TL;DR#
Multi-agent games present significant challenges for AI due to complex dynamics and opponent strategies. Existing methods often suffer from slow convergence and instability. This is particularly problematic in partially observable environments where agents lack complete information about the game state and opponent actions.
To tackle these issues, this paper introduces IMAX-PPO, a novel algorithm that combines multi-agent reinforcement learning (MARL) with imitation learning (IL). IMAX-PPO uses an IL model to predict the next states of opponents, even with limited observations. This prediction is then integrated into a modified Proximal Policy Optimization (PPO) algorithm to improve the policy learning of allied agents. Extensive experiments in three complex environments demonstrate that IMAX-PPO significantly outperforms state-of-the-art MARL algorithms, achieving superior performance and faster convergence.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to enhance multi-agent reinforcement learning (MARL) by integrating imitation learning (IL). This addresses the limitations of existing MARL algorithms that struggle with slow convergence and instability in complex scenarios, especially those with partially observable environments. The proposed IMAX-PPO algorithm achieves superior performance across various challenging game environments. This work opens new avenues for research, particularly in improving the efficiency of MARL algorithms and handling uncertainties in partially observable multi-agent games.
Visual Insights#

🔼 This figure illustrates the IMAX-PPO algorithm’s architecture. Each allied agent receives local observations, including its own state and the states of nearby allies and enemies. The Imitation Learning (IL) component predicts the next states of neighboring enemies using this local information, augmenting the input to the MAPPO policy. Non-neighboring enemy information is masked out.
read the caption
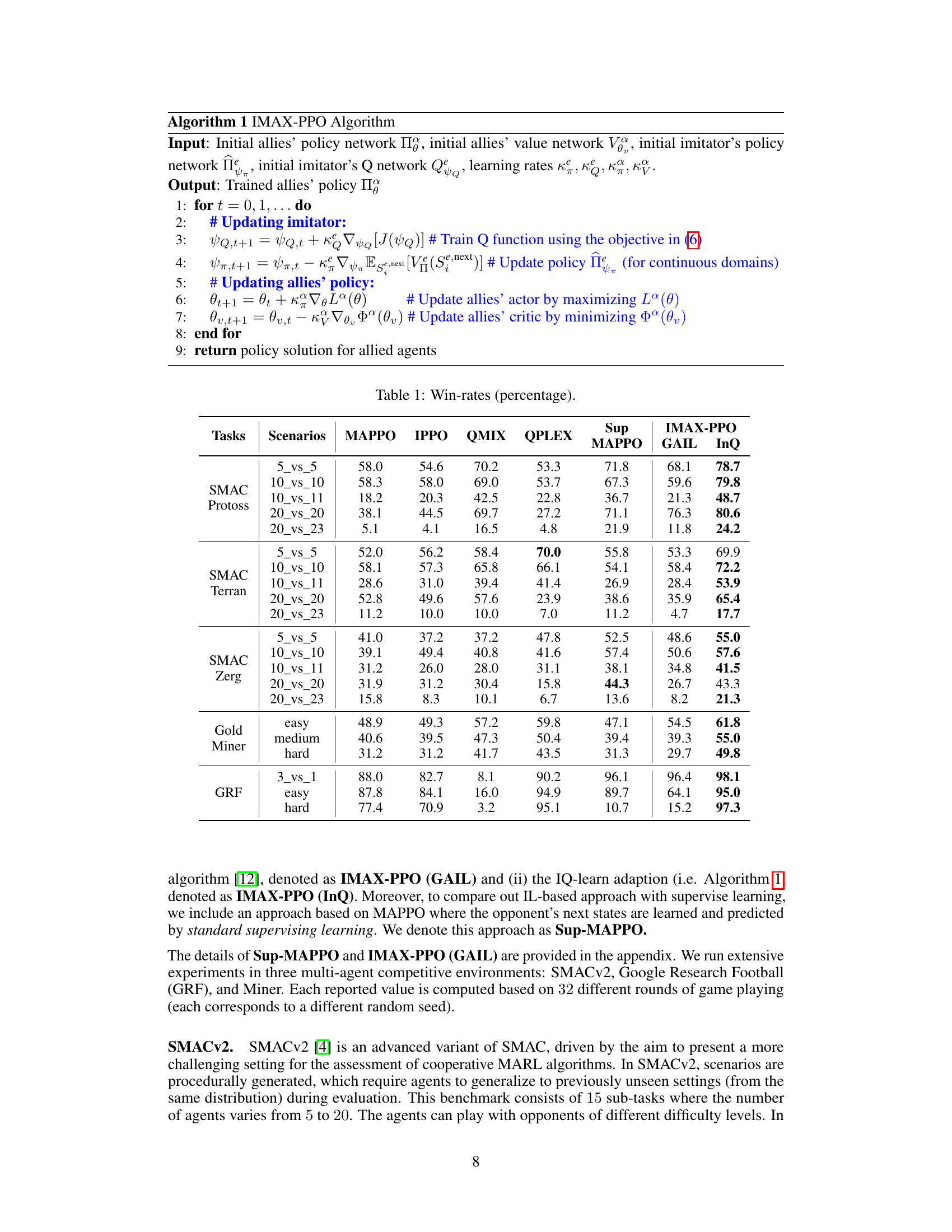
Figure 1: An overview of our IMAX-PPO algorithm. Each local observation of of an ally agent i includes information about itself, as well as enemy and ally agents in its neighborhood (which changes over time). The output of the IL component is the predicted next states of neighboring enemy agents (predictions for the non-neighbor enemies will be masked out).
