TL;DR#
Current image generation methods often require training separate models for different visual content types, limiting efficiency and scalability. Additionally, finetuning pretrained models to generate new types of visual content is often expensive and can lead to overfitting. This paper tackles these issues by focusing on diffusion models, a powerful class of generative models that have achieved remarkable success in generating high-quality images. However, directly applying diffusion models to diverse visual content types is challenging due to the lack of suitable training datasets for each type.
The paper introduces SyncTweedies, a general framework for synchronizing multiple diffusion processes. It achieves synchronization without finetuning by cleverly averaging outputs in a canonical space, preserving the richness of pretrained models while maintaining high performance. The authors demonstrate SyncTweedies’ efficacy across a variety of applications, such as generating ambiguous images, panoramic images, and 3D textures, consistently outperforming state-of-the-art methods in each scenario. This innovative approach significantly expands the capabilities of pretrained diffusion models and opens doors for future research in zero-shot, high-quality visual content generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on generative models and image synthesis. It introduces a novel, zero-shot diffusion synchronization framework that outperforms existing methods in various applications. This opens new avenues for generating diverse and high-quality visual content without extensive fine-tuning, addressing a key limitation of current techniques. The broad applicability and superior performance of the proposed framework make it a valuable contribution to the field.
Visual Insights#

🔼 This figure showcases various examples of visual content generated using the SyncTweedies method. It demonstrates the model’s ability to generate diverse outputs, including ambiguous images (like different viewpoints of a single object), panoramic images (360° views), 3D mesh textures (applying textures onto 3D models), and 3D Gaussian splat textures. Notably, the method achieves this without requiring any fine-tuning for specific visual content, highlighting its generality and efficiency.
read the caption
Figure 1: Diverse visual content generated by SyncTweedies: A diffusion synchronization process applicable to various downstream tasks without finetuning.
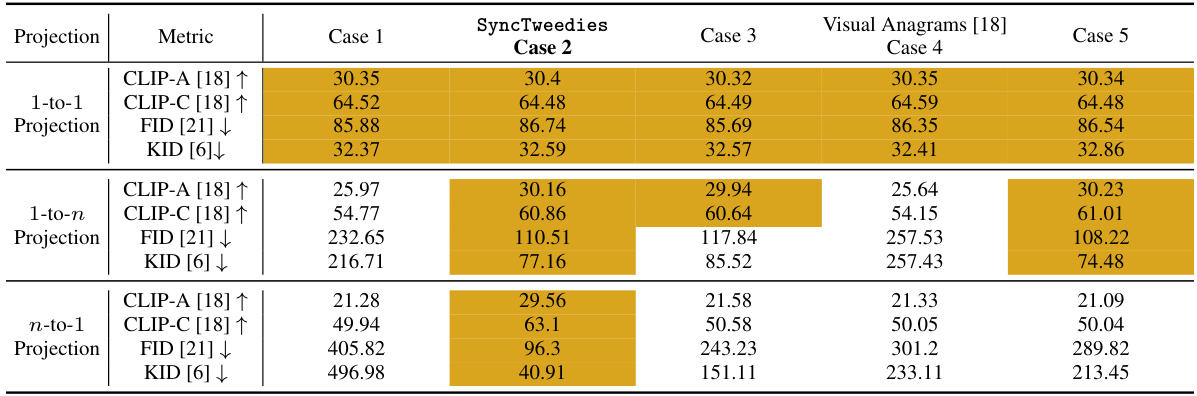
🔼 This table presents a quantitative comparison of different diffusion synchronization methods (Cases 1-5) and Visual Anagrams [18] (Case 4) for ambiguous image generation. The metrics used for comparison include CLIP-A [18], CLIP-C [18], FID [21], and KID [6]. The table highlights the best-performing method (within 95% of the best) for each metric and projection type (1-to-1, 1-to-n, and n-to-1). The KID values are scaled by 103 for easier comparison. The results indicate the relative performance of each method under different scenarios of image transformation.
read the caption
Table 1: A quantitative comparison in ambiguous image generation. KID [6] is scaled by 103. For each row, we highlight the column whose value is within 95% of the best.
In-depth insights#
Sync Diffusion#
The concept of “Sync Diffusion” in a research paper likely refers to methods that synchronize or coordinate multiple diffusion processes. This could involve using a shared latent space or employing clever aggregation strategies to ensure consistency across different diffusion models or instances. The key challenge is harmonizing outputs from separate diffusions, perhaps by averaging results or employing a more sophisticated reconciliation technique. This is especially important when generating diverse or ambiguous outputs, as a synchronized approach ensures that generated content is coherent and not fragmented. One potential application lies in creating consistent textures across multiple views of a 3D model, ensuring a seamless visual experience. Similarly, it could be used to generate images exhibiting different appearances under various transformations (ambiguous images), where the goal is to maintain a consistent underlying representation. Effective synchronization is critical; otherwise, inconsistencies and artifacts could significantly degrade the quality and realism of generated content. The paper would likely delve into various synchronization strategies, comparing their effectiveness based on various metrics. The success of Sync Diffusion hinges on finding efficient, effective approaches to merge the individual diffusion model outputs while preserving the inherent generative power of each model.
Zero-Shot Learning#
Zero-shot learning (ZSL) aims to enable models to recognize or classify unseen classes during testing, having only trained on a subset of classes. This is achieved by leveraging auxiliary information, such as semantic descriptions or visual attributes, to bridge the gap between seen and unseen classes. A key challenge in ZSL is the domain adaptation problem, as the distributions of seen and unseen classes may differ significantly, leading to performance degradation. Methods such as attribute prediction, data augmentation, and transfer learning are employed to address this issue. However, generalization to entirely new, unseen domains remains a significant hurdle. The success of ZSL is highly dependent on the quality and relevance of the auxiliary information used and the effectiveness of the chosen approach in mitigating the domain adaptation challenge. Future research may focus on developing more robust and adaptable methods that are less reliant on the availability of comprehensive auxiliary information, and can effectively transfer knowledge across vastly different visual domains.
Tweedie’s Formula#
Tweedie’s formula, in the context of diffusion models, plays a crucial role in the denoising process. It elegantly bridges the gap between the noisy observation at a given timestep and the underlying clean data point. Its application within the SyncTweedies framework is particularly significant. The framework leverages Tweedie’s formula to synchronize multiple diffusion processes operating in separate instance spaces. By averaging the outputs of Tweedie’s formula across these spaces in the canonical space, SyncTweedies achieves a robust and efficient method for generating diverse visual content. This synchronization is key to overcoming limitations faced by previous methods that relied on finetuning, which often leads to overfitting and reduced generalizability. The analysis of Tweedie’s formula’s behavior within SyncTweedies reveals that its use enhances the stability and quality of the generated outputs, making it a powerful tool for zero-shot generation across diverse applications.
Diverse Applications#
A research paper section on “Diverse Applications” would explore the versatility and adaptability of a proposed method across various domains. It would likely showcase successful implementations in diverse fields, highlighting the method’s ability to solve different types of problems. Strong evidence of applicability across various problem domains is crucial for demonstrating the method’s generalizability and practical significance. The section should present a compelling narrative, showing how the core methodology adapts to varying contexts and data types while maintaining its core effectiveness. Detailed experimental results, including quantitative metrics and qualitative analyses of each application, are essential. This section needs to go beyond simply listing applications and should focus on analyzing the nuanced aspects of each implementation and what makes the method particularly well-suited for each task. The discussion should highlight the key challenges and limitations specific to each application area, providing a balanced view of the method’s successes and limitations. It would be beneficial to compare the performance of the proposed method with existing state-of-the-art techniques within each application domain. This comparison would allow for a more robust assessment of the proposed method’s contribution to the respective fields. The use of visuals, such as tables and figures, would greatly enhance the readability and impact of the “Diverse Applications” section.
Limitations#
A thoughtful discussion on limitations within a research paper is crucial for establishing credibility and fostering future research. Acknowledging limitations demonstrates intellectual honesty, showcasing a nuanced understanding of the study’s scope and potential shortcomings. This section should transparently address methodological constraints, such as sample size limitations or specific data collection biases that could influence the findings. It should also delve into the generalizability of the results, clearly stating whether the conclusions can be reliably extended to broader populations or contexts. Addressing limitations with specificity and providing potential avenues for future research is key to enhancing the paper’s impact. This not only strengthens the current work but also points towards future directions, enriching the overall contribution to the field.
More visual insights#
More on figures

