↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Creating high-quality 3D models usually demands extensive image datasets and complex processing. This is problematic for many applications, especially with the growing demand for 3D content in various fields. Existing methods often struggle with limited input data, requiring hundreds of images to generate acceptable results. This paper addresses this issue by introducing CAT3D.
CAT3D uses a novel multi-view diffusion model that simulates real-world capture processes. Given a limited set of input images, CAT3D generates highly consistent novel views. These views are then fed into a robust 3D reconstruction pipeline to produce real-time renderable 3D models. The results demonstrate CAT3D’s superiority over existing methods in both speed and quality across various input scenarios, showcasing its effectiveness even with single-image or text-based inputs. This represents a significant advance towards more accessible and efficient 3D content creation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents CAT3D, a novel and efficient method for creating high-quality 3D content from limited inputs (single images, few views, or even text prompts). This significantly reduces the time and effort required for 3D content creation, opening new avenues for research in areas such as game development, virtual and augmented reality, and visual effects. The multi-view diffusion model employed in CAT3D shows promise for advancing research on 3D generation and reconstruction.
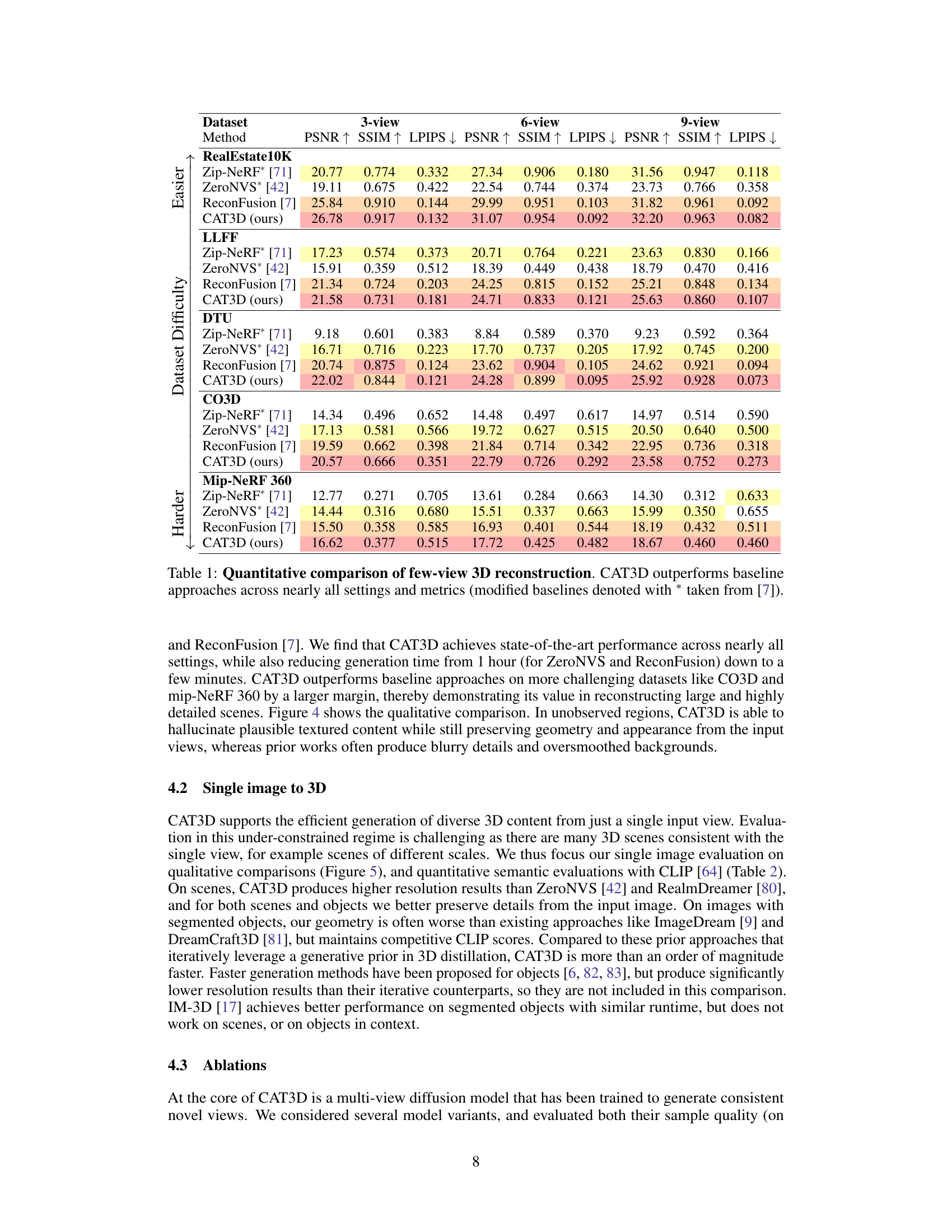
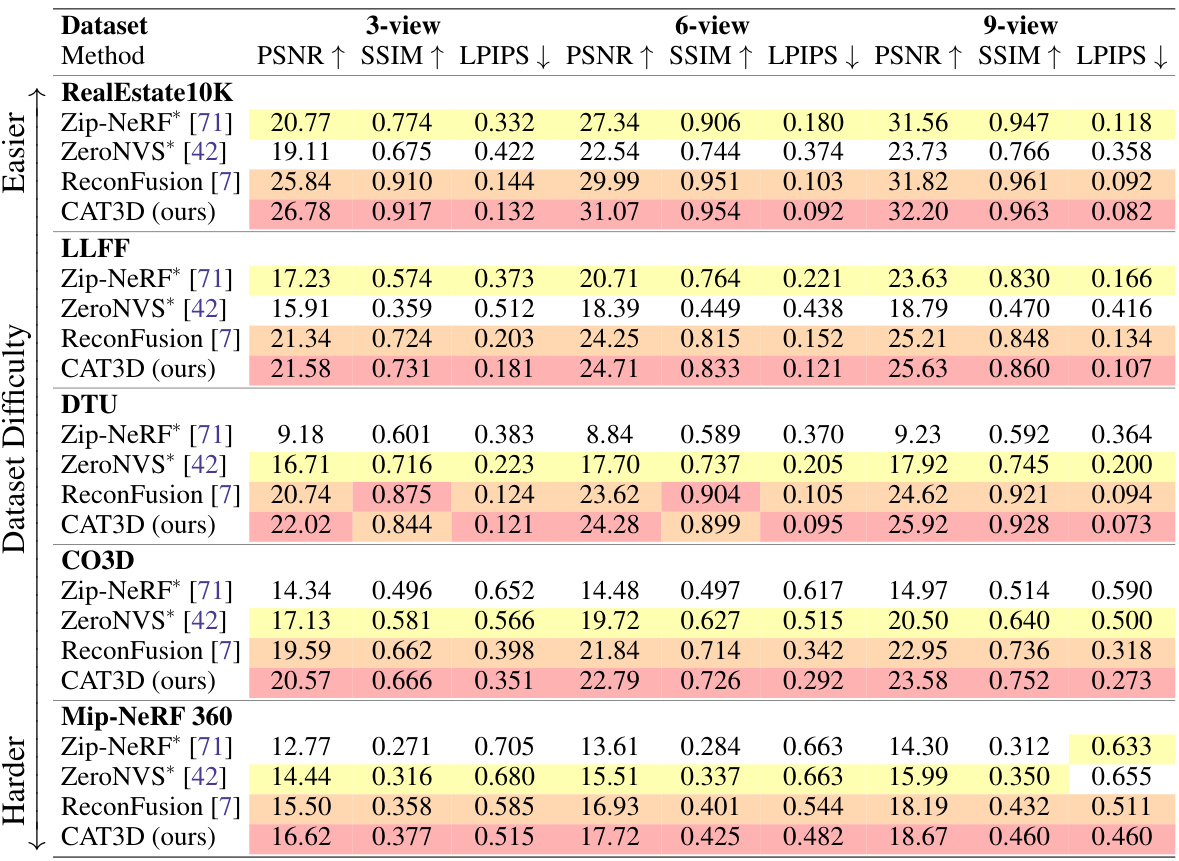
Visual Insights#

This figure shows three examples of 3D scene generation using CAT3D. The first example shows a text-to-image-to-3D pipeline where a text prompt (‘a shiny silver robot cat’) is used to generate an image, which is then used to generate a 3D model. The second example shows a real image to 3D pipeline where a single real image of a dog is used to generate a 3D model. The third example shows a sparse multi-view to 3D pipeline where multiple real images of a bonsai tree are used to generate a 3D model. Each example shows the input images and the resulting 3D model.

