↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Federated learning (FL) faces challenges due to the heterogeneity of edge devices and the presence of domain shifts in local data. Existing FL methods struggle to maintain efficiency and accuracy under these conditions. Specifically, system heterogeneity leads to incomplete model updates from low-capability devices, while domain shifts cause performance degradation due to diverse local data distributions. These issues hinder the development of robust and efficient FL systems for edge computing.
DapperFL addresses these issues by employing a two-pronged approach: Model Fusion Pruning (MFP) generates personalized, compact local models, improving efficiency and robustness against domain shifts. Domain Adaptive Regularization (DAR) enhances the overall performance by encouraging robust cross-domain representations. Experimental results show DapperFL surpasses state-of-the-art methods in accuracy, showcasing its ability to effectively handle heterogeneity and domain shifts. The model size reduction achieved by MFP makes it particularly well-suited for edge devices.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles two major challenges in federated learning: system heterogeneity and domain shifts. It proposes a novel framework, DapperFL, which not only improves the overall performance of federated learning but also significantly reduces the model size, making it more suitable for resource-constrained edge devices. This opens up new avenues for research in efficient and robust federated learning, particularly for applications on edge devices.
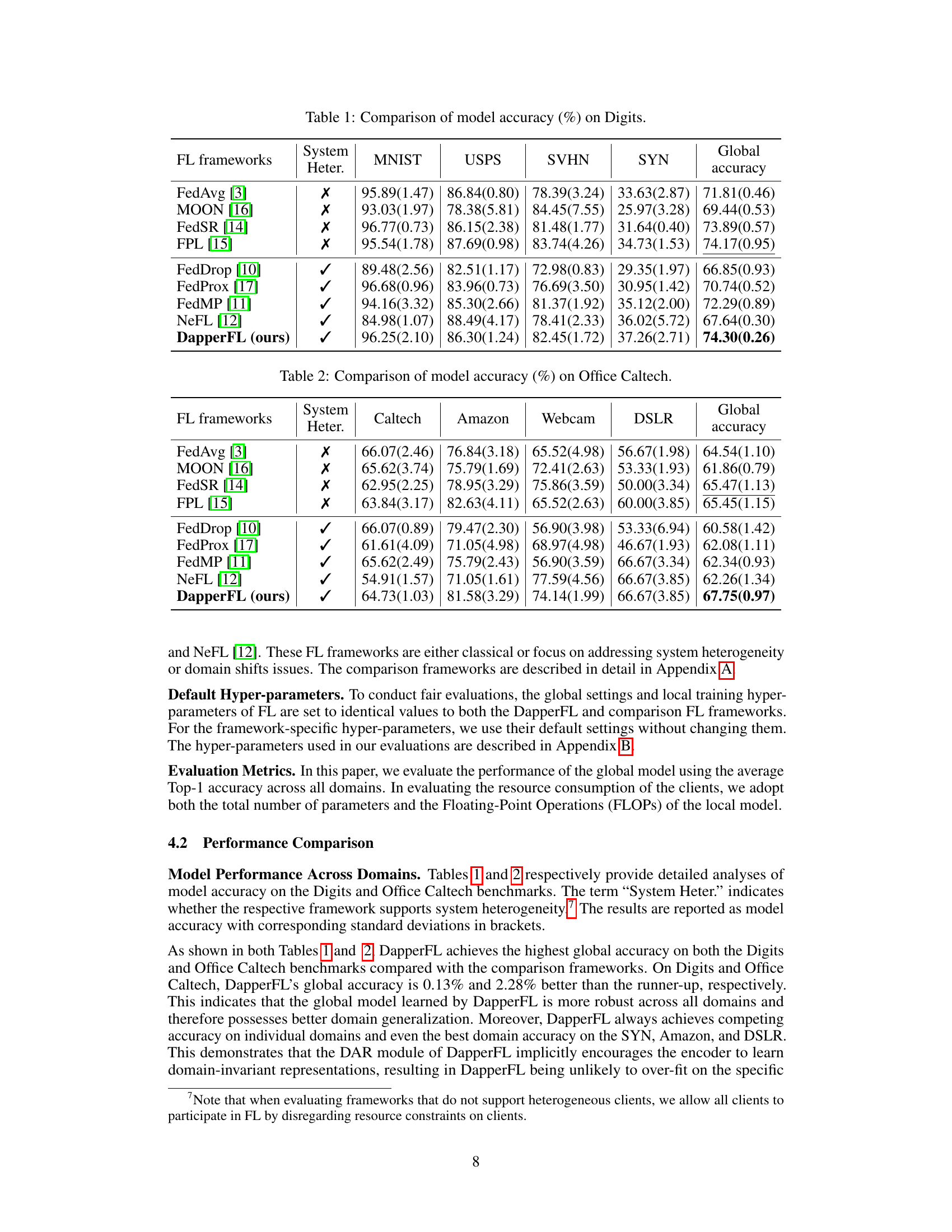
Visual Insights#
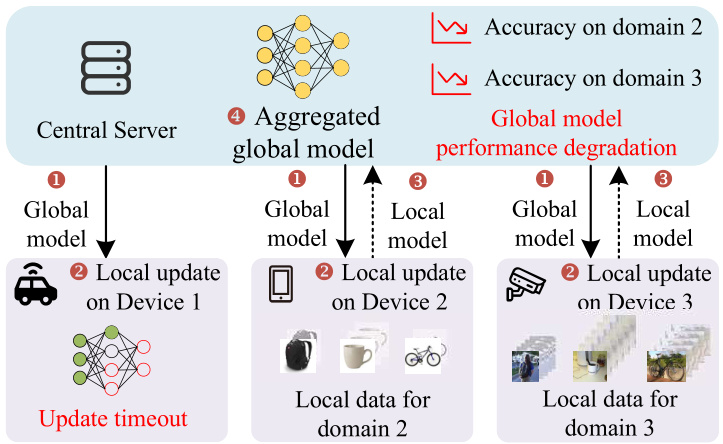
This figure illustrates a scenario in federated learning where three edge devices with varying capabilities and data distributions participate in training a global model. Device 1, due to resource constraints, fails to complete its local model update within the allotted time. Devices 2 and 3 collect data from different domains, resulting in non-IID (independent and identically distributed) data. This heterogeneity and the failure of Device 1 lead to performance degradation of the global model, highlighting the challenges addressed by the DapperFL framework.
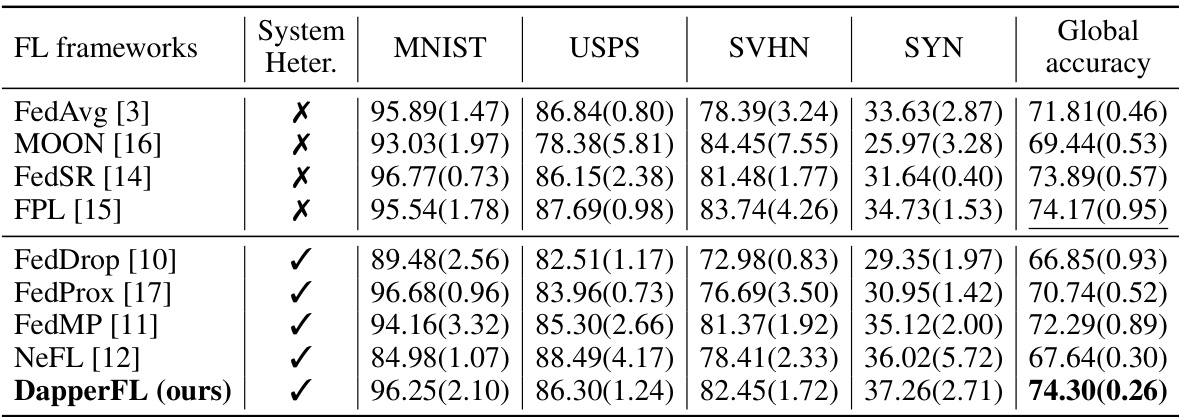
This table presents a comparison of model accuracy achieved by different federated learning (FL) frameworks on the Digits benchmark dataset. The frameworks are evaluated on four subsets of the dataset (MNIST, USPS, SVHN, SYN) and the overall global accuracy is also reported. The ‘System Heter.’ column indicates whether the framework specifically addresses system heterogeneity. The results demonstrate that DapperFL outperforms other state-of-the-art methods, particularly when considering system heterogeneity.