🔼 This figure illustrates the different ways to synchronize multiple diffusion processes. The left side shows how denoising happens individually in multiple instance spaces (Wi) and are synchronized in the canonical space (Z). The right side shows denoising directly in the canonical space. The figure helps visualize the three main cases (Case 1, Case 2, Case 3) of diffusion synchronization described in the paper.
read the caption
Figure 2: Diagrams of diffusion synchronization processes. The left diagram depicts denoising instance variables {wi}, while the right diagram illustrates directly denoising a canonical variable z.

🔼 The figure shows two diagrams illustrating the processes of diffusion synchronization. The left diagram (a) shows the denoising process applied to instance variables (wi). The right diagram (b) shows the denoising process applied directly to a canonical variable z. The diagrams illustrate the different approaches to synchronizing multiple diffusion processes.
read the caption
Figure 2: Diagrams of diffusion synchronization processes. The left diagram depicts denoising instance variables {wi}, while the right diagram illustrates directly denoising a canonical variable z.
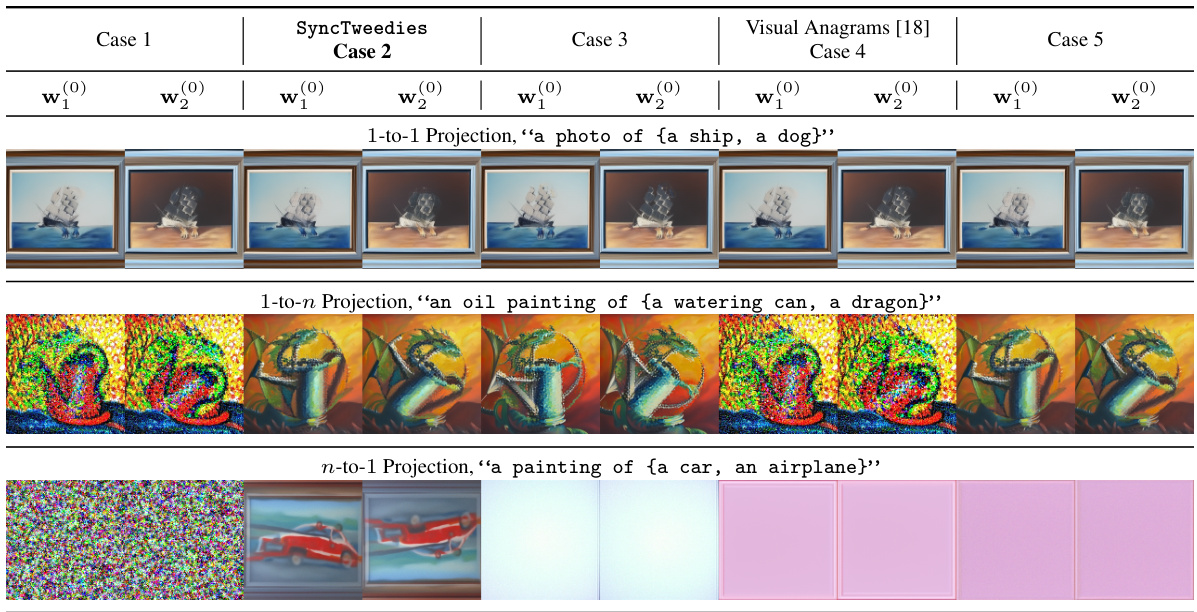
🔼 This figure shows the qualitative results of ambiguous image generation using different diffusion synchronization methods. The results demonstrate the performance of each method with 1-to-1, 1-to-n, and n-to-1 projections. SyncTweedies shows the best performance across different projection types, especially with n-to-1 projections, where other methods fail to generate satisfactory results.
read the caption
Figure 3: Qualitative results of ambiguous image generation. While all diffusion synchronization processes show identical results with 1-to-1 projections, Case 1, Case 3 and Visual Anagrams [18] (Case 4) exhibit degraded performance when the projections are 1-to-n. Notably, SyncTweedies can be applied to the widest range of projections, including n-to-1 projections, where Case 5 fails to generate plausible outputs.

🔼 This figure shows the qualitative results of 3D mesh texturing using different methods. SyncTweedies and SyncMVD generate the most realistic results, while finetuning-based methods (Paint3D) lack detail, optimization-based methods (Paint-it) have unnatural colors and high contrast, and iterative-view-updating methods (TEXTURE, Text2Tex) show inconsistencies across views.
read the caption
Figure 6: Qualitative results of 3D mesh texturing. SyncTweedies and SyncMVD [35] exhibit comparable results, outperforming other baselines. Finetuning-based method [63] produces images without fine details as it was trained on a dataset with coarse texture images. The optimization-based method [62] tends to produce unrealistic and high saturation textures, while iterative-view-updating-based methods [10, 44] show view inconsistencies.