This table compares the performance of CAT3D against other single image to 3D methods using CLIP image scores. The table shows that CAT3D achieves comparable performance to other methods while being significantly faster (1 minute vs. 3-120 minutes).
In-depth insights#
Multi-view Diffusion#
The concept of “Multi-view Diffusion” in the context of 3D generation signifies a significant advancement. It leverages the power of diffusion models, known for their exceptional image synthesis capabilities, to generate multiple consistent views of a 3D scene from limited input. This addresses the core challenge of traditional 3D reconstruction methods, which often require hundreds of images for accurate results. By generating synthetic views consistent with the input, the approach effectively bypasses the need for extensive real-world capture. This dramatically improves efficiency and accessibility. The multi-view aspect is crucial; it ensures that the generated images are not merely individually realistic but also share coherent 3D geometry and structure, enabling robust 3D reconstruction. The method’s strength lies in its ability to bridge the gap between 2D image generation and 3D scene creation, leading to more efficient and potentially higher-quality results. However, challenges remain. Generating truly consistent views across various viewpoints remains difficult, and the reliance on trained diffusion models could limit generalization. Future research should explore improved training strategies, novel network architectures, and techniques to handle diverse scene complexities. This area holds immense potential for advancements in 3D content creation tools and applications.
Novel View Synthesis#
Novel View Synthesis (NVS) is a crucial technique in 3D computer vision and graphics, aiming to generate realistic images of a scene from viewpoints not present in the original data. The core challenge lies in accurately reconstructing the 3D structure and appearance of the scene from limited observations, often a sparse set of images. This requires sophisticated methods to infer the missing information, including geometry, texture, and lighting, and to create images that maintain consistency with the observed views. The recent advances in deep learning have significantly improved the performance of NVS, leading to more photorealistic and detailed synthetic views. However, challenges remain in handling complex scenes, occlusions, and motion, and many approaches still suffer from computational cost. Future work will likely focus on improving efficiency, robustness to noise and incomplete data, and extending NVS to dynamic scenes with moving objects and varying illumination conditions.
3D Reconstruction#
The 3D reconstruction process in this research is crucial, leveraging generated novel views to create a robust 3D representation. The use of a multi-view diffusion model is key, producing a large set of consistent synthetic images that act as input for the reconstruction pipeline. This approach addresses limitations of traditional methods requiring many real-world images, significantly improving efficiency. A robust 3D reconstruction pipeline is employed, using a modified NeRF training process to handle inconsistencies in the generated views, making the system more resilient to inaccuracies inherent in the generative model’s output. The resulting 3D models exhibit high quality and photorealism, allowing for real-time rendering from any viewpoint. This two-step approach (generation then reconstruction) is a significant contribution, addressing challenges with previous techniques that attempted 3D creation from limited views directly.
