TL;DR#
Current 3D generation methods often rely on synthetic datasets with predefined camera trajectories, limiting realism. Real-world datasets offer significantly more realistic 3D scenes but present the challenge of complex, scene-specific camera trajectories. This paper explores this challenge.
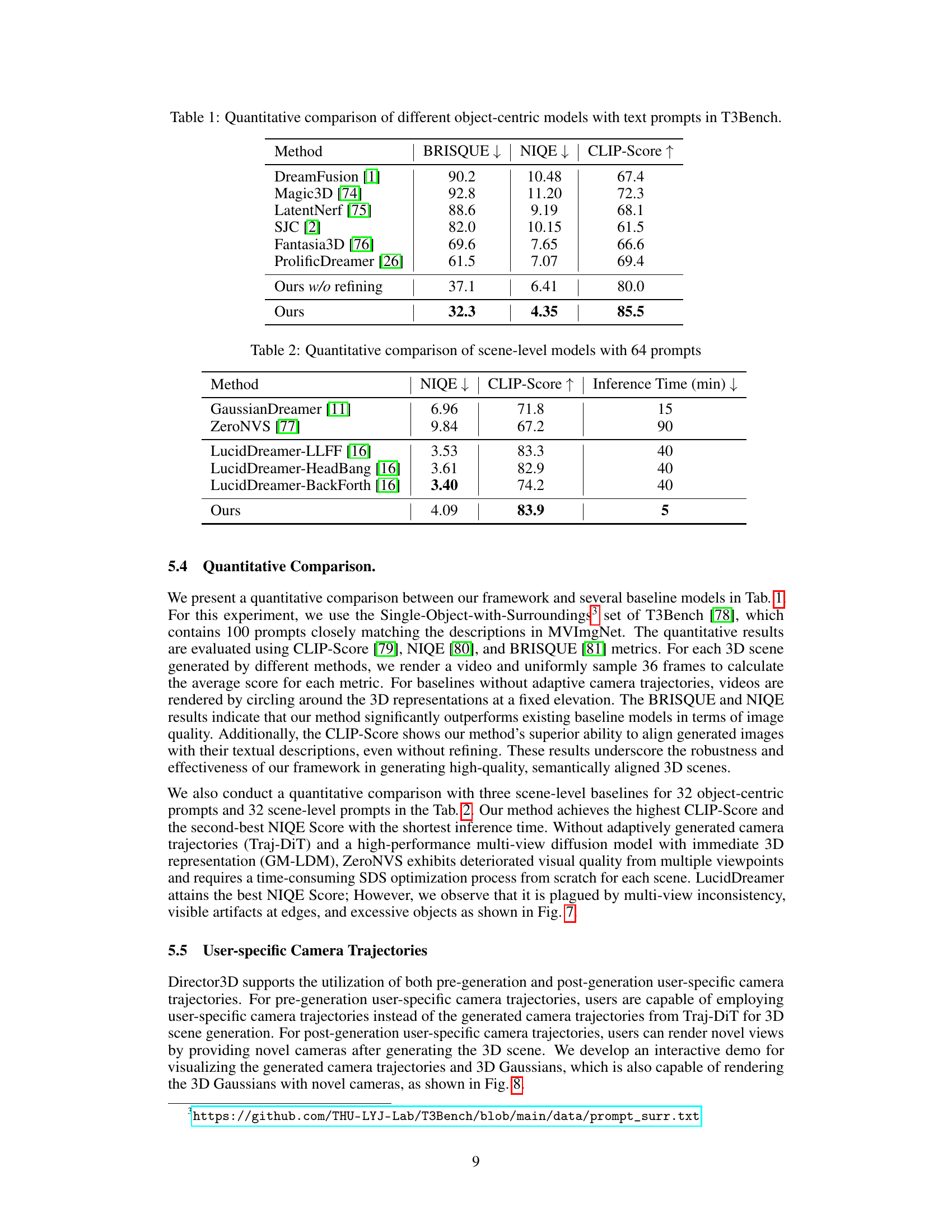
This work introduces Director3D, a novel text-to-3D generation framework that addresses these issues. Director3D leverages a three-component pipeline: the Cinematographer models camera trajectories using a Trajectory Diffusion Transformer, the Decorator generates 3D scenes via a Gaussian-driven Multi-view Latent Diffusion Model, and the Detailer refines the scenes using an SDS++ loss. The approach surpasses existing methods by generating higher-quality real-world 3D content.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D scene generation due to its novel framework, Director3D, which tackles the challenge of realistic scene generation using real-world data and complex camera trajectories. It offers a significant advancement over existing methods by achieving superior performance in real-world 3D generation and opens new avenues for research in open-world text-to-3D generation. The introduction of Trajectory Diffusion Transformer, Gaussian-driven Multi-view Latent Diffusion Model, and SDS++ loss provides a robust and effective pipeline for generating high-quality 3D scenes.
Visual Insights#
🔼 This figure illustrates the pipeline of Director3D, a text-to-3D generation framework. It shows how three key components work together: The Cinematographer generates camera trajectories from a text description. The Decorator creates an initial 3D scene using these trajectories. Finally, the Detailer refines the details of the 3D scene to make it more realistic. Examples of generated 3D scenes are shown as output.
read the caption
Figure 1: Given textual descriptions, Director3D employs three key components: the Cinematographer generates the camera trajectories, the Decorator creates the initial 3D scenes, and the Detailer refines the details.
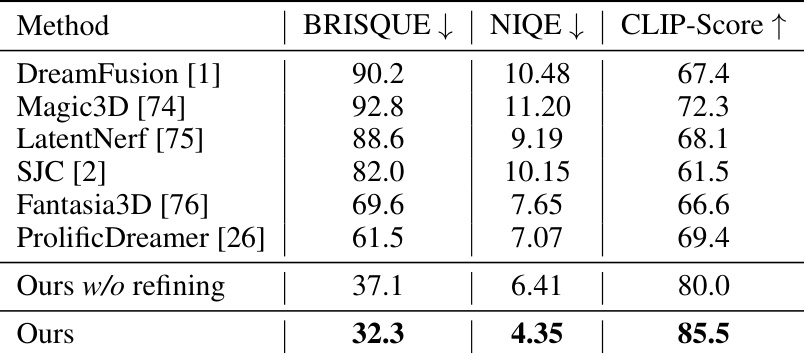
🔼 This table presents a quantitative comparison of various object-centric models using three metrics: BRISQUE, NIQE, and CLIP-Score. Lower BRISQUE and NIQE scores indicate better image quality, while a higher CLIP-Score suggests better alignment between generated images and text prompts. The comparison is performed on the T3Bench dataset, which includes object-level descriptions. The ‘Ours w/o refining’ row shows the performance of the proposed method without the refinement stage, highlighting the impact of the refinement process on overall quality.
read the caption
Table 1: Quantitative comparison of different object-centric models with text prompts in T3Bench.
In-depth insights#
Real-world 3DGen#
The concept of “Real-world 3DGen” signifies a paradigm shift in 3D generation, moving away from reliance on synthetic datasets towards leveraging real-world data. This approach promises greater realism and diversity in generated 3D scenes. However, real-world data introduces new challenges such as complex and scene-specific camera trajectories, unbounded backgrounds, and limited dataset sizes. A successful “Real-world 3DGen” system must address these issues through robust techniques for handling diverse camera paths and complex scene structures. Furthermore, it should be able to effectively learn from limited data to ensure good generalization to unseen scenes. Innovative methods, such as incorporating trajectory diffusion models to predict camera movements and multi-view latent diffusion models for generating 3D representations from image sequences, are key to unlocking the potential of real-world 3D generation. This field remains relatively unexplored but holds immense potential for applications in gaming, robotics, virtual and augmented reality, and more.
Traj-Diff Transformer#
