancement in LLM capabilities, opening new avenues for improved accuracy, efficiency and interpretability in various reasoning tasks. The findings are relevant to current trends in prompt engineering and cognitive AI, inspiring further investigation into efficient and accurate reasoning strategies for LLMs.
Visual Insights#
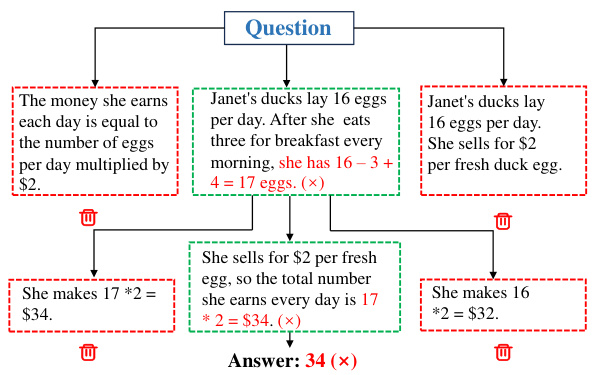
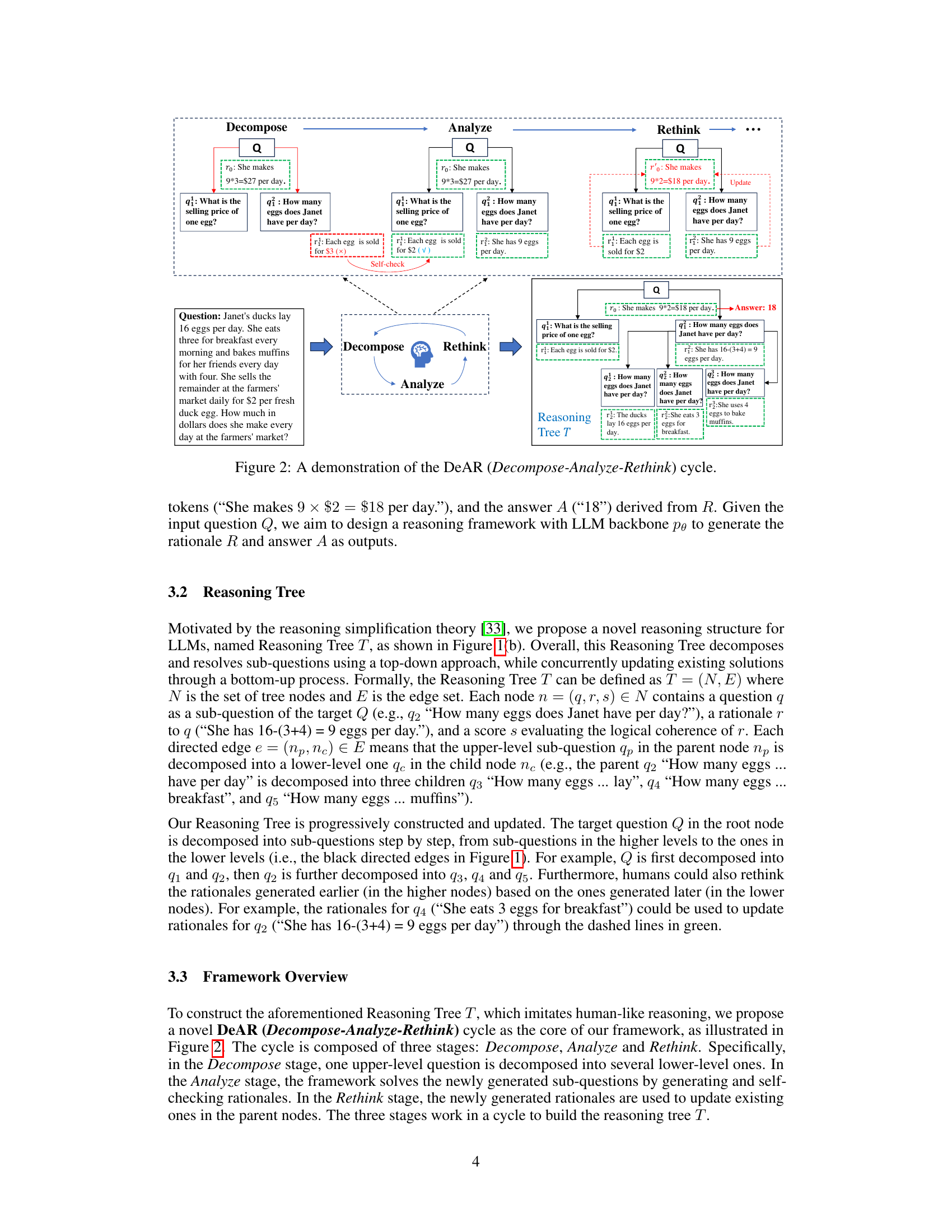
This figure compares the reasoning process of Tree-of-Thoughts (ToT) and the proposed DeAR method on a sample math word problem. ToT uses a tree structure to explore different reasoning paths sequentially, potentially leading to errors propagating through subsequent steps. In contrast, DeAR uses an iterative tree-based question decomposition, analyzing and refining rationales at each step and globally updating them to improve logical consistency and accuracy.
