↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Traditional 3D referring expression segmentation methods struggle with over-segmentation and mis-segmentation due to insufficient focus on spatial relationships between objects. This paper introduces RG-SAN, a novel approach that uses spatial information of the target object for supervision, thereby significantly improving the model’s ability to understand spatial context within referring expressions.
RG-SAN consists of a Text-driven Localization Module (TLM) for initial object localization and refinement and a Rule-guided Weak Supervision (RWS) strategy. RWS leverages dependency tree rules to improve the positioning of core instances. Extensive testing on the ScanRefer benchmark demonstrates RG-SAN’s superior performance, setting new benchmarks and showcasing impressive robustness in handling spatial ambiguities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D computer vision and natural language processing as it significantly advances the field of 3D referring expression segmentation. Its novel approach using only spatial information of the target object for supervision, combined with rule-guided weak supervision, improves accuracy and robustness, pushing the boundaries of existing methods. The improved methodology and performance benchmarks provide a strong foundation for future research, opening doors for better human-computer interaction and autonomous systems. The open-source code further enhances its accessibility and impact on the research community.
Visual Insights#
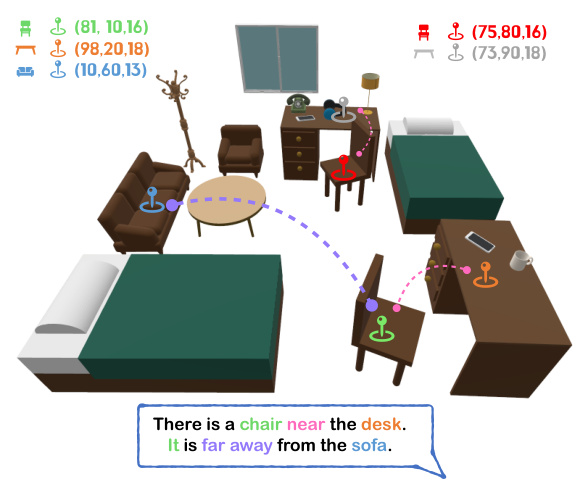
This figure illustrates a scene with a target object (a chair) and several other objects (a desk and a sofa). The caption highlights the difficulty of accurately segmenting the target chair using only textual information, specifically when the description involves relative spatial relationships (like ’near’ and ‘far away’). This scenario demonstrates the need for a model to understand and utilize spatial relationships between objects to perform accurate 3D referring expression segmentation.
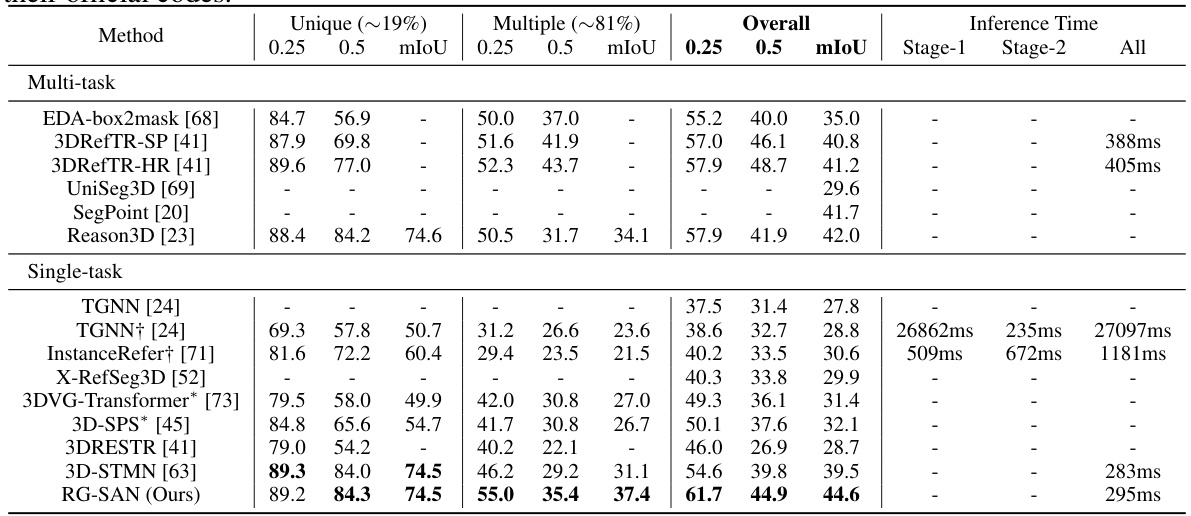
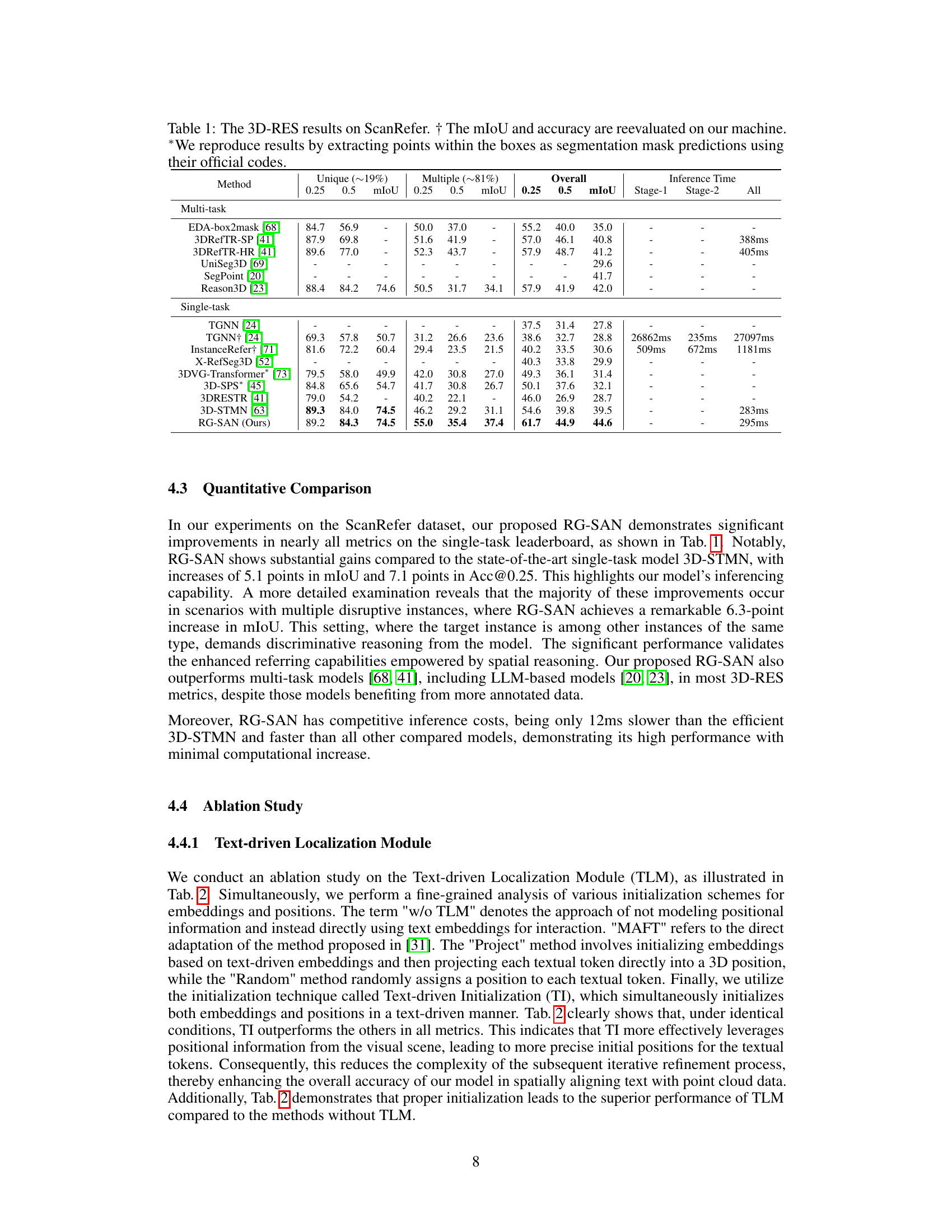
This table presents a comparison of different methods for 3D Referring Expression Segmentation (3D-RES) on the ScanRefer benchmark dataset. It shows the performance of each method in terms of mean Intersection over Union (mIoU) at different thresholds (0.25 and 0.5) for both unique and multiple instances. Inference time is also reported, broken down by stage and overall. The † symbol indicates results were re-evaluated by the authors, while * indicates results reproduced using the methods’ original code.