In-depth insights#
Adaptive FL#
Adaptive federated learning (FL) tackles the heterogeneity and dynamic nature of real-world FL deployments. Central to adaptive FL is the ability of the system to adjust its behavior based on the feedback received from participating clients. This might involve adapting model architectures, training parameters, or even the communication strategy to best suit the capabilities and data characteristics of individual clients. One key aspect of adaptive FL is addressing the problem of data heterogeneity, where clients contribute data from different distributions. Adaptive methods might employ techniques like personalized federated learning or domain adaptation to ensure fair and robust global model aggregation. Another important dimension is handling resource constraints, such as limited computational power or bandwidth. This may involve strategies like federated model compression, selective participation, or local model pruning. Furthermore, adaptive FL systems frequently incorporate mechanisms to maintain privacy, as the nature of FL involves numerous distributed entities. Differential privacy or homomorphic encryption are common choices, ensuring that clients’ private data remains protected throughout the entire training process. Ultimately, successful adaptive FL techniques significantly improve the robustness, efficiency, and security of FL systems, making them more suitable for widespread deployment in diverse edge computing environments.
Model Pruning#
Model pruning is a crucial technique in machine learning for creating more efficient and compact models. It involves removing less important parts of a neural network, such as neurons, connections, or filters, to reduce its size and complexity without significantly compromising performance. The primary benefits of model pruning include reduced computational cost, memory footprint, and faster inference times. This is particularly beneficial for deploying models on resource-constrained devices like smartphones and embedded systems. Different pruning strategies exist, each with trade-offs; unstructured pruning removes arbitrary connections, while structured pruning removes entire units (e.g., filters in convolutional layers). The choice of pruning strategy impacts model performance and efficiency. Post-pruning techniques, such as fine-tuning or retraining, are essential to recover performance lost due to pruning. The effectiveness of model pruning often depends on the architecture of the model, the dataset used for training, and the pruning strategy employed. Furthermore, researchers are exploring automated pruning techniques, which leverage optimization algorithms to identify the least important components for removal. This automation aims to streamline the pruning process and achieve better performance gains. Model pruning is a powerful tool for optimizing model efficiency but requires careful consideration of its impact on model accuracy and the resources available.
Heterogeneous FL#
Heterogeneous Federated Learning (FL) tackles the challenges of diversity in edge computing environments. Unlike homogeneous FL, which assumes uniform client capabilities and data distributions, heterogeneous FL acknowledges the wide range of hardware, software, and data characteristics found in real-world deployments. This heterogeneity manifests in several ways, including varied computational resources, different data distributions, and discrepancies in network connectivity. Addressing these differences is crucial for ensuring FL’s effectiveness and robustness. Strategies for handling heterogeneity often involve model compression or sparsification to accommodate resource-constrained clients, and adaptive training algorithms that account for non-IID data across devices. Furthermore, specialized aggregation techniques are necessary to synthesize model updates from diverse architectures and data sources. The goal is to develop algorithms that fairly include all participants, promoting efficiency and ensuring accuracy without compromising data privacy or violating resource constraints. Research in this area is actively exploring methods for robust model aggregation, personalized model compression, and efficient communication protocols that directly address the unique challenges of heterogeneous FL deployments.
Domain Generalization#
Domain generalization (DG) in machine learning focuses on building models that generalize well to unseen domains, a crucial challenge given the inherent variability of real-world data. The core issue is that training data often doesn’t perfectly represent the distribution of data encountered in real-world applications. Traditional approaches fail because they overfit to the training domain. DG aims to address this by learning domain-invariant features or representations that are robust to domain shifts. Effective DG methods leverage techniques like data augmentation, adversarial training, and meta-learning to improve generalization ability. The research area is continually evolving, with a focus on understanding the underlying causes of domain shift, and developing more effective algorithms to tackle this challenge. Furthermore, the integration of DG techniques into federated learning presents a particularly interesting and promising area of exploration, addressing the non-IID nature of distributed datasets. This combination can lead to more robust and practical applications, particularly in edge computing scenarios where data heterogeneity is a prevalent issue.
