TL;DR#
Semantic scene completion from LiDAR point clouds is challenging due to information loss and occlusion. Existing methods struggle with geometric incompletion, especially in dynamic scenes. They often rely on single-frame processing, neglecting valuable temporal context. These limitations hinder accurate 3D scene reconstruction.
VPNet tackles these challenges using a dual-branch architecture with a novel Confident Voxel Proposal (CVP) and Multi-Frame Knowledge Distillation (MFKD). CVP models voxel uncertainty, while MFKD effectively combines multi-frame information to enhance completion accuracy. The results show that VPNet achieves superior performance over existing methods on established benchmarks, demonstrating its robustness and potential to improve 3D scene understanding.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of existing semantic scene completion methods by proposing a novel approach that leverages multi-frame information and explicitly models voxel uncertainty. This has significant implications for autonomous driving and other applications that rely on accurate 3D scene understanding from point cloud data. The proposed method achieves state-of-the-art results on standard benchmarks, highlighting its effectiveness and potential to advance research in this rapidly developing field. The introduction of confident voxels and multi-frame knowledge distillation also opens new avenues for future research in scene completion and point cloud processing.
Visual Insights#

🔼 This figure illustrates the overall architecture of the proposed Voxel Proposal Network (VPNet). VPNet is a dual-branch network (BEV and 3D) designed for semantic scene completion. The 3D branch uses Confident Voxel Proposal (CVP) to identify confident voxels, representing multiple possibilities for each voxel and implicitly modeling semantic uncertainty. A multi-frame network and Multi-Frame Knowledge Distillation (MFKD) are integrated to improve the accuracy of voxel label prediction. The BEV branch processes the bird’s-eye-view perspective. The two branches are fused to generate the final completion result. Transparent voxels represent unoccupied space.
read the caption
Figure 1: The architecture of VPNet. It consists of BEV and 3D completion branches. CVP in the 3D branch proposes confident voxels to present possibilities for voxels and model the semantic uncertainty of voxels implicitly. Moreover, we construct a multi-frame network and employ MFKD to enhance the accuracy of uncertainty modeling. We represent free voxels as transparent.
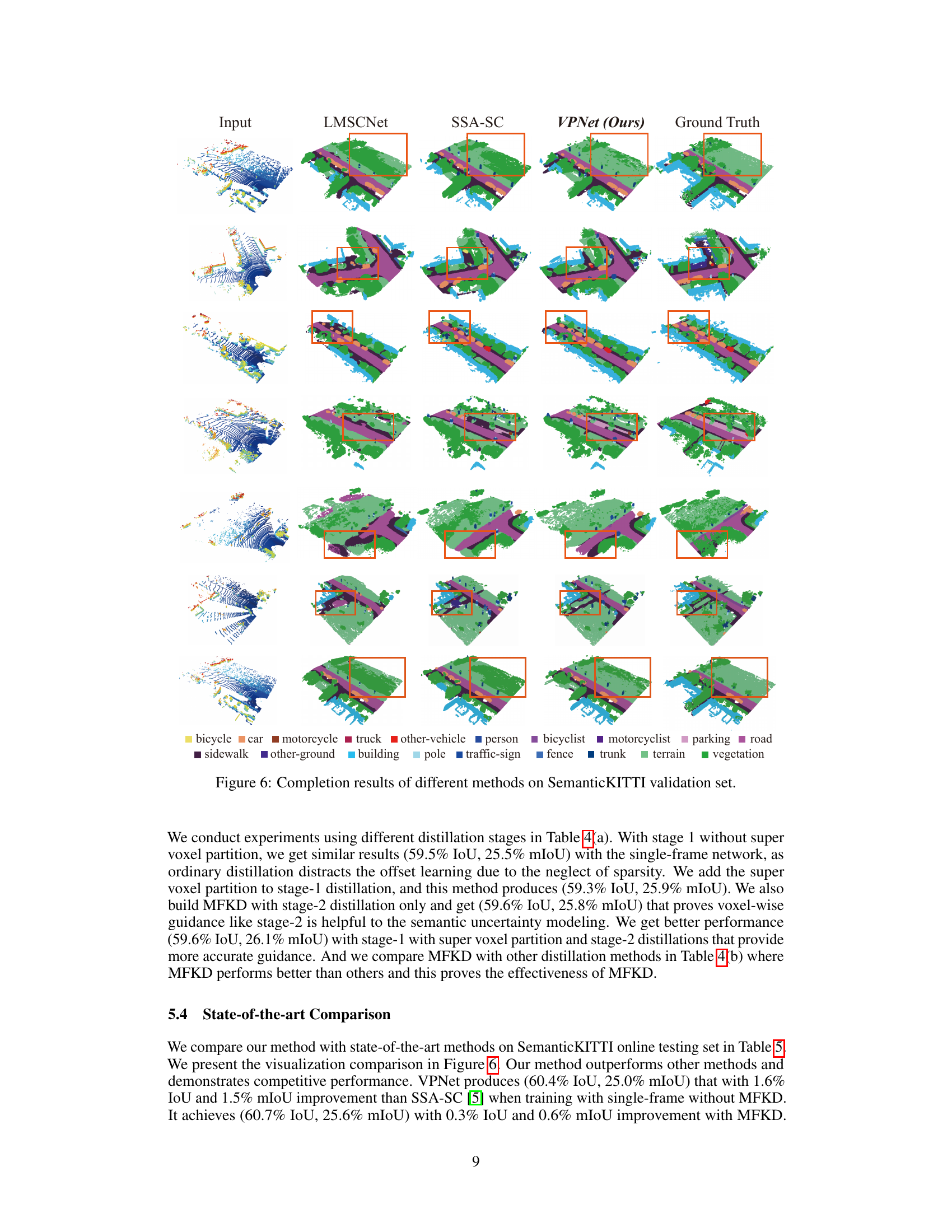
🔼 This table presents an ablation study analyzing the impact of different components of the dual-branch network on the model’s performance. It shows the effect of including or excluding the BEV branch, the 3D segmentation subnetwork, and the 3D completion subnetwork (with and without the CVP module) on the final IoU and mIoU scores.