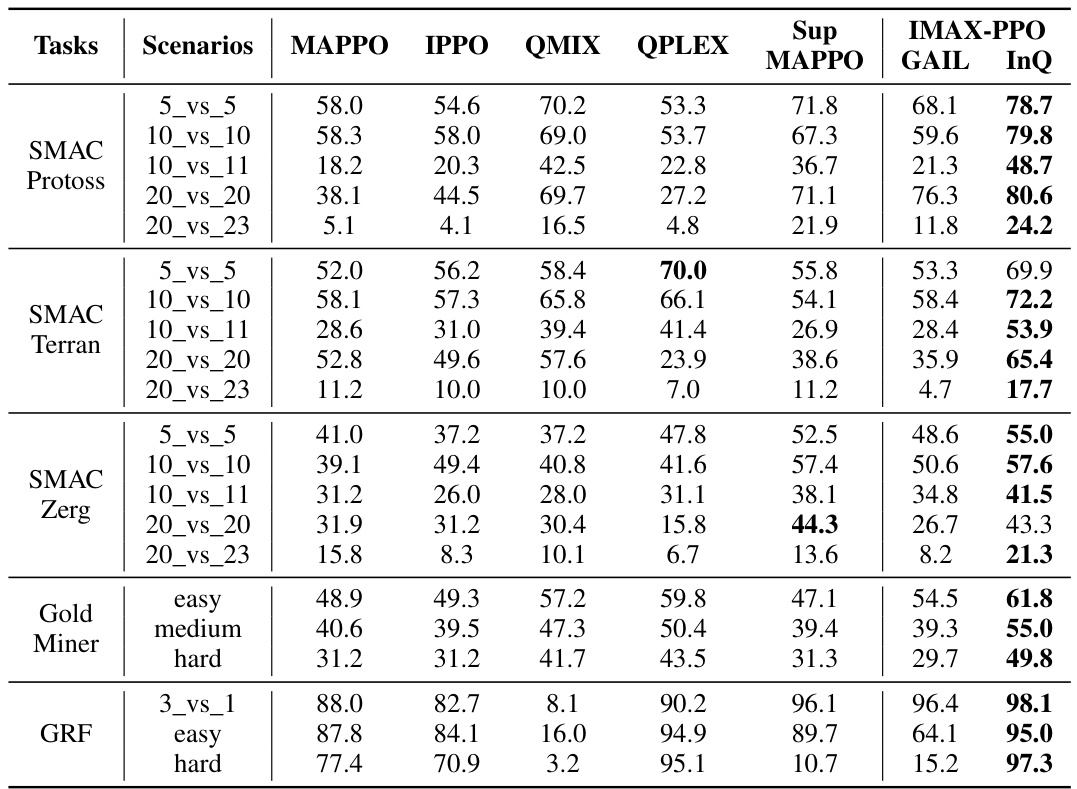
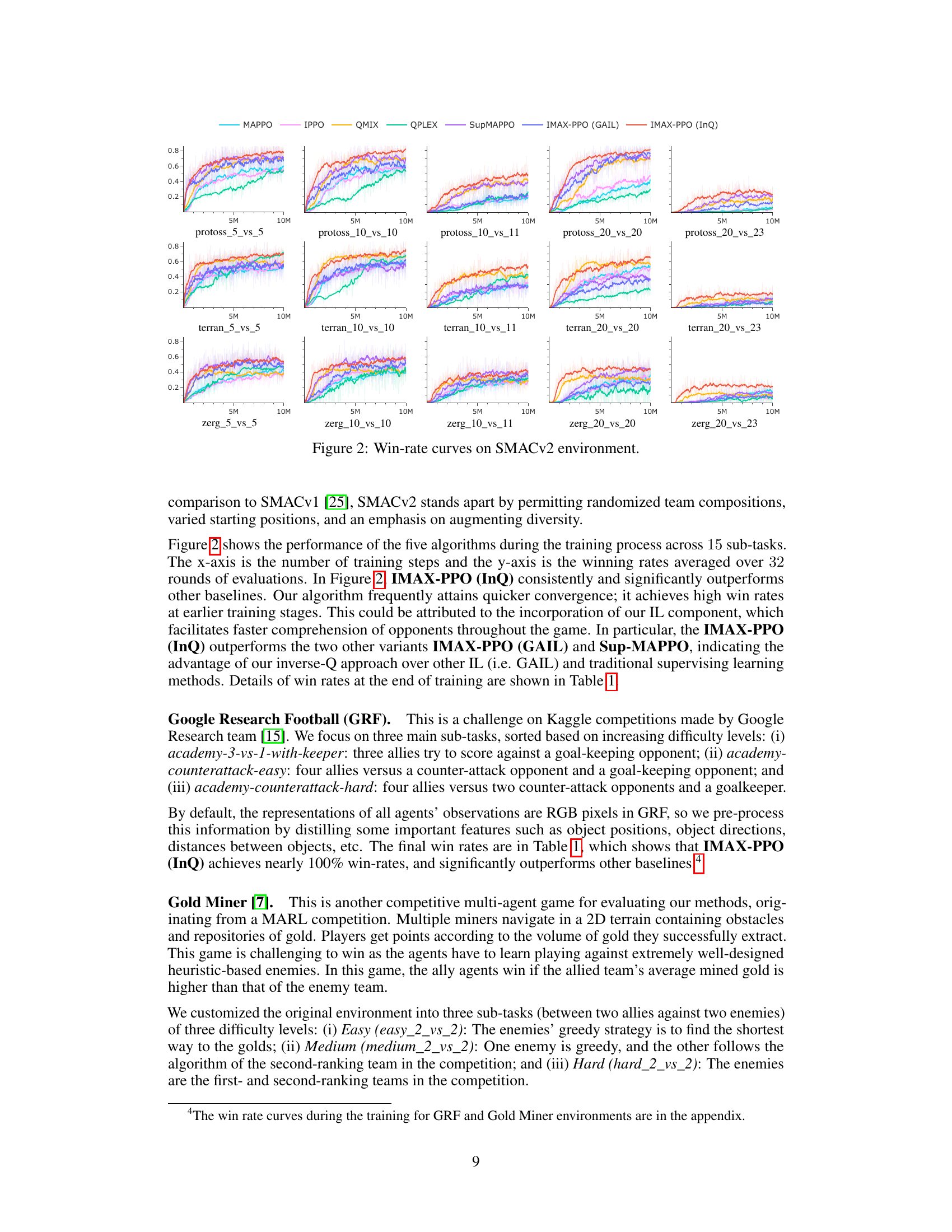
🔼 This table presents the win rates achieved by different multi-agent reinforcement learning algorithms across various scenarios in three benchmark environments: SMACv2, Google Research Football (GRF), and Gold Miner. The algorithms compared include MAPPO, IPPO, QMIX, QPLEX, Sup-MAPPO, IMAX-PPO (GAIL), and IMAX-PPO (InQ). The scenarios vary in terms of the number of agents involved and the complexity of the tasks. The table allows for a comparison of the performance of the proposed IMAX-PPO algorithm against state-of-the-art baselines.
read the caption
Table 1: Win-rates (percentage).