A Traj-Diff Transformer, conceptually, is a diffusion model designed for the specific task of generating camera trajectories. It leverages the power of transformers to model the complex temporal dependencies inherent in realistic camera movements, moving beyond simple predefined paths. The ‘diffusion’ aspect suggests a probabilistic approach, sampling from a learned distribution of trajectories, rather than directly predicting a deterministic sequence. This allows for greater variability and the potential to generate more natural-looking camera motion. The model would likely be trained on a large dataset of real-world or simulated camera trajectories, paired with descriptive text or other contextual information to guide the generation process. The transformer architecture is key to its ability to capture long-range dependencies and context, enabling the model to learn intricate patterns in camera motion that might be missed by simpler methods. A well-designed Traj-Diff Transformer could be a valuable tool for various applications, including 3D scene generation, virtual reality, and autonomous navigation, enabling the creation of more immersive and engaging experiences.
GM-LDM & SDS++#
The proposed framework, integrating GM-LDM and SDS++, presents a novel approach to 3D scene generation. GM-LDM, a Gaussian-driven Multi-view Latent Diffusion Model, leverages the strengths of 2D diffusion models to efficiently generate pixel-aligned 3D Gaussians representing the 3D scene. This is crucial for handling the complexities and scene-specific camera trajectories found in real-world captures. However, the initial 3D Gaussians generated by GM-LDM may lack detail. This is where SDS++, a novel Score Distillation Sampling loss, comes in. SDS++ refines the visual quality of the 3D Gaussians by leveraging the prior of a 2D diffusion model and back-propagating a novel loss. By incorporating both latent and image space objectives, SDS++ ensures both fidelity and coherence of the generated scenes. The combination of GM-LDM and SDS++ effectively addresses the challenges of real-world 3D scene generation by providing both efficient initial scene generation and detailed refinement, leading to superior performance compared to existing methods.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a text-to-3D generation model, this might involve removing or deactivating parts of the pipeline, such as the camera trajectory generator, the 3D scene initializer, or the refinement stage. By comparing the performance of the full model to the results obtained after each ablation, researchers can isolate the impact of each component and gauge its importance. This helps to reveal which elements are most critical for achieving high-quality 3D outputs and provides insights for future model improvements. For example, an ablation study might show that removing a particular loss function significantly degrades the realism of the generated 3D scenes, suggesting the importance of that loss function for achieving photorealism. Conversely, if removing a module has minimal impact, it could indicate potential for model simplification, leading to improved efficiency without substantial loss of quality.
Future Directions#
Future directions for research in this area could involve improving the diversity and quality of real-world multi-view datasets. A larger, more varied dataset would significantly enhance the generalizability of models like Director3D. Further research could also focus on developing more efficient and scalable methods for both camera trajectory generation and 3D scene synthesis, potentially exploring alternative 3D scene representations to reduce computational costs. Improving the fine-grained control over 3D scene generation, allowing users to specify more nuanced details, is another key area for future development. Finally, investigating methods to handle complex, unbounded backgrounds more effectively would lead to more realistic and compelling scene generation, moving beyond currently-limited scene-specific approaches.
More visual insights#
More on figures

