↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Denoising models have primarily been used for generative tasks. This paper addresses the limited exploration of denoising models for discriminative tasks, focusing on representation learning which is crucial for improving feature discrimination in tasks like classification and object recognition. The authors highlight the challenge of directly applying denoising techniques to discriminative models due to the differences in how they process data and extract features. Existing methods often involve applying denoising as a separate step after feature extraction, increasing computational costs.
The proposed solution, DenoiseRep, innovatively treats each embedding layer in a backbone network (like ResNet or ViT) as a denoising layer. This unified approach eliminates extra computational steps because parameters from the added denoising layers are integrated with the existing embedding layers’ parameters. This joint extraction and denoising process is theoretically shown to be equivalent to having separate denoising layers but without the computational overhead. Empirical results show significant improvements on various tasks, including re-identification, image classification, object detection, and segmentation, demonstrating DenoiseRep’s effectiveness and scalability across different model architectures (ResNet and Transformer).
Key Takeaways#
Why does it matter?#
This paper is important because it bridges the gap between generative and discriminative models by introducing a novel denoising model for representation learning. This opens new avenues for improving feature discrimination in various computer vision tasks, offering enhanced performance and efficiency. The label-free nature of the method is also a significant advantage, making it widely applicable and potentially transformative for various machine learning tasks.
Visual Insights#
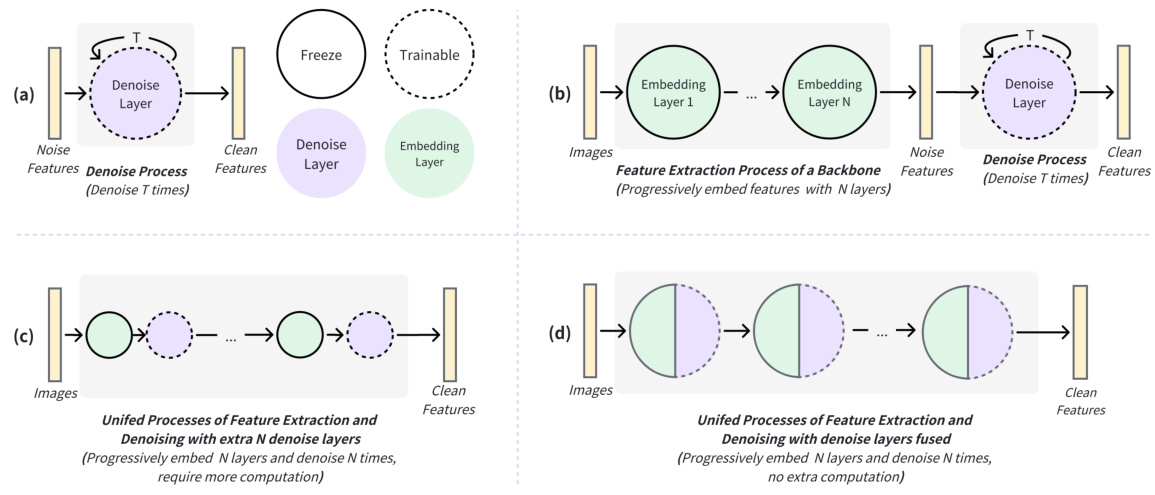
This figure illustrates the core idea of DenoiseRep. (a) shows a standard denoising model used in generative tasks. (b) demonstrates a naive approach of applying denoising to discriminative models, which introduces extra computational cost. (c) and (d) present the DenoiseRep approach, which integrates feature extraction and denoising within the backbone, making the features more discriminative without additional computational overhead. DenoiseRep merges the parameters of the denoising layers into the embedding layers.

This table presents the experimental results of the proposed DenoiseRep model on various discriminative vision tasks, including image classification, person re-identification, object detection, and image segmentation. For each task, it shows the model used (e.g., SwinT for classification, TransReID-SSL for person re-identification), the backbone network used for feature extraction, the dataset used for evaluation, the metric used for evaluating performance (e.g., accuracy for classification, mAP for person re-identification), the baseline performance of the model without DenoiseRep, and the improved performance achieved by incorporating DenoiseRep. The results demonstrate the effectiveness of DenoiseRep in improving feature discrimination across various vision tasks.