In-depth insights#
Spatial Awareness#
The concept of spatial awareness in 3D referring expression segmentation (3D-RES) is crucial for accurately interpreting referring expressions that contain spatial relationships. Traditional methods often fall short, relying heavily on textual reasoning alone, and struggle to disambiguate descriptions involving complex spatial terms or multiple objects. This paper highlights the importance of explicitly modeling spatial relationships using spatial information of instances for improved performance, which enables the network to effectively depict spatial relationships among all entities mentioned in the text, enhancing the reasoning capabilities and robustness. By leveraging solely the spatial information of the target instance for supervision, the model learns to accurately infer and use the positions of all entities to resolve spatial ambiguities. The network’s capability to interpret spatial relationships using only the target object’s position significantly improves the 3D-RES task’s overall accuracy. Rule-based supervision further assists in accurately identifying and processing instances, especially in ambiguous descriptions, significantly enhancing robustness and performance.
Rule-Guided Weak Supervision#
The heading ‘Rule-Guided Weak Supervision’ suggests a novel training approach that cleverly addresses the scarcity of labeled data in 3D referring expression segmentation. Instead of relying on fully labeled data for all entities in a scene, this method leverages spatial relationships and linguistic rules to guide the learning process. The key insight is to use the labeled position of the target object (the object explicitly referred to in the textual description) as a supervisory signal, while inferring the positions of other mentioned entities using contextual clues and rules extracted from a dependency parse tree. This effectively transforms a weakly supervised problem (where only the target is labeled) into a more informative learning task by incorporating spatial relationships and structural knowledge from the language. This strategy enhances the model’s ability to reason about the spatial layout of a scene, improving accuracy and robustness, especially when dealing with ambiguous descriptions. The clever use of rules and weak supervision is crucial for the successful training of a model that understands and segments complex 3D scenes based on natural language instructions.
TLM & RWS#
The core of the proposed approach lies in the synergistic interplay of two key modules: the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS) strategy. TLM iteratively refines the localization of all entities mentioned in the text, starting with an initial prediction based on feature similarity between textual and visual modalities. This iterative refinement process uses relative and absolute positional encodings to ensure continuous improvement in localization accuracy. RWS leverages dependency tree rules to guide the positioning of core instances, acknowledging that only the target object has supervised positional information. This clever use of weak supervision allows the model to accurately depict spatial relationships among all entities described in the text, even when processing descriptions with inherent spatial ambiguity. The combined effect of TLM and RWS results in a significant enhancement of the model’s ability to understand and segment the target object precisely within complex 3D scenes, as demonstrated by substantial improvements in mIoU and robustness on benchmark datasets.
Ablation Studies#
Ablation studies systematically remove components of a model to understand their individual contributions. In this context, an ablation study would likely involve removing or deactivating parts of the proposed model (e.g., the Text-driven Localization Module or the Rule-guided Weak Supervision strategy) and then evaluating the performance on a benchmark dataset like ScanRefer. The results would reveal the importance of each component, highlighting which parts are crucial for achieving high accuracy and robustness, and which are less essential or even detrimental. A well-designed ablation study shows not only what works but also why it works, providing crucial insights into the model’s inner workings and justifying design choices. Moreover, by comparing performance across variations, the researchers can demonstrate the synergy or independence of different components, potentially revealing opportunities for further optimization or simplification. The analysis may also reveal unexpected interactions, highlighting areas needing further investigation. Such studies are essential to establish a thorough understanding of the model’s capabilities and limitations.