Future Works#
Future research directions stemming from this DapperFL framework could involve several key areas. Automating hyperparameter selection is crucial, as the current manual tuning of α₀, αmin, ε, and γ limits ease of use and generalizability. Investigating alternative pruning strategies beyond the l₁ norm, perhaps exploring techniques that consider hardware constraints more directly, would enhance efficiency. Expanding the framework’s applicability to encompass a broader range of model architectures and datasets is vital. Further research should focus on developing more sophisticated mechanisms to address non-IID data distributions and heterogeneous client capabilities in even more robust ways. The impact of different aggregation strategies on model performance and generalization across domains also warrants further study. Finally, a deeper exploration into the theoretical underpinnings of the model fusion and domain adaptive regularization techniques, potentially through rigorous mathematical analysis, could provide valuable insights and inform future improvements.
More visual insights#
More on figures
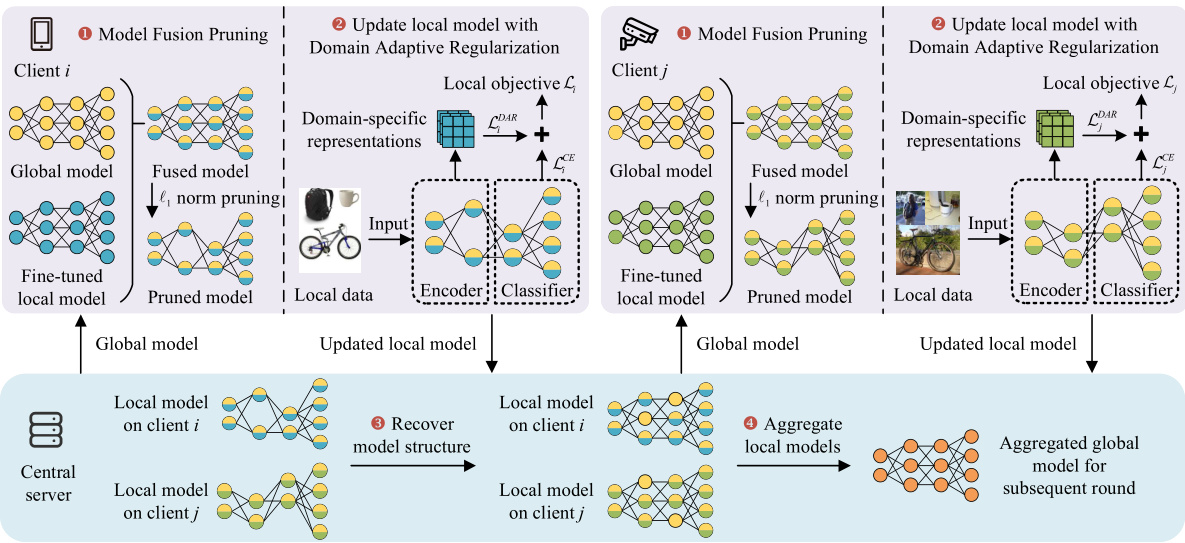
This figure illustrates the workflow of the DapperFL framework during a single communication round. It shows how two clients (Client i and Client j) process their local data, and how the central server aggregates their updated models. The process involves several steps: 1) Model Fusion Pruning (MFP) is used to generate personalized, compact local models. 2) Domain Adaptive Regularization (DAR) is used to further improve model performance. 3) A specific aggregation algorithm is used to aggregate heterogeneous local models. The steps are shown in a diagrammatic format, where each step is represented with its own box. The figure provides a high-level overview of the process and helps to understand how the framework works.
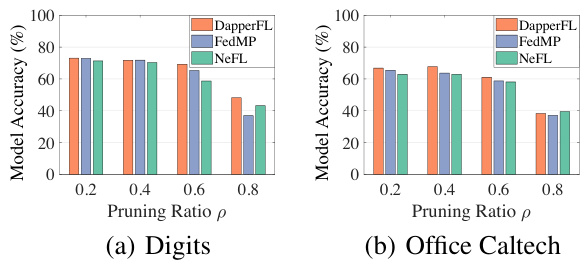
This figure compares the performance of three federated learning frameworks (DapperFL, FedMP, and NeFL) across different pruning ratios on two benchmark datasets (Digits and Office Caltech). It shows how model accuracy varies as the pruning ratio (the amount of model compression) increases. This helps to understand the trade-off between model efficiency and accuracy for each method. DapperFL consistently outperforms others.