In-depth insights#
Denoising Diffusion#
Denoising diffusion models are a powerful class of generative models that synthesize data by reversing a diffusion process. The core idea is to gradually add noise to a data sample until it becomes pure noise, and then learn to reverse this process to generate new data samples. This approach is particularly effective because it avoids the mode collapse problem often encountered in other generative models. The training process involves learning a denoising network that predicts the noise added at each step of the diffusion process. The quality of generated samples hinges on the network’s ability to accurately estimate this noise, enabling the reconstruction of clean, high-fidelity data from its noisy counterpart. Applications span various domains, including image generation, audio synthesis, and even video creation, showing the versatility of this technique. While very effective, these models can be computationally expensive, and their training requires substantial computational resources and sophisticated optimization strategies. Furthermore, understanding the theoretical underpinnings of denoising diffusion remains an active area of research, continually refining and expanding the capabilities of this impressive methodology.
Discriminative Denoise#
The concept of “Discriminative Denoise” merges generative and discriminative model strengths. Generative models, like diffusion models, excel at noise generation and removal, a process leveraged here to enhance feature learning. The discriminative aspect focuses on improving the quality of features for classification or other downstream tasks. By viewing each layer of a neural network as a denoising step, features are progressively refined and improved. The novelty lies in the fusion of feature extraction and denoising parameters, thereby avoiding additional computational costs. The label-free nature of this approach makes it flexible and potentially applicable to numerous tasks, reducing reliance on large labeled datasets. While effective, potential limitations may include sensitivity to hyperparameter tuning and the need for strong backbone networks. Future work could explore optimal parameter fusion techniques and investigate applications beyond image recognition.
Feature Fusion#
The concept of feature fusion is crucial in many computer vision tasks, aiming to combine information from multiple feature maps to improve the overall representation. This paper’s approach cleverly unifies feature extraction and denoising within a backbone network. Instead of treating denoising as a separate process applied after feature extraction, it merges parameters from the trained denoising layers directly into the backbone’s embedding layers. This eliminates the computational overhead associated with additional denoising steps, thus achieving a more efficient and integrated process. The theoretical justification of this parameter fusion is a key strength, ensuring that the combined model’s behavior before and after fusion remains equivalent. By treating each embedding layer as a denoising layer, the model recursively refines feature representations, improving discriminative power. This innovative approach leverages the inherent denoising capabilities of diffusion models, enhancing the effectiveness of discriminative tasks without increasing inference time.
Unsupervised Learning#
The research paper explores the potential of denoising diffusion probabilistic models (DDPMs) in the realm of unsupervised representation learning. DDPMs are typically used in generative tasks, but this work leverages their denoising capabilities to improve feature discrimination in discriminative tasks. The core idea is to treat each embedding layer in a backbone network as a denoising layer, recursively processing features step-by-step. This approach effectively unifies feature extraction and denoising, theoretically resulting in a computation-free feature enhancement. The label-free nature of the method is a key advantage, as it doesn’t require labeled data during training. Experimental results on various discriminative vision tasks show consistent and significant improvements, demonstrating the effectiveness and scalability of this unsupervised learning approach. A key finding is that the method’s performance is further enhanced when combined with labeled data, suggesting a synergistic relationship between unsupervised pre-training and supervised fine-tuning.
Generalization Ability#
The research paper’s exploration of “Generalization Ability” is crucial, focusing on the model’s capacity to perform well on unseen data and diverse tasks. The label-free nature of the DenoiseRep method is a significant aspect of its generalization, enabling adaptability across various datasets without needing task-specific labels. Results across diverse tasks such as re-identification, classification, detection, and segmentation demonstrate the method’s wide applicability. Consistent improvement across different backbone architectures (ResNet and Transformer-based) highlights its robustness and generalizability, suggesting that it isn’t tied to a specific model architecture. However, further investigation into the effects of different noise levels and the method’s limitations on complex tasks with highly variable data would strengthen the understanding of its generalization capabilities and potential limitations.
More visual insights#
More on tables

This table compares the performance of the TransReID-SSL model with and without the DenoiseRep method under various conditions (label-free, label-augmented, and merged datasets). It demonstrates DenoiseRep’s effectiveness as a label-free method and its ability to be enhanced with label information.
