↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current open-world 3D reconstruction methods often struggle with high-quality mesh generation from sparse views due to high computational cost and lack of effective inductive biases. Existing methods either rely on dense input views or are trained on large-scale 3D datasets, limiting their generalizability and speed. These methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. Some recent methods incorporate 2D diffusion models to overcome these issues but their quality is limited.
MeshFormer addresses these challenges by leveraging a novel architecture combining transformers and 3D convolutions for explicit 3D representation. It incorporates multi-view normal maps, along with RGB images, to provide strong geometric guidance during training. A unified single-stage training strategy using surface rendering and SDF supervision leads to faster convergence and significantly improved mesh quality. The results demonstrate that MeshFormer achieves state-of-the-art performance on various benchmarks while being significantly more efficient to train than existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D reconstruction and computer vision because it presents MeshFormer, a novel, efficient model for high-quality 3D mesh generation from sparse views. Its speed and efficiency, achieved through innovative architectural design and training strategies, make it highly relevant to current research trends. This work opens up new avenues for research in open-world 3D reconstruction and integration with 2D diffusion models, enabling advancements in fields like AR/VR, robotics, and digital content creation. Furthermore, the explicit treatment of 3D structure and the use of normal maps offer significant improvements that other researchers can leverage and extend.
Visual Insights#

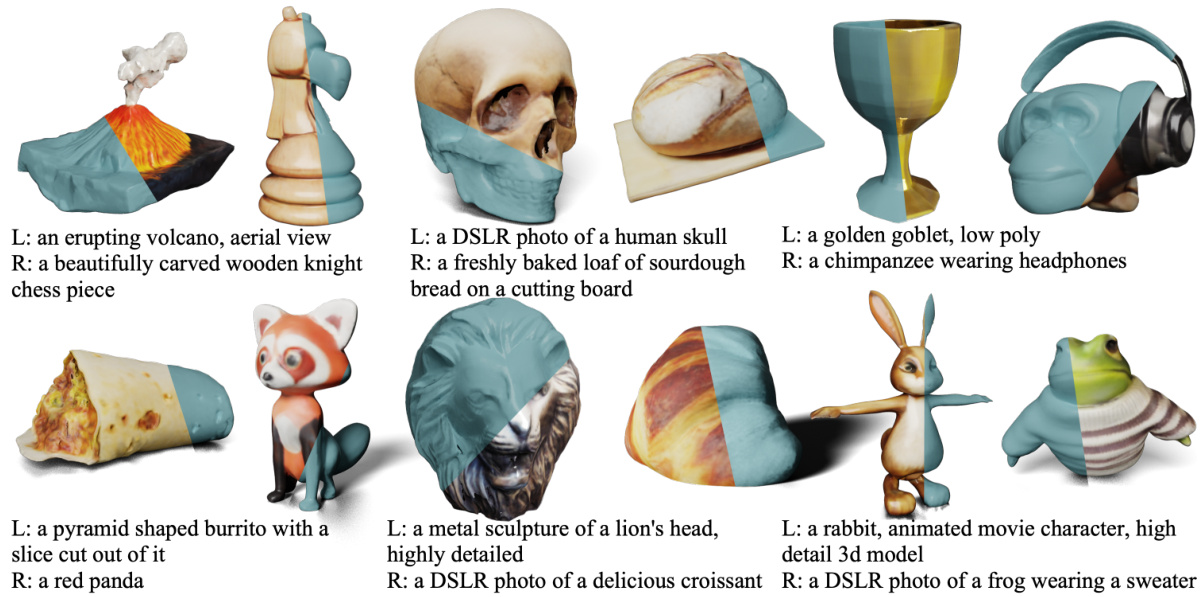
This figure shows example results of the MeshFormer model. Given a small number (e.g., six) of RGB images and their corresponding normal maps from different viewpoints, MeshFormer generates a high-quality 3D mesh in just a few seconds. The generated meshes are textured and exhibit fine details and sharp features. The input for this example uses ground truth (perfect) RGB images and normal maps for demonstration purposes.