Limited Data#
The challenge of ‘Limited Data’ in machine learning, especially concerning 3D content generation, is a critical bottleneck. Traditional 3D reconstruction methods heavily rely on extensive datasets of multiple views, making them impractical for many applications. This necessitates the exploration of innovative techniques for 3D model creation from significantly fewer input images or even a single image, as well as text prompts. The core problem is the inherent under-determination of 3D structure from limited 2D perspectives. Addressing ‘Limited Data’ requires developing models robust to noisy or incomplete information and capable of hallucinating missing details, bridging the gap between the observed and the unobserved aspects of the 3D scene. This could involve incorporating strong generative priors, such as text-to-image models or pre-trained video diffusion models, which inherently encode rich 3D knowledge, enabling the generation of consistent and plausible views from limited inputs. The successful mitigation of ‘Limited Data’ is crucial for advancing realistic and efficient 3D content creation, making the technology accessible across various applications.
Future 3D Research#
Future 3D research should prioritize addressing the limitations of current techniques, such as the reliance on large datasets and computational resources. Developing more efficient and robust 3D reconstruction methods from limited views, including single images or sparse point clouds, is crucial. This includes exploring alternative generative models capable of handling uncertainty and producing more consistent results. Research should also focus on enhancing controllability and semantic understanding in 3D generation, moving beyond simple geometry reconstruction to incorporate realistic textures, materials, and lighting effects. Ultimately, the goal is to enable the creation of high-quality, interactive 3D content quickly and easily, unlocking its potential across diverse fields, from gaming and virtual reality to industrial design and scientific visualization. This requires a holistic approach integrating advancements in generative modeling, computer vision, and rendering.
More visual insights#
More on figures

This figure showcases the qualitative results of 3D models generated by CAT3D from different input modalities. The top row demonstrates the generation from a text-to-image model, showcasing the ability to create 3D objects from textual descriptions. The middle row presents the results from a single captured real image, highlighting the system’s capability in reconstructing 3D scenes from limited input. Finally, the bottom row illustrates the generation from multiple captured real images, demonstrating the system’s robustness and ability to produce high-quality 3D models even with dense input data.
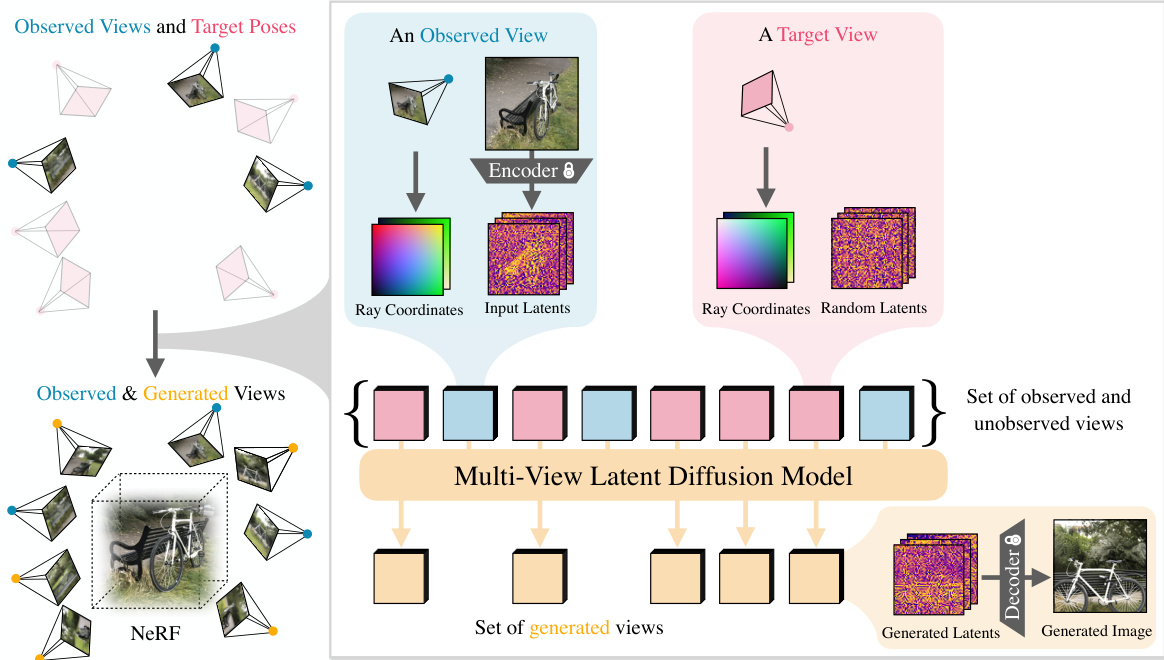
This figure illustrates the two-stage process of CAT3D for 3D scene creation. Stage 1 uses a multi-view latent diffusion model to generate a large number of synthetic views consistent with the input views (one or more). These generated views, along with the original observed views, are then fed into a robust 3D reconstruction pipeline (stage 2) to produce a final 3D model. The separation of the generation and reconstruction steps improves efficiency and reduces complexity compared to previous methods.