In-depth insights#
Opponent Policy IL#
Opponent policy imitation learning (IL) in multi-agent reinforcement learning (MARL) tackles the challenge of hidden opponent actions by focusing on predicting their next states rather than directly imitating their policies. This approach is particularly useful in partially observable environments where agents have limited information about opponents. The key innovation lies in framing opponent state prediction as a new multi-agent IL problem, leveraging techniques like IQ-Learn, adapted to handle the constraints of local observations and unobservable actions. This indirect imitation strategy is more robust than direct policy imitation, mitigating the impact of the ever-changing opponent policies and the limitations of local sensing. The theoretical analysis further supports this approach by providing bounds on the influence of allied agents’ policy changes on the accuracy of opponent state prediction. Ultimately, this clever strategy enables a more effective and stable MARL training process, achieving superior performance compared to state-of-the-art methods.
IMAX-PPO Alg#
The IMAX-PPO algorithm represents a novel approach to multi-agent reinforcement learning (MARL), combining policy gradient methods with imitation learning (IL). It tackles the challenge of partially observable environments and hidden opponent actions by integrating an imitation component. This component, a multi-agent IL model adapted from IQ-Learn, predicts opponent’s next states using only local observations, providing valuable contextual information for the primary policy. This integration enhances the policy’s ability to anticipate and react to opponent behavior, leading to improved performance and stability. The theoretical analysis provided further supports the algorithm’s robustness by bounding the effect of changing allied agent policies on the IL component’s accuracy. Experimental results demonstrate IMAX-PPO’s superiority over other state-of-the-art MARL algorithms across diverse environments, showcasing its effectiveness and generalizability.
Local Obs. IL#
The heading ‘Local Obs. IL’ likely refers to a section detailing an imitation learning (IL) model operating under conditions of local observability. This is crucial in multi-agent scenarios where agents might lack global knowledge of the environment or other agents’ actions. The core idea is to leverage limited, local observations to predict the actions of other agents, likely opponents. This differs from traditional IL, which often assumes complete state observability. The use of local observations is a key innovation, allowing the algorithm to function in realistic multi-agent environments where complete information is rarely available. It might also address challenges related to the computational complexity of global-state methods. The effectiveness of this approach would depend on factors such as how well local observations correlate with opponents’ actions and strategies, and how well the learned model generalizes to unseen situations. Addressing potential limitations of local information, such as the susceptibility to noisy or incomplete data, is critical to ensuring the robust performance of the method. The ‘Local Obs. IL’ section likely provides details on the architecture, training process, and evaluation metrics of this novel approach.
Multi-Agent IL#
Multi-agent imitation learning (IL) tackles the complexities of training agents within multi-agent environments. The core challenge lies in the intricate interplay between agents, where each agent’s actions are influenced by, and in turn influence, the behavior of others. This contrasts with single-agent IL, where the learning process is independent of other agents. In multi-agent scenarios, the dynamics of the environment become highly coupled, necessitating advanced strategies that go beyond simple imitation to accurately predict opponent strategies and anticipate their actions. Effective multi-agent IL must carefully consider partial observability (where each agent has limited information about the global state), the non-stationarity of opponent policies, and the inherent difficulties in directly observing or inferring the actions of other agents. Solutions often involve sophisticated modeling techniques such as inferring opponent intentions through state prediction rather than explicit action imitation. This necessitates innovative reward functions that accurately capture the complexities of the game dynamics. The design of such algorithms therefore represents a significant and active area of research within the broader field of reinforcement learning.
Future Work#
Future research directions stemming from this work on imitation learning in multi-agent reinforcement learning (MARL) could explore several promising avenues. Extending the approach to fully observable environments, where agents have complete knowledge of all aspects of the game state, would allow for a direct comparison with existing state-of-the-art methods. Investigating the impact of more complex opponent policies and game dynamics would assess the model’s robustness and generalizability. Further theoretical analysis could provide tighter performance bounds and a deeper understanding of the algorithm’s convergence properties. Additionally, applying the imitation-enhanced approach to different MARL problem settings would expand its applicability and impact, potentially including cooperative, competitive, and mixed scenarios. Finally, developing more efficient and scalable algorithms remains a key goal to overcome limitations associated with computation and training time.