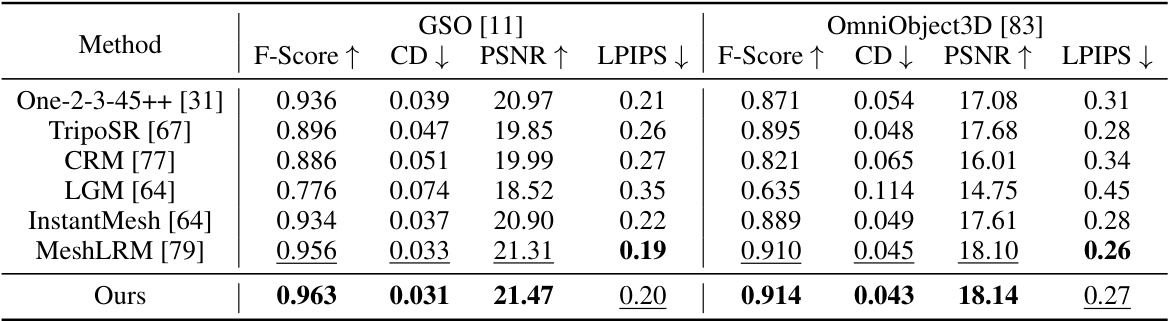
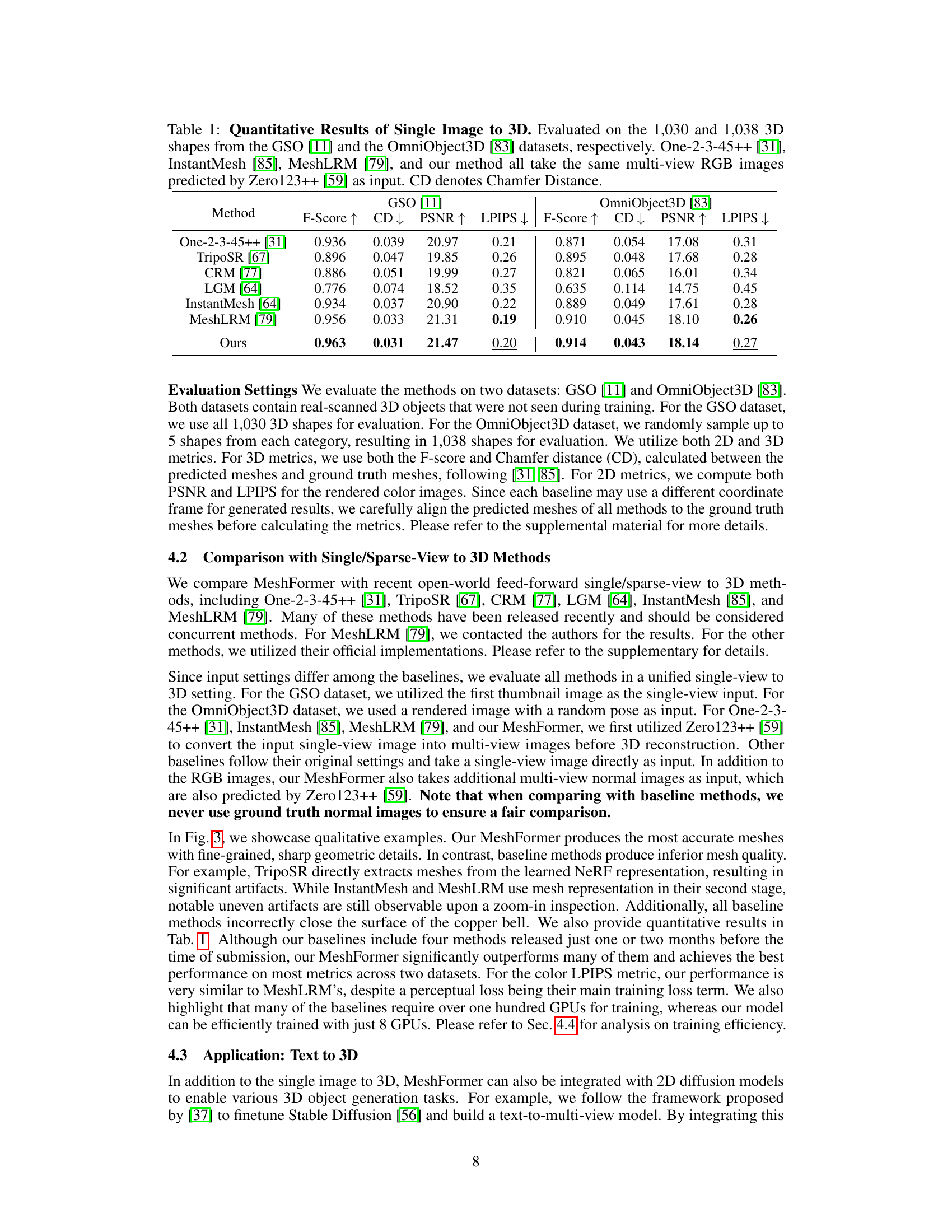
This table presents a quantitative comparison of different single image to 3D methods on two benchmark datasets: GSO and OmniObject3D. The metrics used include F-Score, Chamfer Distance (CD), PSNR, and LPIPS. All methods use multi-view RGB images predicted from a single input image using Zero123++ as input, allowing for a fair comparison.