This figure compares the 3D reconstruction results of CAT3D with those of ReconFusion [7], a state-of-the-art method, using three input views. The top row shows scenes from the mip-NeRF 36 dataset, while the bottom row shows scenes from the CO3D dataset. CAT3D demonstrates improved accuracy in reconstructing visible parts of the scenes and better hallucination of unseen areas compared to ReconFusion.
This figure compares the 3D reconstruction results of CAT3D with ReconFusion on two datasets (mip-NeRF 36 and CO3D) using only 3 input views. It showcases CAT3D’s ability to produce more accurate reconstructions in visible areas of the scene while also generating plausible details in unseen areas, surpassing the performance of the ReconFusion method.

This figure compares the 3D reconstruction results of CAT3D against several baselines (RealmDreamer, ZeroNVS, ImageDream, and DreamCraft3D) when using a single input image. The top row shows the input images. The middle row displays the results generated by CAT3D, showcasing its ability to generate high-quality 3D models for both scenes and objects. The bottom row presents the results from the baseline methods, highlighting the superior quality of CAT3D’s output, especially in the scene reconstructions. The differences are amplified by the scale ambiguity that can exist when generating 3D objects from single images. More comparisons can be found on the supplemental website.
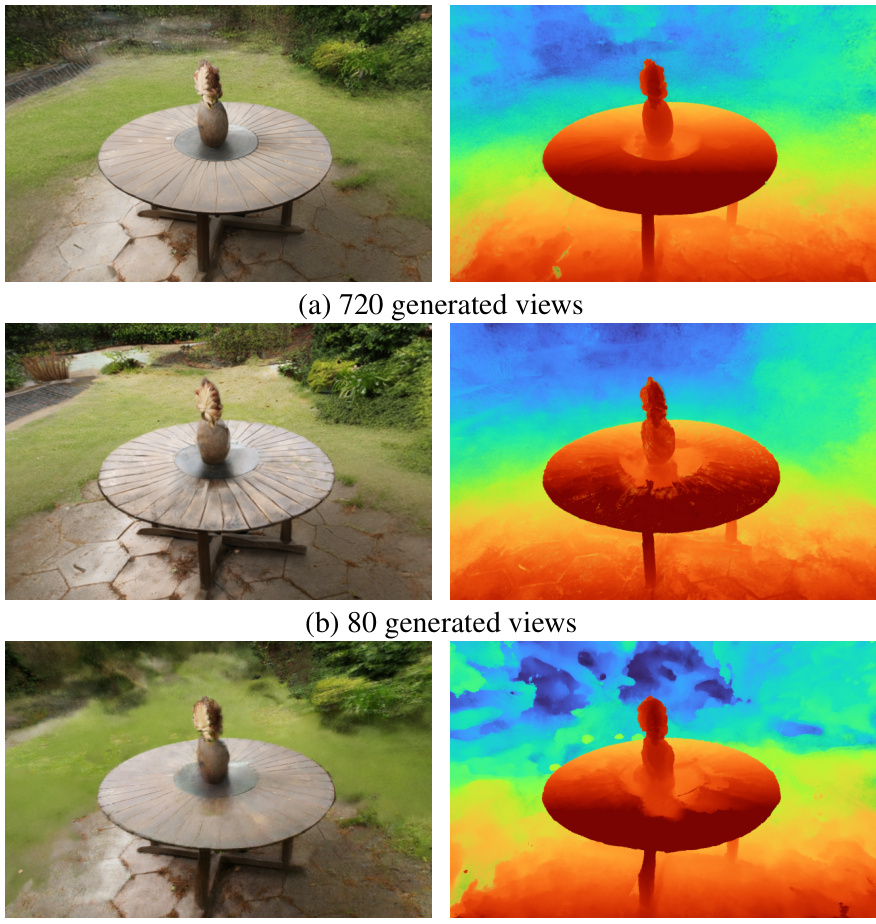
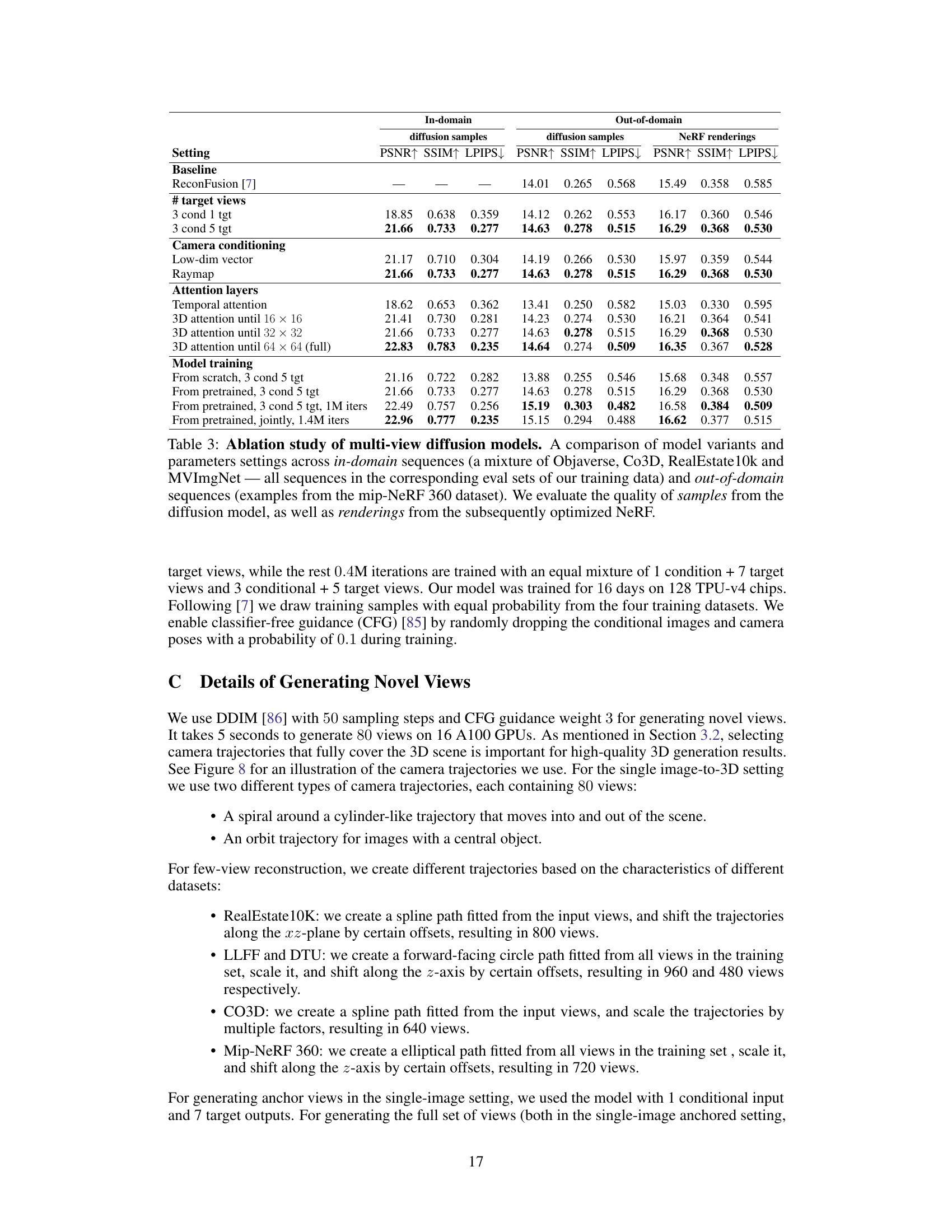
This figure shows a qualitative comparison of the 3D reconstruction results obtained using different numbers of generated views and with/without the perceptual loss. The left column displays rendered images, while the right shows depth maps. It highlights how increasing the number of generated views (from 80 to 720) and including the perceptual loss improves the quality of 3D reconstruction.
