TL;DR#
Many recent works have focused on improving the consistency of images generated via diffusion models. However, simply manipulating attention modules by concatenating features from multiple reference images, while efficient, lacks a clear theoretical understanding of its effectiveness. This paper aims to address this gap by investigating the underlying mechanisms and proposing a novel approach, RefDrop.
RefDrop reveals that the popular approach using concatenated attention actually performs linear interpolation of self-attention and cross-attention. It then introduces Reference Feature Guidance (RFG), a flexible method that allows users to directly control the influence of reference context. Experiments demonstrate that RefDrop achieves controllable consistency in image and video generation, showing superior performance compared to existing methods in terms of quality, flexibility, and ease of implementation. This method significantly advances research in controllable consistency, especially for high-quality, personalized video generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on image and video generation using diffusion models. It introduces a training-free, plug-and-play method that significantly improves controllability and consistency, addressing a major challenge in the field. The proposed method, RefDrop, opens up new avenues for creative applications such as consistent multi-subject generation, feature blending, and high-quality video generation. It is also relevant to current trends in generative AI, which prioritize enhancing the controllability and quality of outputs.
Visual Insights#

🔼 This figure demonstrates the capabilities of the RefDrop model in three key areas: 1. Generating multiple consistent images of a single subject with variations in activities. 2. Seamlessly blending features from different images to create novel combinations, such as a half-fairy, half-devil woman. 3. Generating temporally consistent personalized videos. It highlights RefDrop’s flexibility and controllability in content creation.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method Ref Drop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This table compares several methods for controllable consistent image generation. It highlights whether each method is training-free (no need for additional training), allows for concept suppression (suppressing specific features), and works with a single reference image.
read the caption
Table 1: Comparison of Controllable Consistent Image Generation Methods. ‘Training-free’ indicates no encoder training or diffusion model fine-tuning is needed. ‘Single ref.’ means the method can operate with only one reference image.
In-depth insights#
RefDrop: Overview#
RefDrop, as a training-free method, offers a novel approach to controlling consistency in image and video generation using diffusion models. Its core innovation lies in the precise and direct manner in which it manipulates the influence of reference features within the attention mechanism of the underlying UNet architecture. Instead of simply concatenating features (a linear interpolation implicitly present in prior methods), RefDrop introduces a scalar coefficient to directly modulate this influence, providing users with fine-grained control over consistency. This allows for flexible control, enabling applications like multi-subject consistency, feature blending, and suppression of unwanted features to enhance diversity. The plug-and-play nature of RefDrop is a key strength, avoiding the need for additional training or separate encoders often required by other comparable methods. By revealing the underlying mechanics of prior consistency-enhancing techniques, RefDrop offers a more efficient and versatile approach, making it a significant advancement in controllable image and video synthesis.
Controllable Consistency#
Controllable consistency in image or video generation is a significant challenge, demanding fine-grained control over the output’s visual aspects. The core idea revolves around maintaining uniformity across multiple generated samples while allowing for creative variations. Existing methods often involve complex training procedures or substantial modifications to the underlying models, which can be computationally expensive and limit flexibility. This research explores alternative approaches that focus on direct manipulation of the generation process, enabling users to precisely control consistency through simple parameters like a coefficient. A key innovation is the training-free aspect, making the method easily adaptable to various models without retraining, thereby offering a versatile plug-and-play solution. The algorithm demonstrates improved controllability across numerous tasks, including multi-subject image generation, seamless blending of features, and temporal consistency in video generation, showing promising results with state-of-the-art image-prompt-based generators. While the method offers considerable advantages, limitations regarding fine-grained control over specific features or styles remain, highlighting the need for further development.
RFG Mechanism#
The core of the RefDrop approach lies in its Reference Feature Guidance (RFG) mechanism. RFG is a training-free method designed to precisely control the consistency of image or video generation by directly manipulating the attention mechanism within a diffusion model’s U-Net architecture. Instead of concatenating features from reference images, as prior methods did, RFG performs a linear interpolation between the self-attention of the generated content and the cross-attention with reference features. This interpolation is controlled by a single scalar coefficient, allowing for fine-grained control over the influence of the reference. Crucially, RFG reveals that the effectiveness of prior methods stems from this implicit linear interpolation, rather than simply from feature concatenation alone. The simplicity and flexibility of RFG’s scalar coefficient make it versatile and plug-and-play, easily adaptable to various diffusion models and applicable to diverse tasks including multi-subject consistency, feature blending, and temporal consistency in video generation. The ability to use negative coefficients further enhances the utility of RFG, enabling the suppression of specific features from reference images, thus promoting diversity.
Experiments & Results#
The ‘Experiments & Results’ section of a research paper is crucial for validating the claims made in the introduction and demonstrating the effectiveness of the proposed method. A strong experiments section should clearly define the research questions, meticulously detail the experimental setup, including datasets used, evaluation metrics, and hyperparameters. Reproducibility is paramount; providing enough detail to allow others to replicate the experiments is essential for validating the findings. The results themselves should be presented clearly and concisely, using appropriate visualizations (e.g., tables, charts) to highlight key trends and comparisons with baseline methods. Statistical significance testing should be conducted to ensure the observed results are not due to random chance. A thorough analysis of the results is also necessary, discussing both the successes and limitations of the approach. Addressing potential confounding factors and limitations is crucial for building credibility and fostering a deeper understanding of the work’s scope and impact. Overall, a well-written ‘Experiments & Results’ section forms the backbone of a compelling research paper, presenting evidence to support the study’s claims and contributing to the advancement of the research field.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending RefDrop’s capabilities to handle more complex scenarios, such as generating consistent images with intricate details or multiple interacting subjects, would significantly broaden its applications. Investigating the effect of attention masks within the RefDrop framework could allow for more precise control over feature injection. Addressing the challenges of video generation more directly by incorporating temporal consistency mechanisms would enhance video quality and address current limitations. Furthermore, exploring the potential of different coefficient strategies beyond the rank-1 coefficient used in this work could lead to more nuanced control over the level of consistency. Finally, applying RefDrop to other diffusion models and evaluating its performance across various architectures would determine its generalizability and applicability.
More visual insights#
More on figures