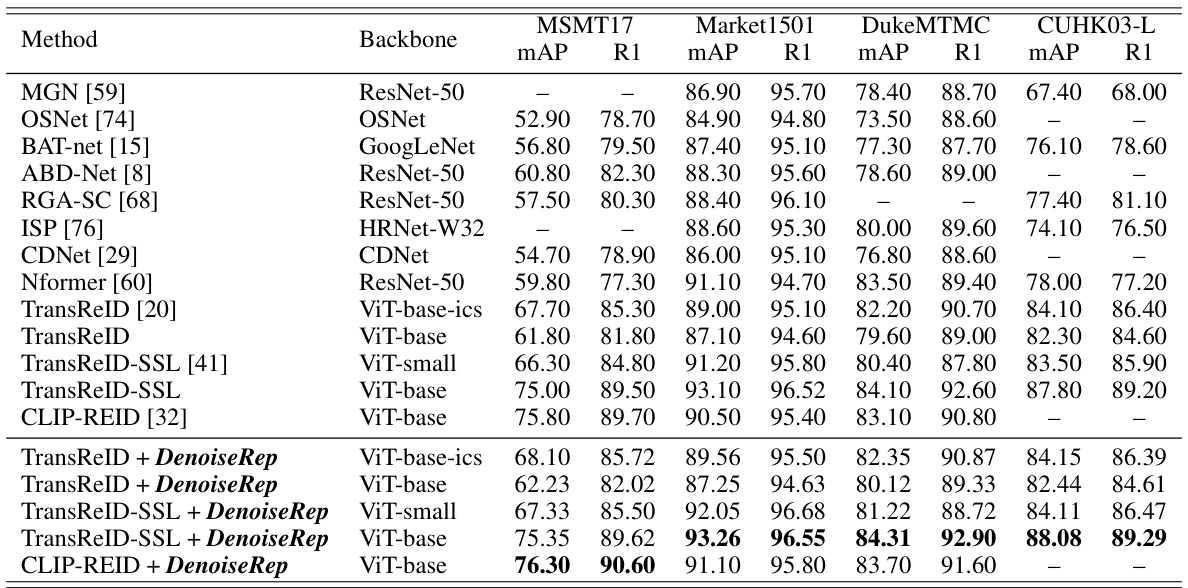
This table compares the proposed DenoiseRep method with several state-of-the-art ReID methods on four datasets (MSMT17, Market1501, DukeMTMC, and CUHK03-L). It shows the performance of different methods using various backbones (ResNet-50, OSNet, GoogLeNet, HRNet-W32, ViT-base-ics, ViT-base, ViT-small) in terms of mean Average Precision (mAP) and Rank-1 accuracy (R1). The table highlights the improvement achieved by integrating DenoiseRep with existing ReID methods, demonstrating its effectiveness in enhancing performance across different datasets and backbones.

This table compares the performance of three different methods on four person re-identification datasets. The first method is the baseline TransReID-SSL which uses a ViT-small backbone. The second method adds a denoising layer to the model that operates on the final layer, and the third method adds the same denoising layer to each layer of the model. The table shows that adding a denoising layer can improve performance, and adding it to every layer is better than adding it only to the final layer. The results are presented in terms of mean Average Precision (mAP) and inference time.
