TL;DR#
Offline reinforcement learning (RL) aims to train AI agents using only pre-recorded data, without requiring real-time interaction with the environment. A common challenge is how to balance learning skills of varying complexity. Existing methods often rely on random masking schemes, which might hinder learning long-term dependencies.
CurrMask addresses this by employing a curriculum-based masking approach. It uses block-wise masking schemes of different complexities, arranged in a carefully selected order. This curriculum dynamically adjusts during pretraining to maximize learning efficiency and skill acquisition, leading to substantial improvements in zero-shot and fine-tuning performance on various downstream tasks. The results showcase CurrMask’s effectiveness compared to existing methods and provide valuable insights into designing efficient training strategies for offline RL.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning and artificial intelligence. It introduces CurrMask, a novel curriculum-based masking technique that significantly improves the efficiency and effectiveness of offline reinforcement learning. The findings are highly relevant to current research trends in self-supervised learning and skill discovery. This work opens new avenues for exploring more efficient and versatile AI agent training paradigms and advances the state-of-the-art in offline RL. The proposed curriculum learning approach is widely applicable beyond the scope of this study, suggesting a potentially broad impact on diverse AI domains.
Visual Insights#
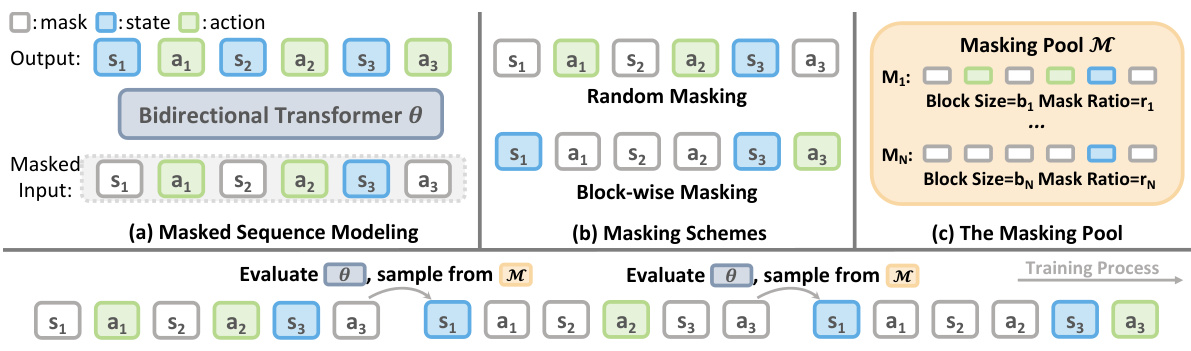
🔼 This figure illustrates the CurrMask framework. Panel (a) shows the general masked sequence modeling framework using a bidirectional transformer. (b) shows two masking strategies: random masking and block-wise masking. (c) shows the concept of a masking pool containing various masking schemes with different complexity levels, represented as a set of different block sizes and mask ratios. (d) illustrates how CurrMask works during pretraining, where it evaluates the model’s performance with different masking schemes and adjusts its sampling strategy accordingly to create a curriculum.
read the caption
Figure 1: Illustration of CurrMask. Based on the framework of masked prediction modeling in (a), the block-wise masking scheme in (b), we design a masking pool M in (c) consisting of masking schemes at different levels of complexity, which CurrMask evaluates the learning progress of the model θ and samples masking schemes from during pretraining in (d).

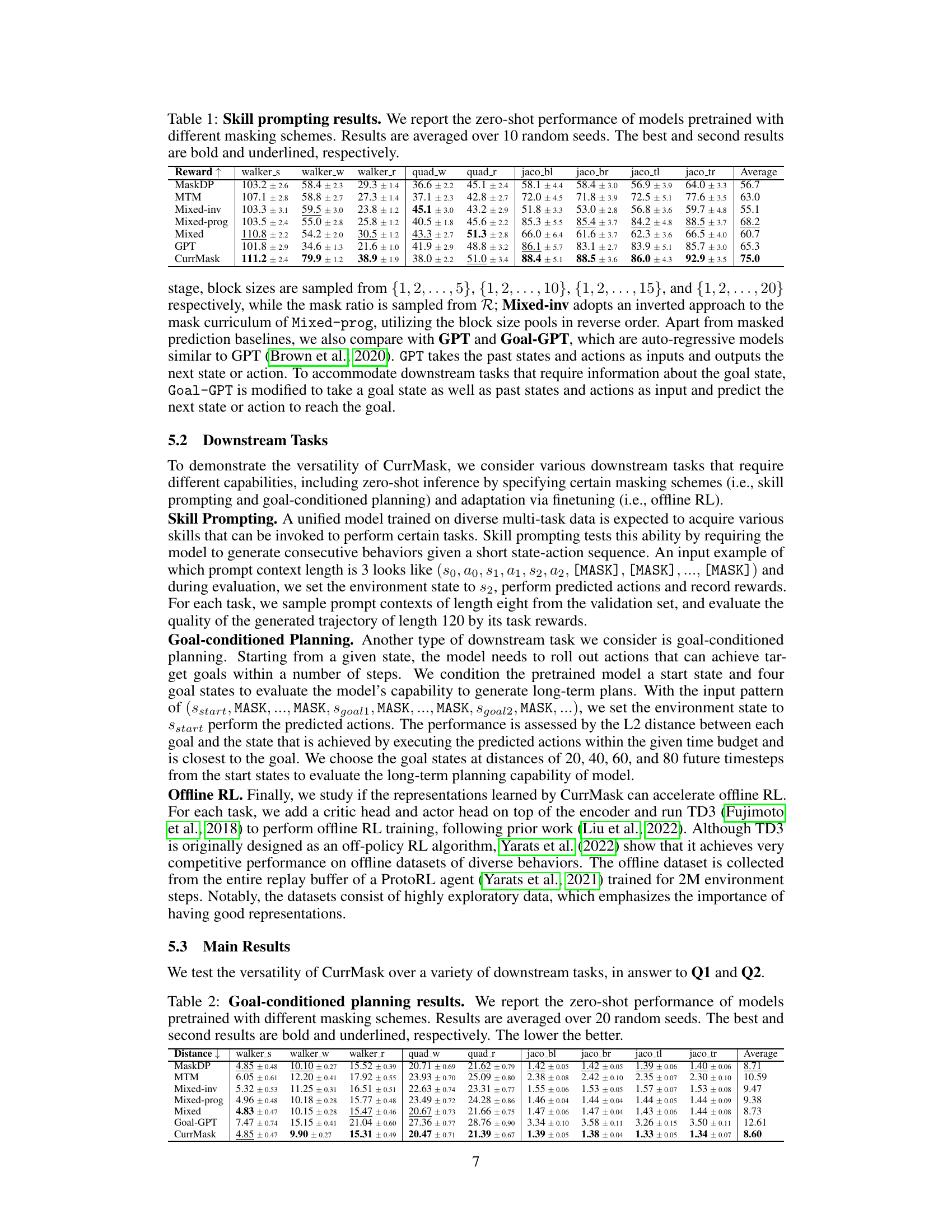
🔼 This table presents the zero-shot performance results of various models trained using different masking schemes on skill prompting tasks. The results are averaged across 10 independent runs (random seeds) for each model and masking scheme. The best performing and second-best performing models for each task are highlighted.