🔼 This figure illustrates the RefDrop’s mechanism. It shows how reference features from a generated image (I₁) are injected into the generation process of other images (Iᵢ) through a Reference Feature Guidance (RFG) layer. The RFG layer linearly combines attention outputs from both standard and referenced routes using a coefficient ‘c’. A positive ‘c’ promotes consistency between Iᵢ and I₁, while a negative ‘c’ encourages divergence.
read the caption
Figure 2: During each diffusion denoising step, we facilitate the injection of features from a generated reference image I₁ into the generation process of other images through RFG. The RFG layer produces a linear combination of the attention outputs from both the standard and referenced routes. A negative coefficient c encourages divergence of I¿ from I₁, while a positive coefficient fosters consistency.

🔼 This figure shows how RefDrop allows for flexible control over the influence of a reference image on the generated image. By adjusting the ‘reference strength’ coefficient (c), users can seamlessly transition between negative similarity (c = -0.4), where the generated image diverges from the reference, and positive similarity (c = 0.4), where the generated image closely resembles the reference. The central column (c = 0) represents the output of the base model without reference guidance. Two examples are shown: a cyberpunk woman on a hoverbike and a cylindrical cream bottle in a forest. This demonstrates the controllability offered by RefDrop.
read the caption
Figure 3: We allow flexible control over the reference effect through a reference strength coefficient.

🔼 This figure compares the results of four different methods (Ours, IP-Adapter, Ref-ControlNet, and BLIPD) for generating consistent images, using a single reference image (shown in red). The comparison highlights RefDrop’s (Ours) ability to maintain consistency in hairstyles and facial features while producing images with diverse spatial layouts, in contrast to the other methods.
read the caption
Figure 4: The reference image for all methods is framed in red. Our method tends to produce more consistent hairstyles, and facial features compared to IP-Adapter, Ref-ControlNet and BLIPD, and our generation has diverse spatial layout. The visual quality of BLIPD is not comparable, as it utilizes SD1.5 [48] as its base model.