More visual insights#
More on figures
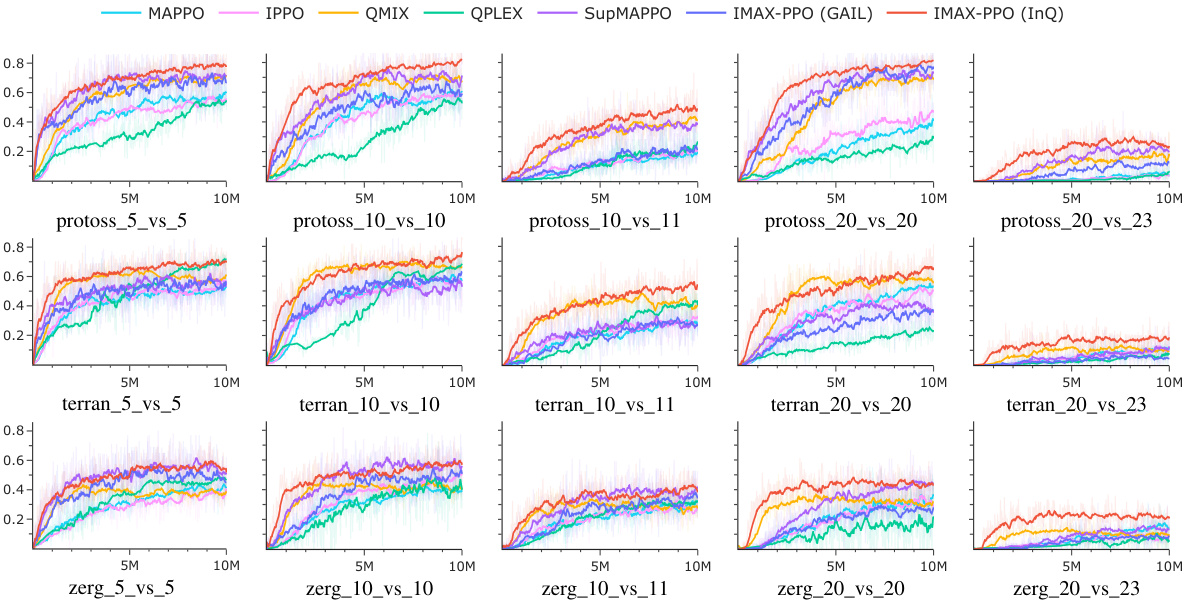
🔼 This figure presents the win-rate curves for seven different multi-agent reinforcement learning algorithms across fifteen sub-tasks in the SMACv2 environment. The x-axis represents the number of training steps, and the y-axis represents the win rate, averaged over 32 rounds of evaluation. Each sub-task corresponds to a specific scenario with varying numbers of allies and enemies. The figure highlights the relative performance of the algorithms in terms of convergence speed and final win rate.
read the caption
Figure 2: Win-rate curves on SMACv2 environment.
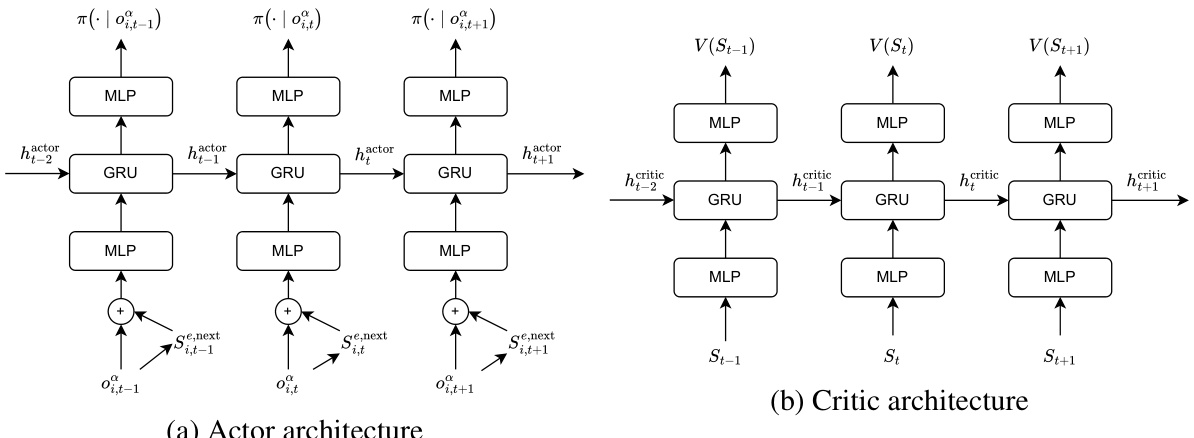
🔼 This figure shows a schematic of the IMAX-PPO algorithm. Each allied agent receives local observations (its own state and those of nearby allies and enemies). An imitation learning (IL) component predicts the next states of nearby enemy agents. This prediction, along with the agent’s local observations, is fed into the main multi-agent actor-critic algorithm (MAPPO) to improve the policy learning of allied agents. The algorithm is decentralized, meaning agents act independently, but the critic utilizes global information.
read the caption
Figure 1: An overview of our IMAX-PPO algorithm. Each local observation of of an ally agent i includes information about itself, as well as enemy and ally agents in its neighborhood (which changes over time). The output of the IL component is the predicted next states of neighboring enemy agents (predictions for the non-neighbor enemies will be masked out).