In-depth insights#
3D Voxel Encoding#
3D voxel encoding offers a powerful way to represent 3D data, particularly for neural networks. Its key advantage lies in its inherent 3D structure, unlike alternative methods such as point clouds or meshes which can be less intuitive for certain deep learning architectures. Voxels provide a regular, grid-based representation, making it easy to implement convolutional operations and other spatial processing techniques directly in the 3D domain. This can lead to more efficient and accurate learning of 3D shapes and scenes, compared to methods that rely on intermediate 2D projections. However, resolution is a critical factor, as higher resolutions increase computational complexity exponentially, leading to limitations in the size and detail of the representable scenes. Furthermore, efficient handling of sparse voxels is crucial for scalability. The choice of voxel size and grid resolution should be carefully considered; it’s a tradeoff between detail, accuracy, and computational cost. Advanced techniques like octrees or hash tables can help address the issue of sparsity but add further complexity.
Transformer Fusion#
Transformer fusion, in the context of a research paper, likely refers to a method that combines the strengths of transformer networks with other neural network architectures. This could involve using transformers to process and integrate features from different modalities or stages of processing. A key advantage might be improved context understanding and long-range dependency modeling, especially useful when dealing with complex, multi-modal data. Potential applications range from image processing (integrating image features with text descriptions) to 3D reconstruction (combining 2D image data with 3D geometric information). The effectiveness of transformer fusion hinges on how well the integration is designed; poor integration can lead to reduced performance and increased computational cost. Successful approaches likely incorporate clever mechanisms for feature alignment and efficient information transfer between different components. The paper might analyze the impact of various fusion strategies on downstream tasks, comparing fusion approaches to using transformers or other architectures alone. A crucial aspect of evaluation would be demonstrating improved accuracy, efficiency, or robustness over alternative methods.
SDF Supervision#
The concept of ‘SDF Supervision’ in 3D reconstruction leverages the power of Signed Distance Functions (SDFs) to improve the accuracy and efficiency of mesh generation. SDFs represent the distance from a point to the nearest surface, providing an implicit surface representation that is particularly well-suited to neural networks. By incorporating SDF supervision during training, the model learns not only to render realistic images but also to accurately capture the underlying 3D geometry. This implicit guidance leads to faster convergence and higher-quality meshes with finer details. This contrasts with methods relying solely on image rendering losses which can struggle with accurate geometry extraction. Efficient differentiable rendering techniques further enhance the integration, allowing the model to directly optimize the SDF, leading to a more robust and refined mesh. SDF supervision acts as a strong regularizer, preventing the network from generating meshes with artifacts or inaccuracies often seen in purely image-based methods. Thus, the combination of SDF supervision and image rendering is a powerful approach to creating high-fidelity meshes.
Normal Guidance#
Incorporating normal maps as input significantly enhances the accuracy and detail of 3D mesh reconstruction. Normal maps provide crucial geometric information, supplementing color data to resolve ambiguities and improve the model’s understanding of surface orientation. This guidance is particularly valuable in sparse-view scenarios, where traditional methods struggle to extract fine-grained details. By using normal maps predicted by 2D diffusion models, the approach avoids the need for expensive depth or normal sensing hardware, making the system more practical. The fusion of normal map information with multi-view RGB input within a unified network architecture enables efficient and effective training. The results demonstrate improved reconstruction accuracy, producing meshes with sharper geometric features and more realistic textures.