read the caption
Table 1: Skill prompting results. We report the zero-shot performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds. The best and second results are bold and underlined, respectively.
In-depth insights#
Curriculum Masking#
The concept of ‘Curriculum Masking’ presents a novel approach to offline reinforcement learning (RL) pretraining. It addresses the challenge of balancing skill acquisition across varying complexities by dynamically adjusting the masking scheme during training. Inspired by human learning processes, CurrMask, as it’s named in the paper, introduces a curriculum where simpler skills are learned first, gradually progressing to more complex ones. This curriculum is not pre-defined but rather learned automatically, using the reconstruction loss as a proxy for measuring learning progress and guiding the masking scheme selection. This approach effectively mitigates information redundancy found in decision-making data, pushing the model to reason about longer-term dependencies instead of solely relying on local correlations. The use of block-wise masking further enhances the model’s ability to capture meaningful skills. The overall effect is improved zero-shot performance on several skill prompting and planning tasks, as well as better fine-tuning performance in offline RL scenarios.
Block-wise Masking#
Block-wise masking, as a core concept, offers a significant advantage over token-wise masking in sequential decision-making tasks. By masking consecutive state-action pairs (blocks) instead of individual tokens, it forces the model to learn higher-level, more meaningful representations of skills and temporal dependencies. This approach directly addresses the limitations of token-wise masking, which often leads to models that rely on local correlations and struggle with long-term reasoning. The size of the blocks becomes a crucial hyperparameter, controlling the granularity of learned skills. Smaller blocks may facilitate initial learning, while larger blocks encourage the learning of more complex, temporally extended skills. The choice of block size and mask ratio thus becomes a parameter space worthy of further exploration. The curriculum-based approach further enhances the effectiveness of block-wise masking. By progressively increasing block sizes over the training process, it guides the model’s learning trajectory, promoting a more efficient learning of diverse and adaptable skills. This structured approach directly mirrors how humans often learn complex skills incrementally.
Skill Acquisition#
The concept of skill acquisition in the context of reinforcement learning is crucial. The paper explores how curriculum masking influences the learning process. It suggests that by gradually increasing task complexity, the model can acquire skills more effectively. Block-wise masking plays a significant role, prompting the model to consider longer-term dependencies rather than focusing solely on short-term, local patterns. The success of this approach is partly attributed to the interplay between exploration and exploitation, where the model dynamically adjusts its masking strategy to balance learning new skills and mastering existing ones. The results demonstrate the benefits of this strategy, showcasing superior performance on various downstream tasks compared to models trained with traditional methods. An adaptive curriculum, as opposed to a fixed one, is shown to be essential for efficient and effective skill acquisition.
Long-Term Dep.#
The heading ‘Long-Term Dep.’ likely refers to the paper’s exploration of long-term dependencies in sequential data. This is a crucial aspect of many complex tasks, especially in reinforcement learning, where an agent’s current actions significantly impact future rewards. The research likely investigates how different methods, particularly masked prediction models, handle these dependencies. The authors probably compare models trained with various masking strategies, highlighting how random masking might struggle to capture long-range interactions, while alternative techniques, perhaps involving structured or curriculum-based masking, might be more effective. The results might show that models capturing long-term dependencies achieve better performance on tasks requiring complex planning and skill acquisition. This would be a key finding, demonstrating the effectiveness of the proposed masking scheme in building more sophisticated agents. The paper might analyze the impact of masking schemes on the learned representations, showing how certain strategies might enable the model to effectively capture long-term dependencies.
Future Work#
Future research directions stemming from this work on curriculum masked prediction for offline reinforcement learning could explore several promising avenues. Extending the approach to more complex environments, such as those involving image-based inputs or high-dimensional state spaces, would be crucial to demonstrate the robustness and generalizability of the method. Investigating different curriculum designs beyond the multi-armed bandit approach used here, perhaps incorporating more sophisticated methods for task scheduling, would also be valuable. Analyzing the impact of various hyperparameters on the performance and learning dynamics of CurrMask, and optimizing these parameters through automated hyperparameter optimization techniques, is another important consideration. Finally, a thorough investigation of the theoretical properties of curriculum masked prediction, and a deeper understanding of its effectiveness in fostering generalization and transfer learning, would enhance the theoretical foundations of the approach and its broad applicability.