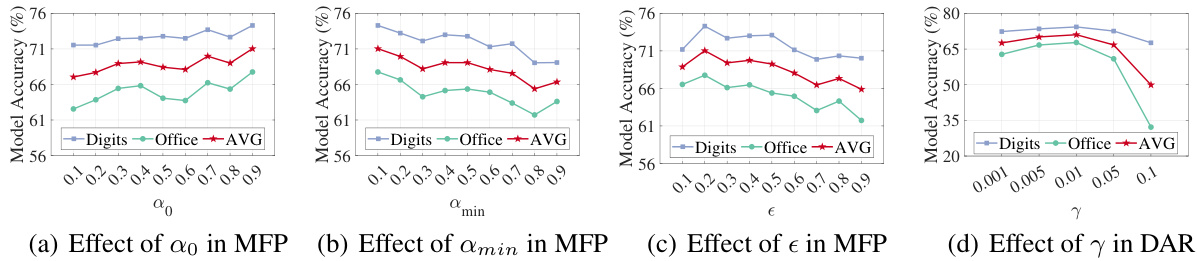
This figure shows the impact of four hyperparameters on model accuracy in the proposed DapperFL framework. The hyperparameters, α₀, αₘᵢₙ, ε, and γ, are part of the Model Fusion Pruning (MFP) and Domain Adaptive Regularization (DAR) modules. The plots display the model accuracy on the Digits and Office-Caltech benchmark datasets, as well as the average accuracy across both datasets. The goal is to demonstrate the optimal values for each hyperparameter to maximize model performance.
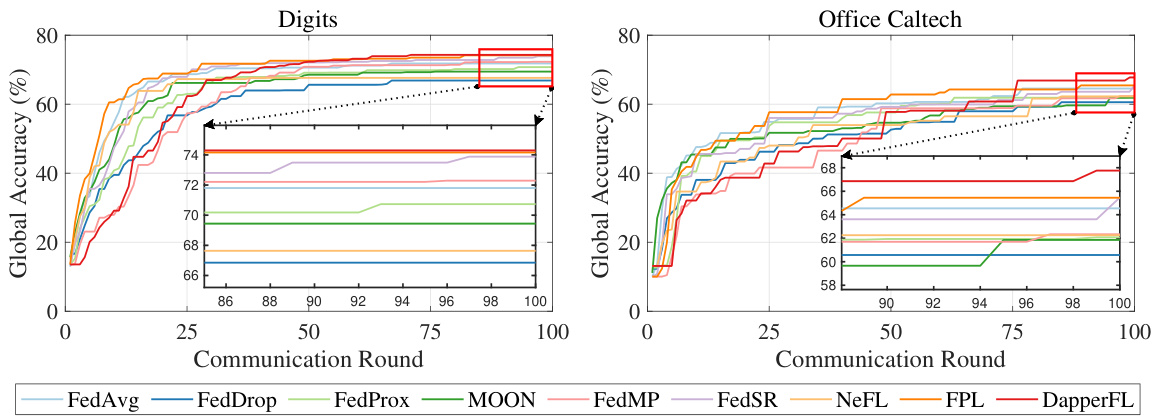
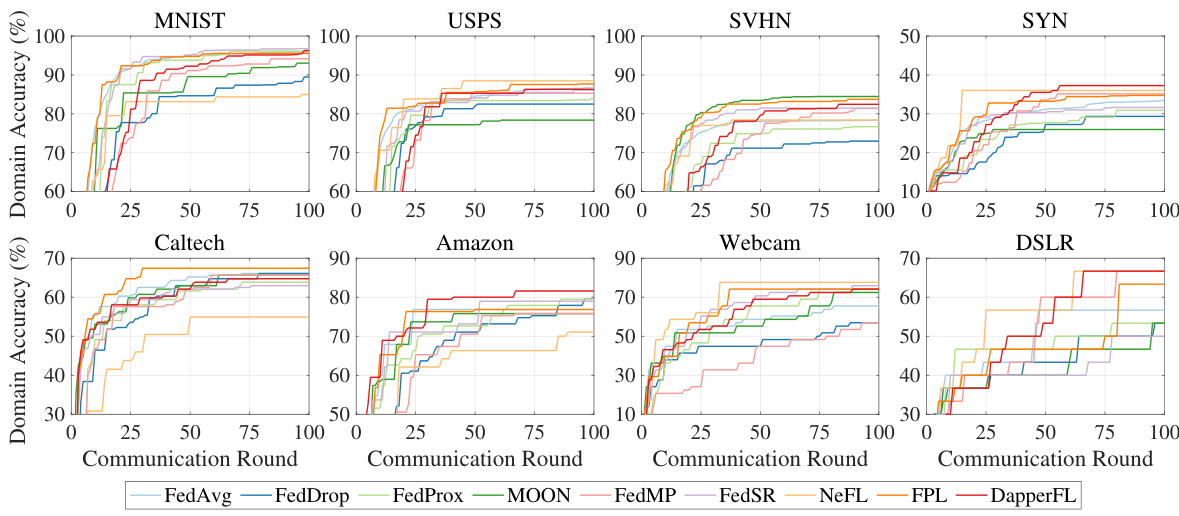
This figure shows the learning curves for global accuracy across different communication rounds for nine Federated Learning (FL) frameworks, including DapperFL, on two benchmark datasets (Digits and Office Caltech). The curves illustrate how the global model accuracy improves as the FL training progresses. The comparison allows for evaluating the performance of DapperFL against state-of-the-art approaches.
