↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Graph Contrastive Learning (GCL) has emerged as a powerful tool for learning graph representations without manual annotation. However, existing GCL methods, despite comparable performance, lack a unified understanding of their effectiveness. The differences among them, including the choice of negative sampling, group discrimination and bootstrapping schemes, seem to stem from diverse approaches to contrast learning. This makes it difficult to further improve their performance.
This paper identifies a previously unobserved mechanism shared across various successful GCL approaches: representation scattering. The authors show that existing GCL methods implicitly leverage this mechanism, but not to their full potential. To harness the power of representation scattering, they propose a new framework called Scattering Graph Representation Learning (SGRL). SGRL explicitly incorporates representation scattering using a novel mechanism and integrates graph topology to prevent excessive scattering. This new approach significantly outperforms existing GCL methods on various benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in graph contrastive learning and graph representation learning. It uncovers a latent mechanism, representation scattering, unifying seemingly disparate methods. This discovery opens up new avenues for efficient and robust GCL method development, pushing the boundaries of self-supervised GNN training and improving downstream task performance.
Visual Insights#

This figure shows the results of t-SNE dimensionality reduction applied to node embeddings generated by the DGI method on the Co-CS dataset. The visualizations illustrate the distribution of node embeddings before training (random initialization), after the first GNN layer, and after the second GNN layer. Red points represent the embeddings of positive nodes (original graph), and blue points represent embeddings of negative nodes (corrupted graph). The plots demonstrate that DGI-like methods maximize the Jensen-Shannon divergence (JS divergence) between the positive and negative node embeddings by pushing them apart in the embedding space, which is indicative of representation scattering.
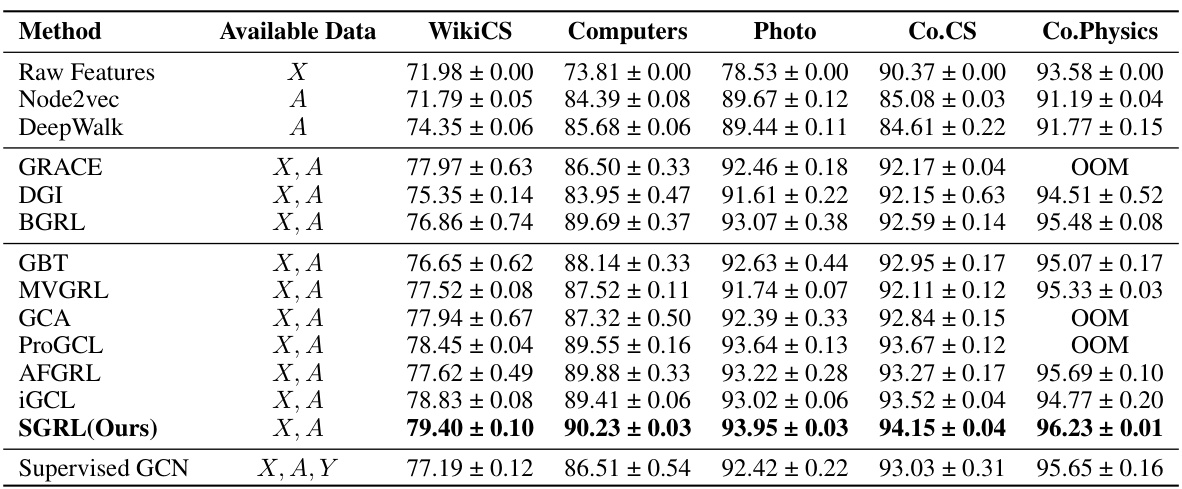
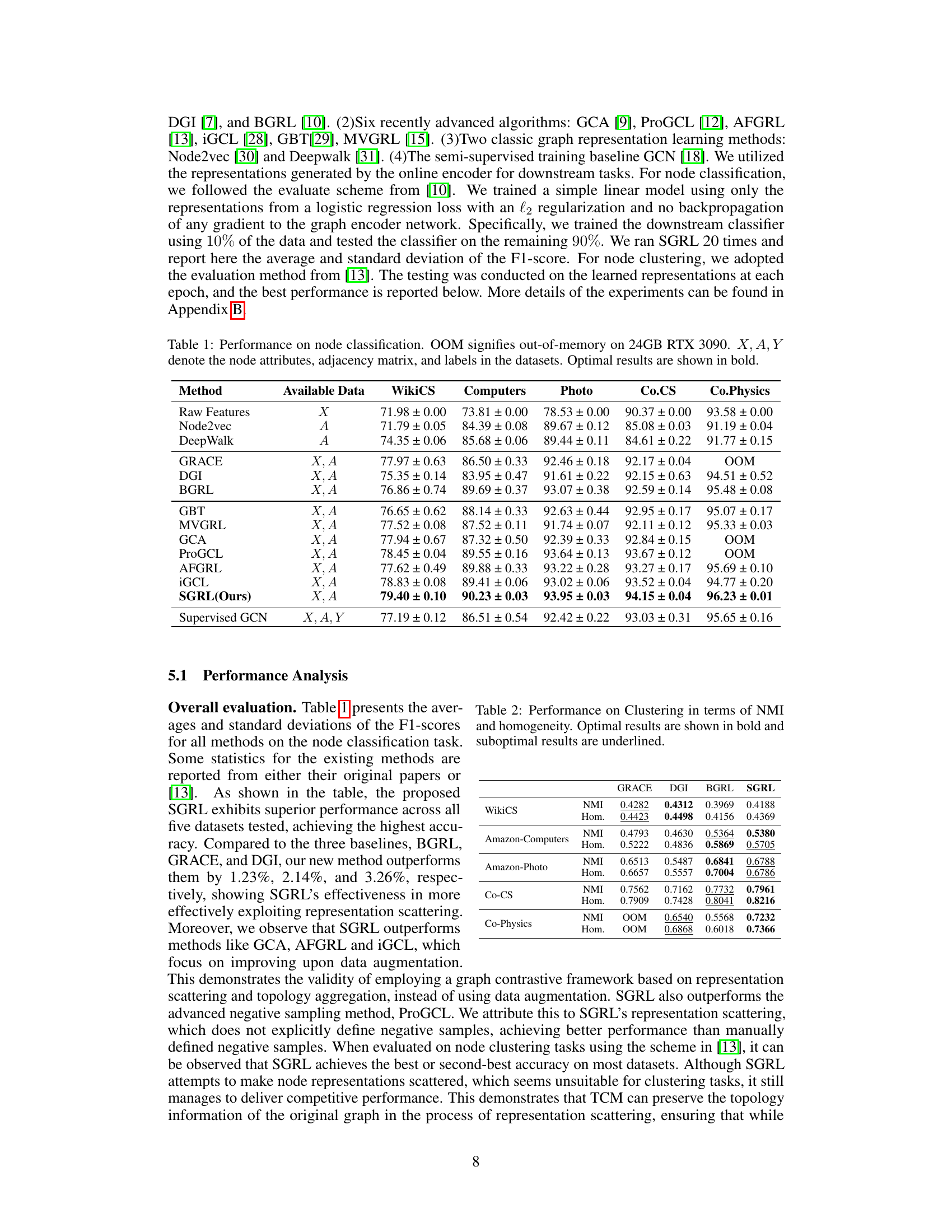
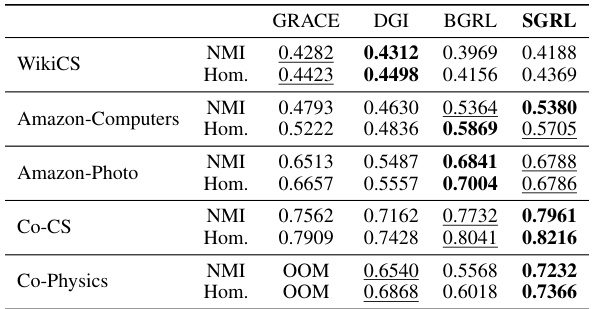
This table presents the performance comparison of various graph contrastive learning methods on node classification tasks across five benchmark datasets. The results are reported as the average F1-score along with standard deviation for each method and dataset. The ‘Available Data’ column indicates which data sources (node features, adjacency matrix, labels) were used by each method. The optimal results in each row are bolded. OOM indicates that a particular method ran out of memory on the hardware used for the experiments.