read the caption
Table 1: Impact of dual-branch network components. 'seg.' means 3D segmentation subnetwork and 'com.' means 3D completion subnetwork.
In-depth insights#
Multi-Frame Fusion#
Multi-frame fusion, in the context of semantic scene completion using LiDAR point clouds, is a crucial technique to overcome the limitations of single-frame data. By integrating information from multiple adjacent frames, temporal consistency and completeness can be significantly enhanced. This is particularly beneficial when dealing with dynamic scenes or scenarios where occlusions are present. The fusion process aims to leverage the complementary information provided by each frame to achieve a more robust and accurate scene representation. Effective strategies for multi-frame fusion often involve carefully aligning and registering the point clouds from different frames, followed by a fusion mechanism to combine the data. Methods like weighted averaging or more sophisticated deep learning-based approaches can be used to integrate the features effectively. The challenge lies in effectively managing the inherent uncertainties and variations across different frames while preserving critical details. Therefore, the design and selection of an appropriate fusion method are critical factors affecting the overall performance of the semantic scene completion system. A well-designed multi-frame fusion strategy can greatly improve the accuracy and reliability of scene reconstruction, particularly in complex and dynamic scenarios.
Voxel Uncertainty#
Voxel uncertainty, in the context of 3D scene completion from point clouds, refers to the inherent ambiguity and unreliability associated with individual voxel labels. Incomplete point cloud data due to sensor limitations or occlusions leads to uncertainty in assigning semantic labels (e.g., car, building, pedestrian) to voxels. Methods that ignore voxel uncertainty often produce inaccurate or incomplete scene reconstructions. Addressing this challenge involves techniques that explicitly model or implicitly capture this uncertainty. This could be achieved via probabilistic methods generating multiple possible labels per voxel, or by using confident voxel proposals, focusing prediction on reliable areas and implicitly handling uncertainty in less certain regions. Multi-frame knowledge distillation can further refine uncertainty estimation by combining information from multiple adjacent frames, mitigating issues caused by individual frame noise and occlusions. Successfully handling voxel uncertainty is crucial for robust and accurate 3D scene completion, enhancing the reliability and usefulness of the reconstructed scenes for applications like autonomous driving and robotics.