🔼 This figure shows several example images generated by the Director3D model. Each row represents a different scene generated from a text prompt. The images show a variety of scenes, including a collection of fresh vegetables in a basket, a bald man, a snowy woodland path, a cluster of tents, a stainless steel toaster, a paint-splattered easel, a badlands terrain, a marketplace, a leopard print hat, a swan on a lake, a derelict space station, and a steep gorge. The images demonstrate the model’s ability to generate realistic and diverse 3D scenes from text descriptions, along with plausible camera trajectories that capture interesting viewpoints.
read the caption
Figure 2: Multi-view image results rendered with the generated camera trajectories and 3D scenes.
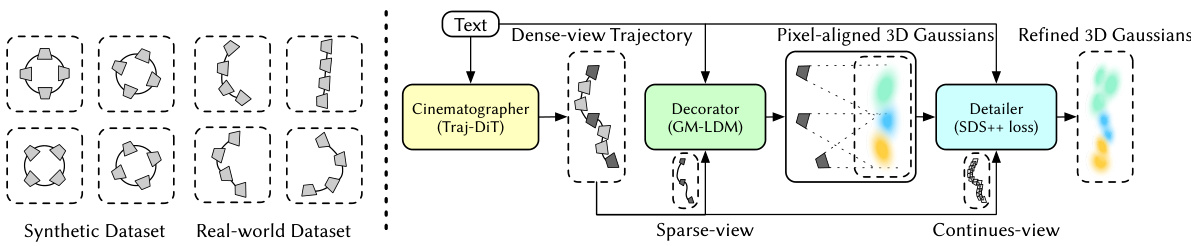
🔼 The figure compares the camera trajectory distributions in synthetic and real-world multi-view datasets. The left panel shows how synthetic datasets have controlled and predefined camera trajectories, often following simple patterns like circles. In contrast, the right panel illustrates real-world datasets which exhibit more complex, scene-specific and unpredictable camera trajectories. The right panel also details the architecture of Director3D, which consists of three key components: the Cinematographer (Traj-DiT), the Decorator (GM-LDM), and the Detailer (SDS++ loss). The Cinematographer generates camera trajectories, the Decorator creates the initial 3D scene representation, and the Detailer refines the scene’s details.
read the caption
Figure 3: Left: Comparison of the simplified camera trajectory distributions between synthetic and real-world multi-view datasets. Right: Pipeline and models of Director3D.