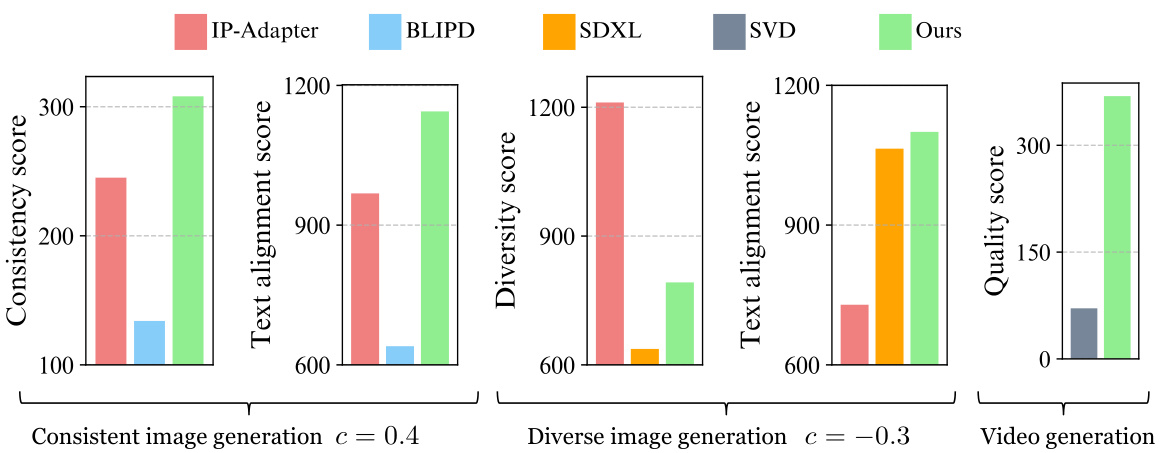
🔼 This figure shows the impact of applying the RFG method with and without excluding the first upsampling block and adding a subject mask. Excluding the first upsampling block helps to reduce the spatial layout leakage, preventing generated objects from having similar poses and backgrounds as the reference image. Adding the subject mask further refines the results by minimizing background leakage, leading to more diverse and natural-looking outputs. The results demonstrate the effectiveness of these techniques in controlling the generation process for enhanced visual quality and diversity.
read the caption
Figure 5: Excluding one block from applying RFG solves the spatial layout leakage issue. Adding subject mask solves the background leakage issue.

🔼 This figure demonstrates RefDrop’s ability to blend features from multiple reference images. Each row shows two distinct reference images (e.g., a superhero and Black Widow, a Japanese temple and a mosque). RefDrop generates a new image that seamlessly combines features from both references. In contrast, the SDXL baseline struggles to produce the same level of cohesive blending of features.
read the caption
Figure 6: Multiple Reference Images: The reference images are highlighted with a red frame, and the third image in each set is the resultant blended image. RefDrop effectively assimilates features from the distinct reference images into a single and cohesive entity, demonstrating robust feature integration capability.

🔼 This figure shows how RefDrop allows flexible control over the influence of a reference image on the generated image. It presents several images generated with different reference strength coefficients (c) ranging from -0.4 to 0.4. Negative coefficients (negative similarity) encourage divergence from the reference, resulting in less consistent but more diverse images. Positive coefficients (positive similarity) increase consistency, leading to more similar-looking outputs. The images showcase the versatility of the method in controlling the level of consistency between the reference and generated images.
read the caption
Figure 3: We allow flexible control over the reference effect through a reference strength coefficient.

🔼 This figure demonstrates the diverse image generation capabilities of RefDrop compared to SDXL and IP-Adapter. RefDrop maintains accurate text alignment while producing more diverse outfits and hairstyles, unlike SDXL which tends towards repetitive features. IP-Adapter, although showing greater diversity, often fails to accurately represent the text prompt and produces oddly proportioned figures.
read the caption
Figure 8: Diverse image generation: Our method enhances diversity in outfits, hairstyles, and facial features, all while ensuring accurate text alignment. For example, while SDXL frequently generates headscarves in the first scenario and beige-colored clothes in the second, RefDrop can vary the presence of headscarves in the left example and produce clothing in different colors in the right example. Conversely, although IP-Adapter can create even more diverse images, it often fails to adhere to the style and human activity instructions in the text prompts. Additionally, it often produces overly small persons that lack detail.

🔼 This figure compares several training-free techniques for improving temporal consistency in video generation. The methods being compared include: RefDrop (the authors’ method), Concatenated Attention, LPFF (Temporal Low Pass Frequency Filter), and unmodified SVD. The results visually demonstrate the effectiveness of RefDrop in stabilizing the video generation compared to the other methods, showing a significant reduction in flickering while maintaining motion and generating higher quality videos.
read the caption
Figure 9: Comparison of training free techniques to improve temporal consistency in video generation.