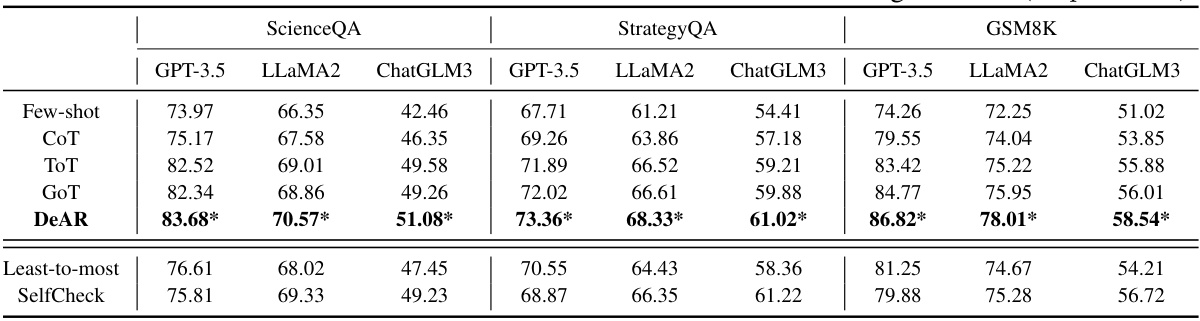
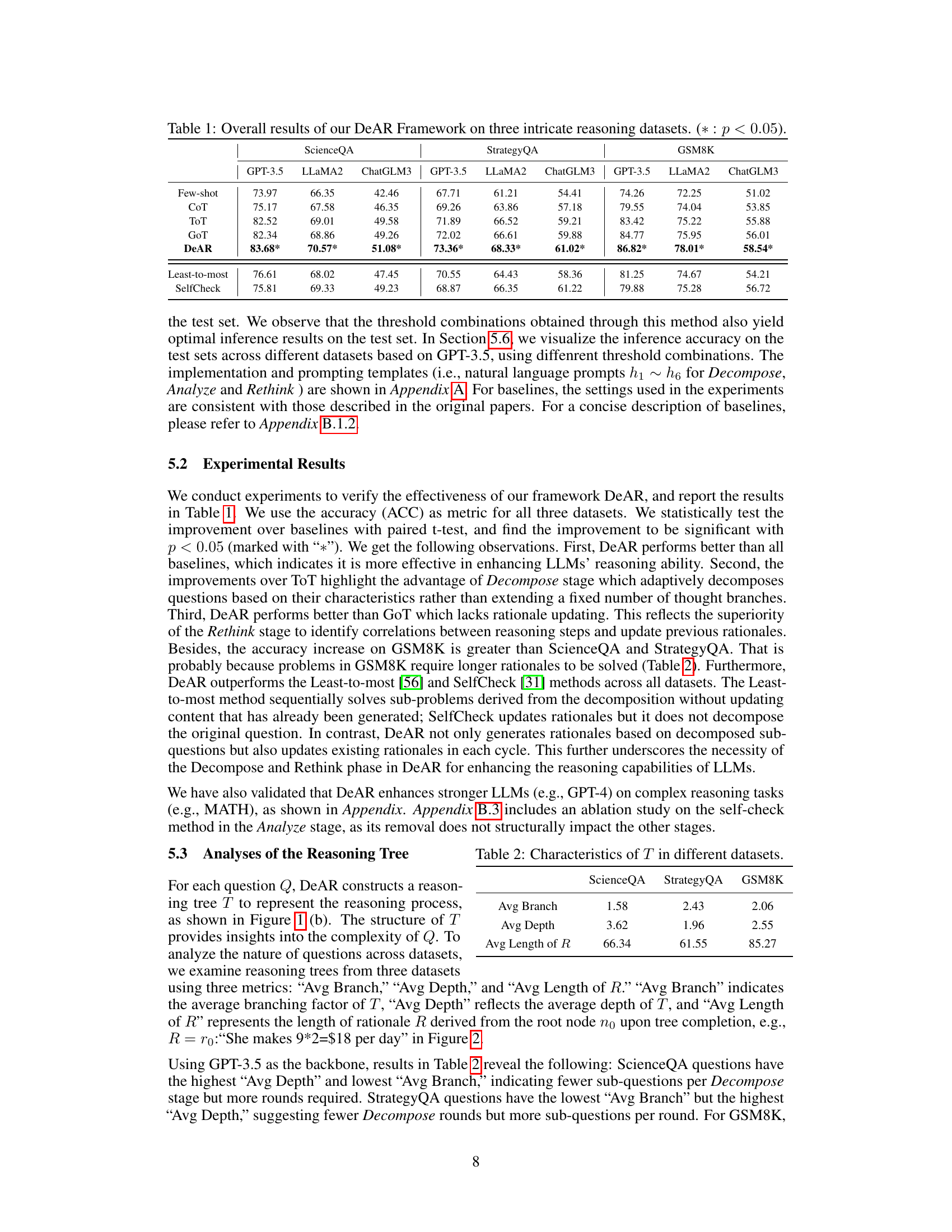
This table presents the overall performance of the DeAR framework on three different reasoning datasets (ScienceQA, StrategyQA, and GSM8K). It compares DeAR’s accuracy against several baseline methods (Few-shot, CoT, ToT, GoT, Least-to-most, and SelfCheck) across three different LLMs (GPT-3.5, LLAMA2, and ChatGLM3). The asterisk (*) indicates statistically significant improvements (p < 0.05) compared to the baselines.