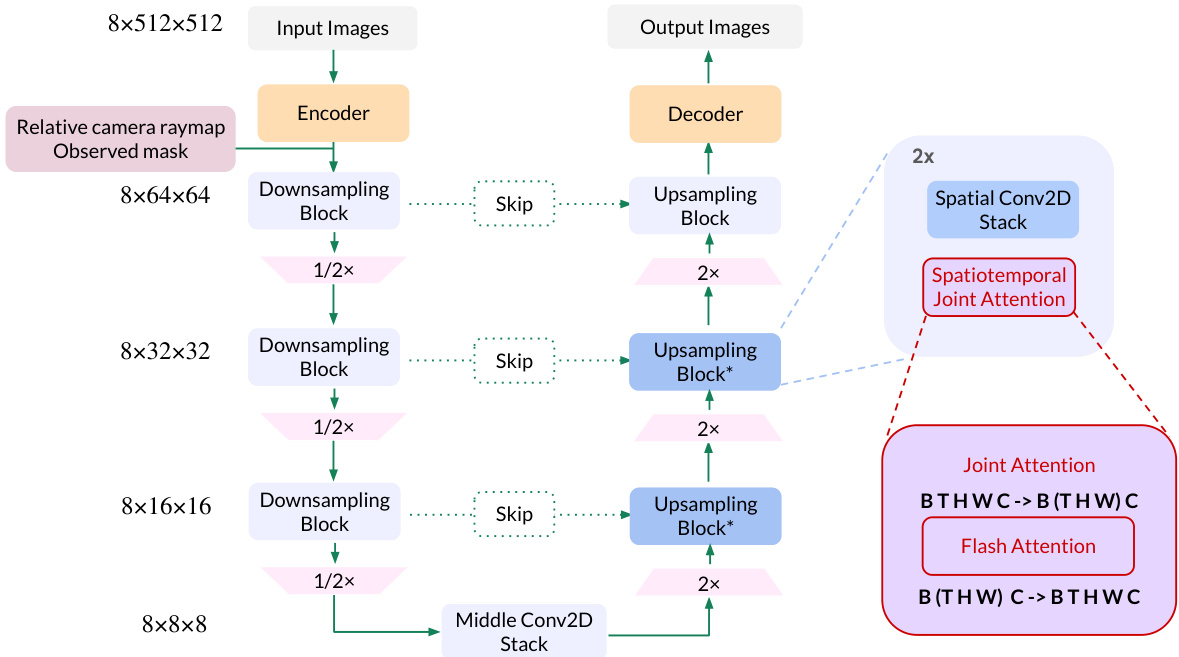
This figure illustrates the two-stage process of CAT3D. First, a multi-view diffusion model generates a large number of synthetic views from one or more input views and their camera poses. Second, a robust 3D reconstruction pipeline processes both the original and generated views to produce a 3D representation of the scene. The decoupling of generation and reconstruction improves efficiency and reduces complexity compared to previous methods.