🔼 This figure displays the qualitative results of generating 360° panoramas from depth maps using different diffusion synchronization methods. SyncTweedies and Case 5 demonstrate superior performance, producing realistic and detailed panoramas. In contrast, MVDiffusion [56], a finetuned model, struggles to generate realistic images for scenes it wasn’t specifically trained on. Other methods (Cases 1, 3, and 4) show significant artifacts and reduced visual quality.
read the caption
Figure 7: Qualitative results of depth-to-360-panorama generation. SyncTweedies and Case 5 generate consistent and high-fidelity panoramas as observed in the 1-to-n projection experiment in Section 3.4.3. MVDiffusion [56] fails to generalize to out-of-domain scenes and generates suboptimal panoramas.
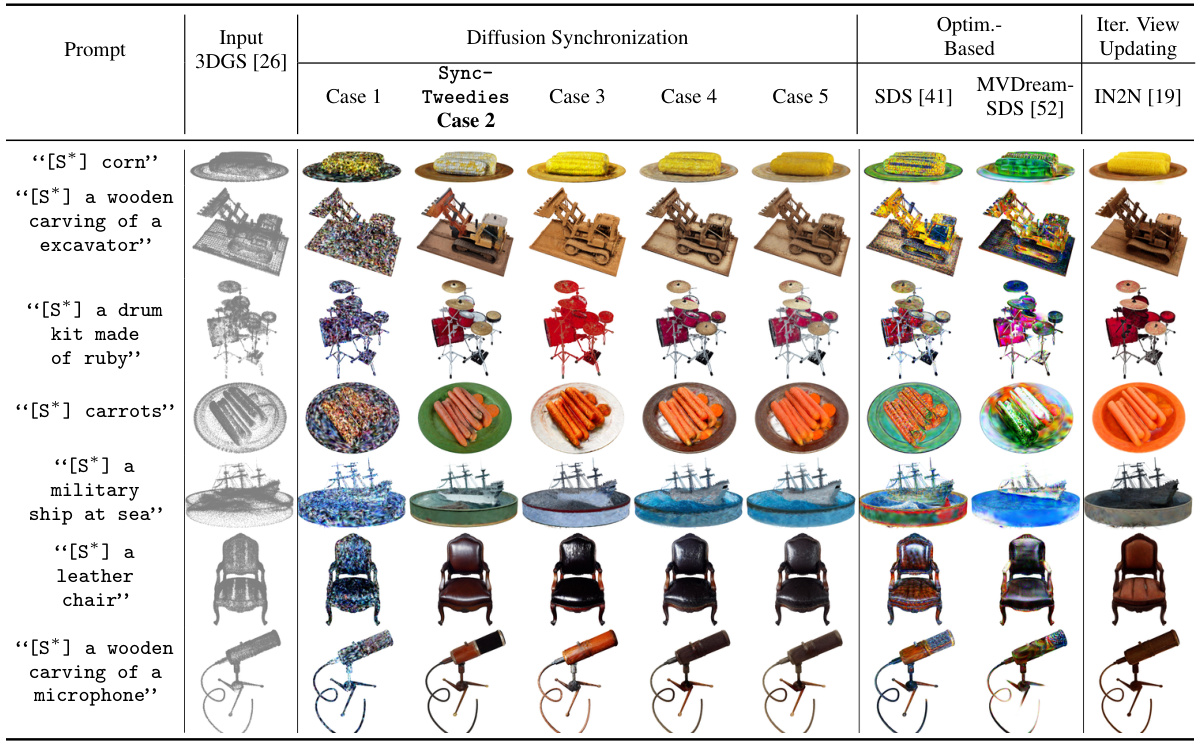
🔼 This figure shows the qualitative results of 3D Gaussian splats texturing using different methods. SyncTweedies outperforms other methods in terms of generating high-fidelity results with intricate details, while other methods like optimization-based methods show artifacts and iterative view updating methods fail to preserve fine details.
read the caption
Figure 8: Qualitative results of 3D Gaussian splats [26] texturing. [S*] is a prefix prompt. We use 'Make it to' for IN2N [19] and 'A photo of' for the other methods. Case 5 tends to lose details due to the variance reduction issue, whereas SyncTweedies generates realistic images by avoiding this issue. The optimization-based methods [41, 52] produce high contrast, unnatural colors, and the iterative view updating method [19] yields suboptimal outputs due to error accumulation.
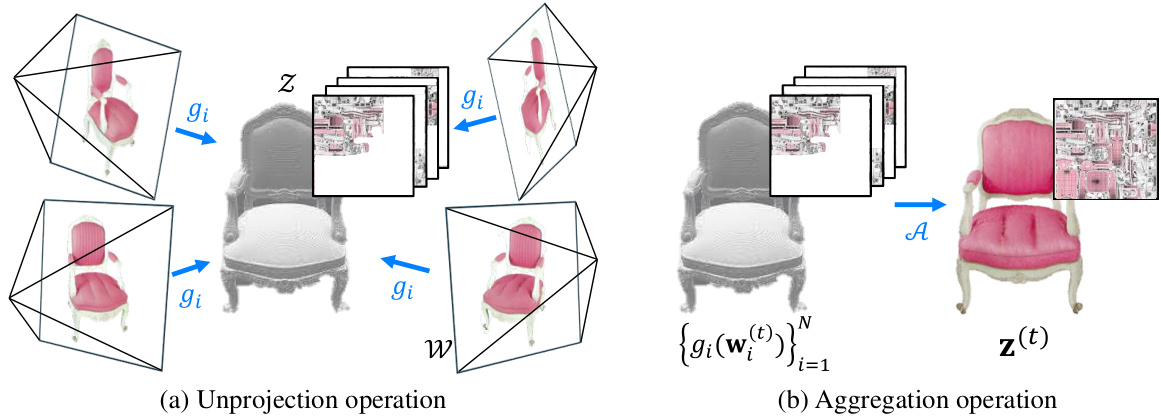
🔼 This figure illustrates the unprojection and aggregation operations in the SyncTweedies framework. The unprojection operation maps data points from instance spaces (multiple views of a 3D mesh) back to the canonical space (the texture image). The aggregation operation averages these data points to obtain a consistent representation in the canonical space.
read the caption
Figure 9: Illustration of unprojection and aggregation operation. The figure shows the synchronization process using the 3D mesh texturing application as an example. The left figure depicts the unprojection operation, where the instance space variables are unprojected into the canonical space. The right figure illustrates the aggregation operation, where the unprojected samples are averaged in the canonical space.

🔼 The figure shows the qualitative results of applying different diffusion synchronization processes to generate arbitrary-sized images using a 1-to-1 projection. It demonstrates that the results across all five methods (Case 1, SyncTweedies (Case 2), MultiDiffusion [5], Case 3, Case 4, and Case 5) are visually identical for this specific projection type. This supports the paper’s findings about the mathematical equivalence of the methods under these conditions.
read the caption
Figure 10: Qualitative results of arbitrary-sized image generation. All diffusion synchronization processes generate identical results in the 1-to-1 projection.