In-depth insights#
DeAR Framework#
The DeAR (Decompose-Analyze-Rethink) framework presents a novel approach to complex reasoning tasks by iteratively building a reasoning tree. Its core innovation lies in its three-stage cycle: decomposition of a problem into simpler sub-problems, analysis and self-checking of rationales for each sub-problem, and rethinking and updating parent-level rationales based on child-node feedback. This cycle mimics human-like logical planning and facilitates timely error correction. Unlike existing methods like Tree-of-Thoughts (ToT) and Graph-of-Thoughts (GoT) which rely on linear rationale extensions or rigid tree structures, DeAR’s tree-based structure offers more flexibility and adaptability, allowing for a more dynamic and human-like reasoning process. The global perspective of DeAR, achieved through iterative updating and self-checking, makes it more accurate and robust than its predecessors. The efficiency gains demonstrated, particularly in terms of the superior trade-off between accuracy and reasoning time, makes DeAR a highly promising approach for future reasoning tasks within large language models.
Reasoning Tree#
The concept of a ‘Reasoning Tree’ offers a compelling structure for representing complex reasoning processes, particularly within the context of large language models (LLMs). It mirrors human cognitive processes, where problems are broken down into smaller, more manageable sub-problems. This hierarchical structure facilitates a more organized and efficient approach compared to linear reasoning methods. The tree’s nodes represent sub-questions, and the edges show the decomposition process. Each node contains rationales, offering insights into the reasoning steps. Crucially, the iterative nature of the tree allows for global updates, where feedback from lower-level nodes (child nodes) can influence and refine the rationales in higher-level nodes (parent nodes). This dynamic updating mechanism is a key strength, allowing for error correction and improved accuracy. However, implementing such a tree structure within LLMs presents challenges. The automatic generation and management of the tree itself require sophisticated prompting strategies and algorithms capable of handling the dynamic nature of its creation. The balance between accuracy and efficiency in building and utilizing these trees remains a critical area for further research.
LLM Enhancements#
LLM enhancements are a crucial area of research, focusing on improving the capabilities and efficiency of large language models. Key areas of enhancement include improving reasoning abilities, particularly in complex, multi-step problems. This involves developing methods to reduce logical errors and enhance accuracy, potentially through techniques like iterative refinement and incorporating feedback mechanisms. Efficiency improvements are also critical, aiming to reduce computational cost and improve response times. This could be achieved by optimizing the model architecture or by employing techniques that allow for selective processing of information, avoiding unnecessary computations. Addressing biases and ethical concerns is equally important, as LLMs often reflect biases present in their training data. Mitigation strategies should be implemented to improve fairness and mitigate potential harm. Finally, improving transparency and interpretability is essential to facilitate better understanding and control of these powerful models, allowing for easier identification and correction of errors. The development of effective methods for evaluating and enhancing these different aspects of LLMs will be key to realizing their full potential.
Empirical Results#
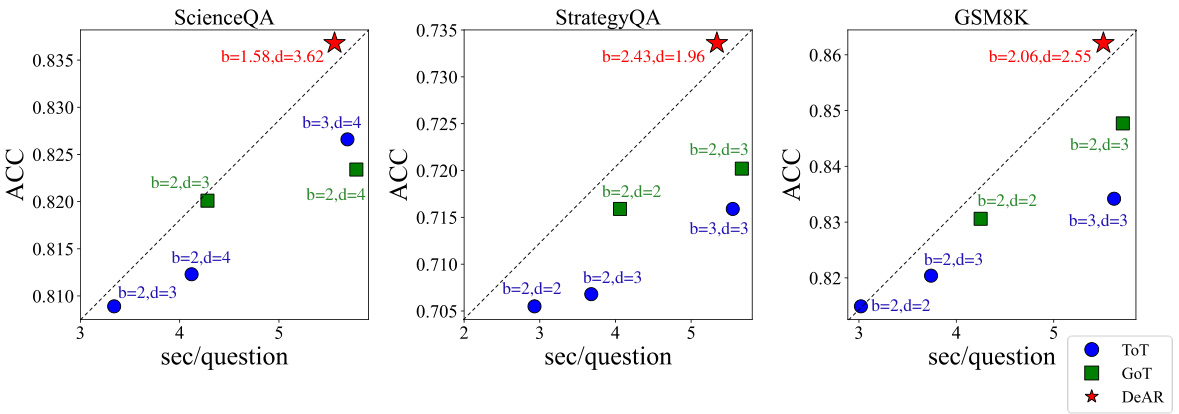
An Empirical Results section in a research paper would present the quantitative findings of experiments, comparing the proposed method’s performance against baselines. Key aspects to look for include clear presentation of metrics (e.g., accuracy, F1-score, runtime), statistical significance testing to show performance differences aren’t due to chance, and comprehensive analysis of results across different datasets and experimental settings. Visualizations (graphs, tables) are crucial for easy understanding and conveying trends. A strong section highlights the method’s strengths, acknowledges weaknesses, and discusses any surprising or unexpected results, potentially linking findings back to the method’s design choices or limitations. The overall goal is to provide compelling evidence supporting the paper’s claims and offering insights into the method’s behavior. Ideally, the presentation would be unbiased, using proper statistical methods and avoiding misleading interpretations.