🔼 This figure showcases RefDrop’s capabilities in generating consistent visual content. The top row demonstrates its ability to create multiple images featuring the same subject consistently, starting from a single reference image. The middle row highlights the seamless blending of characteristics from multiple reference images into a single output. The bottom row displays its capacity to produce temporally consistent videos.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method Ref Drop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.
🔼 This figure showcases RefDrop’s capabilities in three key areas: generating multiple subjects consistently from a single reference image; seamlessly blending features from multiple images to create a unified image; and improving temporal consistency for personalized video generation. The top row demonstrates consistent generation of multiple subjects, all related to a single reference image. The middle row illustrates the ability to seamlessly blend features from different images, effectively merging attributes of different subjects into a cohesive output. The bottom row showcases the enhancement of temporal consistency in video generation, resulting in smoother transitions and improved quality.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method RefDrop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This figure showcases RefDrop’s ability to generate consistent visual content across various scenarios. The top row demonstrates multi-subject consistency, where multiple images are generated, all maintaining consistency with a single reference image. The middle row illustrates seamless blending of characters from multiple images, creating a new image with features from each. The bottom row highlights RefDrop’s capability in generating temporally consistent videos.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method Ref Drop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This figure compares the results of consistent image generation using different methods: RefDrop, IP-Adapter, Ref-ControlNet, and BLIPD. RefDrop shows more consistent generation of hairstyles and facial features, and demonstrates more diversity in the overall layout of the generated image. BLIPD’s output is of lower visual quality due to using an older model.
read the caption
Figure 4: The reference image for all methods is framed in red. Our method tends to produce more consistent hairstyles, and facial features compared to IP-Adapter, Ref-ControlNet and BLIPD, and our generation has diverse spatial layout. The visual quality of BLIPD is not comparable, as it utilizes SD1.5 [48] as its base model.

🔼 This figure shows how the strength of the reference image influences the generated image. It shows a range of coefficients from -0.4 to 0.4, illustrating how negative coefficients encourage divergence from the reference and positive coefficients promote consistency. The example shows a young woman in various styles, demonstrating the controllability of RefDrop over different aspects of the image’s style and content.
read the caption
Figure 3: We allow flexible control over the reference effect through a reference strength coefficient.
🔼 This figure showcases three key capabilities of the RefDrop method: generating multiple subjects consistently using a single reference image; seamlessly blending features from multiple reference images; and enhancing temporal consistency for high-quality personalized video generation. The results demonstrate RefDrop’s flexibility and effectiveness in controlling consistency across various visual content generation tasks.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method Ref Drop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This figure demonstrates three key capabilities of the RefDrop method: generating multiple consistent subjects from a single reference image; seamlessly blending features from multiple reference images; and generating temporally consistent personalized videos. Each row shows examples of the method’s output compared to other state-of-the-art methods, highlighting RefDrop’s superior flexibility and quality.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method RefDrop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This figure compares the image generation results of three different methods: Naive SDXL, Ours (RefDrop), and IP-Adapter. Each row shows a set of generated images from the same prompt, highlighting the diversity achieved by each method. RefDrop demonstrates a good balance between consistency and diversity, while IP-Adapter tends toward higher diversity at the cost of alignment with the prompt. Naive SDXL shows the least diversity among the three.
read the caption
Figure 17: More diverse image generation comparison.

🔼 This figure shows a comparison of image generation results between RefDrop and SDXL. Given two reference images (a Russian Blue cat and a Border Collie), the models were prompted to generate images of the combined creature engaging in various actions (swimming, jumping, playing guitar). RefDrop successfully blends the features of both animals into a single, consistent image that closely matches the prompt description. In contrast, SDXL struggles to create a cohesive image, producing outputs that are less consistent and less faithful to the prompt.
read the caption
Figure 18: Blending a dog and a cat in various activities: RefDrop successfully combines features from two reference images and closely follows the text prompt, whereas SDXL struggles to generate a single cohesive object even with the guidance from the text prompt.

🔼 This figure showcases RefDrop’s capabilities in three key areas: generating multiple consistent subjects from a single reference image, seamlessly blending features from multiple images, and enhancing temporal consistency for high-quality video generation. The top row demonstrates multi-subject consistency, the middle row shows feature blending, and the bottom row illustrates temporal consistency in video generation. Each example compares RefDrop’s results to those of other state-of-the-art methods, highlighting RefDrop’s improved controllability and visual quality.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method RefDrop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This figure shows a comparison of image generation results between the proposed RefDrop method and the baseline SDXL model. The task is to blend features from three distinct source images (a dwarf, Black Widow, and Winnie-the-Pooh) into a single image using a text prompt describing Winnie-the-Pooh with specific features. The RefDrop result successfully integrates the features from all three reference images, while the SDXL result favors the features of the primary subject (Winnie-the-Pooh) and under-represents those of the other two.
read the caption
Figure 20: Blending three distinct subjects, we use the same prompt-'a portrait of Winnie the Pooh with red hair and a gray beard'-for both SDXL and RefDrop. However, SDXL significantly downplays the features of Winnie the Pooh. In contrast, our approach effectively absorbs the features from the reference images, retaining the dwarf's outfit and beard, Black Widow's red hair, and Winnie's facial structure.