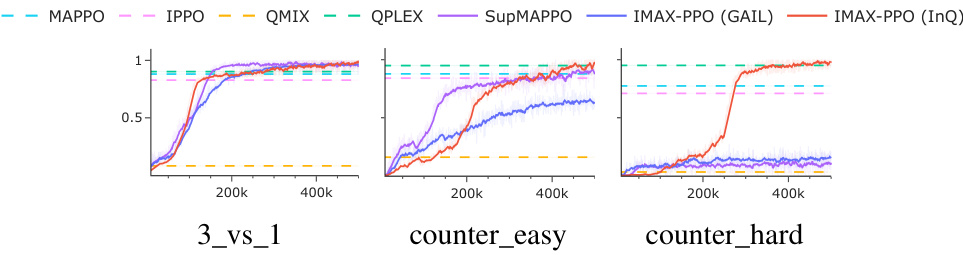
🔼 This figure shows the win rates of different MARL algorithms (MAPPO, IPPO, QMIX, QPLEX, SupMAPPO, IMAX-PPO (GAIL), and IMAX-PPO (InQ)) across three different GRF scenarios (3_vs_1, counter_easy, and counter_hard) plotted against training steps. The horizontal dashed lines represent the average win rates obtained by each algorithm after training. The results demonstrate that IMAX-PPO (InQ) consistently achieves the highest win rate across all scenarios, showcasing its superior performance compared to other state-of-the-art algorithms.
read the caption
Figure 4: Win-rate curves on GRF environment.

🔼 The figure shows the win rates of different multi-agent reinforcement learning algorithms in the Gold Miner environment over the course of training. The x-axis represents the number of training steps, and the y-axis represents the win rate. The algorithms compared include MAPPO, IPPO, QMIX, QPLEX, SupMAPPO, IMAX-PPO (GAIL), and IMAX-PPO (InQ). The Gold Miner environment has three difficulty levels: easy, medium, and hard, each represented by a separate plot. IMAX-PPO (InQ) consistently outperforms other methods across all difficulty levels.
read the caption
Figure 5: Win-rate curves on Gold Miner environment.
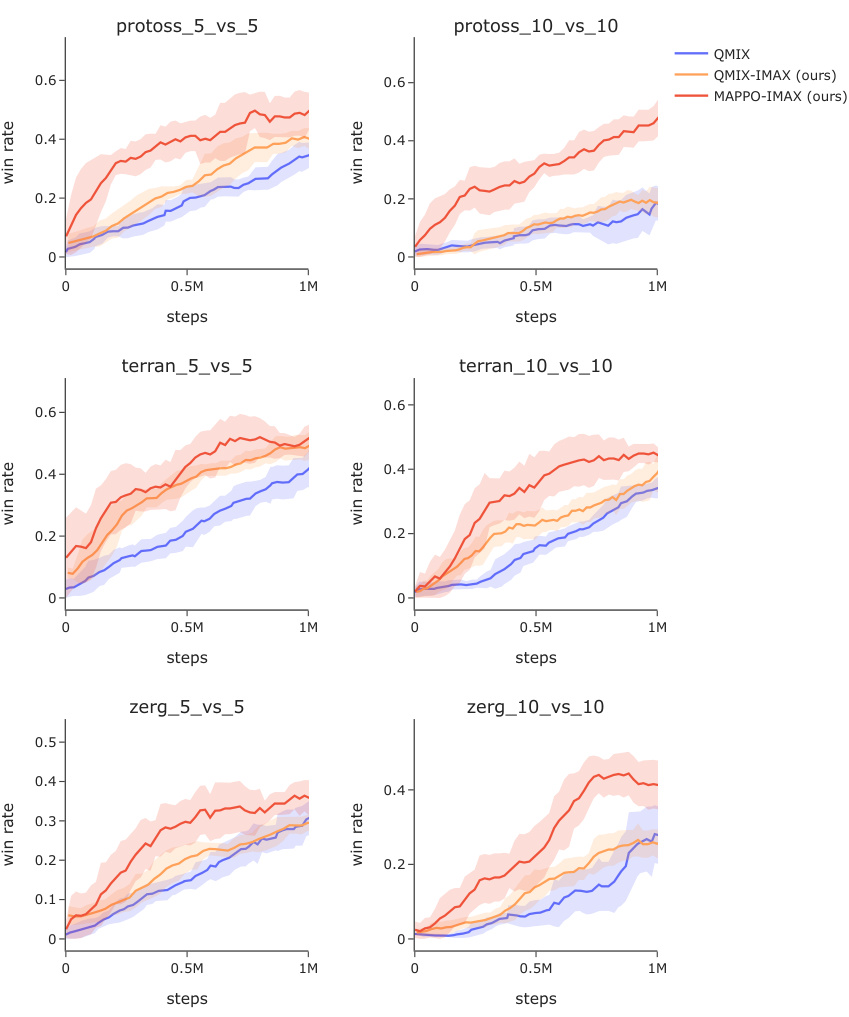
🔼 This figure compares the learning curves of different multi-agent reinforcement learning algorithms on SMACv2, a challenging StarCraft II benchmark. The x-axis represents the number of training steps, while the y-axis shows the win rate. The algorithms compared include QMIX, QMIX-IMAX (the authors’ proposed algorithm integrating imitation learning), and MAPPO-IMAX (another variant of the authors’ algorithm using MAPPO as the baseline). The figure is divided into subplots, each showing results for a different combination of faction (Protoss, Terran, Zerg) and team size (5 vs. 5, 10 vs. 10). The shaded areas represent the standard deviation across multiple runs, showing variability in performance.