Future Work#
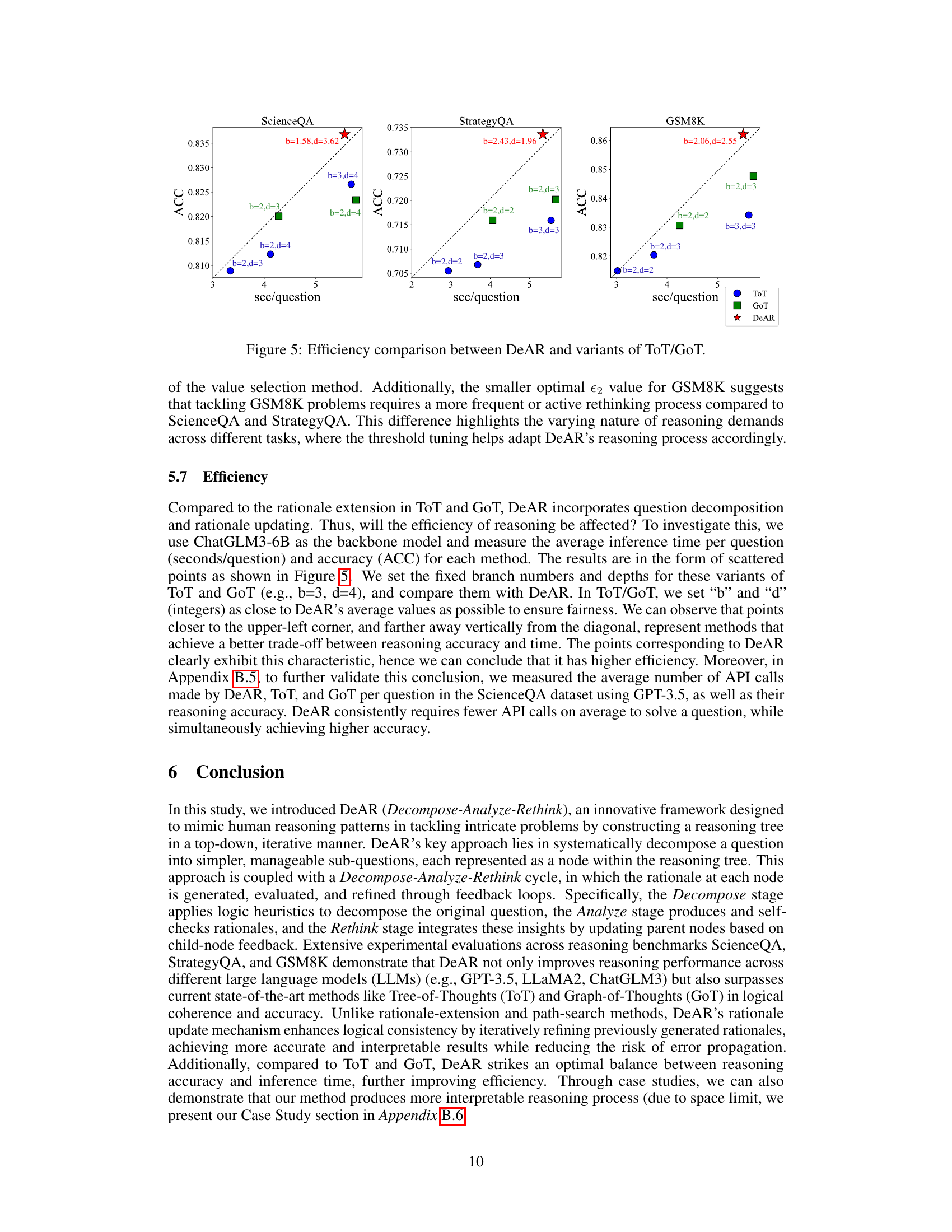
The authors acknowledge that while DeAR shows promise, there’s room for improvement. Reasoning time, especially for complex problems, remains a significant challenge due to the iterative nature of the framework. Future work should focus on enhancing efficiency perhaps through architectural modifications or algorithmic optimizations. While logic heuristics proved beneficial, their creation requires manual annotation; future research should explore automated heuristic generation to improve scalability and reduce annotation burdens. Broader dataset evaluation is crucial to validate DeAR’s generalizability and robustness beyond the benchmarks used. Finally, integrating reinforcement learning techniques, similar to OpenAI’s approaches, could facilitate continuous improvement and more adaptive learning within the DeAR framework.
More visual insights#
More on figures
This figure compares the reasoning process of Tree-of-Thoughts (ToT) and the proposed DeAR method on a sample math word problem. Panel (a) shows ToT’s sequential, tree-like approach where it extends existing rationales, possibly leading to error propagation. Panel (b) illustrates DeAR’s iterative method of decomposing the problem into sub-problems, analyzing each sub-problem, and then using feedback from child nodes to rethink and update rationales at higher levels of the reasoning tree, allowing for error correction and creating a more adaptable and accurate logical structure.