🔼 This figure showcases the diverse visual content generated by the SyncTweedies model. It demonstrates the model’s ability to generate various image types such as 360° panoramas, 3D mesh textures, and 3D Gaussian splat textures. Importantly, the model achieves this without requiring any additional fine-tuning for each specific downstream task, highlighting its generalizability and efficiency.
read the caption
Figure 1: Diverse visual content generated by SyncTweedies: A diffusion synchronization process applicable to various downstream tasks without finetuning.
🔼 This figure showcases various examples of visual content generated using the SyncTweedies framework. The top row shows a 360-degree panorama created from an input depth map. The middle row demonstrates texturing a 3D mesh model with different objects. The bottom row shows textures generated for 3D Gaussian splat models. The diversity of generated images highlights the framework’s broad applicability across different visual content generation tasks, even without fine-tuning.
read the caption
Figure 1: Diverse visual content generated by SyncTweedies: A diffusion synchronization process applicable to various downstream tasks without finetuning.

🔼 This figure shows three examples of 3D mesh texture editing using the SyncTweedies method. The input is a 3D model generated by Genies [1], and SyncTweedies is used to edit the texture of the model. Each row shows the original texture, and three variations created by SyncTweedies in response to a new text prompt. The results demonstrate SyncTweedies’ ability to generate high-quality, diverse, and realistic texture edits on 3D models.
read the caption
Figure 13: Qualitative results of 3D mesh texture editing. We edit the textures of the 3D meshes generated from Genies [1] using SyncTweedies.

🔼 This figure compares the diversity of images generated by the optimization-based method Paint-it and the proposed diffusion synchronization method, SyncTweedies. Both methods are applied to generate textures for the same 3D objects (clock, axe, rabbit, handbag). The images produced by Paint-it show less variation in color and texture, while those produced by SyncTweedies display a much wider range of styles and appearances, highlighting SyncTweedies’ superior ability to generate diverse visual content.
read the caption
Figure 14: Diversity comparison. Optimization-based method Paint-it [62] (Left) and diffusion-synchronization-based method, SyncTweedies (Right). SyncTweedies generates more diverse images.

🔼 This figure shows qualitative results comparing different diffusion synchronization methods for generating ambiguous images. The results demonstrate that while all methods perform similarly with simple 1-to-1 projections (one input to one output), SyncTweedies outperforms the others with more complex projection scenarios (one-to-many and many-to-one). This highlights SyncTweedies’ robustness and broader applicability.
read the caption
Figure 3: Qualitative results of ambiguous image generation. While all diffusion synchronization processes show identical results with 1-to-1 projections, Case 1, Case 3 and Visual Anagrams [18] (Case 4) exhibit degraded performance when the projections are 1-to-n. Notably, SyncTweedies can be applied to the widest range of projections, including n-to-1 projections, where Case 5 fails to generate plausible outputs.
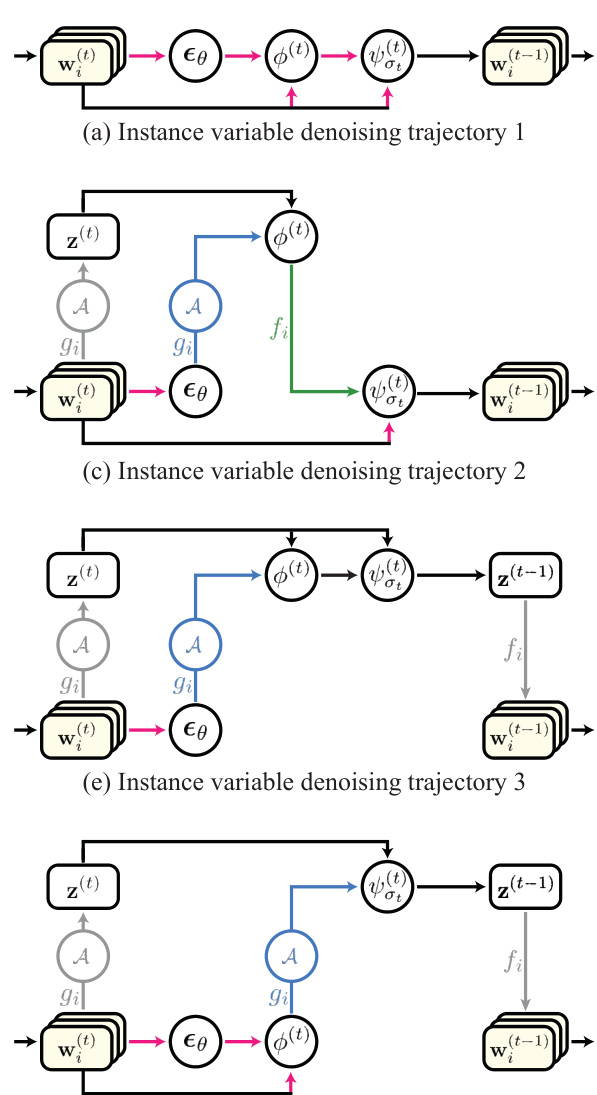
🔼 This figure illustrates the five different approaches to diffusion synchronization. The left side shows the denoising process for individual instance spaces, while the right side illustrates the denoising process directly in the canonical space. Each approach varies in when the aggregation of results from multiple instance spaces occurs (before noise prediction, after Tweedie’s formula approximation, or after the final deterministic denoising step), leading to different characteristics and performance.
read the caption
Figure 2: Diagrams of diffusion synchronization processes. The left diagram depicts denoising instance variables {wi}, while the right diagram illustrates directly denoising a canonical variable z.
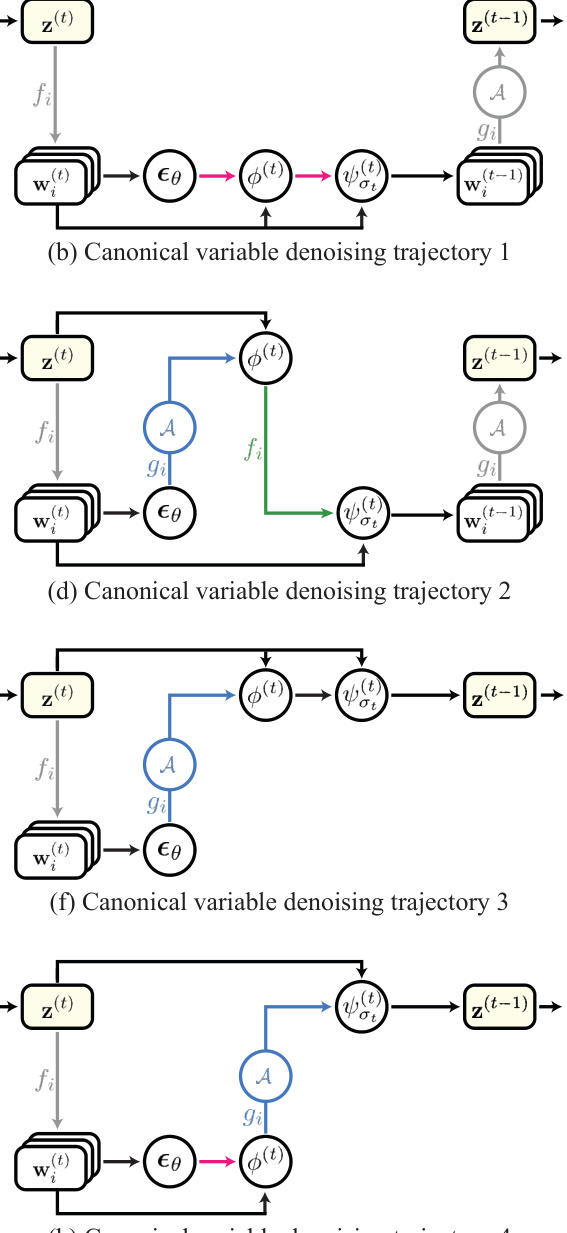
🔼 This figure illustrates the five different diffusion synchronization processes discussed in the paper. The left side shows the process of denoising in the instance spaces, while the right side shows the process of directly denoising in the canonical space. The figure highlights the different ways in which the denoising processes can be synchronized, depending on the timing of the aggregation operation.
read the caption
Figure 2: Diagrams of diffusion synchronization processes. The left diagram depicts denoising instance variables {wi}, while the right diagram illustrates directly denoising a canonical variable z.
More on tables