Future of MeshFormer#
The future of MeshFormer appears bright, given its strong foundation and potential. Improving efficiency remains key; exploring more efficient 3D feature representations and attention mechanisms could significantly reduce training time and computational cost. Enhanced generalization to unseen object categories and more complex scenes is another crucial area for development. This may involve incorporating more sophisticated inductive biases into the model architecture or leveraging larger and more diverse training datasets. Integration with other AI models offers exciting possibilities. Seamless fusion with text-to-image or text-to-3D models could unlock powerful new capabilities in creating detailed 3D assets from simple textual descriptions. Furthermore, extending the input modalities beyond RGB images and normal maps to include depth, point clouds, or even multispectral data could further enhance the model’s accuracy and robustness. Finally, addressing ethical concerns associated with generative AI is paramount. MeshFormer’s ability to produce realistic 3D models necessitates careful consideration of potential misuse and the development of safeguards to prevent malicious applications.
More visual insights#
More on figures
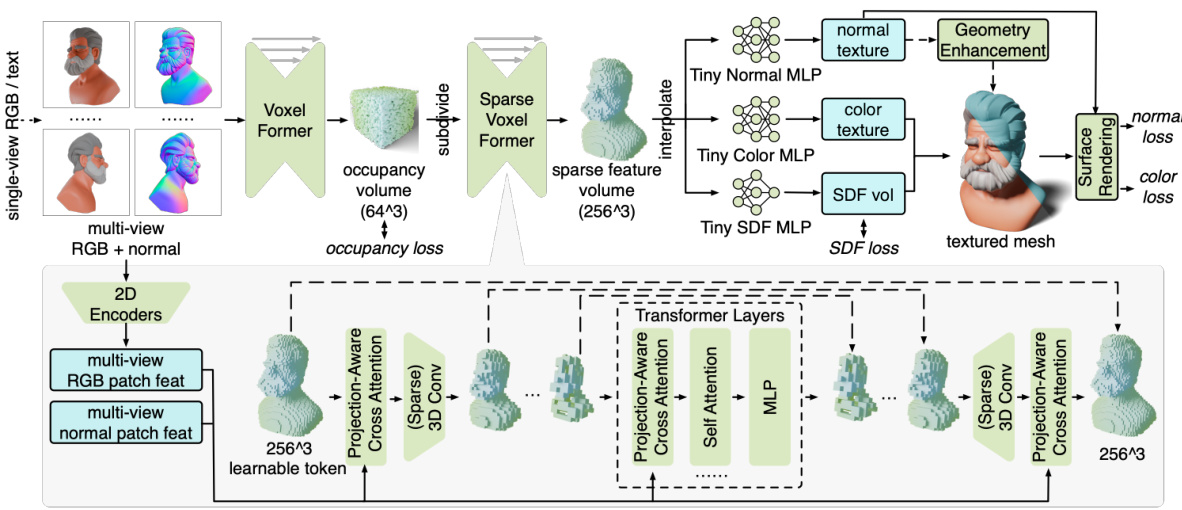
This figure provides a detailed overview of the MeshFormer pipeline. It shows how sparse multi-view RGB and normal images are processed by 2D encoders. The features are then fed into a novel 3D architecture combining transformers and 3D convolutions (Voxel Former and Sparse Voxel Former). This architecture processes the data through a coarse-to-fine approach, generating a high-resolution sparse feature volume. Finally, this volume is used with MLPs to generate the SDF, color texture, and normal texture. The SDF is used for mesh extraction with a geometry enhancement step and used for losses along with rendered images.

This figure shows qualitative comparison results of several single-image-to-3D methods on the GSO dataset. The figure displays both textured and textureless mesh renderings for each method, allowing for a visual comparison of the quality and detail of the generated 3D models. The caption suggests referring to supplementary material for additional results from two specific methods: One-2-3-45++ and CRM.
This figure shows the pipeline of MeshFormer, a 3D reconstruction model. It takes sparse multi-view RGB and normal images as input. These images can be predicted by 2D diffusion models. The model uses a 3D feature volume representation. Two submodules, Voxel Former and Sparse Voxel Former, share a similar architecture. The training process combines mesh surface rendering with SDF supervision. Finally, MeshFormer learns an additional normal texture to improve geometry and details.

This figure shows the effect of geometry enhancement on the quality of generated 3D meshes. The top row displays the meshes before enhancement, while the bottom row shows the same meshes after enhancement. Zooming in on the highlighted areas reveals that the geometry enhancement process sharpens the fine details of the meshes, leading to significantly improved visual quality.