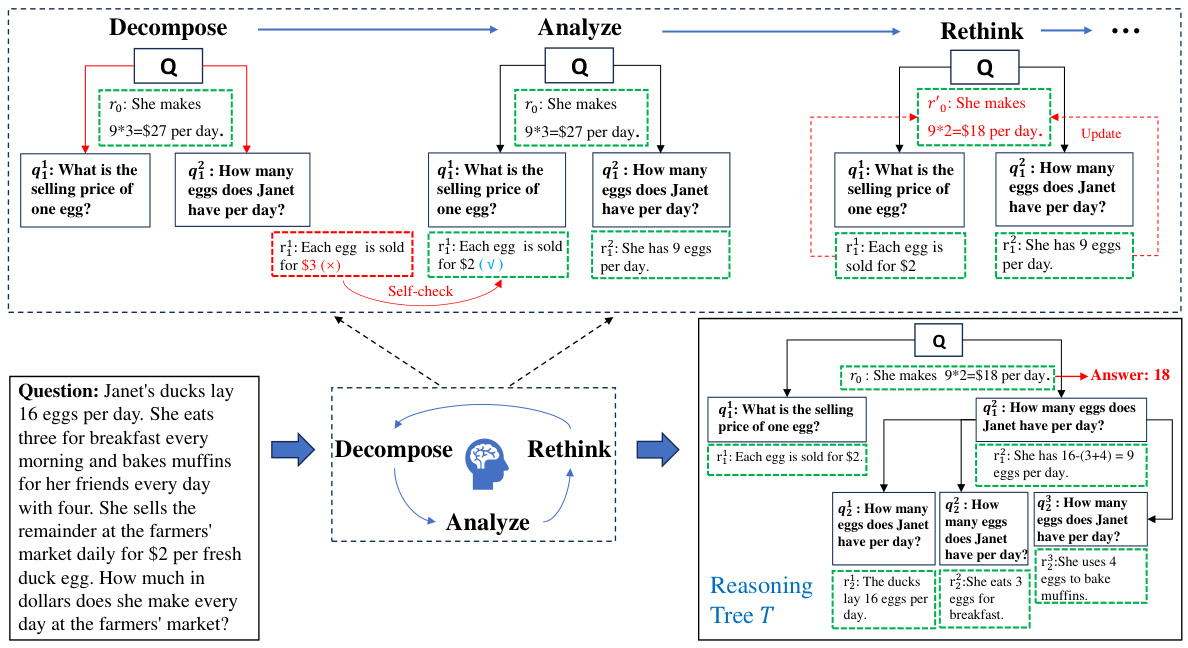
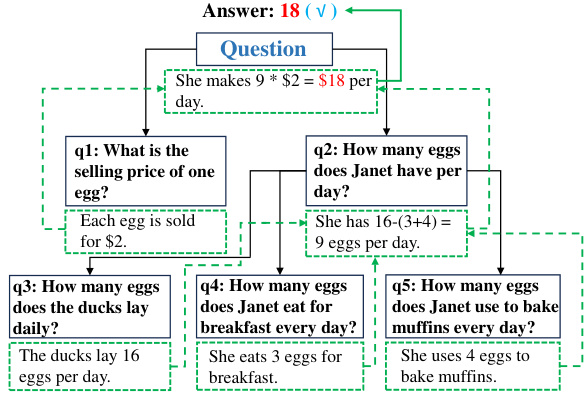
This figure demonstrates the iterative process of the DeAR framework. It shows how a question is decomposed into sub-questions, analyzed to generate rationales, and then rethought by updating the rationales based on the results from lower-level sub-questions. The cycle continues until the final answer is obtained.
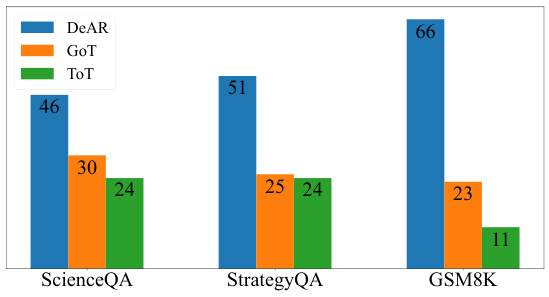
This figure shows the results of a human evaluation comparing the logical coherence of rationales generated by three different methods: DeAR, GoT, and ToT. Annotators were presented with rationales from each method for the same questions and asked to choose the most logical one. The bar chart displays the percentage of annotators selecting each method’s rationales as the most logical for ScienceQA, StrategyQA, and GSM8K datasets. DeAR consistently receives a higher percentage of selections across all datasets, suggesting its rationales are perceived as more logically sound.
This figure compares the reasoning processes of Tree-of-Thoughts (ToT) and the proposed Decompose-Analyze-Rethink (DeAR) framework on a sample math word problem. Panel (a) shows ToT’s approach, which extends a reasoning tree sequentially, potentially leading to errors propagating through the tree. Panel (b) illustrates DeAR, which uses a tree-based question decomposition approach to plan the reasoning process, allowing for global updates and error correction at each step.
This figure compares the reasoning processes of Tree-of-Thoughts (ToT) and the proposed DeAR method on a sample math word problem. Panel (a) shows ToT’s sequential, linear approach, extending a fixed number of branches from the original question. Panel (b) illustrates DeAR’s iterative, tree-based method, which decomposes the problem into sub-questions, analyzes them independently, and updates the reasoning tree through feedback. The difference highlights DeAR’s more adaptable and human-like reasoning.

This figure compares the reasoning process of Tree-of-Thoughts (ToT) and the proposed DeAR method on a sample math word problem. (a) shows ToT’s sequential, branch-limited approach, highlighting the rigidity and potential for error propagation. (b) illustrates DeAR’s iterative, tree-based method, showcasing its flexibility, global perspective, and capacity for error correction through feedback.