🔼 This figure demonstrates RefDrop’s capabilities in three aspects of content generation: multi-subject consistency, feature blending, and temporal consistency in videos. The top row shows multiple consistent images generated from a single reference image. The middle row showcases seamless blending of features from multiple reference images. The bottom row highlights RefDrop’s ability to generate temporally consistent videos.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Bottom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method RefDrop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.

🔼 This figure compares the results of consistent image generation using four different methods: RefDrop (the proposed method), IP-Adapter, Ref-ControlNet, and BLIPD. The reference image is highlighted in red for each method. The results show that RefDrop produces images with more consistent hairstyles and facial features compared to the other methods, while also maintaining more diverse spatial layouts in the generated images. The lower visual quality of BLIPD is noted due to its use of a less advanced model (SD1.5) for generation.
read the caption
Figure 4: The reference image for all methods is framed in red. Our method tends to produce more consistent hairstyles, and facial features compared to IP-Adapter, Ref-ControlNet and BLIPD, and our generation has diverse spatial layout. The visual quality of BLIPD is not comparable, as it utilizes SD1.5 [48] as its base model.
🔼 This figure shows the effects of varying the reference strength coefficient (c) on image generation using the proposed method, Reference Feature Guidance (RFG). Different values of c (ranging from -0.4 to 0.4) control the level of influence of the reference image on the generated output. A positive c promotes consistency between the reference and generated images, while a negative c encourages divergence. The figure demonstrates the flexibility of the RFG method in controlling the level of similarity between generated images and the reference image.
read the caption
Figure 3: We allow flexible control over the reference effect through a reference strength coefficient.
🔼 This figure shows the instructions and an example for the ‘Diverse Image Generation’ part of the human evaluation in the paper. Participants were asked to rate image groups on their diversity across several aspects (human pose, accessories, background, etc.) assigning scores from 1 (least diverse) to 3 (most diverse).
read the caption
Figure 24: The instruction and example for human evaluation

🔼 This figure showcases three key capabilities of the RefDrop method: generating multiple subjects consistently using a single reference image; seamlessly blending features from multiple images to create a unified subject; and improving temporal consistency for personalized video generation. The examples visually demonstrate the flexibility and control offered by RefDrop compared to other methods.
read the caption
Figure 1: RefDrop achieves controllable consistency in visual content synthesis for free. RefDrop exhibits great flexibility in (Upper) multi-subject consistency generation given one reference image, (Middle) blending different characters from multiple images seamlessly, (Buttom) enhancing temporal consistency for personalized video generation. RefDrop is short for 'reference drop'. We named our method Ref Drop to metaphorically represent the process by which a drop of colored water influences a larger body of clear water.
More on tables

🔼 This table presents the results of an ablation study investigating the impact of excluding different UNet blocks from the reference feature guidance (RFG) process on image generation consistency and diversity. DreamSim and LPIPS scores are used to measure the visual similarity between generated images and a reference image. Higher scores indicate greater differences, suggesting increased diversity in spatial layout. The table shows that excluding the Up1 block leads to the highest DreamSim and LPIPS scores, indicating its significant contribution to spatial layout diversity. This suggests that this block plays a major role in controlling the consistency of spatial layout during image generation.
read the caption
Table 2: Comparison of DreamSim and LPIPS distances for excluding different blocks. The Up1 block of SDXL UNet shows the highest values for both metrics, indicating its strong impact on spatial layout diversity.