read the caption
Figure 6: Learning curves with different methods on SMACv2.
More on tables

🔼 This table presents the win rates achieved by different multi-agent reinforcement learning algorithms across various tasks and scenarios. The algorithms compared include MAPPO, IPPO, QMIX, QPLEX, Sup-MAPPO, IMAX-PPO (GAIL), and IMAX-PPO (InQ). The tasks are categorized into SMAC (with sub-categories for Protoss, Terran, and Zerg agents), Gold Miner, and GRF. Each task has multiple scenarios representing different numbers of agents and game complexities. The win rates are percentages, showing the success rate of each algorithm in each scenario.
read the caption
Table 1: Win-rates (percentage).
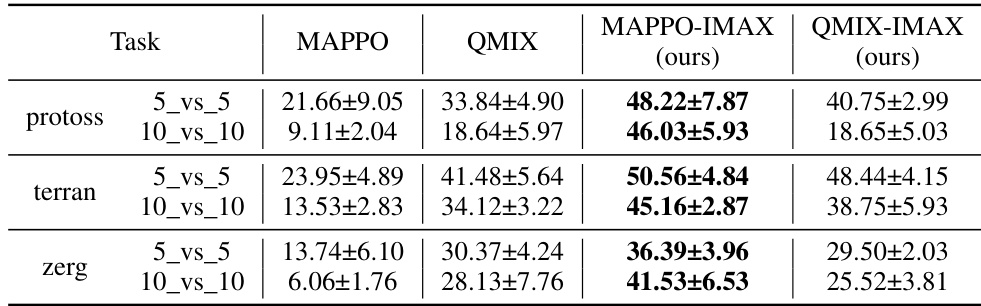
🔼 This table presents the win rates achieved by different multi-agent reinforcement learning algorithms across various scenarios in three game environments: SMACv2 (StarCraft Multi-Agent Challenge), GRF (Google Research Football), and Gold Miner. The algorithms compared include MAPPO, IPPO, QMIX, QPLEX, Sup-MAPPO (MAPPO with supervised learning for opponent prediction), IMAX-PPO (GAIL) (our algorithm using Generative Adversarial Imitation Learning for opponent modeling), and IMAX-PPO (InQ) (our algorithm using Inverse Soft-Q Learning for opponent modeling). Different scenarios within each game environment are tested, varying the number of agents (e.g., 5 vs 5, 10 vs 10) and the race (Protoss, Terran, Zerg for SMACv2). The table showcases the superior performance of the IMAX-PPO algorithms, particularly IMAX-PPO (InQ), compared to the baselines across most scenarios.
read the caption
Table 1: Win-rates (percentage).
Full paper#