CVP Architecture#
A hypothetical “CVP Architecture” section in a research paper would delve into the intricate design of a Confident Voxel Proposal module. It would likely begin by explaining the input, which would be a feature map derived from a point cloud, perhaps enriched with semantic information. The core of the architecture would describe how the CVP generates proposals: a multi-branch approach, possibly utilizing offset learning from occupied voxels. Each branch might process different features or employ varied convolutional filters to generate unique offsets. The section should detail the fusion strategy employed to combine results from multiple branches. It might use weighted averaging, concatenation, or another method to produce a combined, refined set of proposals. The architecture description would then extend to the post-processing steps, such as refinement or filtering, to remove low-confidence proposals. It is also important to discuss the CVP’s mechanisms for handling uncertainty, perhaps through probability distributions. Finally, the section should conclude by outlining the CVP’s output, which should be a set of confident voxel proposals (coordinates and features) ready for subsequent processing stages such as semantic segmentation or scene completion.
MFKD Distillation#
Multi-Frame Knowledge Distillation (MFKD) is a crucial part of the proposed Voxel Proposal Network (VPNet), designed to enhance the accuracy of semantic scene completion by leveraging information from multiple adjacent frames. MFKD operates in two stages. The first stage distills knowledge from individual frames’ confident voxel proposals (CVPs) into the single-frame network, helping it capture the semantic possibilities reflected in each frame separately. This process implicitly models the uncertainty within voxel-wise semantic labels, improving robustness and reducing information loss associated with individual frames. The second stage further refines this uncertainty modeling by distilling the fused representation of multi-frame CVP outputs. By condensing various possibilities of voxel relationships across multiple frames, MFKD enables VPNet to learn and recover lost details and enhance overall scene comprehension, leading to superior semantic completion results. The multi-frame fusion and weighted fusion methods within MFKD are key to its success, allowing for the effective aggregation and integration of information across different frames.
Future Enhancements#
Future enhancements for this semantic scene completion method could focus on several key areas. Improving the robustness to noisy or incomplete point cloud data is crucial, perhaps through the integration of more sophisticated outlier rejection techniques or data augmentation strategies. The current approach relies on a single-round offset learning and feature propagation. An iterative refinement process could significantly boost accuracy and detailed geometric reconstruction. Exploring alternative feature extraction and fusion methods, beyond simple MLPs and concatenation, such as graph convolutional networks or transformers, could unlock richer contextual information and lead to better semantic understanding. Finally, extending the framework to handle dynamic scenes with more complex movements would be a significant step towards real-world applicability. This might involve incorporating temporal context through recurrent neural networks or attention mechanisms that explicitly model changes in scene elements across multiple frames. Addressing these points will enhance the system’s generalizability and practical utility.
More visual insights#
More on figures

🔼 This figure illustrates the process of Confident Voxel Proposal (CVP) and Multi-Frame Knowledge Distillation (MFKD). In the single-frame network, the segmentation subnetwork generates semantics embedded feature maps. CVP then uses these maps to generate confident feature maps, modeling semantic uncertainty through multiple branches. The multi-frame network processes multiple frames, each generating an augmented feature map. MFKD distills knowledge from this multi-frame network to enhance the single-frame network’s predictions in two stages. Stage-1 aligns the multi-frame feature maps with the single-frame branches. Stage-2 condenses multi-frame possibilities into the single-frame augmented feature map.
read the caption
Figure 2: The pipeline of CVP and MFKD. The semantics feature maps are produced with a segmentation subnetwork in the 3D branch.