More visual insights#
More on figures
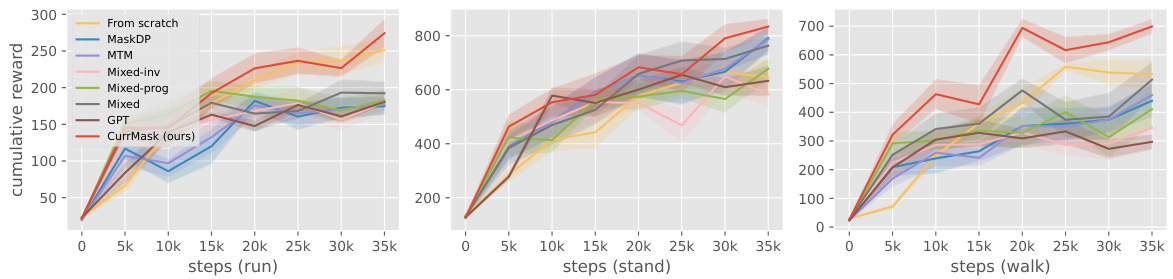
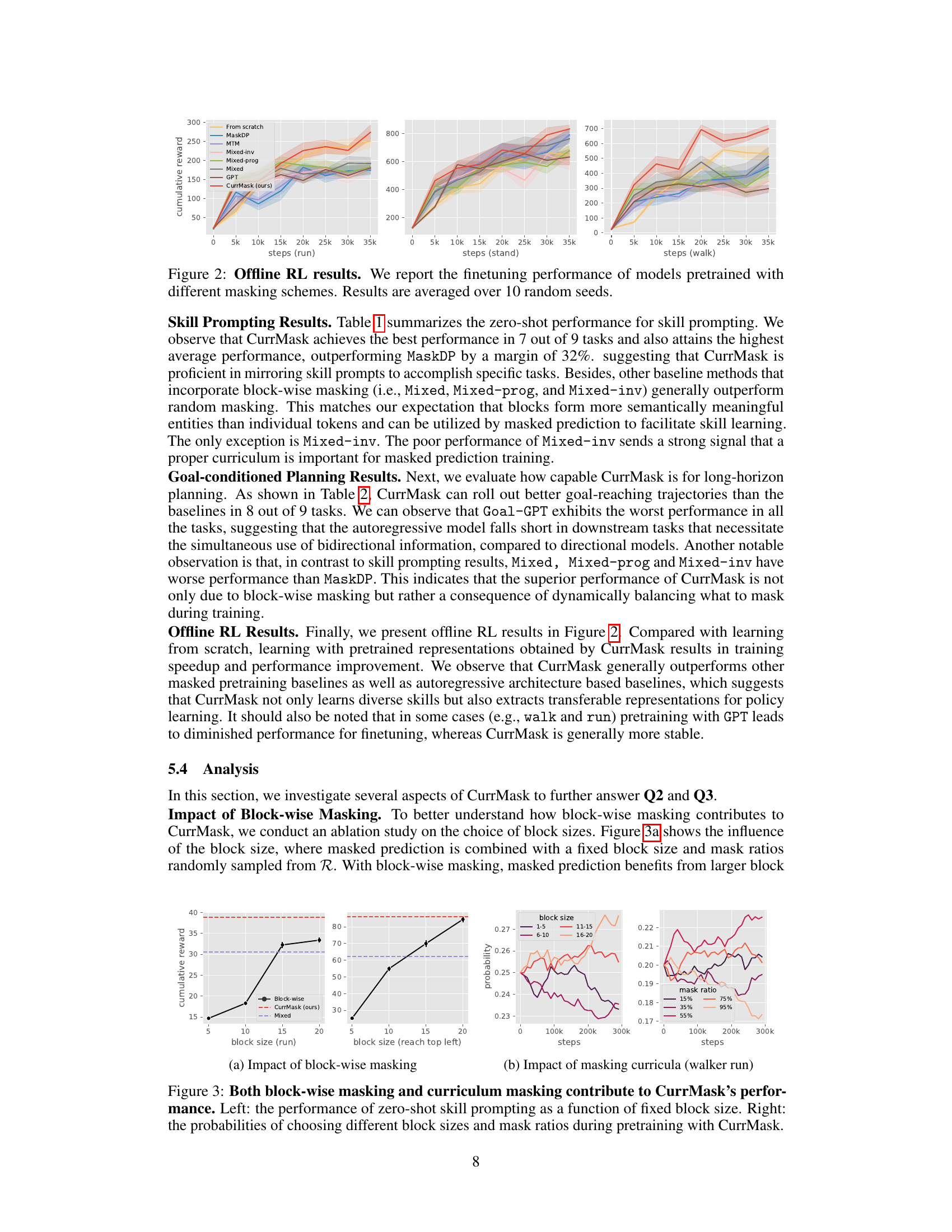
🔼 This figure presents the results of offline reinforcement learning (RL) experiments. Models were pretrained using different masking schemes (detailed in the paper), then fine-tuned on offline RL tasks. The plots show the cumulative reward achieved over training steps for three different locomotion tasks: run, stand, and walk. Error bars represent the standard deviation across 10 runs. The figure compares the performance of CurrMask (the proposed method) to several baselines, demonstrating its effectiveness in improving offline RL performance.
read the caption
Figure 2: Offline RL results. We report the finetuning performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds.
🔼 This figure shows the cumulative reward achieved by different models during the finetuning phase of offline reinforcement learning. The models were initially pretrained using various masking schemes. The x-axis represents the training steps, and the y-axis shows the cumulative reward. The figure compares the performance of CurrMask against several baselines, demonstrating the superior performance of CurrMask in terms of both speed and final reward.
read the caption
Figure 2: Offline RL results. We report the finetuning performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds.

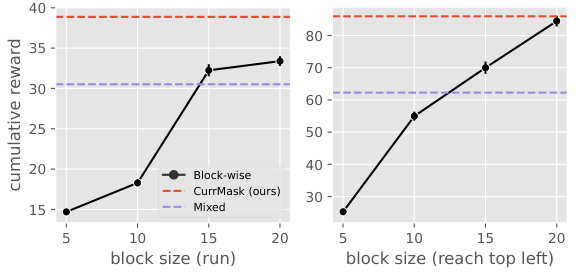
🔼 This figure shows the impact of block-wise masking and curriculum masking on the zero-shot skill prompting performance of the CurrMask model. The left panel shows that using larger block sizes for masking generally improves performance, indicating that block-wise masking helps to capture longer-term dependencies. The right panel shows the probabilities of selecting different block sizes and mask ratios during the curriculum learning process. The probabilities change dynamically during training, reflecting the model’s adaptation to different levels of complexity. This adaptive curriculum learning strategy is crucial for CurrMask’s success.
read the caption
Figure 3: Both block-wise masking and curriculum masking contribute to CurrMask's performance. Left: the performance of zero-shot skill prompting as a function of fixed block size. Right: the probabilities of choosing different block sizes and mask ratios during pretraining with CurrMask.