This figure illustrates the workflow of the DapperFL framework during a single communication round. It involves two clients, each performing Model Fusion Pruning (MFP) and Domain Adaptive Regularization (DAR) on their local models. The MFP module generates personalized compact local models using both local and global knowledge. The DAR module improves the performance of pruned models. The figure visually shows the steps of MFP, DAR, and aggregation on the server. The central server then aggregates the updated local models to produce a new global model for the next round. The figure details the process of model fusion, pruning, aggregation and the interaction between the clients and the server.
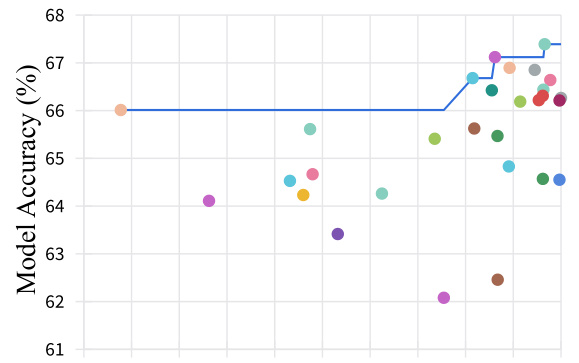
This figure compares the performance of three federated learning (FL) frameworks – FedMP, NeFL, and DapperFL – across different pruning ratios on two benchmark datasets (Digits and Office Caltech). The x-axis represents the pruning ratio (the proportion of model parameters removed). The y-axis shows the model accuracy. The figure visually demonstrates how the model accuracy changes as model size is reduced, showing DapperFL’s superior performance and robustness to model compression.