🔼 The figure illustrates the architecture of the Trajectory Diffusion Transformer (Traj-DiT) and example camera trajectories generated by the model. The left panel displays the architecture of Traj-DiT, showing how text embeddings and timestep information are processed through cross-attention, self-attention, and MLP layers to produce a camera trajectory. The right panel shows example trajectories over time for two different text prompts: ‘An apple’ and ‘A park’. The trajectories show how the model generates camera movement that is smooth and makes sense for the context of each scene.
read the caption
Figure 4: Left: Architecture of Traj-DiT. Right: Visualization of the predicted camera trajectory for different denoising timesteps.
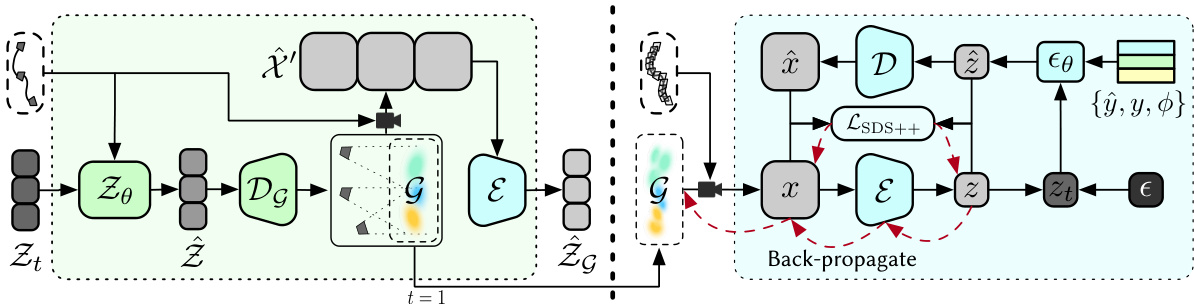
🔼 This figure illustrates the architecture of the Gaussian-driven Multi-view Latent Diffusion Model (GM-LDM) and the process of calculating the SDS++ loss. The GM-LDM is a modified version of a 2D Latent Diffusion Model (LDM), which generates initial 3D Gaussians through rendering-based denoising. The SDS++ loss refines the generated 3D Gaussians by backpropagating a loss from images rendered at randomly interpolated cameras within the trajectory. This two-stage process improves the quality and detail of the generated 3D scenes.
read the caption
Figure 5: Left: Architecture of GM-LDM. The model is fine-tuned from a 2D LDM with minor modifications, performing rendering-based denoising for generating initial 3D Gaussians. Right: Pipeline of calculating SDS++ loss, which refines the 3D Gaussians with the original 2D LDM.
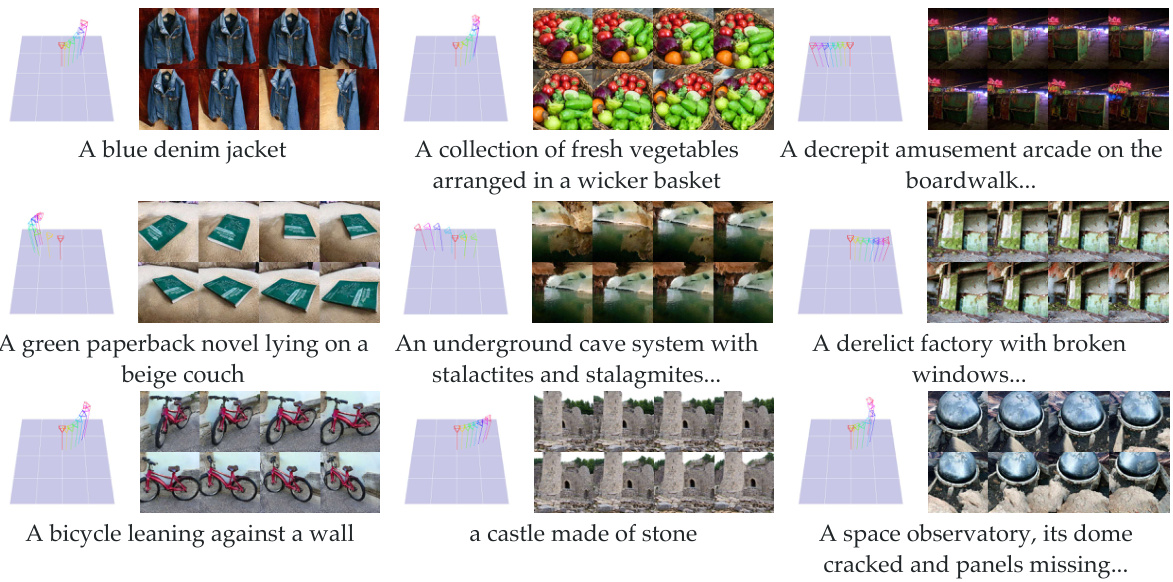
🔼 This figure showcases several examples of 3D scenes generated by Director3D, demonstrating its ability to generate both realistic camera trajectories and high-quality image sequences from text prompts. Each row presents a different text prompt, followed by a visualization of the predicted camera trajectory (a sequence of camera positions and orientations), and a series of rendered images from different viewpoints along the trajectory. The images are of high quality, exhibiting details, realistic lighting, and overall scene coherence. The variety of scenes demonstrates the model’s versatility in handling diverse text descriptions.
read the caption
Figure 6: Generation results of Director3D for both camera trajectories and image sequences.