Future Directions#
Future research directions for 3D referring expression segmentation (3D-RES) could explore several promising avenues. Improving robustness to noisy or incomplete point cloud data is crucial, as current methods struggle with damaged or missing information. Addressing this might involve incorporating advanced data augmentation techniques, exploring more robust feature extraction methods, or developing models that explicitly handle uncertainty. Extending the capabilities to handle more complex scenes and longer, more ambiguous descriptions would significantly enhance real-world applicability. This would require improving the model’s ability to reason about complex spatial relationships and handle subtle linguistic nuances. Furthermore, research could focus on developing more efficient models suitable for resource-constrained environments such as mobile robots. This might involve exploring model compression techniques or developing more efficient architectures. Finally, investigating the potential for incorporating large language models (LLMs) for improved semantic understanding and reasoning in 3D-RES is highly promising. This could lead to models capable of handling highly complex queries and generating more nuanced descriptions of the target object.
More visual insights#
More on figures
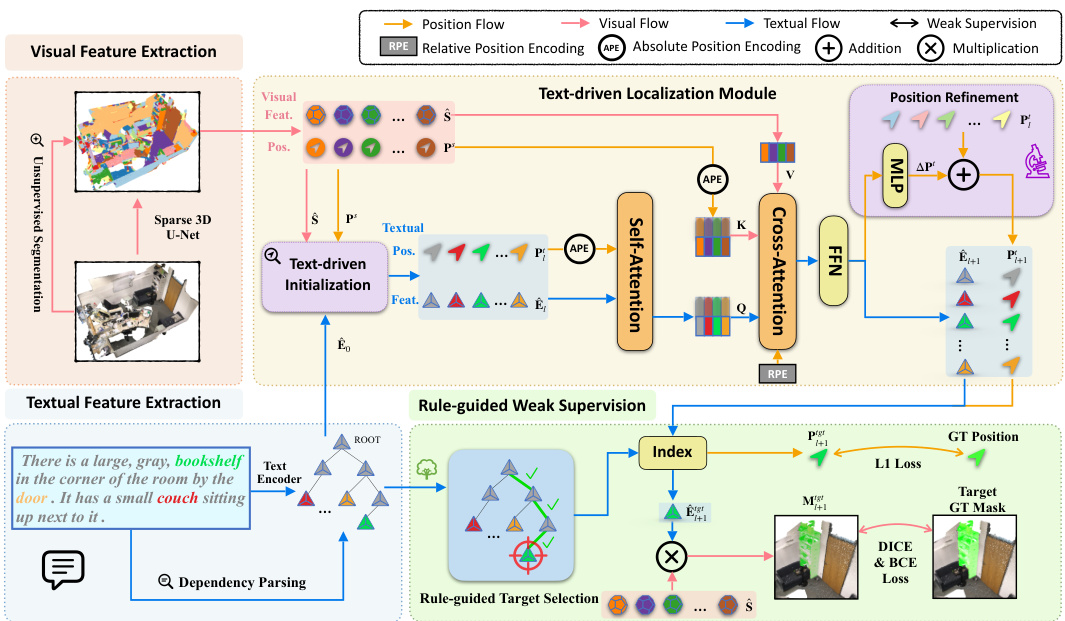
This figure illustrates the architecture of the Rule-Guided Spatial Awareness Network (RG-SAN) for 3D Referring Expression Segmentation. It shows the two main components: the Text-driven Localization Module (TLM) and the Rule-guided Weak Supervision (RWS). The TLM processes both point cloud and text features to iteratively refine the spatial positions of all entities mentioned in the text. The RWS leverages dependency tree rules and the target object’s location to guide the network’s learning, using only the target’s position for supervision. This allows for accurate spatial relationship modeling among all entities. The figure also details the feature extraction, multimodal fusion, position refinement, and loss functions used in the model training process.

The figure showcases the qualitative results of RG-SAN and 3D-STMN on the ScanRefer validation set. It illustrates RG-SAN’s ability to accurately segment multiple instances mentioned in the textual descriptions, unlike 3D-STMN which assigns all nouns to a single target object. This highlights RG-SAN’s enhanced referring capability by precisely segmenting distinct entities, demonstrating its robust generalization for complex texts and precise localization for multiple entities.
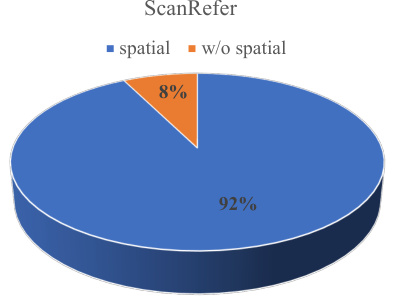
This figure shows a pie chart illustrating the distribution of samples in the ScanRefer dataset based on whether their descriptions include spatial relations. The vast majority (92%) of the descriptions contain spatial terms, highlighting the significance of spatial reasoning in this 3D object localization task. Only a small fraction (8%) of the samples lack spatial descriptions.