More on tables
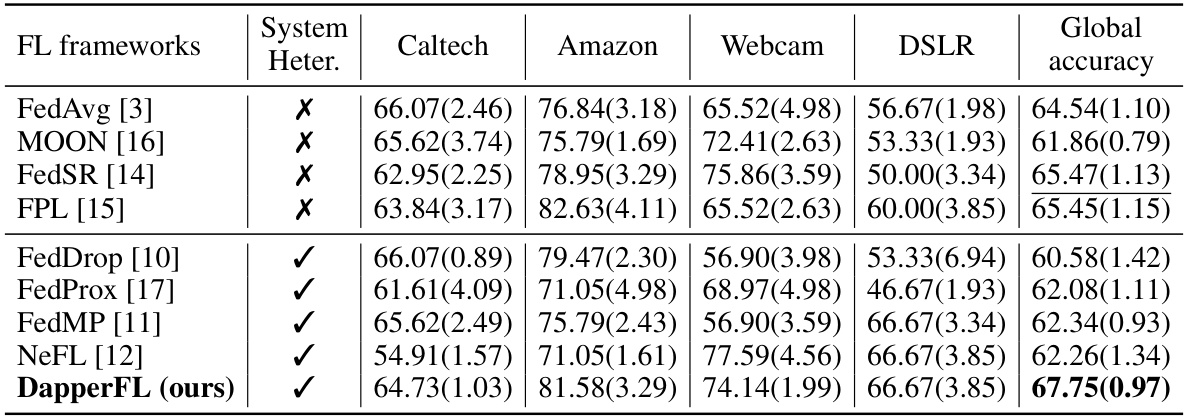
This table presents a comparison of model accuracy achieved by different federated learning (FL) frameworks on the Office Caltech benchmark dataset. The frameworks are evaluated across four domains within Office Caltech (Caltech, Amazon, Webcam, DSLR), and their overall global accuracy is reported. The ‘System Heter.’ column indicates whether each framework supports heterogeneous systems, highlighting the performance differences in handling diverse client capabilities.
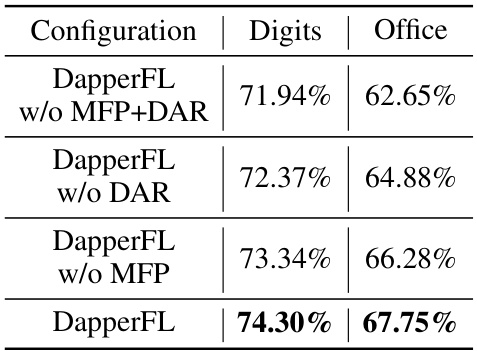
This table presents the ablation study results, showing the impact of the key modules (MFP and DAR) of DapperFL on model accuracy. It compares the performance of DapperFL with and without the MFP and DAR modules on two benchmark datasets (Digits and Office Caltech), demonstrating their individual and combined contributions to model accuracy.
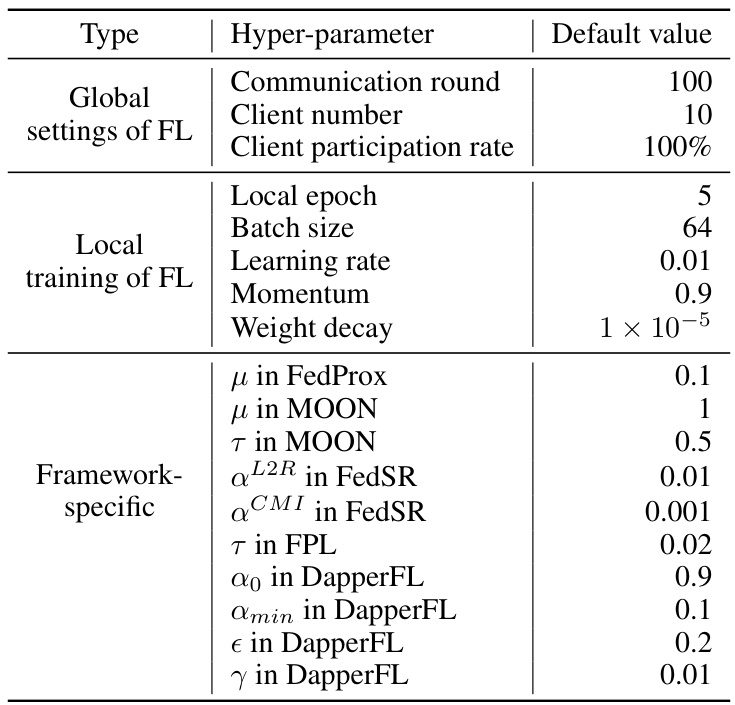
This table lists the default hyperparameter values used in the experiments for all the compared federated learning frameworks, including DapperFL. It shows the settings for global and local training parameters, along with framework-specific parameters. These values were kept consistent across all frameworks for fair comparison.