In-depth insights#
Latent Mechanism#
The concept of a ‘Latent Mechanism’ in a research paper typically refers to an underlying process or factor that significantly influences the observed results, but is not directly observable or easily measured. In the context of a research paper, exploring a latent mechanism involves delving into the hidden structures or processes that drive a phenomenon. This often requires careful analysis, potentially employing statistical modelling or advanced computational methods to extract meaningful insights from complex data. The exploration of a latent mechanism allows researchers to move beyond superficial observations, uncovering deeper causal relationships and advancing understanding of the subject matter. Identifying the latent mechanism allows for the development of more sophisticated and accurate models, leading to more effective interventions or predictions. It implies that the surface-level results or analysis may not fully explain the phenomenon, thereby necessitating the exploration of deeper, causal forces. A latent mechanism provides a more nuanced and insightful explanation compared to solely relying on correlational analysis. The discovery of a latent mechanism often paves the way for developing more targeted and effective strategies for manipulating or influencing the phenomenon under investigation, leading to new avenues of research and innovation.
Scattering GCL#
The concept of “Scattering GCL” suggests a novel approach to graph contrastive learning (GCL) that focuses on the scattering of representations within the embedding space. Instead of relying on explicit negative sampling or bootstrapping, Scattering GCL leverages a mechanism to actively push representations away from a central point, promoting diversity and encouraging uniformity. This approach aims to address some of the limitations of existing GCL frameworks, such as the computational cost associated with negative sampling and potential biases introduced by manually defined negative samples. A key innovation would likely involve a mechanism to control the degree of scattering, preventing excessive dispersion which could negatively impact downstream tasks. This likely involves a constraint mechanism incorporating graph topological information to ensure that closely related nodes maintain proximity in the embedded space. The effectiveness of this approach would depend on the design of the scattering and constraint mechanisms, demonstrating improvements in representation quality and downstream task performance compared to traditional GCL methods.
SGRL Framework#
The SGRL framework, a novel approach to graph contrastive learning, is built upon the crucial insight of representation scattering. Unlike existing methods, SGRL directly incorporates a mechanism to scatter node representations away from a central point, thereby promoting diversity. This core mechanism, termed RSM, directly addresses inefficiencies of earlier methods that rely on indirect methods or face computational challenges. Further enhancing the framework is the TCM, a topology-based constraint mechanism which uses graph structure to regulate the scattering process, preventing excessive dispersion and preserving crucial topological information. The combination of RSM and TCM results in adaptive representation scattering, optimizing the balance between representation diversity and structural integrity. The use of EMA further refines the training process. Overall, SGRL offers a more structured and efficient way to leverage representation scattering in graph contrastive learning, leading to superior performance across multiple benchmarks.
Topology-Based TCM#
A Topology-Based Constraint Mechanism (TCM) in graph contrastive learning addresses the challenge of balancing representation scattering with the preservation of graph structure. It integrates graph structural properties with representation scattering, preventing excessive scattering and ensuring that topologically related nodes maintain proximity in the embedding space. The TCM likely works by incorporating structural information, such as adjacency matrices or graph Laplacians, into the representation learning process. This could involve modifying the loss function to penalize deviations from structural relationships or directly adjusting the node embeddings based on their topological context. The core idea is to leverage the graph’s inherent structure to guide the scattering process, creating more meaningful and informative representations. This approach is crucial for downstream tasks that require understanding both the local and global structure of the graph, such as node classification and link prediction. The effectiveness of TCM hinges on the choice of method to incorporate topology and the balance it strikes between preserving structural information and allowing for sufficient representation scattering. If the constraint is too weak, it may not be effective in preventing excessive scattering; if it’s too strong, it might inhibit the benefits of representation scattering.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, removing the representation scattering mechanism (RSM) or the topology constraint mechanism (TCM) individually, or both, allows for a precise understanding of their impact. The results likely demonstrate that RSM significantly boosts performance, while TCM enhances robustness by preventing excessive scattering, showcasing the interplay of these modules. Significant performance drops when RSM is removed highlight its crucial role, while less drastic reductions with TCM removal could signify TCM’s supportive rather than primary contribution. Observing how performance changes with different combinations of RSM and TCM reveals whether their effects are additive, synergistic, or even antagonistic. The inclusion of an Exponential Moving Average (EMA) likely aims to stabilize training and mitigate any negative interaction between RSM and TCM. Overall, this section provides critical evidence for the effectiveness and necessity of both RSM and TCM, highlighting the careful design of the proposed model architecture.