This figure presents a detailed architecture overview of the proposed RG-SAN model. The model processes both point cloud data and textual descriptions, extracting relevant features from each modality. It employs a Text-driven Localization Module (TLM) to iteratively refine the spatial positions of all entities mentioned in the text. The Rule-Guided Weak Supervision (RWS) strategy leverages the target object’s position to implicitly supervise the positioning of all entities, including auxiliary objects. This enhances the model’s ability to accurately capture and reason about spatial relationships between entities.

This figure visualizes the results of both RG-SAN and 3D-STMN on a sample from the ScanRefer dataset. The image shows the original scene, ground truth segmentation, and the segmentation results from each model. RG-SAN successfully segments multiple instances corresponding to the nouns mentioned in the referring expression. In contrast, 3D-STMN fails to discriminate between instances, assigning all mentioned objects to a single target.
More on tables
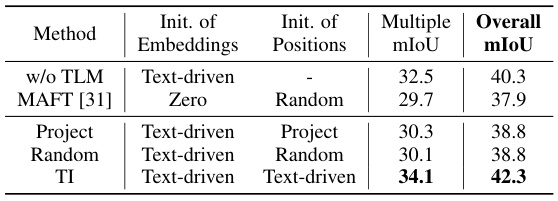
This table presents the ablation study results focusing on the impact of the Text-driven Localization Module (TLM). It compares the performance of the model with and without TLM, and also with different initialization methods for embeddings and positions (Zero, Random, Project, and Text-driven). The results show significant improvements in both Multiple and Overall mIoU metrics with the inclusion of TLM and using Text-driven initialization for both embeddings and positions.
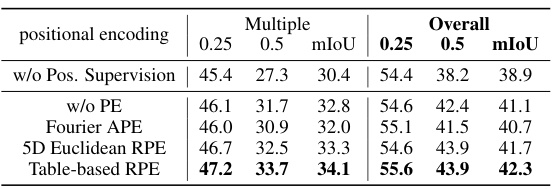
This table presents the ablation study results for positional encoding methods in the RG-SAN model. It compares the performance of the model with no positional supervision, no positional encoding (w/o PE), Fourier Absolute Positional Encoding (APE), 5D Euclidean Relative Positional Encoding (RPE), and Table-based RPE. The results are presented in terms of Multiple and Overall mIoU scores at 0.25 and 0.5 IoU thresholds. It shows the impact of different positional encoding techniques on the model’s accuracy for both unique and multiple instances.
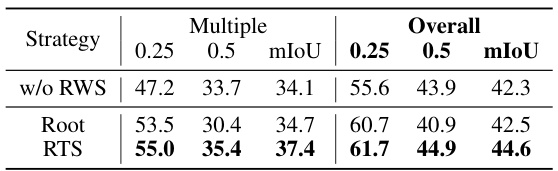
This table presents the ablation study on the weak supervision strategy used in the Rule-guided Weak Supervision (RWS) module of the proposed RG-SAN model. It compares three different strategies: (1) ‘w/o RWS’, which uses the attention-based Top1 approach from a previous work; (2) ‘Root’, which selects the root token of the dependency tree; and (3) ‘RTS’, which is the proposed rule-guided target selection strategy. The results are shown in terms of mean Intersection over Union (mIoU) at thresholds of 0.25 and 0.5, for both ‘Multiple’ and ‘Overall’ scenarios. The ‘Multiple’ scenario represents cases with at least one other object of the same class as the target object, while the ‘Overall’ scenario encompasses all cases.