🔼 This table summarizes the applicability of different diffusion synchronization methods (Cases 1-5) across various projection scenarios (1-to-1, 1-to-n, n-to-1). A green checkmark indicates suitability, while a red ‘X’ signifies unsuitability. It highlights that SyncTweedies (Case 2) shows the broadest applicability, performing well across all three projection types. The table also provides a link to previous works that investigated specific cases of diffusion synchronization.
read the caption
Table 2: Analysis of diffusion synchronization processes on different projection scenarios. SyncTweedies offers the broadest range of applications.
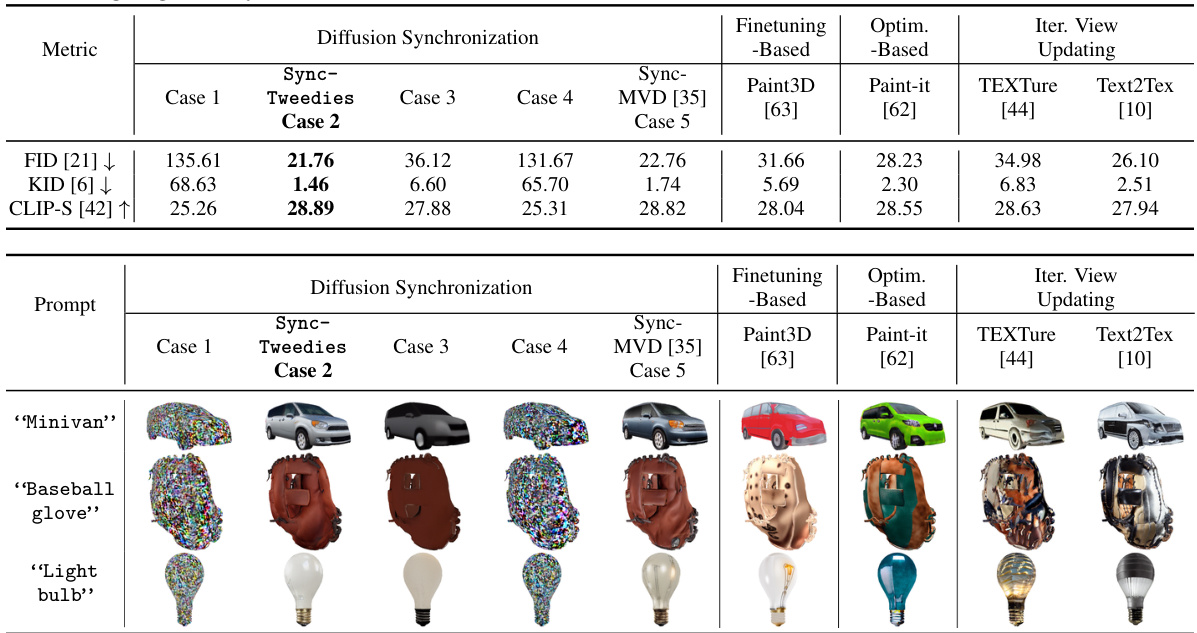
🔼 This table presents a quantitative comparison of different methods for 3D mesh texturing. It compares SyncTweedies (and other variations of the diffusion synchronization process) against several baselines, including finetuning-based methods (Paint3D [63]), optimization-based methods (Paint-it [62]), and iterative view updating methods (TEXTURE [44], Text2Tex [10]). The metrics used for comparison are FID (Fréchet Inception Distance), KID (Kernel Inception Distance), and CLIP-S (CLIP Similarity). Lower FID and KID scores indicate better fidelity, while higher CLIP-S scores represent better alignment with the text prompts. The best performing method in each row is highlighted in bold.
read the caption
Table 3: A quantitative comparison in 3D mesh texturing. KID is scaled by 103. The best in each row is highlighted by bold.