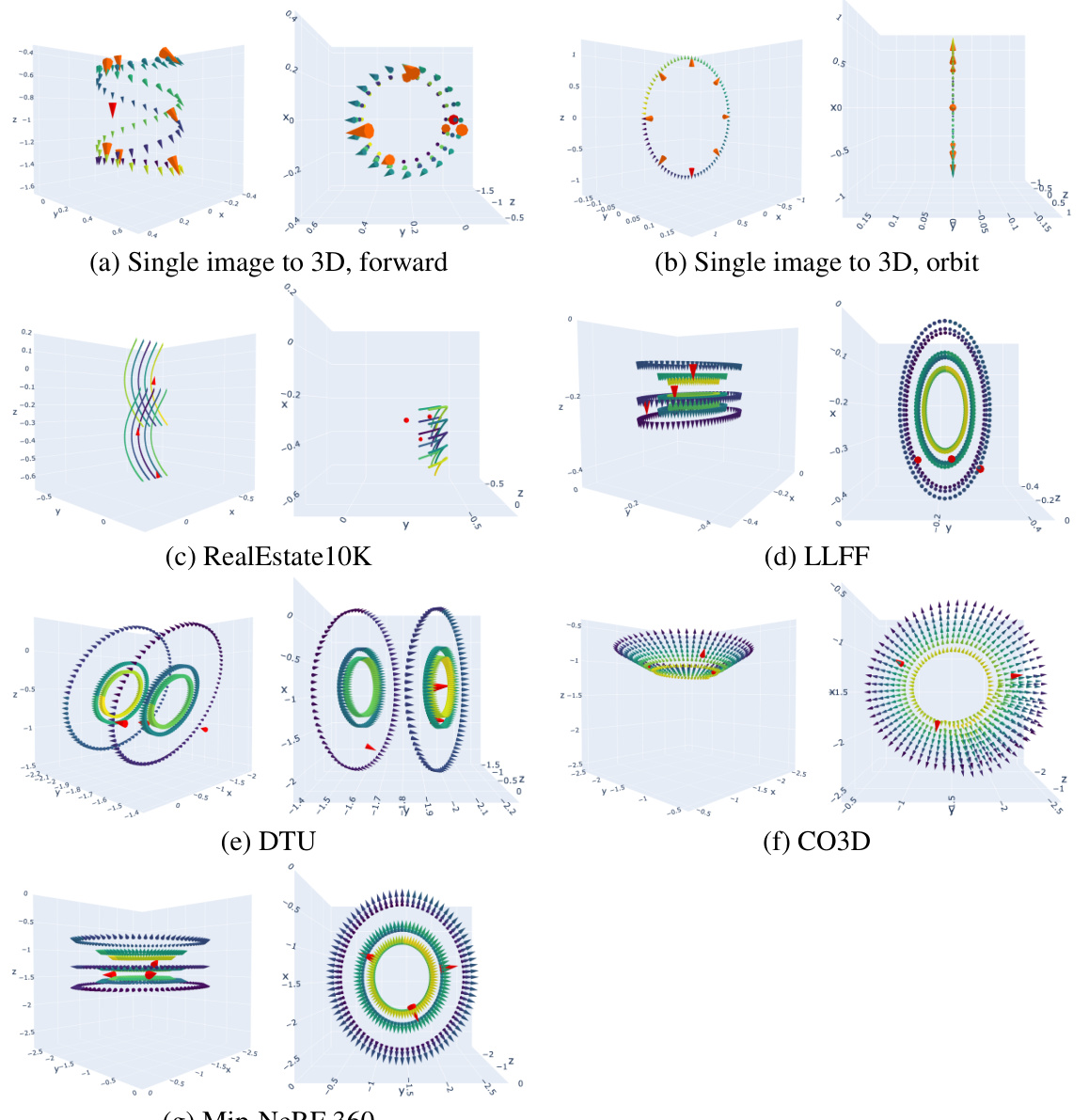
This figure visualizes the camera trajectories used for generating novel views in the CAT3D model. Different camera paths are used depending on the input type (single image vs. multiple views) and dataset. The left and right subplots of each panel show side and top views of the trajectories, respectively, with colors representing the view indices. The observed input views are highlighted in red, and anchor views (for single-image scenarios) are shown in orange.
Full paper#