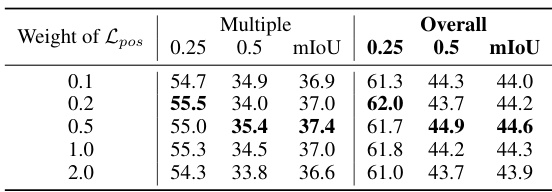
This table presents the ablation study results on the impact of varying the weight of the position loss (Lpos) on the model’s performance. The results are broken down by the ‘Multiple’ and ‘Overall’ categories, with mIoU scores reported at 0.25 and 0.5 thresholds. It shows how different weights affect the model’s ability to accurately predict instance positions, particularly focusing on scenarios with multiple instances of the same class and overall performance.
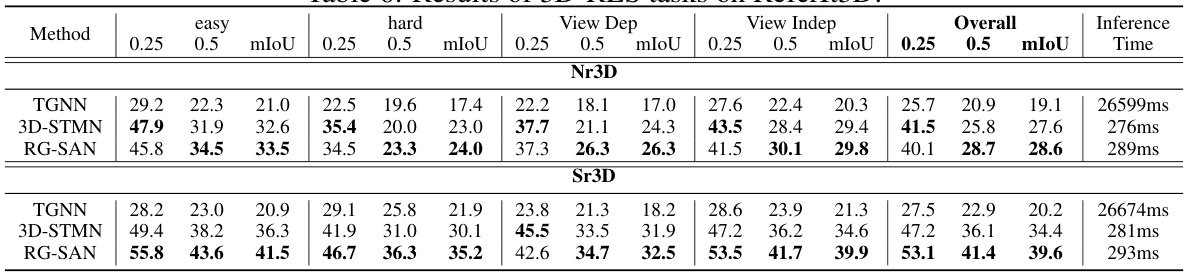
This table presents the quantitative results of various 3D Referring Expression Segmentation (3D-RES) methods on the ScanRefer benchmark dataset. It shows the mean Intersection over Union (mIoU) and accuracy at different thresholds (0.25 and 0.5) for both unique and multiple instances. The table also includes inference time for each method, providing a performance comparison across various approaches. The results are categorized by whether the approach uses a single-stage or multi-stage paradigm and also notes when the mIoU and accuracy are recalculated on the authors’ machine or reproduced using the original code.
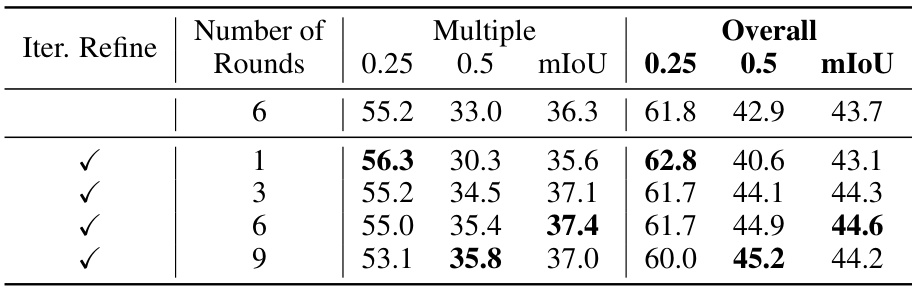