🔼 This table presents a quantitative comparison of different diffusion synchronization methods for depth-to-360-panorama generation. It shows the FID (Fréchet Inception Distance), KID (Kernel Inception Distance), and CLIP-S (CLIP Similarity) scores for each method, including SyncTweedies (Case 1, 2, 3, 4, 5) and MVDiffusion [56]. Lower FID and KID scores indicate better image quality, and higher CLIP-S scores suggest better text alignment. The best performing method in each metric is highlighted in bold.
read the caption
Table 4: A quantitative comparison in depth-to-360-panorama application. KID is scaled by 103. The best in each row is highlighted by bold.
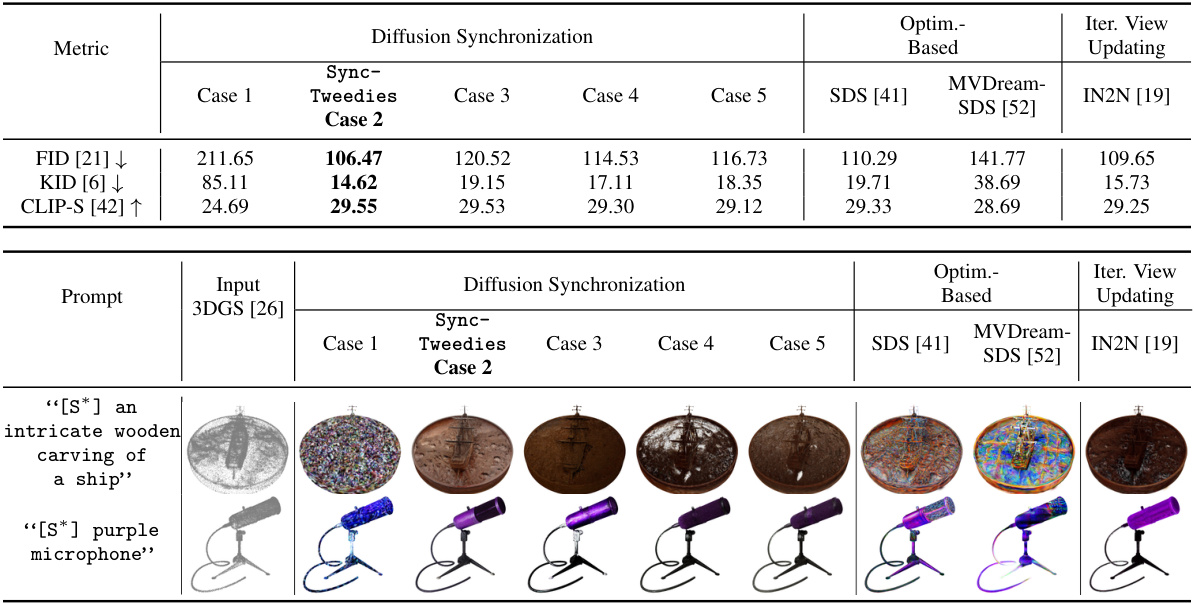
🔼 This table presents a quantitative comparison of different methods for 3D mesh texturing, including SyncTweedies and several baselines (finetuning-based, optimization-based, and iterative view updating methods). The metrics used for comparison are FID (Fréchet Inception Distance), KID (Kernel Inception Distance), and CLIP-S (CLIP Similarity). Lower FID and KID scores indicate better image quality, while higher CLIP-S scores represent better alignment between generated textures and text prompts. The table highlights SyncTweedies’ superior performance in terms of image quality and text alignment compared to the baseline methods.
read the caption
Table 3: A quantitative comparison in 3D mesh texturing. KID is scaled by 103. The best in each row is highlighted by bold.

🔼 This table presents a quantitative comparison of different diffusion synchronization processes in the context of arbitrary-sized image generation. The metrics used for comparison are FID (Frechet Inception Distance), KID (Kernel Inception Distance), and CLIP-S (CLIP similarity). The results show very similar performance across all methods (Cases 1-5) in this 1-to-1 projection scenario. The table highlights the best performing method (within a 95% margin) for each metric.
read the caption
Table 6: A quantitative comparison in arbitrary-sized image generation. KID is scaled by 103. For each row, we highlight the column whose value is within 95% of the best.
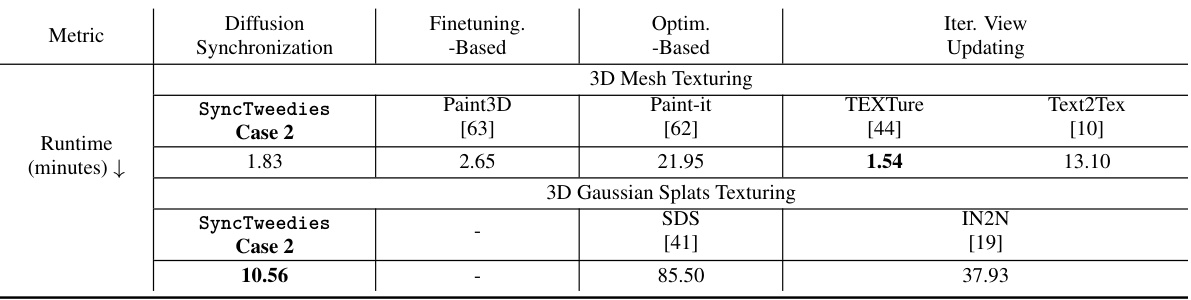
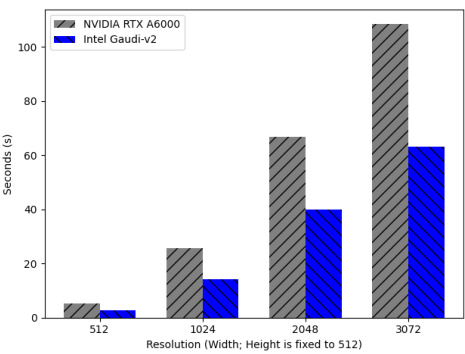
🔼 This table compares the runtime performance (in minutes) of different methods for 3D mesh texturing and 3D Gaussian splats texturing. The methods compared include SyncTweedies (Case 2), Paint3D (a finetuning-based method), Paint-it (an optimization-based method), TEXTure and Text2Tex (iterative view updating methods), and SDS and IN2N. The table highlights the fastest runtime for each task.
read the caption
Table 7: A runtime comparison in 3D mesh texturing and 3D Gaussian splats texturing applications. The best in each row is highlighted by **bold**.

🔼 This table compares the VRAM usage (in GiB) of different methods for 3D mesh texturing and 3D Gaussian splats texturing. It shows the VRAM usage of SyncTweedies (Case 2), finetuning-based methods (Paint3D [63]), optimization-based methods (Paint-it [62], SDS [41]), and iterative view updating methods (TEXTure [44], Text2Tex [10], IN2N [19]). The lowest VRAM usage for each task is highlighted in bold.
read the caption
Table 8: A VRAM usage comparison in 3D mesh texturing and 3D Gaussian splats texturing applications. The best in each row is highlighted by bold.

🔼 This table presents a quantitative comparison of different methods for 3D mesh texturing. It compares SyncTweedies (the proposed method) with several baselines including finetuning-based methods, optimization-based methods, and iterative view updating methods. The metrics used for comparison are FID (Fréchet Inception Distance), KID (Kernel Inception Distance), and CLIP-S (CLIP Similarity). Lower FID and KID scores indicate better image quality, while higher CLIP-S scores indicate better alignment with text prompts. The table highlights the best performing method for each metric.
read the caption
Table 3: A quantitative comparison in 3D mesh texturing. KID is scaled by 103. The best in each row is highlighted by bold.