More visual insights#
More on figures
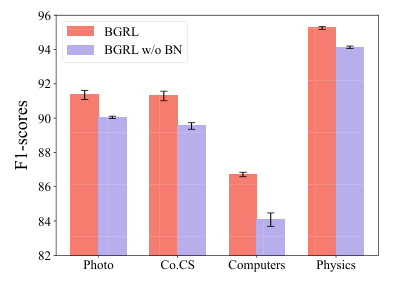
This bar chart compares the F1-scores achieved by the BGRL model with and without Batch Normalization (BN) across four benchmark datasets: Photo, Co.CS, Computers, and Physics. The results demonstrate a significant performance decrease in the BGRL model when BN is removed, highlighting its importance for representation scattering within this framework. Error bars are included to show the variability of the F1-scores.
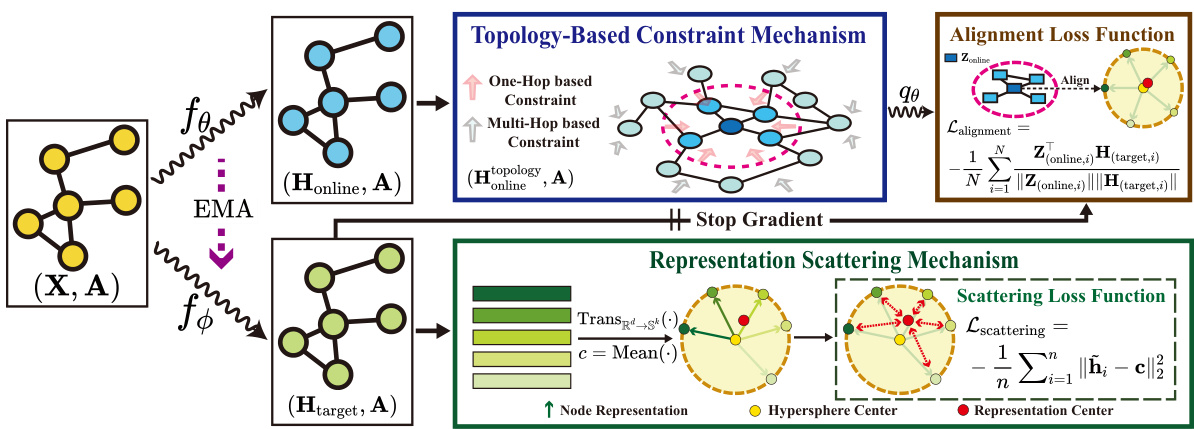
This figure shows a schematic overview of the Scattering Graph Representation Learning (SGRL) framework. It illustrates the two encoders (online and target), the representation scattering mechanism (RSM), the topology-based constraint mechanism (TCM), and the alignment loss function used for training. The figure highlights the process of generating node representations, incorporating topological information, and pushing node representations away from a central point (scattering) for improved performance on downstream tasks.

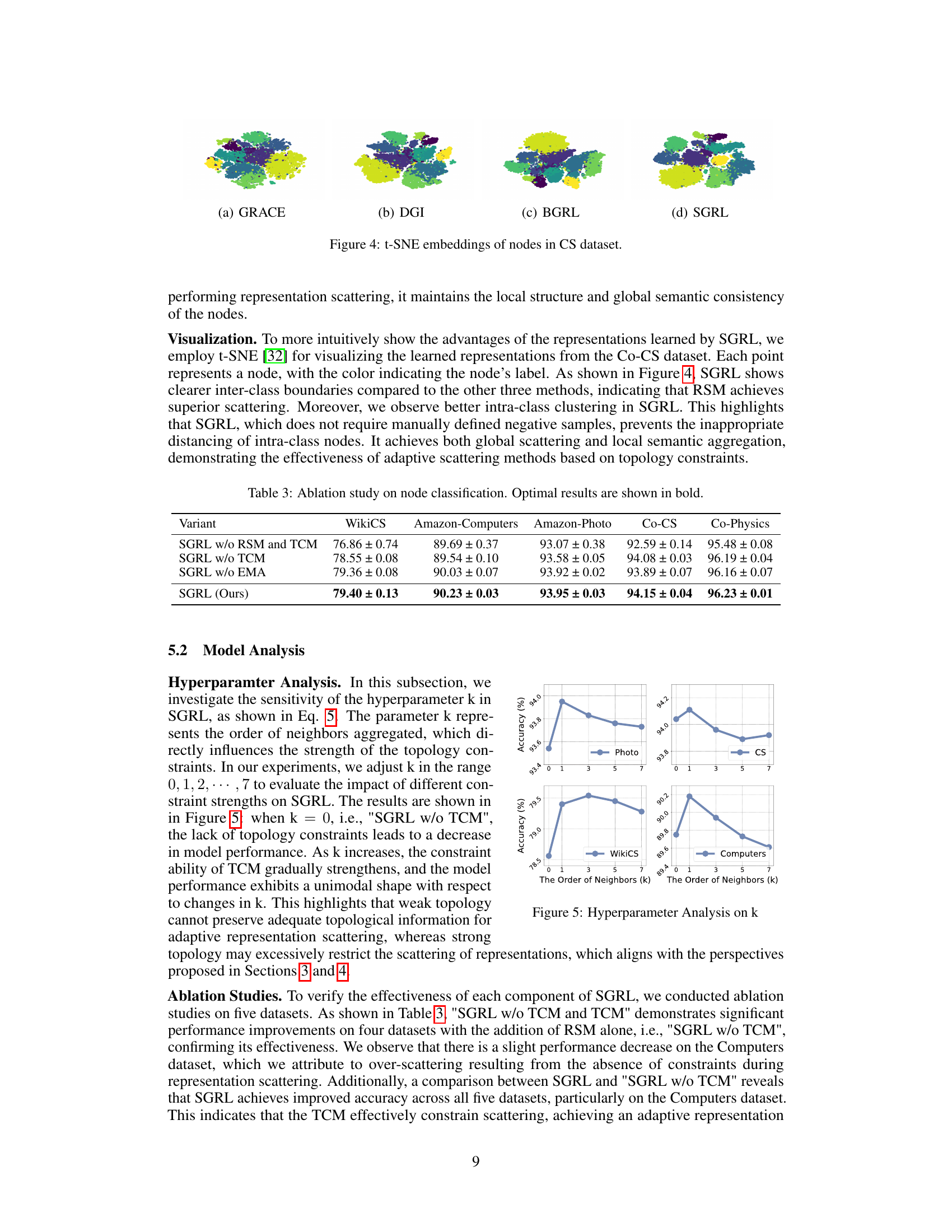
This figure shows the visualization of node embeddings using t-SNE for the Coauthor-CS dataset. Each point represents a node, colored by its label. The figure compares the visualizations generated by GRACE, DGI, BGRL, and SGRL, highlighting the differences in the clustering and separation of nodes based on their labels. SGRL shows clearer inter-class boundaries and better intra-class clustering, indicating effective representation scattering and semantic aggregation.
This figure visualizes the t-SNE embeddings of nodes in the Computers dataset. Each point represents a node, colored by its label. The figure compares the node embeddings generated by four different methods: GRACE, DGI, BGRL, and SGRL (the proposed method). The visualization aims to show how well each method separates different classes (inter-class separation) and groups similar nodes together (intra-class clustering). SGRL shows clearer inter-class boundaries and better intra-class clustering compared to the other methods.