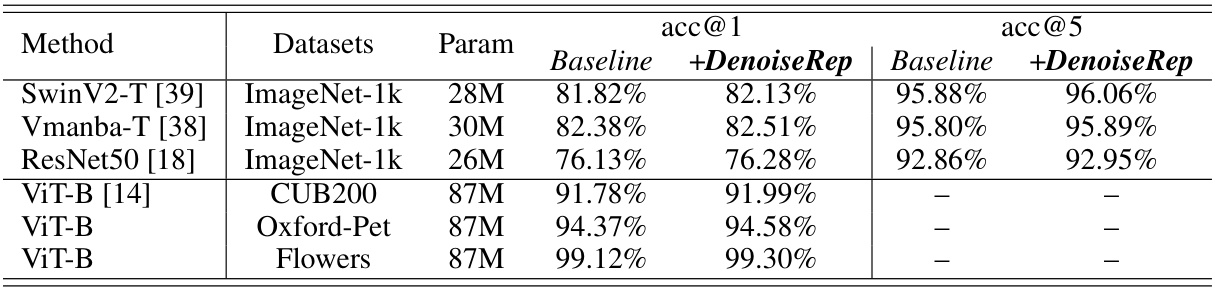
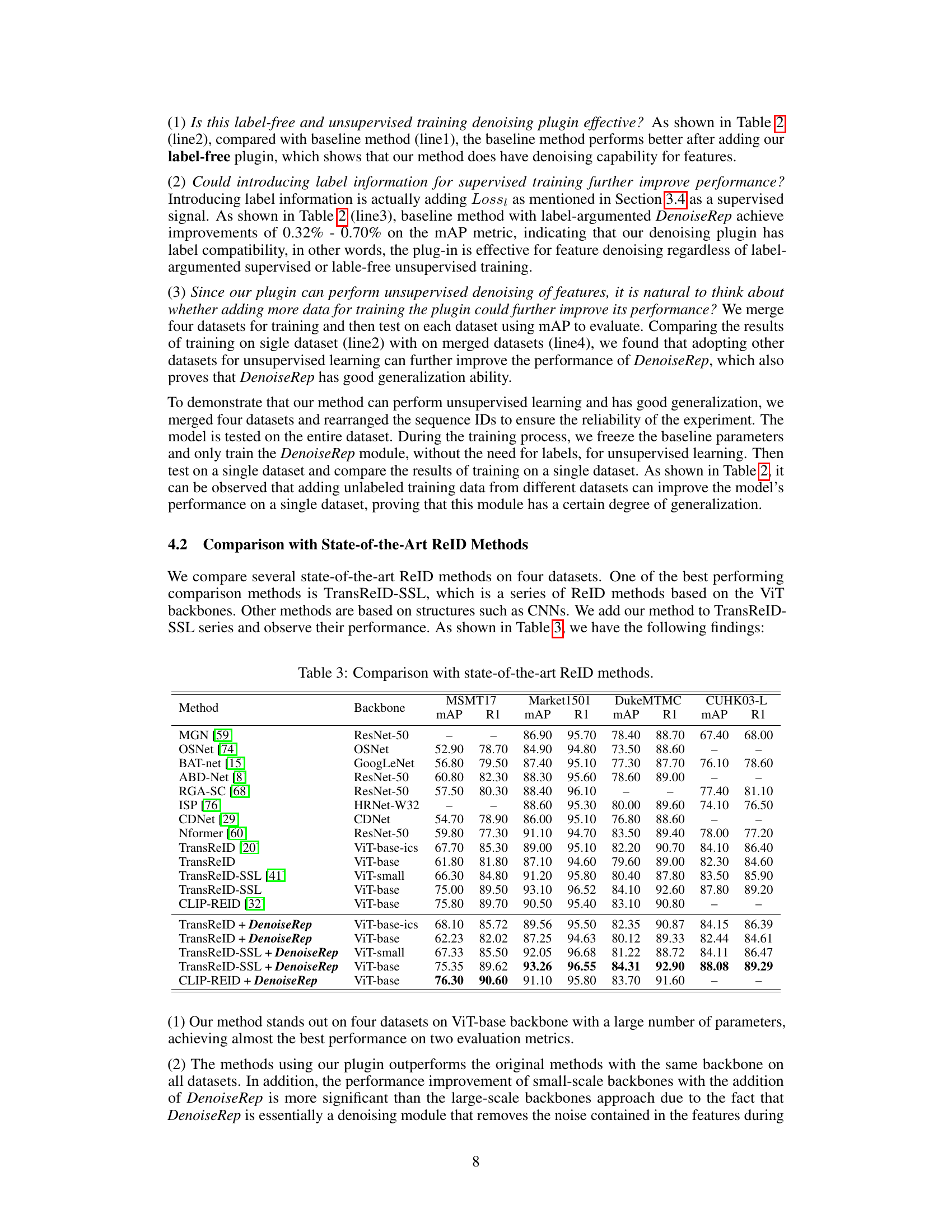
This table presents the results of image classification experiments using different models (SwinV2-T, Vmanba-T, ResNet50, ViT-B) on four datasets: ImageNet-1k, CUB200, Oxford-Pet, and Flowers. The ‘Baseline’ column shows the accuracy (acc@1 and acc@5) achieved by each model alone. The ‘+DenoiseRep’ column shows the improvement in accuracy achieved by adding the proposed DenoiseRep model. The table demonstrates the impact of DenoiseRep across various models and datasets, highlighting its effectiveness in improving classification performance.

This table presents the performance comparison of the baseline method (vehicle-ReID) and the proposed method (vehicle-ReID + DenoiseRep) on the vehicleID dataset. The results show improvement in both mAP and Rank-1 metrics after incorporating DenoiseRep, indicating enhanced performance in vehicle re-identification tasks, particularly in noisy environments.