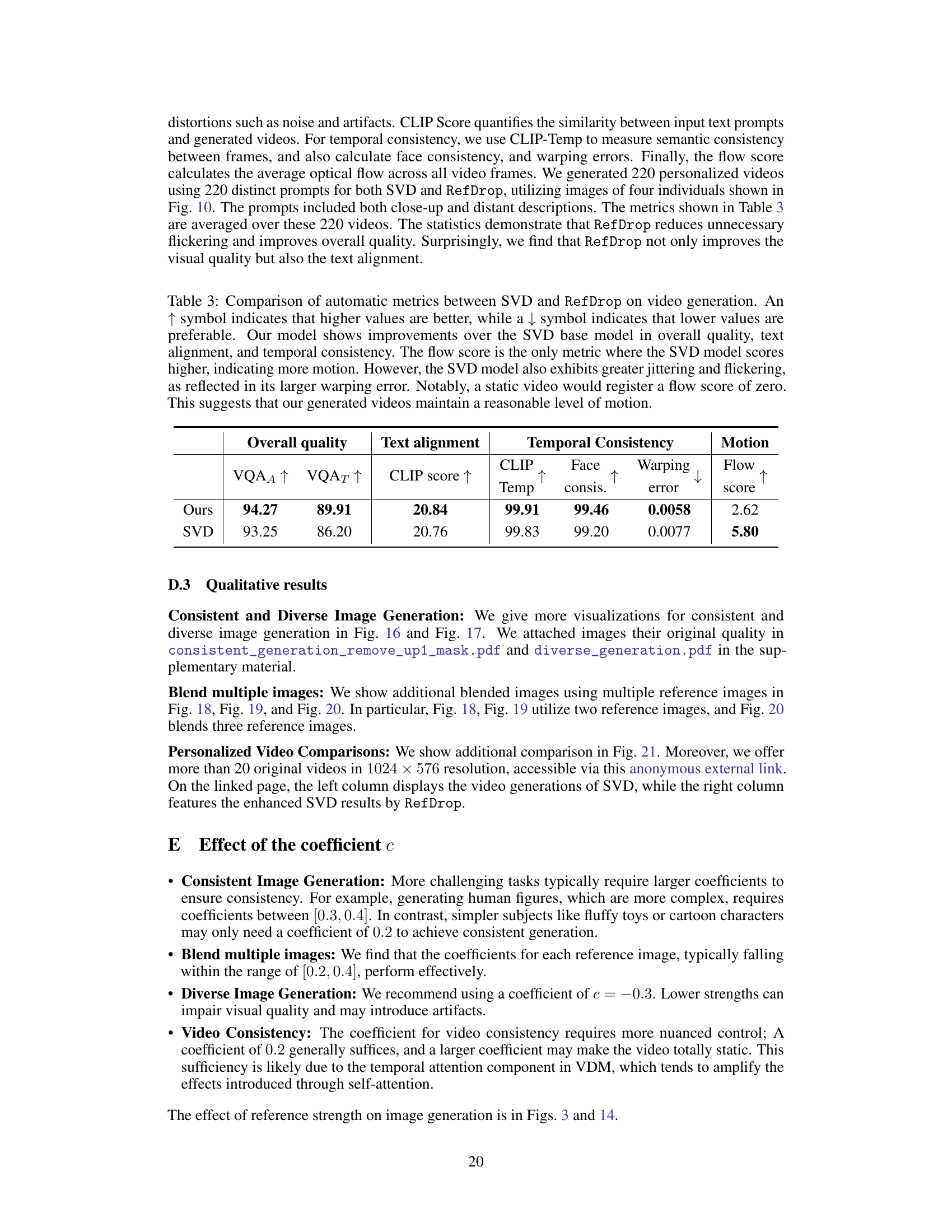
🔼 This table compares the performance of RefDrop and SVD (a baseline video generation model) using automatic metrics provided by EvalCrafter. Metrics assess overall quality, text alignment, temporal consistency (CLIP, Face consistency, warping error), and motion (flow score). RefDrop shows improvement in most metrics, suggesting higher quality and better consistency, while retaining reasonable motion.
read the caption
Table 3: Comparison of automatic metrics between SVD and RefDrop on video generation. An ↑ symbol indicates that higher values are better, while a ↓ symbol indicates that lower values are preferable. Our model shows improvements over the SVD base model in overall quality, text alignment, and temporal consistency. The flow score is the only metric where the SVD model scores higher, indicating more motion. However, the SVD model also exhibits greater jittering and flickering, as reflected in its larger warping error. Notably, a static video would register a flow score of zero. This suggests that our generated videos maintain a reasonable level of motion.

🔼 This table summarizes the base models used in different sections of the paper along with their corresponding CFG (Classifier-Free Guidance) values, reference strength coefficients (for RefDrop), IP-Adapter scales, and TLPFF (Temporal Low Pass Frequency Filter) parameters. It details the specific settings used for consistent and diverse image generation, and temporal consistent video generation experiments. Note that some values are ranges, demonstrating the flexibility of the proposed RefDrop method.
read the caption
Table 4: Base model and hyper-parameters.
Full paper#