🔼 This table presents a quantitative comparison of different diffusion synchronization processes in the task of ambiguous image generation. The metrics used for comparison include CLIP-A, CLIP-C, FID, and KID. The KID values are scaled by a factor of 1000 for easier readability. For each metric, the best-performing diffusion synchronization process (within a 95% margin of error) is highlighted for each projection type (1-to-1, 1-to-n, and n-to-1). The table helps to illustrate which method performs best based on different image projection configurations.
read the caption
Table 1: A quantitative comparison in ambiguous image generation. KID [6] is scaled by 103. For each row, we highlight the column whose value is within 95% of the best.
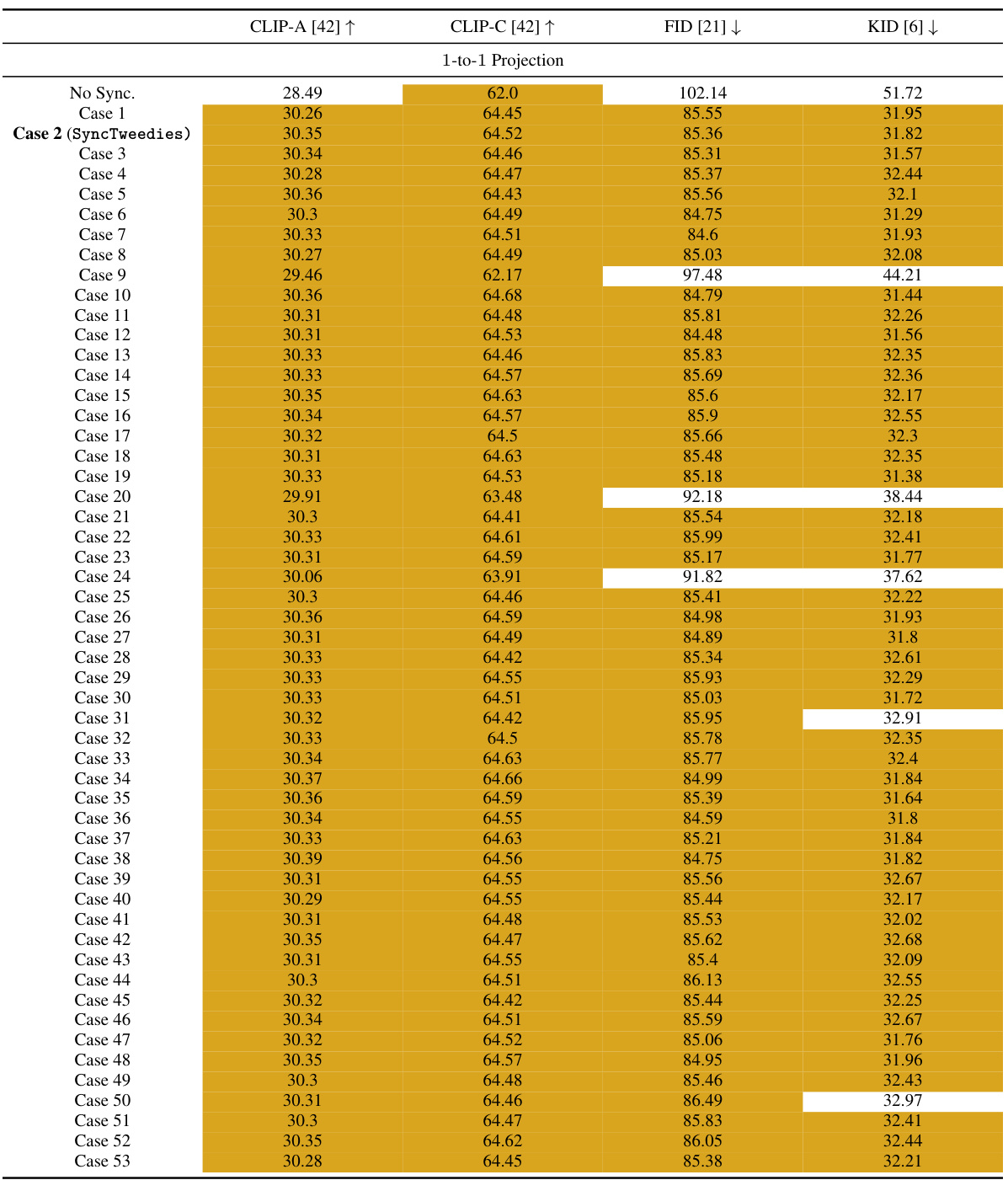
🔼 This table presents a quantitative comparison of different diffusion synchronization methods for generating ambiguous images. The metrics used are CLIP-A (higher is better), CLIP-C (higher is better), FID (lower is better), and KID (lower is better). Each row represents a different method (including SyncTweedies and baselines). The best performing method for each metric in each row is highlighted.
read the caption
Table 1: A quantitative comparison in ambiguous image generation. KID [6] is scaled by 103. For each row, we highlight the column whose value is within 95% of the best.
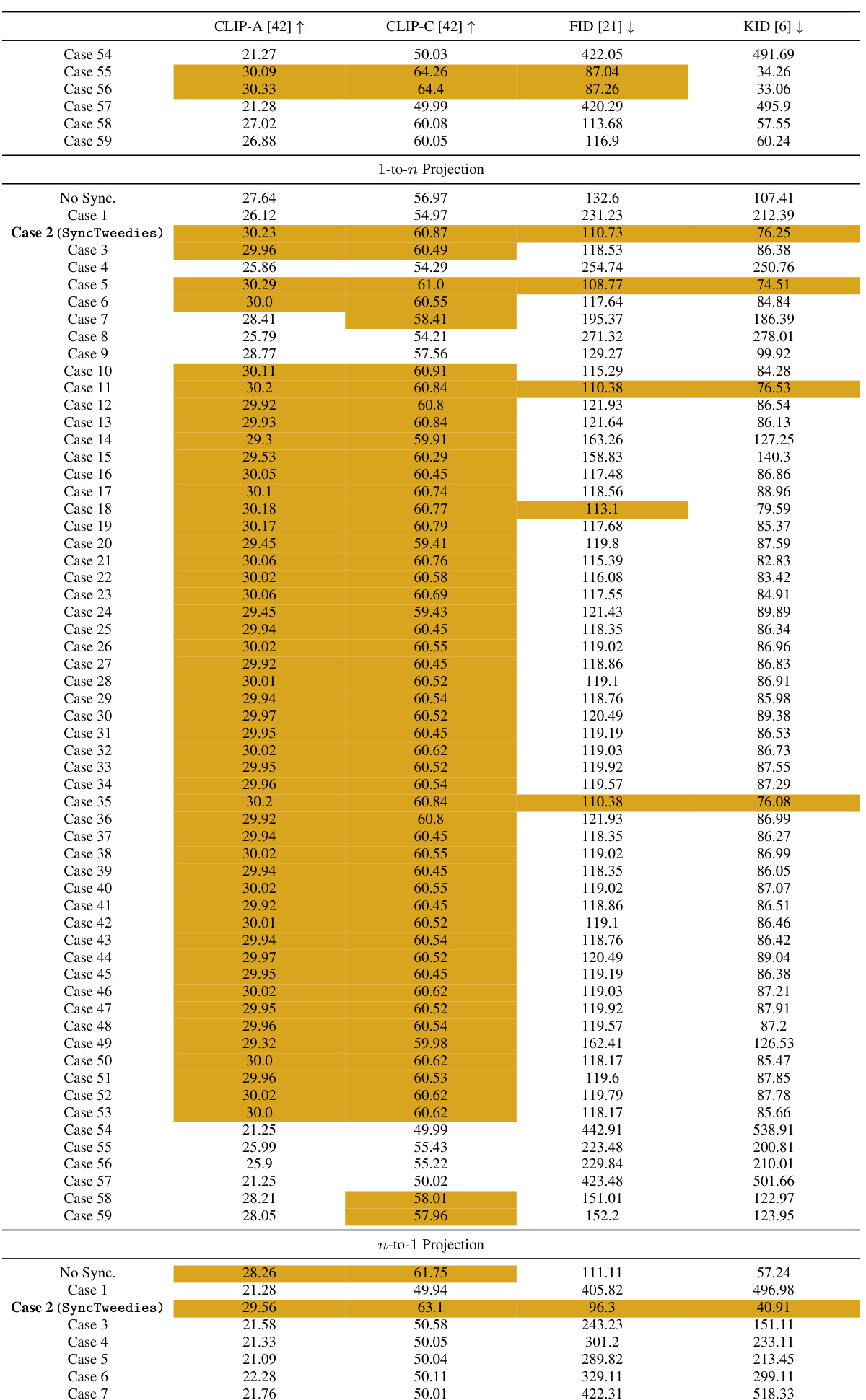