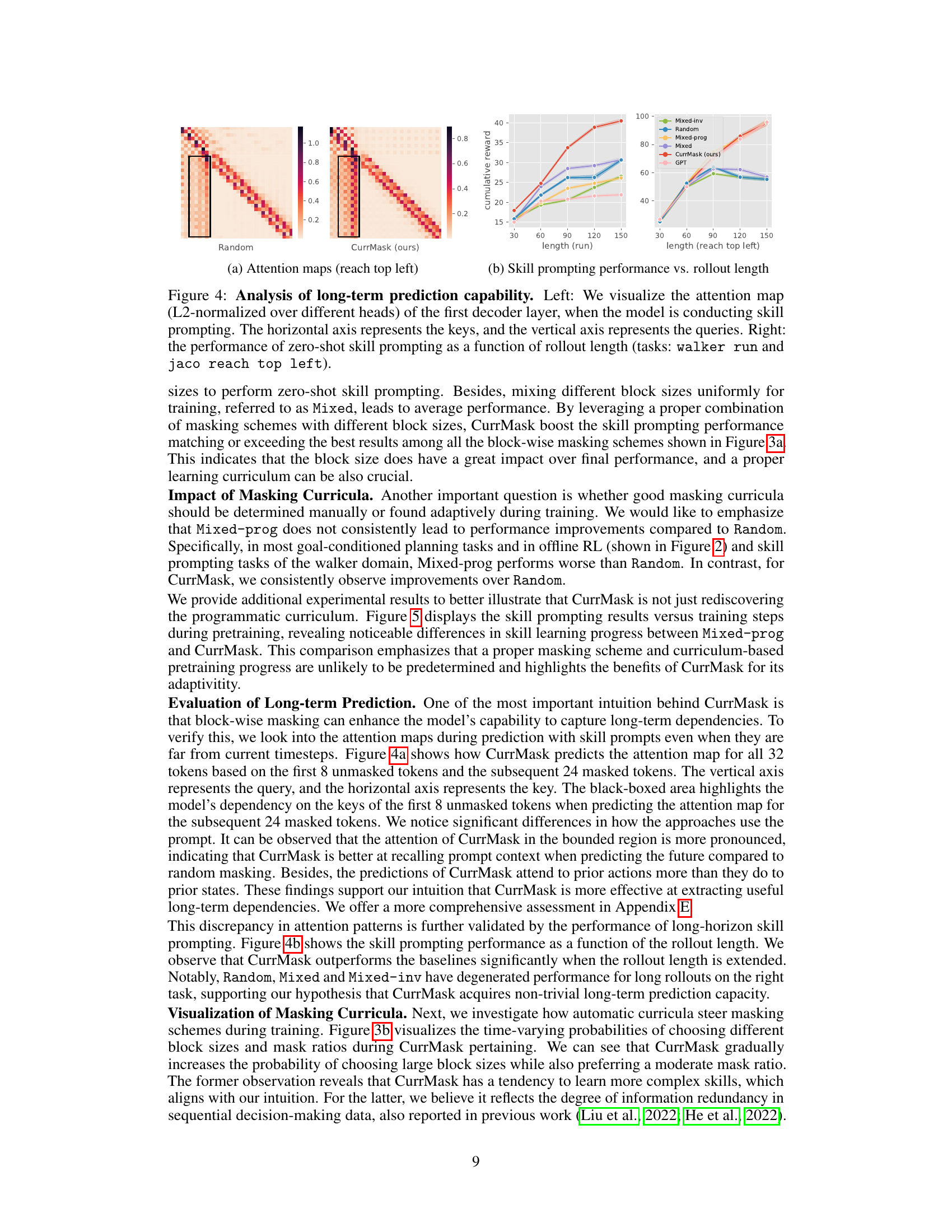
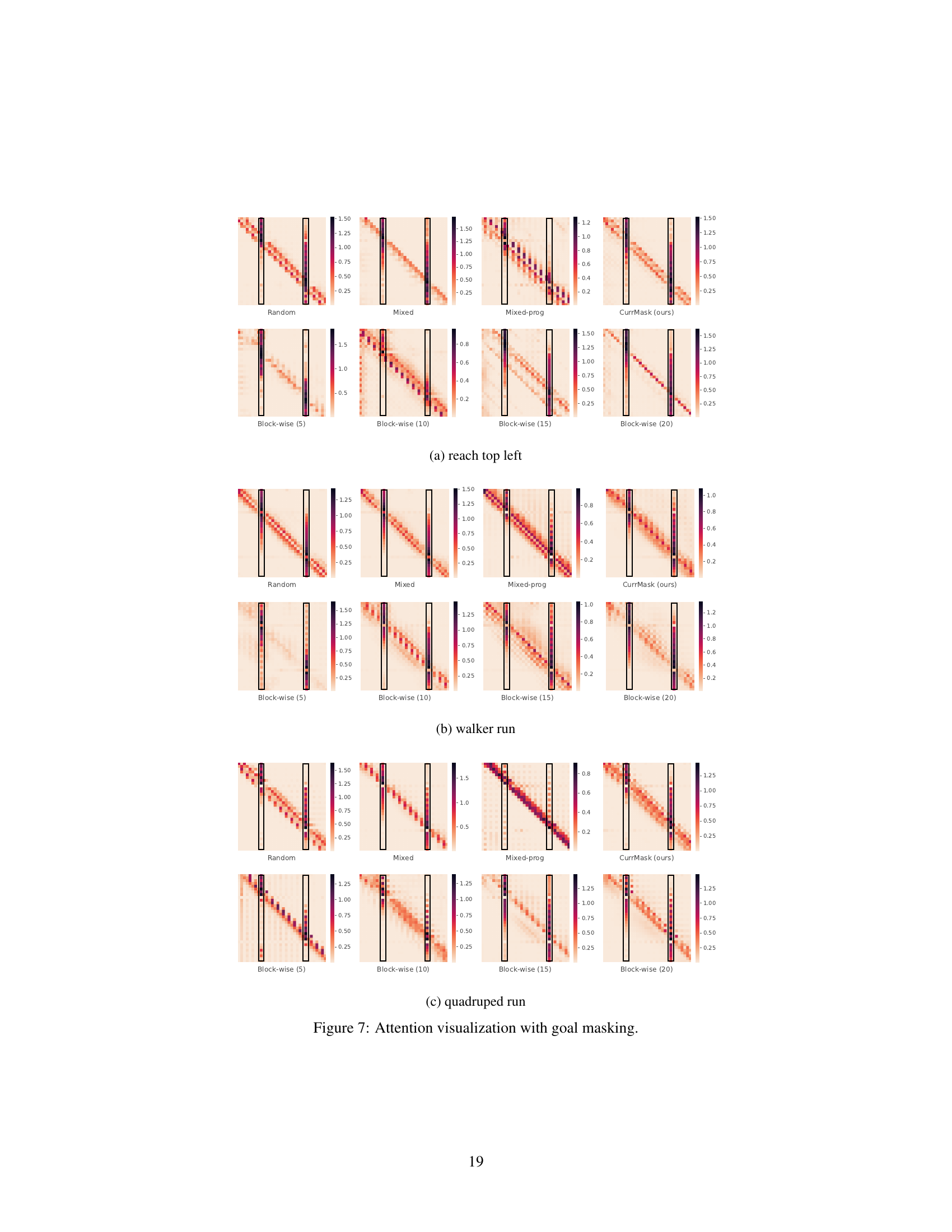
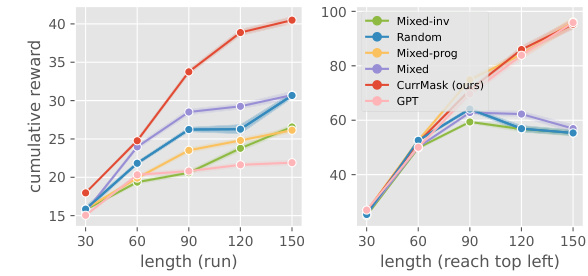
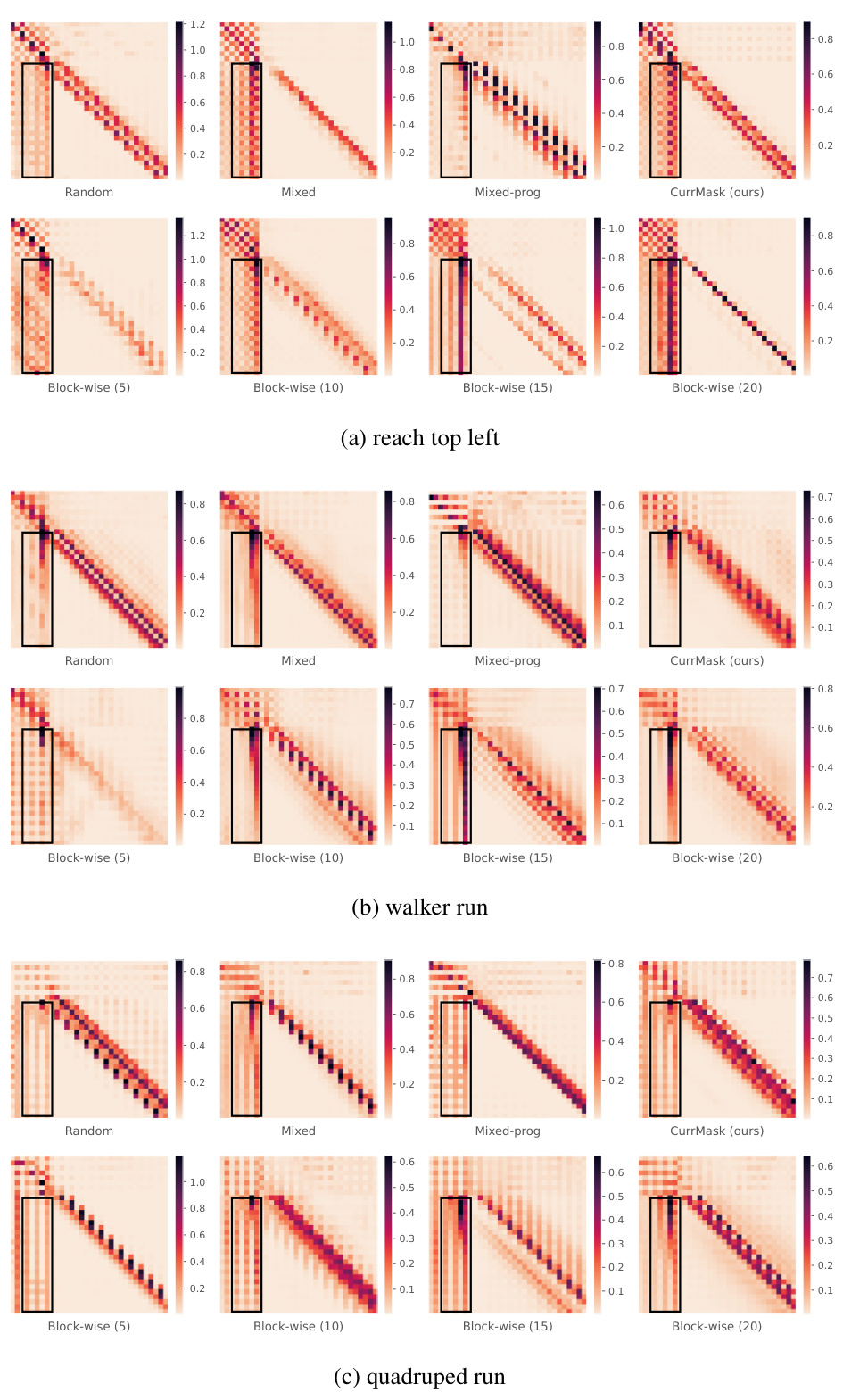
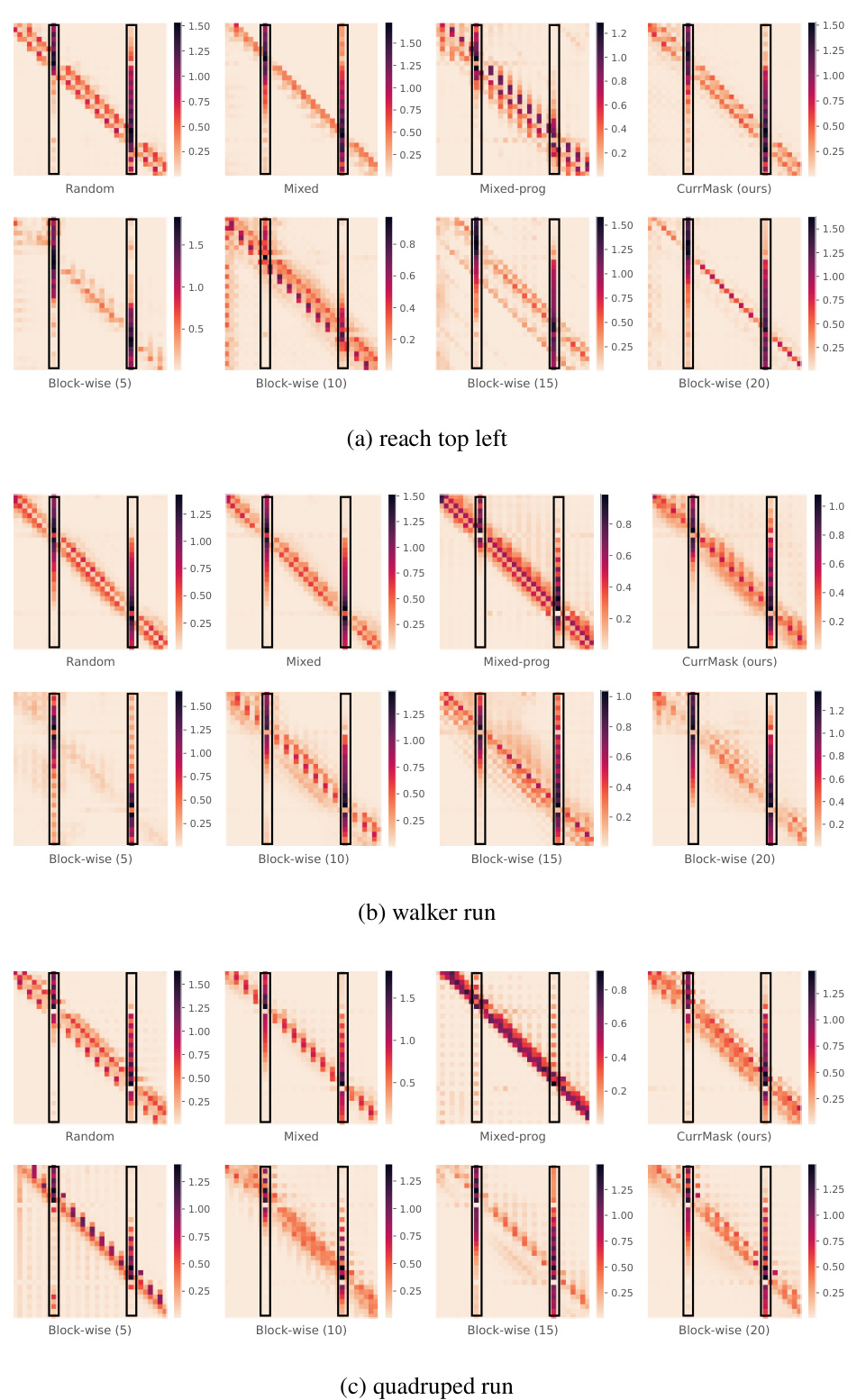
🔼 The figure demonstrates the attention maps and the performance of zero-shot skill prompting at different rollout lengths. The left panel shows the attention maps of the first decoder layer during skill prompting, highlighting the model’s focus on different parts of the input sequence. The right panel shows how the performance of zero-shot skill prompting changes as the rollout length increases, comparing the performance of CurrMask with other baselines.
read the caption
Figure 4: Analysis of long-term prediction capability. Left: We visualize the attention map (L2-normalized over different heads) of the first decoder layer, when the model is conducting skill prompting. The horizontal axis represents the keys, and the vertical axis represents the queries. Right: the performance of zero-shot skill prompting as a function of rollout length (tasks: walker run and jaco reach top left).
🔼 This figure shows the cumulative reward achieved by different models during the finetuning phase of offline reinforcement learning. The models were pretrained using various masking schemes (MaskDP, MTM, Mixed-inv, Mixed-prog, Mixed, GPT, and CurrMask). The x-axis represents the number of steps in the training process for three different tasks (run, stand, and walk) in the walker environment. The y-axis represents the cumulative reward obtained. The figure demonstrates the effectiveness of CurrMask in improving the performance of offline RL agents compared to other methods.
read the caption
Figure 2: Offline RL results. We report the finetuning performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds.