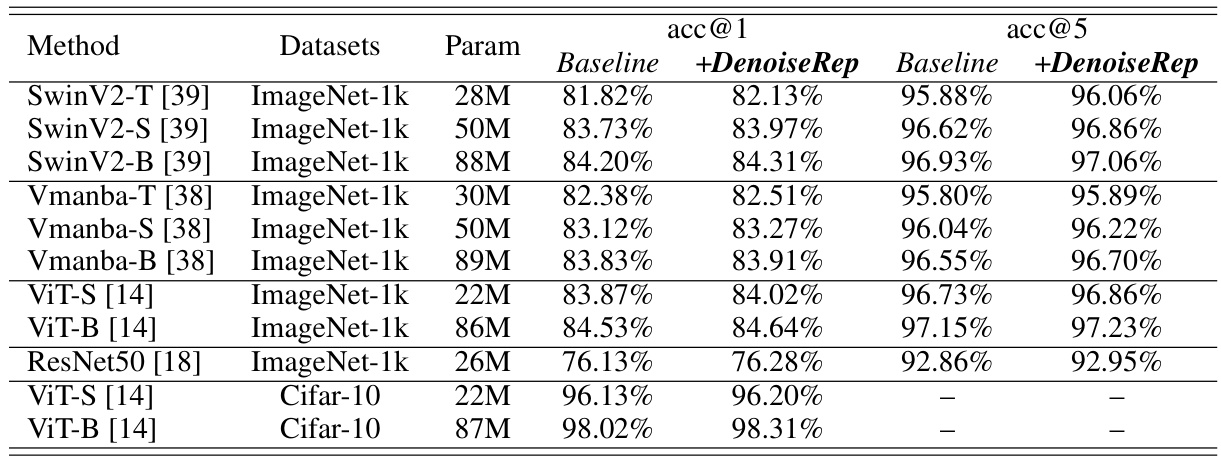
This table presents the results of image classification experiments using various models (SwinV2-T, SwinV2-S, SwinV2-B, Vmanba-T, Vmanba-S, Vmanba-B, ViT-S, ViT-B, ResNet50) on two datasets (Cifar-10 and ImageNet-1k). For each model and dataset combination, the table shows the number of parameters, the baseline accuracy (acc@1 and acc@5), and the accuracy after applying the proposed DenoiseRep method. The results demonstrate that DenoiseRep consistently improves the accuracy of image classification across different models and datasets.
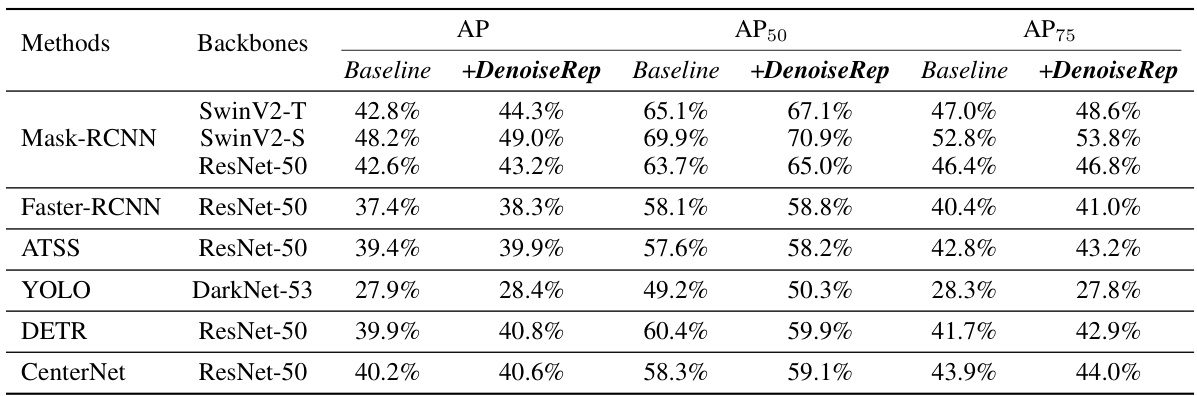
This table presents the experimental results of the proposed DenoiseRep model on various discriminative vision tasks, including re-identification, image classification, object detection, and image segmentation. It compares the performance of different models (SwinT, TransReID-SSL, Mask-RCNN, FCN) with and without the DenoiseRep method on various datasets. The results are shown in terms of metrics relevant to each task (e.g., accuracy for classification, mAP for detection, BIOU for segmentation). The table demonstrates the effectiveness of the DenoiseRep method across different tasks and datasets, showing consistent improvements.