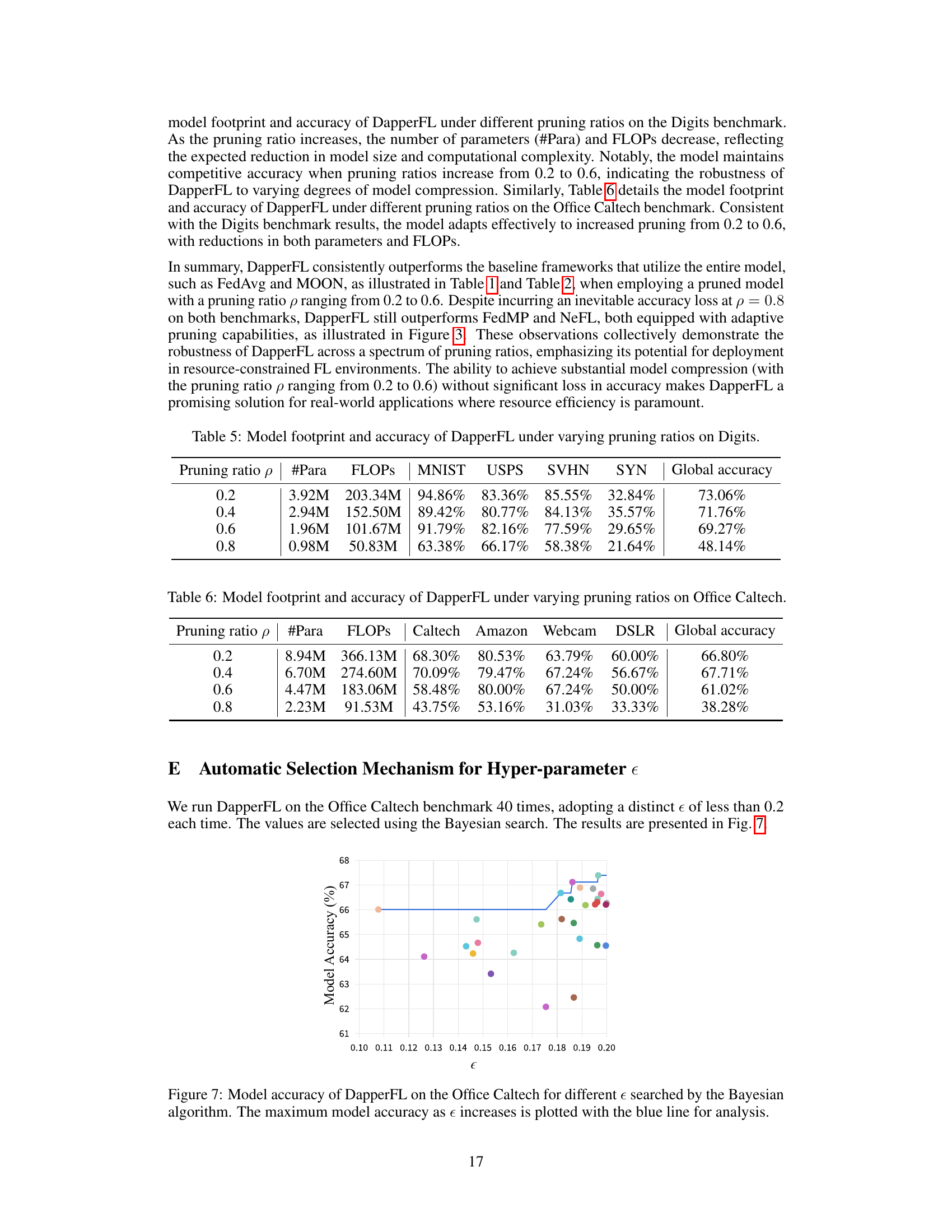
This table presents the model footprint (number of parameters and FLOPs) and accuracy of the DapperFL model on the Digits benchmark dataset for different pruning ratios (p). The pruning ratio controls the level of model compression; higher ratios lead to smaller models but may affect accuracy. The table shows the performance across different sub-datasets within Digits (MNIST, USPS, SVHN, SYN) and the overall global accuracy.

This table shows the impact of different pruning ratios on the model size (number of parameters and FLOPs) and accuracy of the DapperFL model when evaluated on the Office Caltech dataset. It demonstrates how the model’s performance changes as different levels of compression are applied. Note that accuracy decreases as pruning ratio increases, but also the model footprint significantly reduces.
Full paper#