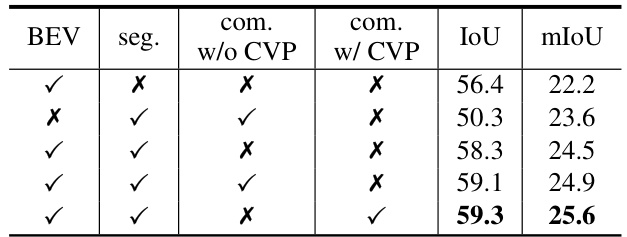
🔼 This figure illustrates the process of confident voxel proposal (CVP) in the 3D completion branch of VPNet. The CVP aims to identify confident voxels with high reliability, implicitly representing voxel-wise semantic uncertainty. The process is split into two stages: (a) Offset learning, where random noise is introduced to the occupied voxel coordinates and features to generate a set of offsets using an MLP (Fᵢ). (b) Voxel proposal, where these offsets are used to propagate features to neighboring voxels. The figure shows how feature interpolation, concatenation, and weighting are used to create the confident voxel coordinates (Gq) and features (Yq), which form the confident feature map (Eq).
read the caption
Figure 3: Branch i of confident voxel proposal (CVP), we divide it into two steps: (a) offset learning and (b) voxel proposal.
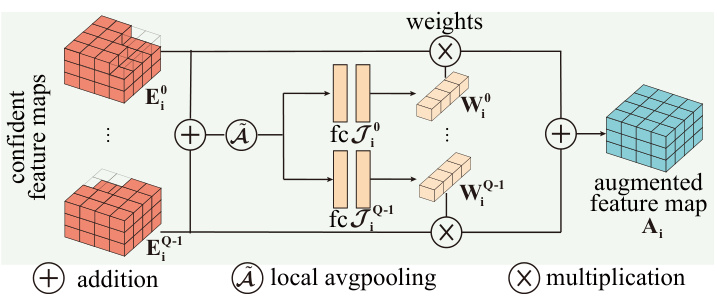
🔼 This figure shows the architecture of multi-branch fusion used in the Confident Voxel Proposal (CVP) module. Multiple confident feature maps (E0 to EQ-1) from different branches are first summed using an addition operation. Then, local average pooling (Ã) is applied to compress the feature maps. Finally, a fully connected layer (fc qi) is used for each branch, followed by weighted multiplication (X) with weights Wqi. The results are summed again, producing the final augmented feature map (Ai). This process effectively combines information from multiple branches, modeling the uncertainty of voxel semantic labels.
read the caption
Figure 4: Architecture of the multi-branch fusion.
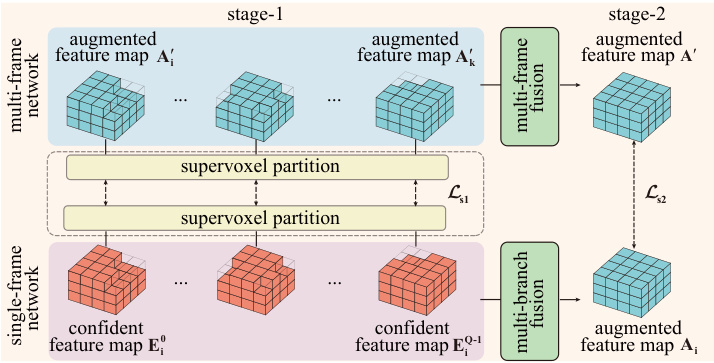
🔼 This figure illustrates the process of Confident Voxel Proposal (CVP) and Multi-Frame Knowledge Distillation (MFKD). The 3D branch’s segmentation subnetwork generates semantic feature maps. CVP then uses these maps to propose confident voxels, representing multiple semantic label possibilities. MFKD, a two-stage distillation process, condenses information from multiple frames to enhance the single-frame network’s accuracy. Stage-1 compares multi-frame and single-frame confident feature maps to guide the single-frame CVP branches. Stage-2 further refines the single-frame representation by distilling the fused multi-frame augmented feature map.
read the caption
Figure 2: The pipeline of CVP and MFKD. The semantics feature maps are produced with a segmentation subnetwork in the 3D branch.