This figure illustrates the pipeline of Meshformer, a model that reconstructs high-quality 3D textured meshes from sparse multi-view RGB and normal images. It highlights the model’s architecture, which combines 3D convolutions and transformers to process 3D voxel features. The training process integrates mesh surface rendering and SDF supervision. Notably, it details the use of a normal texture for geometry enhancement, leading to higher quality mesh outputs.

This figure compares the performance of MeshLRM and the proposed method in capturing fine details, specifically text on the label of a creatine bottle. MeshLRM, which uses a triplane representation, struggles to render the text clearly, while the proposed method produces a much sharper and more accurate rendering of the text. This highlights one of the advantages of using a 3D voxel representation over a triplane representation for detailed 3D reconstruction.

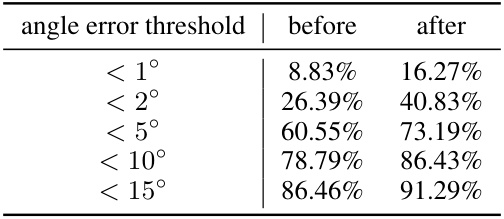
This ablation study compares the performance of Meshformer when trained with different types of normal maps as input. The three conditions are: no normal maps, predicted normal maps from Zero123++, and ground truth normal maps. The figure shows that using ground truth normal maps yields the best results, as expected.

This figure shows a comparison of the 3D reconstruction results from three different methods: One-2-3-45++, CRM, and the proposed MeshFormer. The input is a single image for each object. Both textured and untextured mesh renderings are presented for each method. The figure demonstrates that the proposed MeshFormer method outperforms the others in terms of mesh quality and detail preservation.
More on tables

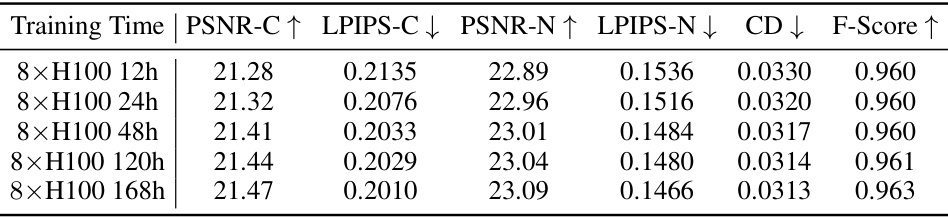