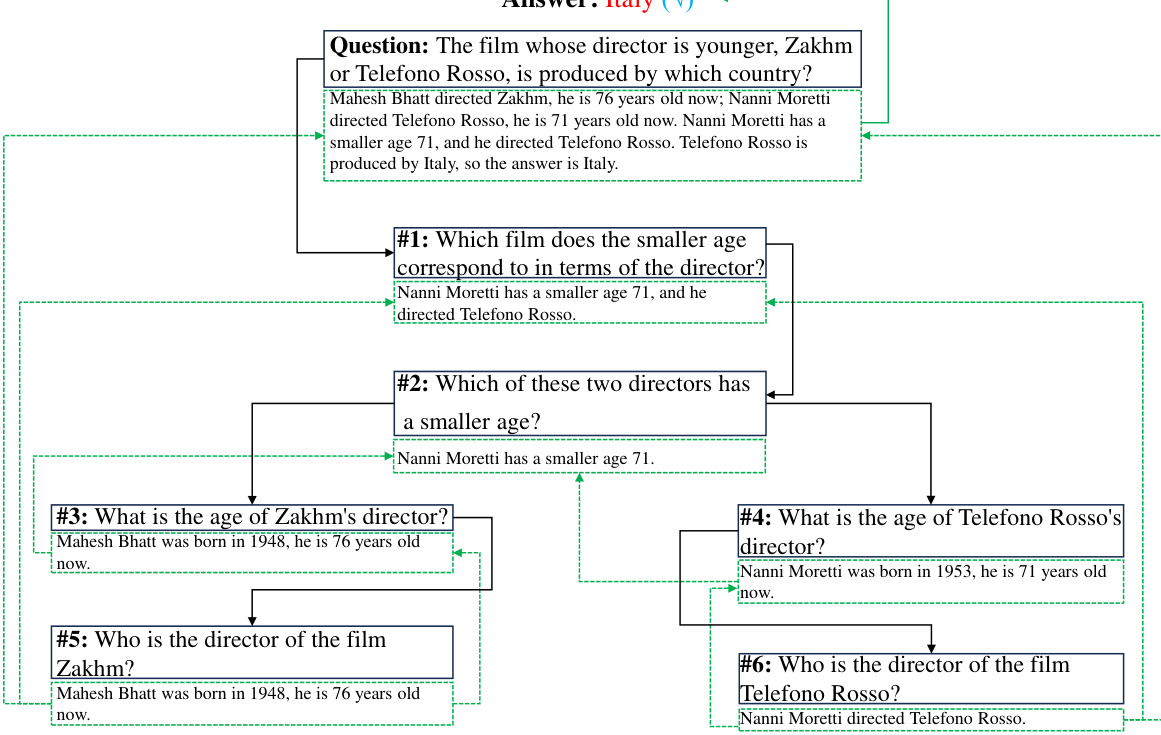
This figure compares the reasoning process of Tree-of-Thoughts (ToT) and the proposed DeAR method on a sample math word problem. ToT uses a tree structure to explore possible reasoning paths, sequentially expanding branches from the original question, whereas DeAR uses a tree-based question decomposition approach that more closely mirrors human-like logical planning. The figure illustrates how DeAR’s iterative decomposition, analysis, and rethinking steps (Decompose-Analyze-Rethink cycle) allow for more adaptive and accurate reasoning with timely error correction.
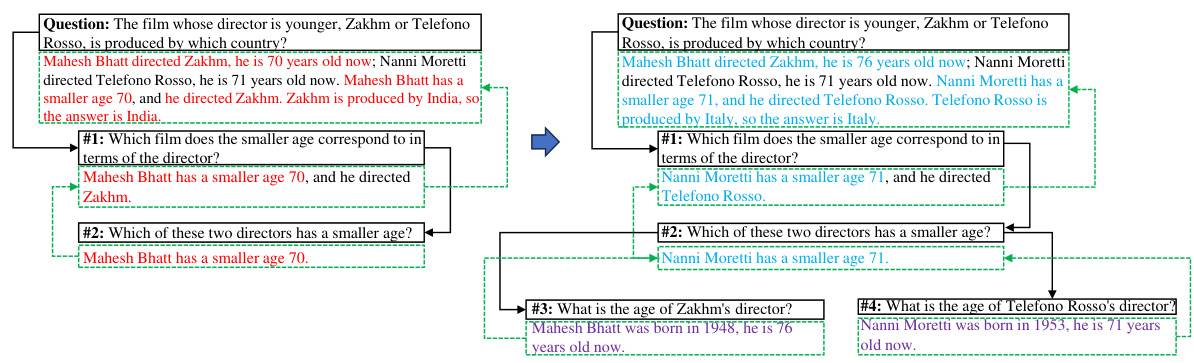
This figure compares the reasoning processes of Tree-of-Thoughts (ToT) and the proposed DeAR framework on a sample math word problem. The ToT approach uses a tree structure with a fixed number of branches (3 in this example), extending rationales sequentially. The DeAR approach iteratively builds a reasoning tree by decomposing the problem into sub-questions (Decompose), generating and self-checking rationales (Analyze), and updating parent-node rationales based on feedback from child nodes (Rethink). The figure visually illustrates the different structures and processes, highlighting DeAR’s more adaptable and accurate approach.