More on tables
This table presents the results of node classification experiments using various methods on five benchmark datasets (WikiCS, Amazon-Computers, Amazon-Photo, Coauthor-CS, and Coauthor-Physics). Each method’s performance is evaluated using the F1-score, and the best performance for each dataset is highlighted in bold. The table also indicates datasets where a method ran out of memory (OOM). The ‘Available Data’ column specifies the type of data used by each method (node features (X), adjacency matrix (A), and labels (Y)).

This table presents the results of an ablation study conducted to evaluate the impact of each component of the SGRL model on node classification performance across five different datasets. The ablation study systematically removes different components of the model (RSM, TCM, and EMA) to isolate their individual contributions. The results demonstrate the effectiveness of each component and the overall superiority of the complete SGRL model.

This table presents the results of node classification experiments across five benchmark datasets. It compares the performance of SGRL against several other methods, including three mainstream GCL baselines (GRACE, DGI, BGRL), six recently advanced algorithms, two classic graph representation learning methods, and a supervised GCN baseline. The table shows F1-scores and indicates out-of-memory errors where applicable. Optimal results for each dataset are highlighted in bold.

This table presents the performance comparison of various node classification methods on five benchmark datasets (WikiCS, Amazon-Computers, Amazon-Photo, Coauthor-CS, and Coauthor-Physics). The results are evaluated using F1-score. The table includes results for several baseline and state-of-the-art methods, along with the proposed SGRL method. ‘OOM’ indicates that the method ran out of memory during the experiment. The best results for each dataset are highlighted in bold. The table also indicates which features (node attributes (X), adjacency matrix (A), and labels (Y)) were used by each method.
Full paper#