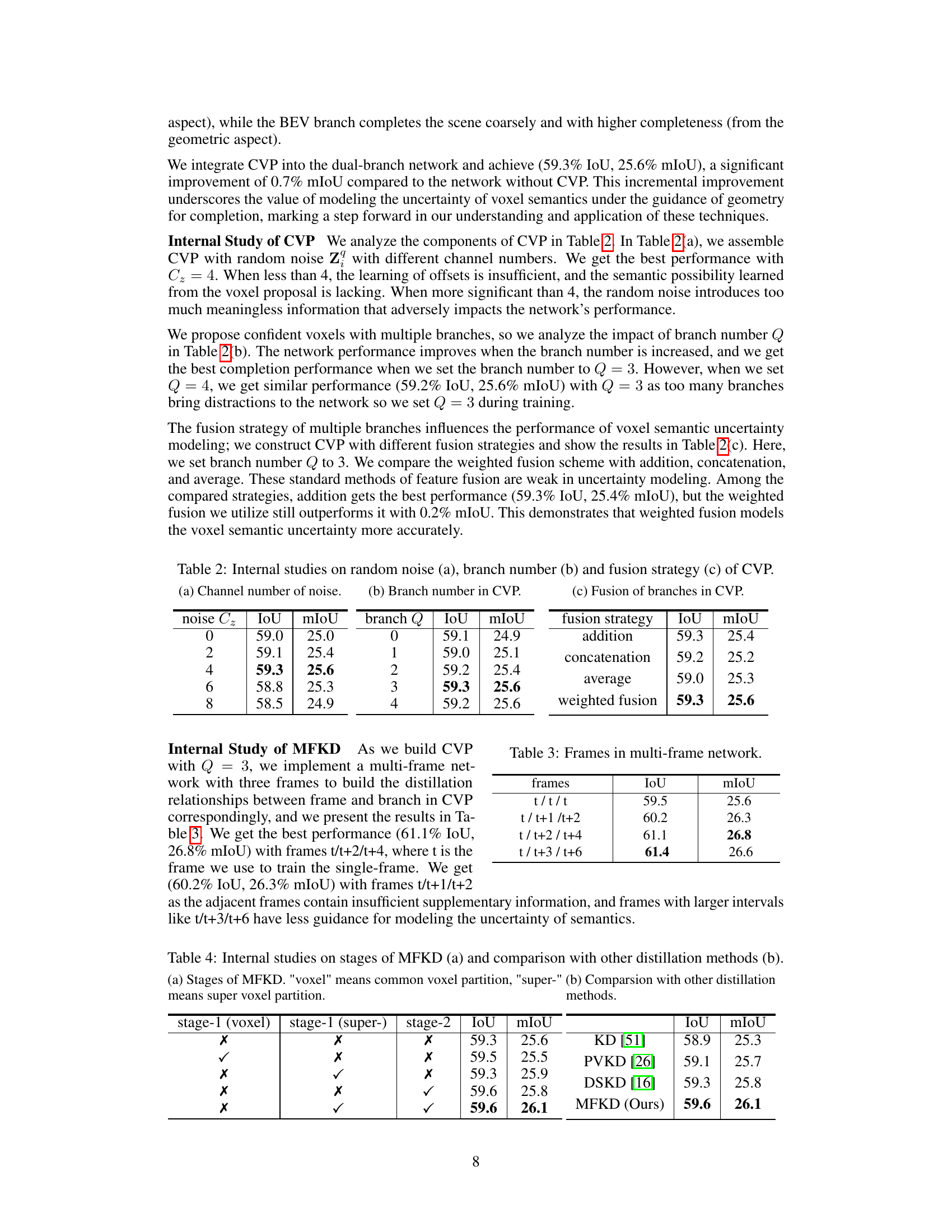
🔼 This figure compares the semantic scene completion results of different methods on the SemanticKITTI validation set. It shows input point clouds and the results generated by LMSCNet, SSA-SC, VPNet (the authors’ method), and the ground truth. Each row represents a different scene, and the color-coding indicates different semantic classes (e.g., car, person, building, road). The figure visually demonstrates VPNet’s improved performance in completing the scene and correctly classifying objects compared to the other methods. Orange boxes highlight specific areas where VPNet shows more accurate or complete results.
read the caption
Figure 6: Completion results of different methods on SemanticKITTI validation set.
More on tables

🔼 This table presents the ablation study results for the Confident Voxel Proposal (CVP) module. It explores the impact of different hyperparameters and design choices on the performance of CVP. Specifically, it investigates: (a) the effect of varying the number of channels in the random noise input (noise Cz); (b) the influence of using different numbers of branches (branch Q) in CVP; and (c) the impact of adopting different fusion strategies for combining the outputs of multiple branches in CVP. The results are evaluated using the Intersection over Union (IoU) and mean Intersection over Union (mIoU) metrics.
read the caption
Table 2: Internal studies on random noise (a), branch number (b) and fusion strategy (c) of CVP.