🔼 This figure presents a qualitative comparison of 3D scene generation results from Director3D against three other methods: GRM, GaussianDreamer, and LucidDreamer. Each row shows the same text prompt rendered by each of the four methods. The results highlight the superior realism and detail achieved by Director3D, particularly in terms of texture quality, lighting effects, and overall scene coherence, compared to the artifacts and inconsistencies present in the other methods. For example, the first row showcases the rendering of ‘Four ripe apples in a basket.’ Director3D shows photorealistic apples within a realistically rendered basket; GRM’s result misses the basket entirely; GaussianDreamer shows acceptable apples but lacks realism in the basket’s texture and lighting; and LucidDreamer generates a blurry, unrealistic render.
read the caption
Figure 7: Qualitative comparison between Director3D and different baselines.

🔼 This figure shows two examples of 3D scene generation using the Director3D model. The top row displays the generated camera trajectory and a distance view of the scene, while the bottom shows the corresponding text prompt. The left-hand side depicts a lake reflecting the sky and surrounding cliffs, whereas the right shows a mountain pass with wind. In both instances, Director3D successfully produces diverse, high-quality renderings from multiple viewpoints.
read the caption
Figure 8: Screenshots of the interactive demo for visualizing generated camera trajectories and 3D Gaussians of Director3D. The frames are rendered with novel cameras.

🔼 This figure shows the ablation study of the SDS++ loss. It compares the results of the full model with different variations of the SDS++ loss, including removing the refining process entirely, setting different parameters (λx, λz, wcfg) and setting εsrc = ε. The results demonstrate the importance of each component in the SDS++ loss for achieving high-quality 3D generation.
read the caption
Figure 9: Ablation of SDS++ loss

🔼 This figure showcases example outputs from the Director3D model, demonstrating its ability to generate camera trajectories and corresponding image sequences from text prompts. Each row presents a different text prompt, followed by the generated camera trajectory (a series of camera viewpoints), and a multi-view rendering of the resulting 3D scene from those viewpoints. The figure visually displays the model’s capacity to interpret diverse textual descriptions and produce coherent 3D scenes with realistically varied camera movements.
read the caption
Figure 6: Generation results of Director3D for both camera trajectories and image sequences.

🔼 This figure showcases the diversity of generation results from Director3D. Using the same text prompts, the model generates diverse camera trajectories and 3D scenes. The top row shows the predicted camera trajectories for different prompts; the bottom row shows the rendered images from those same camera positions.
read the caption
Figure 11: Generation results with diversity.

🔼 This figure shows the results of generating 3D scenes with fine-grained control over clothing and gender. The text prompts specify clothing items, and the generated images accurately depict these features, demonstrating the model’s ability to incorporate such details. Each row shows different variations of the same prompt.
read the caption
Figure 12: Generation results with fine-grained control.