🔼 This table presents a quantitative comparison of different diffusion synchronization processes in the task of ambiguous image generation. The metrics used for comparison include CLIP-A (higher is better), CLIP-C (higher is better), FID (lower is better), and KID (lower is better). The table highlights the best performing case within 95% for each metric, allowing for a clear comparison of the effectiveness of the different methods in generating high-quality and diverse ambiguous images. Five different scenarios (cases) are compared in addition to a baseline approach with no synchronization. The 1-to-1, 1-to-n and n-to-1 projections represent different mapping scenarios between the canonical space and instance spaces for the images.
read the caption
Table 1: A quantitative comparison in ambiguous image generation. KID [6] is scaled by 103. For each row, we highlight the column whose value is within 95% of the best.
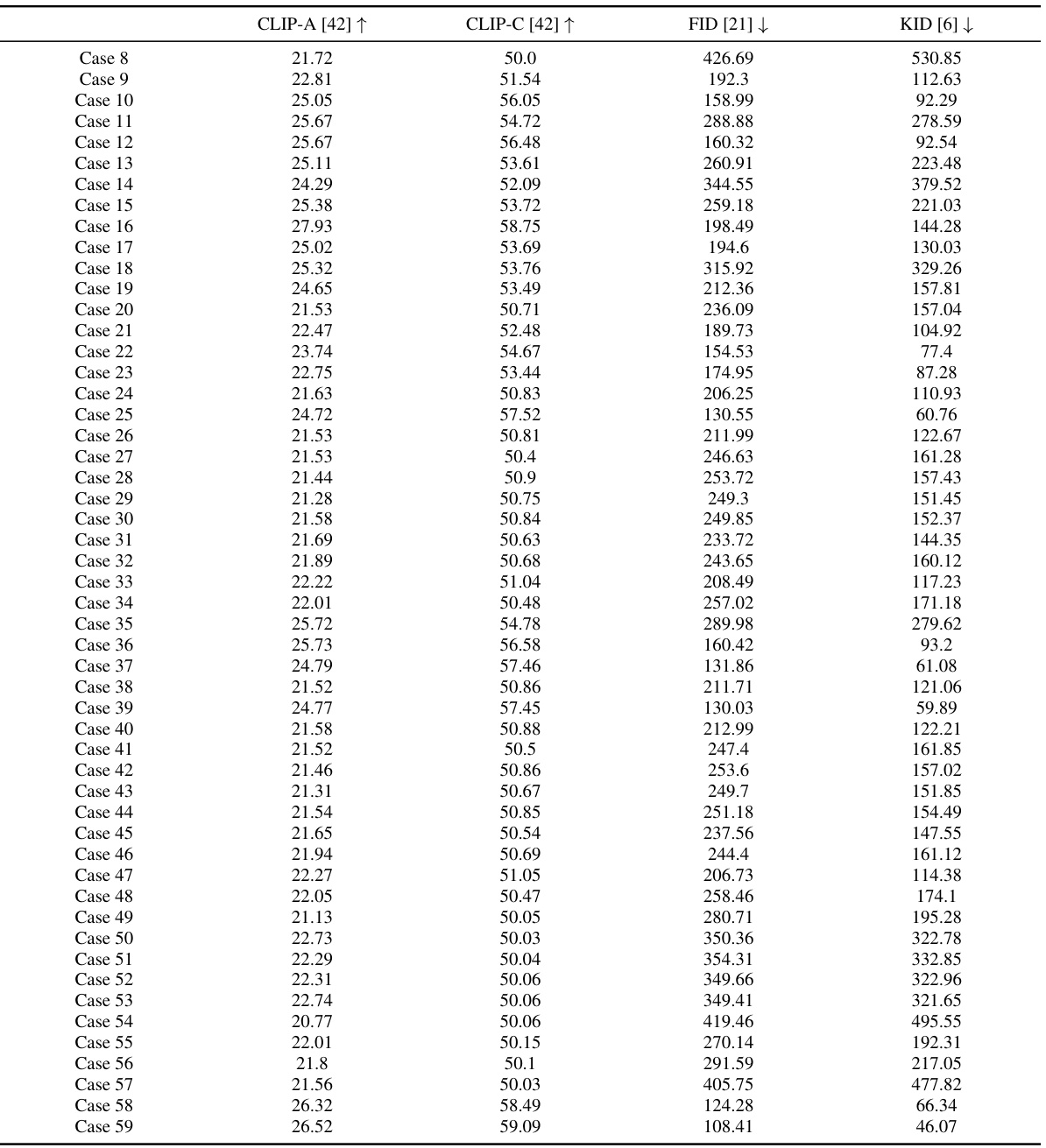
🔼 This table presents a quantitative comparison of different diffusion synchronization processes for ambiguous image generation. The metrics used are CLIP-A, CLIP-C, FID, and KID. The table highlights the best performing method (within 95% of the best) for each metric across five different synchronization processes (Cases 1-5). The results showcase the relative performance of each method, demonstrating how different approaches affect the generation quality of ambiguous images.
read the caption
Table 1: A quantitative comparison in ambiguous image generation. KID [6] is scaled by 103. For each row, we highlight the column whose value is within 95% of the best.
Full paper#



