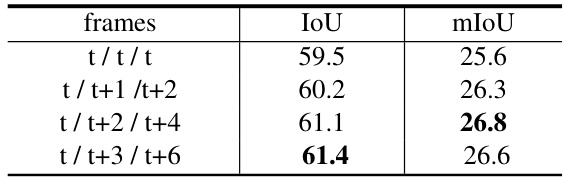
🔼 This table shows the result of experiments using different frame combinations in the multi-frame network. The goal is to find the optimal frame combination that best improves the performance of the model. The table shows that using frames t/t+2/t+4 yields the best performance, with an IoU of 61.1 and mIoU of 26.8.
read the caption
Table 3: Frames in multi-frame network.

🔼 This table presents an ablation study on the effectiveness of the multi-frame knowledge distillation (MFKD) method used in the paper. Part (a) shows the results of experiments conducted with different configurations of MFKD, specifically varying the use of voxel and super-voxel partition in stage-1 and whether stage-2 is included. The results demonstrate that combining super-voxel partition in stage-1 and including stage-2 improves the performance significantly. Part (b) compares MFKD to other existing knowledge distillation methods, illustrating that MFKD achieves the best overall results.
read the caption
Table 4: Internal studies on stages of MFKD (a) and comparison with other distillation methods (b).
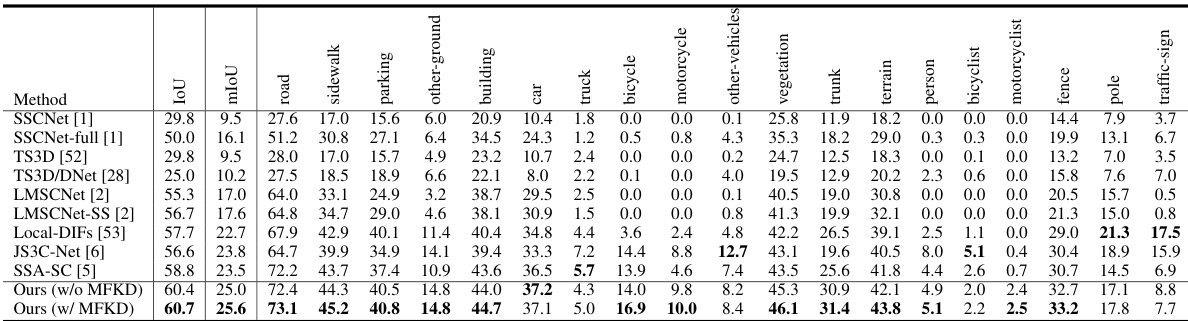
🔼 This table compares the performance of the proposed VPNet model against other state-of-the-art semantic scene completion methods on the SemanticKITTI online testing dataset. It provides a quantitative evaluation across various metrics (IoU and mIoU) and individual semantic classes (road, sidewalk, parking, etc.). The results illustrate VPNet’s performance improvements over existing methods.
read the caption
Table 5. Comparison of VPNet with other works on SemanticKITTI online testing set.
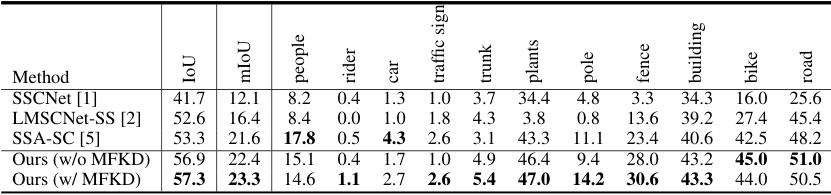
🔼 This table compares the performance of VPNet with other state-of-the-art methods on the SemanticPOSS validation dataset. It shows the Intersection over Union (IoU) scores for each semantic category and the mean IoU (mIoU) across all categories. This allows for a direct comparison of VPNet’s accuracy in semantic scene completion against existing techniques on this specific dataset.
read the caption
Table 6: Comparison of VPNet with other works on SemanticPOSS validation set.
Full paper#