More on tables
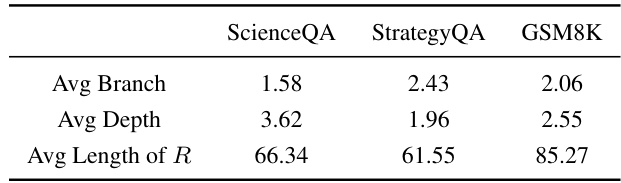
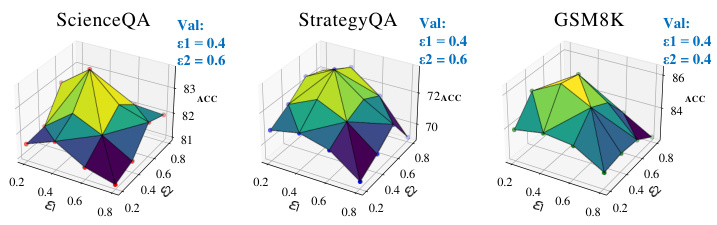
This table presents a quantitative analysis of the reasoning trees (T) generated by the DeAR model across three different datasets: ScienceQA, StrategyQA, and GSM8K. It provides key statistics for each dataset, including the average branching factor (Avg Branch), average depth (Avg Depth), and average length of the rationale (Avg Length of R). These metrics offer insights into the complexity of the questions within each dataset and how the DeAR model approaches them.
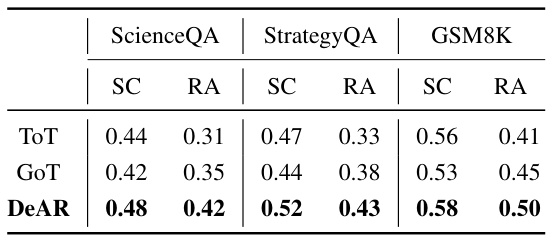
This table presents the results of evaluating the logical coherence of rationales generated by three different methods: Tree-of-Thoughts (ToT), Graph-of-Thoughts (GoT), and the proposed DeAR method. The evaluation uses the ROSCOE suite, specifically focusing on Source Consistency (SC) and Reasoning Alignment (RA) metrics across three different datasets: ScienceQA, StrategyQA, and GSM8K. Higher scores in both SC and RA indicate better logical coherence and alignment with ground truth.
This table presents the overall performance of the DeAR framework on three benchmark datasets: ScienceQA, StrategyQA, and GSM8K. The results compare DeAR against several baseline methods (Few-shot, CoT, ToT, GoT, Least-to-most, and SelfCheck) across three different LLMs (GPT-3.5, LLaMA2, and ChatGLM3). The ‘*’ indicates statistically significant improvements (p < 0.05) over baseline methods. The table shows that DeAR consistently outperforms all baseline methods across all datasets and LLMs.

This table presents the overall performance of the DeAR framework on three benchmark datasets: ScienceQA, StrategyQA, and GSM8K. It compares DeAR against several baseline methods (Few-shot, CoT, ToT, GoT, Least-to-most, and SelfCheck) across three different large language models (LLMs): GPT-3.5, LLaMA2, and ChatGLM3. The results show the accuracy of each method on each dataset and LLM, indicating that DeAR consistently outperforms the baselines. The asterisk (*) denotes statistically significant improvements (p < 0.05).

This table presents the overall performance of the DeAR framework on three benchmark datasets: ScienceQA, StrategyQA, and GSM8K. It compares DeAR’s accuracy against several baseline methods, including few-shot prompting, Chain-of-Thought (CoT), Tree-of-Thoughts (ToT), Graph-of-Thoughts (GoT), Least-to-most prompting, and SelfCheck, across three different LLMs (GPT-3.5, LLaMA2, and ChatGLM3). The results show DeAR achieves significant improvements over the baseline methods on all three datasets and across all LLMs tested, indicated by the asterisks denoting statistically significant differences (p < 0.05).

This table presents the overall performance comparison of the proposed DeAR framework against several state-of-the-art baselines on three complex reasoning benchmarks: ScienceQA, StrategyQA, and GSM8K. The results are broken down by LLM model (GPT-3.5, LLaMA2, and ChatGLM3) and show DeAR’s significant accuracy improvements across all models and datasets. The * indicates statistically significant differences (p<0.05).
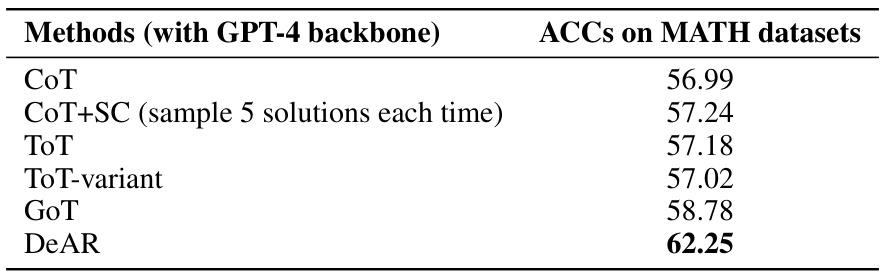
This table presents the overall performance of the DeAR framework on three benchmark datasets: ScienceQA, StrategyQA, and GSM8K. The results are broken down by Large Language Model (LLM) backbone used (GPT-3.5, LLaMA2, and ChatGLM3) and compared to several baseline methods (Few-shot, CoT, ToT, GoT, Least-to-most, SelfCheck). The asterisk (*) indicates statistically significant improvements (p < 0.05) compared to the baseline methods.