🔼 The left part of the figure compares the camera trajectory distributions between synthetic and real-world multi-view datasets. The synthetic datasets have simple, predictable camera trajectories, while real-world datasets have complex, scene-specific trajectories. The right part of the figure shows the pipeline and models of Director3D, which consists of three key components: the Cinematographer (Traj-DiT), the Decorator (GM-LDM), and the Detailer (SDS++ loss). The Cinematographer generates camera trajectories from text descriptions. The Decorator generates pixel-aligned 3D Gaussians as an immediate 3D scene representation. The Detailer refines the 3D Gaussians using a novel SDS++ loss.
read the caption
Figure 3: Left: Comparison of the simplified camera trajectory distributions between synthetic and real-world multi-view datasets. Right: Pipeline and models of Director3D.

🔼 The figure compares camera trajectory distributions between synthetic and real-world datasets, highlighting the complexity of real-world trajectories. It also presents a schematic diagram illustrating the architecture of Director3D, showcasing its three main components: the Cinematographer (Traj-DiT), Decorator (GM-LDM), and Detailer (SDS++ loss), which work collaboratively to generate camera trajectories and 3D scenes from textual descriptions.
read the caption
Figure 3: Left: Comparison of the simplified camera trajectory distributions between synthetic and real-world multi-view datasets. Right: Pipeline and models of Director3D.

🔼 The figure compares the camera trajectory distributions in synthetic and real-world multi-view datasets, highlighting the complexity of real-world trajectories. It then presents a schematic overview of the Director3D framework, showing its three main components: the Cinematographer (generating camera trajectories), the Decorator (creating initial 3D scenes), and the Detailer (refining scene details). The process starts with text input, which is processed by the Cinematographer, then the Decorator, and finally the Detailer to produce pixel-aligned 3D Gaussians as the final 3D scene representation.
read the caption
Figure 3: Left: Comparison of the simplified camera trajectory distributions between synthetic and real-world multi-view datasets. Right: Pipeline and models of Director3D.
More on tables
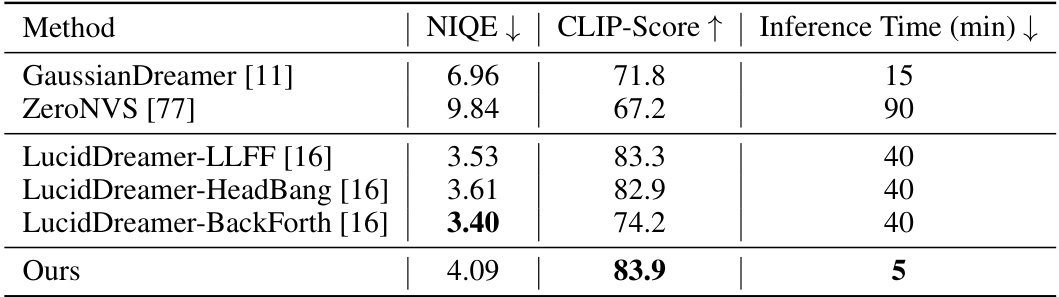
🔼 This table quantitatively compares the performance of Director3D against three other scene-level text-to-3D generation models using 64 different text prompts. The metrics used are NIQE (Natural Image Quality Evaluator), CLIP-Score (a metric measuring the alignment between generated images and text prompts), and Inference Time. Lower NIQE scores indicate better image quality, higher CLIP-Score scores represent better alignment with text descriptions, and lower inference times show faster model processing.
read the caption
Table 2: Quantitative comparison of scene-level models with 64 prompts

🔼 This table presents the results of an ablation study on the SDS++ loss, a key component of the Director3D model. Different configurations of the SDS++ loss are tested, removing components or changing parameters. The results are evaluated using two metrics: NIQE (Natural Image Quality Evaluator), which measures image quality, and CLIP-Score, which measures the alignment between generated images and textual descriptions. The ‘full’ row shows the results with the complete SDS++ loss, while subsequent rows show results after removing or modifying specific parts of the loss function. Lower NIQE scores are better (indicating higher quality images), and higher CLIP scores are better (indicating better alignment with text descriptions). The table shows that the complete SDS++ loss achieves the best performance, highlighting the importance of all its components for high-quality image generation.
read the caption
Table 3: Quantitative ablation study of SDS++ loss
Full paper#