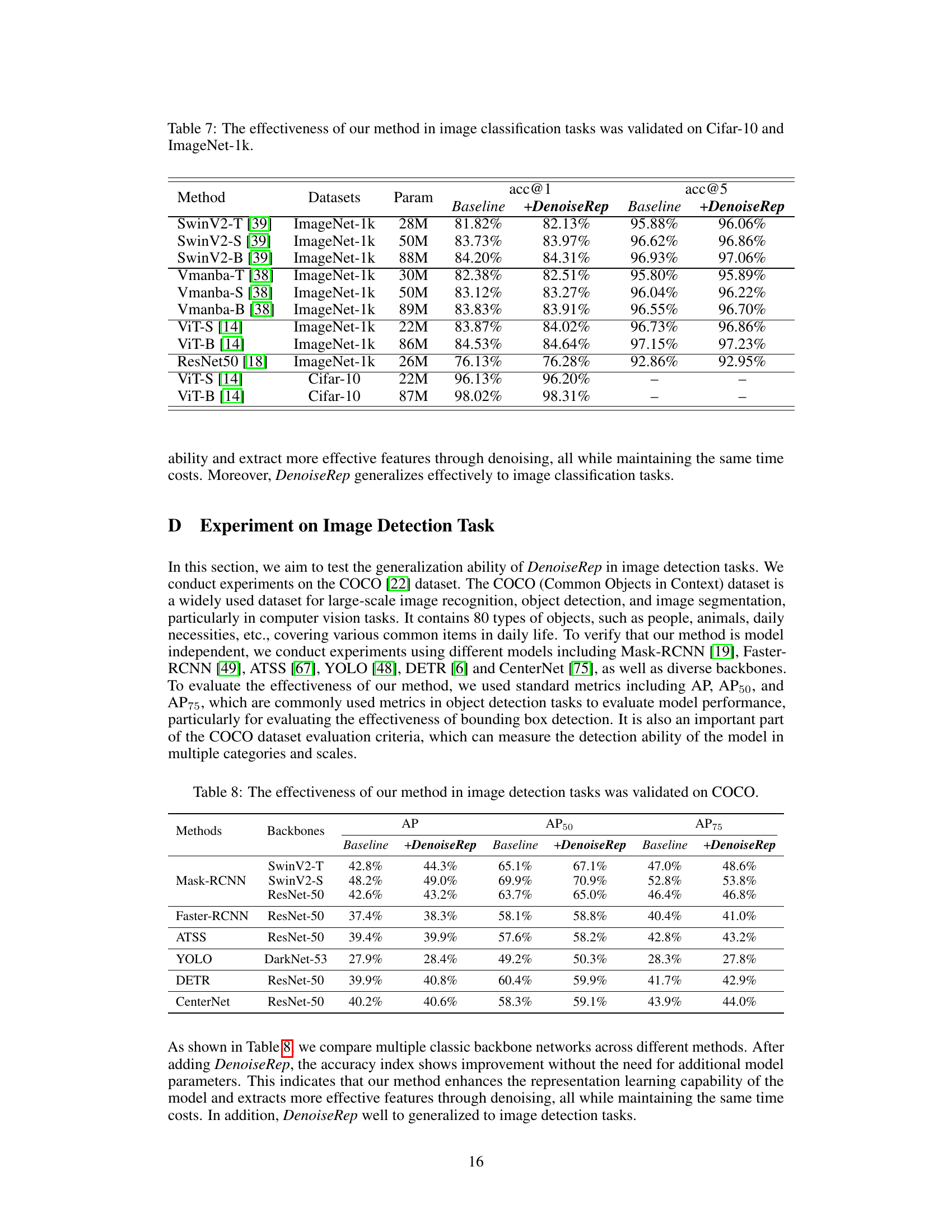
This table presents the results of image segmentation experiments using the ADE20K dataset. It compares different methods (FCN with ResNet-50 and ResNet-101 backbones, and SegFormer with mit_b0 and mit_b1 backbones) and shows the impact of adding the proposed DenoiseRep method. The evaluation metrics are mIoU (mean Intersection over Union), B-IoU (Boundary IoU), and aAcc (average accuracy). Higher values indicate better performance.
Full paper#