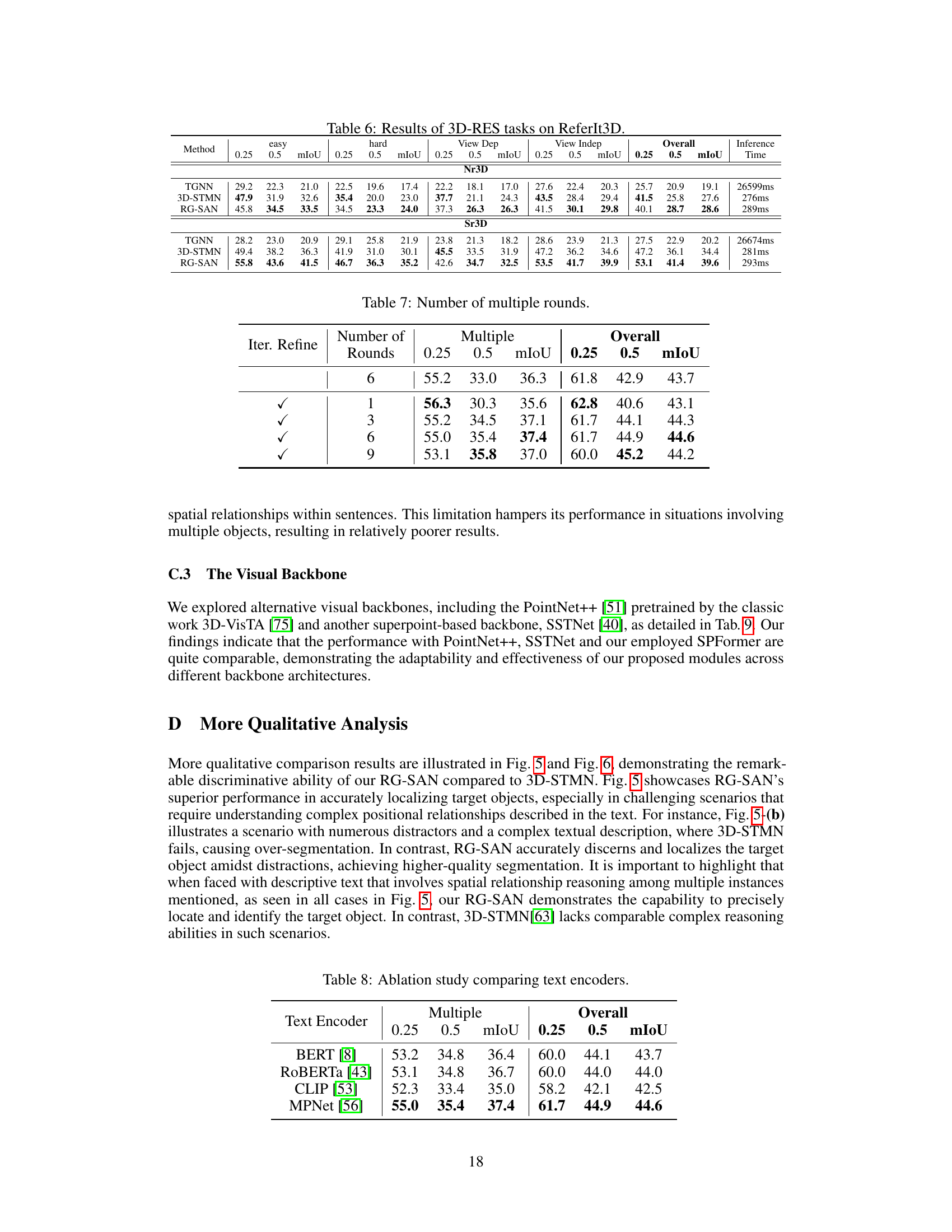
This table presents the ablation study of the number of multiple rounds in the Text-driven Localization Module (TLM). It shows the impact of varying the number of TLM rounds on the model’s performance, measured by mIoU and accuracy at 0.25 and 0.5 thresholds, for both ‘Multiple’ and ‘Overall’ cases. The results indicate that performance improves with more rounds, reaches a peak at six rounds, and then slightly declines, suggesting a balance between model capacity and overfitting.
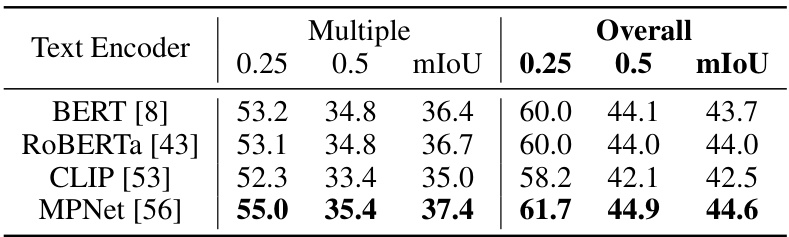
This ablation study compares the performance of different text encoders (BERT, RoBERTa, CLIP, and MPNet) used in the RG-SAN model. The results are presented in terms of mIoU for both the ‘Multiple’ and ‘Overall’ categories, with 0.25 and 0.5 thresholds for the mIoU metric.

This table presents the ablation study results on the impact of different visual backbones on the performance of the proposed RG-SAN model. The results are broken down by the evaluation metrics (mIoU) at different intersection over union (IoU) thresholds (0.25 and 0.5) for both the ‘Multiple’ and ‘Overall’ settings, showing that SPFormer backbone achieves the best overall performance.
Full paper#