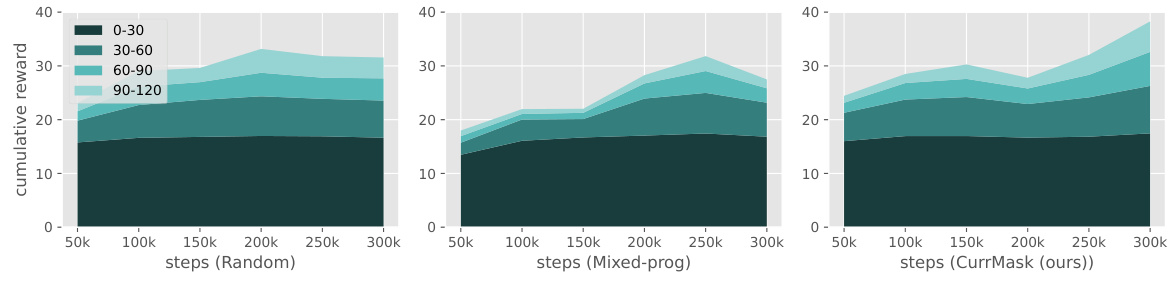
🔼 This figure shows the cumulative reward achieved by different methods for skill prompting on the Walker run task during the pretraining phase. The x-axis represents the number of training steps, and the y-axis represents the cumulative reward. The area chart displays the performance broken down into segments of 30 steps (0-30, 30-60, 60-90, 90-120). The figure compares three different approaches: Random masking, the Mixed-prog curriculum, and CurrMask (the proposed method). It visually demonstrates that CurrMask learns skills more efficiently and adapts its masking scheme dynamically, leading to higher cumulative rewards compared to the other methods.
read the caption
Figure 5: Skill prompting performance on Walker run in the pretraining phase.
🔼 This figure displays the cumulative reward achieved during the finetuning phase of offline reinforcement learning for various models pretrained using different masking schemes. The x-axis represents the number of training steps, and the y-axis represents the cumulative reward. The plot shows that models pretrained with CurrMask generally outperform other methods, indicating that CurrMask’s curriculum masking strategy leads to more effective skill learning and faster adaptation to new tasks.
read the caption
Figure 2: Offline RL results. We report the finetuning performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds.
🔼 This figure shows the results of applying different pre-trained models (with different masking schemes) to offline reinforcement learning tasks. The models were first pre-trained using masked prediction, then fine-tuned for specific offline RL tasks. The graph likely displays metrics such as cumulative reward over training steps for each model. This allows for comparison of the models’ performance after fine-tuning and demonstrates the effectiveness of CurrMask’s pre-training strategy on downstream tasks.
read the caption
Figure 2: Offline RL results. We report the finetuning performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds.
More on tables

🔼 This table presents the zero-shot performance results for skill prompting across various tasks using different model training methods. The performance metric is reward, and results are averages over ten random seeds. The best-performing and second-best-performing methods for each task are highlighted.
read the caption
Table 1: Skill prompting results. We report the zero-shot performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds. The best and second results are bold and underlined, respectively.

🔼 This table presents the results of goal-conditioned planning experiments. The zero-shot performance of different models pretrained with various masking schemes is shown. The results are averaged over 20 trials to ensure statistical reliability, with the best and second-best results highlighted. Lower values indicate better performance, as the metric is the average L2 distance between the achieved state and the target goal state.
read the caption
Table 2: Goal-conditioned planning results. We report the zero-shot performance of models pretrained with different masking schemes. Results are averaged over 20 random seeds. The best and second results are bold and underlined, respectively. The lower the better.

🔼 This table presents the zero-shot performance of various models on skill prompting tasks. Models were pre-trained using different masking schemes (MaskDP, MTM, Mixed-inv, Mixed-prog, Mixed, GPT, CurrMask). The results, averaged over 10 random seeds, show the performance on several locomotion and robotic arm manipulation tasks. The best and second-best performing models for each task are highlighted.
read the caption
Table 1: Skill prompting results. We report the zero-shot performance of models pretrained with different masking schemes. Results are averaged over 10 random seeds. The best and second results are bold and underlined, respectively.
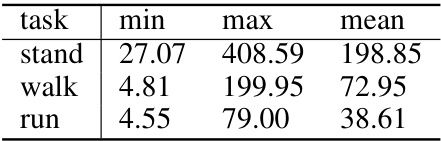
🔼 This table presents the minimum, maximum, and mean episodic returns observed during the training of offline reinforcement learning (RL) datasets for three locomotion tasks: stand, walk, and run. These statistics summarize the performance of the agents used to generate the offline RL data, which is then used to train the model in the experiments. The variation in return values indicates the diversity and quality of the experiences within the training datasets.
read the caption
Table 3: Episodic return statistics of training datasets used for offline RL.
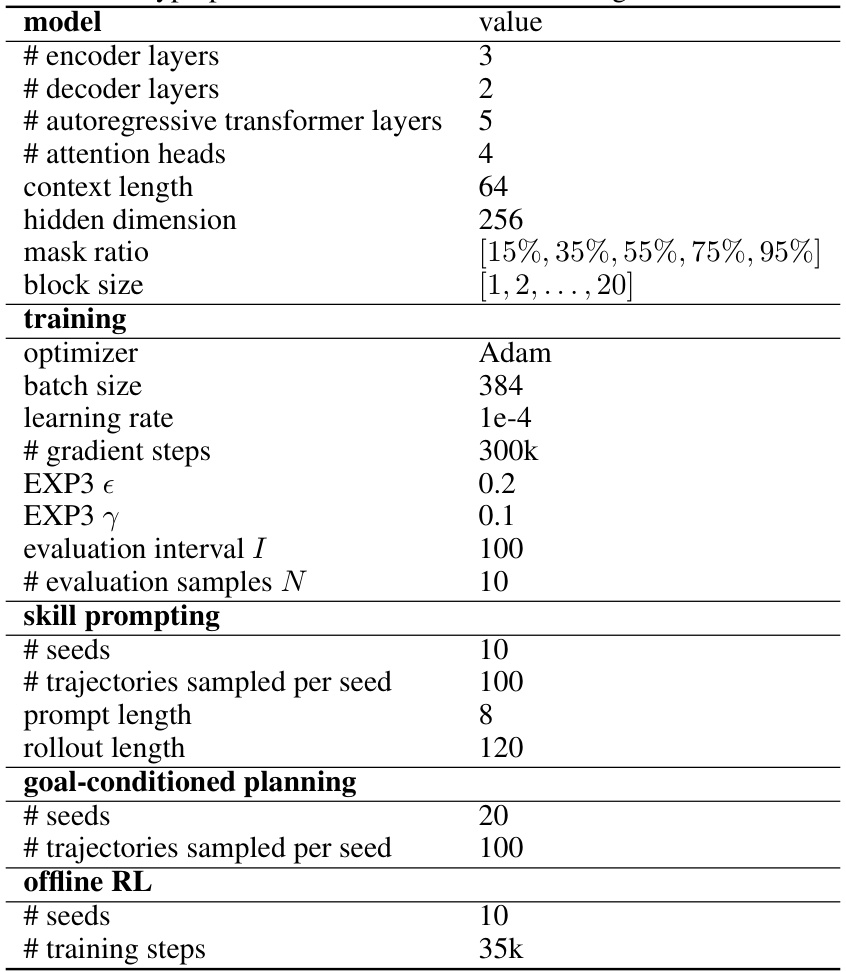
🔼 This table lists the hyperparameters used for training and evaluating the models in the paper. It includes parameters related to the model architecture (number of layers, attention heads, hidden dimension), training process (optimizer, batch size, learning rate, number of gradient steps), and experimental settings for skill prompting, goal-conditioned planning, and offline RL. The hyperparameters for the EXP3 algorithm, used for curriculum learning, are also specified.