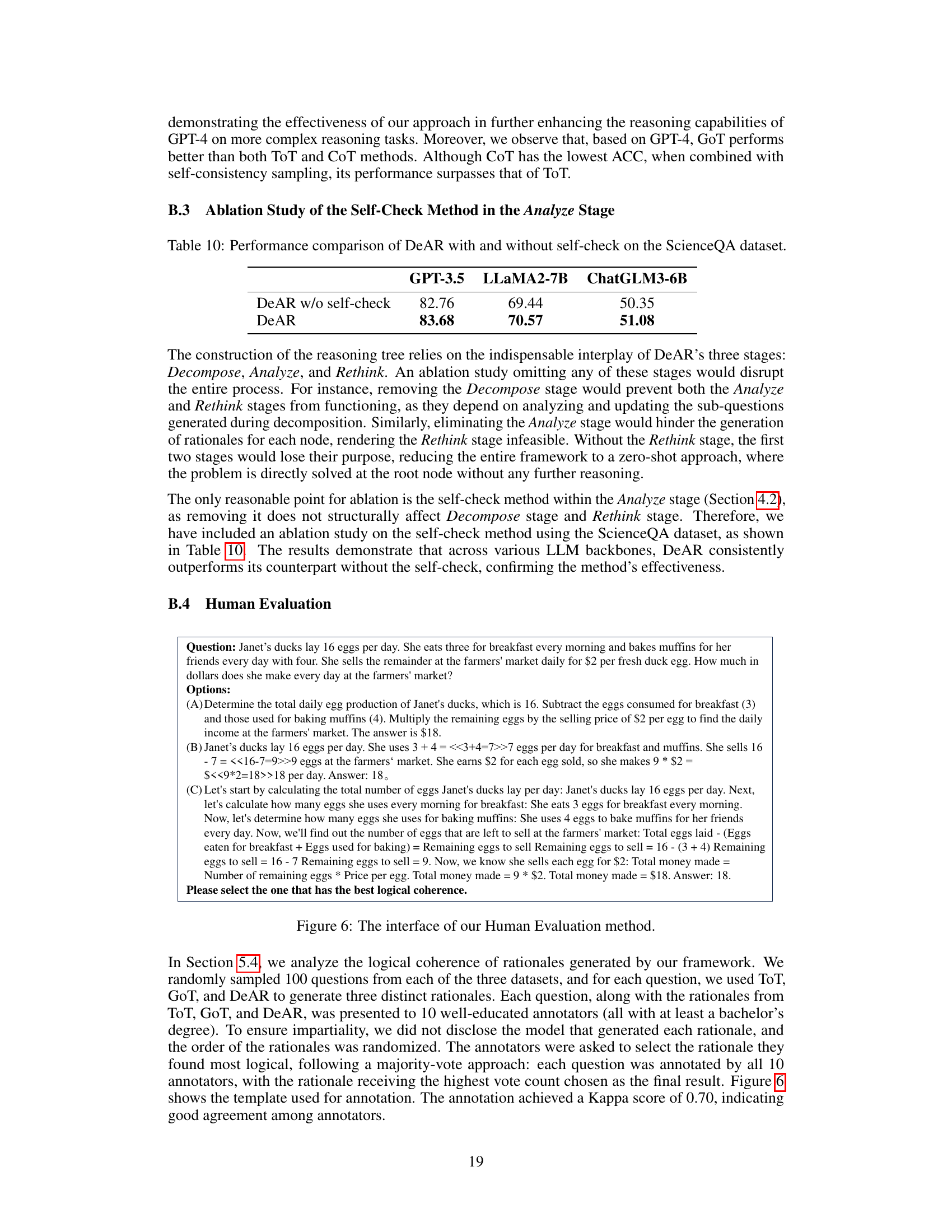
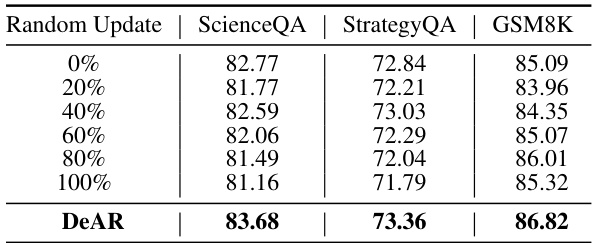
This table presents the results of an ablation study comparing the performance of the DeAR framework with and without the self-check mechanism. The study is conducted using the ScienceQA dataset and three different large language models (LLMs): GPT-3.5, LLaMA2-7B, and ChatGLM3-6B. The accuracy (ACC) is reported for each LLM and framework configuration. The purpose is to demonstrate the impact of the self-check on DeAR’s overall accuracy.

This table presents the overall performance of the DeAR framework on three benchmark datasets: ScienceQA, StrategyQA, and GSM8K. It compares DeAR’s accuracy against several baseline methods (Few-shot, CoT, ToT, GoT, Least-to-most, and SelfCheck) across three different LLMs (GPT-3.5, LLaMA2, and ChatGLM3). The asterisk (*) indicates statistically significant improvements (p < 0.05) compared to the baseline methods.
Full paper#