This table compares the performance of MeshLRM and the proposed MeshFormer model using limited training resources (8x H100 GPUs for 48 hours). The comparison is based on the GSO dataset and uses F-Score, Chamfer Distance (CD), and PSNR/LPIPS scores for color and normal images to evaluate reconstruction quality. The results show that MeshFormer outperforms MeshLRM even with significantly fewer training resources.
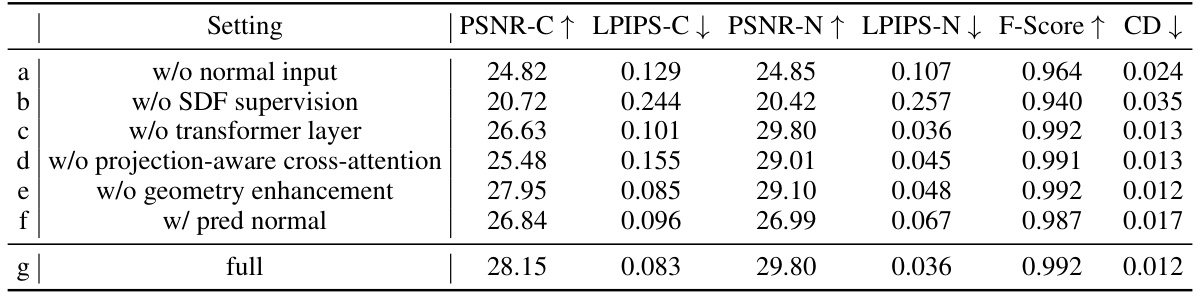
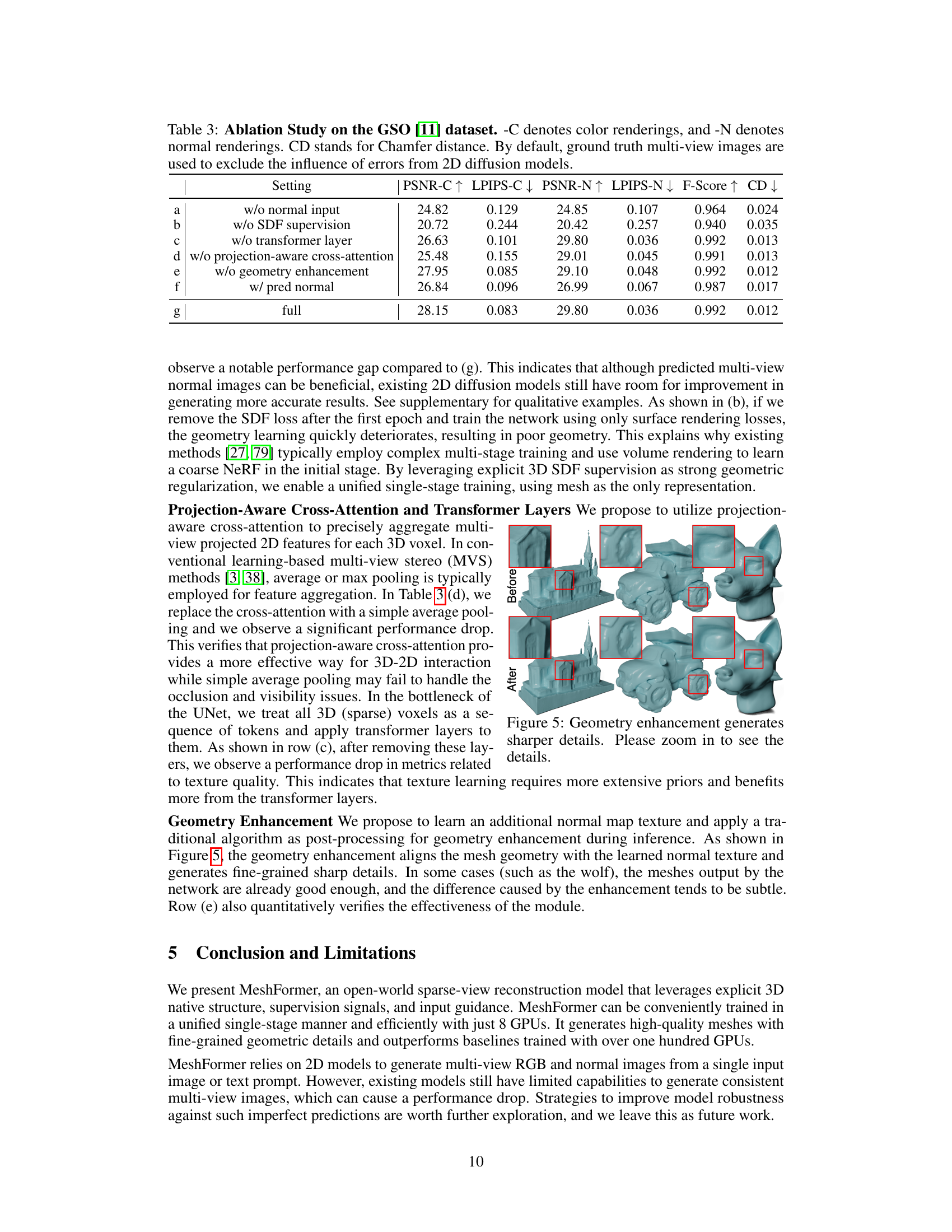
This ablation study analyzes the impact of different components of MeshFormer on the GSO dataset. It shows the performance (PSNR-C, LPIPS-C, PSNR-N, LPIPS-N, F-Score, CD) when removing or altering different parts of the model such as normal inputs, SDF supervision, transformer layers, projection-aware cross-attention, geometry enhancement, or using predicted normals instead of ground truth normals. The ‘full’ row represents the complete MeshFormer model.
This table presents a quantitative comparison of MeshFormer against several state-of-the-art single-view to 3D methods on two benchmark datasets, GSO and OmniObject3D. The evaluation metrics include F-score, Chamfer distance (CD), PSNR, and LPIPS, assessing both the geometry and texture quality of the generated 3D models. All methods used multi-view RGB images predicted by Zero123++ as input, ensuring a fair comparison.
This table presents a quantitative comparison of MeshFormer against several state-of-the-art single/sparse-view to 3D methods on two benchmark datasets: GSO and OmniObject3D. The comparison uses the F-score, Chamfer Distance (CD), PSNR, and LPIPS metrics to evaluate the quality of the generated 3D shapes. All methods use multi-view RGB images predicted by Zero123++ as input.
Full paper#