read the caption
Table 4: Hyperparameters used for model training and evaluation.

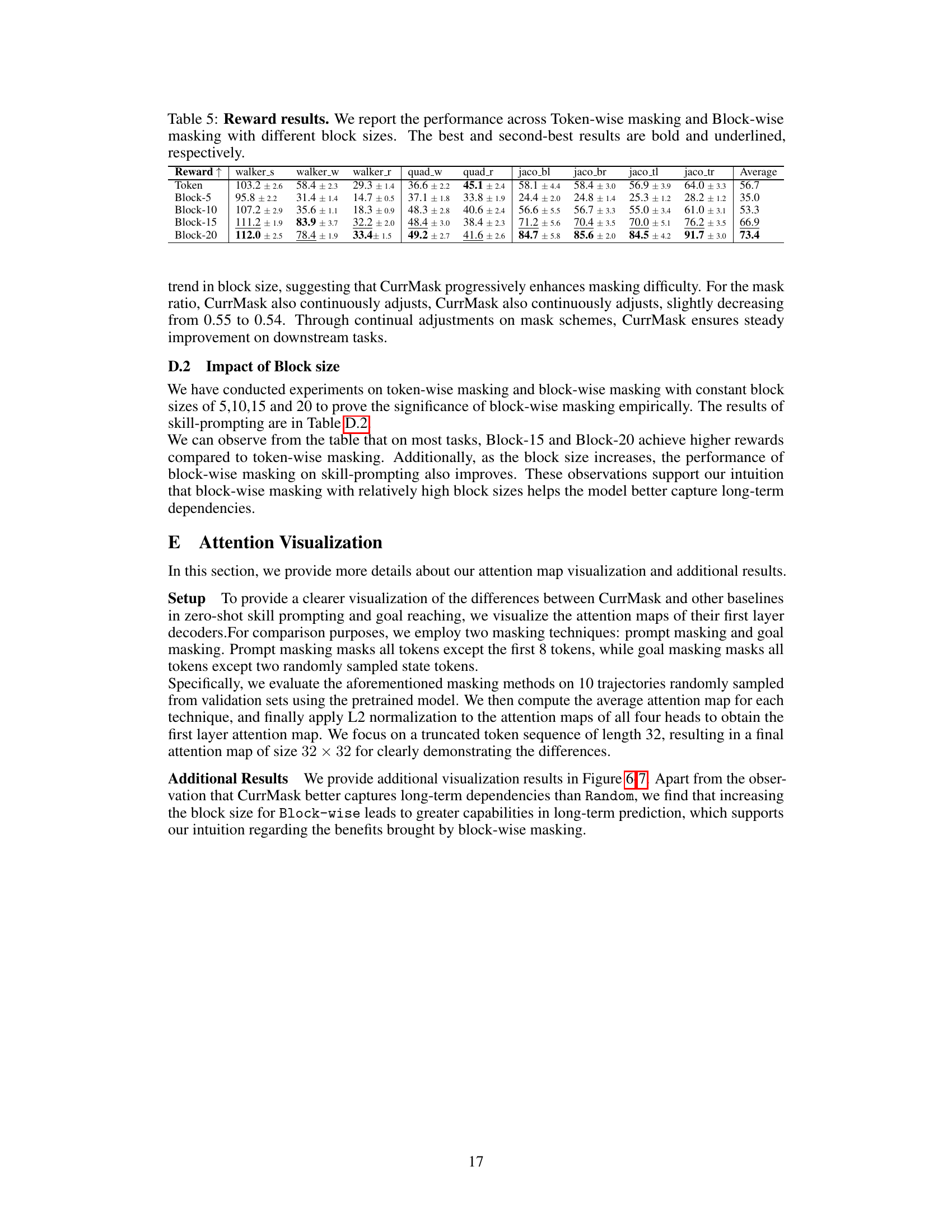
🔼 This table presents the average reward obtained across different tasks (walker_s, walker_w, walker_r, quad_w, quad_r, jaco_bl, jaco_br, jaco_tl, jaco_tr) using various masking schemes. The ‘Token’ row shows results using token-wise masking, while the other rows show results for block-wise masking with different block sizes (5, 10, 15, 20). Higher reward values indicate better performance. The best and second-best results for each task are highlighted in bold and underlined, respectively. This allows for a comparison of the effectiveness of different masking strategies and block sizes on overall task performance.
read the caption
Table 5: Reward results. We report the performance across Token-wise masking and Block-wise masking with different block sizes. The best and second-best results are bold and underlined, respectively.
Full paper#